



Вспомним слова ©Майкла Джексона
Для чего действительно нужна смелость, так это для искренности
Лингвистическая аналитика: какой слог чаще встречается
Доброго дня.
На волне постов о возрождении авторских постов, решил раскопать материалы, чтоб внести свои 5 копеек. Анализ начал делать год назад, собрался силами и наконец-то завершил и подготовил материал.
Итак.
Примерно около 3 лет назад, когда я водил своего сына на подготовку к школе и логопеду, заметил, о том, что детей обучают читать сразу по слогам. То же самое я слышал и от других людей. Любо это действительно лучше для обучения или это веянье моды, не этот вопрос мы будем сейчас решать. Воспримем эту информацию как действительность.
А зададимся другим вопросом.
Если учить по слогам, то в русском языке 10 гласных и 20 согласных (те которые участвуют в формировании слога, т.е "й" не будем учитывать). И того имеем 200 вариантов возможных взаимодействий. Учитывая правила русского языка (всякие ЖИ-ШИ, ЧА-ЩА и т.п.) у нас остается 178 слогов.
Так с каких слогов лучше начать обучение? Какие слоги в тексте встречаются чаще всего?
Ведь начинать обучение со слогов ФЮ, РЭ, НЭ, ВЮ будет нецелесообразно. Из частых слогов, на память, вспомнилось только НО, НА, ПА, МА.
По этому наш анализ начнем с первой гипотезы: "Слога, которые приходят на ум, являются ли самыми распространёнными слогами в русском языке?"
Проанализировав этот вопрос, пришла идея о том, что все буквы расположены у нас под рукой. Да-да, то самое устройство для ввода текста в компьютер или на экране телефона. Клавиатура, которая унаследовала раскладку "ЙЦУКЕН" от печатной машинки.

ЙЦУКЕН раскладка
И так, на ней имеется две гласные буквы "А" и "О" на указательных пальцах (основа слепой печати). Полагаю, что раскладку создавали неглупые люди, по этому данные буквы были выбраны как наиболее встречающиеся в словах. И если учесть, что львиная доля людей правши, то, делаем вывод, самая частая буква русского языка "О".
Ближайшие клавиши по вертикали и горизонтали это буквы "Г", "Р", "Л", "Т" (при этом буква Т смешена вправо). Возможно это говорит о том, что смещение вправо наиболее легче осуществить, и тогда можно сказать, что частым слогом должен быть РО. Во круг буквы "А" соседствуют "К", "В", "П", "С", "М", при этом две последние смещены нижним рядом на середину, для равнозначного доступа к клавишам.
По этой раскладке можно сделать вывод, что, с большей вероятностью, распределение часто встречающихся слогов будет примерно таким: РО, ЛО, РА, ЛА, ГО, ТО, ГА, ТА, ПО, ВО, ПА, ВА, МО, СО, МА, СА. Как-то так.
Гипотеза вторая: "Соответствуют ли слоги созданные ближайшими клавишами от ключевых самым чаще встречающимися слогами?"
Вопрос для анализа поставили, с гипотезами определились. Осталось только проверить на данных.
Вот только где взять эти данные?
Мы можем взять любой словарь русского языка (хоть орфографический) и перебрав все слова найдем слоги, которые встречаются чаще всего. Но это не подходит, мы уходим от основы исследования, как мы помним, у нас ребенок учится читать, и уж точно, дети не зачитываются словарями. Да и одни и те же слова могут встречаться больше одного раза, что увеличит появление слога в тексте.
Значит для анализа нам нужен текст/произведения. Думаю, подойдет и не детская литература, главное, чтоб было по больше текста, чем больше исходных данных, тем вероятнее анализ.
Какая самая большая книжка из русской литературы? Конечно же, произведение Л.Н.Толстого "Война и мир".
Что ж. С источником данных определились. Идем в библиотеку, берем книги, подготовим таблицу со слогами и начнем ставить палочки при каждой встречи слогов.
Ох, если бы я так делал, то пост вы бы смогли прочитать только лет через 5. Как же хорошо, что рутинную работу можно отдать на обработку компьютеру. Как говорится "Что можно автоматизировать, нужно автоматизировать".
Книга "Война и мир", все ее 4 тома, нашлись в свободном доступе в интернете. С помощью языка программирования Python пишем скрипт для обработки текста и подсчета слогов в словах. Выводим результаты и смотрим результаты, подтверждаются ли наши гипотезы.
Перед тем как мы посмотрим выводы скрипта, давайте узнаем некоторые данные и небольшие факты по роману "Война и мир".
В произведении насчиталось чуть больше 460 тысяч слов, какая-то часть на французском, конечно они не учитываются в подсчете русских слогов. Считаю, что для анализа объем более чем достаточен.
Много слов имеют символы, так же возможно, что перенос слов система восприняла как два слова. Так же в тексте используются сокращение числительных, например 1808-м либо использование римских цифр для обозначения дат. По этому посчитаем сколько слов имеют символы и введем, так называемый, коэффициент погрешности измерений.
Получилось чуть более 5 тысяч таких слов. Получается, что погрешность может составить чуть более 1%, возьмем для расчетов 2% (пусть будет очень грубо).
Самые длинные слова в романе состоят из 28 символов, т.е. из 27 букв. Это: сверхъестественно-прекрасное, сверхъестественно-утонченное, непреодолимо-обворожительным. Красивые слова.
Интересное ироническое слово, которое содержит, аж, 4 дефиса: хофс-кригс-вурст-шнапс-рат.
Весь текст романа "Война и мир" я разделил на 2 подсчета:
- Полный текст
- Сокращенный текст (убрал из учета союзы, предлоги, местоимения, частицы, все то, что не относится к словам как таковым).
Пока вы читали весь этот длинный текст, скрипт уже завершил работу и построил графики. Давайте посмотрим.
Возьмем 30 наиболее встречающихся слогов из обоих вариантов текста.
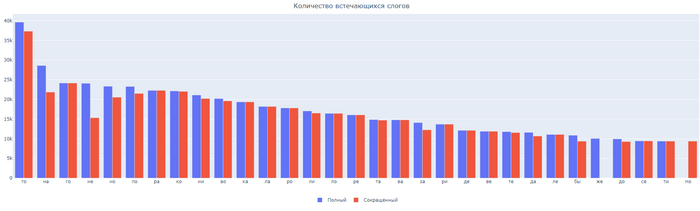
Топ 30 чаще встечающихся слогов.
Числовые данные:
ТО: 39641/37330
НА: 28610/21853
ГО: 24155/24149
НЕ: 24092/15338
НО: 23335/20560
ПО: 23285/21514
РА: 22284/22284
КО: 22141/22029
НИ: 21110/20217
ВО: 20205/19620
КА: 19364/19364
ЛА: 18203/18203
РО: 17817/17817
ЛИ: 17054/16531
ЛО: 16440/16440
РЕ: 16056/16056
ТА: 14869/14727
ВА: 14793/14793
ЗА: 14097/12272
РИ: 13696/13696
ДЕ: 12124/12124
ВЕ: 11895/11895
ТЕ: 11801/11560
ДА: 11613/10682
ЛЕ: 11085/11085
БЫ: 10885/9371
ЖЕ: 10063/не вошло в топ
ДО: 9954/9276
СЕ: 9442/9442
ТИ: 9386/9386
МО: не вошел в топ/9385
По анализу в ТОП 30 вошли слоги ТО, НА, ГО, НЕ, НО, ПО, РА, КО, НИ, ВО, КА, ЛА, РО, ЛИ, ЛО, РЕ, ТА, ВА, ЗА, РИ, ДЕ, ВЕ, ТЕ, ДА, ЛЕ, БЫ, ЖЕ, ДО, СЕ, ТИ, МО.
Слог ТО даже за вычетом погрешности уверенно лидирует среди всех. В топ вошли так же слоги НЕ и НО, которые на раскладке находятся по диагонали и мы их не учли во второй гипотезе.
Слог ЖЕ вошел в топ как частица, но не как вхождение в слово.
Бонусом, длина слов где встречаются 6 самых частых слогов:
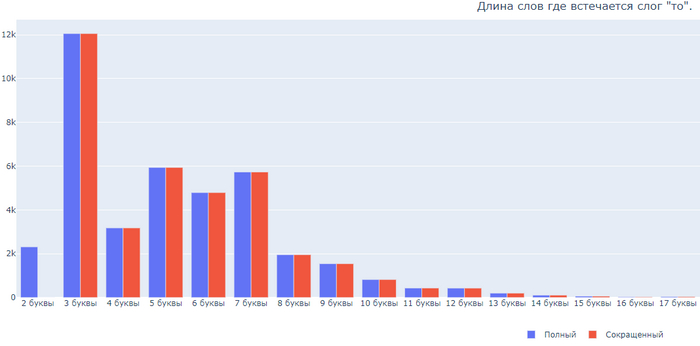
Слог ТО
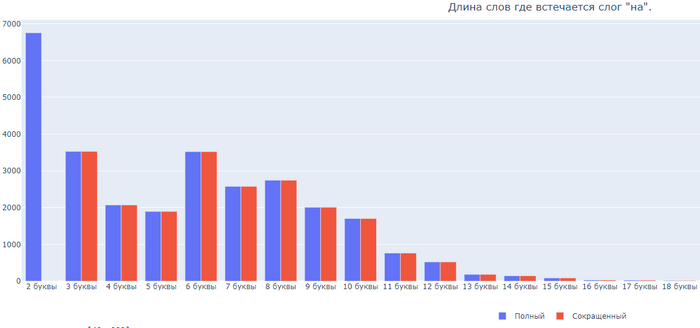
Слог НА
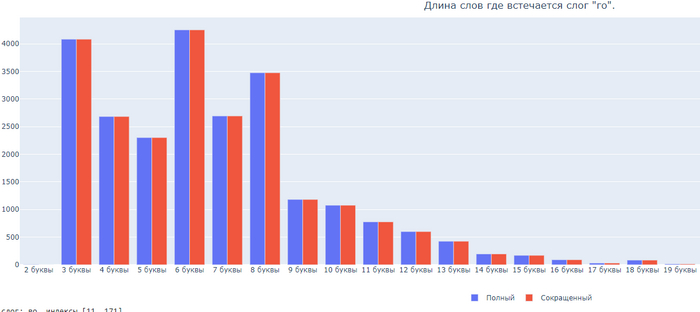
Слог ГО
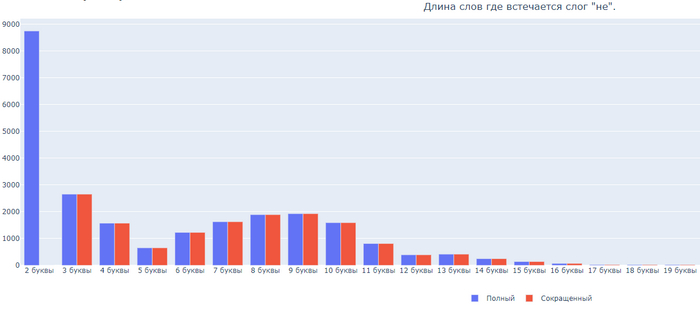
Слог НЕ
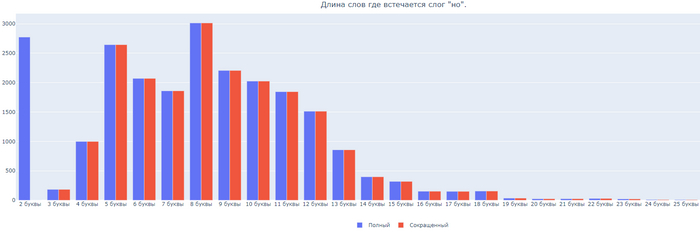
Слог НО
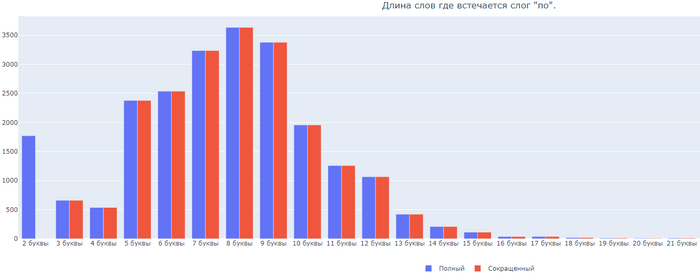
Слог ПО
ВЫВОДЫ:
Моя первая гипотеза частично подтвердилась. Слоги НО и НА действительно входять в часто используемые. Но то, что слог ТО опередит их с количеством больше 10 тысяч было для меня удивлением.
Раскладка клавиатуры ЙЦУКЕН вполне полностью имеют самые частые строки под указательными пальцами.
И главный вопрос анализа, в каком порядке изучать слога располжил ниже под сполером с разбивкой по 10 слогов.
1 группа: ТО, НА, ГО, НЕ, НО, ПО, РА, КО, НИ, ВО;
2 группа: КА, ЛА, РО, ЛИ, ЛО, РЕ, ТА, ВА, ЗА, РИ;
3 группа: ДЕ, ВЕ, ТЕ, ДА, ЛЕ, БЫ, ЖЕ, ДО, СЕ, ТИ;
4 группа: МО, МИ, НЫ, ЧЕ, ВИ, СЯ, СО, РУ, МЕ, МА;
5 группа: НЯ, ВЫ, ДИ, ПЕ, КИ, МУ, ШЕ, НУ, БО, ХО;
6 группа: БЕ, ЧА, ШИ, ЛЯ, ДУ, РЫ, ША, СИ, СА, ЧИ;
7 группа: КУ, ТУ, ТЫ, ЖИ, ЖА, ЩЕ, ЛУ, ПА, ЛЮ, БУ;
8 группа: ЛЫ, РЯ, БА, ГА, ЦЕ, ХА, МЫ, ВУ, СУ, ПИ;
9 группа: ЩИ, БИ, ГИ, ПУ, ГУ, ЗО, ЧУ, ДЫ, ЦА, ЗЫ;
10 группа: ФИ, ТЯ, ГЕ, ЦУ, ЗЯ, МЯ, БЯ, ДЯ, КЕ, ЩА;
11 группа: СЫ, ЗИ, ПЯ, ЦО, ШУ, ЗУ, ПЫ, ШО, ЗЕ, ЦИ;
12 группа: ВЯ, ЖУ, ЦЫ, ХИ, НЮ, РЮ, ФА, ФЕ, СЮ, ХУ;
13 группа: ЩУ, ФУ, ЗЮ, ФО, ЧО, ТЮ, ДЮ, ЖО, СЁ, ХЕ;
14 группа: ЖЮ, МЮ, ФЫ, КЮ, БЮ, ФЮ, ЦЯ, ТЁ, ЛЁ, ТЭ;
15 группа: ПЭ, ВЭ, ДЁ, КЁ, МЭ, НЭ, РЭ, ЩО, БЭ, ВЮ;
16 группа: ДЭ, ЖЭ, ЛЭ, НЁ, РЁ, СЭ, ФЭ, ЧЭ, ЩЭ, ЩЯ.
Благодарю всех кто дочитал до конца. Я надеюсь, что пост будет полезен как родителям, так и людям, которые занимаются профессионально обучениям детей.
P.S. Есть еще несколько идей для аналитики, но если у вас будут идеи оставляйте их в комментариях.
P.P.S. Анализ проведен полностью мной, скрипт разработан мной, пост написан мой, по этому тег МОЁ по праву. Копирование, распространение полного поста или его частей, только с письменного моего согласия. Первое издание поста на Пикабу.
Показать полностью
8

Как подготовить машину к долгой поездке
Взять с собой побольше вкусняшек, запасное колесо и знак аварийной остановки. А что сделать еще — посмотрите в нашем чек-листе. Бонусом — маршруты для отдыха, которые можно проехать даже в плохую погоду.
Рептилоиды среди нас!!!
Читаю как-то сижу литературу. И тут я вижу странную формулировку. Хммм... Палитесь господа иноземные.



О словах и их новых значениях...
Ищу не книгу.
А список слов сменивших или меняющих своё значение.
Есть исследования на эту тему?
Мне попадается везде один и тот же список из десяти-двадцати слов со «смешными» картинками, которые репостят из сообщества в сообщество. Но слов таких явно больше. Я приведу только три примера, чтобы продемонстрировать разницу направлений в которых могут происходить такие изменения. И что я понимаю, под объяснениями этих изменений.

В посте использованы арты прекрасной художницы Ruslana Gus (girls, cats, violet & cyberpunk): инста https://www.instagram.com/rilunify и артсейшн https://www.artstation.com/rilun
1. Кузов — плетёный, часто берестяной «рюкзак», с крышкой или покрывалом, который на лямках носился за спиной. Использовался для хранения и переноски грибов и ягод во время сбора.
Слово по-прежнему обозначает заплечную корзину. Но значительно чаще используется для обозначения части транспорта, предназначенной для размещения пассажиров и груза. Короче, автомобильный кузов.
Мы видим и логику образования и причины смещения смысла.
Раз: речь по-прежнему идёт о некой штуковине для транспортировки груза.
Два: исчезновение плетёных берестяных коробов и плетёных туесов из обихода, заменой их гораздо более удобными «рюкзаками» и «разгрузками», повлияло на то, что слово «кузов» почти перестало употребляться и, в каком-то смысле, освободилось.
Три: повсеместное распространение автомобилей, как основного средства частной транспортировки груза и, как следствие, необходимости появления новых слов, или придания новых значений старым словам (крыло, руль, стекло).
2. Ведьма / Знахарка — женщина, которая что-то эдакое Ведает / Знает.
На данный же момент слово Знахарка устойчиво ассоциируется с сельской врачом-травником и близкими образами, а слово Ведьма стало обозначать в прямом смысле злую колдунью, а в переносном зловредную и злонамеренную женщину с тяжёлым характером.
Здесь уже сложнее. Так как знания остались знаниями, наговоры остались наговорами, и травничество осталось травничеством. С чего тогда такие разительные перемены?
Это целенаправленная замена понятий связана с монополизацией религиозных обрядов в лоне церкви (неважно какой именно, важно что официальной религии) и, соответственно, необходимости очернить конкурентов. Знание — хорошо. Но только если от Бога. Ведать можно — но только нашим жрецам. Чужие жрецы ведают что-то другое, то есть что-то плохое. Любой маг — плохой маг. По той же причине слово Magus (Маг, Волшебник, Колдун) в библии переведено как Волхв, дабы избежать очевидного вопроса, как Маг может быть хорошим, было изобретено слово Волхв, образованное от слова Волшебник.
3. Нелицеприятный — беспристрастный.
Не-Лице-Приятный. Это не от слова Приятно. А от слова Приятие.
Нелицеприятный — это не тот человек, который принимает к сведению общественное положение участвующих в деле лица. То есть тот, кто судит, не взирая на лица. Неподкупный, непредубежденный, беспристрастный, объективный, справедливый, правосудный.
В том же словаре Даля раскрывается и изначального слова: «лицеприятие — человекоугодье, пристрастье, предпочтенье одного лица другому, не по достоинству, а по личным отношениям. Лицеприятствовать кому, лицеприимничать — быть пристрастным, лицеприятным, творить неправду, угодствовать лицу».
А сейчас считается, что нелицеприятный, этот тот у кого лицо неприятное. Мерзкий тип.

Так же интересует список слов, который часто, если не повсеместно, употребляется неправильно, хотя формального значения не менял. Я встречал такие слова в произведение Лескова «Левша»:
Тугамент — документ.
Студинг — соединение слов: пудинг и студень.
Мелкоскоп — соединение слов: микроскоп и мелко.
Долбица умножения — соединение слов: таблица и долбить.
Двухсестная карета — соединение слов: двухместная и сесть.
И думал, что это всё понятно... Крестьяне, несчастные люди. Воспринимали слова на слух, кое-как. Спросить-то правильного значения было не у кого, додумывали смысл, как могли. Соотносили с тем, что видят, что знают. Сейчас, казалось бы... все уже привиты чипами, 5G прямо в мозг заливает расплавленные микроволны — получай информацию широкой полосой.
Но людей, которые кое-как сами себе додумали смыслы становится не меньше (как должно было бы быть при повсеместной грамотности и интернете), а больше!
Вместо тех, кто «растекается мысью по древу», то есть тех, чей разум прыток и скор, как белка, скачет с темы на тему, как белка с ветки на ветку, получились те, кто «растекается мыслью по древу», то есть тех, кто размазывает по стволу свои склизкие размышления.
Вместо тех, кто просит прощения, появились хамы, которые не только делают, что-то такое за что следует просить прощения или извинения, а тут же на месте, сами себя и прощают, говоря: «Извиняюсь».
Вместо «доведённых до кипения» или «доведённых до белого каления», появились люди которых доводят до белого колена... Какая у них в этот момент в голове картинка? Какой образ? Колено? Белое? Большое? Лысое? Страшное?
Иронично, но «белое колено» звучит в ролике «основные ошибки писателей» от человека с ником Литератор. И нет, это были не примеры ошибок, это просто Литератор так учит писателей... в комментах там кто-то подробно расписал Литератору целую страницу ошибок из пятнадцатиминутного ролика, но я запомнил только про «белое колено» и «всю ипостасю».
Вместо тех, кто понимает, что кипенно-белый означает очень-белый (это не единственное значение, кстати, но самое частое), появились люди, которые думают... я не знаю, что именно они думают, но у них, что-то вроде формулы в голове:
Раз кипенно-белый = очень-белый,
а цвет белый = цвет белый,
то следовательно: кипенно = очень.
Эдакое уравнение!
И они его таки решили!!!
И поэтому теперь я могу услышать о кипенно-синем (очень насыщенном синем цвете), кипенно-розовом (фуксии или мадженте), о кипенно-зелёном (вырвизглазно ярком), и так далее...

Про тех, кто сожительствуют, говорят, что «живут в гражданском браке».
Хотя имеют в виду, как раз то что они «НЕ живут в гражданском браке».
Это вообще пример употребления в обратном значении!
Видимо, у народа в голове есть:
— церковный брак (одно из христианских таинств, союз, заключённый через священнодействие);
— гражданский брак (зарегистрированный в ЗАГСе, не настоящий — не благословлённый Богом);
— «настоящий брак» (церковный, батюшка, мужчина и женщина, иконы, свечи, короны);
— «ненастоящий брак» (ЗАГС, просто какая-то бумажка с росписями и штампом).
А потом на эти представления наложились новые:
— «настоящий брак» это (должна быть бумажка, одобрение инстанций, кольца);
— «ненастоящий брак» это «без бумажки» (вот доучимся / переедем / кредит выплатим и тогда)...
И потом это всё сплавилось, и «настоящесть» брака наложилась на русскую-православную обрядовую часть, «важность» наложилась на советское «наличие бумажки».
А теперь много кто даже не понимает, что есть только один «гражданский брак» и никакого другого в России просто нет. И гражданский брак это загс, роспись, штамп, вот это вот всё...
При этом я сам — дабы быть понятым — тоже говорю неправильно:
Про тех, кто просто вместе спит, я скажу:
Они живут в гражданском браке!
Хотя я могу знать, что они и вместе не живут вместе, и в гражданском браке не состоят.
Но я не буду объяснять всю эту предысторию собеседнику, я лучше подстроюсь под его понятия.
По поводу понятий...
Априори — это знание, полученное до опыта и независимо от него, то есть знание, как бы заранее известное. Противоположность апостериори — знания, полученного из опыта.
На воле появились «а приори» или «а приоре» или «в априоре» или «аля-приоре» или «в приоре» (серьёзно). Причём «в приоре» это вообще комбо: это как бы и настоящий тру автомобиль и «приоритет», слово с туманным, но явно крутым смыслом, и собственно термин «априори»...что получилось? Правильно — в приоре! (чаще всего используют «в априоре»)...

Люди путают инцесты и эксцессы, плацебо и либидо, компиляцию и корреляцию и пр...
Это понятно! Но умилительна тяга к использованию этих «умных» слов.
Это смотрится так же глупо, как перевод крылатой фразы. Неоднократно встречал, когда кто-то говорит фразу на иностранном языке, латинское выражение, например. А потом её переводит.
И с этаким превосходством ещё оглядывает своих собеседников:
Видали? Видали, как я смог? Латынь, не х*й собачий...
Ну так и хочется сказать, ну чего ты смог-то? Опозориться? Зачем перевёл?
Если рассчитываешь, что тебя поймут — не переводи.
А если рассчитываешь, что не поймут — не кичись плебейским гонором, не произноси заведомо непонятную для собеседников фразу, чтобы казаться умнее, не так это работает... Но нет же...
Так. Это я уже не в ту степь...

Собственно, вопрос в том, можно ли где-то посмотреть списки этих слов. Значение которых перекочевало и поменялось... или почти поменялось... или меняется... и когда достигается критическая масса в изменениях? Когда люди такие:
Всё, теперь это слово значит не вот это вот, что значило с 1720 по 2020, а вот это вот...
Вот например, нелицеприятный означает «неподкупный», но употреблять его следует как «неприятный», иначе людям будет непонятно... так?
Вот вы слово «нелицеприятный» и подобные как употребляете?
В старом смысле (как в словаре)? Или в новом смысле (как люди понимают)?
С одной стороны:
Значение слов определяется не словарём, а теми с кем разговариваешь. Людьми.
С другой стороны не хотелось бы начинать изъясняться в духе:
Я в априоре знаю, что важный тугумент(договор) лежит в кипенно-красной папке.
ИТОГО:
Есть ли исследования и списки слов сменивших своё значение?
Вы стараетесь использовать слова как по словарю или как их знает собеседник?
Показать полностью
5

Как увеличить читаемость с помощью дефисов

Всё это очень субъективно, но использование дефисов в длинных словах необычайно увеличивает читаемость. Рублика т.е. РубРика "Капитан Очевидность". Но вот вам наглядный пример. Польское прилагательное из 19-ти букв визуально понятнее, чем аналоги из 15-ти и 20-ти букв. Провернём фокус в русском: Древне-верхне-немецкий. Сразу видно три основы. Без них каком-нибудь умном тексте можно и увязнуть.
1) А в чём же отличие древневерхненемецкого языка от средненижненемецкого?
2) А в чём же отличие древне-верхне-немецкого языка от средне-нижне-немецкого?
Есть длинное существительное "водогрязеторфопарафинолечение". Какая-то каша из букв. Исправим: водо-грязе-торфо-парафино-лечение.
Электрофотополупроводниковый -> электро-фото-полупроводниковый.
Какое-нибудь слово, вроде дезоксирибонуклеиновая, с дефисами приобретает читаемость: дезоксирибо-нуклеиновая // дезокси-рибо-нуклеиновая. Но это уже за гранью добра и и зла. Надо сказаать, что в химии дефисы используются и их использование регулируют ннкоторыеправила. "Бета-гидрокси-3-метилфентанил".
Но вот с "сельскохозяйственно-машиностроительный" такой фокус вряд ли пройдёт. Можно, конечно, наплевать на всё, разделив сами слова на 4 основы и поставив посередине среднее тире:
"сельско-хозяйственно–машино-строительный"
Показать полностью


Ответ на пост «Уборк спил слом а уча дерев строе вывоз стков ьев ний»

Показать полностью
1
Уборк спил слом а уча дерев строе вывоз стков ьев ний

Показать полностью
1