Vispunk - это графический AI-редактор с простым интерфейсом. В нем можно генерировать изображения по выбранной форме, позе и описанию, обрабатывать различные области фотографии и многое другое, например можно поменять композиции сцен с использованием фигур, преобразовать рисунки в объекты, а также добавить конкретные элементы на изображение.
Видео внизу отлично демонстрирует, что можно загружать свои собственные изображения и менять в них детали. А функция “Select” позволяет выбирать конкретные области изображения.Можно легко встраивать одну картинку в другую, удалять фон и объекты, настраивать позу человека.
Но главное, Vispunk заменяет объекты на фото в пару кликов: просто выделяем любую область и пишем, что нужно там сгенерировать.
Плюсы:
➕ Бесплатный и без регистрации
➕ Не требуется установка - все работает из браузера
➕ Позволяет контролировать, где будут размещены объекты.
Хотите узнавать первыми о полезных сервисах с искусственным интеллектом для работы, учебы и облегчения жизни? Подпишитесь на мой тг (ссылка в описании профиля) там я рассказываю, как использовать нейросети для бизнеса
Этот пост больше для тех, кто на меня подписан, а таких уже 🎉 20 человек, но если вы случайный читатель и вам это будет интересно, то не проходите мимо. Возможно затея не обретёт популярность, но если понравится то буду периодически повторять.
Итак, я решил потратить выходной день на раздачу наград от Prime Gaming на ваши учетные записи, чтобы посмотреть, что вообще вам может быть интересно. Если с ключами от игр мы с вами уже разобрались в прошлых постах, то те награды от Prime Gaming которые являются просто игровыми бонусами просто лежат в копилке и кормушке)
Что предлагаю: Если вам интересно получение игровых бонусов или игр, которые получаются только прямой привязкой, то: 1. Пишите на почту news@gameout.ru с пометкой какую награду и куда вам отправить (логин пароль от учеток без 2FA) Например: Ghostwyre Tokyo Epic Games (лог:пароль) 2. Я читаю письмо и отправляю вам награды 3. Вы пишите спасибо под этим постом (Если вы будете писать "спасибо" на почту, то мы с вами запутаемся) 4. Отправляю всё до 22.10.2023 (23:59 МСК)
Что я не буду отправлять: - Награды для игры Electronic Arts [Apex Legends, Fifa 24, Madden NFL и тд] (так как у них существуют лимиты привязок по аккаунтам Amazon на пол года) - Награды для игр Riot Games [League of Legends, Valorant, TFT и тд] - Награды, акция на которые уже прошла
Из интересного: Игры: Golden Light (Epic Games) Ghostwyre Tokio (Epic Games)
Награды: Скины и наборы для WOW, Warframe, World of Tanks (EU), Naraka, CoD, PUBG. Ключики на бонусы: Honkai Star Rail, Lords Mobile, Pubg Mobile, Shadow Fight 3,
Отправляю коды и привязываю всё подряд.
P.S. Учетки мне ваши не нужны (можете потом менять пароли). Пост создан с целью просто поделится халявкой, потому что есть такая возможность.
Возможно написано сумбурно и не структурировано. Возможно кто-то обвинит меня в том, что я делаю это ради рейтинга. Возможно кто-то почувствует тут подвох. Мой ответ таким сразу - тебе не надо мне тем более.
Шел в магазин за хлебом. На обочине остановилась скорая, выскочили две молоденькие девчонки и в булочную. Я за ними, стоят, заказывают. Я продавщице - все за мой счет и мне булку дарницкого. Девчули в отказ, я говорю есть такой флешмоб - увидел скорую - накорми. Они рассмеялись, поблагодарили. Плюсик в карму. Если нет, просто приятно. Периодически оплачиваю покупки бабулек в магазинах... Эмоции от неприятия до полного непонимания происходящего. Пока им кассир не объясняет что уже все оплачено.
Не смогу пойти на концерт, сегодня в 7. Можно ли кому-то отдать бесплатно или за шоколадку и как, чтоб не получать спам потом? Может напишите кому отправить электронный билет, купил за 3500..
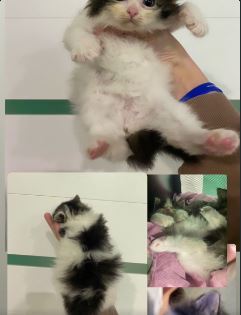
Нашли на улице котенка. Пока что приютили у себя. Совсем кроха недель 6. Кто хотел бы завести котенка, пожалуйста отпишитесь. Довезем в пределах МСК немного по подмосковью.
Немного неуклюжий, не фотогеничный , но очень ласковый. Пожалуйста найдитесь.
На видео кошка которая за ним присматривает была найдена котенком в контактном зоопарке сочи ,в вольере с козлами которые ее пытались затоптать.
Привет всем! Я расскажу о сервисах для распознавания текста или OCR. Считайте это небольшим рейтингом лучших OCR-утилит.
Обложка поста сгенерирована нейросетью
Оптическое распознавание символов (OCR - Optical Character Recognition) - механизм электронного или механического конвертирования изображения или печатного текста, например, с отсканированного документа, фотографии и т.д.
Я испытаю следующие программы и сервисы:
PDF - Adobe Acrobat Pro - эталон всех распознавателей.
PDF24 tools - богатый инструментарий для работы с PDF-документами, включает OCR.
NewOCR - заявляют себя как сервис конвертации в текст форматов: JPEG, PNG, GIF, BMP, TIFF, PDF, DjVu.
Img2txt - сервис отличается красивым интерфейсом, но спасёт ли его это?
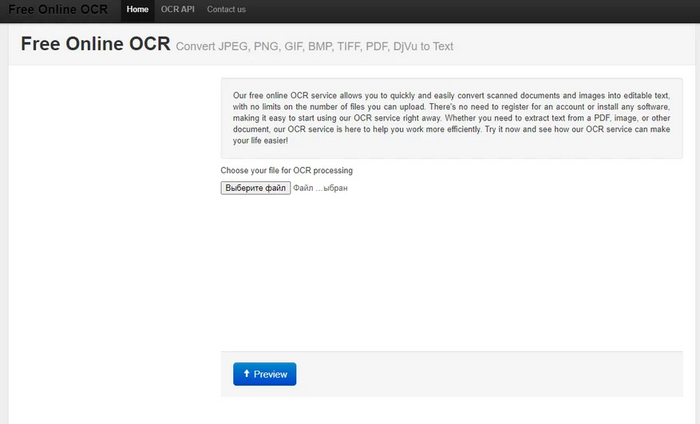
Free Online OCR - простецкий онлайн-сервис для распознавания.
Чтобы результат был наглядным и достоверным, нужно протестировать. Для этого я подготовил специальные документы:
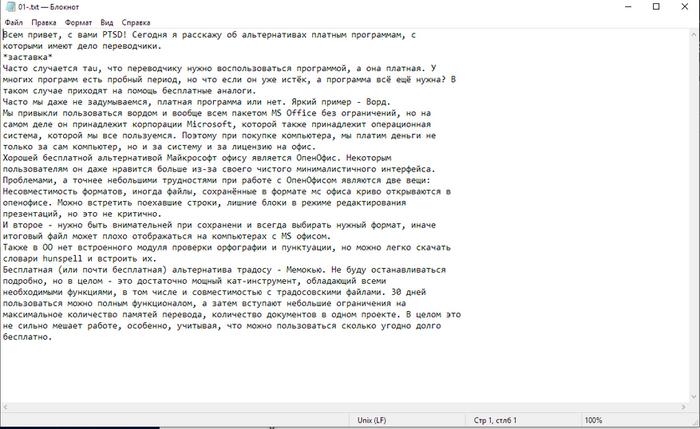
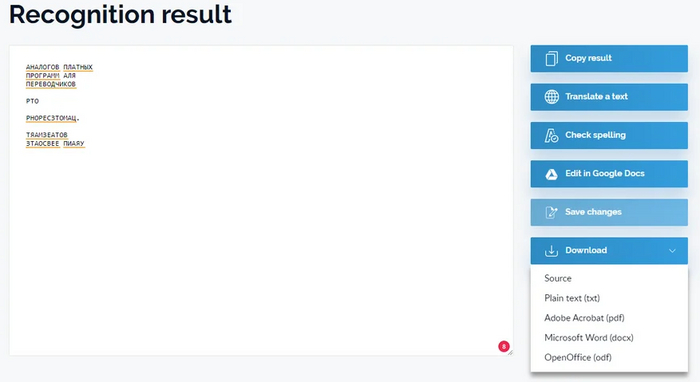
Фрагмент статьи “8 бесплатных аналогов платных программ для переводчиков” из подборки. Текст был написан в ворде, затем переведён в PDF. Сложность может представлять надпись нестандартным шрифтом, мелкие буквы, а также текст на эмблеме, но в целом документ простой и имеет текстовый слой.
Тот же фрагмент, но без текстового слоя - скрин, завёрнутый в PDF. Базовые сложности те же, только к ним ещё добавляется необходимость распознавания всего остального текста и необходимость сохранить форматирование.
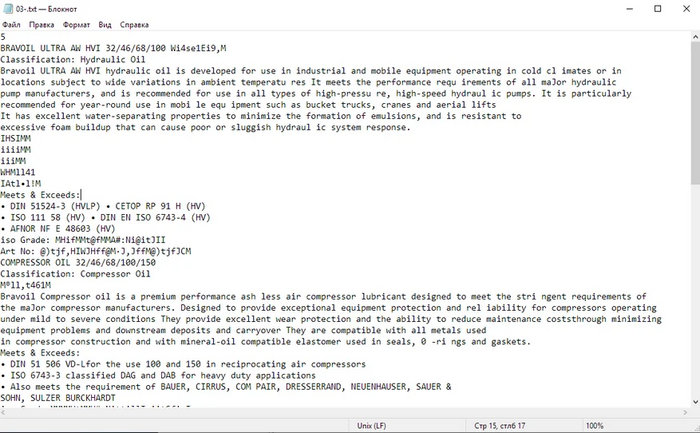
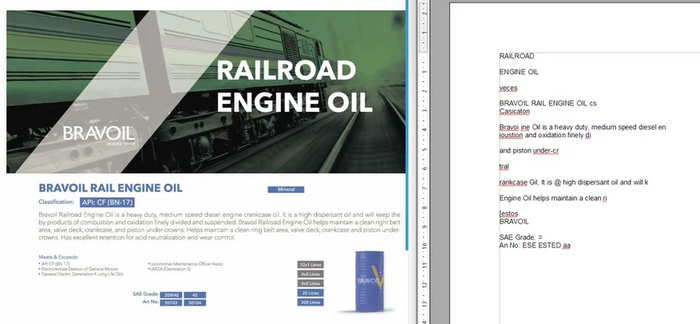
Рекламная брошюра масел. Сложное и разное форматирование, местами текстовый слой есть, местами его нет. Отнюдь не простой документ. Посмотрим, справятся ли конкурсанты.
Adobe Acrobat Pro
Я попробую сравнить качество распознавания при конвертировании в редактируемый формат между бесплатными сервисами и эталоном - Adobe Acrobat DC.
Adobe Acrobat DC идёт первым как эталон, созданный для одной задачи - для работы с pdf-файлами.
Простой файл с текстовым слоем:
Ожидаемо. Никаких трудностей. Полная конвертация в редактируемый формат. Изображение по центре осталось нетронутым, но это невеликая проблема, можно подписать или обработать в Paint.
Простой файл без текстового слоя:
Нестандартный шрифт не распознался, но мелкий шрифт под звёздочкой распознался достаточно хорошо. Ещё пару букв пропустил, но допустимая погрешность для последующего ручного редактирования.
Сложный файл с непостоянным текстовым слоем:
Как сказать. Результат ожидаемо плохой, потому что файл очень сложный. Впрочем, отредактировать всё равно можно, лучше, чем ничего.
Почему я не взял на тест больше программ для ПК? А их нет. Существует несколько простых программ, которые распознают только изображения или устанавливают на компьютер мусор. Я пробовал: Free OCR, Simple OCR, CuneiForm OCR, Freemore OCR. Вторая категория - это титаны вроде Abbyy или Adobe, которых мы стараемся избежать в этой статье.
Итак, перейдём к онлайн-сервисам.
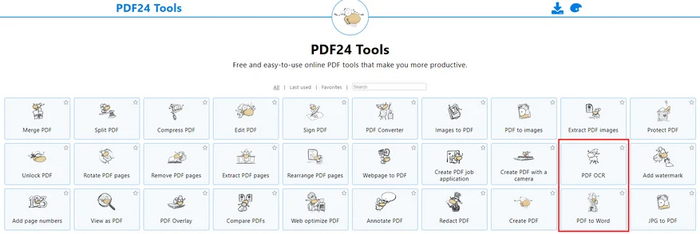
PDF24 tools
PDF24 tools - многогранный сервис. Он может распознать текст в PDF, но в результате всё равно выдаст PDF. На наше счастье среди утилит этого сайта есть и конвертер в Word. Они даже расположены рядом.
Простой файл с текстовым слоем:
Получилось очень плохо, но текст типа сохранён полностью. Изображение вырезано и половина страницы пустая. Ладно, сочтём, что так и должно быть.
Простой файл без текстового слоя:
С задачей сервис не справился. После распознавания и конвертации в ворд, я увидел пустой лист.
Сложный файл с непостоянным текстовым слоем:
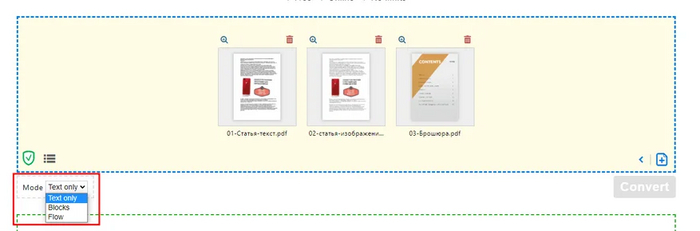
Результат оказался таким же - пустой лист. Но сервис предлагает три режима конвертации:
Я попробовал все три, лучший результат выдал третий режим "только текст":
Распознался даже сложный шрифт!
Брошюра тоже распозналась, но легче мне от этого не стало:
Вердикт:
Спорный сервис. Конвертирует и распознаёт быстро и удобно, много разных утилит. Пусть будет, конечно, на крайняк покатит.
NewOCR
NewOCR - нашёл в одной из статей про лучшие сервисы распознавания символов на просторах интернета. Говорят, что сервис хороший.
Простой файл с текстовым слоем:
Текст распозанёт хорошо, но предлагает выбрать только формат .txt, не распознаёт картинку и даже не пытается сохранить форматирование.
Простой файл без текстового слоя:
Неплохо распознал основной язык - русский, но ужасно справился с английским. Вся латиница превратилась в какую-то кашу. С другой стороны распознать получилось даже нестандартный шрифт с картинки. Не без ошибок, нор всё же. А ещё удалось получить формат Word. От чего это зависит - не знаю.
Сложный файл с непостоянным текстовым слоем:
Брошюра тоже распозналась косячно. Вместо многих символов ужасные кракозябры, слова собрались в кашу, формат только .txt. Зачем мне нужно вот это? Легче отредактировать скриншоты в paint, чем так.
Вердикт:
Сервис неплохо справляется с распознаванием текста, но что-нибудь сложнее, чем абзацы текста ему не под силу. Если в тексте встречается несколько языков, то один из них обязательно будет воспринят неправильно. Даже если указать два языка в поле перед распознанием. Про форматирование можно забыть, его здесь не будет. А ещё мне не понравилось, что каждую страницу многостраничного документа придётся распознавать и скачивать отдельно. Документ на 50 страниц? Простите, но придётся выкачивать по одной странице за раз. А ещё придётся подождать 5 секунд перед распознанием очередной страницы. Не больше ни меньше. Если попытаетесь распознать быстрее, получите ошибку. А ещё не всегда с первого раза точно прицеливается в страницу, иногда выхватывает маленький фрагмент страницы и пытается его распознать.
Img2txt
Сервис Img2txt. Нашёл его где-то на просторах интернета в комментариях к статье о лучших сервисах.
Простой файл с текстовым слоем:
Крупный текст распознал, мелкий превратил в кашу. Решил, забить на текстовый слой и распознал только картинку. Странное решение. Зато предлагает много форматов.
Простой файл без текстового слоя:
Не сказать, что плохо, но и не сказать, что хорошо. Некоторые буквы перепутал, латиницу не распознал. Но по крайней мере можно скачать в вордовском формате.
Сложный файл с непостоянным текстовым слоем:
Слева оригинал, справа результат распознания
Куцый результат. Распозналось плохо, большая часть текста пропущена, слова в кашу превратились. Получилась бесполезная белиберда.
Вердикт:
Ещё один сервис, который распознаёт неплохо простые документы с большими абзацами текста. Раздражает, что сначала нужно загрузить файл, выбрать для него язык, потом файл обработается сервером, нужно снова выбрать для него язык и запустить распознавание. Я как-то ожидал, что загружая я уже достаточно чётко выражаю намерение распознать файл.
Ещё одна беда - это постраничное распознавание. Как и в случае с NewOCR каждая страница распознаётся отдельно, скачивается отдельным документом. Только тут ещё необходимо для каждой новой страницы повторно выбирать язык.
А ещё это единственный сервис с ограничением размера файла. Максимум - 8 мб.
Online OCR
Online OCR - сервис с самым непримечательным названием. Я упоминал этот сервис в статье про 8 бесплатных аналогов платных программ.
Простой файл с текстовым слоем:
Ого. Результат удивляет. Почти идеальный. Мало того, что распознание прошло почти мгновенно, так ещё и латиница распозналась там, где надо. Даже мои опечатки были распознаны правильно. То что текст вокруг картинки - это ерунда. Чуть-чуть не дотянул до уровня Adobe.
Простой файл без текстового слоя:
Снова в яблочко! В этот раз побольше промахов, но результат достойный. Хотя бы картинка сохранилась и часть мелкого текста с неё удалось распознать.
Сложный файл с непостоянным текстовым слоем:
Ух ты! Сервис справился с распознаванием и этого документа! Удивительно, но факт. Есть некоторые недочёты, но это очень хороший результат. С редактированием такого файла в ворде придётся очень сильно помучиться, зато распознаны все таблички, большинство надписей. Если в ваши обязанности не входит вёрстка, то это именно то, что нужно.
Я бы назвал это самым большим успехом. Даже Adobe по сравнению с этим меркнет:
Adobe слева, Online OCR справа
Вердикт:
Это лучший сервис! К сожалению, без регистрации он не даст распознать PDF больше 15 страниц, большие изображения, ZIP-архивы и ещё что-то. Но после регистрации сервис даёт только 50 бесплатных страниц.
Я слышу слово "абьюз" или мне кажется? Раскрою секрет, как сделать сервис абсолютно бесплатным. Создатели сайта не придумали подтверждение почты при регистрации. Можно указать любой вымышленный адрес. Как только заканчиваются страницы, переезжаем на новый аккаунт и пользуемся 50 бесплатными. Забавно получается.
Читайте другие статьи переводческого цикла в серии постов.
Если вам интересен подобный контент, приглашаю подписаться на мой телеграм-канал @grolchannel, где я публикую разнообразные посты значительно чаще.
На днях загрузила свою 900-ю статью в Википедию. Нет, я сейчас здесь не для хвастаться, хвастаться буду, когда напишу тысячную. У меня одна мысль появилась, чуть ниже сформулирую.
Я тут статистику по написанным мною статьям подсчитала, вышло так:
из 900 статей
- 423 -- населённые пункты, реки, заливы, полуострова и заповедники Эстонии
- 129 -- улицы Таллина
- 56 -- предприятия Эстонской ССР и Эстонской республики
- 55 -- мызы (бывшие имения) на территории Эстонии
- 50 -- персоналии (СССР, Польша, Эстония, Белоруссия, Германия, Англия)
- 38 -- муниципалитеты Эстонии
- 30 -- эстонская мифология
- 23 -- история, культура и география Белоруссии
- 22 -- история и культура Эстонии
- 19 -- населённые пункты Испании, Черногории, Хорватии, Венгрии, Словакии, Румынии
- 15 -- сооружения и объекты Эстонии
- 11 -- катастрофы, трагедии, красный и белый террор
- 3 -- парусный спорт
ну, и оставшееся там по мелочи на различную тематику, от польского оркестра до бессточного озера и марсианского кратера. А ещё я иллюстрирую статьи: загружаю свои фотографии и исторические, найденные в различных интернет-архивах (с соблюдением требований авторского права, естественно). Моих фотографий в фонде Википедии сейчас около 900.
Так вот, к чему я всё это. Однотипные статьи по эстонской географии меня в последнее время сильно притомили, однако, эту работу не брошу, так как в последние годы я в Википедии практически одна пишу по эстонской тематике, ну и недавно появился довольно эрудированный господин под ником Принц Шотландии. Он не из Эстонии, но почему-то очень ею интересуется.
Ну вот, опять в сторону ушла.
Так вот, девочки и мальчики, если вы хотите, чтобы в Википедии появились статьи о людях, которых вы очень любите/уважаете (но статей о которых в Wiki почему-то нет), значимых событиях и резонансных происшествиях, населённых пунктах и их истории -- с удовольствием напишу статью. Бесплатно. Вся моя работа в Википедии не имеет никакого денежного вознаграждения (это у меня хобби такое, вместо компьютерных игр). Только изредка кто-то напишет похвальное письмо (за 6 лет 7 месяцев и 11 дней их было 4), да виртуальным орденом наградят (их у меня 3). Ну, и статус у меня на проекте более-менее "авторитетный":
я -- патрулирующая. То есть загруженные мною статьи, правки чужих статей, переименования статей проектом принимаются сразу, без необходимости утверждения кем-то более высоким по статусу.
К персоналиям такие требования: наличие званий / титулов / госнаград / учёной степени (не ниже докторской, статьи о кандидатах наук без орденов или хотя бы медалей безжалостно удаляются администраторами в течение пары дней). Если человек умер -- статья будет как в память о нём, если жив -- подарок ему. Я сама буду искать авторитетные источники информации и через какое-то (недолгое) время извещу вас, возможно написать такую статью или нет. Мой стаж писательско-редакторской работы -- 30 лет.
Жду ваших предложений.
Да, вот ещё что. Если у вас есть сделанные вашими руками фотографии, подходящие для иллюстрирования уже имеющихся в Википедии статей -- с большим интересом обсужу с вами этот вопрос. Статей без иллюстраций в Википедии очень много, особенно о деревнях и сёлах России и стран бывшего СССР, об их истории, и мне от такого положения дел становится обидно.
К знатокам у меня такая просьба: подскажите современные источники по теме "красного" и "белого" террора (особенно интересует прибалтийский регион). Советские источники, как считают некоторые "вики-умники", устарели. Для меня это типа того, как "Труды Н. М. Карамзина как исторический источник устарели", но спорить в Википедии -- это тратить дни/недели/месяцы времени и килограммы нервных клеток (коих у меня осталось в мизерном количестве).