Только что поймал себя на мысли, которая теперь не даёт мне покоя.
В слове "кешбэк" обе гласные произносятся как "э", в английском обе гласные "a", но при этом при написании на русском первая гласная "е", а вторая "э". В слове "Бэтмен" обе гласные произносятся как "э", в английском обе гласные "a", но при этом при написании на русском первая уже "э" , а вторая "е".
Сразу предупреждаю тех, кто придерживается методики "ну это же видно". В данном случае видно только то, что имеется одинаковый внешне корень "кус" в обоих словах.
Но частенько есть ещё кое-что, что сразу не увидишь. В данном случае это то, что в старославянском "вкусить" выглядело как "въкоусити" (и тому подобное: "искусить" - "искоусити"). Тогда как "кусать" писалось как "кѫсати". Бадум-тс. Совсем другой гласный в корне.
В сухом остатке: то, что сейчас пришло к виду "кус", было двумя разными корнями - один "коус" и второй "кѫс". А это неумолимо приводит нас к тому, что корни разные.
И да, скорее всего, они давным-давно перепутались, как минимум в головах носителей языка, и зачастую, в зависимости от приставок, сблизились в значении. Но изначально они даже не братья... А кто же?
Искусать
Чтобы восстановить первоначальный смысл этого глагола, пройдёмся по родственникам. Помимо употребления, идентичного нашему, где значение остаётся "кусать", то есть "вцепляться и\или отгрызать зубами", Этимологический словарь славянских языков упоминает:
болгарский "късам" ("рвать, разорвать")
словенский "kosati" ("измельчать")
белорусский "куцаць" ("долго пережёвывать")
Получается, что главное в процессе кусания - и в семантике корня "кѫс" - это измельчение и разрывание, что-то примерно такое. Нанесение ущерба, так сказать. Отсюда же слово "кусок", то есть оторванная часть.
Искусить
Здесь тот же словарь даёт других родственников:
болгарский "куся" ("пробовать на вкус, отведывать")
Таким образом, главный смысл тут, скорее, носит исследовательский характер. Речь о пробных прикосновениях, об испытаниях, опытах. Смысл ущерба от зубов может встречаться уже только как пересечение с семантикой "отведать", но он здесь глубоко косвенный (что, однако, не помешало ему в итоге смешать у людей в умах эти два корня и все их производные).
А ведь вот этот второй глагол изначально не наш, а заимствован из готского в праславянский период: "kausjan" у них переводилось тоже как "отведать, попробовать".
Можно сразу ответить на вопрос, а почему, собственно, это сразу заимствование, может быть, это был наш глагол, развивавшийся параллельно. Потому что по фонетическим соответствиям он должен был бы тогда выглядеть не как "кусити", а как "гусити", с тем же звуком [г], что и в латыни (в латыни мы этот корень действительно знаем со звуком [г] - в слове "дегустация", что опять-таки означает "проба").
Ещё пример для убедительности: ПИЕ-корень *gal- у нас дал исконное слово со звуком [г] "голос", у англичан "call", а вот заимствовали мы его тоже уже с их звуком [к] - "колл-центр". В латыни опять. как и положено, [г] - "gallus" ("петух").
А теперь давайте посмотрим, какие ещё слова получились у нас из этого "кус" в значении "пробы" и "попытки".
В древнерусском языке широко встречается слово "искус" в значении "опыт". Например, "искоусимъ врачь", то есть "опытный врач". Pдесь без труда можно узнать то, что сегодня чаще выражается словом "искусный" того же происхождения.
Слово "искусъ" также могло означать "истязания, пытки", например, в договоре с Византией от 945 года:
...аще кто от крестьянъ или от Руси мученьа образомъ искусъ творить...
Таким образом можно сделать предварительный вывод, что весь этот заимствованный корень "кус" мог бы полностью соответствовать нашему исконному "-пыт-": ведь "искус" - это "опыт" и "пытка", а "искусный" - это "опытный". "Искусить" в таком случае - это "испытать", а "искушение" логичным образом равно "испытанию", а "покуситься" - это "попытаться", "покушение" - "попытка".
Слово "искусство" тоже входит в это гнездо. Сначала оно означало именно "высокую степень мастерства" - подразумевая, что мастерство получено в процессе приобретения опыта, а уже позже оно стало также использоваться для названия отдельных видов искусств.
"Искусственный" - в таком случае, это сделанный мастером, человеком, а не созданный природой.
Скорее всего, здесь повлиял и немецкий язык, где "Kunst" - это "искусство", а "künstlich" - "искусственный". Впрочем, так же происходит и в латинском: "ars, artis" - это "искусство", а "искусственный" мы все тоже знаем, "artificiālis" (англ. "artificial").
В связи с церковно-славянским написанием слова "въкоушати" делается вывод о том, что слова "кушать" и "вкус" тоже происходят от этого глагола, и их первое значение было именно "пробовать".
Вот так, два совершенно разных не родственных корня оказались настолько близки, что в современном языке уже почти не разделимы.
Источники:
История слов. В. В. Виноградов
О преподавании отечественного языка. Ф. И. Буслаев
Что за ерунда у нас вообще творится в бранной речи?
Я в детстве был мальчиком впечатлительным, поэтому когда один гопник пообещал «вскрыть мне еб*ло», я впечатлился. Мозг живо нарисовал мне картину сложнейшей хирургической операции на моих гениталиях, которую проводит человек, употребляющий в своём ежедневном общении слово «еб*ло». Это страшно.
Потом я понял, что он имел ввиду вскрытие от удара такой силы, что плоть сама разойдётся кусками, что было тоже страшновато, но уже поменьше. И лишь спустя значительное количество времени я случайно узнал, что еб*ало это, оказывается, лицо. Страх тогда отпустил полностью, но появилось недоумение. С какой это стати «еб*ло» это вдруг лицо, а не член? Что там эти гопники делают, пока никто не видит?
Однако странности русской нецензурщины на этом для меня не заканчивались. Смысл фразы «дать пи*ды» для меня никогда загадкой не являлся, но я никак не мог понять, почему это вдруг стало означать угрозу избиением. Я на тот момент был пухлым девственным мудаком, так что примерно вся моя жизнь вращалась вокруг поиска какой-нибудь несчастной, разочаровавшейся во всём девушки, которая дала бы мне пи*ды в буквальном смысле.
Какой сумрачный гений вообще посмотрел на женское влагалище и подумал, что так теперь и будем все называть физическое насилие в отношении других людей? И почему другие с этим согласились? Эти же люди, получается, услышали от своего духовного лидера что-то вроде:
- Пацаны, с этого дня лицо – это еб*ло.
И пацаны спокойно так пожали плечами и сказали: «Окей, почему бы и нет, в этом полно смысла». А потом пошли еб*ться лицами.
Где все филологи, когда они так нужны? Как сказать кому-то «нет слова "ложить", есть слово "класть"» так их целая очередь выстраивается, а как доходит до реально важных вопросов, так днём с огнём не сыскать. Поясните, пожалуйста, что у нас за ерунда такая у нас с матерными словами, и как дошли мы жизни такой.
Лайк - это спасибо.
Подпишись, если понравилось, постов у меня еще много.
Доброго дня. На волне постов о возрождении авторских постов, решил раскопать материалы, чтоб внести свои 5 копеек. Анализ начал делать год назад, собрался силами и наконец-то завершил и подготовил материал.
Итак. Примерно около 3 лет назад, когда я водил своего сына на подготовку к школе и логопеду, заметил, о том, что детей обучают читать сразу по слогам. То же самое я слышал и от других людей. Любо это действительно лучше для обучения или это веянье моды, не этот вопрос мы будем сейчас решать. Воспримем эту информацию как действительность. А зададимся другим вопросом. Если учить по слогам, то в русском языке 10 гласных и 20 согласных (те которые участвуют в формировании слога, т.е "й" не будем учитывать). И того имеем 200 вариантов возможных взаимодействий. Учитывая правила русского языка (всякие ЖИ-ШИ, ЧА-ЩА и т.п.) у нас остается 178 слогов. Так с каких слогов лучше начать обучение? Какие слоги в тексте встречаются чаще всего? Ведь начинать обучение со слогов ФЮ, РЭ, НЭ, ВЮ будет нецелесообразно. Из частых слогов, на память, вспомнилось только НО, НА, ПА, МА.
По этому наш анализ начнем с первой гипотезы: "Слога, которые приходят на ум, являются ли самыми распространёнными слогами в русском языке?"
Проанализировав этот вопрос, пришла идея о том, что все буквы расположены у нас под рукой. Да-да, то самое устройство для ввода текста в компьютер или на экране телефона. Клавиатура, которая унаследовала раскладку "ЙЦУКЕН" от печатной машинки.
ЙЦУКЕН раскладка
И так, на ней имеется две гласные буквы "А" и "О" на указательных пальцах (основа слепой печати). Полагаю, что раскладку создавали неглупые люди, по этому данные буквы были выбраны как наиболее встречающиеся в словах. И если учесть, что львиная доля людей правши, то, делаем вывод, самая частая буква русского языка "О". Ближайшие клавиши по вертикали и горизонтали это буквы "Г", "Р", "Л", "Т" (при этом буква Т смешена вправо). Возможно это говорит о том, что смещение вправо наиболее легче осуществить, и тогда можно сказать, что частым слогом должен быть РО. Во круг буквы "А" соседствуют "К", "В", "П", "С", "М", при этом две последние смещены нижним рядом на середину, для равнозначного доступа к клавишам. По этой раскладке можно сделать вывод, что, с большей вероятностью, распределение часто встречающихся слогов будет примерно таким: РО, ЛО, РА, ЛА, ГО, ТО, ГА, ТА, ПО, ВО, ПА, ВА, МО, СО, МА, СА. Как-то так.
Гипотеза вторая: "Соответствуют ли слоги созданные ближайшими клавишами от ключевых самым чаще встречающимися слогами?"
Вопрос для анализа поставили, с гипотезами определились. Осталось только проверить на данных. Вот только где взять эти данные? Мы можем взять любой словарь русского языка (хоть орфографический) и перебрав все слова найдем слоги, которые встречаются чаще всего. Но это не подходит, мы уходим от основы исследования, как мы помним, у нас ребенок учится читать, и уж точно, дети не зачитываются словарями. Да и одни и те же слова могут встречаться больше одного раза, что увеличит появление слога в тексте. Значит для анализа нам нужен текст/произведения. Думаю, подойдет и не детская литература, главное, чтоб было по больше текста, чем больше исходных данных, тем вероятнее анализ. Какая самая большая книжка из русской литературы? Конечно же, произведение Л.Н.Толстого "Война и мир".
Что ж. С источником данных определились. Идем в библиотеку, берем книги, подготовим таблицу со слогами и начнем ставить палочки при каждой встречи слогов. Ох, если бы я так делал, то пост вы бы смогли прочитать только лет через 5. Как же хорошо, что рутинную работу можно отдать на обработку компьютеру. Как говорится "Что можно автоматизировать, нужно автоматизировать".
Книга "Война и мир", все ее 4 тома, нашлись в свободном доступе в интернете. С помощью языка программирования Python пишем скрипт для обработки текста и подсчета слогов в словах. Выводим результаты и смотрим результаты, подтверждаются ли наши гипотезы.
Перед тем как мы посмотрим выводы скрипта, давайте узнаем некоторые данные и небольшие факты по роману "Война и мир". В произведении насчиталось чуть больше 460 тысяч слов, какая-то часть на французском, конечно они не учитываются в подсчете русских слогов. Считаю, что для анализа объем более чем достаточен. Много слов имеют символы, так же возможно, что перенос слов система восприняла как два слова. Так же в тексте используются сокращение числительных, например 1808-м либо использование римских цифр для обозначения дат. По этому посчитаем сколько слов имеют символы и введем, так называемый, коэффициент погрешности измерений. Получилось чуть более 5 тысяч таких слов. Получается, что погрешность может составить чуть более 1%, возьмем для расчетов 2% (пусть будет очень грубо). Самые длинные слова в романе состоят из 28 символов, т.е. из 27 букв. Это: сверхъестественно-прекрасное, сверхъестественно-утонченное, непреодолимо-обворожительным. Красивые слова. Интересное ироническое слово, которое содержит, аж, 4 дефиса: хофс-кригс-вурст-шнапс-рат.
Весь текст романа "Война и мир" я разделил на 2 подсчета: - Полный текст - Сокращенный текст (убрал из учета союзы, предлоги, местоимения, частицы, все то, что не относится к словам как таковым).
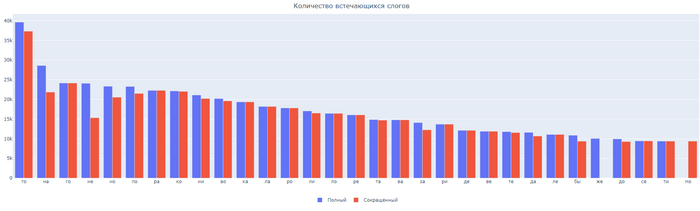
Пока вы читали весь этот длинный текст, скрипт уже завершил работу и построил графики. Давайте посмотрим. Возьмем 30 наиболее встречающихся слогов из обоих вариантов текста.
По анализу в ТОП 30 вошли слоги ТО, НА, ГО, НЕ, НО, ПО, РА, КО, НИ, ВО, КА, ЛА, РО, ЛИ, ЛО, РЕ, ТА, ВА, ЗА, РИ, ДЕ, ВЕ, ТЕ, ДА, ЛЕ, БЫ, ЖЕ, ДО, СЕ, ТИ, МО. Слог ТО даже за вычетом погрешности уверенно лидирует среди всех. В топ вошли так же слоги НЕ и НО, которые на раскладке находятся по диагонали и мы их не учли во второй гипотезе. Слог ЖЕ вошел в топ как частица, но не как вхождение в слово.
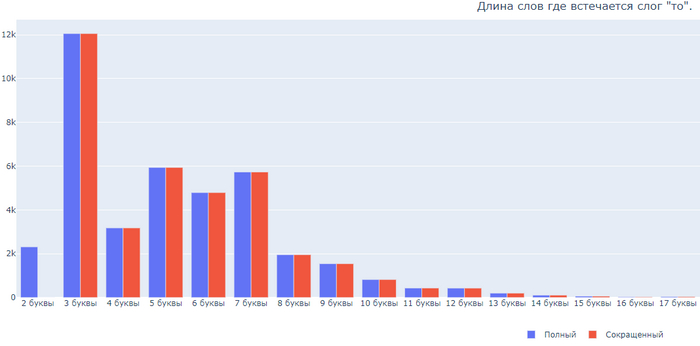
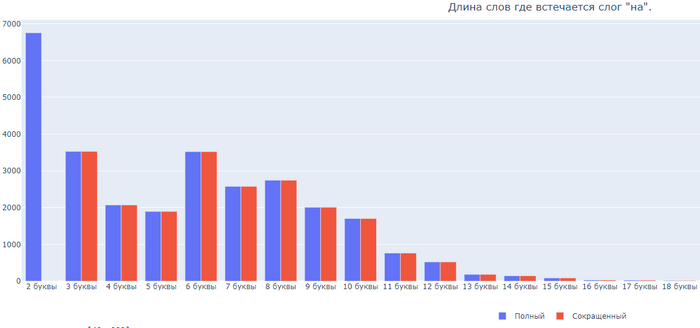
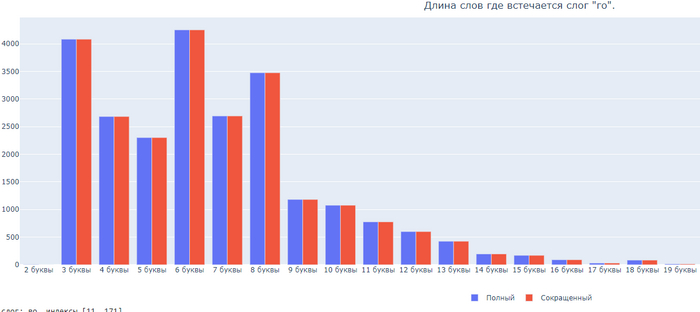
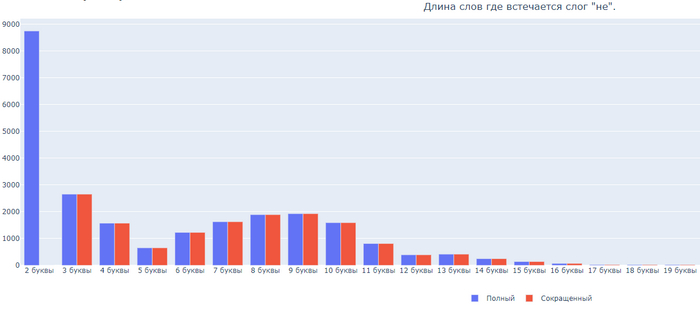
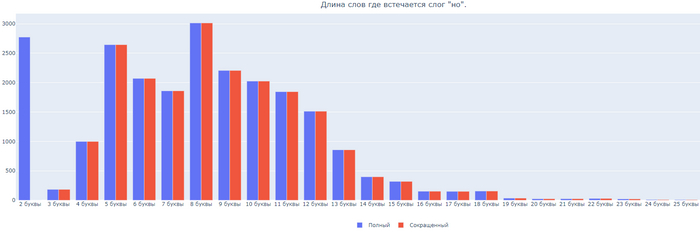
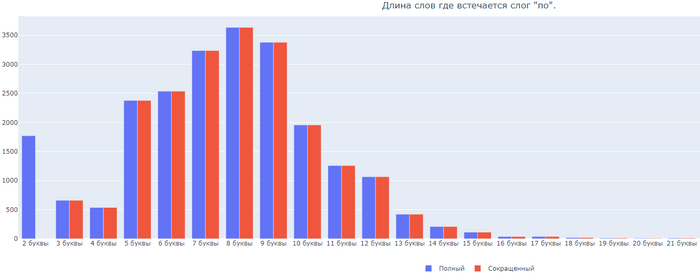
Бонусом, длина слов где встречаются 6 самых частых слогов:
Слог ТО
Слог НА
Слог ГО
Слог НЕ
Слог НО
Слог ПО
ВЫВОДЫ: Моя первая гипотеза частично подтвердилась. Слоги НО и НА действительно входять в часто используемые. Но то, что слог ТО опередит их с количеством больше 10 тысяч было для меня удивлением. Раскладка клавиатуры ЙЦУКЕН вполне полностью имеют самые частые строки под указательными пальцами.
И главный вопрос анализа, в каком порядке изучать слога располжил ниже под сполером с разбивкой по 10 слогов.
Благодарю всех кто дочитал до конца. Я надеюсь, что пост будет полезен как родителям, так и людям, которые занимаются профессионально обучениям детей.
P.S. Есть еще несколько идей для аналитики, но если у вас будут идеи оставляйте их в комментариях. P.P.S. Анализ проведен полностью мной, скрипт разработан мной, пост написан мой, по этому тег МОЁ по праву. Копирование, распространение полного поста или его частей, только с письменного моего согласия. Первое издание поста на Пикабу.
Это слово появилось примерно в 1400 году, но тогда оно означало 'having power to control fate' ("имеющий силу/власть управлять судьбой") 🔸от древнеанглийского wyrd 'fate, chance, fortune; destiny' (читай: судьба), 🔸от протогерманского *wurthiz (стало источником для древнесаксонского wurd, древневерхненемецкого wurt "судьба", древнескандинавское urðr "судьба"), 🔸от протоиндоевропейского (PIE) *wert - "поворачивать, наматывать".
Значение "жуткий, сверхъестественный" у слова weird развилось из среднеанглийского употребления слова weird sisters для обозначения трех судеб или Норн (в германской мифологии) - богинь, которые управляли человеческой судьбой🔮 Они изображались странными или пугающими внешне, что привело к появлению прилагательного, означающего "странно выглядящий, сверхъестественный" (1815); "странный, непонятный, тревожно непохожий" (1820) (odd-looking, uncanny, odd, strange, disturbingly different) - то самое слово WEIRD, которое мы употребляем сейчас.
Приехали к нам друзья семьи из Израиля. Эмигрировали в 90-х, дети ещё маленькими совсем были. На русском младшее поколение говорит хорошо, но иногда переспрашивают. У Лёни блокнотик – он туда незнакомые слова записывает, словарный запас пополняет.
Привезли их к нам на дачу – банька, картошечка своя, шашлычок кошерный ))) Лёня докурил сигарету и спрашивает у моей мамы:
– А куда выкинуть? (показывает окурок) – Хабарик? В бочку кинь. – Хабарик? – Ну да, окурок, хабарик... – Понятно (записывает в блокнотик)
Идёт к бочке, по дороге встречает моего папу:
– Ты куда? – Я иду выбрасывать... (заглянул в блокнот) хабарик! – Это не хабарик, это бычок! – ??? В чём разница? – Ну, понимаешь, бычок можно докурить... – Как это – докурить???
Культурная пропасть )
------------------------------
Когда ставишь теги, слово "Бычок" есть, а начинаешь вводить "хабарик" -- и выпадет подсказка "Окурки" ))
Недавно услышала слово "притатакать" Подруга позвонила сыну своему и говорит: сына, притатакай мой кошелек. 🙄🤔 Я немного офигела. Никогда раньше не слышала такого слова.