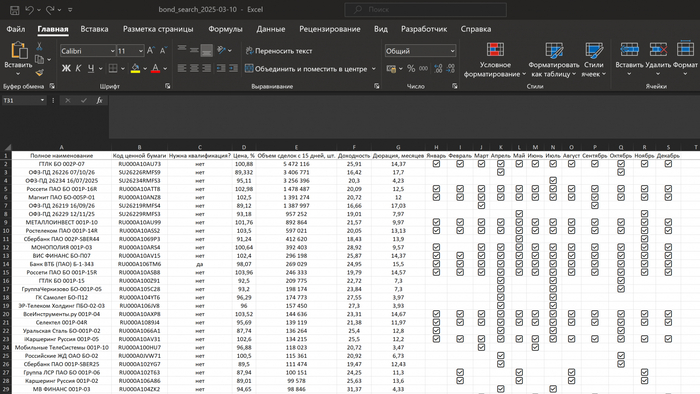
На Московской бирже торгуется более 2500 облигаций, но большая часть из них неликвидна - в стакане почти нет предложений и сделок совершается крайне мало. Это затрудняет покупку и продажу таких бумаг. При этом известные мне публичные сервисы не суммируют объемы торгов за период, поэтому сложно быстро найти облигации с высокой ликвидностью.
Пять лет назад написал Node.js-скрипт, затем адаптировал его для Google Таблиц, а теперь разрабатываю Python версию. При помощи сообщества на GitHub эта Python версия идёт к созданию полноценной библиотеки с расширенными возможностями: автоматический поиск ликвидных облигаций, расчет денежных потоков, сбор новостей по эмитентам и вычисление оптимального объема покупки. Все это направлено на помощь простым инвесторам, вроде нас с вами, чтобы оперативно находить выгодные инвестиционные инструменты и принимать решения на основе актуальной информации.
В материале будет много интересной информации для поиска облигаций, но также будет интересно почитать и тем, кто хочет узнать о более простых альтернативах инвестирования.
Критерии выбора ликвидных облигаций на Московской Бирже
Ликвидность это один из ключевых параметров, поскольку даже высокодоходная бумага бесполезна, если её невозможно купить. В моём скрипте для поиска облигаций используются несколько основных критериев:
Доходность
Эффективная доходность облигации — один из главных параметров. В фильтре задаётся диапазон, например, от 15% до 30%. Важно учитывать, что этот показатель не включает налог с купонов и комиссии брокера.
Текущая цена
Облигации торгуются по разным ценам относительно номинала, все цены облигаций указаны в процентах, и этот параметр позволяет фактически выбрать стратегию получения дохода:
Если облигация торгуется сильно ниже номинала, основная доходность будет сформирована к моменту погашения (за счёт разницы между ценой покупки и номиналом).
Если облигация торгуется близко к номиналу, основная доходность складывается из купонных выплат в течение срока жизни.
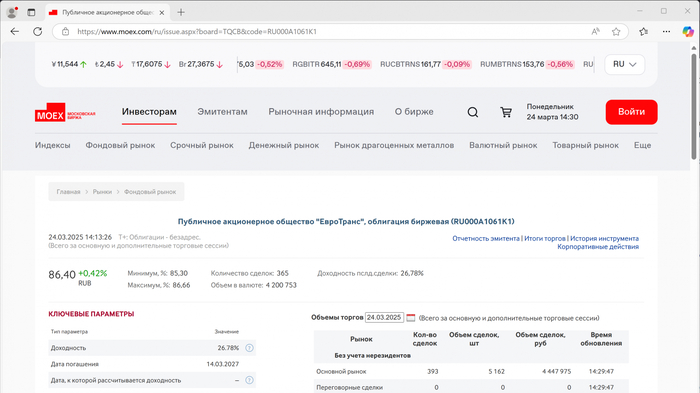
Пример: облигация ЕвроТранс БО-001Р-03 на 10 марта 2025 года (код RU000A1061K1, ссылка):
Текущая цена: 86% от номинала
Купонная доходность: 13,6% годовых
Доходность к погашению: 26,78% годовых. Доходность к погашению предполагает, что вы держите облигацию до погашения и что все купонные выплаты будут произведены в срок.
Откуда такая разница? Дело в том, что облигация сейчас торгуется ниже номинала, а при погашении инвестор получит 100% номинальной стоимости. То есть, кроме купонов, инвестор дополнительно зарабатывает на разнице в цене. Именно поэтому параметр текущей цены помогает выбрать, когда получать основную доходность — постепенно в течение срока или разово в момент погашения.
Дюрация
Показатель дюрации позволяет выбрать облигации с нужным сроком жизни. Например, если мне нужна бумага на ближайшие 3–18 месяцев, фильтр исключает слишком краткосрочные или долгосрочные варианты.
Прозрачность выплат
Наличие полной информации о будущих купонных выплатах или наличие оферты.
Также я исключаю флоатеры, поскольку Московская биржа не передаёт по ним данные о будущих платежах.
Ликвидность
Ликвидность - основной критерий, ради которого создавался этот инструмент. В скрипте анализируются:
Минимальное число сделок за каждый из последних 15 дней - чтобы исключить облигации, которые могут внезапно «замереть».
Общий объём сделок за 15 дней - параметр, который позволяет выявлять бумаги с устойчивым спросом. Этот скрипт позволяет гибко подстраивать фильтры и находить действительно ликвидные облигации, подходящие под конкретно Вашу стратегию инвестирования.
Как работает скрипт
Скрипт использует API Московской биржи для получения актуальных данных об облигациях. Данные скачиваются для ознакомительных целей и это позволяет оперативно находить ликвидные облигации.
Ограничение запросов. С сентября 2024 года API Московской биржи начало периодически разрывать соединение без объяснения причин. Это продолжалось около полугода, поэтому в коде был установлен лимит — не более 50 запросов в минуту. Сейчас, в марте 2025, эта проблема больше не наблюдается, но ограничение оставлено для стабильности.
Московская биржа периодически меняет формат данных, что требует оперативного обновления скрипта.
Пошаговое руководство по запуску
Если вы не разбираетесь в программировании, но хотите воспользоваться этим Python-скриптом, следуйте инструкции:
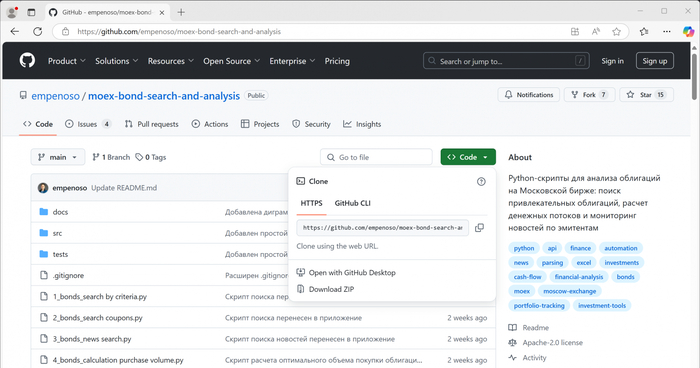
Шаг 1. Скачайте скрипт
Откройте ссылку: GitHub проекта.
Нажмите "Code" → "Download ZIP".
Разархивируйте ZIP в удобную папку.
Шаг 2. Установите Python
Если Python не установлен:
Шаг 3. Установите зависимости проекта
Откройте папку с проектом.
Дважды кликните файл install_requirements.bat (Windows) или install_requirements.command (MacOS).
Шаг 4. Запустите скрипт
Дважды кликните файл 1_bonds_search by criteria.py.
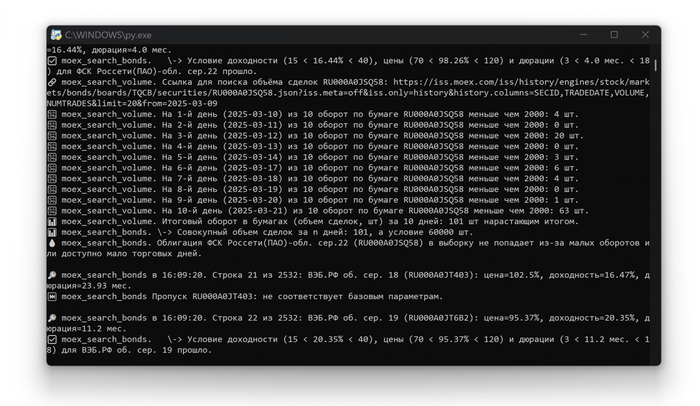
Во время выполнения отображается лог выполнения.
Шаг 5. Наслаждайтесь результатом
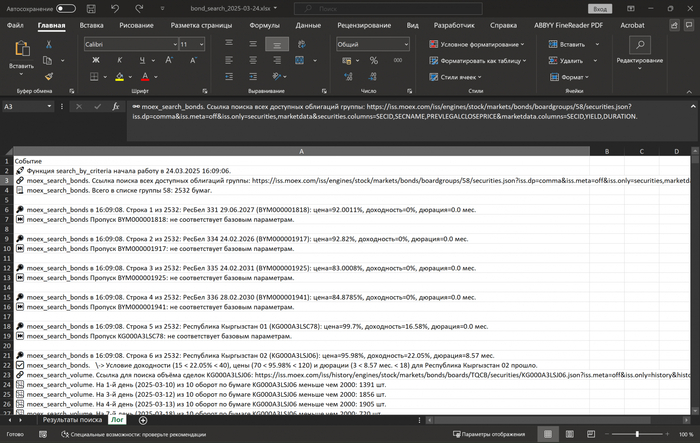
Будет создан файл с текущей датой: bond_search_2025-03-25.xlsx
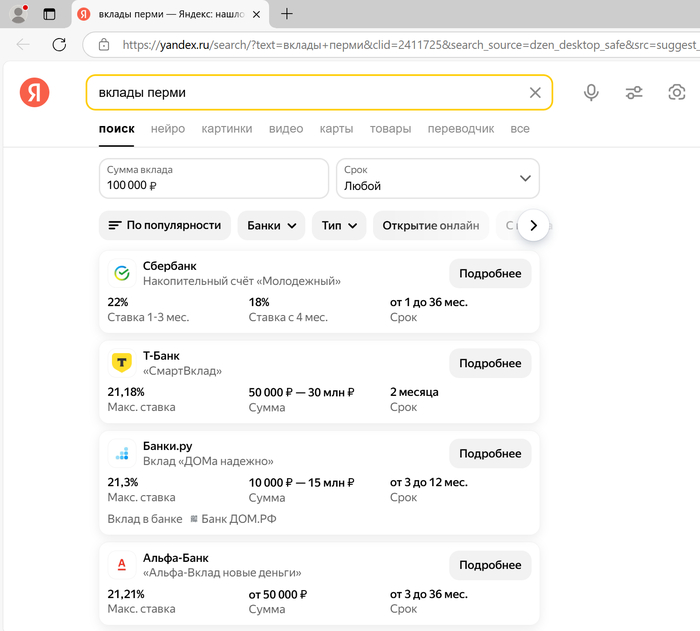
Обычные вклады это до сих пор альтернатива облигациям
Государственные облигации федерального займа считаются наиболее надежными инструментами инвестирования и приносят доходность в диапазоне от 14% до 18%, в зависимости от сроков обращения. Этот показатель сейчас уступает ставкам по банковским вкладам.
Следующими по надежности идут корпоративные облигации, чья доходность может доходить до 35%, однако они сопряжены с большими рисками. Надо понимать что высокие доходности несут высокие риски: это подходит тем, кто больше разбирается в данной сфере и лучше понимает, что такое эмитенты и как с ними работать.
Банковские вклады занимают промежуточную позицию между этими категориями активов. Их доходность сравнима с доходностью надежных корпоративных облигаций, однако основное преимущество вкладов заключается в отсутствии рисков благодаря системе государственного страхования вкладов. Они также отличаются простотой использования: достаточно разместить средства и ожидать истечения срока депозита.
Опытным инвесторам можно рекомендовать облигации, но тем, кто предпочитает избегать глубокого анализа рынка и сложных поисков, банковские вклады станут достойной альтернативой. К тому же, сейчас легко отслеживать ситуацию на рынке. Можно просто пользоваться поисковиком Яндекса.
Преимущества open source и шаги к Python-библиотеке
Идея - набор из четырёх скриптов для личного использования. Разработал их как частный инвестор, понимая какие задачи стоят передо мной:
Поиск ликвидных облигаций
Автоматический расчёт денежных потоков
Сбор новостей по эмитентам
Расчёт оптимального объёма покупки
От одиночного скрипта к полноценной библиотеке
Так как проект открыт, к нему подключилось сообщество. Одним из первых с pull request пришёл lmasikl, который заинтересовался темой облигаций и предложил преобразовать набор скриптов в полноценную Python-библиотеку. Уже было внесено множество улучшений:
Март 2025
#12 – Добавлен простой тест как пример (автор: lmasikl, одобрено 19 марта)
#11 – Добавлена диаграмма взаимодействия пользователя со скриптом (автор: lmasikl, одобрено 17 марта)
#7 – Отформатирован код с дефолтными настройками Ruff (автор: lmasikl, одобрено 14 марта)
#6 – Внесен в приложение скрипт расчета оптимального объема покупки облигаций (автор: lmasikl, одобрено 13 марта)
#5 – Перенесен в приложение скрипт поиска новостей (автор: lmasikl, одобрено 12 марта)
#4 – Перенесен в приложение скрипт поиска облигаций (автор: lmasikl, одобрено 10 марта)
#3 – Начат переход к полноценной библиотеке (автор: lmasikl, одобрено 6 марта)
Февраль 2025
#2 – Исправлены некорректные значения в рублях (автор: gogbajbobo, одобрено 21 февраля)
#1 – Выполнен рефакторинг кода (автор: lmasikl, одобрено 20 февраля)
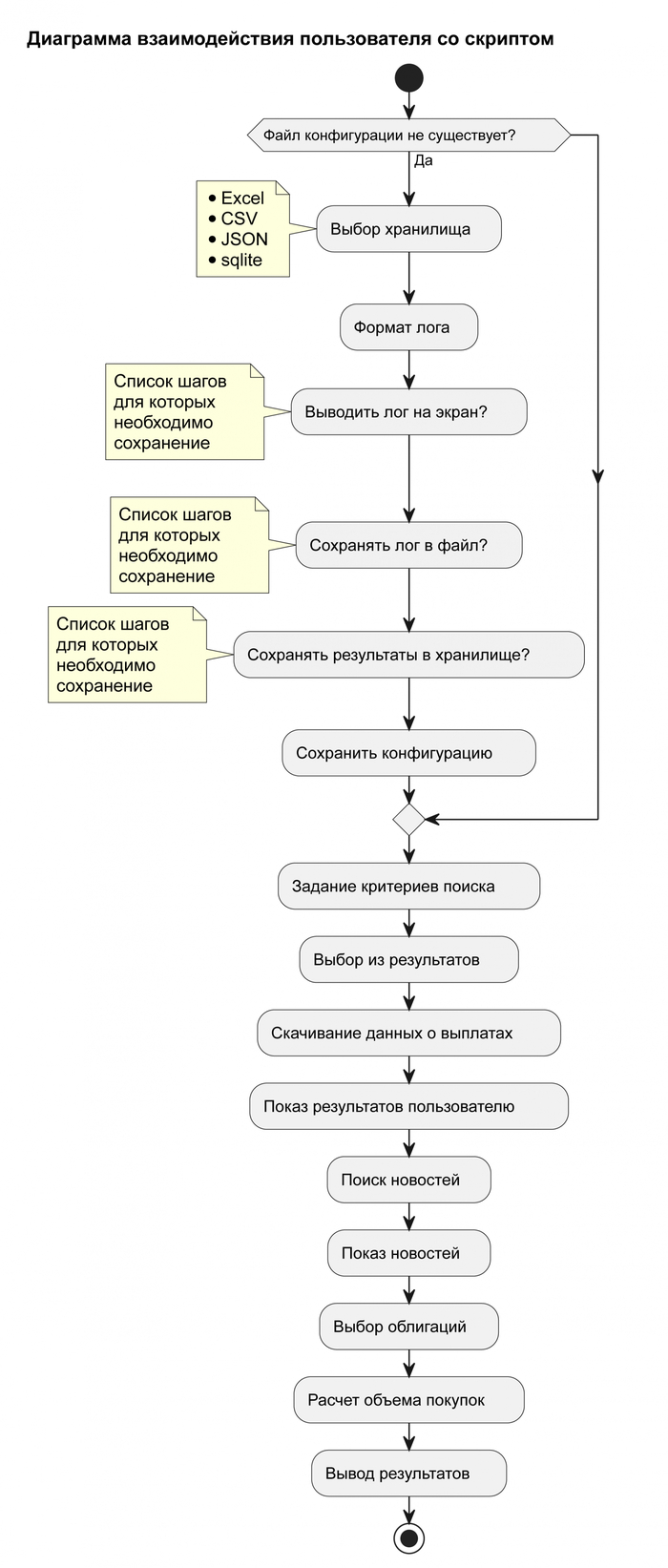
Добавлен план схемы работы:
Почему open source — это важно?
Открытый код даёт возможность сообществу вносить улучшения, исправлять ошибки и расширять функциональность. Гибкость библиотеки позволяет каждому настроить поиск облигаций под собственные нужды, создавая индивидуальные стратегии отбора.
Как практически использовать эту библиотеку
Допустим, у нас есть 300 000 рублей, которые мы хотим вложить в облигации. Чтобы минимизировать риски, разделим сумму на 10 разных облигаций.
Поиск ликвидных облигаций
Первая часть скрипта анализирует рынок и отбирает бумаги с хорошей ликвидностью, подходящие под заданные критерии (доходность, дюрация, цена и т. д.).
Проверка эмитента
Запускаем вторую часть скрипта — он собирает последние новости по эмитентам. Если обнаружены негативные публикации (например, судебные иски или финансовые проблемы компании), такие облигации исключаем из списка.
Расчёт денежных потоков
Далее, используя третью часть скрипта, можно заранее рассчитать будущие выплаты по купонам и спрогнозировать точную доходность портфеля.
Расчёт объёма покупки
Последний скрипт поможет рассчитать, сколько именно облигаций можно приобрести с учётом доступного капитала и НКД. Это позволяет эффективно распределить средства и избежать недостатка ликвидности.
Раз в месяц достаточно просматривать портфель, анализировать новые облигации через первый скрипт и при необходимости докупать бумаги. Такой алгоритм можно повторять бесконечно, постепенно увеличивая капитал.
Заключение
Использование этого скрипта позволяет частному инвестору систематизировать процесс подбора облигаций, минимизировать риски и упростить управление портфелем.
Присоединяйтесь к сообществу!
Этот проект развивается благодаря усилиям энтузиастов и разработчиков, заинтересованных в автоматизации инвестирования. Если у вас есть идеи по улучшению функциональности или вы хотите протестировать новые возможности, присоединяйтесь к обсуждению на GitHub!
Любые предложения, правки и новые модули помогут сделать библиотеку ещё более мощным инструментом для инвесторов.