


Деревья
4 поста
4 поста

2 поста

Прошло уже больше года, но многие разработчики до сих пор не в курсе - вышел SPRING AI. Этот спринговый фреймворк позволяет интегрировать AI решения используя лишь Java. До этого решения бОльшая часть решений была написана на python/nodejs. Давайте сделаем короткий обзор на те возможности которые предлагает этот фреймворк:
Возможность писать решения совместимыми с большинством существующих моделей. Те одно и тоже решение сможет применять разные модели без изменений кода - например chatgpt/grok/antropic/deepseek
Возможно интегрировать MCP сервера, которые модель может использовать для обогощения контекста запроса
Интеграция с векторными хранилищами - еще одна возможность поиска, если данных большое количество
Возможность сохранения истории - очень удобно для создания чат ботов
Структурированный ответы (на той случай если нужно обязательно возвращать данные в нужном формате, например json итд)
Я перечислил лишь часть возможностей, но уже они решают огромное количество базовых проблем при интеграции программы с LLM моделями. Благодаря этому решению Java может стать одной из альтернатив, ранее лидерство (да и до сих пор) держал Python. Но благодаря лучшей производительности и богатой инфраструктуре, идущей вместе со сущесвующей экосистемой спринг может стать хорошей альтернативой.
В следующих статьях мы более подробно рассмотрим Spring AI, а пока кому интересна промышленная разработка приглашаю в котовскую телеграм группу
В предыдущих частях мы познакомились с рекурсивным подходом решения деревьев. В этой части мы воспользуемся стэком.

Рекурсия чаще всего используется только во время собеседований (а этот цикл статей именно направлен на подгтовку к собеседования). В промышленной разработке её чаще избегают изза потенциальных следующих потенциальных проблем:
Криво написанная рекурсия может выполняться бесконечно (в "лучшем" случае это приведет к ошибке переполнения стэка). В худшем программа повиснет (особенно если программа однопоточная).
Изначально чаще всего под стэк выделяется не более 1мб памяти а это значит что рекурсивная функция сможет вызвать саму себя где то от 10 до 20 тысяч раз. (размер можно легко увеличить с помощью параметра -Xss но стоит помнить что у JDK есть ограничения по верхней границе - обычно до 1 ГБ)
Рекурсия сложна для понимания, особенно новичкам.
Высокое потребление памяти - каждый раз спуская на уровень ниже мы позволяем сборщику мусора удалить ссылки используемые на верхних уровнях - и это не ошибка тк все объекты используемы выше текущего уровня будут использованы когда мы вернемся "снизу"
Во многом, задача на деревья определяется тем, как мы можем проитерироваться по всем узлам. В рекурсии мы вызываем рекурсивную функцию и передаем ей наследники. В случае же с очередью или стэком мы используем следующий трюк:
Добавляем корневой элемент в очередь
Проходим по всем элементам очереди и ранее добавленные узлы
Если наследники узла не пусты добавляем в очередь опять
Распечатаем все значения дерева сверху вниз, распечатывая значения на каждом уровне слева направо, как гирлянду.
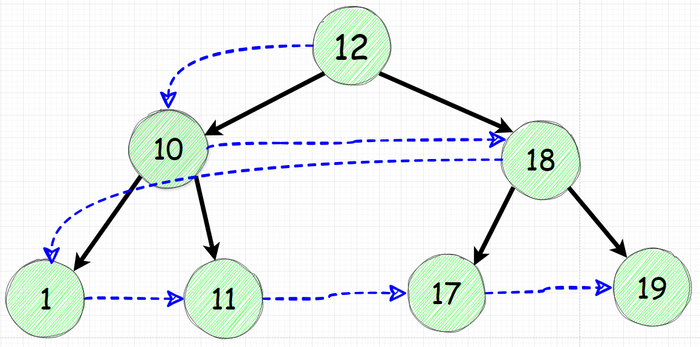
Желаемый порядок распечатки - сверху вниз, слева направо.
Для начала познакомимся с интерфейсом очереди (Queue) в Java. Очередь представляет собой FIFO (first in, first out - первый зашёл, первый вышел) структуру. В нашем случае потребуется два метода:
add - добавить в очередь
poll - вытащить первого из очереди (элемент который бы добавлен раньше других)
Обходить дерево мы будем следующим способом:
Добавим в очередь корневой элемент
"Вытащим" добавленный элемент и положим в очередь его наследников
Повторим 1-2 шаги пока в очереди ничего не останется
Изобразим эти действя по шагам:
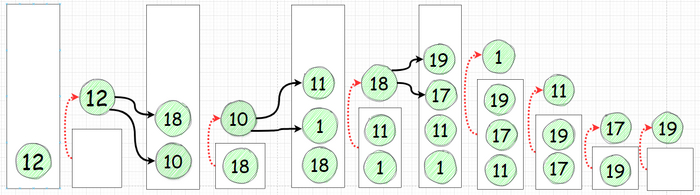
Движемся слева направо. Красными стрелками указаны "вытаскиваемые" из очереди элементы.
На графике выше вы могли бы заметить, что после момента добавления 4-х элементов больше элементы не добавляются, так как у каждого из 4-х узлов нет наследников.

И так как запомнить данный подход если он попадется на собеседовании? Я бы рекомендовал держать в памяти две вещи:
условие while (!queue.isEmpty())
queue.poll() - вытаскивание элемента
В следующих статьях мы будем использовать очередь для решения задач, связанных с деревьями. Кому интересна промышленная разработку приглашаю в котовскую телеграм группу
Продолжаем цикл статей про деревья. Основной целью этого цикла является практика и подготовка к собеседованиям а не промышленные решения (о них я расскажу в следующих частях). В этой части мы еще раз воспользуемся рекурсией для решения одной популярной задачи.

Для начала определимся что такое бинарное дерево поиска:
У дерева не более двух наследников (оно бинарное)
В левом подграфе значения всех узлов меньше, чем значение самого узла
В право подграфе значения всех узлов больше, чем значение самого узла
Такое дерево называется Бинарным Деревом Поиска (Binary Search Tree). Но не стоит путать его с балансированым бинарным деревом. Про сбалансированные бинарные деревья мы поговорим в следующих частях.
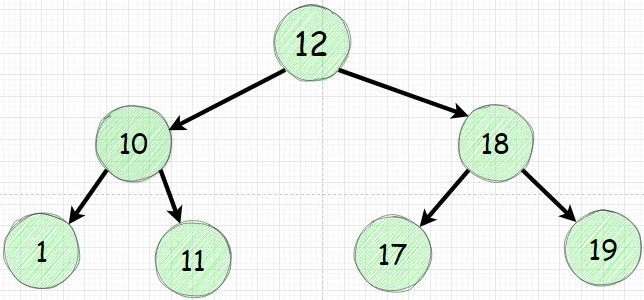
В примерах ниже если вы возьмете любой узел и проверите значения его левого подграфа то все эти значения будут меньше чем сам узел. Аналогично справа все значения будут больше:
Теперь обратим внимание на деревья нарушающие требуемую логику:
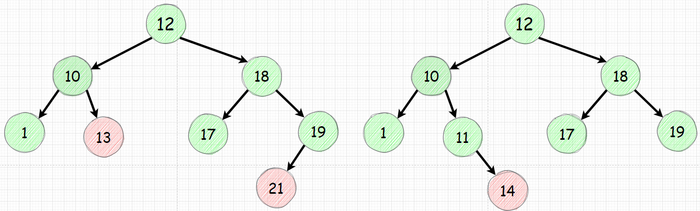
В дереве слева есть следующие недостатки:
Значение 13 хоть и больше 10 но должно быть меньше 12
Значение 21 хоть больше 12 но должно быть меньше 19
В дереве справа
14 больше 11 но должно быть меньше 12
Из требований складывается впечатление что мы должны:
Обойти все узлы и применить к ним единообразную логику (те написать функцию которая вызывает саму себя)
Проверить что левый наследник меньше текущего значения узла
Проверить что правый наследник больше текущего значения узла
Напишем решение для данного невалидного дерева:
И так код:

к сожалению это решение - лишь частично верное.
Чтобы код был более читаем я изобразил это графически:
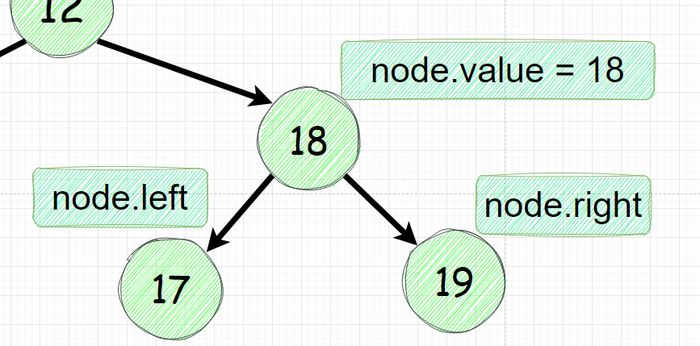
node - это текущий узел где мы "находимся"
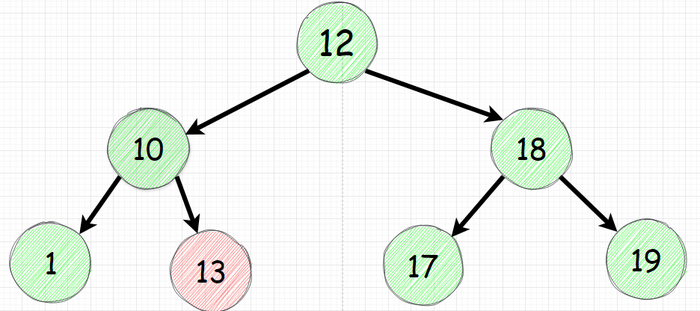
node.value это текущее значение узла, на картинке ниже значение текущего узла 18
node.left это ссылка на левого наследника.
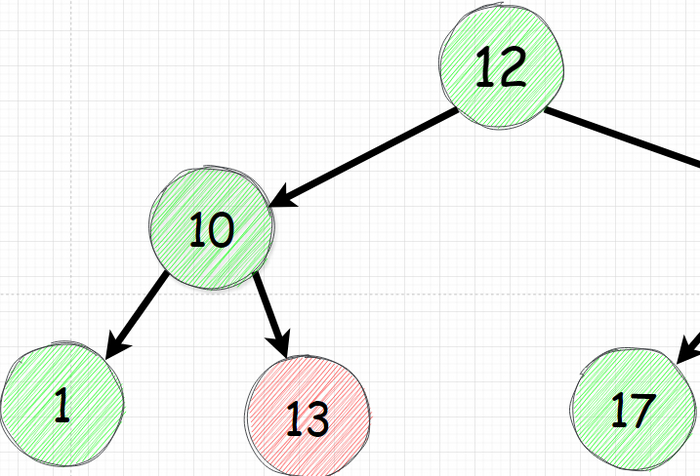
Данная рекурсия берет в учет лишь 3 переменных - значение текущего, левого и правого узлов. Поэтому ниже будет считаться правильным хотя узел 13 слева хоть и больше своего предка (10) но никак не учитывает что он должен быть меньше 12.
Первая попытка никак не учитывает значения дальних предков (те узлов выше родительского). Поэтому наша рекурсия должна будет передавать какую то информацию "сверху". Но какую информацию?
Проанализируем какие есть ограничения на значения узлов:
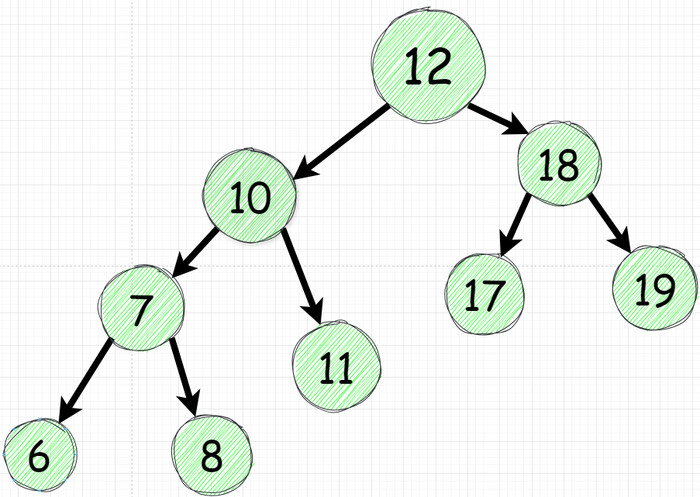
Узел 12 может быть любым числом на него не ограничений, разве что если мы полагаем что каждый узел является целочисленным (integer) типом то он ограничен между Integer.MIN и Integer.MAX
Узел 10 (слева) должен быть меньше 12 но также он может быть больше чем Intger.MIN
Узел 11 - имеет все ограничения примение к 10 И он имеет новое ограничение - он должен быть больше 10.
Узел 7 имеет ограничения которые есть у узла 10 плюс и также он должен быть меньше 10.
Узел 6 имеет ограничения которые есть у узла 7 плюс он должен быть меньше 7
Визуализируя описанно мы получаем вот такую штуку:
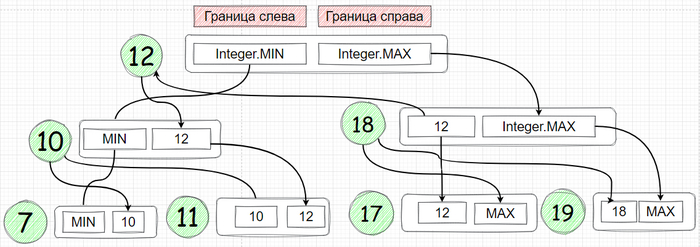
под MIN, MAX подразумевается Integer.MIN, Integer.MAX - сделано чтобы уместить широкую картинку
Рекурсия должна учитывать как минимум 2 значения приходящие "сверху" те левую и правую границы
Передаваемая влево минимальное значение является минимальным пришедшим сверху
Передаваемое влево максимальное значение является максимальным пришедшим сверху
Передаваемое влево максимальное - текущее
Передаваемое вправо минимальное - текущее
Давайте перепишем наш код согласно этой логике:

Код мог бы быть меньше но я написал его именно так с целью упрощения чтения и понимания.
A - мы проверяем условие что значение каждого узла лежит в рамках передаваемых min/max значений
B - минимальное значение передаваемое левому наследнику копируется "сверх"
C - минимальное значиение передаваемое правому - текущее значение
D - максимальное значение передаваемое левому - текущее
F - максимлаьное передаваемое правому копируется "сверху"
Задача успешно решается рекурсией
Задача явно не так очевидна и первое решение скорее всего займет больше 30 минут и поэтому не подходит для собеседований (хотя это моё личное мнение)
Это не единственный подход к решению этой задачи но сейчас мы практикуем именно простые рекурсии. Подобную задачу вы скорее всего встретите при собеседованиях в FAANG или подобные большие компании. Такое решение скорее всего будет зачтено интервьювером.
Всем кому интересно узнать про промышленную разработку приглашаю в мой котоджавовский телеграм канал.
Эта часть является продолжением цикла лекций про деревья. В этой части мы снова воспользуемся рекурсией чтобы инвертировать дерево. Задача довольно популярна и по сложности является довольно простой.
Допустим у нас есть дерево ниже:
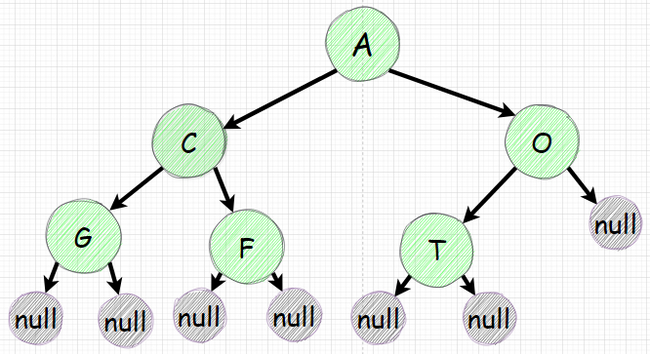
Целью является инвертировать дерево. Те для каждого узла нужно поменять местами его левый и правый наследники. Логику надо также применять к наследникам наследников.
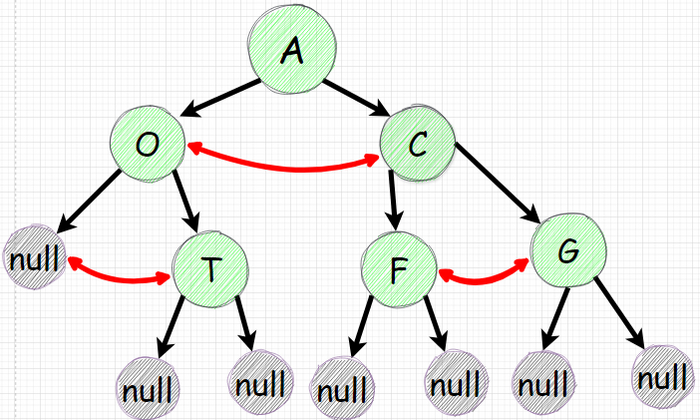
Проитерироватсья по всем узлам рекурсией те нам понадобится функция которая будет вызывать саму себя.
Нижние пустые null узлы нужно будет проигнорировать
Для всех остальных узлов нужно выполнить смену ссылок для правого и левого наследников

Думаю вам тоже задача показалось довольно простой но при этом она является одной из самых частых во время собеседований. В следующей статье мы рассмотрим более сложные случаи. Всем кому интересно - добро пожаловать в мою группу.
В прошлой части мы рассмотрели разные подходы рекурсивного обхода дерева. Давайте воспользуемся некоторыми из них для решения довольно известных задач.
Одна из самых популярных и простых задач на деревья - поиск узла находящегося на максимально удаленом расстоянии. Рассмотрим дерево ниже:
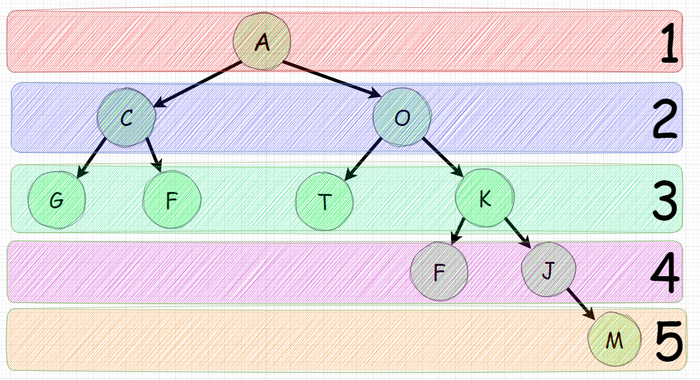
Высота данного дерева - пять
Довольно очевидно что самый длинный узел в данном дереве - M и он является пятым по счету если головной является первым.
Если сильно упрощать то нам нужно сделать 2 действия:
Обойти все узлы
Каким то образом "сохранять" состояния каждый раз когда мы обходим узлы
Но как же сохранять состояния о той глубине на которой мы побывали? Тут есть как минимум два варианта:
Использовать возвращемое значение самой рекурсивной функции и "возвращать" её на уровень выше.
Иметь какой то объект в котором мы будем сохранять состояния находясь внутри рекурсии
Рекурсивная функция должна передавать значение сама себе "наверх"
Определить какое именно значение должно перебрасываться.
Логика передаваемого "наверх" значения.
Самые нижние уровни (те что указывают на null) должны возвращать 0 тк они не включены в расчет глубины данного подграфа
Нижний уровень который с листьями имеет лишь null предков должен вернуть 1 тк он является первым уровнем
Узел выше чем 1й (те не лист) должен выбирать максимальный уровень из двух его наследников и добавлять 1 тк находится на уровень выше из наибольшего из них.
После данных рассуждений у нас вырисовывается вот такая картина:
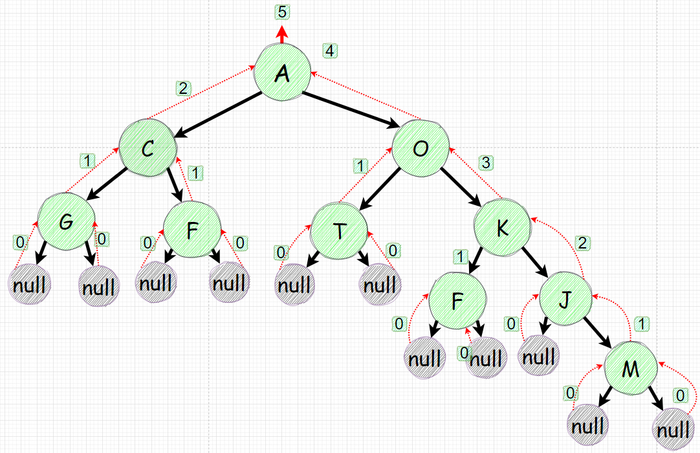
null уровни 0, листья 1 и все остальные узлы - выбирает наибольшее из наследников и добавляют 1.
Все эти рассуждения намекают что в нашей итеративной функциии будет 3 разных сценария и функция которая выбирает наибольшее из двух. Именно подобные размышления чаще всего помогают перевести абстрактные размышления в код.

Версия рабочая но слишком многословная - хотя для собеседования вполне подойдет.
Самый важная часть кода - итеративный вызов левого и правого поддерева и последующий расчет максимального значения среди них. И конечно же добавление 1 наибольшему из них чтобы учесть и текущую высоту.
Этот код можно было бы улучшить удалив случай когда мы находимся в самом низу - дело в том что если условие истино то возвращаемое значение maxDepth + 1 будет также равно 1.
Спасибо за внимание, всем кому интересна промышленная разработка приглашаю в мой канал.


