А вы делаете "бук апы"?!
Показать полностью
1

31 января 2017 года произошло важное для мира OpenSource событие: один из админов GitLab.com, пытаясь починить репликацию, перепутал консоли и удалил основную базу PostgreSQL, в результате чего было потеряно большое количество пользовательских данных, и сам сервис ушел в офф-лайн. При этом все 5 различных способов бэкапа/репликации оказались нерабочими. Восстановились же с LVM-снимка, случайно сделанного за 6 часов до удаления базы.
Понесенные потери
Потеряны данные за примерно 6 часов.
Потеряно 4613 обычных проектов, 74 форка и 350 импортов (грубо); всего 5037. Поскольку Git-репозитории НЕ потеряны, мы сможем воссоздать те проекты, пользователи/группы которых существовали до потери данных, но мы не сможем восстановить задачи (issues) этих проектов.
Потеряно около 4979 (можно сказать, около 5000) комментариев.
Потенциально потеряно 707 пользователей (сложно сказать точнее по логам Kibana).
Веб-хуки, созданные до 31 января 17:20, восстановлены, созданные после — потеряны.
Хронология (время указано в UTC)
2017/01/31 16:00/17:00 — 21:00
- YP работает над настройкой pgpool и репликацией в staging, создает LVM-снимок, чтобы загрузить боевые данные в staging, а также в надежде на то, что сможет использовать эти данные для ускорения загрузки базы на другие реплики. Это происходит примерно за 6 часов до потери данных.
- Настройка репликации оказывается проблематичной и очень долгой (оценочно ~20 часов только на начальную синхронизацию pg_basebackup). LVM-снимок YP использовать не смог. Работа на этом этапе была прервана (так как YP была нужна помощь другого коллеги, который в тот день не работал), а также из-за спама/высокой нагрузки на GitLab.com.
2017/01/31 21:00 — Всплеск нагрузки на сайт из-за спамеров
- Блокирование пользователей по их IP-адресам
- Удаление пользователя за использование репозитория в качестве CDN, в результате чего 47 000 айпишников залогинились под тем же аккаунтом (вызвав высокую нагрузку на БД). Информация была передана командам технической поддержки и инфраструктуры.
- Удаление пользователей за спам (с помощью создания сниппетов)
- Нагрузка на БД вернулась к норме, было запущено несколько ручных вакуумов PostgreSQL, чтобы почистить большое количество оставшихся пустых строк.
2017/01/31 22:00 — Получено предупреждение об отставании репликации
- Попытки починить db2, отставание на этом этапе 4 GB.
- db2.cluster отказывается реплицироваться, каталог /var/opt/gitlab/postgresql/data вычищен, чтобы обеспечить чистую репликацию.
- db2.cluster отказывается подключаться к db1, ругаясь на слишком низкое значение max_wal_senders. Эта настройка используется для ограничения количества клиентов WAL (репликации).
- YP увеличивает max_wal_senders до 32 на db1, перезапускает PostgreSQL.
- PostgreSQL ругается на то, что открыто слишком много семафоров, и не стартует
- YP уменьшает max_connections с 8000 до 2000, PostgreSQL стартует (при том, что он нормально работал с 8000 почти целый год).
- db2.cluster все еще отказывается реплицироваться, но на соединения больше не жалуется, а вместо это просто висит и ничего не делает.
- В этот время YP начинает чувствовать безысходность. Раньше в этот день он сообщил, что собирается заканчивать работу, так как становилось уже поздно (около 23:00 по местному времени), но он остался на месте по причине неожиданно возникших проблем с репликацией.
2017/01/31 около 23:00
- YP думает, что, возможно, pg_basebackup чересчур педантичен по поводу чистоты директории для данных и решает ее удалить. Спустя пару секунд он замечает, что запустил команду на db1.cluster.gitlab.com вместо db2.cluster.gitlab.com.
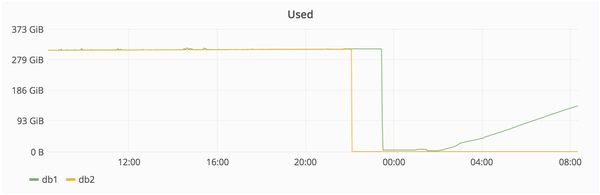
- 2017/01/31 23:27: YP отменяет удаление, но уже слишком поздно. Из примерно 310 Гб осталось только 4.5
Восстановление — 2017/01/31 23:00 (бэкап от ~17:20 UTC)
Предложенные способы восстановления:
1. Смигрировать db1.staging.gitlab.com на GitLab.com (отставание около 6 часов)
- CW: Проблема с веб-хуками, которые были удалены во время синхронизации.
2. Восстановить LVM-снимок (отстает на 6 часов).
3. Sid: попробовать восстановить файлы?
- CW: Невозможно! rm -Rvf Sid: OK.
- JEJ: Наверное, уже слишком поздно, но может ли помочь, если достаточно быстро перевести диск в режим read-only? Также нельзя ли получить дескриптор файла, если он используется работающим процессом (согласно http://unix.stackexchange.com/a/101247/213510).
- YP: PostgreSQL не держит все свои файлы постоянно открытыми, так что это не сработает. Также, похоже, что Azure очень быстро удаляет данные, а вот пересылает их на другие реплики уже не так шустро. Другими словами, данные с самого диска восстановить не получится.
- SH: Похоже, что на db1 staging-сервере отдельный PostgreSQL-процесс льет поток production-данных с db2 в каталог gitlab_replicator. Согласно отставанию репликации, db2 был погашен в 2016-01-31 05:53, что привело к остановке gitlab_replicator. Хорошие новости заключаются в том, что данные вплоть до этого момента выглядят нетронутыми, поэтому мы, возможно, сможем восстановить веб-хуки.
Предпринятые действия:
2017/02/01 23:00 — 00:00: Принято решение восстанавливать данные с db1.staging.gitlab.com на db1.cluster.gitlab.com (production). Несмотря на то, что они отстают на 6 часов и не содержат веб-хуков, это единственный доступный снимок. YP говорит, что ему сегодня лучше больше не запускать никаких команд, начинающихся с sudo, и передает управление JN.
2017/02/01 00:36 — JN: Делаю бэкап данных db1.staging.gitlab.com.
2017/02/01 00:55 — JN: Монтирую db1.staging.gitlab.com на db1.cluster.gitlab.com.
Копирую данные со staging /var/opt/gitlab/postgresql/data/ в production /var/opt/gitlab/postgresql/data/.
2017/02/01 01:05 — JN: nfs-share01 сервер выделен в качестве временного хранилища в /var/opt/gitlab/db-meltdown.
2017/02/01 01:18 — JN: Копирую оставшиеся production-данные, включая запакованный pg_xlog: ‘20170131-db-meltodwn-backup.tar.gz’.
2017/02/01 01:58 — JN: Начинаю синхронизацию из stage в production.
2017/02/01 02:00 — CW: Для объяснения ситуации обновлена страничка развертывания (deploy page). Link.
2017/02/01 03:00 — AR: rsync выполнился примерно на 50% (по количеству файлов).
2017/02/01 04:00 — JN: rsync выполнился примерно на 56.4% (по количеству файлов). Передача данных идет медленно по следующим причинам: пропускная способность сети между us-east и us-east-2, а также ограничение производительности диска на staging-сервере (60 Mb/s).
2017/02/01 07:00 — JN: Нашел копию нетронутых данных на db1 staging в /var/opt/gitlab_replicator/postgresql. Запустил виртуальную машину db-crutch VM на us-east, чтобы сделать бэкап этих данных на другую машину. К сожалению, она ограничена 120 GB RAM и не потянет рабочую нагрузку. Эта копия будет использована для проверки состояния базы данных и выгрузки данных веб-хуков.
2017/02/01 08:07 — JN: Передача данных идет медленно: по объему данных передано 42%.
2017/02/02 16:28 — JN: Передача данных закончилась.
Процедура восстановления
[x] — Сделать снимок сервер DB1 — или 2 или 3 — сделано в 16:36 UTC.
[x] — Обновить db1.cluster.gitlab.com до PostgreSQL 9.6.1, на нем по-прежнему 9.6.0, а staging использует 9.6.1 (в противном случае PostgreSQL может не запуститься).
Установить 8.16.3-EE.1.
Переместить chef-noop в chef-client (было отключено вручную).
Запустить chef-client на хосте (сделано в 16:45).
[x] — Запустить DB — 16:53 UTC
Мониторить запуск и убедиться, что все прошло нормально.
Сделать бэкап.
[x] — Обновить Sentry DSN, чтобы ошибки не попали в staging.
[x] — Увеличить идентификаторы во всех таблицах на 10k, чтобы избежать проблем при создании новых проектов/замечаний. Выполнено с помощью https://gist.github.com/anonymous/23e3c0d41e2beac018c4099d45..., который читает текстовый файл, содержащий все последовательности (по одной на строку).
[x] — Очистить кеш Rails/Redis.
[x] — Попытаться по возможности восстановить веб-хуки
[x] Запустить staging, используя снимок, сделанный до удаления веб-хуков.
[x] Убедиться, что веб-хуки на месте.
[x] Создать SQL-дамп (только данные) таблицы “web_hooks” (если там есть данные).
[x] Скопировать SQL-дамп на production-сервер.
[x] Импортировать SQL-дамп в рабочую базу.
[x] — Проверить через Rails Console, могут ли подключаться рабочие процессы (workers).
[x] — Постепенно запустить рабочие процессы.
[x] — Отключить страницу развертывания.
[x] — Затвитить с @gitlabstatus.
Возникшие проблемы
1. LVM-снимки по умолчанию делаются лишь один раз в 24 часа. По счастливой случайности YP за 6 часов до сбоя сделал один вручную.
2. Регулярные бэкапы, похоже, также делались только раз в сутки, хотя YP еще не выяснил, где они хранятся. Согласно JN они не работают: создаются файлы размером в несколько байт.
SH: Похоже, что pg_dump работает неправильно, поскольку выполняются бинарники от PostgreSQL 9.2 вместо 9.6. Это происходит из-за того, что omnibus использует только Pg 9.6, если data/PG_VERSION установлено в 9.6, но на рабочих узлах этого файла нет. В результате по умолчанию запускается 9.2 и тихо завершается, ничего не сделав. В итоге SQL-дампы не создаются. Fog-гем, возможно, вычистил старые бэкапы.
3. Снимки дисков в Azure включены для NFS-сервера, для серверов баз данных — нет.
4. Процесс синхронизации удаляет веб-хуки после того, как он синхронизировал данные на staging. Если мы не сможем вытащить их из обычного бэкапа, сделанного в течение 24 часов, они будут потеряны.
5. Процедура репликации оказалось очень хрупкой, склонной к ошибкам, зависящей от случайных shell-скриптов и плохо документированной.
SH: Мы позже выяснили, что обновление базы данных staging работает путем создания снимка директории gitlab_replicator, удаления конфигурации репликации и запуска отдельного PostgreSQL-сервера.
6. Наши S3-бэкапы также не работают: папка пуста.
7. У нас нет надежной системы оповещений о неудачных попытках создания бэкапов, мы теперь видим такие же проблемы и на dev-хосте.
Другими словами, из 5 используемых способов бэкапа/репликации ни один не работает. => сейчас мы восстанавливаем рабочий бэкап, сделанный 6 часов назад.
Заключение
Что показательно, ребята из GitLab сумели превратить свою грубейшую ошибку в поучительную историю, и, думаю, не только не потерять, но и завоевать уважение многих айтишников. Также за счет открытости, написав о проблеме в Twitter и выложив лог в Google Docs, они очень быстро получили квалифицированную помощь со стороны, причем, похоже, совершенно безвозмездно.
Как всегда, радуют люди с хорошим чувством юмора: главный виновник инцидента теперь называет себя "Database (removal) specialist" (Специалист по [удалению] баз данных), какие-то шутники предложили 1 февраля сделать днем проверки бэкапов http://checkyourbackups.work/
Оригинал https://docs.google.com/document/d/1GCK53YDcBWQveod9kfzW-VCx...
https://github.com/sukria/Backup-Manager
Написан на bash и perl, может работать с архивами форматов tar, tar.gz, tar.bz2 и zip. Есть режим параллельного запуска нескольких копий программы с различающимися настройками.
Поддерживается создание дампов MySQL, Subversion и инкрементное резервное копирование.
Резервные копии могут храниться в течение заданного количества дней, а по протоколам FTP, SSH или Rsync возможна их выгрузка на удалённые хосты, также поддерживается выгрузка на Amazon S3 и запись резервных копий на устройства CD/DVD.
Возможно шифрование архивов.
Заканчиваю перевод материала: Backup Manager 0.7.7 User Guide © Alexis Sukrieh, ver. 1.7 - 14 Apr, 2008 который стал основой для написания раздела Настройка статьи о Backup Manager.

Мне одному показалось в конце фильма когда маги восстанавливали город после разрушений, что их колдовство построено на "git checkout -- <file>"
Это первая статья о моём «путешествии» к становлению системным администратором.
Закончив ВУЗ, я стал искать работу. Горел желанием работать сисадмином, хотя сам даже не помню, откуда появилась эта идея. Наконец, меня взяли младшим системным администратором в небольшую компанию на 60 человек.
У компании несколько офисов в моём городе, ещё 3-4 в других городах. 4 сервера в основном офисе, около 40 ноутбуков и ПК по точкам, роутеры, сетевые коммутаторы (далее – свитчи), камеры видеонаблюдения и прочее.
Сразу отмечу, в моих статьях будут вещи, о которых я узнавал в процессе работы. Да, я понимаю, что некоторые из них элементарны, но как бы то ни было, узнавал я о них впервые. И пишу я для таких же начинающих эникейщиков как я сам, поэтому всех профи и матёрых сисадминов попрошу воздержаться от бомбления.
Огромное спасибо авторам статей https://habrahabr.ru/post/118475/ и https://habrahabr.ru/post/50008/ - очень помогли понять, кем я сейчас работаю и что нужно делать для развития.
Если коротко: эникейщики, помощники сисадминов и младшие системные администраторы – люди без опыта, но с базовыми знаниями о компьютерной технике, семействе Windows и его приложений вроде MicrosoftOffice. Это минимум. Чем больше знаний, тем больше шансов попасть в более крупное предприятие. Повезло и тебя приняли? Теперь учись, пробуй, а главное – читай. Читать надо вообще всё, начиная от всё той же операционной системы Windows (Администрирование Windows), компьютерных сетях (OSI, IP/TCP, DCHP, как происходят первые и последующие соединения в сетях и т.д.), заканчивая семейством Linux и поднятием ActiveDirectory на работающем сервере.
Итак, мои первые две недели.
От гендиректора поступило задание провести инвентаризацию всей компьютерной техники. От меня требовалось:
1. Собрать информацию с работников: кто (основная информация о работнике), где работает, чем пользуется (из оборудования), какие программы использует;
2. Нарисовать схему подсетей в организации;
3. Раздать инвентаризационные номера каждому устройству.
Для начала я создал табличку, где указал, что именно мне нужно от сотрудника и отправил по почте каждому сотруднику (список взял в бухгалтерии). В последующем выяснилось, что почтой владеют не все сотрудники, а некоторые из них слишком важные персоны, чтобы перевернуть мышку и посмотреть название. Поэтому мне всё равно пришлось пройти по этажам, затем проехаться по другим офисам и записать устройства самостоятельно. Собранную информацию я заносил в табличку в Word, систематизировал, запоминал.
Далее – схема.
Я долго перебирал варианты, как бы эту схему лучше составить. В итоге, остановился на программе LanStatePro. Она показалась мне довольно красивой и простой, тем более что от меня и не требовалось ничего особенного.
Для примера картинка из интернета.
Теперь остались инвентаризационные номера.
Открыл Хабр, почитал статьи об этом. Взяв за основу статью https://habrahabr.ru/post/205802/, открыл мою схему сети, пронумеровал произвольным способом офисы в разных городах, затем в моём городе. Следующая цифра – этаж. Получилось примерно MSK1-1. Москва, 1 офис, 1 этаж. Далее составил таблицу всех устройств и дал им номера. Например, системный блок 01, мышь 02, клавиатура 03, монитор 04 и т.д. Захожу в комнату N и слева направо раздаю номера. Ноутбук MSK1-1-05-1, второй ноутбук MSK1-1-05-2, мышь MSK1-1-02-1 и далее по списку. Цифр в инвентарном номере мало – но ведь это информация для меня и сисадмина, верно?
По номеру я пойму, в каком здании, комнате, на каком рабочем столе лежит эта мышь и кому она принадлежит. Распечатав материал, я потратил день на нанесение номеров на каждое устройство в своём городе. Остальным офисам отправил по электронной почте просьбу наклеить и сфотографировать.
Осталось всё оформить и отнести гендиректору.
Время от времени поступали задания от системного администратора. У кого-то не работает принтер – переустановил драйвера. Появился новый сотрудник – готовил для него ноутбук. И вот тут, пожалуй, остановлюсь.
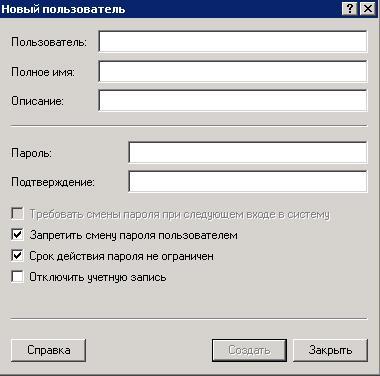
В подготовку входило: переустановка Windows, настройка MicrosoftOffice, Skype. Всё это происходило с двух флешек сисадмина. Передавая их мне, он тут же добавил – тебе нужно завести свои флешки по 8-16 Гб, на одной будет ОС Windows, на другой - полезные программы. Всё поставил. Далее создание почты, скайпа, доступа к RDP(удалённый рабочий стол). Под логином сисадмина мы заходим в RDP, ПКМ по Компьютеру, Управление – Конфигурация – Локальные пользователи и группы – Пользователи. Снова ПКМ, Новый пользователь и заполняем данные пользователя. Галочки ставим на «Запретить смену пароля пользователю» и «Срок действия пароля неограничен», а снимаем с «Запросить сменить пароль при следующем входе».
Снова ПКМ, Новый пользователь и заполнение данных пользователя. Галочки ставим на «Запретить смену пароля пользователю» и «Срок действия пароля неограничен», а снимаем с «Запросить сменить пароль при следующем входе».
Пользователя мы создали. Теперь необходимо дать ему нужные права и запретить ему заходить туда, куда не нужно.
Ищем пользователя в списке, ПКМ, Свойства.
- Членство в группах: там могут быть созданы группы вроде «Бухгалтерия», «Программисты 1С», «Водители» и другие, с уже заданными правами. Например, Бухгалтерия имеет доступ к базам, связанным с расходками, распределением средств, зарплатами. А водители могут лишь отметиться в базе управления персоналом.
- Среда: убираем галочку с «Подключение дисков пользователя», а вот «Подключения принтеров пользователя» и «По умолчанию выбрать основной принтер клиента» оставим, многим нужно печатать прямо с 1С, а тот принтер, что установлен у них по умолчанию, с помощью галочки подключится и в RDP.
- Сеансы:
• завершение отключенного сеанса – 5 минут;
• ограничение активного сеанса – никогда;
• ограничение бездействующего сеанса – 30 минут.
• При превышении ограничений или разрыве связи – Отключить сеанс;
• Разрешить переподключение – только от прежнего клиента.
Пользователь закрыл RDP – через 5 минут сервер его завершит. Пользователь работает в RDP– пусть работает, никто его не отключит. Пользователь не двигает мышкой 30 минут или отошёл – сеанс выключится, нечего тратить ресурсы сервера. Пропал интернет – сеанс отключится, есть 5 минут на переподключение. Если кто-то входит в тот же RDPна другом ПК – сеанс первого завершится.
Остальные настройки по вкусу, но по совету сисадмина я трогать ничего не стал.
Далее создание почты. Так как почтовый сервер у нас свой, почта создается через него. Создание ящика дело нехитрое, поэтому останавливаться тут я не буду. Так же пропустим то, как я создавал учётную запись в скайпе.
Итак, логины/пароли готовы, ноутбук тоже. Устанавливаем его на рабочем месте, настраиваем Wi-Fi. Принтер настраивается через «Устройства и принтеры», создание нового, после поиска выбираем нужный и в большинстве случаев это всё. Теперь – общая папка.
Заходим: Панель управления – Учётные данные пользователей – Администрирование учётных записей Windows - Добавить учётные данные. Вбиваем данные пользователя, адрес сервера. Обычно в компаниях используют VPN- виртуальную частную сеть. Совсем просто – это создание «локальной» сети. Даже если офис Nв другом городе, через интернет создаётся туннель к серверу, и теперь офис N почётный член локальной сети, а значит, он имеет доступ к общей папке в локальной сети. Теперь заходим через сисадмина в RDP, выбираем папку для общего доступа, если она не настроена, или создаём ещё одну. В свойствах папки, в разделе Доступ добавляем новых пользователей и раздаём им права: «Чтение и запись», либо только «Чтение».
The End.
Компьютер готов к использованию.
В следующей статье: новое задание от сисадмина – написать bat-файл для бекапа с условиями, а так же, как я лишил доступа к RDPвсех, включая сисадмина.
Посмотрел на выходных "Фантастических тварей", в конце фильма идут волшебники и восстанавливают разрушенный город, а в голове одна мысль - хорошо что бекап города был.
Одна вакансия, два кандидата. Сможете выбрать лучшего? И так пять раз.