(Это НЕ установочный файл. Это ссылка на мою страницу в Github, чтобы Вы могли скопировать код. Пикабу автоматически удаляет пробелы в коде, из-за чего код не работает)
Несколько недель назад я опубликовал статью о том, как превратить обычный диктофон в инструмент для расшифровки речи с помощью OpenAI Whisper. Идея была создать бесплатную и приватную систему ИИ диктофона, которая избавляет от необходимости переслушивать аудиозаписи лекций или выступлений. Тогда статья нашла своего читателя, собрав 16К просмотров и 120 закладок.
ИИ и обычные диктофоны
В процессе настройки я боролся с несовместимостью библиотек, подбирал нужные версии драйверов и вручную собирал рабочее окружение. В комментариях мне справедливо заметили: «Вместо всей этой возни можно было найти готовый Docker-контейнер и поднять всё одной командой». Звучало логично, и я с энтузиазмом принял этот совет. Я ведь верю людям в интернете.
Новая идея - не просто расшифровывать речь, а разделять её по голосам - как на совещании или встрече. Это называется диаризацией, и для неё существует продвинутая версия - WhisperX. Цель была проста - получить на выходе не сплошное полотно текста, а готовый протокол встречи, где понятно, кто и что сказал. Казалось, с Docker это будет легко.
Но я заблуждался. Путь «в одну команду» оказался полон сюрпризов - всё сыпалось одно за другим: то скрипт не видел мои файлы, то не мог получить к ним доступ, то просто зависал без объяснения причин. Внутри этой «волшебной упаковки» царил хаос, и мне приходилось разбираться, почему она не хочет работать.
Но когда я всё починил и заставил систему работать, результат превзошёл мои ожидания. Новейшая модель large-v3 в связке с диаризацией выдала не просто текст, а структурированный диалог.
Это был настолько лучший результат, что я смог передать его большой языковой модели (LLM) и получить глубокий анализ одной очень важной для меня личной ситуации - под таким углом, о котором я сам бы никогда не задумался.
Именно в этот момент мой скепсис в отношении «умных ИИ-диктофонов», которые я критиковал в первой статье, сильно пошатнулся. Скорее всего их сила не в тотальной записи, а в возможности превращать хаос в структурированные данные, готовые для анализа.
В этой статье я хочу поделиться своим опытом прохождения этого квеста, показать, как обойти все скрытые сложности, и дать вам готовые инструкции, чтобы вы тоже могли превращать свои записи в осмысленные диалоги.
В комментариях меня критиковали за то, что я опять написал статью про Linux. Да, у меня на домашнем компьютере стоит Ubuntu в режиме двойной загрузки - и многим непонятно, почему я не сделал всё под Windows. Ответ прост: для задач с нейросетями Linux даёт меньше неожиданностей и больше контроля. Драйверы, контейнеры, права доступа - под Linux их проще исследовать и чинить, особенно когда начинаешь ковырять CUDA и системные зависимости.
Ещё меня критиковали за RTX 5060 Ti 16GB - мол, не у всех такие видеокарты. Согласен, это не смартфон в кармане. Но для работы с большими моделями и диаризацией нужна мощь GPU: я использую её как инструмент. К тому же подходы, которые я описываю, работают и на более скромных конфигурациях - просто медленнее.
А теперь начнём с самого начала - что такое Docker простыми словами? Представьте, что вместо того, чтобы настраивать компьютер под каждую программу, вы берёте готовую «коробку» и в ней уже есть всё: нужные версии Python, библиотеки, утилиты. Эта «коробка» запускается одинаково на любой машине - как виртуальная мини-кухня.
То есть мой план действий был такой:
Установить Docker.
Скачать готовый образ с WhisperX.
Запустить одну команду и получить готовый протокол встречи.
Так что могло пойти не так?
Первое столкновение с реальностью
Уже на первом шаге начались сюрпризы:
Секретный токен, который не дошёл до адресата
Чтобы запустить диаризацию, WhisperX использует модели от pyannote, а они требуют авторизации через токен Hugging Face. Я передал его как переменную окружения Docker (-e HF_TOKEN=...), будучи уверенным, что этого достаточно. Но утилита внутри контейнера ожидала его совсем в другом виде - аргументом командной строки (--hf_token). В итоге модель упорно отказывалась работать, и я долго не понимал, где ошибка.
Война за права доступа
Следующая засада - PermissionError при попытке записи в системные папки /.cache. Контейнер как гость в доме: ему разрешили пользоваться кухонным столом, а он пошёл сверлить стены в гостиной. Разумеется, система его остановила. Решение оказалось простым - создать отдельную «полку» для кеша (~/.whisperx) и явно указать путь.
Загадочное зависание
Запускаешь скрипт - и тишина. Ни ошибок, ни логов, будто процесс замёрз. На деле работа шла, просто механизм вывода в контейнере «затыкался». Решение - добавить индикатор прогресса.
Так что Docker - не магия, а всего лишь ещё один инструмент, который тоже нужно приручить.
Решение: два скрипта
Я написал две утилиты - один раз подготовить систему, второй - управлять обработкой. Это простая, надёжная пара: установщик устраняет системные «подводные камни», оркестратор - закрывает все проблемы запуска (HF-token, кэш, права, прогресс).
Назначение: однократно подготовить Ubuntu - поставить Docker, NVIDIA toolkit, скачать образ WhisperX, создать рабочие папки и общий кэш ~/whisperx. Что делает:
проверяет дистрибутив и наличие GPU (nvidia-smi);
устанавливает Docker и добавляет пользователя в группу docker;
ставит NVIDIA Container Toolkit и настраивает runtime;
Когда все технические баталии были позади, я наконец смог оценить, стоила ли игра свеч. Результат был отличный.
В первой статье обычный Whisper выдавал сплошное текстовое полотно. Информативно, но безжизненно. Вы не знали, где заканчивается мысль одного человека и начинается реплика другого.
Было (обычный Whisper):
...да, я согласен с этим подходом но нужно учесть риски которые мы не обсудили например финансовую сторону вопроса и как это повлияет на сроки я думаю нам стоит вернуться к этому на следующей неделе...
Стало (WhisperX с диаризацией):
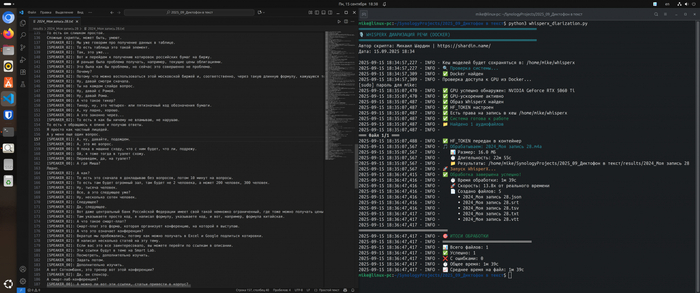
[00:01:15.520 --> 00:01:19.880] SPEAKER_01: Да, я согласен с этим подходом, но нужно учесть риски, которые мы не обсудили. [00:01:20.100 --> 00:01:22.740] SPEAKER_02: Например, финансовую сторону вопроса и как это повлияет на сроки? [00:01:23.020 --> 00:01:25.900] SPEAKER_01: Именно. Я думаю, нам стоит вернуться к этому на следующей неделе.
WhisperX с диаризацией превращает этот монолит в сценарий пьесы. Каждый спикер получает свой идентификатор, а его реплики - точные временные метки. Разница колоссальная. Теперь это не просто расшифровка, а полноценный протокол.
Мой личный кейс
Но настоящая магия началась, когда я решил пойти дальше. Я взял расшифровку одного личного разговора, сохранённую в таком структурированном виде, и загрузил её в нейросеть бесплатную нейросеть от гугла Gemini 2.5 Pro с простым запросом: «Действуй как аналитик. Проанализируй этот диалог».
Именно из-за структуры Gemini смогла отследить, кто инициировал темы, кто чаще соглашался или перебивал, как менялась тональность и динамика беседы. В итоге я получил анализ скрытых паттернов в общении, о которых сам никогда бы не задумался. Это был взгляд на ситуацию с абсолютно неожиданной стороны, который помог мне лучше понять и себя, и собеседника.
Даже бесплатное приложение в телефоне может служить источником
Я понял, что их главная ценность «ИИ-диктофонов» - не в способности записывать каждый ваш шаг, а в умении превращать хаос человеческого общения в структурированные, машиночитаемые данные. Это открывает возможности: от создания кратких сводок по итогам встреч до глубокого анализа коммуникаций, который раньше был невозможен.
Заключение
В итоге путь от «просто используй Docker» к рабочей связке WhisperX показал очевидную вещь: контейнеры - удобный инструмент, но не магия.
Подготовка системы и правильная оркестровка запуска - это то, что превращает хаос в рабочий процесс. Если вы готовы потерпеть небольшие сложности ради удобства в дальнейшем - результат оправдает усилия: структурированные протоколы и возможность глубокого анализа бесед.
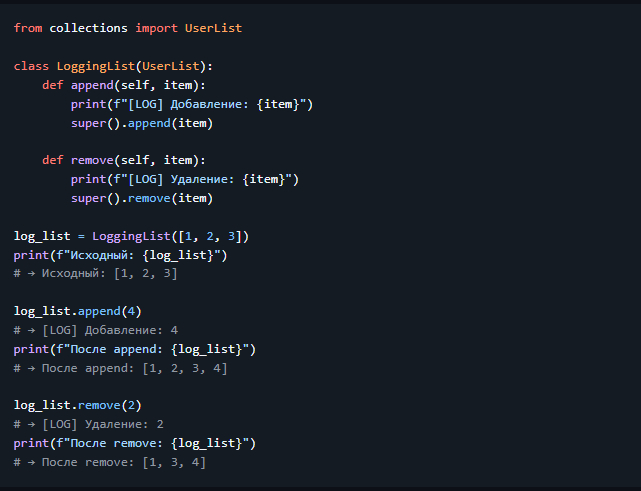
Наследуется от `collections.UserList`. Используется, чтобы создать список с переопределённым поведением.
> 💡 Полезен, когда нужно добавить логирование, валидацию, или изменить поведение стандартного списка.
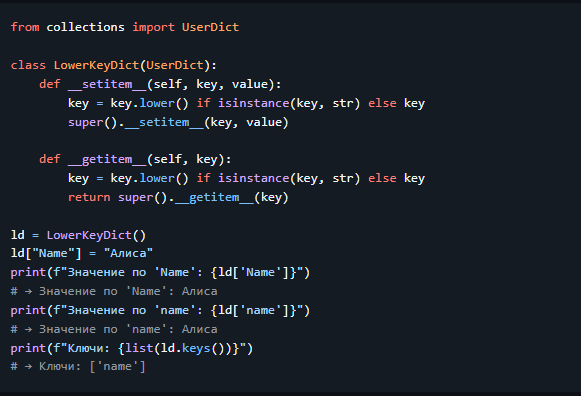
13. UserDict — кастомные словари
Наследуется от `collections.UserDict`. Используется, чтобы создать словарь с переопределённым поведением.
> 💡 Используется для создания словарей с нормализацией ключей, валидацией, логированием, кешированием и т.п.
---
Сравнение коллекций по памяти и скорости
Выбор коллекции влияет на производительность и потребление памяти. Ниже — практические замеры для типичных сценариев.
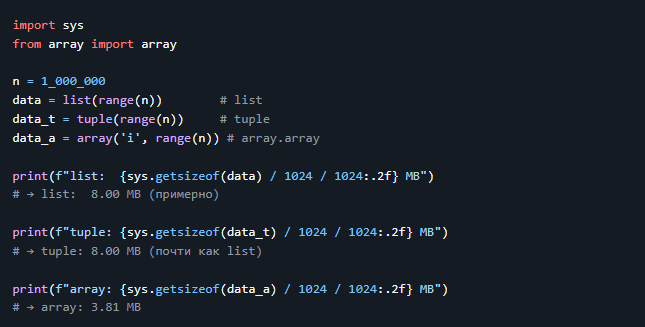
1. Память: `list` vs `tuple` vs `array.array`
Создадим коллекции из 1 000 000 целых чисел и сравним размер в памяти.
> 💡 Вывод: > - `array.array` экономит ~2x памяти для чисел. > - `list` и `tuple` потребляют примерно одинаково, но `tuple` немного быстрее при итерации.
---
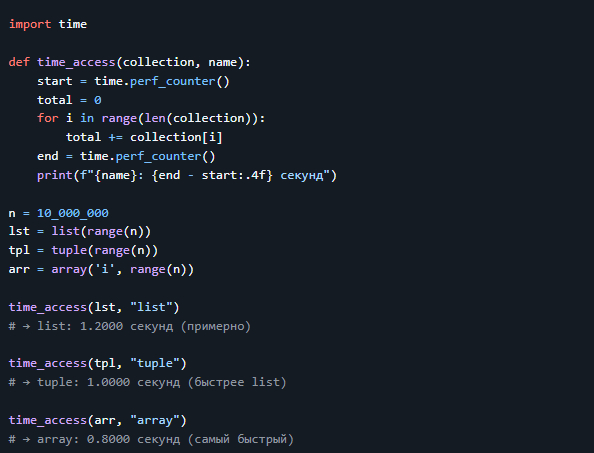
2. Скорость доступа: `list` vs `tuple` vs `array.array`
Замерим время доступа к каждому элементу в коллекции из 10 000 000 элементов.
> 💡 Вывод: > - `array.array` — самый быстрый для чисел. > - `tuple` быстрее `list` на 10–20%. > - Разница заметна на больших объёмах.
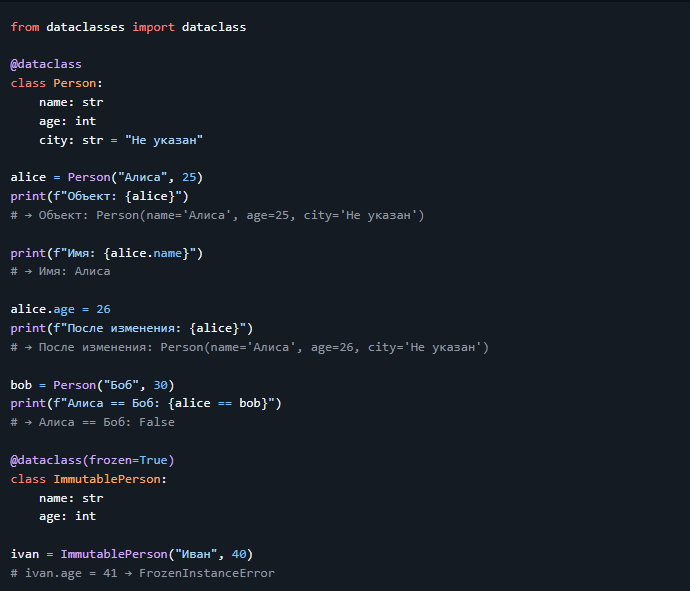
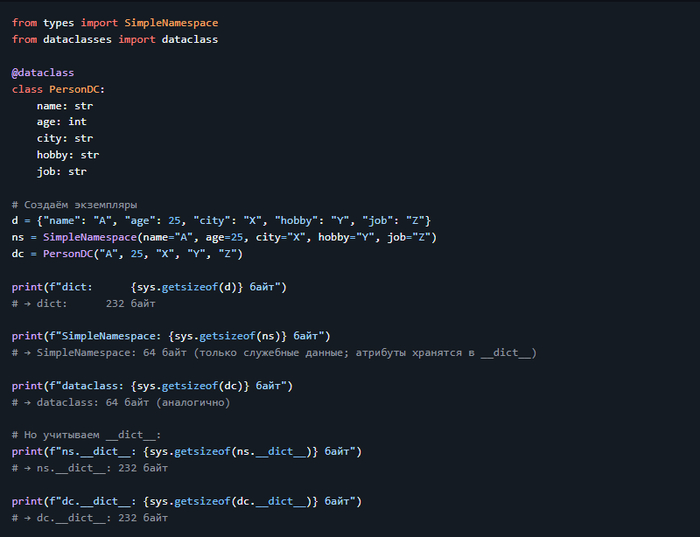
3. Память: `dict` vs `SimpleNamespace` vs `dataclass`
Создадим объекты с 5 полями и сравним размер.
> 💡 Вывод: > - `SimpleNamespace` и `dataclass` потребляют столько же памяти, сколько `dict`, потому что используют `__dict__`. > - Если нужна экономия — используйте `__slots__` (см. ниже).
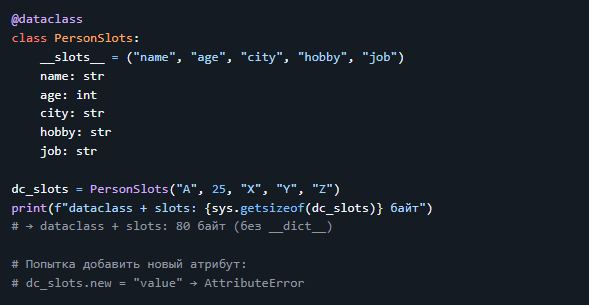
4. Экономия памяти: `dataclass` с `__slots__`
> 💡 Вывод: > - `__slots__` экономит память и ускоряет доступ к атрибутам. > - Цена — нельзя добавлять новые атрибуты динамически.
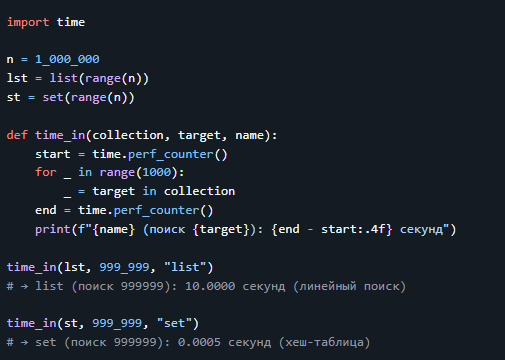
5. Скорость поиска: `list` vs `set`
Проверим, насколько быстрее `set` при проверке вхождения.
> 💡 Вывод:
> - `set` в тысячи раз быстрее `list` для проверки вхождения.
> - Всегда используй `set`, если нужно часто проверять `x in collection`.
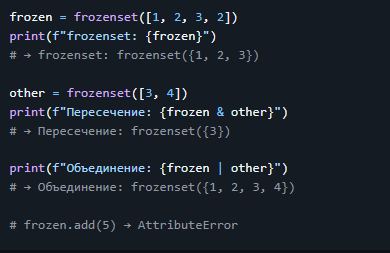
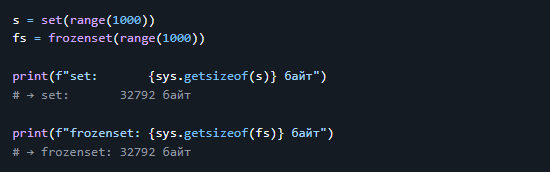
6. Память: `set` vs `frozenset`
> 💡 Вывод: > - `frozenset` и `set` потребляют одинаково. > - Разница только в изменяемости.
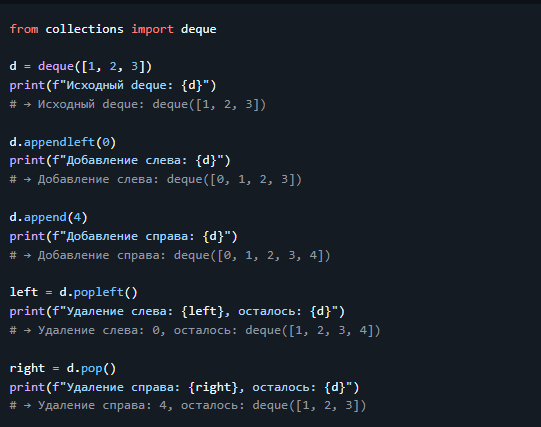
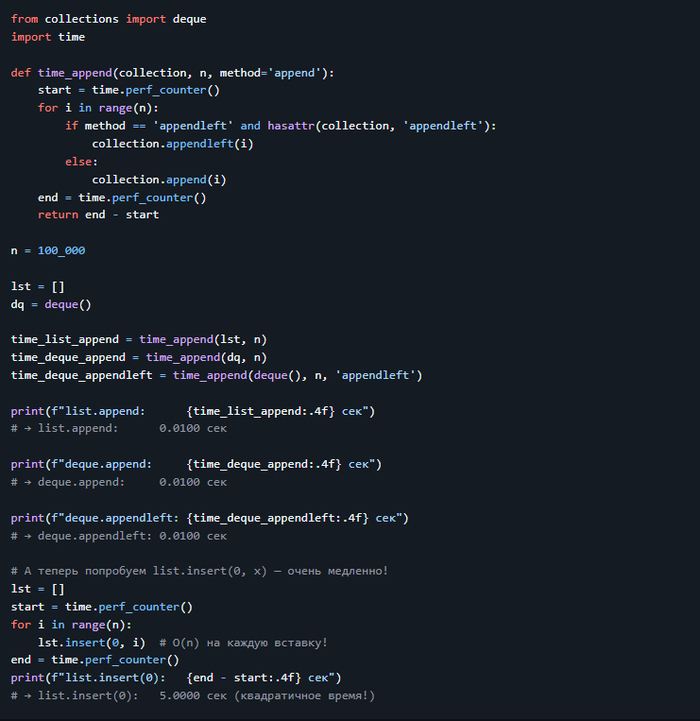
7. Скорость добавления: `list.append` vs `deque.append` vs `deque.appendleft`
> 💡 Вывод: > - `deque.appendleft` работает за O(1), в отличие от `list.insert(0)`, который O(n). > - Для частых операций на обоих концах — только `deque`.
---
Общие рекомендации по производительности
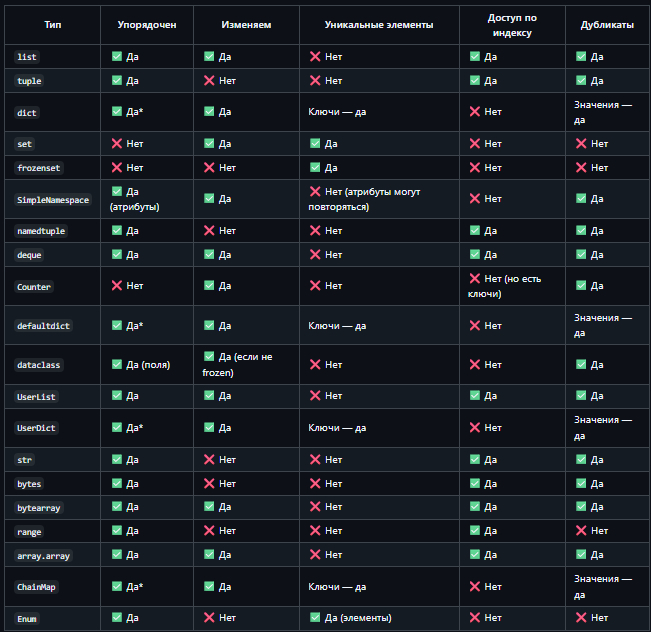
Сравнение коллекций
> * — с Python 3.7+ словари, `defaultdict`, `UserDict`, `ChainMap` сохраняют порядок вставки.
Дисклеймер. На пиакбу нет редактора кода поэтому картинки. Поскольку это шпаргалка с примерами то в этом посте допустимо.
Статья вышла большая, количество иллюстраций превышает предел, поэтому я разделил ее на две части.
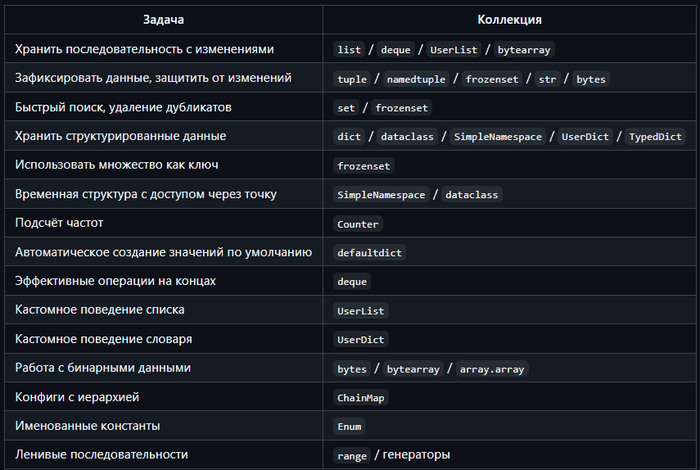
В Python коллекция — это объект, содержащий группу элементов и позволяющий с ними работать как с единым целым.
Коллекции обычно поддерживают:
- итерацию ( `for item in collection` )
- проверку вхождения ( `x in collection` )
- определение длины ( `len(collection)` )
- доступ по индексу или ключу (если упорядочены или ассоциативны)
> 💡 В Python нет строгого интерфейса «коллекция», но есть неформальные протоколы. Если объект поддерживает `__iter__`, `__len__`, `__contains__` — его можно считать коллекцией.
---
Что не является коллекцией
Следующие типы не считаются коллекциями, так как не содержат группы элементов:
- `int`, `float`, `bool` — скалярные значения
- `None` — отсутствие значения
- функции, модули, классы — это объекты, но не контейнеры данных (если только не содержат `__dict__`)
---
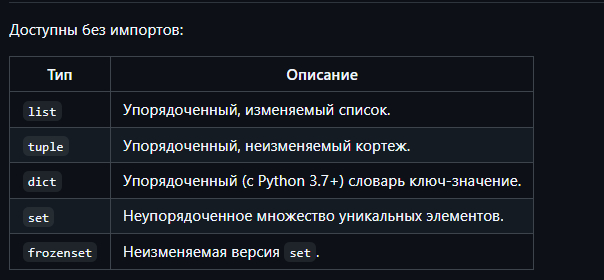
Основные встроенные коллекции
Доступны без импортов:
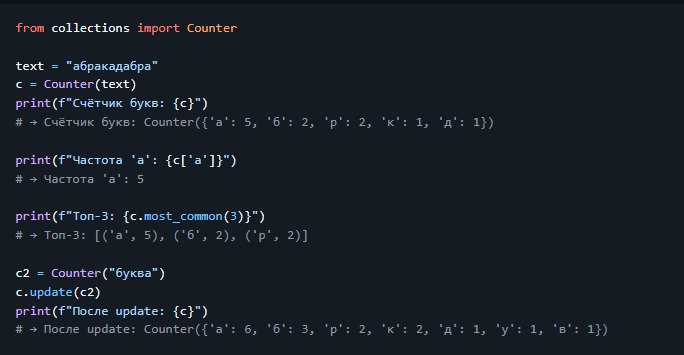
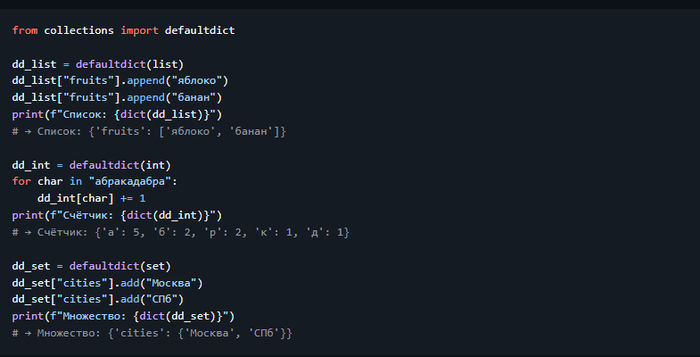
Расширенные коллекции из стандартной библиотеки
Другие коллекции и коллекционоподобные типы
Хотя не всегда называются «коллекциями» в бытовом смысле, эти типы тоже хранят или представляют группы данных.
1. `str` — строка
Неизменяемая упорядоченная коллекция символов.
2. `bytes`, `bytearray`
3. `range`
Ленивая упорядоченная последовательность чисел. Не хранит элементы в памяти.
4. `array.array`
Хранит однотипные числовые данные компактно (как в C).
5. Генераторы и итераторы
Не хранят данные — генерируют по запросу. Не поддерживают `len()` или индексацию.
6. `ChainMap` (из `collections`)
Объединяет несколько словарей в одну виртуальную коллекцию — поиск идёт по цепочке.
7. `OrderedDict` (из `collections`)
Словарь с гарантированным порядком вставки. Актуален для Python < 3.7.
8. `enum.Enum`, `enum.Flag`
Коллекции именованных констант.
9. `typing.NamedTuple`, `typing.TypedDict`
Типизированные обёртки над `namedtuple` и `dict`.
10. `heapq`, `bisect` — инструменты, а не коллекции
Работают с коллекциями, но сами коллекциями не являются:
- `heapq` — поддержка кучи через списки. - `bisect` — вставка в отсортированный список с сохранением порядка.
---
1. Списки — `list`
Упорядоченная, изменяемая коллекция. Элементы могут повторяться, типы — любые.
Применяется, когда нужна гибкая последовательность: добавление, удаление, изменение элементов.
Создание: `[]`
2. Словари — `dict`
Коллекция пар **ключ → значение**. Ключи должны быть хешируемыми. С Python 3.7 сохраняет порядок вставки.
Полезен для структурированных данных: профили, конфиги, JSON.
Создание: `{}`
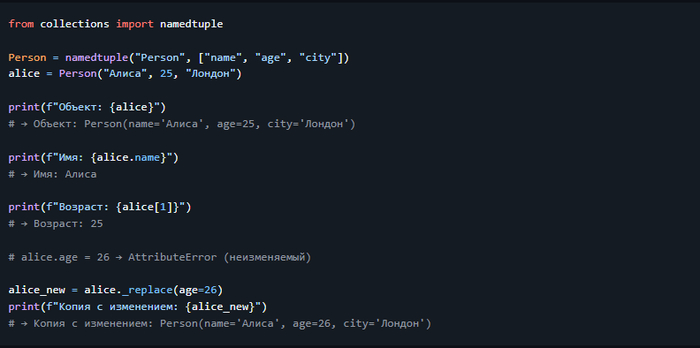
3. Кортежи — `tuple`
Упорядоченная, неизменяемая коллекция. Подходит для фиксированных данных.
Используется, когда важна неизменяемость: координаты, параметры, возвращаемые значения.
Создание: `()`
> 💡 Кортежи занимают меньше памяти и работают быстрее списков. Идеальны, когда изменяемость не нужна.
Работая с геоданными, я регулярно сталкиваюсь с одной и той же проблемой - обилие рутины. Форматы не совпадают, координаты «прыгают», отчёты приходится собирать вручную. Даже если речь идёт о небольшом проекте, половина времени уходит не на сам анализ, а на подготовку и приведение данных к нужному виду.
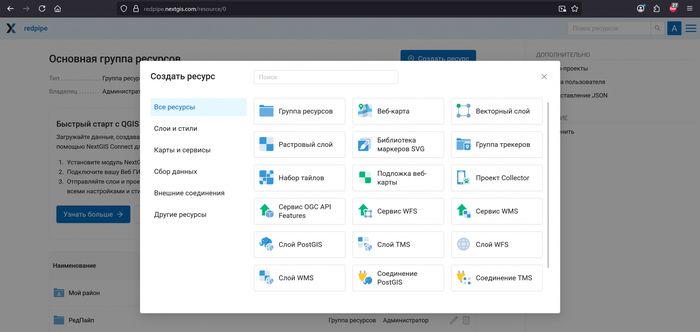
И хотя Python и open source-инструменты здорово помогают, есть задачи, где одной только «самодельной автоматизации» недостаточно. Когда данных становится слишком много, когда к ним нужно дать доступ коллегам или когда важно наладить единый процесс - тут уже нужен сервер, который позволит и хранить, и обрабатывать, и публиковать информацию в удобном виде. Недавно обнаружил для себя NextGIS Web.
Почему локальные инструменты не спасают
QGIS и Python - мои помощники, и я искренне люблю их за гибкость. Вручную править пару шейп-файлов или написать скрипт для одноразовой конвертации - это легко.
Но реальность большинства проектов другая: сотни файлов, регулярные партии данных от подрядчиков, ежедневные правки от полевых инженеров и требования выдавать отчёты руководству. В таких условиях «локальный» подход быстро превращается в набор костылей:
QGIS удобен для визуальной правки и разовых операций, но его рабочие процессы плохо масштабируются. Автоматизация в QGIS возможна, но требует настройки шаблонов, умений у каждого пользователя и постоянного контроля за версиями слоёв. Плюс - кто будет запускать эти операции по расписанию, если ноутбук у коллеги выключен или уходит в отпуск?
Отдельные Python-скрипты решают конкретные задачи: геокодирование, объединение атрибутов, очистка адресов. Но набор скриптов растёт, появляется технический долг - разные интерфейсы, разные форматы входных/выходных данных. Поддерживать такой набор в команде трудоёмко: нужно документировать, отлавливать ошибки, следить за зависимостями.
Библиотека GDAL для работы с геопространственными растровыми данными
Когда речь идёт о сотнях файлов и командной работе, появляются другие требования, которые «локалки» не закрывают: централизованное хранилище с историей изменений, управление правами доступа по ролям, веб-интерфейс для быстрого просмотра и простых правок, API для интеграции с учётными системами и планировщиком задач. Без этого процессы остаются фрагментированными: кто-то работает с копией, кто-то - с устаревшим слоем, отчёт собирают вручную, а синхронизация - через пересылку архивов по почте.
Нужен сервер, который объединит всё в единую платформу. Такой сервер должен предоставить интерфейс для быстрой публикации карт, механизмы кэширования для быстрой работы с растрами и векторами, и главное - программный интерфейс (API), через который можно запустить автоматические конвертации, обновления слоёв и экспорт отчётов по расписанию. Это позволяет перенести «рутинную» работу из головы инженеров в отлаженные пайплайны: раз написать - и забыть, пока не придут новые данные.
Именно здесь open source-инструменты (GDAL, PostGIS, OGR и Python-библиотеки) демонстрируют свою силу: они дают инструменты для преобразований и анализа, но им нужна надстройка - серверная платформа с API и правами доступа, чтобы автоматизация работала надёжно и в командном режиме.
NextGIS Web - это не просто «ещё один сервер», а слой, который снимает с команды часть организационной и технической рутины: база данных, удобный веб-интерфейс для просмотра и правок, и документированное API для интеграций. Сервер хранит слои и их историю, умеет публиковать WMS/WFS и поддерживает распространённые форматы (GeoTIFF, GeoPackage, Shapefile и т.п.), что делает его удобным связующим звеном между полевыми сборщиками, аналитиками и учётными системами.
База данных: под капотом типичный развёрнутый NextGIS Web держит пространственные данные в PostGIS и обеспечивает централизованный доступ к слоям, транзакциям и версии объектов. Это снимает классическую проблему «у кого последняя версия» - все правки фиксируются на сервере, а НЕ в локальных копиях у сотрудников.
Веб-интерфейс: наличие понятного веб-интерфейса означает, что не каждому сотруднику нужен QGIS и локальная установка: быстрый просмотр, поиск, табличная работа с атрибутами, базовые правки и печать макетов - всё это доступно прямо в браузере. Для команд это экономия времени и снижение порога ошибок при обмене данными. При этом NextGIS Web сохраняет гибкость стилизации слоёв и позволяет готовить карты для управления задачами и отчётности.
API и автоматизация: самое ценное - хорошо документированное API: загрузка данных, обновление слоёв, экспорт отчётов и вызов конверторов можно встроить в пайплайн и запускать по расписанию из CI/CD, cron или задачного планировщика. Это переводит повторяющиеся преобразования из «делай вручную» в «раз написал - забыл», что особенно критично при регулярных партиях данных от подрядчиков.
Кейс: загрузил один раз и команда работает. Представьте, вы получили партию шейп-файлов от подрядчика: загрузили на сервер, настроили стили и права - и вся команда сразу видит слои в едином интерфейсе. Полевая бригада правит объекты в браузере или в QGIS через подключение, аналитики берут актуальные данные для отчётов, а автоматический экспорт строит ежедневные CSV-отчёты. Синхронизация и контроль версий - уже не ваша головная боль.
NextGIS Web - открытое ПО с документированным кодом и инструкциями по установке, но это всё равно часть экосистемы. Однако если вы ищете лёгкую открытую альтернативу для выкладки тайлов и простых интеграций, обратите внимание на pg_tileserv - компактный tile-сервер для PostGIS.
Настройка прав, стилизация и публикация карт - это тот набор возможностей, который превращает набор скриптов и локальных QGIS-проектов в управляемую командную платформу: одни загружают данные, другие стилизуют, третьи - включают слои в веб-отчёты. В реальных проектах это экономит часы и снижает количество ошибок при подготовке данных.
Open source как продолжение NextGIS Web
Если NextGIS Web - это платформа-дирижёр для хранения и публикации геоданных, то богатая экосистема open source-инструментов - это её оркестр, исполняющий всю черновую работу. Именно связка серверного API и гибких скриптов на Python позволяет выстроить полноценный конвейер обработки данных, где ручные операции сведены к минимуму.
if resource['resource']['cls'] == 'vector_layer' or resource['resource']['cls'] == 'postgis_layer': features = requests.get(resource_url + '/feature/', auth = auth).json() for feature in features: print(feature)
Ключевую роль здесь играют проверенные библиотеки. Python + GDAL/OGR выступают универсальными «переводчиками»: они способны прочитать практически любой мыслимый формат (от Shapefile и GeoTIFF до экзотических CSV с координатами в текстовом виде), выполнить трансформацию систем координат и подготовить данные для загрузки в PostGIS, который находится под капотом у NextGIS Web. Библиотеки Fiona и Shapely работают на более тонком уровне: Fiona упрощает чтение и запись векторных данных, а Shapely позволяет проводить хирургические операции с геометрией - «лечить» некорректные полигоны, находить пересечения, объединять объекты и проверять их на валидность перед отправкой на сервер.
[Источник данных (FTP)] ↓ [Python-скрипт (GDAL/OGR)] ↓ [NextGIS Web API] ↓ ├── [Веб-карта для команды] ↓ └── [CSV-отчет руководству]
Имея такой инструментарий, мы можем писать скрипты для полной автоматизации рутинных задач. Например, скрипт, запускаемый по расписанию (через cron), может раз в час проверять FTP-папку, забирать оттуда новые данные от подрядчика, проверять их структуру, перепроецировать в нужную систему координат и через API обновлять соответствующий слой в NextGIS Web. Другой скрипт может ежедневно выгружать из Веб ГИС данные по определенным объектам, генерировать на их основе CSV-отчёт и отправлять его по почте руководству. Автоматизация стилизации - ещё один мощный приём: можно написать скрипт, который на основе атрибутов слоя (например, статуса объекта) генерирует готовый файл стилей в формате QML или SLD и загружает его на сервер. Это гарантирует, что все новые данные будут выглядеть единообразно, без необходимости ручной настройки.
Практический эффект
Внедрение связки из централизованной веб ГИС и автоматизированных скриптов даёт три ключевых преимущества, которые напрямую влияют на производительность и качество работы с геоданными.
Во-первых, резко сокращается объём рутины. Вместо того чтобы вручную конвертировать форматы, искать объекты на карте по кадастровому номеру или сводить данные в отчёты, инженеры получают готовые инструменты. Например, интеграция с 1С превращает кадастровый номер в карточке абонента в гиперссылку, которая сразу открывает нужный участок на карте со всей инфраструктурой. Это экономит минуты на каждой заявке, что в масштабах компании выливается в сэкономленные часы рабочего времени. Аналогично, автоматическая загрузка данных от подрядчиков избавляет от необходимости каждый раз «причёсывать» файлы вручную.
Во-вторых, данные всегда остаются актуальными и консистентными. Проблема «у кого последняя версия shape-файла» исчезает, поскольку сервер становится единым источником правды. Интеграция с системами реального времени, такими как SCADA для мониторинга оборудования или сервисами пожаров FIRMS, позволяет отображать на карте самую свежую информацию. Оператор диспетчерской службы или аналитик видят на карте актуальные статусы объектов или термоточки, обновляемые практически в реальном времени, что критически важно для принятия оперативных решений.
В-третьих, и это самое главное, инженеры начинают решать профильные задачи, а не копаться в форматах. Платформа берёт на себя технические сложности: надёжное хранение данных в PostgreSQL/Postgres Pro, интеграцию с корпоративными системами (1С, SCADA) и быструю доставку данных конечным пользователям, в том числе через современные форматы вроде векторных тайлов (MVT). Благодаря этому специалист по планированию сетей может сосредоточиться на поиске оптимального маршрута прокладки линии, а не на конвертации выписки из Росреестра. Освобождённое от рутины время и силы направляются на анализ, проектирование и принятие решений, то есть на ту работу, где человеческий опыт и знания действительно незаменимы.
Вывод
NextGIS Web даёт основу - централизованное хранилище, права доступа, веб-интерфейс и API для интеграции. Это «скелет» системы, который обеспечивает надёжность и управляемость. Open source-инструменты, в свою очередь, добавляют гибкость: Python-скрипты, GDAL/OGR, Shapely или Fiona позволяют строить автоматизацию под конкретные задачи.
В связке они превращают хаотичный набор локальных файлов и скриптов в управляемый процесс: сервер обеспечивает единый источник данных, а open source-пакеты берут на себя преобразования, геоаналитику и интеграцию. В итоге организация получает и готовый сервис «из коробки» для работы команды, и «конструктор», который можно адаптировать под уникальные бизнес-процессы.
Именно сочетание платформы и гибких инструментов делает автоматизацию геозадач устойчивой, расширяемой и экономящей время.