


Теперь понятно в чем разница Java и JavaScript

Телеграм: @DevComics
Показать полностью
1
Телеграм: @DevComics

Из области курьезов. В недавно опубликованной вакансии говорится, что ищется администратор Windows 3.11. Напомним, что Windows 3.11 была выпущена 8 декабря 1993 года и, следовательно, существует уже довольно много лет. В частности, похоже, что место стало вакантным в железнодорожной компании, или Siemens.
Как заявлено, соискатель должен обладать знаниями операционных систем Windows 3.11 и старше, а также Windows Manager (в частности, MS-DOS и Windows for Workgroups). По-видимому, речь идет о дисплеях в поездах, разработанными компанией Siemens, поскольку в качестве местонахождения указан Эрланген, а также упоминается Sibas, "система железнодорожной автоматизации Siemens".
Конечно, это не единственная устаревшая система в используемая в крупных компаниях. Многие из них явно следуют девизу "Если работает, не трогай".
Продолжающаяся кампания вредоносной рекламы нацелена на китайских пользователей, предлагая им популярные приложения для обмена сообщениями, такие как Telegram или LINE, с целью распространения вредоносного ПО. Интересно, что программное обеспечение, подобное Telegram, сильно ограничено и ранее было запрещено в Китае.

Многие сервисы Google, включая поиск Google, также либо ограничены, либо подвергаются жесткой цензуре. Однако многие пользователи пытаются обойти эти ограничения с помощью различных инструментов, таких как VPN.
Угроза использует аккаунты рекламодателей Google для создания вредоносных объявлений и направления их на страницы, где ничего не подозревающие пользователи загружают троянские программы удаленного администрирования (RAT). Такие программы дают злоумышленнику полный контроль над машиной жертвы и возможность распространять дополнительное вредоносное ПО.
Возможно, это не совпадение, что вредоносные рекламные кампании в первую очередь направлены на ограниченные или запрещенные приложения. Хотя мы не знаем истинных намерений участников угроз, одним из их мотивов может быть сбор данных и шпионаж. В этом блоге мы поделимся более подробной информацией о вредоносных объявлениях и полезных нагрузках, которые нам удалось собрать.
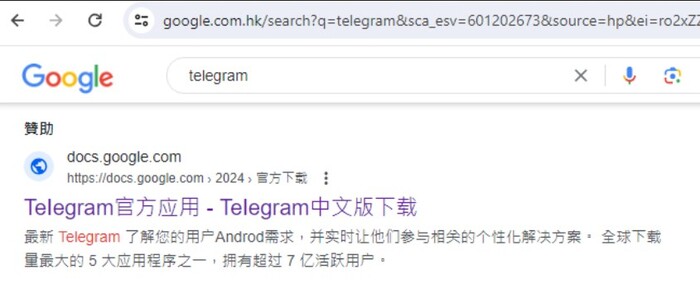
Посетители сайта google[.]cn перенаправляются на google.com[.]hk, где поиск, как утверждается, не подвергается цензуре. Набрав в поисковой строке "telegram", мы видим результат спонсированного поиска.
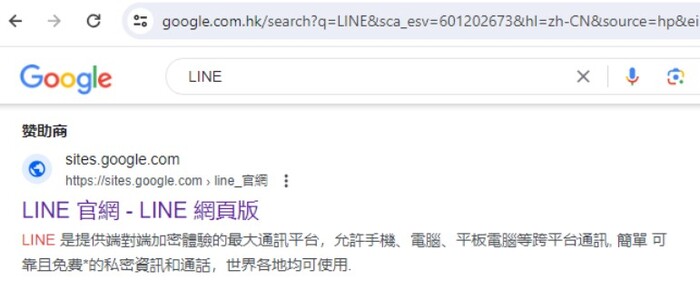
Вот реклама "LINE".
Мы выявили два аккаунта рекламодателей, стоящих за этими объявлениями, причем оба они были связаны с профилем пользователя в Нигерии:
Interactive Communication Team Limited
Ringier Media Nigeria Limited
Учитывая количество объявлений на каждой из этих учетных записей (включая множество не связанных с этими кампаниями), мы считаем, что они могли быть захвачены.
По всей видимости, используют инфраструктуру Google в виде Google Docs или сайтов Google. Это позволяет им вставлять ссылки для загрузки или даже перенаправлять на другие сайты, которые они контролируют.
Мы собрали несколько полезных нагрузок из этой кампании, все в формате MSI. Некоторые из них использовали технику, известную как побочная загрузка DLL, которая заключается в объединении легитимного приложения с вредоносной DLL, загружаемой автоматически.
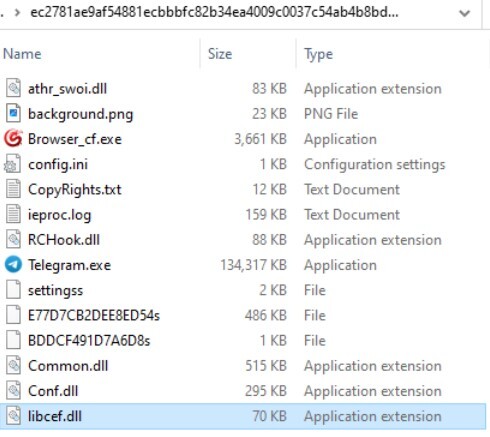
В приведенном выше примере DLL подписана ныне отозванным сертификатом Sharp Brilliance Communication Technology Co., Ltd., который также недавно использовался для подписи образца PlugX RAT. (PlugX - это китайская RAT, которая также выполняет побочную загрузку DLL).
Не все найденные вредоносные программы являются новыми, некоторые из них уже использовались в других кампаниях и являются вариантами Gh0st RAT.
На сайте и форуме (bbs[.]kafan[.]cn), посвященном безопасности и посещаемом китайскими пользователями, постоянно появляются вредоносные программы из этих кампаний, которые они называют FakeAPP.

Кроме того, похоже, что отдают предпочтение количеству перед качеством, постоянно продвигая новые полезные нагрузки и инфраструктуру в качестве командно-контрольной.
Онлайн-реклама - это эффективный способ привлечь определенную аудиторию, но, конечно, им тоже можно злоупотреблять. Люди (например, активисты), живущие в странах, где средства шифрованной связи запрещены или ограничены, будут пытаться обойти эти меры. Судя по всему, потенциальных жертв заманивают с помощью такой рекламы.
Полезная нагрузка соответствует угрозам, наблюдаемым в регионе Южной Азии, и мы видим схожие методы, такие как побочная загрузка DLL, которая довольно популярна среди многих RAT. Этот тип вредоносного ПО идеально подходит для сбора информации о человеке и бесшумного внедрения дополнительных компонентов, если это необходимо.
Мы уведомили Google о вредоносной рекламе и сообщили соответствующим сторонам о поддерживающей инфраструктуре.
Поддельные домены:
telagsmn[.]com
teleglren[.]com
teleglarm[.]com
Перенаправления:
5443654[.]site
5443654[.]world
Полезные нагрузки:
CS-HY-A8-bei.msi
63b89ca863d22a0f88ead1e18576a7504740b2771c1c32d15e2c04141795d79a
w-p-p64.msi
a83b93ec2a5602d102803cd02aecf5ac6e7de998632afe6ed255d6808465468e
mGtgsotp_zhx64.msi
acf6c75533ef9ed95f76bf10a48d56c75ce5bbb4d4d9262be9631c51f949c084
cgzn-tesup.msi
ec2781ae9af54881ecbbbfc82b34ea4009c0037c54ab4b8bd91f3f32ab1cf52a
tpseu-tcnz.msi
c08be9a01b3465f10299a461bbf3a2054fdff76da67e7d8ab33ad917b516ebdc
C2s
47.75.116[.]234:19858
216.83.56[.]247:36061
45.195.148[.]73:15628
Подсел на просмотр архивных видео о развитии IT с переводом от Яндекса. Лучшее объяснение устройства ПК для меня на данный момент.
Если честно,я так очень много часов насмотрел. Технология фантастическая.
/ Амбиции Meta по созданию "универсального переводчика" остаются в силе

Конгломерат социальных сетей Meta создал единую модель искусственного интеллекта, способную переводить на 200 различных языков, в том числе и на те, которые не поддерживаются существующими коммерческими инструментами. Компания выложила проект в открытый доступ в надежде на то, что другие разработчики будут использовать его в своей работе.
ИИ-модель является частью амбициозного научно-исследовательского проекта Meta по созданию так называемого "универсального переводчика речи", который компания считает важным для развития многих платформ - от Facebook и Instagram до таких развивающихся областей, как VR и AR. Машинный перевод не только позволяет компании Meta лучше понимать своих пользователей (и тем самым улучшать рекламные системы, которые приносят 97% ее доходов), но и может стать основой "убийственного" приложения для будущих проектов, таких как очки дополненной реальности.
Конгломерат социальных сетей Meta создал единую модель искусственного интеллекта, способную переводить на 200 различных языков, в том числе и на те, которые не поддерживаются существующими коммерческими инструментами. Компания выложила проект в открытый доступ в надежде на то, что другие разработчики будут использовать его в своей работе.
ИИ-модель является частью амбициозного научно-исследовательского проекта Meta по созданию так называемого "универсального переводчика речи", который компания считает важным для развития многих платформ - от Facebook и Instagram до таких развивающихся областей, как VR и AR. Машинный перевод не только позволяет компании Meta лучше понимать своих пользователей (и тем самым улучшать рекламные системы, которые приносят 97% ее доходов), но и может стать основой "убийственного" приложения для будущих проектов, таких как очки дополненной реальности.
Эксперты в области машинного перевода сообщили The Verge, что последнее исследование Meta является амбициозным и основательным, но отметили, что качество некоторых переводов модели, скорее всего, будет значительно ниже, чем у более популярных языков, таких как итальянский или немецкий.
"Основной вклад здесь - это данные", - сказал The Verge профессор Александр Фрейзер, эксперт по вычислительной лингвистике из LMU Munich (Германия). "Что важно, так это 100 новых языков [которые могут быть переведены с помощью модели Meta]".
Достижения Meta, как это ни парадоксально, обусловлены как масштабом, так и направленностью ее исследований. В то время как большинство моделей машинного перевода работают лишь с несколькими языками, модель Meta является всеобъемлющей: это единая система, способная переводить в более чем 40 000 различных направлениях между 200 различными языками. Однако Meta также заинтересована в том, чтобы включить в модель "языки с низким уровнем ресурсов" - языки, на которых имеется менее 1 млн. переведенных пар предложений. К ним относятся многие африканские и индийские языки, которые обычно не поддерживаются коммерческими средствами машинного перевода.
Научный сотрудник Meta AI Анжела Фан, работавшая над проектом, рассказала изданию The Verge, что на создание технологии перевода ее вдохновило недостаточное внимание, уделяемое в этой области языкам с более ограниченными исходными ресурсами.
"Перевод не работает даже для тех языков, на которых мы говорим, поэтому мы и начали этот проект", - сказала Фан. У нас есть такая мотивация - "что нужно сделать, чтобы создать технологию перевода, которая будет работать для всех?".
По словам Фан, модель, описанная в исследовательской статье, уже тестируется для поддержки проекта, помогающего редакторам Википедии переводить статьи на другие языки. Методы, разработанные при создании модели, в скором времени будут также интегрированы в инструменты перевода компании Meta.
Перевод - сложная задача и в лучшие времена, а машинный перевод, как известно, может быть нестабильным. При масштабном применении на платформах Meta даже небольшое количество ошибок может привести к катастрофическим последствиям, как, например, в случае, когда Facebook неправильно перевел сообщение палестинца "С добрым утром" как "навреди им", что привело к его аресту израильской полицией.
Для оценки качества работы новой модели Мета создала тестовый набор данных, состоящий из 3001 пары предложений для каждого языка, на который рассчитана модель, каждое из которых было переведено с английского на язык перевода человеком, являющимся профессиональным переводчиком и носителем языка.
Исследователи прогнали эти предложения через свою модель и сравнили машинный перевод с эталонными человеческими предложениями с помощью общепринятого в машинном переводе эталона, известного как BLEU (BiLingual Evaluation Understudy).
BLEU позволяет исследователям присваивать числовые баллы, измеряющие степень совпадения пар предложений. По утверждению компании Meta, ее модель позволяет улучшить показатели BLEU на 44% для всех поддерживаемых языков (по сравнению с предыдущими современными разработками). Однако, как это часто бывает в исследованиях в области ИИ, оценка прогресса на основе контрольных показателей требует контекста.
Хотя показатели BLEU позволяют исследователям сравнивать относительный прогресс различных моделей машинного перевода, они не являются абсолютным показателем способности программного обеспечения создавать качественные переводы.
Помните: Набор данных Meta состоит из 3001 предложения, и каждое из них было переведено только одним человеком. Это позволяет судить о качестве перевода, но всю выразительность языка невозможно отразить на столь малом фрагменте реального языка. Эта проблема ни в коем случае не ограничивается Meta - она касается всех работ по машинному переводу и особенно остро проявляется при оценке языков с ограниченными ресурсами, - но она показывает масштаб проблем, стоящих перед этой областью.
Кристиан Федерманн, главный менеджер по исследованиям, занимающийся вопросами машинного перевода в компании Microsoft, считает, что проект в целом "заслуживает похвалы" за стремление расширить сферу применения программ машинного перевода за счет менее распространенных языков, но отмечает, что сами по себе оценки BLEU могут дать лишь ограниченную оценку качества результата.
"Перевод - это творческий, генеративный процесс, в результате которого может получиться множество различных переводов, одинаково хороших (или плохих)", - сказал Федерманн в интервью The Verge. Невозможно определить общие уровни "хорошести" по шкале BLEU, поскольку они зависят от используемого тестового набора, его эталонного качества, а также от свойств, присущих исследуемой языковой паре".
По словам Фэн, оценки BLEU были также дополнены человеческой оценкой, и эти отзывы были очень позитивными, а также вызвали некоторые неожиданные реакции.
"Один из действительно интересных феноменов заключается в том, что люди, говорящие на языках с низким уровнем ресурсов, часто имеют более низкую планку качества перевода, поскольку у них нет другого инструмента", - сказала Фэн, которая сама является носителем языка с низким уровнем ресурсов - шанхайского. Они очень щедры, и поэтому нам приходится возвращаться и говорить: "Нет, вы должны быть очень точны, и если вы видите ошибку, скажите об этом".
Работа над переводом с помощью искусственного интеллекта часто представляется как однозначное благо, однако создание такого программного обеспечения сопряжено с особыми трудностями для носителей языков с низкими ресурсами. Для некоторых сообществ внимание "больших технологий" просто нежелательно: они не хотят, чтобы инструменты, необходимые для сохранения их языка, находились в чьих-либо руках, кроме их собственных. Для других проблемы не столько экзистенциальные, сколько связанные с качеством и влиянием.
Некоторые сообщества просто не хотят, чтобы их язык контролировали большие технологии.
Инженеры Meta изучили некоторые из этих вопросов, проведя интервью с 44 носителями языков с низким уровнем ресурсов. В ходе интервью был отмечен ряд положительных и отрицательных моментов, связанных с открытием их языков для машинного перевода.
Одним из положительных моментов, например, является то, что такие инструменты позволяют носителям языка получить доступ к большему количеству медиа и информации. С их помощью можно переводить богатые ресурсы, такие как англоязычная Википедия и учебные тексты. В то же время, если носители языков с низкими ресурсами будут потреблять больше медиа-материалов, созданных носителями языков с лучшей поддержкой, это может снизить стимулы к созданию таких материалов на своем родном языке.
Сбалансировать эти вопросы непросто, и проблемы, возникшие даже в рамках этого недавнего проекта, показывают, почему. Так, например, исследователи Meta отмечают, что из 44 носителей языков с низкими ресурсами, которых они опросили для изучения этих вопросов, большинство были "иммигрантами, живущими в США и Европе, и около трети из них идентифицируют себя как работники технического сектора" - это означает, что их точка зрения, скорее всего, отличается от точки зрения их родного сообщества и изначально предвзята.
Профессор Фрейзер из LMU Munich отметил, что, несмотря на это, исследование, безусловно, было проведено "в том ключе, который становится все более характерным для привлечения носителей языка", и что такие усилия "заслуживают похвалы".

Телеграм: @DevComics






