Шпаргалка: Неочевидные возможности f-строк, о которых вы могли не знать
Дисклеймер. В пикабу нет редактора кода, поэтому будут картинки, впрочем, в данном посте это не мешает восприятию.
F-строки в python — это современный и очень удобный способ встраивать значения переменных и выражения прямо в текст строки.
Чтобы создать f-строку, просто поставьте букву f перед открывающей кавычкой. Внутри строки вы можете вставлять переменные, обернув их в фигурные скобки {}. Python автоматически заменит {переменная} на её значение.
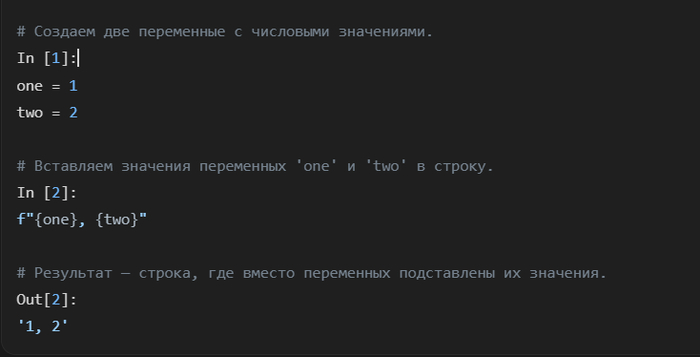
Сила f-строк в том, что в фигурные скобки можно помещать не просто переменные, а практически любое валидное выражение Python. Это позволяет выполнять вычисления "на лету", не создавая лишних переменных.
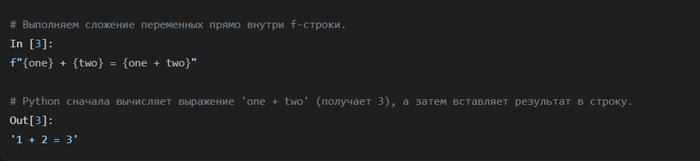
Вы можете легко обращаться к элементам структур данных, таких как словари (по ключу) и списки (по индексу), прямо из f-строки.
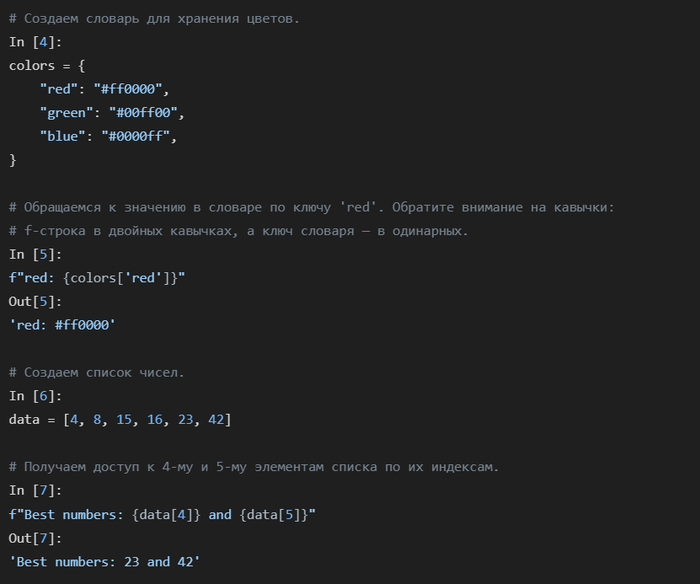
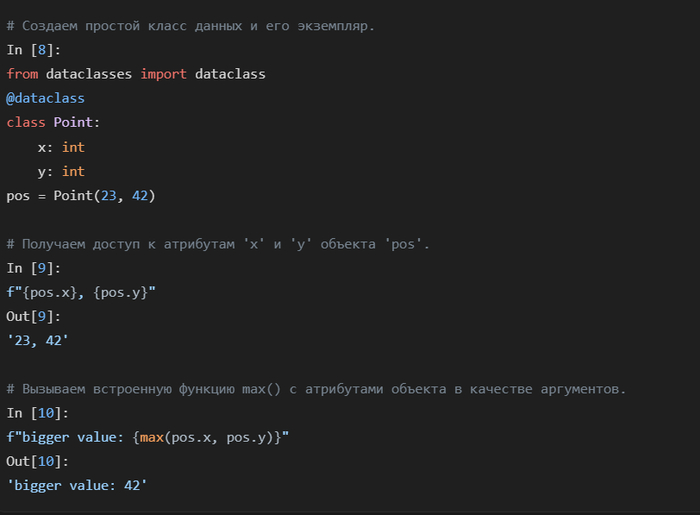
Точно так же можно обращаться к атрибутам объектов (через точку .) и даже вызывать функции.
Использование f-строк для отладки
Начиная с Python 3.8, в f-строках появился мощный инструмент для быстрой отладки.
Если после имени переменной в фигурных скобках поставить знак равенства (=), Python выведет не только значение переменной, но и её имя. Это невероятно удобно для быстрой проверки значений в коде.
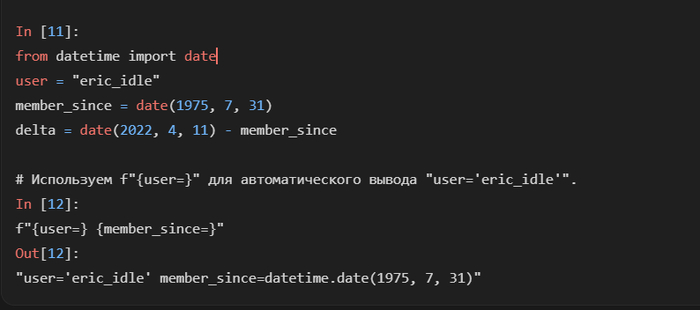
Отладочный спецификатор = можно комбинировать с обычными спецификаторами форматирования. Например, можно вывести имя переменной, а её значение отформатировать особым образом.
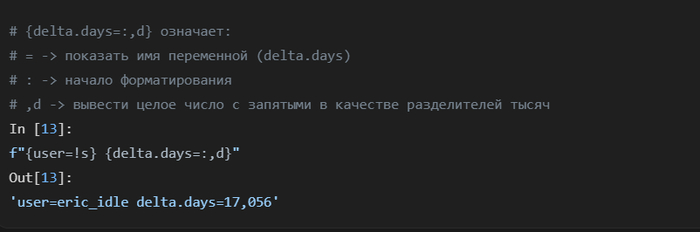
Знак = работает для целых выражений, что позволяет наглядно показать и само вычисление, и его результат.
Печать отладочного представления (repr)
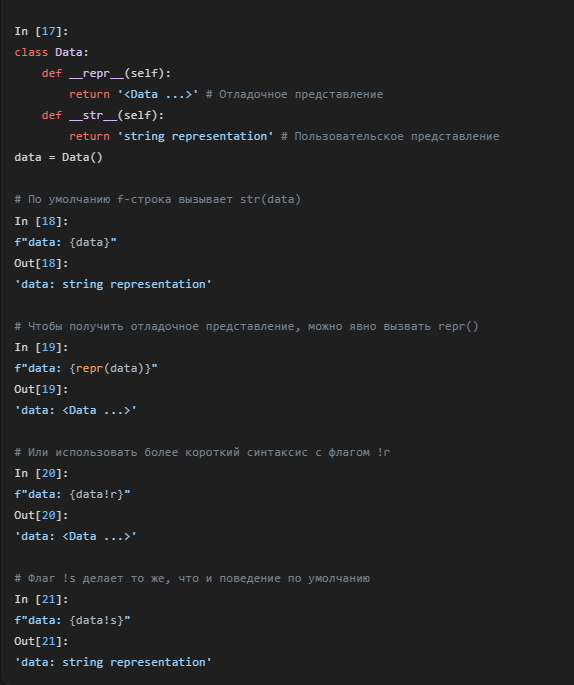
У объектов в Python есть два строковых представления: str() (для пользователей) и repr() (для разработчиков). По умолчанию f-строки используют str().
Чтобы управлять этим, можно использовать флаги !s (для str) и !r (для repr) прямо в f-строке. Это более короткий и удобный способ, чем вызывать функции str() или repr() вручную.
Дополнение, выравнивание и усечение
F-строки предоставляют полный контроль над форматированием вывода, включая ширину поля, выравнивание и заполнение.
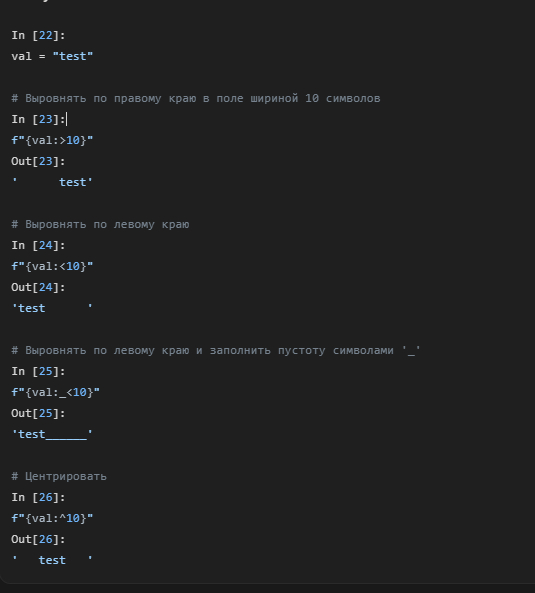
После переменной ставится двоеточие :, а затем спецификатор формата.
> — выравнивание по правому краю
< — выравнивание по левому краю
^ — центрирование
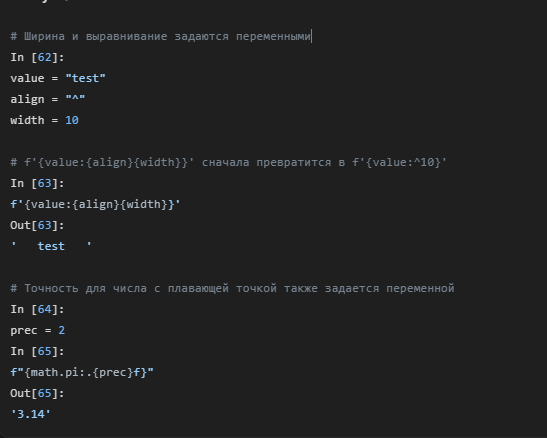
Число после символа выравнивания задает общую ширину поля.
Символ перед выравниванием задает, чем заполнять пустое место (по умолчанию — пробел)
Чтобы обрезать строку до определенной длины, используется синтаксис :.N, где N — максимальное количество символов.
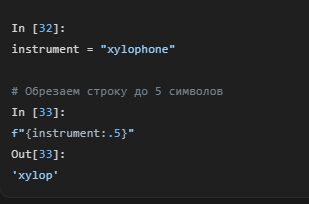
Числа и их представления
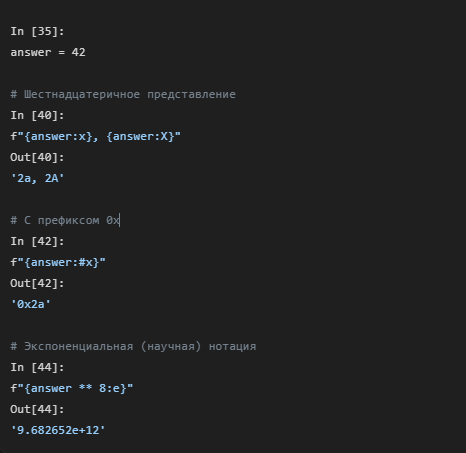
Для чисел существует множество полезных форматов.
Вы можете легко конвертировать числа в двоичную (b), восьмеричную (o) или шестнадцатеричную (x/X) системы. Использование # добавляет соответствующий префикс (0b, 0o, 0x).
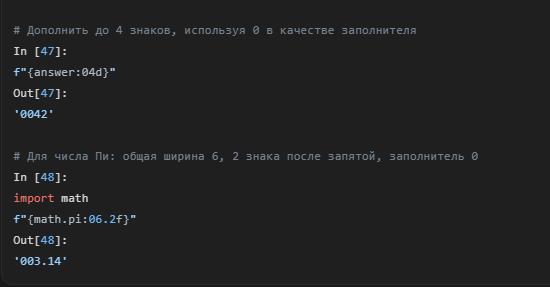
Часто нужно дополнить число ведущими нулями до определенной длины (например, 0042). Для этого используется 0 в качестве символа-заполнителя. Для чисел с плавающей точкой можно контролировать и общую ширину, и количество знаков после запятой.
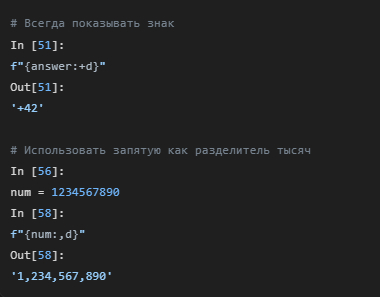
Для управления знаком и разделителями существуют специальные символы:
+: всегда показывать знак (+42, -42).
(пробел): показывать пробел для положительных чисел, минус для отрицательных (42, -42). Удобно для выравнивания в столбец.
, или _: использовать как разделитель тысяч
Многие встроенные объекты, как datetime, имеют свой собственный мини-язык форматирования, который можно использовать напрямую в f-строках.

Сами спецификаторы формата не обязаны быть статичными! Их можно задавать с помощью переменных, используя вложенные фигурные скобки.
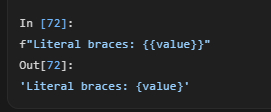
Если вам нужно вывести в строке сами символы { или }, просто удвойте их.
Многострочные f-строки
Для длинных строк или генерации многострочного текста (например, SQL-запросов, HTML-шаблонов) используйте тройные кавычки. Выражения внутри также могут быть многострочными.

Результат:
Вопросы безопасности (Очень важно!)
Это ключевой аспект, который часто упускают.
F-строки сами по себе безопасны. Когда вы пишете f"Привет, {name}", это не является уязвимостью. Python не выполняет код, который может находиться внутри переменной name. Он просто берет её строковое представление.
Опасность возникает, когда вы комбинируете f-строки с функциями, исполняющими код, такими как eval() или при работе с шаблонизаторами.
Представьте, что вы позволяете пользователю вводить свой собственный шаблон формата.
КРАЙНЕ ОПАСНЫЙ КОД — НИКОГДА ТАК НЕ ДЕЛАЙТЕ:
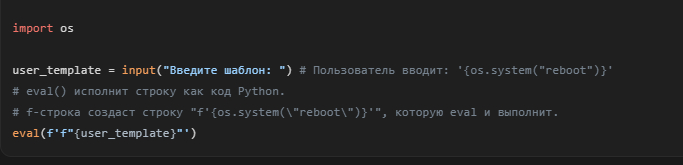
Если пользователь введет {os.system("reboot")}, ваш сервер перезагрузится. Это уязвимость удаленного выполнения кода (RCE).
Мораль: F-строки предназначены для форматирования строк, шаблоны которых пишет сам разработчик. Никогда не передавайте строки, полученные от пользователя, в eval() или другие исполняющие функции, даже через f-строки. Для пользовательских шаблонов используйте безопасные движки, такие как Jinja2.
Производительность: почему f-строки так быстры?
f-строки быстрее, чем .format() или %. Но почему?
Причина в том, что f-строка — это не функция, а часть синтаксиса Python. Когда Python компилирует ваш .py файл в байт-код, он парсит f-строку и разбивает её на две части:
Литеральные части (обычный текст).
Выражения для вычисления.
В байт-коде это превращается в очень эффективную последовательность инструкций: взять литерал, вычислить выражение, преобразовать его в строку, взять следующий литерал и так далее, а затем объединить все части за одну операцию (BUILD_STRING).
Метод .format() же является обычным вызовом функции. Это означает дополнительные накладные расходы на вызов метода, парсинг строки формата во время выполнения и поиск соответствий между {} и аргументами. F-строки делают большую часть этой работы во время компиляции, что и дает им преимущество в скорости.
4. Инструменты для миграции
flynt и pyupgrade.
flynt: Это инструмент, специально созданный для автоматического преобразования старого кода с .format()и%` на f-строки. Он анализирует код и производит замену там, где это возможно.
pyupgrade: Более универсальный инструмент. Он не только обновляет синтаксис форматирования строк, но и применяет множество других современных синтаксических конструкций Python (например, super() без аргументов, синтаксис для аннотаций типов и т.д.).
Использование этих инструментов на старой кодовой базе — отличный способ быстро её модернизировать и улучшить читаемость.
Понравилось — ставь «+»
Полезно? Подпишись.
Задавай вопросы в комментариях 👇👇👇
Удачи! 🚀