


Машинное обучение: устраивает ли наша поисковая система пользователя. История одного исследования
Всем привет! В моём одном посте меня попросили подробно рассказать о конкурсе по машинному обучению, в котором я принимал участие с Олегом. В этом посте будет приведено наше исследование. Получилось довольно много материала, но, надеюсь, что будет интересно. Ну-ка, от винта!
1. Описание задачи.
2. Постановка задачи и исходные данные.
3. Немного терминологии
4. Как мы решали задачу
4.0. Первый штурм (создание признаков)
4.1. Первая ошибка
4.2. Вторая ошибка
4.3. Как Ленка помогла нам попасть в десятку
5. Послесловие, список литературы и мораль.
1. Описание задачи
Есть такая поисковая система. Яндекс называется. Есть у него такая фишка: если пользователю не понравились результаты в выдаче, то пользователь может посмотреть результаты его конкурентов. Если пользователь начинает смотреть результаты гугла, а запрос был сделан в яндексе, то это называется switch. Так вот, яндекс объявил конкурс, целью которого было научиться предсказывать будет ли в сессии пользователя свитч.

2. Постановка задачи и исходные данные
Что же нам дано?
Наши данные представляют из себя пользовательские поисковые логи, содержащие идентификаторы пользователей, запросных сессий, запросов, списки отранжированных Яндексом документов, показанных пользователям, пользовательские клики на них и переходы на другие поисковые системы. Разумеется, что все данные анонимизированны.
Немного статистики:
Уникальных запросов: больше 10 млн.
Уникальных документов: почти 50 млн.
Уникальных пользователей: около миллиона
Сессий: 8.5 млн.
Временной охват: 1 месяц.
Поисковые логи представляют из себя набор строк, где каждая строка представляет одну из возможных записей: метаданные следующей поисковой сессии, запрос, клик или переход на другую поисковую систему.
Метаданные следующей сессии (TypeOfRecord = M):
SessionID Day TypeOfRecord USERID SwitchType
Запрос (TypeOfRecord = Q):
SessionID TimePassed TypeOfRecord SERPID QueryID ListOfURLs
Клик (TypeOfRecord = C):
SessionID TimePassed TypeOfRecord SERPID URLID
Переход (TypeOfRecord = S):
SessionID TimePassed TypeOfRecord
-SessionID – уникальный идентификатор пользовательской сессии.
-Day – номер дня, за который собраны данные (все данные собраны за 30 дней).
-TypeOfRecord – тип записи. Это может быть либо запрос (Q), либо клик (C), либо переход (S), либо метаданные следующей сессии (M).
-UserID – уникальный идентификатор пользователя.
-SwitchType – индикатор, сообщающий что переходы какого типа (не менее одного) содержит данная сессия. Это либо переход, который был замечен благодаря установленному у пользователя тулбару (B), либо переход, который удалось отследить непосредственно с поисковой выдачи (P), либо в сессии есть переходы обоих типов (H), либо в сессии не удалось отследить переходы (N). Тип каждого конкретного перехода в сессии не разглашается. То бишь, просто ставится в записи буква S.
-TimePassed – время, прошедшее с начала текущей сессии в условных временных единицах. Количество секунд в одной временной единице не разглашается.
-QueryID – уникальный идентификатор текста запроса.
-SERPID – идентификатор поисковой выдачи, уникальный на уровне сессии.
-URLID – уникальный идентификатор документа.
-ListOfURLs – список документов, отранжированный слева направо так как они были показаны пользователям на странице выдачи Яндекса (сверху вниз).
Пример:
744899 23 M 123123123 B
744899 0 Q 0 192902 632428 309585 319567 6547 20264 3094446 90 841 8344 119571
744899 592 S
744899 1403 C 0 632428
Тестовая выборка была точно такой же, как и тренировочная за исключением одного момента: запись типа swtich отсутствовала.
Требовалось: для всех SessionID в тестовой выборке дать вероятность того, что в ней был Switch.
Вся тестовая выборка была поделена на две части
-Публичная часть. На основании результатов из публичной части составлялся рейтинг участников. То есть, чтобы мы могли смотреть удачно или не очень мы составляем программу
-Приватная часть. На основании результатов в приватной части и определяется победитель конкурса.
Разумеется, никто из участников не знает, какие данные из тестовой выборки к какой части относятся. Это большая тайна :)
3. Немного терминологии

В принципе, довольно всё понятно. Немного детальней опишем множество X. Довольно естественно каждый x из Х представлять в виде признаков. Например с нашими котиками. Допустим, у нас есть три признака:
f1 = есть шерсть
f2 = чёрные глаза
f2 = старше двух лет
Теперь молодого котёнка сфинкса с чёрными глазами можно описать при помощи вектора: (0,1,0). А пожилой голубоглазый перс будет описан при помощи вектора (1,0,1). Тогда мы можем всю нашу выборку представить в виде матрицы объектов-признаков
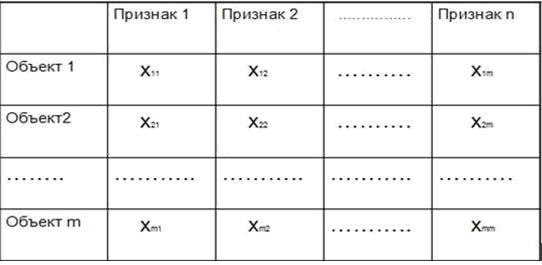
Обычно к матрице добавляют ещё вектор значений: то есть, какой ответ ставится в соответствие объекту.
По сути задача всего конкурса сводилась:
1. Создать матрицу объектов-признаков
2. Натренировать алгоритм
3. Победить.

Кстати, а как нам понимать, насколько удачно мы натренировали алгоритм? Ведь решения можно посылать только пару-тройку раз в сутки. Обычно, для контроля качества используется техника кросс-валидации. В ходе обучения алгоритма наша выборка делится на N частей. Затем алгоритм обучается на N-1 части, а на последней тестируется. Однако, можно просто выделить валидационное множество и на нём проверять всё.
От себя замечу, что подобные конкурсы - просто золото. Сейчас пошла мода давать уже готовые матрицы и весь конкурс сводится к тому, кто лучше задрочит свой алгоритм. Никакого творчества и реальной пользы, как мне кажется, практически нет. Нету исследовательской работы. Иногда проскакивают интересные задачи, но таких, увы, подавляющее меньшинство.
4. Первый штурм

Когда вступил в научно-исследовательский турнир среди нескольких сотен команд по СНГ, я чувствовал себя сим славным паладином. Я остался с Олегом после пар, предупредив свою любимую Лену, чтобы она шла домой. Олег предложил сначала попробовать понять: а как нам же сформировать матрицу объектов-признаков? Ведь это же ключевой момент. Алгоритм, который бы учился предсказывать вероятность перехода, у нас уже был - Random Forest в реализации Weka. Мы решили, что объектами будут сессии пользователя, что логично. А признаки, при помощи которых будем описывать, были следующие (Честно говоря, в нашем отчёте я весьма халатно перечислял признаки, поэтому бОльшую часть я уже не помню. Помню лишь идеи):
Признаки сессии: время сессии (продолжительность), ID-пользователя, день месяца, количество запросов в сессию , количество кликов в сессии, количество запросов в сессии без кликов, максимальная серия последовательных кликов между запросами в рамках сессии.
Признаки пользователя: количество свичей в известных сессиях пользователя; общее число сессий; процент свичей пользователя.
На самом деле, несколько признаков была полная дичь - день месяца, ID-пользователя. Я не знаю, нафига мы с Олегом их включили? Но сказано - сделано.Также я разбил тренировочный файл на два: один шёл для обучения алгоритма, а второй использовался для валидации.
Ошибка первая.
Придя домой, я набросал довольно быстро парсер и стал рассчитывать вероятности и значения признаков по всему тренировочному файлу. Олег запустил алгоритм и на нашей валидационной выборке результат был более чем обнадёживающим. Значение AUCa было аж 0.86! Олег отправлял решение на сайт, а я уже мысленно с Леной был где-то далеко-далеко на Чёрном Моречке. Однако, результат на публичной части данных нас просто убил. AUC(целевая метрика) равнялся где-то 0.7 и мы гордо плелись в конце. Epic fail...
В принципе, такой результат достаточно просто объясним. Смотрите: когда я составлял матрицу объектов-признаков, я фактически сказал нашему алгоритму, как распределены те или иные величины и в частности, как они распределены в валидационном множестве. А так делать нельзя.
Отсюда первая мораль:
Выборку надо дробить на три части. На одной считать разные вероятности и другие статистические величины. На другой составлять матрицу объектов-признаков и обучать алгоритм. На оставшейся части смотреть качество работы алгоритма.
После этого результаты на публичной выборке яндекса стали совпадать с нашими на нашей валидационной части.
Ошибка вторая.
Вторая ошибка наша была... не совсем ошибка. Судите сами.
Стали сидеть с Олегом и думать: а как же на всё-таки апнуться? И пришли к следующей мысли (которая довольно давно известна всем seo-шникам и описана в литературе). Все запросы можно поделить на две группы:
-Навигационные
-Информационные
Навигационный запрос - это запрос, который требует чёткого ответа от поисковой системы. Обычно, это запрос конкретного сайта. Например, "форум wow.ru". В выдаче должна быть обязательно ссылка на форумы про творение близзардов.
Информационный запрос - это запрос, на который может быть быть много адекватных ответов и всё зависит от пользователя. Например, "форум". В выдаче может быть и ссылка на википедию, где рассказывается что такое форум, или ссылки на всевозможные форумы.
Мы с Олегом предположили следующее: Навигационные запросы яндекс отрабатывает и сам. Пользователю нет резона переходить на другую поисковую систему. А вот с информационными запросами он может и не справляться. Значит, если в запросе был информационный запрос, то есть вероятность, что пользователь перейдёт на другую страницу.
Видите в чём ошибка наших мыслей? Рассуждения у нас в принципе здравые, но мы начинаем решать другую задачу. Мы старались научиться понимать тип запроса, а не будет ли свитч. Определённо, задача свича имеет связь с определением запроса, но далеко нетривиальную. Как итог: мы потеряли ещё две недели из отпущенного месяца. Осталась неделя. Хотя, не совсем потеряли. Небольшой прирост мы получили. Где-то до 0.73, но это убийственно мало.
Что мы приобрели из признаков:
- количество свичей после заданного запроса,
- количество свичей после клика на документ;
- вероятность свича после данного запроса.
Мораль: искать взаимосвязь с другими задачами - это безусловно хорошо. Но в первую очередь надо решать ту задачу, которую вам поставили.
Как благодаря Ленке мы попали в десятку

Олег к задаче явно охладел. Уже почти зачётная неделя. Олег мне прямо сказал, чтобы я бросал задачу и готовился к экзаменам (я был весёлым магистрантом первого года обучения) и лучше бы сдал сессию на отл. Я был мягко говоря в отчаянии. Единственное, что меня остановило от того, чтобы забросить всё - это Лена. Я не мог взять и так просто сдаться, ведь я пообещал свозить её на моречко...
Однажды мы с ней сидели и искали ей статьи для курсача по улучшению изображений. Искали мы на русском языке. Искали мы в Яндексе, но когда не было нормальной инфы, то гуглили. Находили подсказки в гугле и снова искали в яндексе.
Мне пора была идти домой. Пока я ехал в маршрутке, я задумался про задачу. Потом подумал про Лену. Потом про задачу. Снова про Лену. И до меня допёрло. Я же час назад наблюдал за пользователем, который постоянно делал свичи. Да ведь это же то, что мне надо! Когда она начинала гуглить? Когда в поисковой выдаче был мусор. То есть, чем дольше она ничего не предпринимала, то тем больше вероятность, что она начнёт гуглить. А какие у нас записи удалены в тестовой выборке? В которых был свич. Но она потом возвращалась обратно в яндекс. Ну ведь это же опять свич! Давайте в рамках задачи посмотрим на этот процесс:
Ленка сделала запрос.
744899 0 Q 0 192902 632428 309585 319567 6547 20264 3094446 90 841 8344 119571 - получила результат. Начинает изучать...
744899 592 S - Лене ничего не понравилось и она пошла гуглить. Эта запись удалена, её нет.
744899 1403 C 0 632428 - в гугле тоже ничего не нашла. Она вернулась. Мне известно это.
... другие записи.
А теперь посмотрите, сколько времени прошло между запросом и первым кликом? До фига и больше. Это же супер-фича! До этого мы учитывали общее время сессии, но это же неверно! Пользователь может долго вкуривать надо документом. А теперь мы учитываем сколько времени он тратит на изучение выборки и принятие решения. Я сразу же понадобавлял признаков: медиана времени раздумья всех пользователей над документом и запросом; количество превышений пользователем медианы времени раздумий в сессии; разные статистические величины для пользователя, сколько он времени потратил на изучение поисковой выдачи; сколько народ тратил времени на эти документы. То есть, акцент признаков по времени сместился со всей сессии на отдельные действия, что было безусловно правильно.
Как итог: мы сразу же ворвались в десятку с 0.79. Но времени всего было два дня и мы уже больше не апались.
Послесловие

Был уже март следующего года. Мы готовились к публикации и мне надо было добавить список используемой литературы. Ради интереса я полез читать и обомлел. Все указывали на самый простой признак, который нам не пришёл в голову. Надо было добавить признак, на какой в очереди пользователь кликнул документ! Ведь если пользователь кликнул на первые три документа - скорее всего, он нашёл что-то релевантное. Если где-то по серёдке клик - вероятность свича уже выше, а если кликнул на последние документы в очереди - то это же сигнал, что будет скорее всего либо свич, либо переформулирован запрос! Я добавил несколько признаков на этой идее. Если бы я это сделал чуть раньше - мы бы заняли второе место и получили бы наши доллары.
По итогу у нас было под 40 различных признаков. Алгоритм обучался в течении получаса.
Мораль: учите матчасть!
p.s. Ленку я на моречко всё-таки свозил - мне факультет за публикацию, отличную учёбу и шахматные деяния выплатил 70 штук. А на морях:
А в голове мутит,
И ангелы летают,
И все проблемы тают, исчезают!
Список литературы:
В принципе, всё, что тут делалось было нашим деянием и исследованием. Вообще, есть и другие подходы. Самым популярным из которых является Байесовский (статистический) подход к решению задачи и соответствующие ему алгоритмы:
1. Скрытые марковские модели
2. Алгоритмы разделения смеси распределений
3. Победитель: градиентый бустинг регрессионных деревьев для ранжированного поиска (pGBRT)
Обещаю, что следующий пост про машинное обучение будет сугубо техническим и теоретическим. Матан, метопты + теорвер. Будет он посвящён: построению ансамблей алгоритмов, обзору нескольких метрик (AUC, Accuracy, Precision|Recall), RapidMiner. Опубликую его также на выходных - а то несколько репетиторских заметок ждут своего часа...














