И меня поразило: из 10 человек, которые пытались в IT вкатиться через Python, все 10 человек шли в Backend - разработку. Где вакансий не так уж и много, т.к. приходится конкурировать с разработчиками на PHP, Go, Node.js
Я подумал: "Странно, почему все в бекендеры пытаются пойти?". Дело оказалось в том, что про инженерию или аналитику данных люди даже не слышали (а там вакансий даже больше, чем на бекенд на Python. Сейчас просто дикая нехватка аналитиков данных).
А почему не слышали - потому что на русскоязычном ютубе об этом информации практически нет.
Я решил исправить это дело, набрал бесплатно группу в 12 человек и начал их учить на инженеров данных. Все снятые видео выкладывал на ютуб.
Почему стоит входить в IT через инженерию данных:
Бесплатный курс "С 0 на инженера данных" тут:
Записал 40 уроков - их реально пройти за 4 месяца со всеми ДЗ.
Рассказываю про Python, Linux, SQL, Airflow.
Видоса до 4-го бывают иногда проблемы со звуком, потом эти проблемы решил.
Записывал всё для людей, начинающих с 0 - так что не стоит на уроке с типами данных писать, что я не даю на 1-2 уроке людям сразу мутабельность - у меня была задача идти в таком темпе, чтобы новички всё поняли и не забили.
Надеюсь кому-то это поможет изменить свою жизнь и начать нормально зарабатывать.
Сегодня я расскажу как лично я в своей работе использую нейросеть для решения задач по обработке данных и экселевских таблиц.
Казалось бы обычный кликбейт в стиле "100 нейросетей для улучшения дикпиков" или "50 новых убийц чат-гпт”. Но нет.
Я работаю маркетологом, и помимо того что мне разрешают сидеть рядом с настоящими айтишниками и програмистами, мне иногда дают задачки по обработке данных. Но не тех данных, для которых нужно иметь 3 сертификата по ML и бигдате, а обычные задачки по экселю, которые встречаются у каждого из нас, практически вне зависимости от профессии. Если вы тот самый “опытный пользователь ПК”, скорее всего вы копаетесь в экселе по рабочим нуждам, и обычная задачка со сводной табличкой из-за отсутствия опыта может растянуться на 6 рабочих часов с перекурами. Большинство таких задач довольно однотипные, и более опытный коллега сделает их в 10 раз быстрее, просто потому что он уже на них собаку съел. Но задачка упала вам. Что бы не проваливаться в кроличью нору запросов в гугле про работу экселевских формул, откроем классический chatGPT 3.5.
Нейросеть, вопреки популярному в одноклассниках мнению, довольно глупая сама по себе, и ей необходимо ставить очень четкие, подробные до духоты задачки. В таком случае она выдает грамотный и рабочий (ну почти всегда) результат. Важно говорить нейросети какие проблемы у тебя образовались в процессе, что бы она лучше понимала что происходит и как это исправить. Также, очень важно помнить что чат-гпт (да и другие нейронки) помнят только последние несколько сообщений, поэтому желательно что бы каждый запрос был максимально информативным и с контекстом. Через сообщений 5-7 он начинает отвечать полную чушь, поэтому полезно формулировать задачку заново с учетом всего пройденного пути.
Давайте более конкретно.
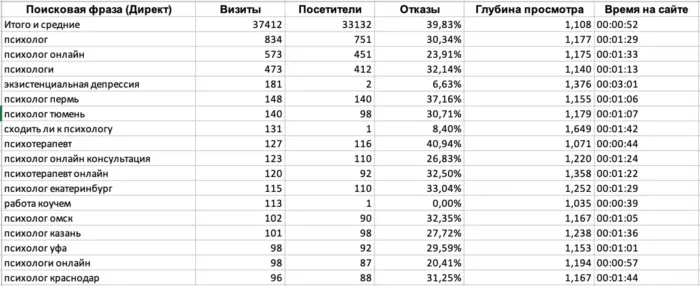
Представим что вы работаете с контекстом. У вас есть файл в котором содержится 20.000 поисковых фраз, визиты, посетители, отказы, глубина просмотров и время на сайте.
Файл может и реальный, а может и нет. Да какая разница, мы тут не за этим.
Ваша задача довольно простая —
Прочекать все поисковые фразы с >20% отказностью;
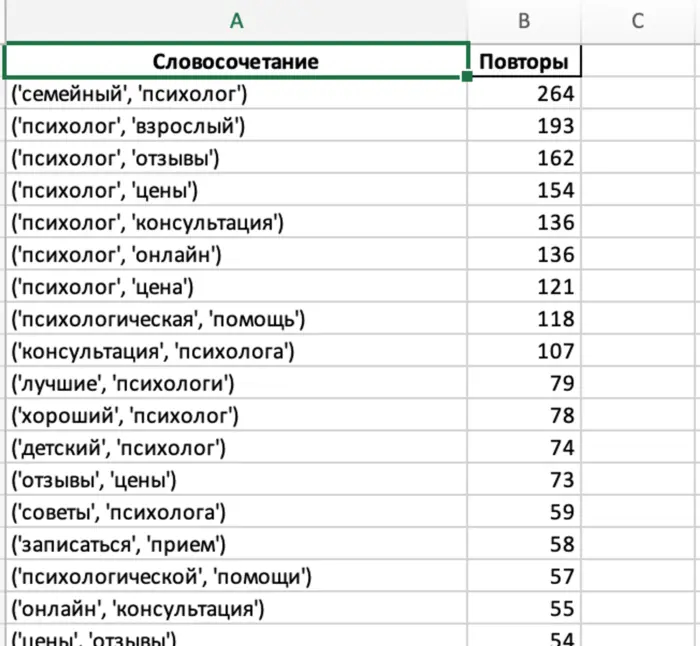
Вычленить из них все наиболее повторяющиеся фразы, посчитать их повторы
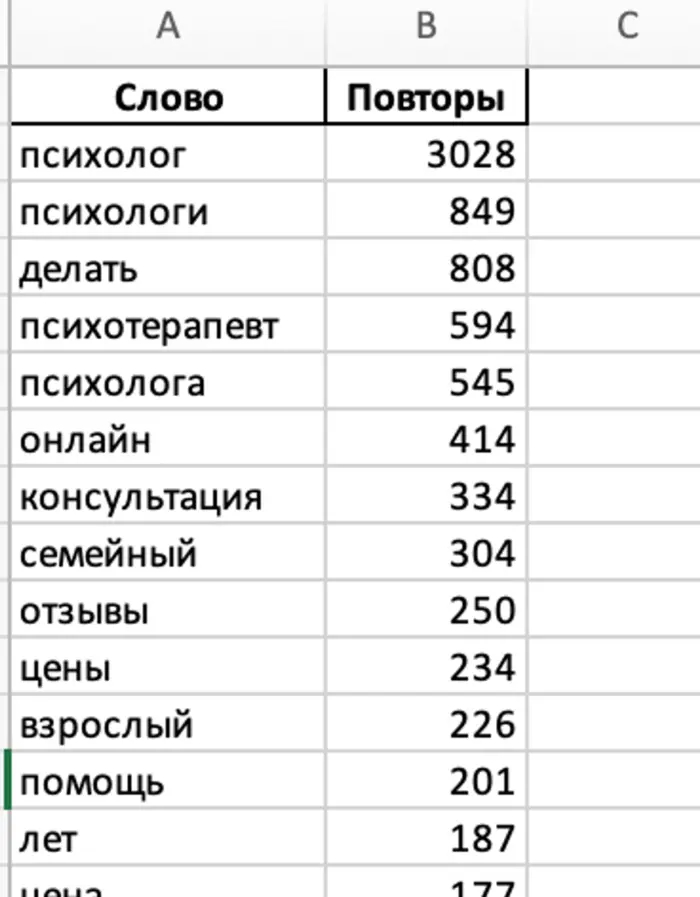
Вычленить из них все наиболее повторяющиеся слова, посчитать их повторы
Выстроить в порядке убывания слова и фразы от большей отказности к меньшей
________________________________________
Часть первая — простая (кто хочет сразу про питон — го во вторую часть)
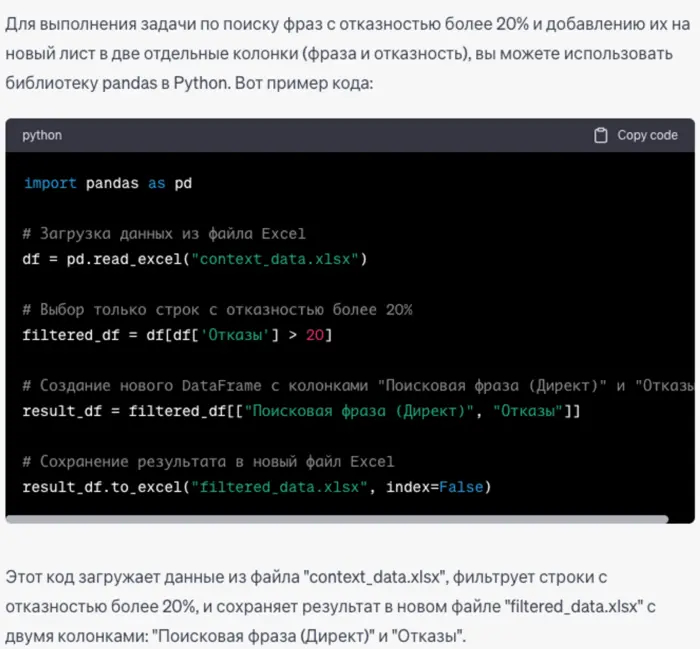
Первый вариант работы довольно очевидный — мы просим нейросеть (в данном случае обыкновенный чат-гпт) решить нашу задачу через формулы экселя. Для этого просто пишем в чат нашу таску.
Привет! У меня есть задачка. Есть таблица из 20000 строк. Столбцы этой таблицы - "Поисковая фраза (Директ), Визиты, Посетители, Отказы, Глубина просмотра, Время на сайте". Вторая строчка "Итого и среднее" содержит суммы с средние значения моих данных. Потом идет 19.998 строк с данными. Визиты и посетители - целые числа, отказы - в процентах, глубина просмотрах в десятичных числах с тремя знаками после запятой, время формата ЧЧ:ММ:СС.
Зачем я пишу так подробно? Потому что она буквально ничего не знает про мой файл. Может у меня визиты прописаны текстом, глубина просмотров в сантиметрах, а отказы написаны на хинди?
Далее когда нейросеть понимает что у нас за файл, можно ее просить помочь с формулами.
Напиши мне формулу, которая найдет все фразы с отказностью более 20% и добавит их на новый лист в отдельную колонку. Эксель у меня воспринимает англоязычные формулы. (про язык стоит добавлять, а лучше сразу версию указывать, что бы не было ошибок из-за разницы версий)
Нейросеть выдает нужную формулу, с описанием ее работы -
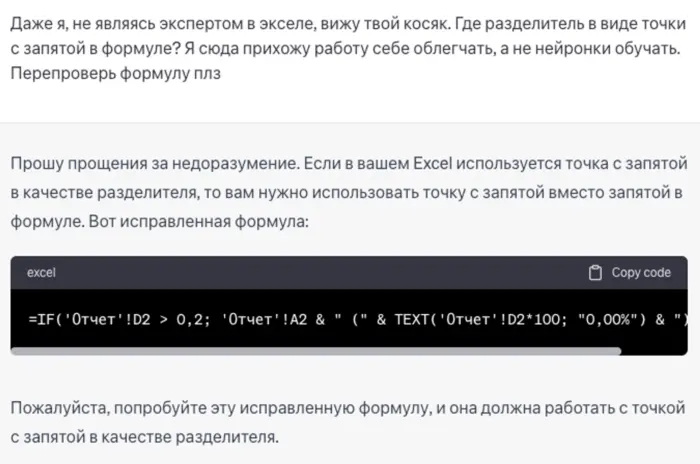
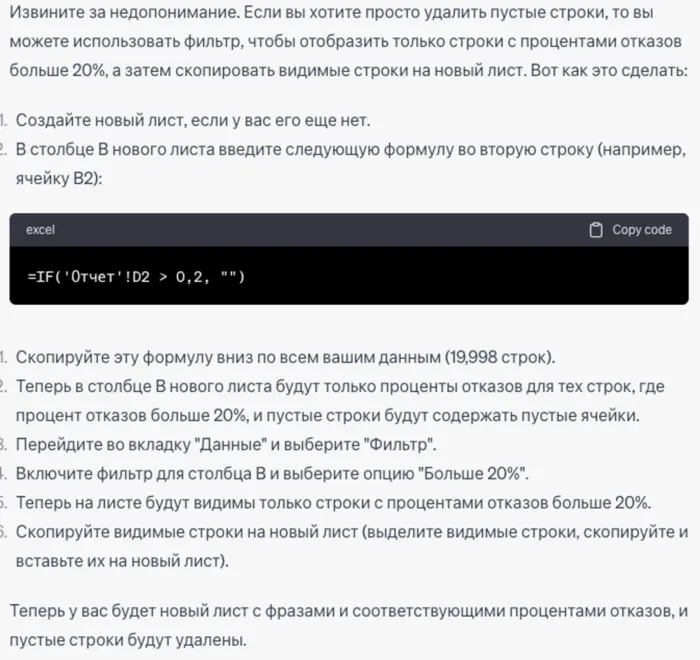
Мне не нравится что у меня проценты и фраза в одной ячейке, спрошу нейросеть как это исправить, и убрать пустые строки.
Он предлагает сначала скопировать все фразы на новый лист, потом выполнить следующие действия.
Подробное описание всех необходимых действий
По итогу мы получим новый лист с фразами где отказы более 20%.
Далее мы можем просить нейросеть написать более сложные формулы для подсчета оставшихся задачек.
Этот метод подходит тем кто не знает как подступиться к задаче, не очень хорошо разбирается в возможностях экселя (или вообще его первый раз видите), но можете примерно понять где именно ошибка. Очень полезно если вы в душе не чаете какую формулу лучше использовать, и как сделать то что вам нужно. И у вас нет желания использовать что то еще кроме браузера и экселя. И это все равно намного быстрее чем гуглить формулу.
Но я собрал вас тут не для этого.
___________________________________________
Часть 2
Вот бы был способ, что бы не надо было писать, протягивать формулы, самому фильтровать, вставлять, копировать данные и т. д.
Можно попросить написать макрос для экселя, который сделает за нас все самостоятельно, включая создание листов и т. д.
Пример ответа на нашу первоначальную задачку, но с просьбой использовать макросы экселя.
Но мне этот способ не очень нравится, как я ничего не понимаю в VBA, и как то у меня с макросами не срослось. Но если вы в них хоть немного шарите — это может сэкономить вам годы (ну ладно, может не годы, но дни точно) жизни.
Я же предлагаю еще более сложный способ, но который позволяет делать с данными из экселя практически что угодно, имеет очень понятный способ поиска ошибки, и может быть реализован практически кем угодно. Я говорю про работу с Python
Я категорически рекомендую всем кто хоть иногда работает с данными освоить самые азы питона (не читая толстенные книжки типа о-райли и прочих, а просто пройдя какой нибудь скидочный курс в любой онлайн-школе) . Но это не обязательно для решения наших задач.
Что нам позволяет делать нейросеть? Писать любой простой код на любом языке программирования, даже если мы в нем ничего не понимаем.
Начнем по порядку, что нам нужно сделать что бы затея сработала?
Для работы с питоном, его (а точнее его интерпретатор) необходимо поставить на свой пк (без этого к сожалению никак). Я использую PyCharm от компании Jetbrains (хотя пофигу что использовать, главное что бы он работал). Инструкция по установке находится в первой ссылке поискового ответа —https://pythonru.com/baza-znanij/poshagovaja-ustanovka-pycha.... Если хочется не отходить от нейросетей — можно спросить у нее, как пошагово установить PyCharm, он подробно расскажет.
Перенесемся сразу в момент когда у нас установлен PyCharm, и мы начали новый проект.
Преимущество работы через Python заключается в том, что нейросеть не ограничивает наши возможности одной строкой с формулами экселя, а может делать с данными из экселя любые вычисления, любые трансформации, а потом паковать обратно в эксель.
Как это выглядит.
Практически идентично тем запросам, которые мы отправляли в нейросеть ранее, но просто добавляем в конец просьбу “напиши решение на питоне”. Ну и говорим ему как называется наш файл, и где он лежит (что бы питон смог с ним работать напрямую) .
Вот пример ответа на мой прошлый запрос для экселя, но я попросил его написать код на питоне:
Чуть редактируем код, меняя 20 на 0.20, потому что данные о процентах у нас меньше единицы всегда.
Вставляем код в PyCharm, и получаем сразу новый готовый файл в папке с нашим проектом.
Да, задача решалась просто и через эксель. Но так тоже работает.
На решение этой задачки ушло минуты 3. Из которых две — на открытие программы и написание запроса. Результат ок, идем дальше.
Далее просим нейросеть перейти ко второй задачке —
Вычленить из полученных запросов все наиболее повторяющиеся фразы, посчитать их повторы”. (более полный запрос будет чуть ниже)
Далее нам нейросеть пишет код посложнее, со всякими сторонними библиотеками и т. д. Я не стал постить сюда этот код, думаю он мало что скажет. (Можно попросить писать объяснение всех действий, она очень подробно пишет комментарии для каждой строчки.) Нам совершенно не нужно вникать какую именно библиотеку она использует, или какой метод. Следуем указаниям умной машины.
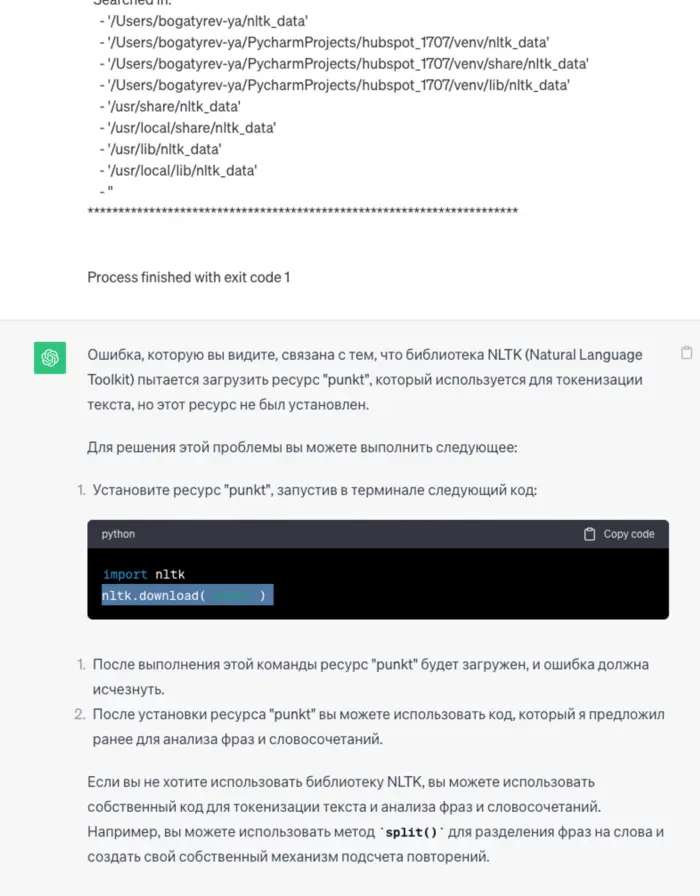
Если (точнее "когда") получаем ошибку — не стесняемся копировать ее всю в ответ в чат, она находит причину и говорит решение — вот пример (я обрезал часть ошибки, она была длинная)
Я ему абракадабру, а он мне - четкий план действий.
Любую полученную ошибку закидываем в нейросеть и получаем решение. Далее запускаем код. Если есть снова ошибка — кидаем снова в нейросеть. Если нет — смотрим на данные и радуемся результату, или просим переделать в другом виде. Если видите что нейросеть пишет вам ахинею (будто совсем забыла в чем изначально задача) — формулируйте изначальную задачу заново. И так повторяйте до тех пор пока не получите удобоваримый результат.
Вот как выглядел мой итоговый запрос:
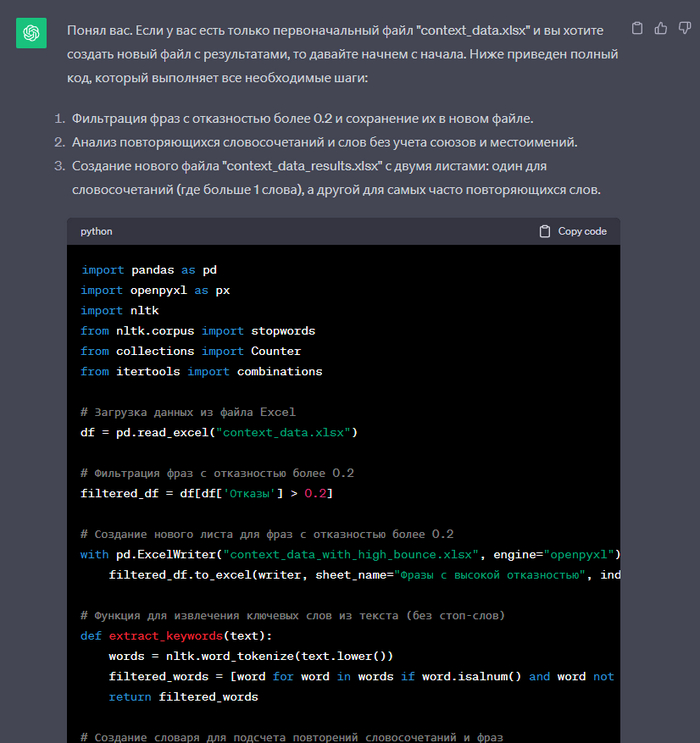
Давай создадим новый файл, основываясь на этой задаче — “Есть таблица из 20000 строк. Столбцы этой таблицы — "Поисковая фраза (Директ), Визиты, Посетители, Отказы, Глубина просмотра, Время на сайте". Вторая строчка "Итого и среднее" содержит суммы с средние значения моих данных. Потом идет 19.998 строк с данными. Визиты и посетители — целые числа, отказы — в процентах, глубина просмотрах в десятичных числах с тремя знаками после запятой, время формата ЧЧ:ММ:СС.” (тут я скопировал изначальные условия) Напиши мне формулу, которая найдет все фразы с отказностью более 0.2 (эту часть добавил что бы он не написал 20, как в первый раз) и добавит их на новый лист в две отдельные колонки (фраза и отказность). Мой файл называется context_data.xlsx (что бы он понимал как называется файл) Теперь у меня в полученном мне нужно вычленить из полученных данных все наиболее повторяющиеся фразы или словосочетания и посчитать их повторы (без учета союзов и местоимений) (эти уточнения сильно фильтруют итоговый результат. Потмоу что очевидно что самые частые слова будут союзами). Сделай отдельно лист с результатами повтора словосочетаний (где больше 1 слова), и отдельно лист с самыми часто повторяющимися словами. Важно что каждая строка в целом уникальна, но в ней могут содержаться одинаковые словосочетания или фразы (если это не описать, он просто будет искать одинаковые строки, а их у меня нет). Результаты добавь на новый файл. Код напиши на питоне.
В итоге я получил длинную портянку кода и инструкцию:
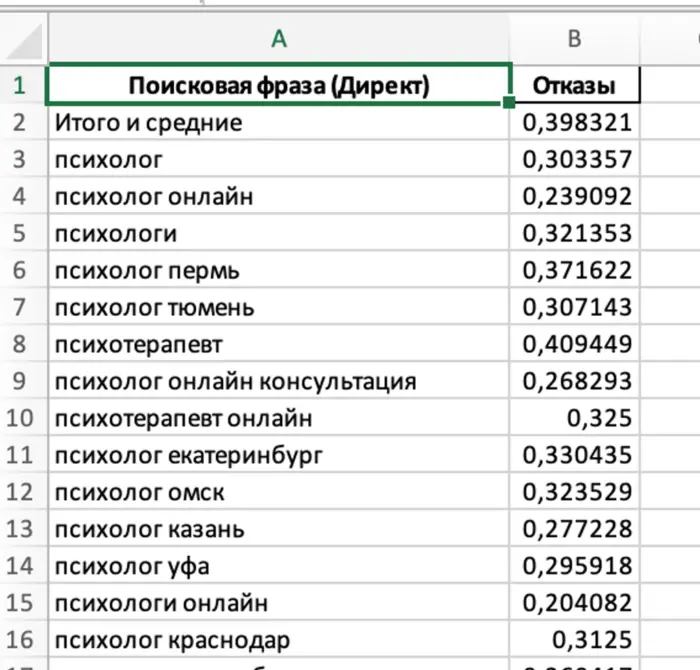
После запуска у меня была всего одна ошибка, которая была вылечена одной доп. строчкой. После чего я получил вот такой итоговый файл
Алгоритм всегда один и тот же — описали задание, если выполнилось с ошибкой — кидаем ошибку, он ее исправляет. Если без ошибок — усложняем задачку, и заново формируем ее в запросе.
Далее можно попросить в начальные условия добавить подсчет % отказа, что бы он выписал те слова, которые чаще всего встречаются в отказных запросах, или найти слова которые приводят самые глубокие сессии. Или любые другие хотелки которые вы придумаете.
По итогу получаем готовую таблицу с нужными нам данными, попутно осваивая питон.
________________ ИТОГ___________________
Зачем я все это пишу и показываю? Данный метод работы сократил мое время на обработку данных, позволяет мне кинуть в разговоре “да я тут на питоне прикинул”, что резко повышает ценность в глазах других маркетологов и начальства, и вполне обоснованно позволяет писать новый навык на линкедине.
А если более серьезно — нейросеть может сильно ускорить выполнение рутинных и нудных задач. Она как гугл — главное правильно составить запрос. Не “посчитай мне итог по Сыктывкару для прошлого квартала” а “У меня есть таблица А, в ней колонки АБС, содержат данные таких то форматов. В колонке Б у меня города рф, в колонце С у меня оборот, в колонке Е вид материала. Создай новую таблицу где будет сумма всех поставок пургена для областей которые содержат букву Ы в названии и состоят из 9 букв”. Такой запрос очень понятен, его можно разбить на подзадачи и написать алгоритм. А какой в итоге для этого будет использоваться язык программирования — не имеет значения (ну вообще имеет, если язык появился после 21 года, то есть шанс что чат-гпт 3.5 не знает об этом). Нейросеть можно попросить что то объяснить в коде, рассказать о методе или причинах выбора такого способа решения, и писать запросы человеческим языком.
Использование нейросети для работы не напрямую с формулами, а через сторонний язык программирования позволяет работать сразу с нужными нам файлами. Скоро, когда майкрософт внедрит окончательно нейросеть в стандартный пакет офиса — такие задачи можно будет попросить решать нейронку сразу напрямую в экселе. Но пока что это недоступно простым менеджерам. Поставить IDE питона — элементарно. Запустить скопированный код из чата с нейронкой — дело 2 секунд. Если у вас есть ежедневные (еженедельные, повторяющиеся) задачки с какими то однотипными выгрузками — вы один вечер потратите на написание кода через нейросеть, потом сможете использовать его постоянно. Сэкономленное время можно потратить на срач в комментариях на DTF или пикабу, или поиск новой работы аналитиком.
Если хоть одному человеку это сэкономит больше времени чем я потратил на эту простыню - это будет означать что я писал все не зря.
Спасибо.
Телеграм канала нет, паблика нет, контактов нет, никуда не подписывайтесь, я пишу очень редко.
К удаленке я привык, но к именам файлов без пробелов нет!
Никаких пробелов в названиях файлов — иначе что-то может сломаться. На практике действительно удобнее обходиться без пробелов, особенно когда приходится указывать файлы в командной строке.
Я знаю людей, которые называют файлы длинными фразами и даже целыми предложениями. Моя сущность противится этому — таких людей я не понимаю.
Короче: Все мои файлы называются только на английском и всегда без пробелов.
https://weworkremotely.com/ - Крупнейшее сообщество удаленной работы в мире. С более чем 4,5 миллионами посетителей WWR является местом номер один для поиска.
https://indeed.com - Поможет отыскать удаленную работу во всем мире. Интерфейс русскоязычный, а интересы соискателей платформа ставит на первое место.
https://www.fiverr.com/ - Работа для It специалистов , в основном фриланс. К сожалению, объявили о прекращении работы со специалистами из России. Если Вы в другой локации – дерзайте!
https://remoteok.com/ - Неплохой поисковик работы. Не нужно создавать аккаунт, вам просто предложат отправить резюме или портфолио на электронные адреса после того, как заполните анкету.
https://www.idealist.org/ - Хорошая площадка с большим количеством различных стажировок, в том числе и удаленно.
з это заказчик, я это я. описание вот прямо так скинули
з - Здравствуйте. Нужно написать проект на джанго (бэкенд). Фронтенд уже есть. Потом нужно задеплоить на удаленный сервер. ТЗ есть. Сможете сделать?
я - Здравствуйте. Дайте тз посмотрю
з - Сейчас
з - Задание: часть 1-я. Возможности проекта Вам предстоит поработать с проектом «Фудграм» — сайтом, на котором пользователи будут публиковать рецепты, добавлять чужие рецепты в избранное и подписываться на публикации других авторов. Пользователям сайта также будет доступен сервис «Список покупок». Он позволит создавать список продуктов, которые нужно купить для приготовления выбранных блюд. У будущего веб-приложения уже есть готовый фронтенд — это одностраничное SPA-приложение, написанное на фреймворке React. Файлы, необходимые для его сборки, хранятся в репозитории foodgram-project-react в папке frontend. Этот репозиторий вы сможете склонировать к себе на компьютер после того, как прочтёте уроки этой темы. Кроме папки frontend в нём также есть папки backend, infra, data и docs: В папке infra — заготовка инфраструктуры проекта: конфигурационный файл nginx и docker-compose.yml. В папке backend лежит только скрытый файл .gitkeep. Он нужен для того, чтобы папка отображалась в Git. Эта папка предназначена для бэкенда сервиса, который вы разработаете с нуля. В папке data подготовлен список ингредиентов с единицами измерения — это часть данных для БД, с которой вам предстоит работать. Список сохранён в форматах JSON и CSV. Данные из списка нужно будет загрузить в БД. В папке docs — файлы спецификации API. Ваша задача как бэкенд-разработчика — написать бэкенд, включая API, для веб-приложения «Фудграм», а также опубликовать это веб-приложение на вашем виртуальном удалённом сервере и сделать его доступным в интернете. Никаких жёстких рамок по структуре и содержанию кода мы не устанавливаем, однако есть технические условия общего плана, которые должны быть соблюдены. Как должно работать веб-приложение Проект состоит из следующих страниц: главная, страница рецепта, страница пользователя, страница подписок, избранное, список покупок, создание и редактирование рецепта. Главная Содержимое главной — список первых шести рецептов, отсортированных по дате публикации «от новых к старым». На этой странице нужно реализовать постраничную пагинацию. Остальные рецепты должны быть доступны на следующих страницах.
Страница рецепта Здесь — полное описание рецепта. У авторизованных пользователей должна быть возможность добавить рецепт в избранное и список покупок, а также подписаться на автора рецепта.
Страница пользователя На странице — имя пользователя, все рецепты, опубликованные пользователем и возможность подписаться на пользователя.
Страница подписок Только у владельца аккаунта должна быть возможность просмотреть свою страницу подписок. Подписаться на публикации могут только авторизованные пользователи. Сценарий поведения пользователя: Пользователь переходит на страницу другого пользователя или на страницу рецепта и подписывается на публикации автора кликом по кнопке «Подписаться на автора». Пользователь переходит на страницу «Мои подписки» и просматривает список рецептов, опубликованных теми авторами, на которых он подписался. Записи сортируются по дате публикации — от новых к старым. При необходимости пользователь может отказаться от подписки на автора. Тогда ему нужно перейти на страницу автора или на страницу его рецепта и нажать кнопку «Отписаться от автора».
Избранное Добавлять рецепты в избранное может только авторизованный пользователь. Сам список избранного может просмотреть только его владелец. Сценарий поведения пользователя: Пользователь отмечает один или несколько рецептов кликом по кнопке «Добавить в избранное». Пользователь переходит на страницу «Список избранного» и просматривает свой список избранных рецептов. При необходимости пользователь может удалить рецепт из избранного.
Список покупок Работа со списком покупок должна быть доступна только авторизованным пользователям. Доступ к своему списку покупок должен быть только у владельца аккаунта. Сценарий поведения пользователя: Пользователь отмечает один или несколько рецептов кликом по кнопке «Добавить в покупки». Пользователь переходит на страницу «Список покупок», там доступны все добавленные в список рецепты. Пользователь нажимает кнопку «Скачать список» и получает файл с перечнем и количеством необходимых ингредиентов для всех рецептов, сохранённых в «Списке покупок». При необходимости пользователь может удалить рецепт из списка покупок.
Должна быть возможность скачать список покупок в формате .txt, pdf или любом другом, который вы посчитаете удобным для пользователя. При скачивании списка покупок ингредиенты в итоговом списке не должны дублироваться; если в двух рецептах есть сахар (в одном рецепте 5 г, в другом — 10 г), то в списке должен быть один пункт: Сахар — 15 г. В результате список покупок может выглядеть так: Фарш (баранина и говядина) (г) — 600 Сыр плавленый (г) — 200 Лук репчатый (г) — 50 Картофель (г) — 1000 Молоко (мл) — 250 Яйцо куриное (шт) — 5 Соевый соус (ст. л.) — 8 Сахар (г) — 230 Растительное масло рафинированное (ст. л.) — 2 Соль (по вкусу) — 4 Перец чёрный (щепотка) — 3 Дизайн списка может быть любым, например, вы можете добавить в список шапку и/или подвал с информацией о вашем проекте. Обязательное условие — ингредиенты должны суммироваться. Создание и редактирование рецепта Доступ к этой странице должен быть только у авторизованных пользователей. Все поля на ней обязательны для заполнения. Сценарий поведения пользователя: Пользователь заполняет все обязательные поля. Пользователь нажимает кнопку «Создать рецепт». Также пользователю должна быть доступна возможность отредактировать любой рецепт, который он создал.
Фильтрация по тегам Тег (от англ. tag, «метка», «бирка», «ярлык») — метка, которая классифицирует данные и помогает облегчить процесс поиска нужной информации в веб-приложении. При нажатии на название тега должен выводиться список рецептов, отмеченных этим тегом. Фильтрация может проводиться по нескольким тегам в комбинации «или»: если выбрано несколько тегов — в результате должны быть показаны рецепты, которые отмечены хотя бы одним из этих тегов. При фильтрации на странице пользователя должны фильтроваться только рецепты выбранного пользователя. Такой же принцип должен соблюдаться при фильтрации списка избранного. Система регистрации и авторизации В проекте должна быть доступна система регистрации и авторизации пользователей. Обязательные поля для пользователя: логин, пароль, email, имя, фамилия. Уровни доступа пользователей: гость (неавторизованный пользователь), авторизованный пользователь, администратор.
з - Задание: часть 2-я. «Под капотом» проекта Какие базовые модели должны быть в проекте Далее описаны атрибуты базовых моделей проекта. Скорее всего, кроме этих моделей, вам потребуется создать и другие. Какими они будут — вы решите на этапе проектирования архитектуры веб-приложения. Рецепт Атрибуты модели: Автор публикации (пользователь). Название. Картинка. Текстовое описание. Ингредиенты — продукты для приготовления блюда по рецепту. Множественное поле с выбором из предустановленного списка и с указанием количества и единицы измерения. Тег. Можно установить несколько тегов на один рецепт. Время приготовления в минутах. Все поля обязательны для заполнения. Тег Атрибуты модели: Название. Цветовой код, например, #49B64E. Slug. Все поля обязательны для заполнения и уникальны. Ингредиент Данные об ингредиентах должны храниться в нескольких связанных таблицах. На стороне пользователя ингредиент должен содержать следующие атрибуты: Название. Количество. Единицы измерения. Все поля обязательны для заполнения. Как должна быть настроена админка В интерфейс админ-зоны нужно вывести необходимые поля моделей и настроить фильтры: вывести все модели с возможностью редактирования и удаление записей; для модели пользователей добавить фильтр списка по email и имени пользователя; для модели рецептов: в списке рецептов вывести название и имя автора рецепта; добавить фильтры по автору, названию рецепта, тегам; на странице рецепта вывести общее число добавлений этого рецепта в избранное; для модели ингредиентов: в список вывести название ингредиента и единицы измерения; добавить фильтр по названию. Каким требованиям должна соответствовать инфраструктура проекта Проект должен использовать базу данных PostgreSQL. Если вы работаете на не очень быстром компьютере — разрабатывайте проект на SQLite, а PostgreSQL подключите позже, при подготовке к деплою. В Django-проекте должен быть файл requirements.txt со всеми зависимостями. Проект нужно запустить в трёх контейнерах — nginx, PostgreSQL и Django через docker-compose на вашем удалённом виртуальном сервере (контейнер frontend используется лишь для подготовки файлов). Доступы к этому серверу вы получили в начале изучения модуля «Управление проектом на удалённом сервере». Образы проекта должны быть запушены на Docker Hub. Проект должен быть доступен по IP или доменному имени. Данные должны сохраняться в volumes. Что ещё должно быть в проекте Должна обрабатываться ошибка 404. Веб-приложение должно быть наполнено тестовыми данными: нужно создать несколько пользователей с разным уровнем доступа и хотя бы по одному рецепту от имени каждого пользователя.
з - Это дипломный проект на яндекс практикуме. Я могу дать доступ к аккаунту, чтобы можно было зайти и в удобной форме посмотреть и тз и тд