Нейросети, которые создают уникальный визуальный контент, сейчас на пике популярности. Ими пользуются как в личных интересах, так и для развития бизнеса. Dimplex не остался в стороне от трендов и тоже обратился к искусственному интеллекту, мол, а вдруг получится что-то интересное. Спустя несколько месяцев активных экспериментов уверенно говорим: «получилось!». Сейчас мы готовы рассказать о пробах и ошибках, а также поделиться результатами.
Мы тестировали только известную нейросетью Midjourney, поэтому речь пойдет именно о ней.
Возможно, интерьеры с очагами Dimplex от Midjourney, которые вы увидите в этой статье, вдохновят вас на создание собственного дизайнерского проекта с электрическим камином. А может наш пользовательский опыт подтолкнет вас воспользоваться нейросетью, чтобы найти интересные решения и воплотить их жизнь.
Немного о Midjourney
Midjourney – это симбиоз творчества и искусственного интеллекта. Можно сказать, что это искусственно созданный коллективный разум, который обучен создавать самые невероятные и даже абсурдные картинки по текстовому описанию. Путем анализа огромного объема данных всемирного интернета и использования сложных алгоритмов, нейросеть генерирует креативные и уникальные изображения от абстрактных композиций до фотореалистичных интерьеров с брендовой мебелью.
Алгоритм работы достаточно прост. Регистрируемся в Discord, создаем себе личную группу с ботом Midjourney (в интернете достаточно информации, как это сделать) и после ввода команды \imagine пишем наш запрос на английском языке. После этого нейросеть предложит четыре варианта, из которых можно выбрать самый подходящий и даже улучшить его.
Dimplex и нейросеть: об опыте из первых уст
Несмотря на простой алгоритм работы, все не так легко. Трудности кроются в главном шаге к созданию изображения — в текстовом запросе или промте, как он правильно называется.
Когда мы только начинали осваивать Midjourney, чтобы улучшить визуал на сайте и в соцсетях Dimplex, мы использовали простые запросы, например, «электрокамин Dimplex в интерьере» или «электрокамин Dimplex в большой комнате».
Такие промты нейросеть отлично понимала и выдавала корректные изображения. Их мы использовали и используем до сих пор для сопровождения статей об электрокаминах и в соцсетях, когда рассказываем о бренде в целом и дизайн пространства нам не важен. Конечно, не всегда обходится без магии фотошопа. Порой Midjourney предпочитала нашим очагам модели других брендов или ломала законы физики, но в целом простые запросы ей были понятны, так как в интернете достаточно фотографий нашей продукции в том числе и в интерьерах.
Когда базовые навыки работы с нейросетью были освоены, а сгенерированных картинок стало больше, чем надо, мы пошли дальше. Подключилась фантазия, а вслух впервые была произнесена фраза, с которой начинаются все эксперименты: «А что, если бы…». А что, если бы электрокамины Dimplex разных моделей были знаками зодиака? А что, если бы наш очаг был встроен в портал в виде банана? А что, если бы электрокамин можно было установить в глыбе льда? После мозгового штурма было принято решение усложнить задачу для нейросети и проверить ее креативность как раз с помощью таких необычных запросов.
Первый такой эксперимент мы затеяли к Всемирному дню защиты детей. Для социальных сетей нужно было сгенерировать 10 интерьеров детских комнат, в которых электрокамины Dimplex были бы встроены в порталы в форме мультяшных персонажей, фруктов, сказочных замков и космических кораблей.
И вот тут сначала мы сели в лужу. Во-первых, мы узнали, что промты «портал под электрокамин в виде панды» «портал под электрокамин в форме панды» абсолютно разные и приводят к непохожим результатам, хотя для нас как для носителей русского языка слова «в виде» и «в форме» часто являются синонимами. Во-вторых, оказалось, что если с созданием интерьеров, к которым нет требований по стилю и декору, нейросеть справляется не хуже именитых дизайнеров, то в моменты креатива флер профессионализма слетает.
Хоть нейросеть и имеет доступ к материалам со всего интернета, анализировать их она не умеет. Вот такие результаты мы получили на просьбу сгенерировать электрокамин Dimplex в форме Шрека, машины, капусты и крокодила. Будь они реальны, гармонично бы не смотрелись ни в одной комнате, да и камин куда-то пропал.
Создание промтов похоже на игру в «Угадайку» с маленьким ребенком, у которого огромный словарный запас. Слова он понимает, а причинно-следственные связи, которые должны привести к результату без должного объяснения нет. Чтобы получить желаемый результат, промт нужно составлять максимально подробно, грамотно и корректно.
Путем проверки промтов и небольших манипуляций с фотошопом заветные картинки все же были сгенерированы.
Впервые использовав Midjourney для создания креативного контента, мы сделали определенные выводы, которые очень пригодились в дальнейшей работе:
- нейросеть – это не готовое решение, а инструмент, которым нужно научиться владеть. Понять, как правильно создавать промты можно только на практике;
- без человека (пока что) никуда. Так или иначе это человек должен придумать идею и представить себе конечный результат, чтобы описать это в промте;
- фотошоп пригодится. Midjourney отлично справляется с тенями, фактурами и ракурсами, но порой дублирует предметы, соединяет несовместимое, нарушает законы физики и плохо справляется с человеческими фигурами. Использовать сгенерированные изображения без правок можно далеко не всегда.
Очаги Dimplex в стилистике «королей ужасов» к Хэллоуину — пока что последняя, но не финальная подборка от нейросети. При ее создании больше времени уходило на первичную проработку концепций и написание корректных промтов. Зато на генерацию и обработку готового материала времени было затрачено гораздо меньше.
Когда все инструменты изучены, а ожидаемый результат получен и не раз, можно наконец-то сказать о плюсах нейросети для площадок Dimplex, которые мы выявили.
1.Разнообразие контента. Нейросеть создает уникальный контент, которого нет ни у конкурентов, ни вообще на просторах интернета.
2. Экономия времени. Отточив мастерство формулировать промты, можно генерировать изображения очень быстро и получать необходимое. Останется лишь немного поправить в графическом редакторе и то не всегда.
3. Свежий взгляд. Порой бренды, которые на рынке уже несколько десятилетий, не знают, чем можно удивить. У Midjourney нет рамок нормы и абсурда, поэтому нейросеть может выдать самый неожиданный, но вовлекающий визуальный контент.
4. Развитие фантазии. Чтобы дать «тз» нейросети, нужно придумать идею и визуализировать ее. Развивать способность мыслить не по шаблону очень важно, чтобы оставаться интересными.
Когда говорят о плюсах, обычно приводят и минусы, но в Midjourney мы их не нашли. Если рассматривать нейросеть как инструмент, который может помочь, но не сделает работу за вас, то она открывает множество возможностей. Нейросети способны как создавать привлекающий контент, так и приносить реальную пользу. Например, генерируя изображения интерьеров, дизайнеры могут найти новые фишки или неожиданные решения, а их клиенты вдохновиться на ремонт и создать идеальный референс.
Провела опыт по созданию видеоролика при помощи нейросетей.
И должна сказать совершенно определенно, что они никогда не заменят человеческий мозг. Нейросеть – это потрясающий инструмент, который позволяет получить результат быстро. Но путь к этому результату складывается из всего того бэкграунда, который у нас уже имеется.
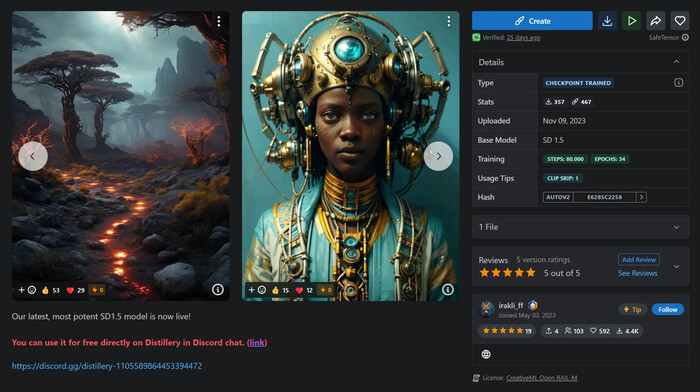
В мире генераторов изображений ИИ выделяются две нейросети: Midjourney и Stable Diffusion. Midjourney может генерировать изображения с исключительным качеством, но его невозможно запустить на вашем компьютере. Stable Diffusion известен тем, что имеет открытый исходный код, но качество генерации у базовой модели все еще далеко от Midjourney.
Теперь появилась Distillery - модель ИИ, которая сочетает в себе уровень контроля Stable diffusion с простотой использования и качеством, близким к Midjourney.
Что такое Distillery?
Distillery - это сервис генерации с открытым исходным кодом, созданный компанией FollowFox, которая является венчурной студией, специализирующейся на создании небольших моделей искусственного интеллекта. По словам представителей компании, они обязуются раскрывать все свои бэкенды и модели сообществу.
Distillery с открытым исходным кодом
FollowFox выпустила свою новейшую модель Cosmopolitan, основанную на Stable Diffusion 1.5 (SD 1.5). Эта мощная модель доказала свою высокую эффективность в общих случаях использования, и теперь Distillery доступна бесплатно в Discord.
В соответствии с философией открытого исходного кода, компания предоставляет открытый доступ к своим методам обучения и кодам.
Процесс разработки включал в себя несколько этапов: выбор и создание набора данных, тонкая настройка модели и смешивание различных версий модели для достижения желаемого результата. Команда явно приложила много усилий, чтобы выпустить Distillery.
Вы можете ознакомиться с моделью с открытым исходным кодом в CivitAI, чтобы запустить ее на своем компьютере.
Если вам интересно узнать, как работает бэк-энд Distillery, прочитайте эту статью.
Запустите локально на своем компьютере, загрузив эту модель
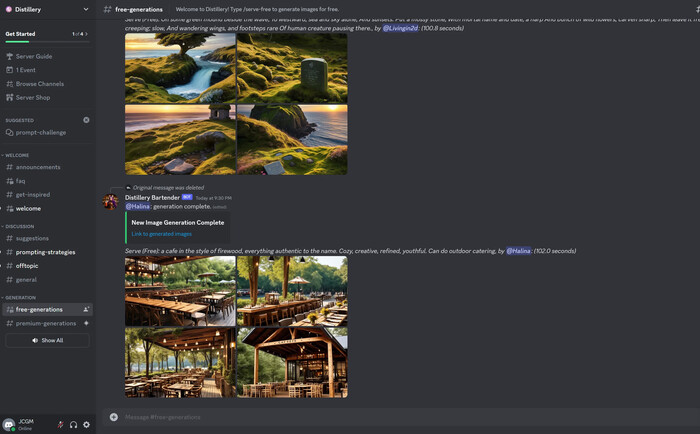
В этом примере я расскажу вам о процессе генерации изображений в Discord. Перейдите на канал free-generations.
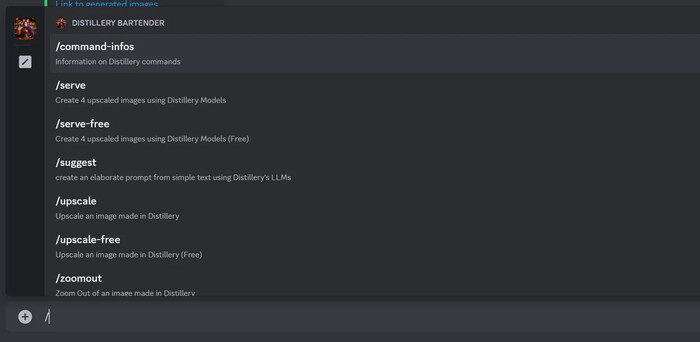
Нажмите клавишу "/", и вы увидите несколько вариантов:
/command-infos - информация о командах Distillery
/serve - создать четыре увеличенных изображения с использованием платных моделей
/serve-free - создать четыре увеличенных изображения с использованием бесплатных моделей
/suggest - создать сложный промпт из простого текста, используя LLM Distillery
/upscale - увеличить изображение с помощью платной модели
/upscale-free - увеличить изображение с помощью бесплатной модели
/zoomout - уменьшить масштаб изображения
Промпт: an image of an astronaut riding a horse on the moon
Генерация изображений заняла около минуты. Что вы думаете о результатах? Я думаю, что они выглядят очень хорошо; уровень детализации исключительный.
Они потрясающе детализированы и не уступают Midjourney.
LoRA
LoRA, или Low Rank Adaptation, - это дополнительный и простой способ добавить предварительно обученный стиль к генерируемым изображениям.
Существуют десятки курируемых LoRA, которые интегрированы в модели Distillery по умолчанию. Для достижения наилучших результатов важно использовать LoRA с соответствующими словами активации в промпте.
Вот несколько примеров:
Промпт: /serve-free an astronaut riding a bike on Mars — lora realism — image
Промпт: /serve-free a photo of Jennifer Lawrence having sitting in a Parisian coffee shop, analog style — lora analog — cfg 5 — seed 2000 — neg deformed, low quality — ar 16:9
В настоящее время пользователям доступно 90+ различных стилей. Пользователи могут объединить до пяти различных LoRA в одном промпте, что может привести к неожиданным творениям. Мне нравится возможность сочетать столько стилей и влияний в одном изображении.
Уникальной особенностью Distillery является возможность слияния стилей и использования изображений в качестве основы для генерации. Ниже показано, как объединить изображение воина с фоном пляжа Ипанема, используя функции управления и адаптации Distillery.
Это потрясающе.
Вот еще один пример практического использования Distillery. Конечный результат, который предполагается получить, представляет собой смесь реализма и волшебства, символизируя открытые двери для безграничных творческих возможностей. Для получения результата в качестве базового используется изображение "открытого окна", а второе изображение - для стилистической обработки.
Изучение всех функций, моделей, стилей и вариантов их использования в Distillery займет некоторое время, но как только вы освоите их, это станет невероятно интересным занятием, потому что вы сможете использовать все вместе и начать смешивать стили и изображения, чтобы сделать новые открытия.
Цены
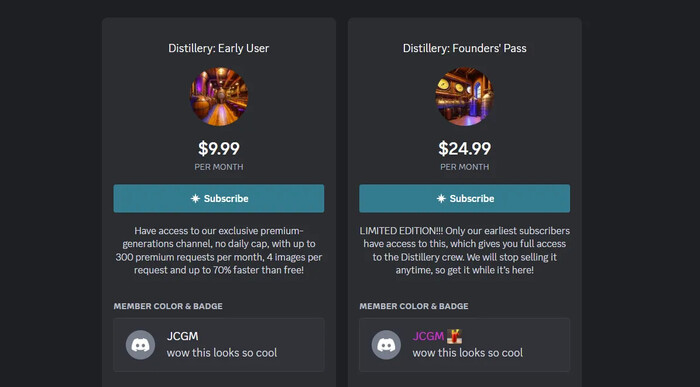
Distillery - это freemium-продукт на Discord с тремя тарифными планами:
Free - дает вам 10 бесплатных генераций в день. При каждом бесплатном запросе вы получаете четыре изображения высокого разрешения (1024x1024 пикселей).
Early User - стоимость 9,99 доллара в месяц. Вы получаете 300 премиум-генераций в месяц без ограничения по количеству ежедневных генераций. При каждом запросе вы получаете 4 изображения (в отличие от 2, предоставляемых в бесплатном варианте).
Founders' Pass - за 24,99 доллара вы получаете 1 000 премиум-запросов в месяц (в 3,33 раза больше, чем у Early User). Участники Founders' Pass получат пожизненный доступ ко всем будущим публичным уровням и другим предложениям.
Обратите внимание, что это все еще альфа-версия модели и в будущем она может быть улучшена.
Мы должны подчеркнуть, что это все еще наша MVP. У нас огромные планы на Distillery на ближайшее будущее, и мы с нетерпением ждем возможности рассказать о них в ближайших постах.
В целом, Distillery - это замечательная модель изображений с открытым исходным кодом, которая конкурирует с Midjourney по качеству и при этом обеспечивает максимальный контроль над процессом генерации. Открытый исходный код модели изображения также делает ее привлекательной для тех, кто хочет интегрировать ее в свои собственные продукты.
Distillery все еще находится в разработке, поэтому в следующих итерациях, скорее всего, будут внесены улучшения. Мы будем внимательно следить за развитием этого продукта в ближайшие месяцы!
Друзья, всем привет, долгожданное продолжение обзора на графическую нейросеть Fooocus, уже версии v2.1. Это видео полностью посвящено Input Image.
Вы узнаете как работают вариации, чтобы сделать похожее изображение, и апскейл, чтобы увеличить картинку. Как работает каждый ControlNet на вкладке Image Prompt, и поймете когда какие использовать, чтобы совместить несколько изображений или сделать обложку с текстом, и узнаете как заменить лицо. Поймете как использовать InPaint и OutPaint, чтобы изменить то, что уже нарисовано, или раздвинуть границы изображения.
Друзья, всем привет, в прошлой статье Fooocus v2 — бесплатный Midjourney у вас на компьютере, вы познакомились с рисующей нейросетью которая вполне способна заменить Midjourney, узнали как её установить, как пользоваться, за что отвечают все настройки и как работают режимы, как писать запросы, чтобы нейросеть вас понимала.
Из этой части вы узнаете как с помощью нейросети Fooocus можно дорисовать любое изображение выйдя за его границы, изменить любую деталь на изображении, узнаете как добавить на свою генерацию текст, наложить свое лицо или как создать изображение по вашему референсу. Сегодня я расскажу про раздел Input Image.
Вкладка Upscale or Variation
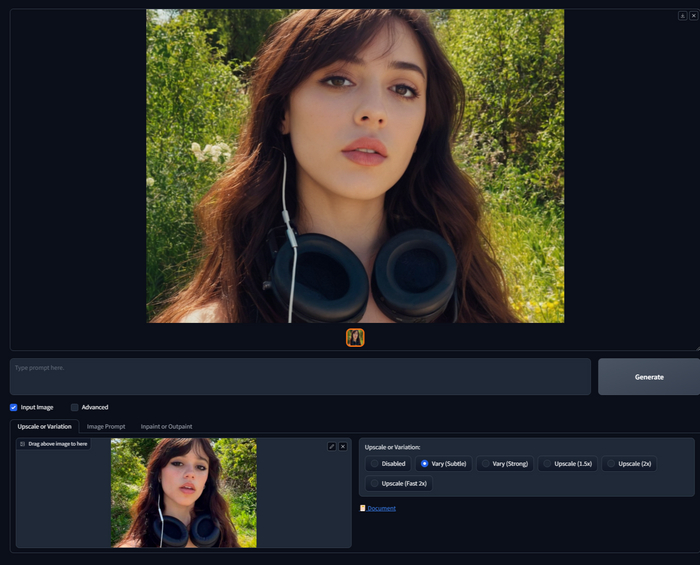
Ставим галочку на Input Image и попадаем в мир роскоши и комфорта, на вкладку где вы можете либо создать вариации уже существующего изображения, либо увеличить изображение. Это может быть как то, что вы сгенерировали, так и ваша фотография. Чтобы что-то заработало нам надо загрузить изображение, я для примера возьму фотографию Джены Ортеги, которая играла Уенсдей в одноименном сериале от Нетфликс.
Variation - Вариации
Допустим нам нельзя использовать фотографию Джены, например в коммерческой публикации, но она идеально соответствует нашей задаче, для рекламы наушников например. Выбираем в таком случае Vary (Subtle), чтобы получить то же самое, что изображенона загруженном изображении, в нашем случае девушку в лесу в наушниках, нам даже запрос писать не нужно, нейросеть сама поймет что нужно сделать. Если будем использовать Vary (Strong), то такого сходства с загруженным изображением уже не получим, оно будет просто "на тему", режим Vary (Strong) лучше работает для того, чтобы сделать вариацию генерации, где используется запрос.
Вариации отличный и простой способ получить собственную версию любого изображения, но что делать, если изображение нужно использовать, например для печати, как увеличить его разрешение?
Upscale - Увеличение
A picture of a beautiful girl with headphones around her neck walking in the woods
В положении Upscale происходит увеличение изображения, можно выбрать увеличение в 1.5 или 2 раза, есть еще 2x Fast, но он делает ощутимо хуже. Важно понимать, что новые детали таким образом не появятся, изображение просто будет увеличено с некоторым количеством едва заметных артефактов. Если необходимо вы можете несколько раз по кругу закидывать полученное изображение в апскейл, для этого просто перетащите его сверху в форму ниже. А мы переходим дальше, к самому мощному инструменту.
Вкладка Image Prompt
close-up female portrait. road, retrowave colors
Вкладка Image Prompt позволяет вам использовать в качестве подсказки изображение, и сделать это большим количеством способов, используя различные модели ControlNet. Комбинируя разные способы вы можете получить совершенно любое изображение. Вот в примере выше я взял фотку Джены, текст на прозрачном фоне, пейзажик и ретро фотографию жигулей. С первой картинки я получил надпись, со второй позу, расположение и эмоцию девушки, с третьей часть фона и с четвертой часть палитры. Невероятный результат, по очень простому запросу. Ниже я расскажу как работает каждый из режимов, чтобы увидеть эти дополнительные настройки нажмите на галочку Advanced.
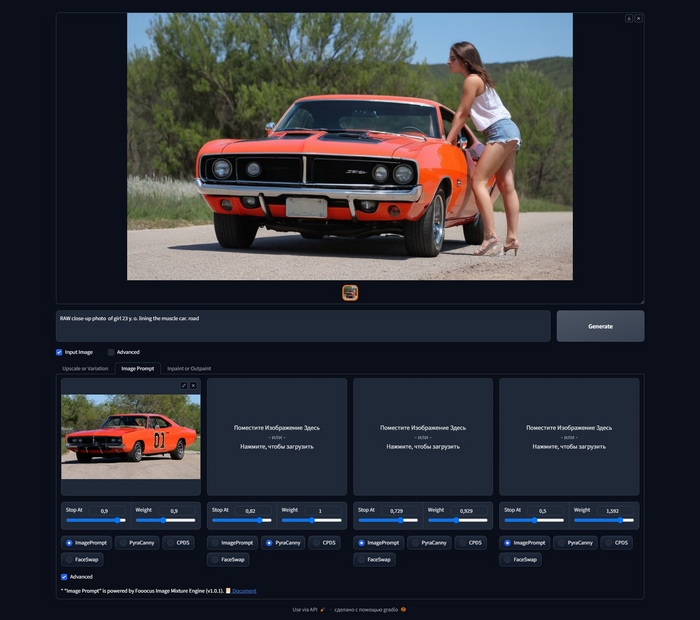
ImagePrompt - Стиль и содержимое
Режим Image Prompt он же СontrolNet IP adapter создан для того, чтобы вы могли использовать в качестве запроса изображение, при том забирает с референсного изображения Image Prompt не только стиль, но и содержимое, т.е. улавливает контекст. Покажу на простом примере. Загружаем фотографию ретро автомобиля, пишем простой запрос RAW close-up photo of girl 23 y. o. lining the muscle car. road, я не пишу в запросе ни модель машины ни цвет, но получаю фотографию девушки рядом с очень похожей машиной, на ту что я загрузил в качестве референса.
RAW close-up photo of girl 23 y. o. lining the muscle car. road
Таким же образом можно взять стиль с любого изображения. Еще пример: я нашел классную картинку с разрушенным городом на PromptHero, это сайт где можно найти интересные примеры и запросы для нейросетей. Картинка атмосферная, мне нравится, но она сделана в миджорни и её запрос мне не поможет. К тому же мне нужна такая же только с перламутровыми пуговицами горизонтальная и с плюшевым медведем. Задачка кажется сложной.
Чтобы получить похожую картинку только по запросу придется постараться. Можно поступить проще, загружаю это изображение в Image Prompt, пишу запрос Photo of a gloomy ruined city, close-up of a teddy bear, и получаю сразу же отличный результат, ровно такой, каким я себе представлял. Драматичная темная картинка с плюшевым мишкой который героически идет к светящемуся зданию, сразу хочется узнать что будет дальше.
Photo of a gloomy ruined city, close-up of a teddy bear
Но что делать, если результат не устраивает, всегда можно подкрутить Stop At, он отвечает за то, когда нейросеть перестанет смотреть на то изображение которое вы загрузили. По умолчанию стоит на 0.5. т.е. половину всей генерации фокус придерживается загруженного изображения, а потом уже генерирует как хочет. Часто бывает полезно увеличить или наоборот уменьшить это значение.
Увеличивать стоит если вы хотите хорошо перенести визуальный стиль. А уменьшить, если вам достаточно лишь общей композиции, так вы дадите нейросети больше свободы. Кроме того можно увеличить влияние изображения, с помощью ползунка Weight, чем больше вес, тем сильнее влияние на генерацию, выше интенсивность влияния, но одновременно с этим уменьшается и креативность нейросети, поэтому находите баланс.
Когда использовать Image Prompt? Когда надо скопировать стиль, атмосферу, освещение, а при высоком Weight и композицию изображения.
PyraCanny - Контуры
Canny создает так называемую карту, того, что изображено на картинке которую вы загружаете. Это карта состоит только из ключевых контуров, на ней отсутствует информация о цвете или стиле. Эти контуры лягут в основу вашей будущей генерации.
Например я сгенерировал милого кролика, но мне хочется сделать кролика в другом стиле, при этом я хочу полностью сохранить его пропорции. Загружаю кролика в Image Prompt, выбираю PyraCanny, ставлю Stop At на 0.9 или даже на 1, чтобы сохранить пропорции до конца генерации. И просто по промпту Bunny начинаю переключать различные встроенные в фокус стили, пока не найду то, что мне нравится. Про стили подробно рассказывал в первой части. Вот такой получается результат у меня.
Bunny + стили
Очень полезный инструмент, чтобы сделать вариации персонажей, иконок в разных стилях. Кстати вам не обязательно загружать готовое изображение, вы можете загрузить и контурный набросок сделанный от руки и Фокус попытается сгенерировать по нему изображение.
Еще PyraCanny отлично подходит чтобы стилизовать текст. Все что вам нужно, это сделать PNG изображение текста, на прозрачном фоне, для этого подойдет любой редактор, онлайн могу посоветовать photopea.com он удобный и бесплатный. Я предпочитаю делать обводку тексту, так обычно интереснее стилизуется. Чтобы текст был читаемым и не прыгал стоит поставить Stop At на 1 и Weight на 1.2, а иногда и выше, если текст искажается или недостаточно виден.
Когда использовать PyraCanny? Когда надо скопировать содержимое изображения, персонажа, архитектуру, черты лица или композицию, или добавить текст.
CPDS - Глубина и контрастность
confused Keanu Reeves as John Wick in the desert, holding a gun
CPDS создает карту на основе резкости и контрастности загруженного изображения. После обесцвечивая изображения, остается только информация о силуэте, очертаниях и резкости и глубине. Это позволяет перенести в вашу генерацию любую сложную сцену или позу, не ограничиваясь при этом строгими контурами как это делает Canny.
Для примера я взял знаменитую сцену с Траволтой из фильма Криминальное чтиво и воссоздал с участием других персонажей: Гомера Симпсона, Гэндальфа, Джона Уика, Дарта Вейдера и еще нескольких.
Получилось отлично, а главное достаточно просто, запросы были в духе confused Homer Simpson.
Когда использовать CPDS? Когда нужно перенести силуэты и глубину, воссоздать сложные сцены, позы, глубину в пространстве.
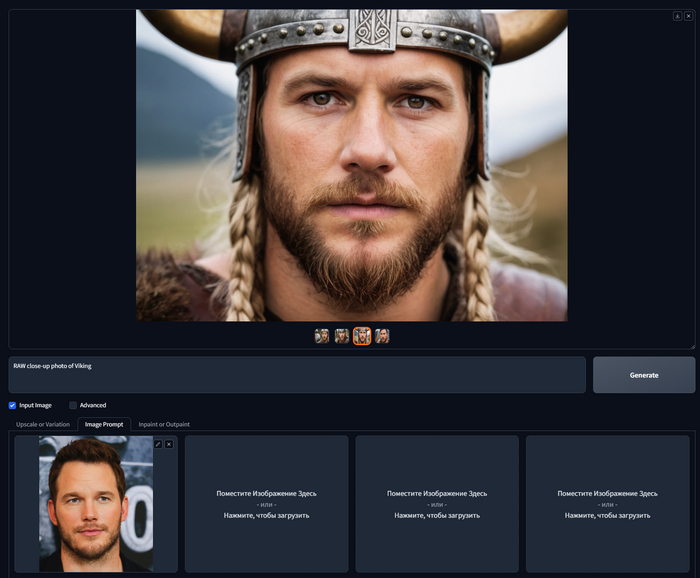
FaceSwap - Замена лица
Вот мы добрались и до единственной ложки дегтя, то, что разработчик называет FaceSwap, на самом деле никакой не FaceSwap, а просто IP Adapter, как и Image Prompt, но обученный на лицах, он их вырезает и пытается встроить в генерацию. Но, честно говоря, это работает плохо. Такое ощущение, что пьяный друг кому-то рассказал как вы выглядите, и генерация это результат по мотивам такого описания. Определенно есть какое-то сходство, но есть и различие , которое пугает эффектом зловещей долины. Как я не крутил настройки так и не смог заставить этот режим работать хорошо. Разве узнаете вы на этой фотке Криса Пратта, Звездного лорда из Стражей галактики? Я нет.
RAW close-up photo of Viking
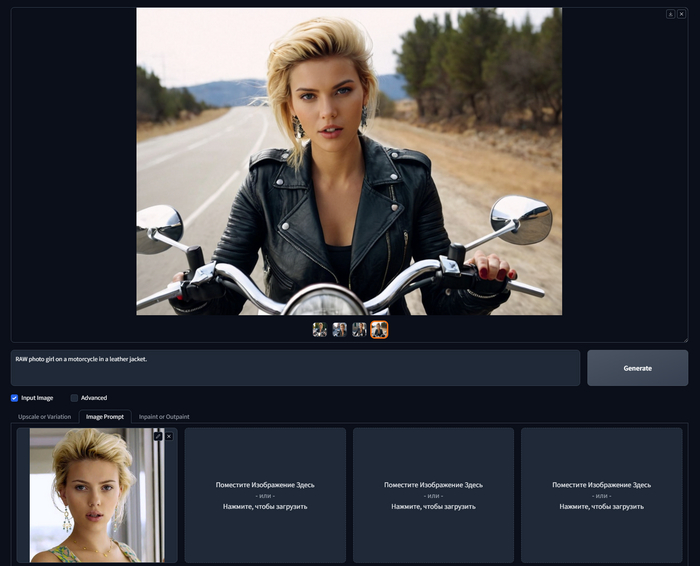
Хотел бы я сказать, что с женщинами получается лучше, но нет, вместо Скарлетт Йоханссон на мотоцикле, у меня получается её троюродная сестра, видимо.
RAW photo girl on a motorcycle in a leather jacket
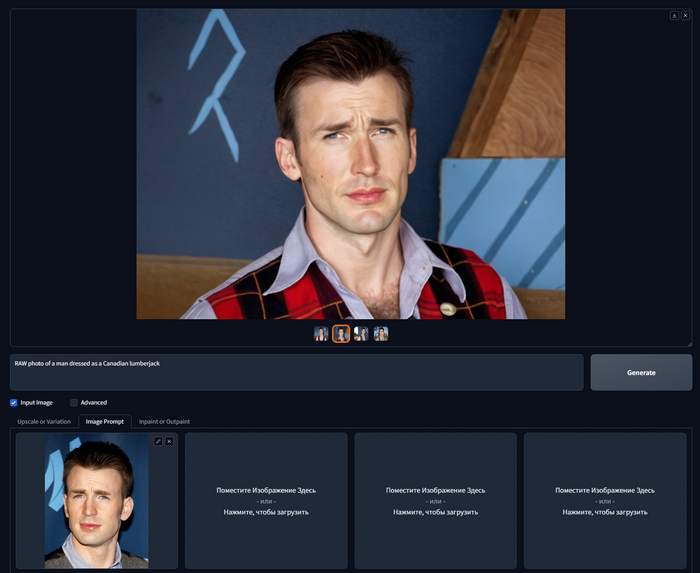
Если вы думаете что получится просто поднять Weight, то и тут вас ждет разочарование, если его поднять, то композиция, ракурс и цвета будет наследоваться с загруженного изображения, а то что вы пишите в запросе практически не будет учитываться. Для примера я загрузил фотку Криса Эванса, и выкрутил вес до 1.4, да так лицо действительно чуть больше похоже, это уже не родственник, а конкурс двойников. Но теперь все время пролезает кусок фона с референса, а ракурс лица невозможно изменить.
RAW photo of a man dressed as a Canadian lumberjack
Настоящий же FaceSwap очень аккуратно и тщательно смешивает черты лица с оригинала с загруженным лицом и практически всегда дает отличный результат, я об этом рассказывал в статьеСтань героем мемов! Делаем гифки со своим лицом с помощью нейросетей, посмотрите, очень интересная.
Я не могу назвать реализацию замены лиц в фокусе действительно работающей. Будем надеяться что в будущем разработчики либо улучшат этот редим, либо сделают тот классический FaceSwap который мы знаем по другим приложениям.
Когда использовать FaceSwap? Когда вы хотите чтобы у всех ваших персонажей было похожее лицо или типаж, либо готовите базовую картинку для замены лица в другом приложении, например в ReActor.
Различные комбинации
Самое классное, что вы можете комбинировать возможности Image Prompt как угодно, загружайте разные изображения, добавляйте текст, стили, и конечно управляйте запросом. Вот еще несколько классных примеров, которые были бы сложно получить только по текстовому описанию.
anime character in a cloud of fire, super strength
Close-up portrait of a girl on road, foggy, fireflies
Character portrait, a teddy bear dressed as a knight rests on the steps of a temple.
Специально для моих подписчиков на Бусти я собрал пак из 1 800 необычных и интересных изображений - референсов, для использования в Image Prompt. В этом материале многие изображения как раз оттуда. Теперь добавить необычный эффект, сделать интересный фон или стиль можно в пару кликов и без сложных запросов. Подпишитесь на Бусти и вы, там много полезных материалов, записи обучающих стримов и доступ в наш закрытый чат. Только поддержка подписчиков позволяет мне писать такие подробные гайды и инструкции для вас друзья. А мы двигаемся к двум оставшимся, но не менее крутым функциям, впереди Inpaint и Outpaint.
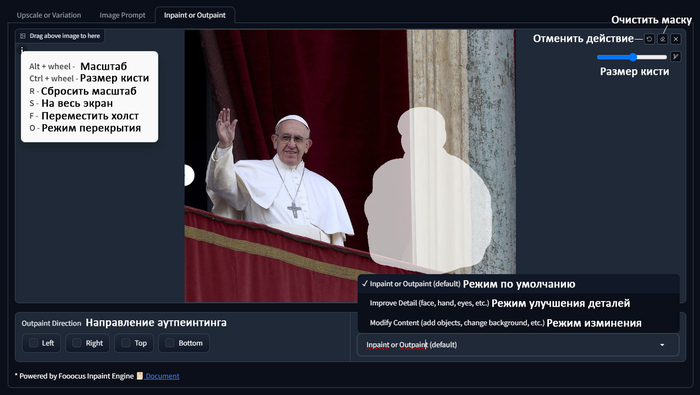
Вкладка Inpaint or Outpaint
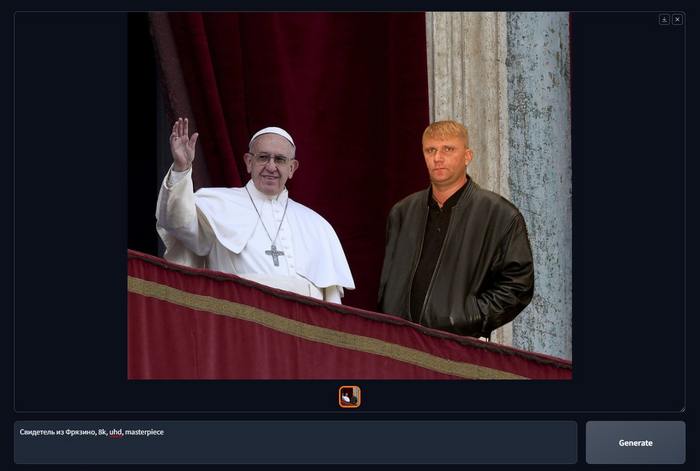
Конечно Свидетель из Фрязино уже был на этом фото c Папой Франциском, когда я его нашел, сгенерировать его не получится, но на этом примере я могу показать как можно изменить реальное изображение, прежде чем мы приступим к аутпеинтингу.
Inpaint - Изменяем изображение
Шпаргалка по быстрым клавишам и основным функциям
Как часто бывает, что на хорошей фотографии есть что-то, чего там быть не должно, раньше исправить такое фото было сложно. Теперь же есть инпеинтинг, простая механика - закрашиваем то, что нам не нравится маской, пишем что хотим вместо того, что под маской и получаем отличный результат. При том использовать запрос не обязательно. У инпеинтинга есть три режима:
Inpaint or Outpaint (default) - режим включенный по умолчанию, он же используется на аутпеинтинга. Подходит в целом для любой задачи, но разрешение в этом режиме будет ниже чем в двух других.
Improve Detail (face, hand, eyes, etc.) - режим улучшения деталей, отлично подходит для улучшения детализации лица, рук, глаз или других объектов.
Modify Content (add objects, change background, etc.) - режим изменения, в этом режиме удобно изменять или добавлять, то чего на изображении не было.
В режимах Improve и Modify появляется дополнительное поле, в котором можно указать конкретные изменения, это сделано чтобы вам не пришлось менять основной запрос, а потом вспоминать что там было.
Например, если мы хотим избавиться от персонажа на фото, то просто запустим генерацию с пустым запросом, либо с описанием той поверхности которая находится рядом, например стена или природа. Точно так же мы можем заменить персонажа на любого другого, достаточно лишь описать его. Конечно если делать это так же грубо как я на этих примерах, то будут заметны артефакты. Но если у вас есть тачпад, то вы сможете очень аккуратно нарисовать маску.
Но, этим не ограничиваются возможности инпеинтинга, еще вы можете: заменить фон, поменять одежду или прическу, улучшить лицо, добавить то, чего не хватает, удалить то что есть, возможности ограничиваются только вашей фантазией. На мой взгляд инпеинтинг самая мощная механика в работе с изображениями, а в фокусе она к тому же максимально удобно реализована.
Outpaint - Расширяем изображение
Атупеинтинг позволяет выйти за границы изображения, работает он очень просто. Вам достаточно выбрать сторону, в которую надо расширить изображение, влево, вправо, вверх, или вниз, вы конечно можете поставить сразу все 4 галочки, но так качество будет хуже, лучше делать одну сторону за раз. Вы можете как указывать запрос, так и нет. Допустимо немного изменять запрос между итерациями аутпеинтинга, чтобы добиться желаемого результата.
Вы можно делать аутпеинтинг много раз подряд, перетягивая сгенерированную картинку вниз, но важно помнить что каждый раз разрешение изображения становится больше и в какой-то момент у вас просто не хватит видеопамяти.
Аутпеинтинг прекрасная механика которая не только позволяет изменить размер кадра и соотношение сторон, заглядывая за границу несуществующего, но и отличный инструмент для создания больших детализированных изображений. Как это, его разрешение 4674х2772, но для вашего удобства я превратил его в видео. Есть конечно косячки на склейках, но их можно убрать множеством других способов.
Друзья, на этом мы закончили изучать возможности Input Image в Фокусе, поздравляю вас! Теперь вы знаете как делать вариации, увеличивать изображения или генерации, как использовать вкладку Image Prompt и все виды ControlNet, чтобы получить уникальное изображение созданное по вашему референсу, содержащее текст или даже похожее на вас. И конечно же вы теперь сможете изменить что-то в уже существующем изображении с помощью инпеинтинга или заглянуть за границы изображения с помощью аутпеинтинга.
Cinematic still of cat holding shopping bag full of vegetables with paws, shopping with smile in a market
Делитесь тем что у вас получается в нашем чате нейро-энтузиастов и увидимся на стримах, ближайший, уже 28 ноября в 20:00 на Бусти, вход как и всегда свободный, подпишитесь чтобы не пропустить начало. Разберем Фокус по косточкам, отвечу на все вопросы.
А еще я рассказываю больше о нейросетях у себя на YouTube, в телеграм и на Бусти. Буду рад вашей подписке и поддержке. Всех обнял.
Теперь приз обещан тому, кто выиграет в его собственном конкурсе. Чтобы сделать это, вам придется отличить творчество нейросети от настоящего.
В этой статье я попытаюсь разобрать опубликованное видео и проанализировать его содержимое для выявления ИИ. Начнем с краткого содержания:
Автор и его команда c канала Zonom попытались повторить «достижение» жителя США по имени Джейсон Аллен, о котором ранее сообщалось в новостях. Тому удалось одержать победу в крупном творческом конкурсе с помощью генерации средствами «Midjourney». По словам американца, он потратил на подборку идеального варианта большое количество времени, а также сам придумал идею и сформулировал запрос, поэтому считает присужденное ему первое место заслуженным. Сторонники противоположных мнений назвали его мошенником и заявили, что творения нейросети не должны соревноваться с картинами настоящих художников.
С того момента прошло немало времени, и нейросети уже прогремели на весь мир. Но повлияла ли общеизвестная скандальность новых средств ИИ на возможность побеждать в конкурсах? Герой видео решил это проверить.
Первый конкурс состоялся в рамках ежегодного состязания художников «Мифы рождества», организованного площадкой преподавателей рисования «FUNGI». Авторы социального эксперимента применили две разных нейросети для генерации изображений, но ни одна из них не выдала цельного качественного результата, поэтому им пришлось «склеить» удачные фрагменты.
Несмотря на вполне убедительный «рисунок», приз достался другому участнику. В итоговом разборе работы принял участие и сам директор цифровой школы рисования, но даже ему не удалось распознать фальшивку.
Организаторы второго конкурса «Монстродевочки» от студии разработки игр «Cavemen programmerz» заранее предупредили участников о недопустимости попыток нейросетевого подлога, однако это не остановило авторов эксперимента.
Общественность довольно быстро выявила фальшивые картины и все закончилось закономерным скандалом, повеселившим публику.
Третий конкурс проходил в сети магазинов «Шишка». От участников требовалась креативная фотография с символикой организатора, при этом допускалось использование средств фотомонтажа.
И хотя генерации героев видео полюбились жюри и легко прошли во второй тур, по итогу они не смогли занять первое место… По крайней мере, так было поначалу. В последний момент призовой пьедестал неожиданно претерпел изменения. Выяснилось, что главный финалист совершил так называемую «накрутку» голосов, доказательства этому были найдены самими организаторами. Состоялся пересмотр и повторное объявление победителей. На сей раз Zonom и его помощники очутились на первой строчке рейтинга. Это означало, что им достается главный приз – Playstation 5. После церемонии вручения желанный подарок был запечатлен на камеру.
На этой ноте видео плавно переходит в научно-философскую плоскость и начинает пестреть умозаключениями на тему будущего человечества, которое будет вынуждено мириться с возможностями ИИ. Но давайте пропустим пространные рассуждения и перейдем к делу: ответим на брошенный автором вызов и попробуем вычислить нейросетевой контент в опубликованном им видеоблоге. К тому же, создатель оставил для зрителей подсказку, и мы не имеем права ею пренебречь.
Музыкальный контент.
Исходя из шпаргалки, оставленной в описании, в видео могут звучать от нуля до пяти композиций, созданных не человеческими усилиями. Вариант «Все музыкальное сопровождение написано компьютером» мы не рассматриваем, потому что уже при первом просмотре встречаются некоторые узнаваемые музыкальные темы из стандартной фонотеки контентмейкеров. Возможен ли вариант «Все музыкальное сопровождение написано людьми»? Сомневаюсь, ведь это было бы скучно. Зачем устраивать эксперимент, если в наличии нет ни одного сгенерированного компьютером трека?
Идем по порядку: от легкого к сложному. Первым делом заглядываем в описание и смотрим credits, а также в инструментарии самого youtube находим распознанные треки. Таким образом мы уже отсеяли около половины всех композиций и узнали их название. Следующий шаг – задействовать SHAZAM. Но чтобы этот способ сработал, придется отсеять голос комментатора, который перекрывает музыкальное сопровождение, с помощью пресловутого vocal remover. Последний этап: дать послушать все оставшиеся под вопросом композиции человеку, занимающемуся музыкой по своему призванию. Тут самое интересное! Он сразу же уловил нейросетевые нотки в мелодии, которая играет во фрагменте с загадками для стримеров.
Последующие мелодии тоже вызвали подозрения, причем все они идут подряд в количестве трех. Неужели это и есть то самое – правильное число? Что ж, возможно, где-то на протяжении всего хронометража спрятаны еще две композиции, – но, если это так, они ничем не отличаются от живой музыки.
Визуальный контент.
На 35-ой и 36-ой минутах видео автор дает нам задание найти одну настоящую фотографию, спрятанную среди десяти искусственных. Давайте проанализируем каждую из них.
В цветочной лавке присутствуют предметы странной формы и непонятного назначения, а форма и размер полок сильно разнятся. Я не флорист, но сомневаюсь, что настоящий инвентарь выглядит так. На футболке-поло самого продавца присутствуют лишние дырки для пуговиц, фартук вызывает подозрения, а ручка окна на заднем плане резко прерывается и не имеет логичного крепления к раме. Вердикт: фальшивка.
Казалось бы, перед нами типичный сварщик. Но присмотритесь к искаженному фону. Впрочем, это не самое главное. В руках рабочего бумажный стаканчик для кофе. Вы когда-нибудь видели фастфуд-тару с керамическими ручками? Вот и я не видел. И это еще не все. Его роба не соответствует профессии, а к электродному держаку не присоединены провода. Вердикт: подделка.
Истинное происхождение черно-белой «фотографии» с девушкой за ветриной выдает неразборчивый генеративный текст на ценнике блюда, а также странный «шрам» на носу и подозрительные колтуны в волосах. Вердикт: фикция.
Улыбающийся парень выглядит достаточно правдоподобно, но есть небольшая проблема с зубами, а щетина больше похожа на трещины. Вердикт: больше склоняюсь к нейросети, но однозначного ответа дать не могу.
Псевдофотографию с волной я сразу смог нагуглить, и как оказалось, она имеет под собой целую историю, связанную с очередным конкурсом. Похоже, автор оставил для нас отсылку. Эта работа некогда тоже заняла первое место среди настоящих фотографий, однако после победы участник чистосердечно признался в использовании AI и решил вернуть присужденные ему призовые.
Ягоды в ладонях выглядит весьма убедительно. На этой фотографии я не смог обнаружить однозначных признаков присутствия «цифровой руки». Мы сможем нащупать нить истины только методом исключения, поэтому не задерживаемся и переходим к следующим вариантам. Вердикт: пока остается под вопросом.
Девушка-диджей выдает себя странным техническим устройством наушников, неживым взглядом и прочими подозрительными фрагментами. Вердикт: пожалуй, нейросеть.
Чернокожая братия имеет едва заметные проблемы с баскетбольным мячом и козырьком кепки, но самым явным признаком нейросети является неудачно сгенерированное лицо на заднем плане. Вердикт: ненастоящая фотография.
Сперва я подумал, что ангельское изваяние – это и есть та самая живая фотография, которую мы ищем. Но интуиция меня подвела. Сосчитайте пальцы на ноге. Их шесть. Вердикт: обман.
Толпа в метро смотрится очень неплохо, но чем дольше всматриваешься в изображение, тем больше возникает вопросов. Вагоны «сращиваются» со стенами, а некоторые люди будто стоят на каких-то возвышениях, ну а пара лиц и вовсе искажены. Вердикт: ну, вы сами поняли.
Забавно, что друг за другом нам были продемонстрированы лишь 10 изображений, однако на общем плане в конце фрагмента видеоряда затесалась еще одна потенциальная фотография с веснушчатой девушкой. Это простая уловка, чтобы сбить зрителя с толку. Почти нет сомнений, что это тоже нейросетевая генерация.
Итак, после всех наблюдений мы делаем вывод: правильным вариантом является горсть черешни. Пусть я и метался между двумя вариантами, все же ягоды мне импонируют больше.
Информационный контент.
Наконец-то мы добрались вплавь до знакомой мне территории. Будучи рыбой в воде, воспитанной информационными акулами в океане слов, осмелюсь заявить настолько твердо и четко, что мне позавидовал бы сам Борис Николаевич Ельцин: текст сценария к обсуждаемому видео однозначно не мог быть написан сугубо компьютером. Эпитеты, метафоры, абстракции, живая и стройная подача, сложные речевые обороты – все в наличии. Такое искусственному интеллекту не под силу… пока. Невозможно доподлинно определить, могла ли быть основа и структура повествования предложена нейросетью, а впоследствии отредактирована, или же компьютер вовсе не притрагивался к рассказу о приключениях автора. Придется выбирать из двух вариантов – словно подкинуть монетку. Пятьдесят на пятьдесят. И право подбросить эту монетку я оставляю вам.