Хочу от себя сразу добавить, что перевод терминов почти буквален и из-за этого может показаться стремным😬 Если вы знаете, как можно было бы лучше передать смысл терминов «networking», «mindset», «promotion focused», «prevention focused», пишите в комменты, интересно!
Также сама идея этого исследования Джино мне лично не кажется интересной, но чего только люди не изучают.
Для ЛЛ: в этот раз Джино прокололась не на сортировке данных, а на том, что подделала количественные данные, забыв исправить качественные – ответы на открытый вопрос.
В этой статье Джино и соавторы предположили, что ментальные установки могут влиять на то, как люди относятся к нетворкингу. Установки, которые они изучали, известны как «ориентация на продвижение» и «ориентация на предотвращение». Первая включает в себя размышления о том, что человек хочет делать, а вторая – что должен. Гипотеза авторов была в том, что люди будут хуже относиться к нетворкингу, если будут настроены на «предотвращение».
То есть глобально суть в том, что настрой перед мероприятием будет влиять на то, как мы его воспримем.
Участников (599 человек) попросили выполнить короткое письменное задание, чтобы спровоцировать установку на продвижение, на предотвращение или на отсутствие каких-либо установок. Для этого их случайным образом распределили по группам и попросили написать об одной из трех вещей:
1.Надежда или стремление (установка на продвижение)
2. Долг или обязательство (установка на предотвращение)
3. Их обычные вечерние занятия (контрольное состояние)
После письменного задания участники попросили представить, что они находятся на социальном (нетворкинг-) мероприятии, где они установили какие-то профессиональные связи.
Затем участников просили оценить по 7-балльной шкале, насколько это мероприятие заставило их почувствовать себя: грязным, испорченным, неаутентичным, пристыженным, неправильным, неестественным, нечистым. Среднее этих семи определений представляло собой ключевую зависимую переменную, которую авторы расследования предложили назвать «моральной нечистотой» (1 – в нетворкинге нет ничего плохого; 7 – нетворкинг максимально «нечистый»).
Наконец, что очень важно для расследования, участников попросили перечислить 5-6 слов, описывающих их чувства по поводу мероприятия по нетворкингу. Джино и соавторов эти слова не особо интересовали, их даже никак не проанализировали. Но для Data Colada именно они стали ключиком к раскрытию фальсификации.
Как обычно, гипотеза авторов была убедительно подтверждена статистикой: участники чувствовали себя более нечистыми в отношении мероприятия по нетворкингу при установке на предотвращение, чем при установке на продвижение (F(2, 596) = 17,69, p < 0,0000001).
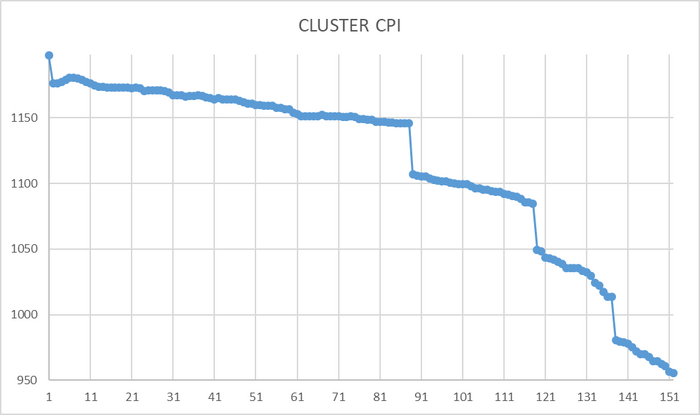
Но посмотрим на базу данных
Она была размещена в открытом доступе в 2020 году.
В верхней строке показан участник, который поставил «1» для всех элементов «нечистоты». То есть он совсем не чувствовал себя грязным, испорченным, неаутентичным и т. д., «находясь» на мероприятии по нетворкингу. Слова, которые он написал, также были положительными: «Комфортно», «Принимаемый», «Принадлежность», «Командная работа» и т. д.
Положительные оценки – положительные слова. Логично.
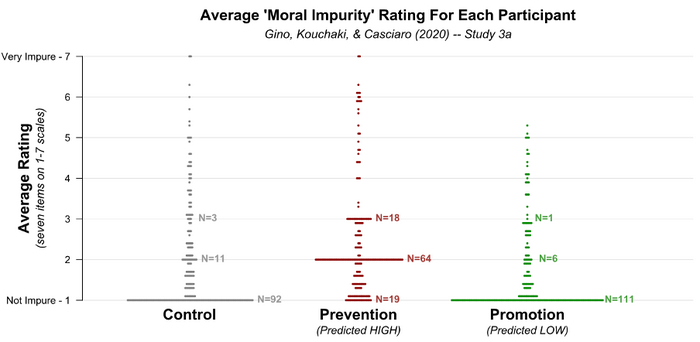
Рейтинг моральной нечистоты
На графике ниже показан средний рейтинг моральной нечистоты для каждого участника исследования.
В контрольном условии (слева) мы видим, что 92 участника поставили 1,0 балл, то есть они не чувствовали себя нечистыми ни по одному из пунктов шкалы. В целом, кажется логичным, что многие участники ответили бы таким образом. Возможно, нет ничего грязного или неправильного в установлении дружеских связей с коллегами.
Но посмотрим теперь на условие предотвращения (посередине), для которого авторы предсказали более высокие (более «нечистые») оценки. Действительно – там намного меньше единиц, но зато много двоек и троек.
Если это среднее значение семи оценок, то самый простой и распространенный 2,0 получается, когда все семь оценок равны 2. Хотя авторам Data Colada не кажется удивительным, что многие люди ответили 1 на все пункты шкалы, для них странно, что так много людей поставили по всем пунктам 2 или 3, то есть они чувствовали себя немного грязными, немного неаутентичными, немного пристыженными и т. д.
Это вызвало подозрение, что данные в условии предотвращения были подделаны, а именно некоторые из «все 1» были заменены на «все 2» и «все 3».
Data Colada также заметили, что в условии продвижения отсутствуют очень высокие значения, зато много средних 1,0, что тоже позволило заподозрить, что некоторые из более высоких значений были вручную изменены на 1,0.
Попробуем проверить эти подозрения. Используя слова.
Джино и соавторам не были интересны слова, которые написали участники. Но именно они и раскрывают всю картину мошенничества.
Насколько известно Data Colada, эти слова никогда не анализировались. Они даже не упоминаются в разделе результатов исследования.
Потому что тот, кто хочет подделать результаты, может изменить оценки, забыв изменить слова.
И, похоже, так и произошло. Далее в анализе будут противопоставлены подделанные оценки мероприятия по нетворкингу и описывающие его слова, которые подделать забыли.
Для анализа слов нужно было количественно определить, что они выражают. Для этого было нанято три человека, которые не знали, что конкретно проверялось и которые независимо оценили общую позитивность/негативность словосочетаний каждого участника по шкале от 1 – крайне негативно до 7 – крайне позитивно. Эти оценки затем усреднялись, чтобы получить для каждого участника общий показатель позитивности/негативности их слов.
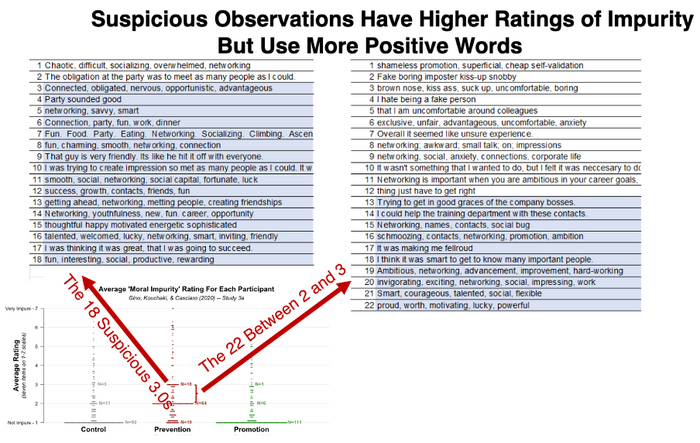
Посмотрим внимательнее на фальсификацию №1 – подозрительные 2,0 и 3,0 в условии предотвращения
Первое (и самое сильное) подозрение заключалось в том, что морально «нечистые» 2,0 и 3,0 в условии предотвращения исходно были 1,0, то есть совершенно «чистые». Если это правда и если их слова не были изменены, тогда мы должны увидеть, что слова, связанные с этими 2,0 и 3,0, слишком позитивны.
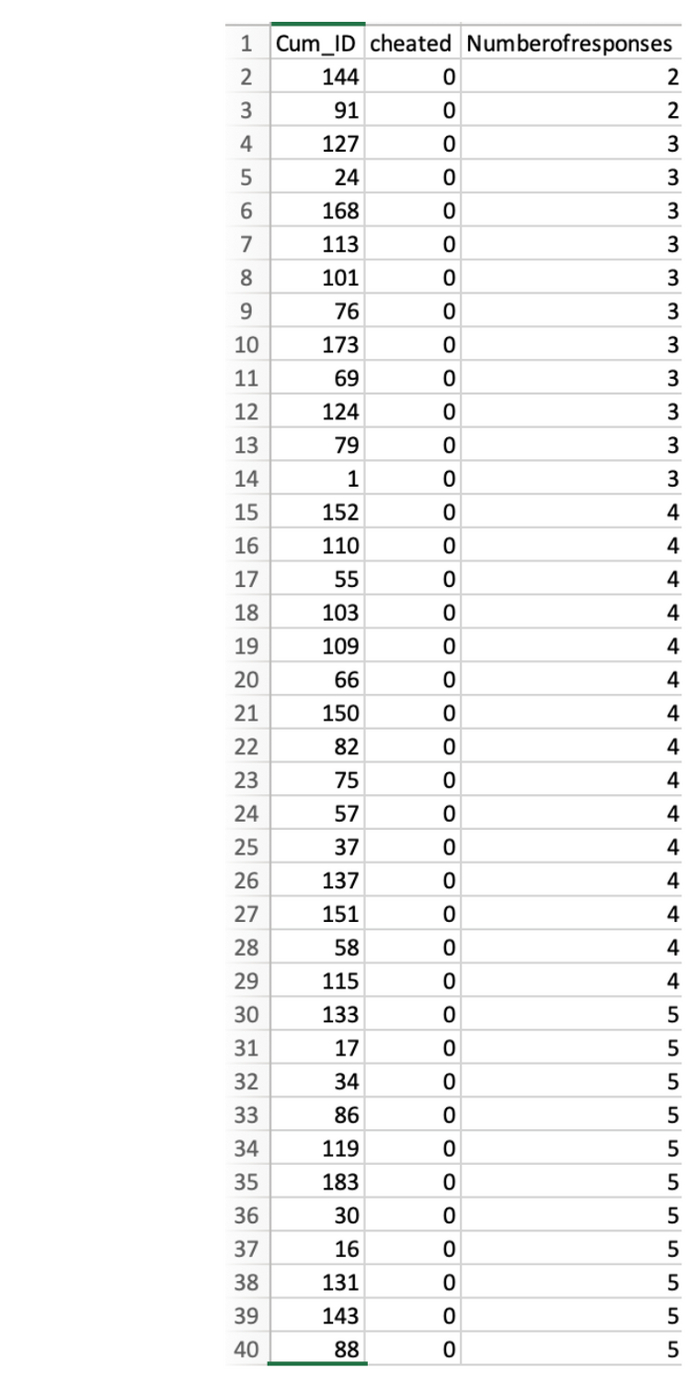
Чтобы убедиться, что это так, давайте сначала просто посмотрим на необработанные данные.
Строки на снимке отсортированы по степени положительности слов, так что самые отрицательные словосочетания находятся сверху. Синим цветом выделены получившие положительную оценку (выше среднего). Слева – предположительно подделанные 3,0, справа – предположительно настоящие оценки от 2,0 до 3,0.
Поскольку 3,0 по «нечистоте» выше, чем значения между 2,0 и 3,0 мы должны увидеть, что для 3,0 написали больше негативных вещей. Но вместо этого мы видим намного больше положительных. И это очень странно. Если только эти 3,0 исходно не были 1,0.
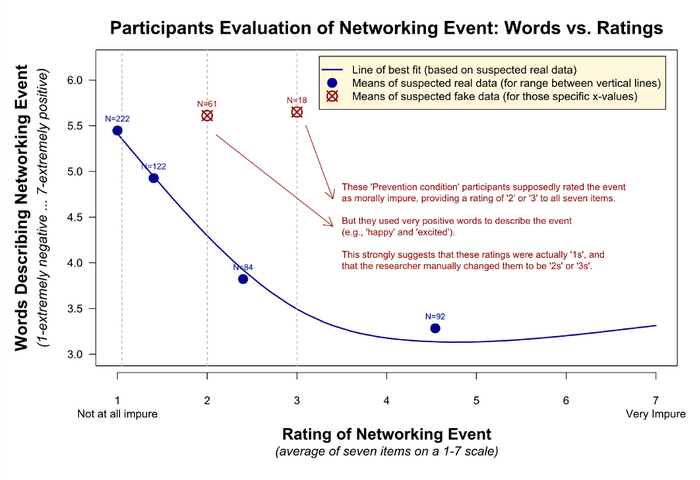
Попробуем проверить это подозрение количественным анализом.
По оси Y представлены оценки слов, которые написали участники и которые оценивали независимые эксперты (чем больше, тем позитивнее), а по оси X – те количественные оценки, которые поставили сами участники. Четыре синие точки на линии или рядом с ней представляют средний рейтинг слов для участников, которые дали оценки моральной нечистоты 1,0; от 1,0 до 2,0; от 2,0 до 3,0; и выше 3,0. И все они логичны.
Но обратите внимание на красные точки, которые обозначают средний рейтинг, связанный слов со «всеми 2» и «всеми 3» в условии предотвращения. Они не имеют смысла, так как ассоциируются со слишком позитивными словами. Действительно, они так же положительны, как и «все 1» в остальной части набора данных. Это дополнительное свидетельство того, что эти «все 2» и «все 3» раньше были «всеми 1».
Теперь перейдем к фальсификации № 2: подозрительные 1,0 в условии продвижения.
Второе (и более слабое) подозрение заключалось в том, что некоторые рейтинги высокой моральной нечистоты в условии продвижения были изменены на 1,0.
Чтобы проверить это, Data Colada внимательнее изучили подгруппу участников, которых они условно назвали «любители нетворкинга». Это участники, которые поставили «1» по всем семи пунктам моральной нечистоты (и, таким образом, не нашли ничего нечистого в нетворкинге), а также поставили «7» четырем последующим пунктам, которые оценивали, насколько вероятно, что они добровольно будут участвовать в нетворкинге в следующем месяце (то есть предельно вероятно).
Эти «любители нетворкинга» были максимально позитивно настроены в отношении нетворкинга по всем доступным им шкалам оценки. И поэтому логично ожидать, что они напишут положительные отзывы о мероприятии. Но если некоторые из этих 1,0 были подделаны и в реальности оценили нетворкинг плохо, то некоторые из этих «любителей нетворкинга» должны были бы использовать довольно негативные слова для описания сети.
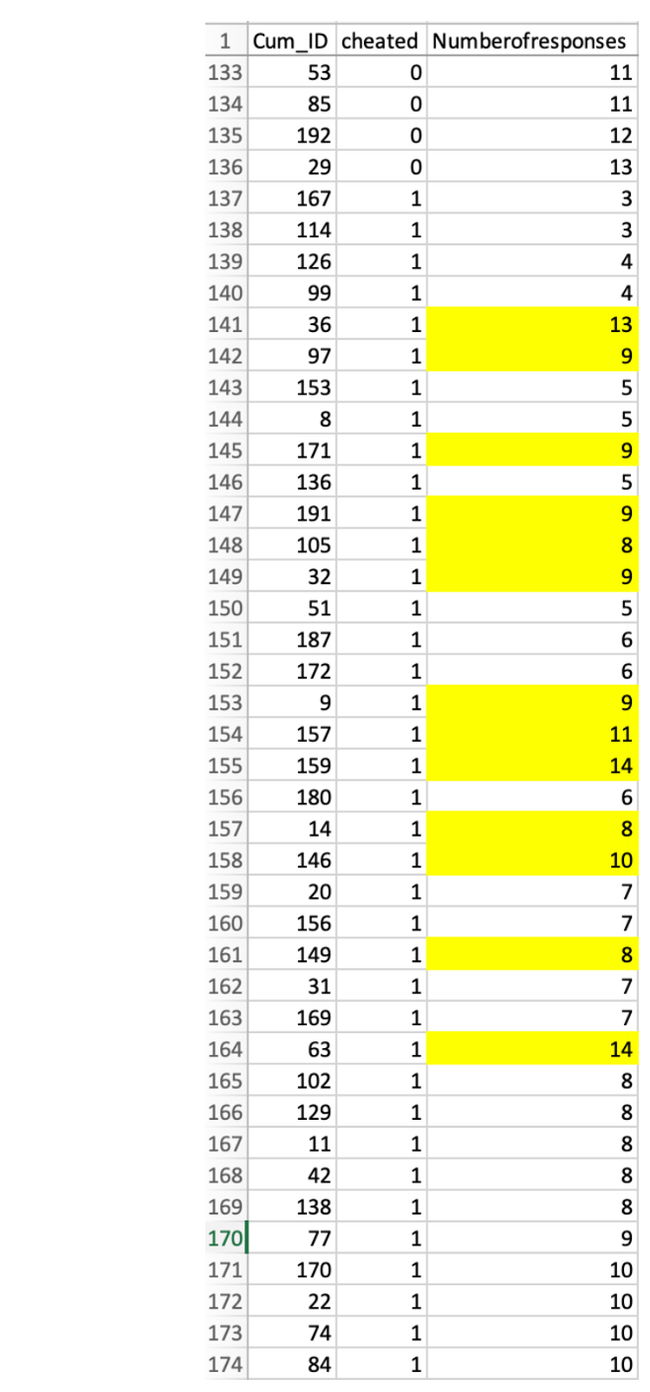
В условии продвижения было 38 «любителей нетворкинга» (слева), а в контрольном условии и условии предотвращения – 22 (справа). На рисунке ниже показаны 15 «любителей нетворкинга» в каждой из этих двух групп, которые написали больше всего негативных слов. Каждое словосочетание, получившее отрицательную оценку (ниже средней точки шкалы), выделено красным.
В наблюдениях, которые предположительно не подделывались (условия контроля и предотвращения – справа), только один из 22 «любителей нетворкинга» написал о нем негативные слова, и то, что он написал, было лишь слегка негативным (на 3,3 из 7). Однако в наборе наблюдений, которые предположительно включают фальсифицированные данные (условие продвижения), 8 из 38 написали отрицательные отзывы о нетворкинге, и во многих случаях эти слова были очень негативными.
С одной стороны, таких людей довольно мало, и только на основании этого анализа однозначных выводов сделать нельзя. С другой стороны, должно быть очень немного любителей нетворкинга, пишущих о нем негативные вещи, не говоря уже о целых 8 в одном условии.
Это принимается как косвенное доказательство того, что некоторые из этих 1,0 в условии продвижения раньше имели более высокие оценки моральной нечистоты.
Что, если мы просто проанализируем слова?
Если подозрения в фальсификации оценок верны, то эффект авторов должен исчезнуть при простом анализе слов. И он уходит.
Даже не просто уходит – он почему-то переворачивается. Люди использовали больше положительных слов для описания мероприятия по нетворкингу в условии предотвращения (M = 5,14, SD = 1,67), чем в условии продвижения (M = 4,74, SD = 1,92), что может означать, что фокус на продвижении вреден для самопрезентации.
Неизвестно, почему это так. Возможно, это случайность, поскольку значимость (p-value) не особо впечатляет. Возможно, данные были сфальсифицированы как-то еще. Или на самом деле верна гипотеза, противоположная той, что выдвинули авторы. Какой бы ни была причина, такой результат является дополнительным доказательством того, что данные были cфальсифицированы.
«Мы получили подтверждение извне Гарварда, что сотрудники Гарварда просмотрели исходный файл данных Qualtrics и что данные действительно были изменены».
Если честно, само исследование Джино какое-то дурацкое, но было интересно прочитать про еще один способ раскрытия фальсификаций.