Все мы видели, как нейросети рисуют крокодило бомбардино и балерин-капучино. Но я хочу рассказать, как нейросеть помогла с реальным бизнес процессом.
Это история о том, как я написал полноценную CRM-систему с помощью ChatGPT, работая обычным менеджером по работе с заказчиками.
Пример творчества нейросетей.
Я решил поделиться своим опытом использования нейросети в рабочих процессах в действующей компании.
Возможно, кому-то это будет полезно, и побудит что-нибудь эдакое сварганить и для себя.
До недавнего времени, я работал в организации, которая поставляла инженерные материалы для новостроек в СПБ и Лен Области.
Мы поставляли как материалы собственного производства, так и являлись дистрибутором нескольких крупных производителей.
И так как мы являлись не единственным дистрибутором и толкались на рынке еще с парой тройкой десятков таких же дистрибуторов - существовала специальная процедура, позволяющая получить преимущество относительно других дистрибуторов при продаже продукции (по цене)
Процедура эта называлась крепление объекта.
По сути на, спец ресурсе производиля / в лс ответственному менеджеру / по почте нужно оставить заявку, доказывающую, что на данном объекте ты работаешь больше лучше и активнее чем твои коллеги, после чего ты получал преимущество по цене.
Проблема
После моего прихода в данную компанию, оказалось что какого либо контроля/статистики по данному процессу не ведется, многие крепления "теряются", многие объекты упускаются.
Ситуация усугублялась тем, что крепление отправляется не только по объекту, но и по подрядчикам. А у одного менеджера могло быть по 20 штук этих самых подрядчиков, и ситуация когда про кого-то забывали, теряли - была не редкой.
Я пробовал вести в экселе статистику по объектам и креплениям, но по ходу наполнения информацией я понял что в перспективе это неудобно, неэффективно.
Что же делать?
Идея
Т.к я достаточно активно в своей повседневной жизни юзаю chat GPT, и писал с его помощью много различного софта для своего личного пользования, я решил что вполне возможно с его помощью создать узконаправленную CRM систему, которая поможет в ежедневной работе и контроле данных.
Ниже пример экранного переводчика/помощника который я делал для себя, под игру GW2
Реализация
Первое, что нужно было сделать - прописать максимально подробное ТЗ, в котором описать свой финальный результат.
Я описал нейросети скелет приложения, как я его вижу, какой стек хочу использовать, прописал правила форматирования текста (чтобы код был читаемым для дальнейшей доработки), правила организации кода, модульность маршруты, завёл чейнжлог, инициировал репозиторий в гитхабе и начал работу по вечерам, после смен. Тратил времени относительно немного, 8-9 часов в неделю.
И вот спустя 2-3 недели разработки, 300+ пушей в гитхаб, и неисчислимого количество багфиксов, появилось оно - моё первое полностью рабочее веб приложение, которое я потащил в директорат на согласование.
Ниже прикладываю скрины и описание функционала (ДИСКЛЕЙМЕР, чувствительных данных нет, вся информация "тестовая", сгенерированная, никаких данных компании я не раскрываю)
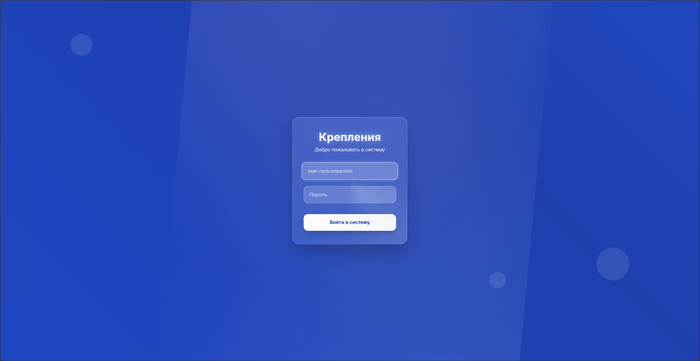
Страница авторизации встречает простым лаконичным логин/пароль. Есть защита от брутфорса. Так же интегрирована гугловская капча. Кнопки регистрации/сброса пароля нет, т.к количество пользователей не превышало 15 человек - всех заводил вручную.
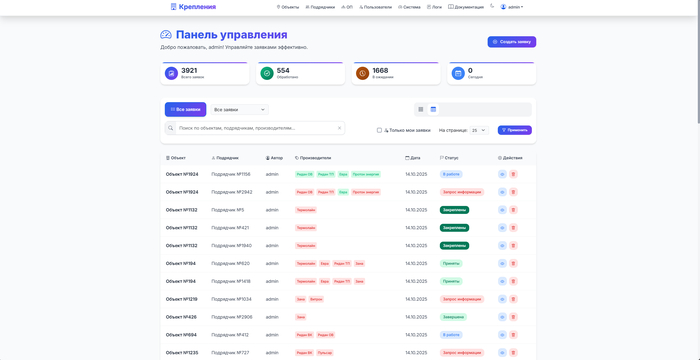
Главная страница (от лица администратора, у юзера меньше кнопок в навбаре). Тут можно увидеть текущие заявки, их статус/автора/дату размещения. Реализована система поиска и пагинация.
Несмотря на то, что в бд приличное кол-во записей, веб приложение достаточно шустро работает на таком скромном железе. (учитывая кол-во пользователей Big data тут и нее пахнет :) )
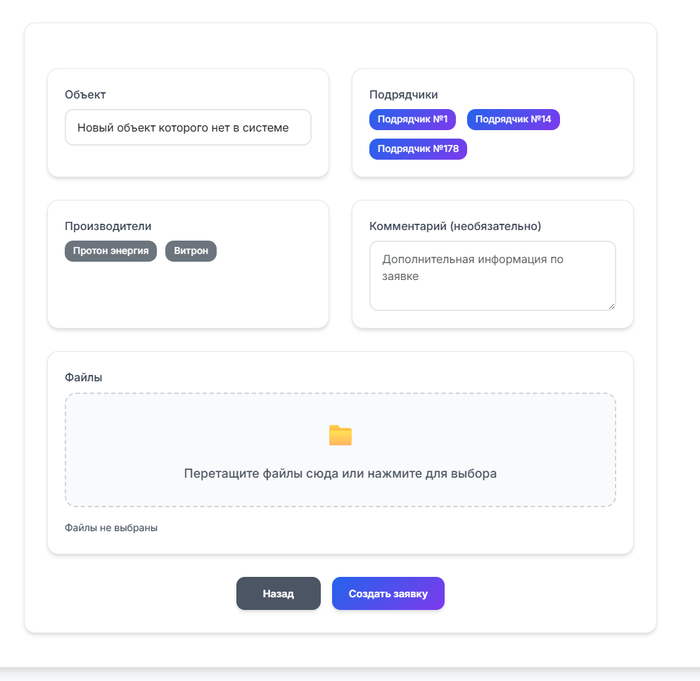
Так как всю информацию по закреплению объектов вел один человек - необходимо было сделать так, чтобы менеджер создавая заявку мог это сделать максимально просто и интуитивно.
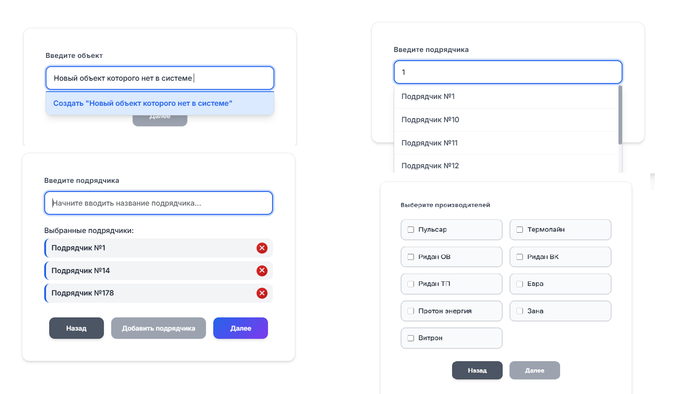
Мастер заведения новых заявок мой отдельный источник головной боли, но в результате справился и с ним.
Первый шаг - предлагает нам выбрать объект. Начинаем вводить название/номер и срабатывает автодополнение подсказывая варианты. Если такого объекта нет в системе предлагается его добавить.
Второй шаг предлагает выбрать подрядчика/подрядчиков.
Третий шаг отметить производителей, по которым мы хотим отправить заявки на крепление
И финальный шаг предлагает проверить введённую информацию, добавить комментарии, при необходимости и загрузить документацию.
Шаги первый второй и третий, везде есть автодополнение которое ищет в бд "на лету" то что мы вводим.
Финальное окошко в котором мы подтверждаем информацию
Я считаю, что получилось достаточно просто и интуитивно, UX/UI не пострадал ;)
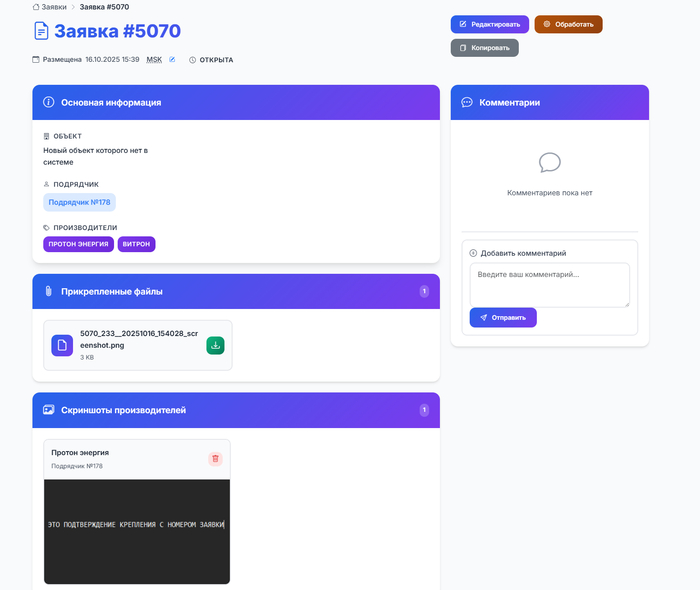
Окно просмотра заявки получилось тоже достаточно простым, мы видим заявку, её статус/переписку (комментарии), и скриншоты подтверждающие отправку/подтверждение крепления. Так же если к заявке прикреплены файлы они тоже отображаются и доступны для скачивания.
По результатам отслеживание креплений стало значительно проще.
Исчезли ситуации с потерей данных, забытыми подрядчиками, усилился контроль за бизнес процессом.
В компании работу приняли, используют.
Мне даже заплатили небольшую премию, было приятно.
Т.к когда я уволился мы никаких NDA/лицензионных договоров не подписывали, считаю что могу свободно распоряжаться данным ПО и приглашаю всех желающих зайти посмотреть что получилось.
https://gerbesh.ru/ (развернул на домене который был в наличии, не покупать же новый ради демки)
авторизация доступна по кнопке "демо вход"
ВЫВОД
Что хотелось бы сказать.
Я считаю, что это невероятно круто, что любой пользователь с нулевым/околонулевым знанием языков программирования может написать для себя/для работы проект, позволяющий сделать жизнь/работу лучше и легче.
Не мемами едиными, выходит :)
Искренне благодарю всех, кто дочитал до конца. Чукча не писатель, но ради вас старался.
Готов подробно ответить на все вопросы в комментариях, ежели таковые будут.
Привет! Я совсем новичок, но хотела бы обучиться програмированию на пайтоне, может вы можете подсказать, пожалуйста, какие-то хорошие курсы? База у меня есть, умею работать с функциями, но не хватает практики и углубленного изучения. Не знаю, важно ли это, но пишу в Visual Studio Code, т.к там удобнее.
Преобразование файлов PDF в формат Excel необходимо для анализа данных, создания отчетов и автоматизации рабочих процессов. Python предоставляет несколько библиотек, которые позволяют выполнить эту задачу эффективно. В этой статье мы рассмотрим два подхода с использованием бесплатных Python API:
Преобразование всей страницы или документа PDF в Excel
Извлечение таблиц из PDF и экспорт в Excel
Мы сравним эти методы, чтобы помочь вам выбрать оптимальное решение для ваших задач.
Установка необходимых библиотек
Для начала установите следующие библиотеки:
Free Spire.PDF for Python — бесплатная, но мощная библиотека для работы с PDF, включая конвертацию PDF в Excel и извлечение таблиц.
openpyxl — популярная библиотека с открытым исходным кодом для чтения, записи и редактирования файлов Excel.
✅ Сохраняет макет PDF (позицию текста, изображения, форматирование). ✅ Хорошо подходит для документов со сложным оформлением. ❌ Возможны слияния ячеек или изменение размеров строк и столбцов. ❌ Текст может быть разбит по нескольким ячейкам.
Метод 2. Извлечение таблиц из PDF и экспорт в Excel
Этот метод извлекает только табличные данные из PDF и экспортирует их в Excel, обеспечивая чистую и структурированную таблицу.
✅ Извлекает только табличные данные в структурированном виде. ✅ Таблицы в Excel выглядят аккуратно (без слияния ячеек и проблем с форматированием). ❌ Не сохраняет нетабличный контент (изображения, свободный текст и т. д.). ❌ Требует чётко определённых таблиц в PDF для корректного извлечения.
Итог
Используйте «Преобразование всей страницы», если нужно сохранить оригинальное оформление PDF, включая изображения и текст (например, для юридических или форматированных документов).
Используйте «Извлечение таблиц», если вам нужны только структурированные табличные данные в чистом Excel (например, для анализа данных).
Оба метода имеют свои преимущества — выбирайте тот, который лучше подходит для вашего проекта. Удачных конверсий!
Короче, заколебался читать новости про искусственный интеллект. Открываешь статью — а там: "Мультимодальная трансформерная архитектура с механизмом внимания обеспечивает... бла-бла-бла". Бро, я просто хотел узнать, что нового в ChatGPT!
Решил запилить свой Telegram-канал "Пельмени на завтрак", где переводю всю эту AI-муть на человеческий. С приколами и понятными аналогиями.
Как это работает?
Каждое утро в 9:00 — свежая порция AI-новостей. На чтение уходит 2 минуты, пока ты жрёшь завтрак.
Вот реальные примеры:
Было (техно-бред): > "Компания интегрировала Parlant и Streamlit для создания интерфейса передачи запросов от AI-агентов операторам call-центра"
Стало (по-человечески): > 🤝 Как AI-агент страхования учится передавать дела человеку > > Представь, твой виртуальный помощник по страхованию вдруг запутался и не знает, что делать. Теперь он может передать дело живому человеку! Это как если бы твой робот-бариста звал тебя, когда не знает, как сделать латте. > > Зачем это тебе? Скоро даже страховые компании смогут быстро решать твои проблемы 😄
Было: > "OpenAI выпустила AgentKit — платформу для создания, тестирования и деплоя AI-агентов с визуальным конструктором"
Стало: > 🎨 OpenAI сделала конструктор для AI-агентов > > Представь, что ты собираешь LEGO: берёшь детали, соединяешь их и получаешь своего цифрового помощника. Это как конструктор, только для AI! > > В бета-версии можно перетаскивать элементы и настраивать сложные штуки. Скоро каждый сможет создать своего AI-помощника без программирования.
Было: > "На Dev Day Sam Altman представил приложения, работающие нативно в окне ChatGPT"
Стало: > 💻 OpenAI хочет сделать ChatGPT твоей операционной системой будущего > > Представь, что ты общаешься с другом, а он ещё и решает твои задачи. Это как если бы твой гостер вдруг начал готовить завтрак сам! 🔍 > > Сэм Альтман на конференции показал приложения, которые работают прямо в окне чата. Может, скоро увидим новый браузер для ChatGPT? 🤔
Почему "Пельмени на завтрак"?
Потому что:
Быстро — как варить пельмени (2 минуты на пост)
Сытно — никакой воды, только мясо фактов
Понятно — без изысков и технобреда
Для всех — не надо быть программистом
Для кого это?
Если ты:
Слышал про ChatGPT, но не шаришь в деталях
Работаешь с AI-инструментами, но устал от технического жаргона
Просто любопытный и хочешь быть в теме
Заебался читать статьи, где половина слов на английском
То это твой канал!
Что уже есть?
142 подписчика за короткое время
Посты каждый день без пропусков
Реальные новости: OpenAI, Google, Anthropic и другие
Меня зовут Михаил Шардин. Я летел в Москву из Перми с одной простой задачей — провести мастер‑класс по Python для трейдеров. Но вместо лекции я попал в закрытый клуб. В эпицентр российского HFT‑трейдинга, где прибыль измеряют в миллисекундах, а убытки от одной ошибки в коде — в десятках тысяч рублей за три секунды. То, что я там увидел, меня поразило. Делюсь своим взглядом изнутри — не как спикер, а как исследователь. К тому же я не связан с организаторами и делюсь исключительно личными впечатлениями.
Мой полёт
Дорожные парадоксы
Перелёт из Перми в Москву оказался сам по себе отдельным приключением.
Сдача багажа
Пока выбирал билеты, наткнулся на любопытный парадокс: самые дешёвые варианты — это вылет в шесть утра и обратка в полночь. Цена приятная, но расплата — бессонная ночь и борьба со сном весь следующий день. Даже если доплатить за раннее заселение в отеле, часть «выгоды» тут же сгорает. Дневной рейс, как у меня, стоит примерно в два раза дороже, зато сохраняешь здоровье и силы. По сути, деньги уходят в любом случае — вопрос лишь в том, платишь ли их авиакомпании или своему организму.
Булка в самолете Аэрофлота
Сама дорога прошла спокойно: два часа в воздухе, и в «Аэрофлоте» традиционный набор — сэндвич с индейкой на тостовой булке, яблоко и маленькая шоколадка. Еда простая, но с ощущением заботы — создаёт иллюзию, что ты уже в рабочем ритме. После прилёта ушло ещё полтора часа, чтобы добраться до отеля. И тут формат оказался идеальным: Holiday Inn Сокольники объединяет и конференц‑залы, и проживание. Не нужно метаться по городу — всё в одном месте. Удобство, которое особенно ценишь, когда приехал не отдыхать, а работать и учиться.
Атмосфера и организация
Табличка в зал
С самого начала поразила сама обстановка. Мероприятие не было большим, но ощущалось, что собрался сильный состав. Организаторы признались: спрос оказался выше, чем они ожидали, поэтому все места быстро заняли. Это сразу дало понять — тема востребована, а попасть сюда получилось не у каждого.
И публика это подтверждала. В зале не было случайных людей. Казалось что каждый участник пришёл с деловым интересом. Атмосфера была рабочей, без лишнего официоза — словно встреча практиков, которые знают цену времени и информации. Я быстро понял, что попал в круг тех, кто живёт этим делом каждый день.
Зал Арбат
Разбор докладов
Основная часть конференции — доклады, и каждый из них стал отдельным взглядом на арбитраж. Первым выступил Рамиз Курбанов, сооснователь «Викинга». Его тема «Basket Arbitrage» была о том, как превратить трейдерскую интуицию в чёткий алгоритм. Он показал, что арбитраж — это не только спот против фьючерса, но и поиск дисбалансов внутри целой корзины инструментов.
Дальше слово взял я с докладом «Арбитраж начинается с данных». Мой акцент был на источниках котировок: официальные API, брокеры, скрытые «шахты» и веб‑парсинг. Я поделился приёмами, как находить собирать данные там, где кажется, что их нет, и как превращать это в рабочий инструмент для поиска неэффективностей.
Затем выступили практики: Сергей Усанов рассказал о системном отборе стратегий, Евгений Кнышов — о ловушках терминалов при подсчёте прибыли, Дмитрий Власов — о рисках, а Глеб Карпов завершил секцию разбором живых кейсов с Мосбиржи.
Рамиз Курбанов: «Basket Arbitrage - как формализовать интуицию трейдера»
Рамиз Курбанов
Первым выступал сооснователь «Викинга» Рамиз Курбанов, и его доклад задал тон всему мероприятию. Он сразу сместил фокус с классического понимания арбитража на более широкую концепцию. По его мнению, арбитраж — это не просто поиск расхождения между фьючерсом и спотом, а работа с «внутренней структурой цены» и дисбалансом между любыми связанными инструментами.
Ключевая мысль Рамиза, которая меня зацепила: самая сложная задача для алготрейдера — это формализовать то, что он видит глазами. Мы смотрим на график и интуитивно понимаем: «вот здесь цена оторвалась от группы, это явный прокол, надо покупать». Но как объяснить это роботу? Как превратить «прокол» в четкую математическую инструкцию?
Именно эту задачу Рамиз и решал на примере своей стратегии Basket Arbitrage. Он показал, как группа из девяти скоррелированных крипто‑инструментов движется в общем канале, но периодически один из них аномально отклоняется. Чтобы поймать это отклонение, он предложил пошаговый алгоритм:
Создание синтетического индекса. Вместо того чтобы сравнивать каждый инструмент с каждым, создается единый взвешенный индекс, который выступает в роли «справедливой цены» для всей корзины. Это та самая «вторая нога» арбитражной пары, только расчетная.
Нормализация данных. Цены всех инструментов и индекса приводятся к единой оси относительно нуля. Вместо хаотичных графиков мы получаем наглядную картину, где видно, какой инструмент стал «лидером», а какой — «аутсайдером».
Формула входа. Вход в сделку происходит, когда относительное изменение одного из инструментов по отношению к индексу превышает некое пороговое значение. Проще говоря, робот покупает самый «отставший» инструмент и (опционально) продает самый «убежавший».
Отдельно Рамиз затронул философский вопрос: хеджироваться или нет? С одной стороны, хедж делает эквити более гладким и защищает от системного движения всего рынка. С другой — он съедает значительную часть прибыли за счет комиссий, проскальзываний и спреда по второй ноге. Особенно ярко это проявляется при торговле индексным арбитражем с большой корзиной.
В ходе ответов на вопросы выяснилось, что его главный критерий риска в этой стратегии — время. Он готов «сидеть на шпагате», если ноги разъехались, но не дольше определенного лимита (в его примере — полчаса). Если за это время цена не вернулась, позиция закрывается, потому что скользящее окно расчета уже «подтянулось» к новым реалиям, и сигнал исчез. Это был очень честный и глубокий доклад о превращении трейдерского чутья в работающий код.
Михаил Шардин: «Арбитраж начинается с данных» - мое выступление
Я, Михаил Шардин
Поскольку следующим спикером был я, позволю себе кратко изложить суть своего доклада. Моя тема была посвящена самому фундаменту любой алгоритмической стратегии — данным. Я предложил аудитории посмотреть на данные как на золото, а на способы их получения — как на разные типы месторождений.
«Официальные рудники» (API бирж): Это самые чистые и надежные данные, но часто с бюрократией в виде сложной документации и платного доступа к самым ценным источникам.
«Надежные поставщики» (API брокеров): Финам, АЛОР, Тинькофф — здесь все проще, есть документация и «песочницы». Главный плюс — единое окно для получения данных и отправки приказов.
«Заброшенные шахты» (скрытые API): Мой любимый тип. Сервисы вроде Yahoo Finance или Investing.com когда‑то имели официальный API, но закрыли его. Однако данные до сих пор можно получать через внутренние запросы, которые использует сам сайт. Это похоже на шпионский квест: нужно притвориться браузером, получить специальные ключи (cookies, crumbs), и тогда «шахта» снова начнет выдавать золото.
«Золото на поверхности» (веб‑парсинг): Когда данные есть на сайте, но нет никакого API. Приходится «просеивать» HTML‑код страницы. Это гибко, но крайне ненадежно — любая смена верстки на сайте ломает ваш скрипт.
Михаил Шардин
Чтобы это не было голой теорией, я показал несколько практических кейсов на Python. Например, как с помощью простого локального сервера на Python можно в реальном времени транслировать данные из стакана (которые нельзя бесплатно получить через API Мосбиржи) прямо в Excel.
Также я поделился скриптом, который обходит защиту от ботов на сайтах вроде Investing.com, используя специальные библиотеки, меняя user‑agent и эмулируя поведение человека.
Основная мысль моего выступления: ключ к успеху — в комбинировании источников. Где‑то проще и надежнее взять официальные данные, а для поиска уникальных неэффективностей придется лезть в «заброшенные шахты». Главное — делать это этично, только для личных исследовательских целей и осознавать все риски.
Сергей Усанов: «Выбор арбитражной стратегии» - системный подход практика
Сергей Усанов
Сергей Усанов, главный разработчик Live Investing, владелец ROBOT‑QLUA, представил доклад, который идеально ложился в канву мероприятия: от теории к практике. Он поделился кейсом, как подошел к задаче создать консервативную торговую стратегию с доходностью «ставка + 5%» и околонулевыми рисками.
Его подход — это системный отбор и анализ. Он не пытается найти «грааль», а методично просеивает известные типы арбитража:
Классика: Спот‑фьючерс.
Парный трейдинг: Акция против акции (например, обычка/преф) или фьючерс против фьючерса (календарные спреды).
Индексный арбитраж.
Чтобы не выбирать «на глазок», Сергей написал собственный скринер на шарпе, который прогоняет исторические данные по сотням пар и рассчитывает ключевые метрики. Он наглядно показал, как это работает на примере пары «Полюс Золото» (акция vs фьючерс). Скринер строит график раздвижки, вычитает из него «справедливую» цену (рассчитанную по безрисковой ставке), и уже для этого итогового графика отклонений ищет точки входа.
Что важно, он очень трезво подходит к бэктестам. Сергей подчеркнул, что тест на минутных свечах всегда будет излишне оптимистичным, так как цена закрытия свечи — это не реальные бид/аск в стакане. Чтобы приблизить тест к реальности, он берет в качестве сигналов на вход не пиковые отклонения, а среднее арифметическое всех отклонений за вычетом комиссии. Это очень здравый подход, который отсекает иллюзии.
Центральное место в его анализе занимает тест Йохансена на коинтеграцию. В отличие от простой корреляции, которая лишь показывает, что активы движутся в одном направлении, коинтеграция говорит о том, что между ними есть долгосрочная устойчивая связь, и раздвижка будет стремиться к своему среднему значению. Его скринер автоматически рассчитывает этот тест для пар, отбирая только статистически значимые. Интересно, что иногда тест проходит даже для, казалось бы, не связанных фундаментально бумаг (как в примере «Сургутнефтегаз» против «МКБ»), что подтверждает тезис о том, что математический подход может находить неочевидные связи.
В итоге, проанализировав все варианты, для поставленной задачи он отобрал портфель, где 85% занимает самый консервативный спот‑фьючерс, а оставшиеся 15% — более рискованные, но и потенциально более доходные календарные и статистические пары. Это был образцовый пример инженерного подхода к созданию торговой системы.
Евгений Кнышов: «Аналитика доходности» - почему ваш терминал может вам врать
Евгений Кнышов
Доклад Евгения Кнышова поднял проблему, о которой многие даже не задумываются: финансовый результат (финрез), который вы видите в своем торговом роботе, может сильно отличаться от реального результата в отчете брокера.
Евгений — практикующий высокочастотник, и он столкнулся с этим на собственном опыте, торгуя арбитраж фьючерс‑акция через платформу «Викинг». Он наглядно продемонстрировал эксперимент: два абсолютно одинаковых портфеля, торгующих одну и ту же пару, за две недели показали кардинально разный финрез: -21 000 ₽ в одном и +32 000 ₽ в другом. Разница была лишь в одной настройке, отвечающей за «искусственное проскальзывание».
Копнув глубже, он выяснил причину. Оказывается, для достижения максимальной скорости HFT‑платформа может работать с фактом выставления заявки, а не с фактом ее реального исполнения по конкретной цене. Когда вы отправляете большой объем в неликвидный стакан, робот может рассчитать цену входа, исходя из глубины стакана (Order Book), и сразу же отправить хеджирующую заявку, не дожидаясь ответа от биржи о том, по какой именно цене исполнилась первая нога. В итоге в логах финреза оказывается расчетная цена, а реальная цена исполнения (например, по лучшему биду/аску, если исполнилась лишь малая часть заявки) может быть совсем другой. Разница, как показал Евгений на примере, может достигать 10-15%.
Какой выход? Евгений и его коллеги‑энтузиасты разработали собственную систему аналитики. Их схема гениальна в своей простоте:
С помощью коннектора (в их случае — к терминалу «АЛОР Трейд») они в реальном времени собирают реальные данные о сделках от брокера.
Все сделки сохраняются в локальную базу данных (SQLite).
Специальный скрипт на Python с библиотекой Pandas обрабатывает эту базу, корректно сопоставляет сделки по ногам в арбитражные пары и считает фактический, а не предполагаемый финансовый результат.
Этот доклад — яркий пример того, что в HFT дьявол кроется в деталях. Скорость — это не только преимущество, но и компромисс. И для серьезной работы необходимо строить внешние системы верификации, которые будут сверять показатели робота с «землей» — отчетом брокера. Рамиз Курбанов позже подтвердил, что это действительно осознанное архитектурное решение в «Викинге» ради минимизации задержек (roundtrip).
Дмитрий Власов: «Контроль рисков» - как не дать роботу сжечь ваш депозит за 3 секунды
Дмитрий Власов
Дмитрий Власов, эксперт с 20-летним опытом, посвятил свой доклад самой важной теме в алгоритмической торговле — контролю рисков. Причем не тех рисков, что заложены в логику стратегии, а технических и операционных, которые могут возникнуть из‑за сбоя биржи, ошибки в коде или просто человеческой невнимательности.
Дмитрий поделился двумя поучительными историями из своей практики. Первая — из далекого прошлого, когда после сбоя биржа прислала в его самописного робота поток всех сделок с начала дня. Робот, не ожидавший такого, честно отработал каждую, захеджировав их по уже неактуальным ценам и принеся серьезный убыток. Вывод: всегда нужно ставить фильтры на время приходящих данных.
Вторая история случилась совсем недавно уже на платформе «Викинг». Дмитрий автоматизировал расчет уровней входа (LimSell) и выхода (LimBuy) через внешние формулы на C++. LimSell у него подтягивался автоматически, а LimBuy нужно было корректировать вручную. В один из дней трейдер забыл это сделать. В итоге LimSell подполз слишком близко к LimBuy, расстояние между ними стало меньше комиссии на круг. Результат — робот за 3 секунды совершил 3000+ сделок в обе стороны, генерируя убыток на каждой и «слив» 20 000 рублей на одном контракте.
Эти случаи привели его к созданию комплексной системы автоматического контроля рисков, реализованной прямо внутри «Викинга» через те самые формулы на C++. Он использует одно поле (Extra field 1) для логики стратегии, а второе (Extra field 2) — исключительно для проверок безопасности. Его система в реальном времени отслеживает:
Слишком маленький спред: Если разница между ценой продажи и покупки меньше комиссии, торговля по портфелю немедленно останавливается.
Аномальное количество сделок: Если число сделок превышает расчетный максимум (зависящий от размера позиции), торговля блокируется.
Превышение лимита просадки: Дмитрий реализовал кастомный расчет финреза внутри дня. Если просадка по открытой позиции достигает, например, 10 000 рублей, робот отключается.
Превышение лимита на капитал: Система контролирует общий объем открытых позиций в деньгах и останавливает торговлю, если он выходит за установленные рамки.
Особо Дмитрий отметил, что для написания таких формул сегодня не нужно быть гуру C++. Современные нейросети (он рекомендовал китайскую Qwen и Perplexity для анализа новостей) отлично справляются с переводом бизнес‑логики на язык кода, если им предоставить документацию и примеры.
Его выступление — это настоящий мастер‑класс по построению эшелонированной обороны для защиты своего капитала.
Глеб Карпов: «Неэффективности Мосбиржи» - охота на крупных игроков в стакане
Если предыдущие спикеры говорили о полной или частичной автоматизации, то Глеб — представитель «ручного» скальпинга и арбитража, где главное оружие — это глаза трейдера и его умение читать стакан.
Глеб Карпов
Его основной инструмент — это не графики, а вертикальный статический стакан (из привода вроде CScalp), где видно плотности, принты сделок и, самое главное, действия крупных участников. Весь его доклад был построен на разборе конкретных кейсов, где один‑единственный крупный игрок создавал аномальные и очень прибыльные неэффективности.
Самый яркий пример — ситуация с календарным спредом на юань в сентябре прошлого года. Глеб заметил, что на протяжении нескольких контрактов подряд за 2–3 недели до экспирации в стакане появлялся участник, который начинал агрессивно давить спред вниз огромными заявками‑айсбергами («айсами»). Большинство участников, торгующих по «классике», пытались его контрить, покупая спред в расчете на возврат к справедливой цене, и теряли деньги. Глеб же, наблюдая за этим из раза в раз, начал торговать вместе с этим участником, шортя спред и забирая по 20–30 пунктов движения в день.
Эта ситуация привела к каскадному эффекту. Из‑за давления на фьючерс юаня возникла огромная (до 8-9%!) раздвижка между фьючерсом на доллар и фьючерсом на юань. Те, кто зашортил этот спред на пике, не видя стакана, получили колоссальные убытки. А те, кто, как Глеб, видел, что в стаканах появились аналогичные «айсы», но уже в другую сторону, смогли зайти в сделку на схождение и не только заработать на самом арбитраже, но и получать двойной положительный фандинг.
Ключевая мысль Глеба: никакая полная автоматизация не сможет повторить то, что делает трейдер, который видит и интерпретирует действия конкретного крупного игрока. Робот может быть лишь исполнителем — он поможет войти в сделку по лучшей цене и без проскальзывания, но решение о входе и выходе принимает человек. По его словам, такой полуручной подход позволяет получать доходности в сотни процентов годовых (он упомянул 568% в 2024 году, но не предоставил доказательств), в то время как полностью автоматизированные стратегии часто «бьются» за доходность в 30-50% годовых. Это был очень отрезвляющий взгляд на рынок, который напомнил, что за всеми графиками и цифрами всегда стоят живые люди и их капиталы.
Сила сообщества. Нетворкинг и общение
Самое интересное на таких встречах часто происходит не только на сцене, но и в кулуарах. Перерывы между докладами превращались в отдельную ценность: люди знакомились, обменивались идеями, обсуждали свежие подходы и делились практическими кейсами, которые не попадают в официальные слайды. Я тоже активно общался с участниками, обсуждал их стратегии и делился своими наработками — именно в этих живых разговорах появляются неожиданные инсайты.
Мое фото с Рамизом Курбановым
Такие контакты — это настоящее золото, которое невозможно скачать из интернета или прочитать в статье. Я ушёл с ощущением, что подобные мероприятия формируют не только знания, но и сообщество. Здесь рождаются новые идеи, проекты и, возможно, будущие коллаборации.
Мое фото с Дмитрием Власовым
Кстати, уже в следующем месяце я снова прилетаю в Москву — 25 октября на конференцию Smart‑Lab Conf 2025. Мое выступление состоится в зале № 7 («Спекуляции») в 12:00. Буду рад видеть всех, кто интересуется автоматизацией и новыми подходами к работе с финансовыми данными. До встречи!
Заключение: что я понял, побывав в сердце HFT
Я возвращаюсь из Москвы с четким пониманием нескольких вещей:
HFT — это не магия, а инженерия. Современный алготрейдинг — это сугубо инженерная дисциплина. В ее основе лежат математические модели, скорость исполнения и надежность инфраструктуры, а не поиск секретных индикаторов.
Сообщество решает сложнейшие задачи. Уровень дискуссий показал, насколько зрелым стало российское алго‑сообщество. Здесь строят собственные системы верификации сделок и пишут сложный код для контроля рисков на уровне микросекунд. Погружение в эту среду — мощный толчок для развития.
И самое отрезвляющее: порог входа. Мир HFT — это не только мир высоких технологий, но и высоких капиталов. Чтобы конкурировать здесь всерьез, нужен стартовый капитал минимум 30–50 миллионов рублей. Эти деньги идут на разработку, инфраструктуру (включая размещение серверов в дата‑центре биржи) и, собственно, на сам торговый депозит. Это игра не для всех, и важно понимать это с самого начала.
(Это НЕ установочный файл. Это ссылка на мою страницу в Github, чтобы Вы могли скопировать код. Пикабу автоматически удаляет пробелы в коде, из-за чего код не работает)
(Это НЕ установочный файл. Это ссылка на мою страницу в Github, чтобы Вы могли скопировать код. Пикабу автоматически удаляет пробелы в коде, из-за чего код не работает)