Вышла лучшая нейросеть для генерации кода. Судя по тестам, OpenCI превосходит GPT-4 и превращает любой запрос в рабочую программу.
Нейронка даже учится на вашей обратной связи, чтобы постоянно улучшать свою работу на лету. Самое крутое — код модели выложили в открытый доступ, а это значит, что ее можно запустить у себя на ПК, бесплатно и без VPN.
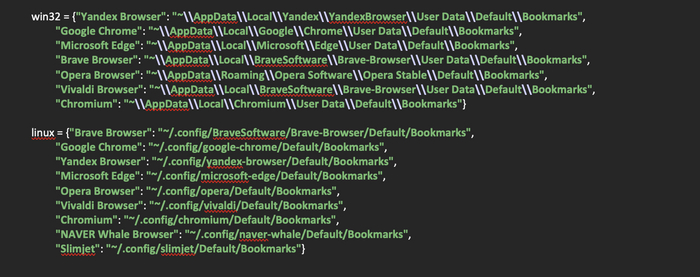
Почти все браузеры, основанные на chromium, хранят закладки похожим образом. Меняются только директории, в которые эти браузеры установлены. Исключением является только Mozilla Firefox. При этом закладки хранятся в открытом виде, так что, любой желающий может получить к ним доступ. Не сказать, чтобы это была супер секретная информация. Но все же, стоило бы продумать этот момент. В данной статье мы рассмотрим код, который в автоматизированном режиме получает все закладки из распространенных браузеров с помощью Python.
Создадим файл browser_check.py. В нем, напишем код, который будет производить поиск браузеров по пути указанному в одном из словарей.
Импортируем необходимые библиотеки для работы скрипта и определим список, в который будем помещать словари с найденными браузерами:
Следующим шагом будет создание двух словарей, в которые поместим пути к распространенным браузерам на операционных системах Windows и Linux, так как поиск браузеров будет производиться по путям, которые специфичны для каждой из операционных систем.
Создадим функцию browser_find(platform: dict) -> None, которая на входе будет получать словарь с путями к закладкам браузеров и проверять их существование. Если путь существует, в объявленный ранее список browser будет добавляться словарь с названием браузера и путем к его закладкам.
Следует обратить внимание на тот факт, что пути к закладкам браузеров указаны при установке их в директории по умолчанию. Если же пользователь поменял расположение директории с браузером, то он найден не будет.
Двигаемся далее и создадим функцию main, в которой будем определять платформу, на которой запущен скрипт. В принципе, если у вас MacOS, то нужно добавить еще один словарь с путями и условие, в котором определяется ваша система. Но, в данном случае детектируются только две операционные системы: Windows и Linux.
В зависимости от того, какая из систем установлена на компьютере с запущенным скриптом, забираем нужный словарь с путями к закладкам и передаем его в функцию browser_find, которую напишем в отдельном файле.
После этого проверяем, есть ли что-то в списке с браузерами. Если список пуст, выводим сообщение для пользователя, что браузеры не найдены. Если же список не пуст, итерируемся по нему в цикле, забираем словари и получаем название браузера, которое содержится в переменной key и путь к закладкам, содержащийся в переменной value.
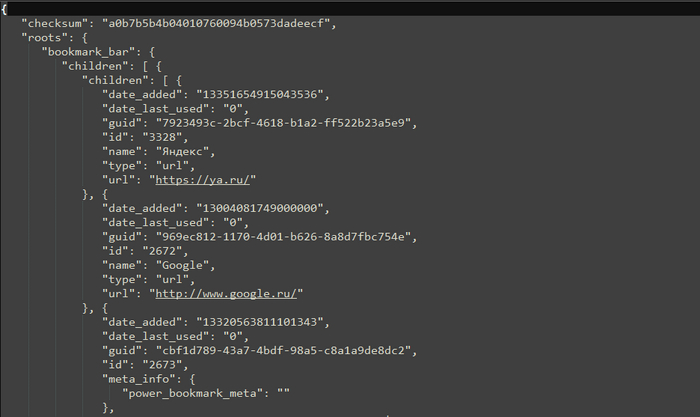
Передаем полученное значение в функцию по парсингу json. На самом деле, файл с закладками, это json-файл с достаточно большой структурой вложенности.
Часть структуры файла закладок
В зависимости от того, что вернет функция парсинга, а возвращает она или список со словарями, в которых содержаться полученные значения или False, двигаемся дальше. Если мы получаем список, то открываем файл с названием браузера на запись. Обратите внимание на то, что в данном случае файл открыт в режиме дозаписи, о чем свидетельствует параметр «a». Затем итерируемся по полученному списку, забираем из словарейОбратите внимание на ветку «roots», в которой и находятся все закладки. Так как закладки в браузере, это не просто последовательный набор названий и ссылок, то их группировка происходит по директориям создаваемым пользователем. Данные директории имеют название «children» и имеют тип «folder». Также, к примеру, на Панели закладок могут быть как директории с закладками, так и просто закладки для быстрого доступа. Тип закладок без папок «url».
Создадим файл bookmarks_find.py и приступим к написанию кода. Для начала импортируем библиотеки, которые понадобятся в данном скрипте.
import json
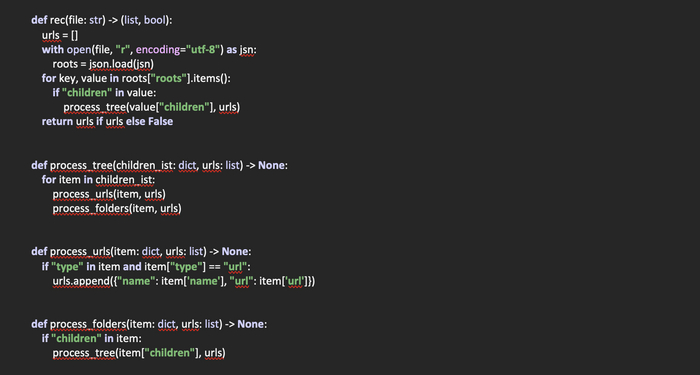
Создадим функцию rec(file: str) -> (list, bool), в которую передается путь к закладкам браузера. Возвращает же данная функция список со словарями, в которых содержится имя и url закладки. В случае же, если закладки найти не удалось, возвращается False.
Объявляем список urls, в который будем помещать найденные закладки в виде словарей. Откроем файл с закладками для чтения, поместим его содержимое в переменную roots.
Так как значение данной переменной будет являться словарем, проитерируемся по нему в цикле, указав ветку «roots» в качестве стартовой. Получим ключ и значение и проверим, есть ли в нем название «children». Если да, передаем полученную ветку в функцию process_tree, которую мы создадим чуть позже для обработки. Также передаем в эту функцию список urls. По сути, при передаче списка, если вспомнить его свойства, мы передаем указатель на оригинальный список, так как его копирования в данном случае не происходит. А значит, при его изменении в других функциях измениться и оригинальный словарь.
После того, как завершим итерацию по файлу, проверяем, пуст или нет список. Если список не пуст, возвращаем его из функции. Если пуст - возвращаем False.
Теперь создадим функцию process_tree(children_ist: dict, urls: list) -> None, которая получает на входе словарь из полученной директории и указатель на список, в котором будут храниться найденные ссылки в виде словарей.
Здесь все просто. Данная функция как переходник, в котором мы итерируемся по полученному словарю и передаем полученные значения в следующие функции для обработки.
Создадим функцию process_urls(item: dict, urls: list) -> None, которая на входе получает словарь со значениями и ссылку на список. У данной функции предназначение – выявить ссылки в переданном словаре. Для этого проверяем, есть ли в переданном словаре ключ «type» и является ли его значение «url». Если да, забираем название ссылки и саму ссылку и добавляем в виде словаря в список urls.
И еще одна функция, которая будет необходима для проверки, не является ли полученный словарь директорией со ссылками «children». Создадим функцию process_folders(item: dict, urls: list) -> None, которая на входе получает словарь со значениями и ссылку на список.
Здесь все тоже просто, проверяем, есть или нет «children» в переданном словаре. Если есть, передаем его рекурсивно в функцию process_tree для дальнейшей обработки.
Полный код скрипта:
import json
На этом вроде бы все. Основные скрипты и функции написаны, осталось только проверить, как это будет работать.
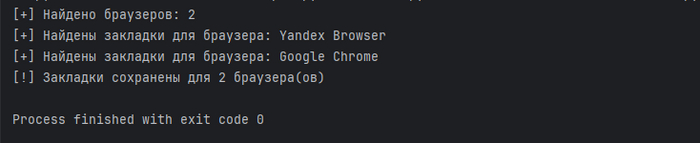
В процессе работы скрипт выведет несколько сообщений: о том, сколько было найдено браузеров, для какого из браузеров найдены закладки и для какого количества из найденных закладки сохранены.
Сообщения в терминале
Если скрипт найдет браузеры в системе, в директории скрипта будут созданы файлы с названиями найденных браузеров, в которых содержатся закладки.
Файлы с найденными закладками
Как видно на скриншоте, у меня установлено два браузера. Давайте откроем один из файлов и посмотрим на часть его содержимого.
Содержимое файла с найденными закладками
Как видим, закладки найдены. За годы работы в данном браузере их накопилось чуть более 3000. Конечно же, показывать все я не буду, потому, только самое начало, для того, чтобы убедиться, что скрипт работает.
Скрипт работает как на Windows, так и на Linux. Вот скрин с работой скрипта в Fedora Workstation, в которой браузеры установлены по умолчанию, с помощью пакетов.
Работа скрипта в Fedora Workstation
Подведем итоги:
В данной статье мы научились рекурсивно парсить файл json, узнали, каким способом можно определить операционную систему, установленную на компьютере, а также сохранять данные из json в текстовый файл.
В перспективе, применений данному скрипту можно найти достаточно много. Все зависит только от вашей фантазии.
Стандарт Open Document стал де-факто уже давно. И если раньше формат документов Microsoft Office был проприетарным, то теперь он представляет собой «.zip»-файл в котором храниться множество «.xml», а также изображения и прочие файлы. Конечно же, самым простым способом извлечь документы является изменение расширения документа на «.zip» и последующее извлечение файлов любым архиватором. Но, если вам нужно сделать это не с одним документом, это может быть достаточно продолжительно по времени. Поэтому, давайте рассмотрим несколько способов, с помощью которых можно извлечь изображения из файлов формата ".docx", ".xlsx", ".pptx", ".odp", ".ods", ".odt".
Способ №1: используем стандартные библиотеки python
Для данного способа не требуется установка сторонних библиотек. Достаточно тех, что поставляются в комплекте с самим интерпретатором.
Импортируем нужные нам в процессе работы библиотеки:
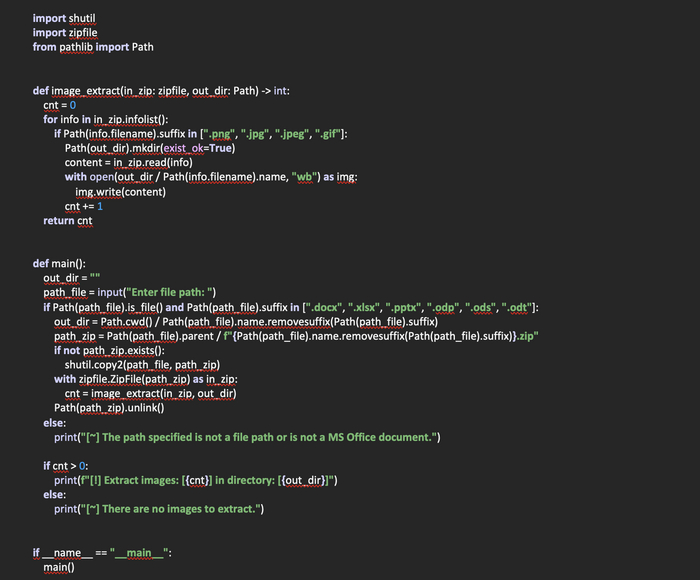
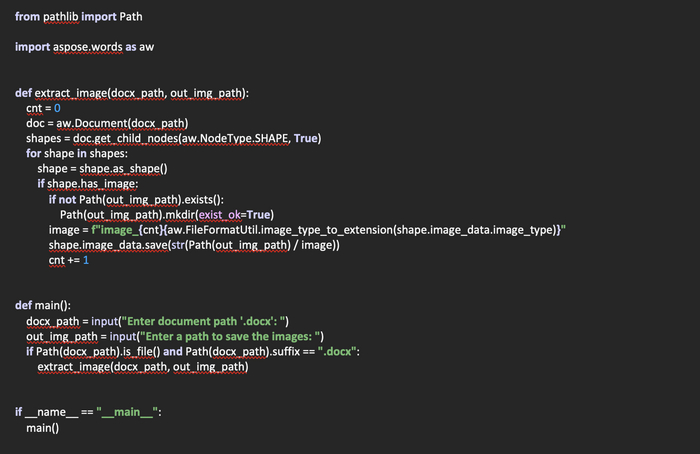
Создадим функцию image_extract(in_zip: zipfile, out_dir: Path), в которую будем передавать zip-файл, а также путь к директории в которую будут распакованы изображения. В данном случае путь у пользователя запрашиваться не будет.
Объявим переменную cnt, которая будет счетчиком распакованных изображений. Затем в цикле пробежимся по списку содержимого архива. Проверим расширения файлов в архиве. И если они совпадают с расширениями из списка, будем читать текущий файл с изображением и сохранять в байтовом режиме в директорию, которая передается в функцию. Также, данная директория создается автоматически и называется именем исходного документа. После того, как все изображения будут сохранены, возвращаем из функции наш счетчик.
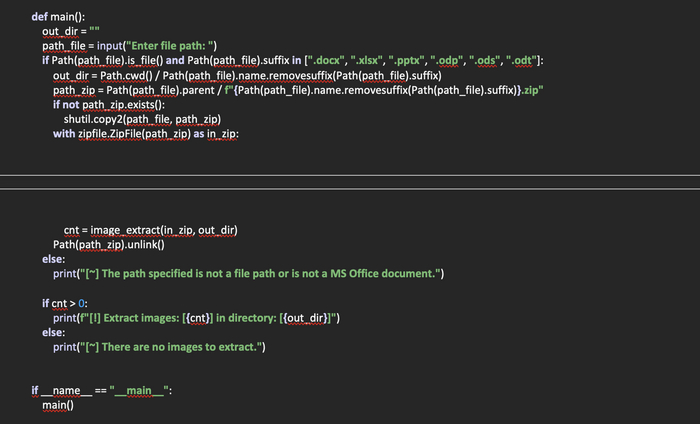
Осталось дело за малым, запросить у пользователя путь к файлу, проверить, является ли он файлом и имеет ли нужный формат. После чего скопировать файл с расширением «.zip», открыть с помощью zipfile и передать в функцию для поиска изображений и их распаковки. Ну и напоследок удалить скопированный zip-файл.
После окончания извлечения изображений вывести сообщение пользователю о том, сколько файлов было извлечено и в какую директорию.
Полный код скрипта:
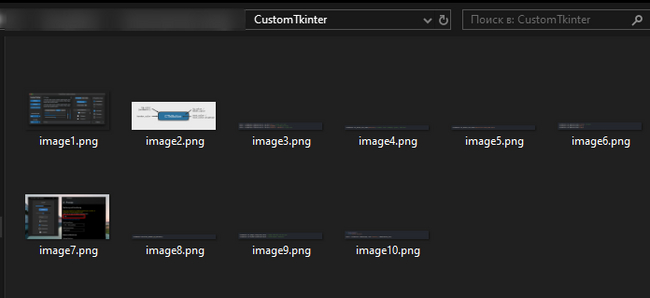
Протестируем созданный скрипт. У нас есть, для примера документ «CustomTkinter.docx». В нем содержаться несколько изображений. Вот их мы и попробуем извлечь.
Запускаем скрипт, указываем путь к документу и получаем папку с названием документа, в которой содержаться изображения.
Способ №2: используем библиотеку docx2txt
Создадим файл docx2im.py. В данном случае мы будем использовать стороннюю библиотеку docx2txt. Для ее установки пишем в терминале или командной строке:
Теперь импортируем нужные библиотеки в скрипт.
В данном случае нам не понадобиться создавать дополнительных функций. Сделаем все в одной. Хотя, в теории, можно было бы разделить извлечение изображений и текста. Да, дополнительным бонусом, при том, что извлекаются изображения только из документов «.docx», является извлечение текста.
Для начала запросим у пользователя путь к документу и путь к папке для извлечения изображений. Проверим, является ли переданный параметр путем к документу и является ли расширение данного документа «.docx». Затем проверим, существует ли директория для извлечения изображений. Если нет, создадим ее, так как docx2txt ее самостоятельно не создает.
Теперь передаем путь к документу и путь для извлечения изображений в функцию process данной библиотеки. Из нее будет возвращен текст документа. Проверим, содержится ли в переменной text что-нибудь. Для этого обрежем пробелы и знаки переноса каретки, так как, если в документе нет текста, но есть пустая строка, переменна text не будет пуста.
Затем открываем текстовый документ на запись и записываем в него полученный текст.
Этот способ достаточно простой, но, как вы уже поняли, извлекать изображения из других форматов документов он не умеет.
Думаю, что вышеприведенных скриптов будет достаточно. Можно использовать также библиотеку aspose-words, которая устанавливается с помощью команды:
pip install aspose-words
Однако, способ извлечения с ее помощью изображений не особо отличается от предыдущих. Создадим файл aspose_extract.py. Вот для примера код:
Выбирать, что использовать вам и в каком виде, конечно же, вам. Здесь описаны только несколько способов, с помощью которых можно проделать данную операцию. Скорее всего, если поискать более тщательно, найдется еще множество библиотек, с помощью которых можно извлечь изображения из документов.
Когда мы получаем какую-либо информацию о домене, в числе прочих параметров мы узнаем его ip-адрес. И получить его с помощью python не составляет большого труда. Однако давайте рассмотрим, как, не используя прямое обращение к сокету получить ip-адрес непосредственно из запроса.
Зачастую, чтобы получить ip-адрес мы используем socket. И в случае, когда нам требуется выполнение только данной операции этого вполне достаточно.
Но можно поступить несколько иначе, особенно если мы уже получаем какие-либо данные с сервера. Хотя бы те же заголовки. Давайте на примере посмотрим, как реализовать получение доступа к необработанному объекту сокета.
Установка необходимых библиотек
В данном случае нам понадобиться библиотека requests. Для ее установки пишем в терминале:
Импорт библиотек в скрипт. Создание заголовков для запроса
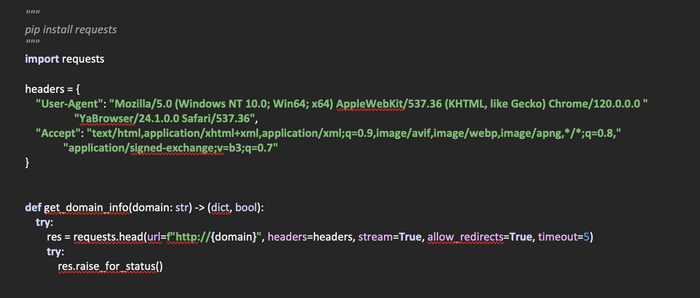
После того, как установлены необходимые библиотеки, нам их нужно импортировать в скрипт. В данном случае, так как мы установили библиотеку requests, импортируем ее.
После этого создадим словарь с заголовками содержащими «User-Agent» и «Accept». Их мы будем передавать в запрос в качестве параметра, чтобы изменить стандартные заголовки отправляемые python.
Получаем заголовки и ip-адрес
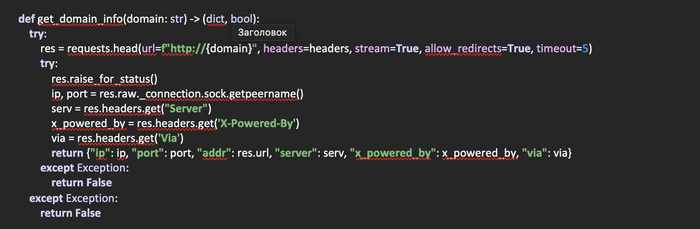
Создадим функцию get_domain_info(domain: str) -> (dict, bool), которая на входе будет получать домен, а возвращать заголовки отправленные сервером, а также ip-адрес домена. Выполним запрос на получение заголовков, куда передадим адрес домена, заголовки. Укажем свойство allow_redirects = True. Это сделано для того, чтобы производилась переадресация. То есть, в данном случае мы делаем следующее: так как мы не знаем точного адреса сайта, доменное имя которого передано в функцию, поступим как браузер. Для начала пойдем по протоколу http. Если на сервере включена переадресация, то мы будем автоматически переадресованы на нужный адрес. Также, stream=True. Это необходимо для получения ip-адреса из запроса.
Обработаем исключение raise_for_status(), чтобы отсекать ненужные статус-коды. В случае же, когда код 200, получим ip и порт, которые возвращаются в кортеже при выполнении следующего кода: res.raw._connection.sock.getpeername(). Важно то, что эти данные необходимо получить в самом начале, до обработки остальных данных запроса, то есть в первую очередь. И уже после получим частично содержимое из заголовков отправленных сервером. Вернем пользователю словарь из полученных данных. В случае же неудачи или неверного статус-кода, вернем из функции False.
Ну и создадим функцию main, где и будем запрашивать у пользователя домен, отправлять его в функцию для получения информации и выводить на печать полученные в виде словаря данные.
Здесь я не проверяю полученную информацию, так как данный код служит примером. Если вы попробуете получить ip-адрес с помощью socket, результат, зачастую, будет одинаковым. Однако, если вы увидите, что адреса различаются, то не считайте это ошибкой. Я проверял специально данные, получая информацию от DNS. Тут дело в том, что на одном домене может быть несколько NS-серверов. И в этом случае возвращается значение ближайшего. Ну или свободного. В данном случае механизм для меня пока еще не совсем понятен. Главное, что и тот, и тот адреса являются правильными.
Полный код скрипта
Протестируем написанный код и получим заголовки и ip-адрес для домена python.org.
Результат работы скрипта
Как видим, скрипт отработал правильно и вернул ip-адрес, а также информацию из полученных заголовков.
А на этом, пожалуй, все.
Спасибо за внимание. Надеюсь, данная информация будет вам полезна!
1) Спустя месяц - два, чистого обучения Я: До изучил основы языка программирования C++, изучил функции, и преступил изучать указатели. 2) Написал несколько игрушек: Крестики - нолики, Игра в кубики(а-ля кости), и т.п.
Под прошлом постом, мне писали что данный ЯП очень тяжелый и всё в этом духе. Но что хочу сказать, да нифига!) Данный язык вполне хорошо запоминается и усваивается (Да, я понимаю зависит от человека), но конкретно в моём случае, всё довольно-таки отлично.
В планах на скорое время, начать заполнять своё портфолио, уже появляются множество идей что можно будет создать.
Что мне нравиться кодить на С++? Программы. Писать свои программулины это прямо вообще классно! Как я сказал выше, уже появляются идеи - мне бы ещё знаний по больше, хах)
В общем, я продолжаю обучаться, останавливаться не собираюсь! Хочу поблагодарить многих комментаторов под прошлым постом, многие дали очень нужную информацию к изучению. Всех Благ!!!)
Ps: Если у кого-то возникнет желание глянуть что я там написал, могу поделиться.)