Всем привет! Что посоветуете: Java или Go ? Golang меня привлекает больше, но на нём вакансий намного меньше. Щас учусь в универе, уже хочу определиться с языком программирования для бекенда. Java уже знаю немного, т.к. в вузе его преподают. Spring тоже трогал. Как думаете ? Или может другие яп посоветуете ?
Большинство нынче популярных языков (C#, Java, C++, JS, Python) не работают с многопоточною настолько хорошо, насколько бы нам того хотелось. Почему так?
Потому что они были придуманы в то время, когда ещё не был придуман процессор с двумя ядрами. Они были придуманы для работы на одном ядре, без нормальных (оптимизированных и простых) инструментов параллелизации кода
То, что я назвал выше - признак старых языков. Go и Rust под эту категорию не подходят, потому что к моменту их создания, многоядерные процессоры уже были... были. За счёт этого, они относительно просто и эффективно работают с многопоточностью (жрут меньше памяти, работают быстрее, работать с ними программисту проще)
Технологическое будущее за нативной многопоточностью
Документация служит всеобъемлющим руководством, объясняющим, как взаимодействовать с сервисом через API. Хорошая документация ускоряет процесс разработки, уменьшает количество ошибок и улучшает общее качество интеграции, поскольку включает в себя:
Описание конечных точек (эндпойнтов).
Форматы запросов и ответов.
Методы аутентификации.
Обработку ошибок.
Примеры использования.
Представляем подборку лучших инструментов для создания API-документации.
Swagger
Swagger – один из самых популярных инструментов: он поддерживает много языков программирования и предоставляет удобный интерфейс для проектирования и документирования API. Swagger позволяет определять конечные точки, форматы запросов и ответов, а также методы аутентификации. Кроме того, он предоставляет интерактивные инструменты для исследования и тестирования API.
Apidog
Apidog – комплексный инструмент для разработки, документирования и управления API. Он предлагает автоматическую генерацию интерактивной документации и возможность тестирования API в реальном времени. Apidog также поддерживает генерацию кода на разных языках программирования и предоставляет широкие возможности для настройки стиля документации.
ReDoc
ReDoc – опенсорсный инструмент, поддерживающий спецификации OpenAPI 2.0 и 3.0. Он отлично подходит для публикации интерактивной API-документации и предлагает удобную навигацию с настраиваемым поиском, а также стильный, адаптивный дизайн с возможностью настройки тем.
DapperDox
DapperDox – опенсорсный OpenAPI-рендерер, совместимый с OAS 2.0 и 3.0. Он позволяет использовать контент в формате Markdown для создания диаграмм и предоставляет модуль исследования структуры API для практических экспериментов.
Theneo – генератор документации, использующий ИИ для автоматического описания API. У него простой интерфейс, напоминающий Notion, и он поддерживает интеграции с Swagger, Postman и GitHub.
Sphinx
Sphinx – мощный генератор документации, широко используемый в Python-сообществе. Он поддерживает много языков и предлагает широкие возможности для настройки. Sphinx может генерировать документацию в разных форматах, включая HTML, PDF и ePub.
Javadoc
Javadoc специально разработан для документирования Java-кода. Он извлекает комментарии и аннотации из исходного кода для создания HTML-документации с подробным описанием классов, методов и полей.
DocFX
DocFX – генератор статических сайтов, разработанный Microsoft и с ноября 2022 года поддерживаемый сообществом .NET Foundation. Предлагает настраиваемые шаблоны для создания документации и лендингов.
Doxygen
Doxygen поддерживает C++, С, Objective-C, Python, Java, IDL, PHP, C# и Fortran, может генерировать документацию в разных форматах, включая HTML, PDF и LaTeX.
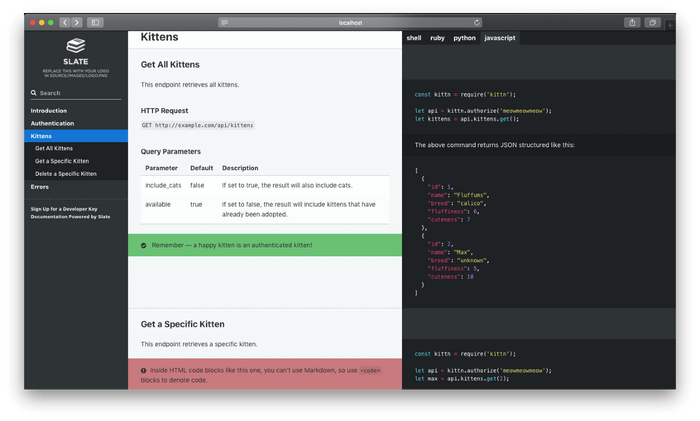
Slate
Slate фокусируется на простоте и удобстве использования, предоставляя удобный, современный, адаптивный интерфейс для API-документации. Он поддерживает Markdown, подсвечивает синтаксис больше 100 языков и предлагает интерактивную консоль для тестирования API-эндпойнтов.
Интерактивная API-документация на Slate
➕➕🧩 Интересные задачи по C++ для практики можно найти на нашем телеграм-канале «Библиотека задач по С++»
Docusaurus
Docusaurus предназначен для создания современной интерактивной документации и любых других статических сайтов. Он поддерживает все популярные языки, предлагает настраиваемые шаблоны, имеет встроенную функцию поиска на базе Algolia, поддержку локализации и версионирования.
😎 Автоматизация слепых SQL-инъекций на основе логических значений
Слепая SQL-инъекция на основе логического значения (Boolean-Based Blind SQL Injection) – тип SQL-инъекции, где атакующий не видит прямого вывода SQL-запроса, но может делать выводы на основе логических (истина/ложь) ответов от приложения (эти ответы могут проявляться в виде разных кодов состояния HTTP, разного содержимого ответа или реже разных заголовков).
Анализ ответов позволяет злоумышленникам определить структуру базы данных, а в дальнейшем – буквально символ за символом выяснить, какая информация в ней содержится. Пентестеры и этичные хакеры знают, что это один из самых трудоемких типов атак для ручной эксплуатации. Но несколько простых Python-скриптов помогают полностью автоматизировать процесс:
Простейший метод – извлекать данные по одному символу, используя функции SUBSTRING() и ASCII() в MySQL. Это позволяет узнавать значение каждого символа в строке путем сравнения с ASCII-кодами.
Оптимизированный подход – использовать алгоритм бинарного поиска. Это сокращает количество запросов для определения одного символа с 96 до 7, что значительно ускоряет процесс и делает атаку менее заметной.
Дополнительные приемы для извлечения разных типов данных включают использование подзапросов для выбора данных из произвольных таблиц, объединение значений из нескольких строк в одну строку с помощью GROUP_CONCAT и преобразование разных типов данных (числа, даты и т. д.) в строки, которые легче извлечь.
Для дальнейшего ускорения процесса можно использовать многопоточность с помощью ThreadPoolExecutor из библиотеки concurrent.futures.
Распределенные системы состоят из многих отдельных частей (или узлов), работающих вместе, но физически расположенных в разных местах. Эти части системы должны общаться друг с другом через сеть, чтобы система могла функционировать как единое целое. Хотя коммуникация критически важна, правильно ее организовать бывает непросто: разработчики иногда пытаются использовать один и тот же подход ко всем задачам коммуникации, что может быть неэффективно. Важно понимать, что существуют разные способы организации коммуникации, и выбор правильного метода зависит от конкретной задачи. Рассмотрим основные паттерны коммуникации, которые можно использовать для решения разных задач.
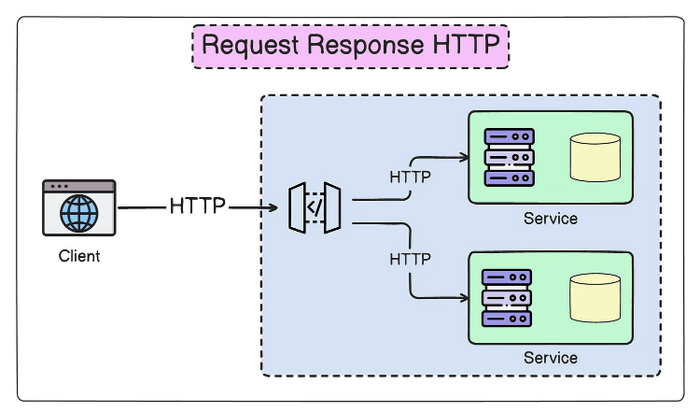
Запрос-ответ с HTTP
Этот синхронный паттерн коммуникации предполагает, что один сервис отправляет запрос другому сервису и ожидает ответа или ошибки, блокируя свою работу до получения результата. REST, наиболее популярный архитектурный стиль для этой модели коммуникации, использует методы протокола HTTP – GET, POST, PUT и DELETE.
HTTP-запрос и ответ
Однако использование этого паттерна может привести к проблемам, если сервисы образуют цепочку взаимодействий: в таком случае сбой одного из сервисов может привести к отказу всей операции, а также к расточительному использованию ресурсов и каскадным сбоям.
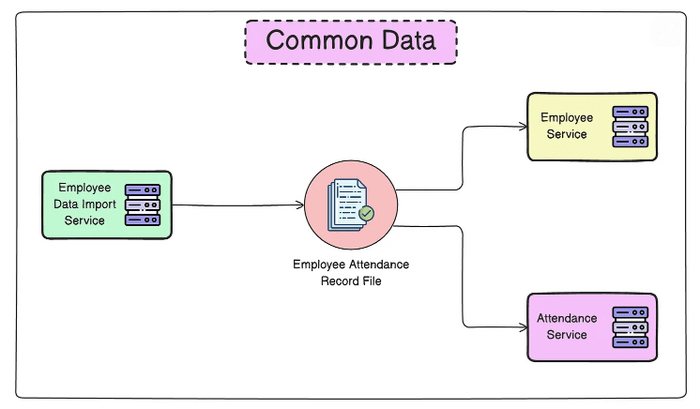
Общие данные
Этот паттерн часто остается незамеченным, поскольку разработчики не всегда воспринимают его как модель коммуникации. В рамках этого подхода один компонент записывает данные в определенное место, а другой компонент считывает и обрабатывает эти данные. Например, один сервис может загрузить файл в облачное объектное хранилище (например, в корзину Amazon S3), а другой сервис затем извлекает этот файл для дальнейших действий.
Общие данные
Главное преимущество этого паттерна – простота реализации и возможность обеспечения взаимодействия между устаревшими и современными системами без проблем совместимости. Однако он не подходит для сценариев, требующих низкой задержки.
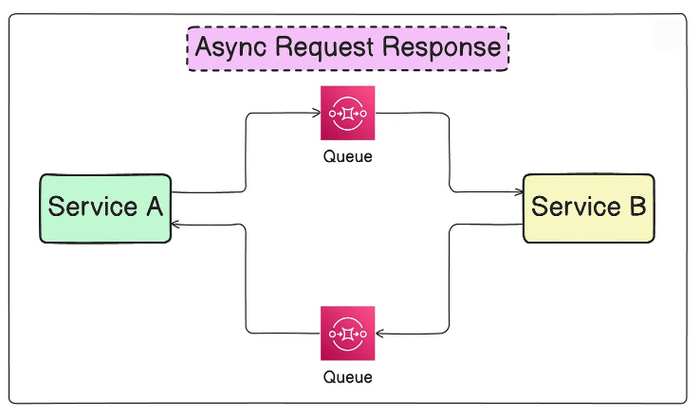
Асинхронный запрос-ответ
В отличие от синхронного подхода, запрос-ответ может быть реализован асинхронно и без блокировки. В этом случае получающий сервис должен явно знать место назначения для отправки ответа. Для реализации этого паттерна идеально подходят очереди сообщений, которые позволяют буферизовать несколько запросов.
Асинхронный запрос-ответ
Основная сложность здесь — корреляция между запросом и ответом: экземпляр сервиса, отправивший запрос, может отличаться от экземпляра, получающего ответ, поэтому требуется способ отслеживания запросов.
🧩☕ Интересные задачи по Java для практики можно найти на нашем телеграм-канале «Библиотека задач по Java»
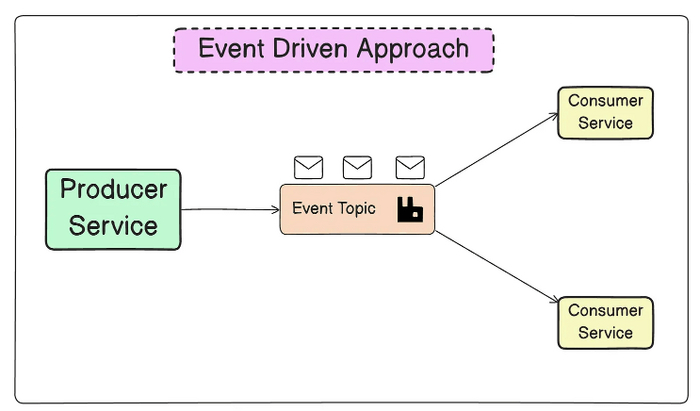
Коммуникация на основе событий
В этом подходе сервисы не общаются напрямую друг с другом, а генерируют события, которые могут быть использованы другими сервисами. Это требует наличия места для отправки данных о событиях и механизма, позволяющего получающим сервисам обнаруживать эти события. Брокеры сообщений, такие как RabbitMQ, могут обрабатывать оба этих аспекта. Издатели используют API для отправки событий в брокер, который управляет подписками и уведомляет подписчиков при поступлении события.
Коммуникация на основе событий
Этот паттерн идеально подходит для создания слабосвязанных взаимодействий между сервисами. Однако брокер сообщений должен обеспечивать надежную доставку событий, их упорядочивание и согласованность. Кроме того, добавляется дополнительный компонент в систему.
🛠️ Инструменты
Postgres Sandbox – ИИ-песочница для работы с PostgreSQL в браузере. Проект реализован на PGlite – легковесной версии PostgreSQL, скомпилированной в WebAssembly и упакованной в клиентскую библиотеку TypeScript. Это позволяет запускать базу данных PostgreSQL непосредственно в браузере, Node.js и Bun без необходимости устанавливать другие зависимости. Размер PGLite – всего 3 Мб после сжатия Gzip, при этом база поддерживает многие расширения PostgreSQL, включая pgvector.
textual-plotext – виджет-обертка библиотеки для построения графиков Plotext. Визуализирует данные из Python-скриптов прямо в терминале.
BunkerWeb – опенсорсный веб-фаервол (WAF), созданный на основе NGINX. Предназначен для защиты веб-сервисов – делает их безопасными по умолчанию. Легко интегрируется в существующие среды (Linux, Docker, Swarm, Kubernetes и т. д.), полностью адаптируется под ваши специфические требования. Предоставляет удобный веб-интерфейс и систему плагинов.
Kardinal – фреймворк для создания сверхлегких временных сред разработки внутри общего кластера Kubernetes. Позволяет быстро и эффективно создавать и удалять рабочие пространства для разработки, тестирования и демонстраций, минимизируя затраты ресурсов и стоимость эксплуатации.
Viking – инструмент для управления удаленными серверами (и группами серверов) через SSH.
Terminus – опенсорсная ОС на базе Kubernetes, которая позволяет создать домашнее облако на собственном сервере. Подходит для любых задач – локального хостинга LLM, хаба по управлению IoT-девайсами, персонального репозитория или рабочего пространства.
Собственное облако Terminus
DeltaDB – легковесная, быстрая и масштабируемая база данных, созданная на основе polars и deltalake. Предназначена для разработчиков и организаций, которым нужно эффективное, простое и гибкое решение для обработки больших объемов данных с высокой скоростью и масштабируемостью.
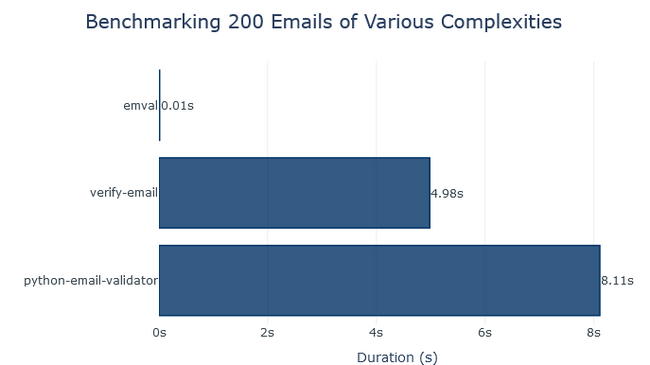
emval – супербыстрый валидатор email-адресов для Python-приложений, написанный на Rust.
emval работает в 100–1000 раз быстрее других подобных модулей
🦫🧩 Интересные задачи по Go для практики можно найти на нашем телеграм-канале «Библиотека задач по Go»
RustPython – интерпретатор Python, написанный на Rust.
Ищу людей которые будут готовы со мной обучаться языку программирования golang с нуля. Что бы если устал или надоело - смогли поддержать друг друга. А так же поделиться новой информацией,придумывать друг для друга задачи соответствующие знаниям и ломать голову вместе над задачами! На данный момент я учусь по книге Head First Рейли Джей Макгарвин.
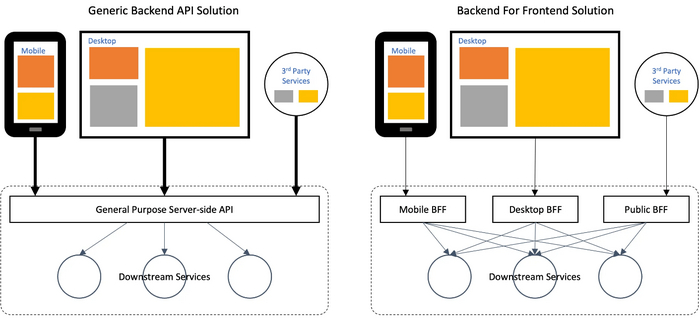
📲 Что такое Backends for Frontends и когда стоит его использовать
Backends for Frontends – это паттерн, который предполагает разработку отдельных бэкенд-сервисов, оптимизированных под фронтенд конкретных приложений (веб, мобильные, IoT и т. д.). Каждый BFF создает API, идеально подходящий для своего клиента. BFF можно рассматривать как развитие концепции API Gateway, однако между ними есть несколько ключевых отличий:
API Gateway обычно предоставляет единую точку входа для всех клиентов, а BFF создает отдельные шлюзы для каждого типа клиента (веб, мобильный и т. д.).
BFF более специализирован и ориентирован на конкретные нужды разных типов фронтендов, а API Gateway более универсален и может обслуживать разные клиенты без специфической оптимизации.
BFF больше фокусируется на оптимизации взаимодействия между конкретным фронтендом и бэкендом, в то время как API Gateway часто используется для общих задач (маршрутизация, аутентификация, балансировка нагрузки).
Как работает BFF:
API Gateway перенаправляет запросы на соответствующий BFF.
BFF взаимодействует с нужными микросервисами (например, Products, Orders, Cart).
BFF обрабатывает и оптимизирует данные для конкретного клиента.
Универсальный API vs BFF для каждого типа клиента
Паттерн появился в 2015 году, приобрел широкую известность к 2021-му и с тех пор остается одним из самых популярных подходов в разработке микросервисов. На это есть веские причины:
Оптимизация производительности – BFF позволяет настроить потоки данных и форматы ответов для каждого фронтенда, повышая скорость работы приложений.
Улучшенная безопасность – изоляция фронтендов дает возможность реализовать меры безопасности, учитывающие специфику каждого клиента.
Гибкость разработки – фронтендеры и бэкендеры могут работать более независимо, в отдельных командах, ускоряя процесс создания и обновления продукта.
Упрощение фронтенд-разработки – BFF предоставляет именно те данные, которые нужны конкретному интерфейсу, избавляя от лишней обработки на клиенте.
Упрощение поддержки и модификации API для каждого отдельного фронтенда.
Когда стоит использовать BFF:
Когда у сервиса несколько типов клиентов с разными потребностями в данных.
Если необходима серьезная оптимизация производительности для конкретных интерфейсов.
Например, BFF будет оптимальным выбором для:
E-commerce платформ – отдельные BFF для веб-сайта, мобильных приложений и умных устройств будут обрабатывать специфические потоки данных и действия пользователей.
Финансовых сервисов – специализированные BFF для веб- и мобильного банкинга обеспечат более удобное и безопасное использование сервиса.
CMS – паттерн упростит адаптивную доставку контента для разных устройств.
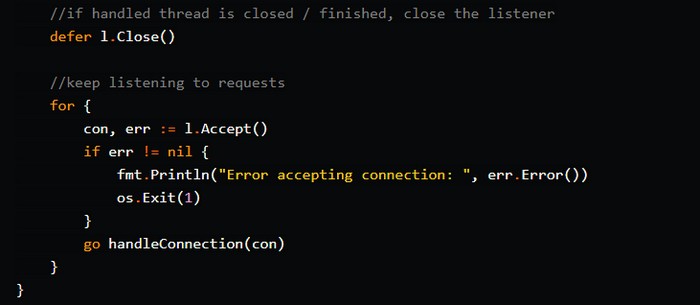
✍️ Как написать HTTP-сервер на Go
Платформа CodeCrafters предлагает практичный подход к обучению – разработчики там учатся и совершенствуют навыки в процессе создания реальных, готовых к использованию приложений. Например, одно из заданий – разработка HTTP-сервера. Студент успешно выполнил задание на Go без использования сторонних библиотек и рассказал о процессе работы в этом пошаговом туториале.
Основные характеристики и функциональность сервера:
Базовый TCP-сервер, слушающий порт 4221.
Обрабатывает HTTP-запросы и отправляет соответствующие ответы.
Поддерживает разные маршруты и HTTP-методы.
Обрабатывает параметры URL и заголовки запросов.
Поддерживает отправку файлов в ответ на запросы.
Предусматривает конкурентную обработку нескольких соединений.
Для каждого нового соединения запускается отдельная горутина
Этот проект отлично подходит для начинающих разработчиков – помогает понять, как работают веб-серверы под капотом, без абстракций, предоставляемых высокоуровневыми фреймворками. Процесс создания аналогичного сервера на Python подробно рассмотрен здесь.
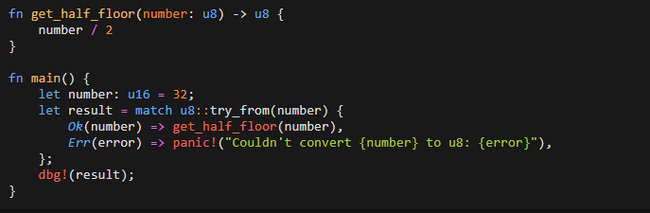
Оператор as используется для приведения типов: позволяет преобразовывать значения одного типа в другой. Но, как пишет опытный Rust-разработчик, использование as может привести к неожиданному поведению при преобразовании в меньший тип данных: если значение не помещается в целевой тип, происходит усечение без предупреждения – это приводит к появлению трудноотслеживаемых ошибок в больших проектах. Например, у нас есть число 288, которое мы хотим преобразовать в тип u8 (8-битное беззнаковое целое число). Тип u8 может хранить значения от 0 до 255. Очевидно, 288 не помещается в этот диапазон. При использовании as для преобразования вместо ожидаемой ошибки или предупреждения Rust выполняет усечение значения. В этом случае результат будет равен 32:
288 в двоичном виде: 100100000.
При преобразовании в u8 Rust берет только 8 младших битов (справа налево): 00100000.
00100000 в десятичной системе равно 32.
Это поведение станет полной неожиданностью для программистов, переключившихся на Rust с языков высокого уровня, где подобные преобразования всегда вызывают ошибки или предупреждения. Лучшее решение этой проблемы – использовать трейт TryFrom вместо as. Этот подход требует чуть больше кода, но это один из тех немногих случаев, когда отказ от стандартного приема действительно оправдан:
TryFrom явно обрабатывает случаи, когда значение не помещается в целевой тип данных
🐍 Как создать инвертированный индекс на Python
Инвертированный индекс – это структура данных, которая позволяет быстро находить документы, содержащие определенное слово или фразу. Главные преимущества инвертированного индекса:
Высокая скорость – поиск по индексу значительно быстрее, чем полный просмотр всех документов.
Эффективность для больших объемов данных – индекс позволяет эффективно обрабатывать большие коллекции документов.
Вместо того, чтобы просматривать каждый документ целиком, индекс хранит информацию о том, в каких документах встречается каждое слово. Для этого он использует хэш-таблицу (словарь в случае Python), где ключами являются слова, а значениями – списки идентификаторов документов, содержащих эти слова. Общий принцип построения индекса выглядит так:
Подготовка данных
Определяется структура документов (например, название и текст статьи).
Создается список документов.
Для каждого документа:
Преобразуется текст – переводится в нижний регистр, удаляются знаки препинания.
Обработанный текст разбивается на слова.
Для каждого слова:
Если слово еще не в индексе, создается запись с пустым списком документов.
Добавляется идентификатор текущего документа в список для данного слова.
Алгоритм поиска по индексу включает в себя:
Преобразование запроса
Запрос приводится к нижнему регистру и очищается от знаков препинания.
Преобразованный запрос разбивается на слова.
Поиск по индексу
Для каждого слова в запросе:
Находится список документов для этого слова в индексе.
Объединяются списки документов для всех слов запроса.
Получение результатов
По идентификаторам из объединенного списка находятся соответствующие документы.
Пример реализации простейшего инвертированного индекса на Python подробно описан здесь.
Сравнение скорости выполнения 20 запросов по 15 000 документов
🛠️ 18 основных паттернов микросервисной архитектуры
В этой статье подробно рассказано о паттернах, которые представляют собой набор проверенных решений типичных проблем и задач в микросервисной архитектуре. Их правильное применение может значительно улучшить масштабируемость, надежность и гибкость системы.
1. Service Registry (Реестр сервисов)
Этот паттерн решает проблему обнаружения сервисов в распределенной системе. Каждый микросервис регистрирует себя в центральном реестре (например, Netflix Eureka или Consul). Когда одному сервису нужно взаимодействовать с другим, он обращается к реестру, чтобы узнать текущий адрес нужного сервиса. Это позволяет сервисам динамически обнаруживать друг друга без жесткой привязки к конкретным адресам.
2. API Gateway (API-шлюз)
API Gateway действует как единая точка входа для всех клиентских запросов. Он принимает запросы от клиентов и перенаправляет их соответствующим микросервисам. API Gateway может также выполнять такие задачи, как аутентификация, авторизация и балансировка нагрузки. Это упрощает взаимодействие клиентов с системой, скрывая сложность внутренней архитектуры.
3. Circuit Breaker (Предохранитель)
Этот паттерн предотвращает каскадные сбои в системе. Когда один сервис начинает давать сбои, Circuit Breaker временно блокирует запросы к этому сервису, предотвращая перегрузку и позволяя системе восстановиться. Это повышает устойчивость системы и помогает избежать полного отказа всей системы из-за проблем с одним сервисом.
4. Bulkhead (Отсек)
Паттерн Bulkhead изолирует компоненты системы друг от друга, чтобы сбой в одной части не повлиял на другие. Например, для разных сервисов могут использоваться отдельные пулы потоков или базы данных. Это повышает устойчивость системы и ограничивает распространение сбоев.
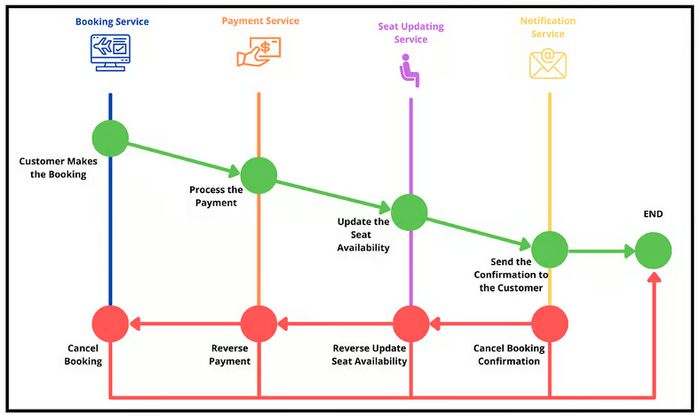
5. Saga Pattern (Сага)
Saga используется для управления распределенными транзакциями в микросервисной архитектуре. Длительная бизнес-операция разбивается на серию меньших, локальных транзакций. Каждый сервис выполняет свою часть транзакции и публикует событие, которое запускает следующий шаг. Если что-то идет не так, выполняются компенсирующие действия для отмены изменений.
Принцип работы паттерна Сага
6. Event Sourcing (Источник событий)
Вместо хранения только текущего состояния этот паттерн сохраняет все события, которые привели к этому состоянию. Это обеспечивает надежный аудиторский след и позволяет восстановить состояние системы на любой момент времени. Особенно полезен в системах, где важна история изменений и возможность отката.
7. Command Query Responsibility Segregation (CQRS, Разделение команд и запросов)
CQRS разделяет операции чтения и записи в приложении. Используются разные модели для обновления информации (команды) и чтения информации (запросы). Это позволяет оптимизировать каждую сторону независимо, что может значительно улучшить производительность и масштабируемость.
8. Data Sharding (Шардинг данных)
Этот паттерн используется для распределения нагрузки на базу данных. Данные разделяются на несколько баз данных или экземпляров базы данных. Каждый микросервис может обрабатывать подмножество данных или определенные типы запросов. Это помогает избежать узких мест в работе с данными и улучшает масштабируемость.
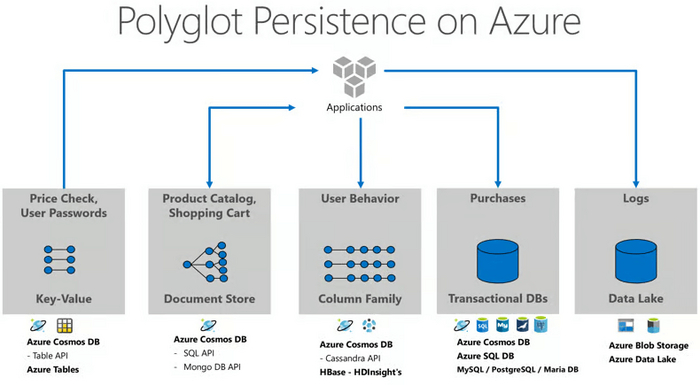
Этот подход позволяет использовать разные технологии баз данных для разных микросервисов, исходя из их конкретных потребностей. Например, один сервис может использовать реляционную БД, другой – NoSQL, третий – графовую БД. Это оптимизирует хранение, извлечение и обработку данных для каждого сервиса.
Реализация многовариантного хранения в Azure
10. Retry (Повторная попытка)
Обеспечивает повторение операции при возникновении временного сбоя – вместо немедленного отказа. Может применяться на разных уровнях: от взаимодействия между сервисами до работы с базой данных. Помогает справиться с кратковременными проблемами в сети или сервисах.
11. Sidecar (Вспомогательный сервис)
Этот паттерн предполагает присоединение вспомогательного сервиса (sidecar) к основному микросервису для обеспечения дополнительной функциональности, такой как логирование, безопасность или коммуникация с внешними сервисами. Позволяет основному сервису сосредоточиться на своей основной функции.
12. Backends for Frontends (BFF, Бэкенды для фронтендов)
BFF предполагает создание отдельных бэкенд-сервисов для каждого типа клиента (веб, мобильный и т. д.). Это позволяет оптимизировать API под конкретные нужды каждого клиента, улучшая производительность и упрощая разработку клиентской части.
13. Shadow Deployment (Теневое развертывание)
Этот паттерн предполагает отправку копии (тени) производственного трафика к новой версии микросервиса без влияния на реальный пользовательский опыт. Это позволяет проверить производительность и корректность новой версии в реальных условиях, не подвергая риску текущих пользователей.
В этом подходе потребители сервисов определяют свои ожидания от поставщиков сервисов. Это помогает обеспечить более надежные и согласованные изменения в системе. Каждый сервис-потребитель описывает, какой именно функционал и в каком формате он ожидает от сервиса-поставщика.
Этот паттерн рекомендует размещать бизнес-логику в самих микросервисах (умные конечные точки), а не полагаться на сложное промежуточное ПО. Инфраструктура коммуникаций (каналы) должна быть простой и заниматься только маршрутизацией сообщений. Это упрощает систему и делает ее более гибкой.
16. Database per Service (База данных для каждого сервиса)
В этом паттерне каждый микросервис имеет свою собственную базу данных, и сервисы общаются через четко определенные API. Это обеспечивает изоляцию данных и независимость сервисов, но требует тщательного подхода к обеспечению согласованности данных между сервисами.
17. Async Messaging (Асинхронный обмен сообщениями)
Вместо синхронного взаимодействия между микросервисами этот паттерн предполагает использование очередей сообщений для асинхронной коммуникации. Это может улучшить отзывчивость системы и ее масштабируемость, так как сервисы не блокируются в ожидании ответа друг от друга.
18. Stateless Services (Сервисы без состояния)
Проектирование микросервисов как stateless (без сохранения состояния) упрощает масштабирование и повышает устойчивость. Каждый сервис обрабатывает запрос независимо, не полагаясь на сохраненное состояние – это облегчает горизонтальное масштабирование.
В этой статье сравниваем ТОП-15 лучших онлайн-курсов по обучению Golang и рассматриваем бесплатные курсы.
Go (или Golang) - это мощный и эффективный язык программирования, разработанный компанией Google. Его синтаксис прост для изучения и освоения. Golang предназначен для создания высокопроизводительных и масштабируемых приложений. Он поддерживает параллельное выполнение задач и предлагает удобные инструменты для работы с сетью и конкурентностью. Golang также славится своей высокой производительностью и быстрым временем компиляции.
Информация о курсе: стоимость — от 3 700 руб. / мес. в рассрочку на 36 месяцев, длительность — 12 месяцев
Особенности: 80% обучения составляют практические задания в различных форматах. Вы получите ответы на все вопросы и постоянную обратную связь от менторов по выполненным заданиям. Центр карьеры начинает работу со студентами с первого дня обучения. По завершении курса вы получите сертификат и диплом.
Информация о курсе: стоимость — 66 000 ₽ или рассрочка - от 6 600 ₽ / мес., длительность — 5 месяцев
Особенности: В процессе обучения вы будете выполнять домашние задания, каждое из которых будет связано с отдельным компонентом вашего итогового проекта. После завершения всех заданий у вас будет готовый выпускной проект. Вы получите помощь в создании резюме, портфолио и сопроводительного письма, разместите свое резюме в базе данных OTUS и сможете получать приглашения на собеседования от партнеров. По окончании курса вам выдадут сертификат.
Информация о курсе: стоимость — 50 000 ₽ - 65 000 ₽ или рассрочка - от 12 500 ₽ / мес., длительность — 8 недель
Особенности: На курсе предусмотрены задания с длинными сроками выполнения, которые проверяют действующие Go-разработчики. Кураторы всегда на связи, помогают с обучением и решают возникающие проблемы. Вы будете выполнять разнообразные задания, постепенно усложняя кодовую базу. После основной программы у вас будет время для подготовки итогового проекта, который можно будет приложить к резюме. По окончании курса получите свидетельство, а при выполнении 80% заданий и защите проекта — номерной сертификат.
В процессе обучения вы освоите:
создание собственного API сервера на Golang
запуск контейнеров
взаимодействие с Docker через Go
работу с пользовательскими операторами и многое другое.
Программа курса:
Основы Go Разберём, зачем нужен язык Go, где его применять, обсудим основные недостатки и выясним, какие рабочие процессы можно упростить с помощью Go.
Встреча с преподавателями
Детально разберём подход Go к объектно-ориентированному программированию (ООП) и обработке и комбинированию ошибок.
Concurrency Научимся различать конкурентность и параллелизм, освоим работу с конкурентностью в Go (стандартные подходы и концепции).
Практика на Go Научимся работать со стандартной библиотекой языка, создавать сложные программы на Go, разберёмся в структуре тестов, поймём, что такое тестирование и как оно организовано, научимся запускать внешние процессы из Go.
Работа с Docker через Go Изучим API и способы взаимодействия с ним, научимся работать с Docker через Go, запускать контейнеры и подключаться к ним, определим характер взаимодействия в зависимости от задач.
Обсуждение пройденных модулей
Паттерны Kubernetes
Операторы Kubernetes Освоим работу с пользовательскими операторами и разберём, зачем нужны паттерны Kubernetes.
Основные конструкции языка Go: условия, циклы, функции и другие элементы.
Создание программ из нескольких модулей.
Эффективный поиск и исправление ошибок в коде с использованием отладочной печати.
Обучение включает в себя изучение основ Go, включая простые типы данных, условия, циклы, объявление пользовательских функций и использование встроенных структур. Вы также познакомитесь с концепциями ООП в Go, включая легковесные потоки и Go-рутины, что является сильной стороной этого языка. Полученные знания помогут вам быстрее освоить основы программирования на Go, предоставив полное представление о его принципах и особенностях.
Этот курс ориентирован на тех, кто уже обладает опытом программирования на других языках и имеет представление о типах данных, переменных, условных конструкциях, циклах, функциях и объектах.
Меня заинтересовали этот язык программирования, в связи с чем хотелось бы задать несколько вопросов всём желающим на них ответить.
Немного о себе: основной язык С++, поверхностно знаю и время от времени использую десятку популярных языков: C#, Java, JS и так далее.
1) Как обстоят дела с развитием Go? Я читал, что это достаточно новый язык. Те обновления, что в него вносятся в настоящее время делают его лучше? Как сообщество относится к этому?
2) Почему он был придуман и какие задачи решает? Я просто могу провести параллель с С++ и Carbon, как продолжение С++. Сейчас про Carbon практически никто не знает, а в продакшене не используются вообще.
3) Интересно было бы узнать, в каких связках Вы использовали эти языки как в продакшене, так и в пет-проектах. Какие ещё инструменты входили в стек разработки?
4) Как обстоят дела с IDE? Какая на Ваш выбор является лучшей?
5) Легко ли писать и отлаживать кроссплатформенный код? На каких платформах существуют компиляторы?
6) Как обстоят дела на рынке? Мне как потенциальному джуну на этом ЯП, понятное дело, сейчас туда бессмысленно соваться, поэтому хотелось бы узнать изменение. Как было раньше, как обстоят дела сейчас и что по Вашему мнению ожидать дальше?
7) Какая ЗП в зависимости от уровня и компаний? Скорее всего, вопрос будет без ответа, но и не задать не могу. Буду благодарен хотя бы вилкам.
8) Какую литературу бы посоветовали?
9) Как относитесь к другим языкам, которые решают похожие задачи? В чем преимущества или недостатки Go перед Elixir, Java, C# и далее, например, при написании сервисов? Было бы интересно узнать и о других областях, в которых имела бы место конкуренция этих ЯП.