Удаляем шум и баннеры из текстовых данных с использованием метода кластеризации KMeans. Алгоритм кластеризации k-средних - метод для обучения без учителя и выявления кластеров объектов данных в наборе данных, который направлен на группировку данных в отдельные кластеры на основе определенных предположений. Алгоритм ищет заранее определенное количество кластеров в неразмеченном многомерном наборе данных, находя центры кластеров и назначая точки ближайшему центру. Модель k-средних реализована на Python с использованием библиотеки scikit-learn...
Средняя стоимость килограмма бананов в магазинах Томска превысила 170 рублей, следует из данных Росстата. За год этот фрукт подорожал на 55%. Причиной резкого роста эксперты называют проблемы с логистикой после февраля 2022 года и ослабление рубля...
Выжимка из текста, очищенный текст от "шума", процент сжатия составляет около 30% от основного текста:
за год бананы в томске и по области в целом подорожали на 55%: в январе 2023-го в супермаркетах города они стояли 111 рублей за килограмм, по региону средняя цена была 109 рублей. в целом по россии рост за год составил 46%: цена на желтый фрукт выросла со 106 рублей за килограмм до 155 рублей, следует из данных статистики. влияние на стоимость бананов могли оказать и внутренние механизмы регулирования цен на социально значимые продукты в россии, говорила партнер консалтинговой компании «нэо» альбина корягина по ее словам, в 2022 году российские власти по мере возможности «влияли на рост цен в рознице на социально значимые продукты, в том числе и на бананы»
Для ЛЛ: Продолжение поста о том как сделал полезную для себя утилиту на Python не зная ни одного языка программирования при помощи ChatGPT.
В прошлом посте высказал мнение, что используя ChatGPT вполне себе можно решить свою небольшую цифровую проблемку, делюсь новостями по реализации задуманного.
Напомню, задача была перенаправлять трафик к определенным доменам через VPN. Сложность заключалась в том, что заворачивать в туннель нужно было трафик к доменам, а не IP адресам т.е. именно к DNS именам IP адреса которых постоянно меняются, что делает практически бесполезным их добавление в статические маршруты или VPN конфиг. Но основной проблемой был относительно слабый роутер Keenetic Air использовать на котором готовые решения было затруднительно или скорее даже невозможно в силу отсутствия USB порта и очень малого количества ROM, которого с трудом хватает даже для свежих родных прошивок.
Итак, благодаря тому, что OpenAI пусть и ограниченно но для всех желающих открыла доступ к ChatGPT Plus удалось сдвинутся с места и решить практически все имевшиеся проблемы.
С новой языковой моделью стало проще договориться, хотя правильнее наверное будет сказать, что она стала лучше понимать что я от нее хочу и в результате утилита была доработана. Основные изменения: - аптайм работы увеличен с нескольких минут до 100% времени. - повышена скорость работы. - убраны задержки при выполнении операций по SSH. - лог консоли стал более информативным.
Для тех кто дочитал до этого места, опишу логику работы: Программа запущена на VPS который одновременно является VPN сервером. На домашнем роутере основным DNS установлен IP адрес сервера с запущенной программой. Программа принимает DNS запрос от хоста, используя вышестоящий DNS сервер разрешает его в IP адрес и дает ответ хосту, после чего проверяет DNS имя (совпадения по первым октетам) на наличие в пользовательском списке и в случае совпадения через SSH отправляет роутеру команду на добавление IP адресов этого DNS имени в статические маршруты, указывая в качестве шлюза для этих IP адресов настроенное в роутере VPN соединение.
Что не получается решить: отправка всех команд за одну SSH сессию, сейчас для каждой команды инициируется отдельное подключение. Никак этот момент победить не получается. Что хочется добавить: работу с несколькими рекурсивными DNS серверами. Сейчас используется один вышестоящий DNS и очень редко, но бывает, он вылетает в таймаут по количеству запросов в секунду.
Однако производительности и текущей конфигурации хватает для обслуживания всех домашних устройств без каких-либо значительных задержек.
Пост запилил себе на память, но, если кто чего подскажет - будет хорошо, а если кому-то окажется полезным так и вообще - восторг. Код доступен на GitHub.
Буквально неделю назад вышла открытая нейросеть- модель именно заточенная под программирование ( поддерживает 60 языков). В этом видео на 2 минуты буквально показываю как банально устанавливается ( но нужен мощный компьютер, от 16GB оперативка как на основном процессоре, так и на графическом) Отвечает пока на английском, хотя и все правильно, но понимает запросы ( задачи для программирования) на русском. Чудеса, иначе не сказать. В интернете эта же сеть https://chat.mistral.ai/chat отвечает и на русском. Может на русском тоже пойму потом как сделать, но пока не понял. С другой стороны для начинающих программистов английский полезно изучать:) Установка через эту программу https://lmstudio.ai/ и дальше грузится модель и всё.. по сути в два клика, не надо мучаться с пайтоном, вчера полдня пробовал по инструкции сделать, то одних библиотек не хватает, то других. Инструкция для пайтонистов вот тут https://huggingface.co/mistralai/Codestral-22B-v0.1
Для тех, кто адски ленив и невнимателен, и не хочет 2 минуты видео смотреть, посмотрите на последнюю ссылку, и выбирайте Codestral последний размером 15GB или 22GB, в видео это видно.
UPD:
На эту тему конечно разгорелись почти что жаркие споры в комментариях, но я то думал довольно очевидно, что если человек использует нейросеть для программирования он какие-то элементарные основы знает: что такое хостинг, ftp хотя бы на бейсике или турбо паскале в школе институте программировал ( как я). Поэтому да, если вы совсем с нуля- то нужно какие-то основы получить, тогда может быть будет смысл для простых программ. У меня уровень крайне простой, программировать не умею, но основы знаю, поэтому например смог обновить на своих сайтах картинки, предварительно спарсив их из источника оригиналов и совместив артикулы, воспользовавшись определенным форматом экселя.. Звучит страшно и непонятно? Если да, то как бы не очень будет вам полезно.. Но научиться я думаю можно быстрей с помощью нейросетей. И плюс ошибаются они, некоторые программки я с 7й попытки писал, то есть делает- ошибка..я ей говорю- ошибка, она такая- исправляю..и так далее. Так что делайте выводы.
И кстати, был невнимателен, по ссылке в тексте где эта нейросеть запускается на сайте- по умолчанию стоит общая сеть, поэтому и отвечает на русском. Очень быстро. Если же там поставить Codestral ( посмотрите внимательно)- также по английски будет отвечать. Так что все как и было задумано:-) Ах да, пришлось просить исправить скрипт на php написанный Codestral - потому что он начал тупить, хоть по кругу.. Copilot все исправил и всё заработало. Так что гибкость и хитрость тоже нужна. Всем успехов!
Начну с того, что всю профессиональную жизнь (с 19 до 36) занимался продажами. Я отлично знаю, что такое маркетинг, операционная эффективность точки продаж, бесконечные встречи с клиентами, управление персоналом, и т.д.
Но суть не в этом.
Суть в том, что в 2022 году я очень заинтересовался программированием.
Скажу честно, что бесконечная реклама школ имела влияние на мою заинтересованность. Но дело не только в этом. Дело в том, что будучи выпускником небольшой сельской школы, я мечтал стать программистом. У меня было представление, что все эти игры, которые захватывали дух школьника начала 2000х, создавали определенные люди. Но, в моей сельской школе маленького поселка на севере Камчатки, даже информатика состояла из того, что мы просто рубились в КС 1.6 или типо того.
Далее, я поступил таки на программиста, даже проучился около года, но в итоге стал юристом)
На данный момент:
- Я живу в Москве;
- Мне 36 лет;
- Мне очень нравится идея автоматизации работы отделов продаж и прочего (опыт бэкграунда);
- Мне очень хочется стать профессионалом в этой сфере;
Я знаю:
- Сам python 3 (+/-);
- Как развернуть сайт на Django, взаимодействие через ssh;
Привет, Пикабу! Меня зовут Александр Троицкий, я автор канала AI для чайников, и я продолжаю серию коротких статей по метрикам качества моделей для машинного обучения!
Что такое регрессия?
Задача регрессии в машинном обучении — это тип обучения в ИИ, когда модель обучается на данных с непрерывным значением, чтобы предсказывать его на основе одного или нескольких входных параметров. Отличие регрессии от задач классификации заключается в том, что регрессия предсказывает непрерывные значения (например, цену на дом, температуру, количество продаж), в то время как классификация предсказывает категориальные метки (например, да/нет, красный/синий/зеленый).
То есть задача регрессии предсказывает какую-то цифру, а задача классификации - это как выбор в тесте из нескольких вариантов ответа.
Пример
Давайте представим, что мы - доска объявлений типа Авито или Циана. Мы хотим подсказывать пользователю в интерфейсе по какой цене ему лучше разместить свою квартиру на основании множества факторов, например:
Местоположение квартиры
Площадь
Этаж
Ремонт
Год постройки здания
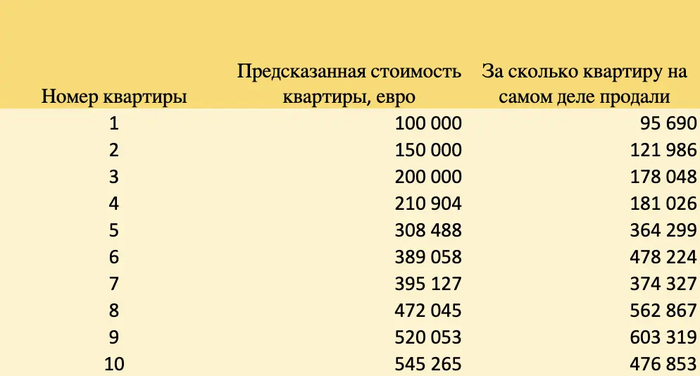
В итоге мы выводим пользователю рекомендуемую цифру в евро.Мы предсказали стоимость 10 квартир, а через месяц узнали за сколько их на самом деле продали.
Далее мы проведем с этими результатами нехитрые вычисления:
Вычтем из предсказанной цены реальную цену (первый столбик)
Возведем эту разницу в квадрат (второй столбик)
Возьмем корень из этого квадрата (третий столбик)
Получим следующие результаты на нашем примере:
P.S. да, можно просто взять разницу по модулю, но более умные математики говорят, что это все-таки не одно и то же - можете почитать об этом отдельно
MSE
Если мы возьмем второй столбик из зеленой таблицы выше, сложим все числа в нем, а потом поделим на количество этих чисел (возьмем среднюю), то получим MSE или среднюю квадратическую ошибку. В нашем случае:
MSE = 3353809295
Большое число! Из-за его величины оно сложно интерпретируется с точки зрения бизнеса. Чаще эту метрику используют при разработке моделей, когда важно наказывать большие ошибки сильнее, чем маленькие, так как ошибка возрастает квадратично. Это делает MSE чувствительной к выбросам. MSE используют, если большие ошибки недопустимы и должны сильно влиять на модель.
RMSE
RMSE или среднеквадратическая ошибка - это младший брат MSE. Чтобы ее посчитать нужно просто взять квадрат из MSE!
В нашем случае получится 57912.
RMSE также штрафует за большие ошибки, но в отличие от MSE, масштаб ошибки аналогичен исходным данным, что облегчает интерпретацию. Это делает RMSE хорошим выбором для многих практических задач, где важна интерпретируемость результата.
MAE
MAE или средняя абсолютная ошибка считается по третьем столбику из зеленой таблички выше. Нужно взять сумму корней из квадрата разницы между предсказанной ценой и реальной ценой и поделить ее на количество наблюдений. Проще говоря, берем среднее из третьего столбика.
В нашем примере MAE = 49243
MAE менее чувствительна к выбросам по сравнению с MSE и RMSE. Это делает её предпочтительным вариантом, когда выбросы присутствуют в данных, но не должны сильно влиять на общую производительность модели.
Немного усложним нашу зеленую табличку
Чтобы разобраться с тем как считается R-квадрат и MAPE нужно дополнить нашу зеленую табличку еще двумя стобиками:
Вычтем из предсказанной цены среднюю предсказанную цену и возведем это в квадрат (четвертый зеленый столбик 4). P.S. Не спрашивайте зачем это нужно и какой в этом практический смысл - просто сделайте :)
Поделим третий зеленый столбик на предсказанную цену квартиру из желтой таблички. То есть поделим разницу между предсказанной и реальной ценой квартиры по модулю на предсказанную стоимость квартиры. (пятый зеленый столбик)
Коэффициент детерминации (R квадрат)
Чтобы его получить надо из единицы вычесть разницу суммы второго и четвертого зеленых столбцов.
R-квадрат измеряет, какая доля вариативности зависимой переменной объясняется независимыми переменными в модели. Это хороший способ оценить адекватность модели: близость к 1 говорит о хорошем объяснении данных моделью. R-квадрат лучше всего подходит для сравнения моделей с одинаковыми данными.
MAPE
Средняя абсолютная процентная ошибка или MAPE - это среднее пятого зеленого столбца.
В нашем случае = 14,2%
MAPE измеряет отклонение прогнозов от фактических значений в процентах и является хорошим выбором, когда нужно легко интерпретируемое показание ошибки в процентном отношении. Однако MAPE может быть неэффективной, когда в данных присутствуют нулевые или очень маленькие значения.
Excel файл с примерами
Вы можете найти эксель файл с этими цифрами, бесплатно его скачать и собственноручно поиграться со значениями в нем вот в этом посте в моем телеграмм канале
Заключение
Поздравляю! Вы узнали про основные метрики в задачах регрессии!
Если вам интересно знать про ИИ и машинное обучение больше, чем рядовой человек, но меньше, чем data scientist, то подписывайтесь на мой канал в Телеграм. Я пишу редко, но по делу: AI для чайников. Подписывайтесь!
Такую задачу поставил Little.Bit пикабушникам. И на его призыв откликнулись PILOTMISHA, MorGott и Lei Radna. Поэтому теперь вы знаете, как сделать игру, скрафтить косплей, написать историю и посадить самолет. А если еще не знаете, то смотрите и учитесь.