

Ответ на пост «Просто хочу поделиться фотографией, которую у себя нашел а архиве»448

г.Байконур / апрель 2025

Здесь собраны все публикуемые пикабушниками посты без отбора. Самые интересные попадут в Горячее.
г.Байконур / апрель 2025
Автор: Денис Аветисян
На протяжении долгого времени анализ видеоконтента сталкивался с фундаментальной проблемой: неспособностью к тонкому, нюансированному рассуждению, необходимому для точного ответа на вопросы. Традиционные подходы часто оказывались бессильны перед сложными сценами и динамичными событиями, упуская критически важные детали. Прорыв, представленный в ‘Open-o3 Video: Grounded Video Reasoning with Explicit Spatio-Temporal Evidence’, заключается в внедрении подхода, который не просто распознает объекты и действия, но и явно связывает их с конкретными моментами времени и пространством, формируя четкое обоснование для каждого ответа. Но сможет ли подобный уровень детализации и прозрачности в рассуждениях открыть путь к созданию действительно "видящих" машин, способных не только понимать видео, но и объяснять свои выводы так же, как это делает человек?

В отличие от предшествующих моделей, ограничивающихся текстовыми объяснениями, Open-o3 Video выявляет ключевые моменты и области видео, демонстрируя логику принятия решения и позволяя проверить обоснованность предсказания.
Понимание видео – это задача, требующая не просто распознавания объектов, но и выстраивания логических связей между ними во времени и пространстве. Традиционные методы анализа видео зачастую оказываются неспособны справиться с этой задачей, ограничиваясь поверхностным описанием сцены и упуская тонкие нюансы, необходимые для точного ответа на вопрос. Это связано с тем, что многие существующие подходы сосредотачиваются на извлечении признаков, не уделяя достаточного внимания построению целостной картины происходящего.
Существующие методы часто испытывают трудности с точной локализацией событий как в пространстве, так и во времени. Неспособность выделить ключевые моменты и указать на конкретные области изображения приводит к неточным или неполным ответам. Представьте себе задачу определения, какой предмет был взят персонажем в определенный момент времени. Если система не может точно определить местоположение персонажа и объекта в кадре, а также момент, когда произошло взаимодействие, ответ будет неверным или неполным. Эта проблема особенно актуальна для сложных сцен с множеством объектов и динамичными событиями.
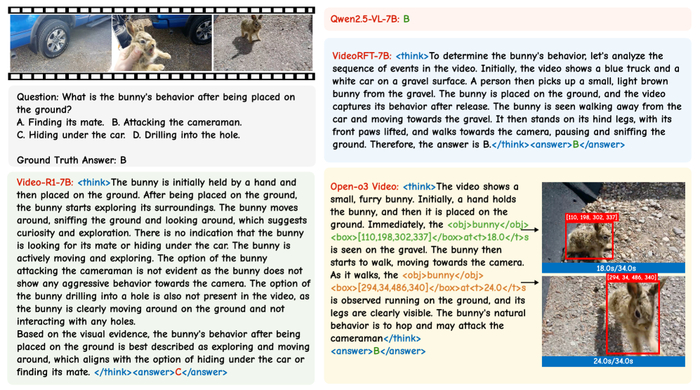
Визуализация точно локализует время и место действия для распознавания действий, превосходя Video-R1.
Недостаток точной локализации приводит к тому, что система не может установить причинно-следственные связи между событиями, что делает невозможным построение осмысленных ответов на вопросы, требующие логического мышления. Для решения этой проблемы необходимо разработать новые методы, которые способны не только распознавать объекты, но и отслеживать их перемещение во времени и пространстве, а также устанавливать связи между ними. Это требует интеграции визуальной информации с временными и пространственными данными, а также использования алгоритмов, способных выявлять закономерности и строить логические выводы.
В конечном итоге, задача понимания видео заключается не просто в извлечении информации, но и в построении осмысленной интерпретации происходящего. Для этого необходимо разработать методы, которые способны не только видеть, но и понимать, что происходит на видео, и предоставлять ответы, основанные на логическом мышлении и понимании контекста.
В стремлении к глубокому пониманию видеоконтента, исследователи представили Open-o3 Video – новаторскую систему, расширяющую границы традиционного видеоанализа. Представьте себе микроскоп, позволяющий не только увидеть изображение, но и проследить динамику процессов, происходящих во времени и пространстве. Именно таким инструментом и является Open-o3 Video. В отличие от подходов, ограничивающихся общим пониманием сцены, эта система генерирует явные пространственно-временные доказательства, связывая логические выводы с конкретными кадрами и ограничивающими рамками.
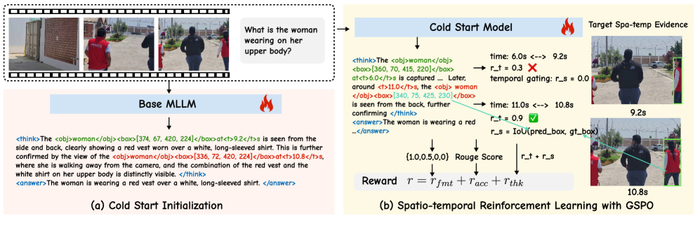
Обзор Open-o3 Video. Используется двухэтапный подход к обучению: (a) инициализация для обучения структурированным результатам; (b) обучение с подкреплением с комбинированной наградой, улучшающей временную и пространственную точность.
Ключевой особенностью системы является её способность к точной привязке процессов рассуждения к видеоконтенту. Вместо абстрактных выводов, Open-o3 Video предлагает конкретные кадры с указанием времени и ограничивающими рамками объектов, участвующих в действии. Это позволяет не только проверить обоснованность выводов, но и проследить логику рассуждений, как будто просматривая фильм с комментариями эксперта. Такой подход открывает новые возможности для интерпретации видеоданных и построения надежных систем искусственного интеллекта.
Разработанная архитектура Open-o3 Video использует двухэтапный подход к обучению. Сначала модель инициализируется для формирования структурированных результатов, а затем проходит обучение с подкреплением, оптимизирующее как временную, так и пространственную точность. Адаптивная близость и управление временем позволяют модели эффективно усваивать знания, избегая перегрузки и обеспечивая стабильность обучения. Этот подход обеспечивает надежность и интерпретируемость, что крайне важно для построения доверительных систем искусственного интеллекта.
В конечном итоге, Open-o3 Video представляет собой значительный шаг вперед в области анализа видеоданных. Благодаря способности генерировать явные пространственно-временные доказательства, система открывает новые возможности для понимания сложных видеосцен и построения интеллектуальных систем, способных к логическому мышлению и обоснованным выводам. Это, по сути, не просто инструмент анализа, а новый способ видеть мир через призму данных.
Для создания надежных систем, способных к пространственно-временному обучению, исследователи представили два тщательно разработанных набора данных: STGR-CoT-30k и STGR-RL-36k. Эти ресурсы созданы для обеспечения комплексной поддержки обучения моделей, позволяя им овладевать сложными паттернами рассуждений и точностью локализации в видеоматериалах. STGR-CoT-30k служит основой для контролируемой тонкой настройки, предоставляя парные данные, состоящие из вопросов, ключевых кадров и подробных цепочек рассуждений. Такая структура позволяет моделям изучать не только точные ответы, но и логические шаги, ведущие к ним.
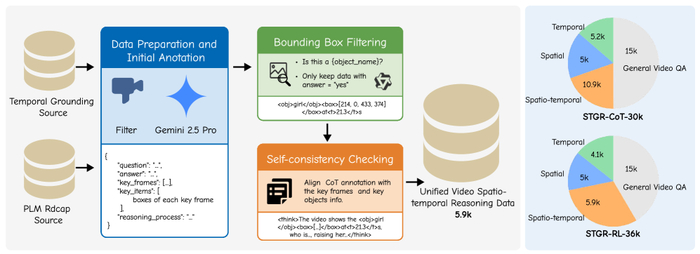
Обзор конвейера построения данных и состава набора данных. Слева: конвейер Gemini 2.5 Pro, фильтрацию ограничивающих рамок и проверку согласованности. Справа: распределение категорий данных в STGR-CoT-30k (SFT) и STGR-RL-36k (RL).
В то же время, STGR-RL-36k разработан специально для обучения с подкреплением, обеспечивая пространственно-временное наблюдение, необходимое для улучшения процесса обучения. Этот набор данных позволяет моделям учиться не только отвечать на вопросы, но и обосновывать свои ответы, выделяя соответствующие моменты и объекты в видео. Оба набора данных созданы с использованием больших языковых моделей, таких как Gemini 2.5 Pro, что гарантирует высокое качество аннотаций и соответствие современным стандартам обработки естественного языка. Применение таких инструментов позволяет моделировать сложные процессы рассуждений и получать более точные и надежные результаты. В результате, исследователи создали ценные ресурсы, которые открывают новые возможности для развития систем компьютерного зрения и обработки видео.
Для достижения устойчивой и точной работы системы пространственно-временного рассуждения, исследователи разработали ряд инновационных методов, направленных на оптимизацию процесса обучения и повышения надежности модели. В основе этих методов лежит понимание того, что недостаток данных или их неточность могут существенно влиять на конечные выводы.
Одним из ключевых аспектов является адаптивное приближение во времени (Adaptive Temporal Proximity). В процессе обучения с подкреплением, исследователи ослабили ограничения по временной точности. Это позволило стабилизировать процесс обучения, особенно на начальных этапах, когда модель еще не способна точно определять моменты времени. Вместо жестких требований к временной привязке, модель получала возможность совершать небольшие ошибки, что способствовало более плавному и эффективному обучению.
Для обеспечения точной пространственно-временной привязки, исследователи использовали механизм временной фильтрации (Temporal Gating). Этот механизм позволяет вознаграждать модель только за точные предсказания по времени, отсекая ложные или неточные результаты. Такой подход способствует более четкой и надежной привязке событий к конкретным моментам времени, что критически важно для понимания динамичных сцен.
Для повышения надежности системы при работе с новыми данными, исследователи разработали метод масштабирования времени тестирования с учетом уверенности (Confidence-Aware Test-Time Scaling). Этот метод позволяет взвешивать различные ответы модели в зависимости от их уверенности, отсеивая ложные или неуверенные результаты. Это позволяет повысить надежность и точность ответов модели, особенно в сложных или неоднозначных ситуациях.

Пример запроса для аннотации данных временной привязки.
В качестве алгоритма оптимизации пространственно-временного рассуждения была выбрана группа последовательной политики оптимизации (GSPO). Этот алгоритм, работающий в рамках обучения с подкреплением, позволяет модели более эффективно извлекать информацию из данных и улучшать свои способности к пространственно-временному рассуждению. GSPO позволяет модели не только идентифицировать объекты и события в видео, но и понимать их взаимосвязь во времени и пространстве. Исследователи подчеркивают, что предложенные методы, в совокупности, позволяют создать более надежную и точную систему пространственно-временного рассуждения, способную решать сложные задачи в области анализа видео.
Оценка возможностей модели в области пространственно-временной привязки является ключевым шагом в развитии систем видеопонимания. В данной работе, в качестве строгой платформы для подобных оценок, использовался бенчмарк V-STAR. Его структура позволяет не просто констатировать факт ответа, но и анализировать, насколько точно модель локализует значимые события во времени и пространстве видеоряда.
В качестве отправной точки для сравнения и дальнейшего развития использовалась модель Qwen2.5-VL-7B, демонстрирующая стабильные результаты. Однако, целью исследования являлось не просто превзойти существующие решения, но и понять, какие именно аспекты видеопонимания требуют особого внимания. Ошибки, допущенные моделью, рассматривались не как провал, а как ценный источник информации, указывающий на слабые места в архитектуре и алгоритмах.
Анализ этих ошибок позволил сформулировать несколько ключевых направлений для дальнейших исследований. Во-первых, необходимо расширить возможности модели в обработке более сложных видеоданных, включающих большое количество объектов и динамичных сцен. Во-вторых, следует уделить внимание развитию алгоритмов, способных к многошаговому логическому выводу, выходящему за рамки простой идентификации объектов и событий. И, наконец, необходимо интегрировать в систему мультимодальные сигналы, включая аудио- и речевую информацию, которые часто содержат важные ключи к пониманию видеоконтента.

Визуализация показывает, что модель идентифицирует более эффективные подтверждающие доказательства в задачах рассуждения о погоде, в то время как связанные модели рассуждения о видео показывают низкую производительность.
Данная работа открывает путь к созданию систем искусственного интеллекта, способных к тонкому и нюансированному пониманию видеоконтента. Это, в свою очередь, позволит разработать передовые приложения в таких областях, как робототехника, системы видеонаблюдения и индустрия развлечений. Важно отметить, что процесс улучшения модели — это не просто достижение более высоких показателей, но и углубление понимания принципов работы визуального мышления и искусственного интеллекта.
Подобно тому, как мы стремимся понять закономерности в сложных системах, представленная работа Open-o3 Video демонстрирует важность явного представления пространственно-временных доказательств при рассуждениях о видео. Как верно заметил Эндрю Ын: «Мы должны сосредоточиться на том, чтобы сделать машинное обучение доступным для всех». Этот подход к обоснованию, с указанием конкретных временных меток и ограничивающих рамок, позволяет не только улучшить точность ответов на вопросы о видео, но и сделать процесс рассуждений более прозрачным и понятным – что, безусловно, приближает нас к созданию действительно интеллектуальных систем. По сути, Open-o3 Video акцентирует внимание на видимом – на доказательствах, которые система использует для обоснования своих выводов – и это соответствует нашему стремлению к пониманию не только что система делает, но и как она к этому пришла, избегая скрытых закономерностей и влияний шума.
Представленная работа, безусловно, продвигает нас вперёд в понимании видео, но давайте не будем спешить с оптимизмом. Явное представление пространственно-временных доказательств – это, конечно, элегантно, но остаётся вопрос: насколько эта "явность" действительно приближает нас к пониманию, а не просто к более эффективному сопоставлению паттернов? Мы видим улучшение метрик, но часто забываем, что метрика – это лишь проекция, упрощение сложной реальности. Настоящее понимание требует не просто обнаружения "когда" и "где", а осознания "почему".
Будущие исследования, на мой взгляд, должны сосредоточиться на преодолении хрупкости этих систем. Слишком часто небольшие изменения в видео, незначительные отклонения от тренировочных данных, приводят к катастрофическим ошибкам. Необходимо развивать методы, способные к обобщению, к экстраполяции знаний за пределы узкого контекста. И, конечно, крайне важно исследовать возможности интеграции с другими модальностями – текст, звук, тактильные ощущения – чтобы создать поистине многогранное представление о мире.
И ещё одна мысль: визуальная интерпретация требует терпения. Быстрые выводы могут скрывать структурные ошибки. Возможно, нам стоит замедлиться, перестать гнаться за state-of-the-art и посвятить больше времени тщательному анализу тех фундаментальных принципов, которые лежат в основе нашего восприятия и понимания видео.
Оригинал статьи: https://arxiv.org/pdf/2510.20579.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Горит уже третий ветрогенератор.
Источник 1: https://t.me/RVvoenkor/102528?single=
Источник 2: https://t.me/readovkanews/102553?single=
Мужик купил будильник, который кричит: «Вставай, лентяй!»
На следующий день будильник проснулся первым,
посмотрел на спящего хозяина и сказал: «Ладно… ещё пять минут.»
Кому интересно, ссылка на парик для кошки

Национальный парк Лейк Кларк, Аляска, США.
Фотограф Mike Rigney.
Анекдот времен окончания Второй Мировой.
Если вы видите в небе коричневый самолет - это ВВС Британии. Если видите зеленый самолет - это ВВС СССР. Если видите серебристый самолёт - это ВВС США. Если не видите ни одного самолета - это Люфтваффе.
Анекдот #2
Британские учёные изобрели 300° спирт. Вроде хорошее изобретение, но где применять. Решили протестить на пьяницах самых пьющих стран. Зайдет им или нет. Приезжают в Финляндию, заходят в бар, подходят к мужику за стойкой: выпить на халяву хочешь? Тот - без вопросов, наливай! Наливаю стопку, он выпивает и падает замертво. Британцы - дело плохо, тут продажи не пойдут и сваливают. Та же история в Ирландии, Румынии и Словакии. Ни одного выжившего после дегустации. Почти отчаявшись едут в Россию, залезают в какие то дебри, смотрят, мужик поле на тракторе пашет. Те к нему. Выпить хочешь? По чем? Да бесплатно даем, работаешь давно, уставший, вот помочь хотим. Протягивают стопку. Мужик морщится, отворачивается и какое то время копошится в кабине. Достает граненый стакан, обтирает об фуфайку и подставляет британцам. Те переглянулись, подали плечами и налили трактористу полный стакан. Тот выпивает залпом, занюхивает рукавом, заводит трактор и едет дальше. Бриты в осадке. Вдруг трактор резко тормозит, из него выпадывает мужик, катается по земле, материться и залазит обратно. Через 100 метров ситуация повторяется снова. И так несколько раз. Бриты вобще в сюре, бегут к нему, тормозят трактор, говорят: мужик, те видимо весьма херово, или накрыло не так, может еще хряпнешь? Тракторист с раздражением: да идите вы нахрен со своим самогоном! Как отрыгну - фуфайка загорается!
Старый и более тупой анек:
Дневник марсианина.
Дата 577.75.447
К нам прилетели американцы с земли. Вскрыли наш бункер с помощью бензорезов за пол часа. Пришли и раздали нам бургеры. Было вкусно, но хватило не всем. Сожрали американцев.
Дата 588.66.245
Прилетели японцы. С помощью лазера вскрыли бункер за 10 минут. Пришли, раздали нам суши. Было вкусно, но хватило не всем. Пришлось сожрать японцев.
Дата 594.02.786
Прилетали русские. С помощью лома и чьей то матери взломали бункер за 2 минуты. Пришли и раздали "пиздюлей". Было не вкусно. Но хватило всем.







