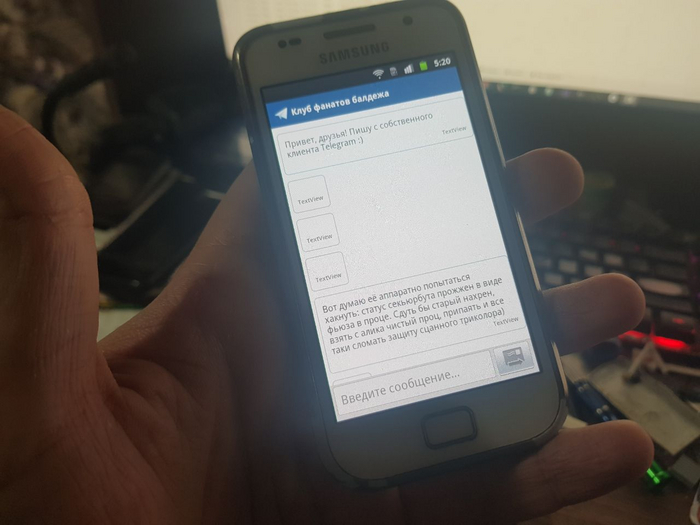
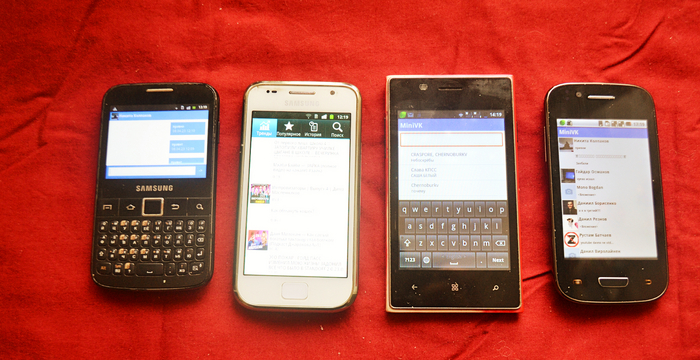
Где я подробно рассказываю о том, как реализовал клиент современного мессенджера Telegram на Android 1.5+ и выше. Таким образом, Telegram будет работать даже на самом первом Android-смартфоне в мире, T-Mobile G1, причём на стоковой прошивке!
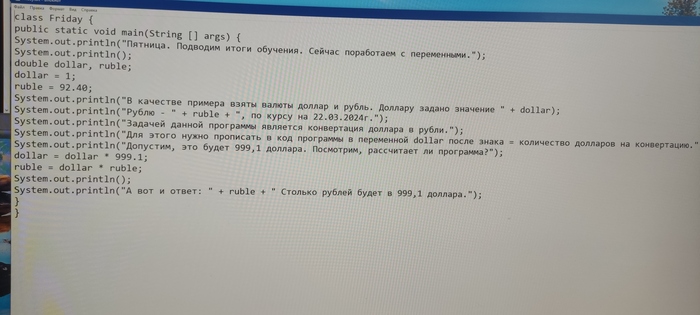
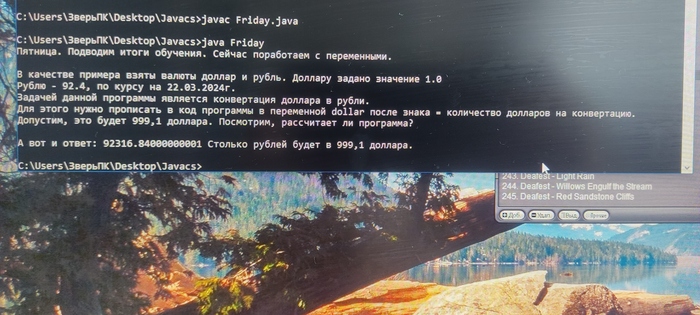
Всем привет! Спецы по Java, скажите, почему в ответе после точки столько нулей и единица? С математикой у меня конечно не айс, но не на столько же)
За отсутствие отступов извините 🫣 сегодня уже начал писать по человечески)
Upd: ответ получен, благодарю всех! Спасибо так же за наставления и подсказки. Теперь буду правильно фотографировать экран, писать не в блокноте, жать 200 и цитировать Шекспира (на будущее тем, кто не смог ответить на поставленный вопрос, но очень метко нашел мои непрофессиональные недостатки 😁).
Друзья! Думаю многие мои давние читатели помнят о цикле статей "сам себе экосистема", где я стараюсь вдохнуть новую жизнь в девайсы 10+ летней давности путем разработки собственных клиентов нужных мне сервисов! Уже вышло две статьи из этой рубрики ( Сам себе экосистема: Как я адаптировал старый смартфон под современные реалии и написал клиенты нужных мне сервисовНе дадим Windows Phone умереть! Как я написал свои клиенты VK, YouTube для Nokia Lumia? Сам себе экосистема ч.2 ). Сейчас, вот, держу несколько своих девайсов на Android 2.2 и потихоньку пилю наработки ещё нескольких нужных мне приложений: клиент Сбера на СМСках (по сути, удобная обертка над 900 с виджетами), актуальная погода на неделю вперед, вьювер карт OpenStreetMap и трекинг посылок. ВКшечка и ютубчик, как мы помним, уже есть. Давайте устроим голосование, не одному ли мне это интересно и быть ли третьей статье из рубрики "сам себе экосистема"?
Язык Основное: - Java Core (основные механизмы языка: типы данных, циклы и тд) - коллекции - исключения - дженерики - аннотации (про них я, кстати, писал статью на хабр) - функциональные интерфейсы и Stream API Достаточно общего понимания и умения отвечать на собесах: - многопоточность - сборщик мусора - устройство памяти JVM - общее устройство JDK Курс по Java от Oracle
Фреймворк (Spring) Основное: - Spring MVC - Spring Data JDBC - основы работы Spring: IoC, DI, бины и тд - разница между Spring и Spring Boot Для общего развития: - Spring Security Курс по основам Spring
В прошлой части мы ознакомились с базовыми понятиями деревьев и обошли одно дерево рекурсией. В данной статье мы еще раз рассмотрим понятие рекурсии и посмотрим как небольшие во время итерации могут повлиять на результат. В данной части мы сфокусируемся на итерации, а в следующе мы уже будем использовать эти подходы для решения задач.
Обход деревьев часто ощущается как лабиринт
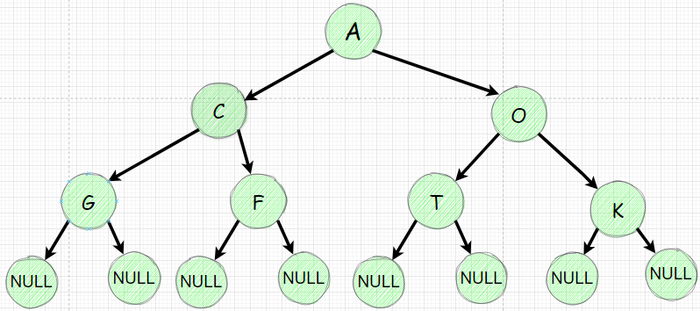
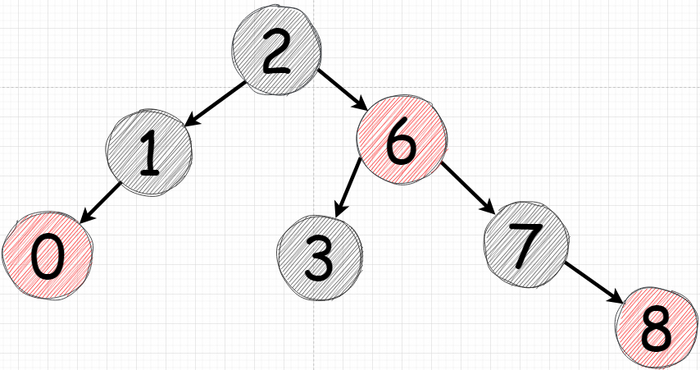
Давайте рассмотрим уже знакомое дерево:
Прямой обход дерева (Префиксный) - NLR
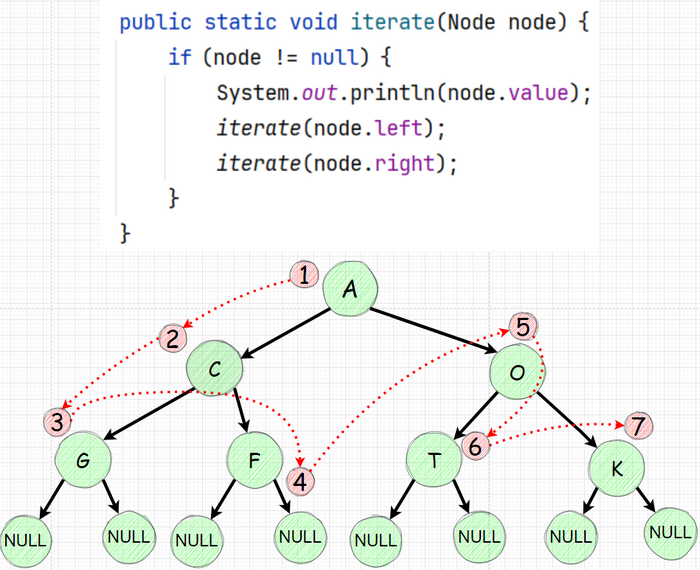
В прошло части мы уже итерировались по дереву рекурсивно. В нем мы сначала печатали значение узла (Node) затем посещаем левое поддерево (Left) и лишь потом правое поддерево (Right). Такой подход называется прямым или еще префиксным - NLR.
Распечатка значения и последующее движение влево вниз и уже затем вправо.
Центрированный обход дерева (Инфиксный) LNR
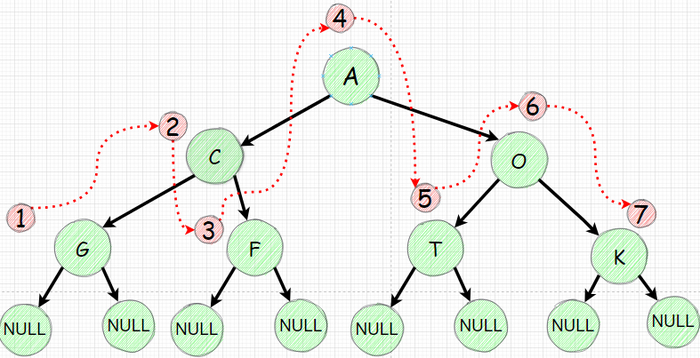
Теперь сделаем одно минимальное изменение - сначала мы пойдем в левое поддерево (Left) затем распечатаем значение узла (Node) и потом пойдем в правое поддерево (Right) - этот обход называют Инфиксным (от лат. in внутри fixus закрепленный) или центрированным - LNR. Понятие инфиксный прошло из математики. Если очень упрощать значит что N находится между L и R.
разница лишь в 1 линии но процес "обхода" меняется.
И так вроде рекурсия выполнила ровно такой же обход, но теперь процесс распечатки значения узла мы стали делать после того как уходим "влево". Теперь если задуматься то первая печать произойдет лишь когда мы дойдем до нижнего левого узла. Давайте изобразим как будет выглядеть "обход" а порядок печати значений узлов:
Обратный или Постфиксный обход. LRN
Думаю уже понятно что данный подход подразумевает печать значения узла (Node) после посещения левого (Left) поддерева и правого (Right) поддерева - LRN
Печатаем лишь после обхода левого и затем правого поддеревьев.
Порядок распечатки изображен ниже:
Минимальные изменения - большие последствия.
Изза минимальных изменений (меняя лишь порядок одной строчки) мы получили разные обходы дерева. Это позволит нам решать разные задачи в будущем.
Следующий этап.
В следующей статье мы рассмотрим какие задачи мы можем решать используя описанные подходы. Одна из главных целей цикла статей - помочь преодолеть страх задач про деревья во время собеседований. Думаю стоит повторить еще раз - как только вам прилетела задача на деревья во время собеса начинайте с того что напишите функцию обхода. Большинство алгоритмических задач решается именно через рекурсию (но не только через неё).
Деревья являются одним из самых пугающих вещей в разработке. Еще хуже дело обстоит, когда программист встречает задачу, связанную с деревьями, во время собеседования. В этой статье я постараюсь минимизировать боль, связанную с этой темой.
Деревья бывают разные. Мы рассмотрим двоичное сбалансированное.
В данной статье мы рассмотрим наиболее популярные — двоичные сбалансированные (красно-черные) деревья.
Пример бинарного дерева. У каждого листка может быть не более двух наследников.
Основные понятия.
Рассматривая бинарные деревья нужно знать следующие понятия:
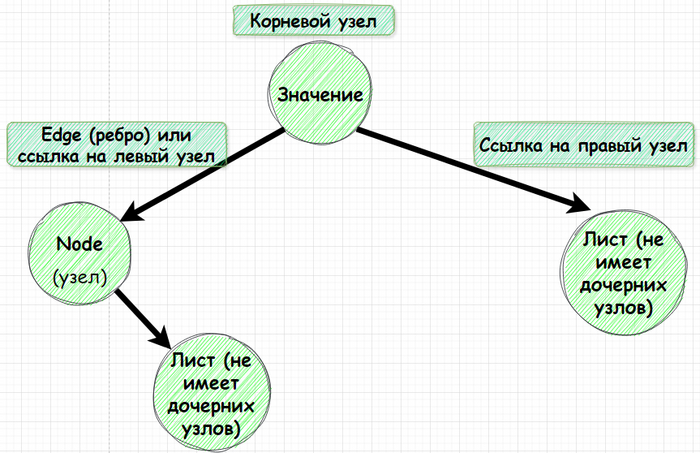
Node - он же узел. Это элемент дерева, содержащий какое-то значение, которое может быть любым, от примитива (например, числа) до объекта (например, пользователя).
Edge или ребро. Ссылка, соединяющая один узел с другим или указывающая на пустое значение (null).
Root Node. Верхний узел дерева, от которого начинается вся структура.
Leaf - Узел, не имеющий наследников, то есть находящийся в самом низу иерархии.
Высота дерева - Количество "уровней", от корня до самого нижнего узла.
Несбалансированные деревья могут выродиться в связный список.
Несбалансированные деревья — это деревья, у которых высота левой и правой веток может значительно отличаться. В худшем случае все узлы могут располагаться по одной стороне. В этом случае дерево деградирует до связного списка.
деградированное дерево вырожденное в связанный список.
Сбалансированные деревья.
Сбалансированные (например красно-черные) при каждом добавлении нового узла проверяют, является ли дерево "несбалансированным". Если условие истино то дерево делает "разворот" свои узлов.
Пример красно черного сбалансированного дерева. Именно такое используется в TreeMap
Сбалансированные деревья никогда не вырождаются в связанные списки. В J ava джаве деревья представлены коллекцие TreeMap и TreeSet (который инкапсулирует TreeMap внутри себя).
Как могут быть представлены деревья на уровне кода.
Если мы не используем готовые решения вроде TreeMap то простейшее дерево может быть представлено в виде следующего класса:
Простейший узел. По большому счету это единственный важный момент.
Итого что мы имеем:
String data это то значение которое хранит узел. Это может быть любым объектом - в нашем случае просто строка.
Node left - ссылка на левого наследника.
Node right - ссылка на правого.
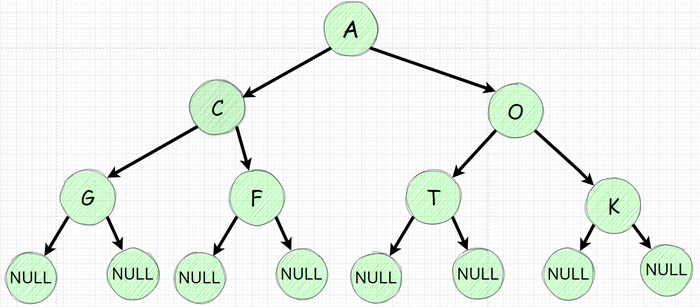
Используя Node класс создадим дерево
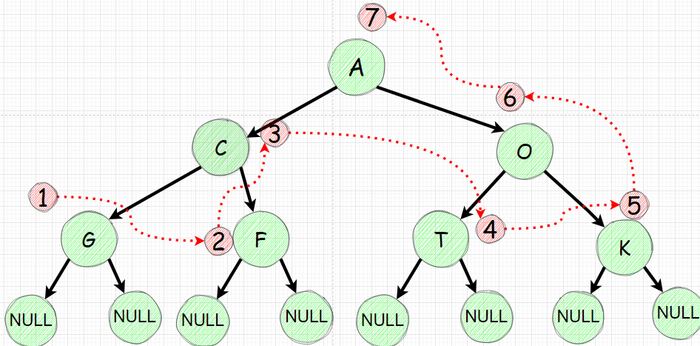
Поочередно инициализируем наше дерево с 7 узлами
Изобразим полученное дерево:
Итерация по дереву - один из самых важных навыков для решения задач.
Большинство (если не все) задач, связанных с деревьями требуют итерации или обхода узлов. Чаще всего, умея обходить дерево, вы решаете львиную часть проблемы. В данной статье мы рассмотрим лишь 1 вариант итерации, я напишу отдельные статьи чтобы рассмотреть другие подходы.
Используем рекурсию для итерации и распечатки всех элементов.
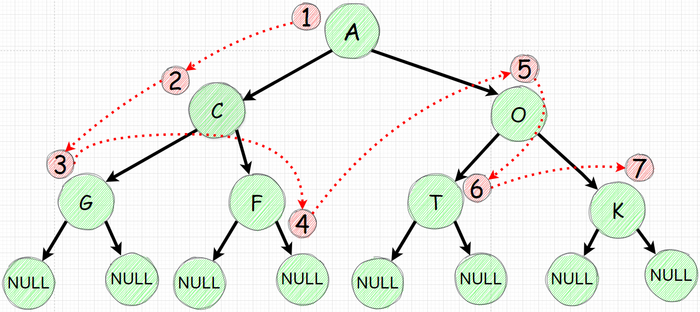
Каждый раз когда вам прилетела задача по деревьям, помните - скорее всего в основании решения будет рекурсия (это не всегда так, но довольно часто). Те у вас будет функция которая будет вызывать сама себя. Для распечатки дерева напишем рекурсию которая обходит все элементы начиная с левого наследника:
Код вроде простой но не стоит его недооценивать. Давайте проговорим этапы:
Распечатываем значение узла
Идем к левому наследнику и повторяем действие (те опять распечатываем и идем влево)
после того мы обошли все левые и уткнулись в null мы "возвращаемся" на уровень который находится наверху от нижнего левого и идем в правый наследник
зайдя в правый распечатывем и идем влево повторяя шаги 2-3.
Все это звучит странно проще будет изобразить:
Это лишь первая статья но в ней мы ознакомились с основными понятиями. Также мы обошли дерево, используя рекурсию. Это один из самых популярных подходов в решениии подобных задач. В следующей части мы рассмотрим альтернативные варианты работы с деревьями.
Например, вот так в Java выглядят классные и простые методы интерфейса List:
Но у обобщений много нюансов: вложенность, вариантность, границы и т.д. Это сильно усложняет их использование.
Вот не менее классный, но совсем непростой flatMap интерфейса Stream🙈:
Также, реализация дженериков - всегда трейдоф. Мы либо получаем большой исполняемый файл, из-за того, что приходится генерировать код для разных типов. Либо получаем дополнительную нагрузку в рантайме, из-за различных проверок.
Из-за таких сложностей, в языке Go (философия которого - простота и минимализм) дженерики появились аж через 12 лет после релиза языка. А первый коммент про то что нужны дженерики появился меньше чем через 24 часа🙃
Вообще, во многих популярных языках дженерики появились не с первой версии, но рано или поздно, разработчики были вынуждены их ввести: - С++ вышел в 1979, а дженерики добавили в 1986 - Java - 1996, дженерики - 2004 - C# - 2001, дженерики - 2005 - Go - 2009, дженерики - 2021