Ретро анекдот из будущего
- Папа, а что такое «офлайн»?
- Не знаю, сынок, спроси у Алисы!
- Папа, а что такое «офлайн»?
- Не знаю, сынок, спроси у Алисы!
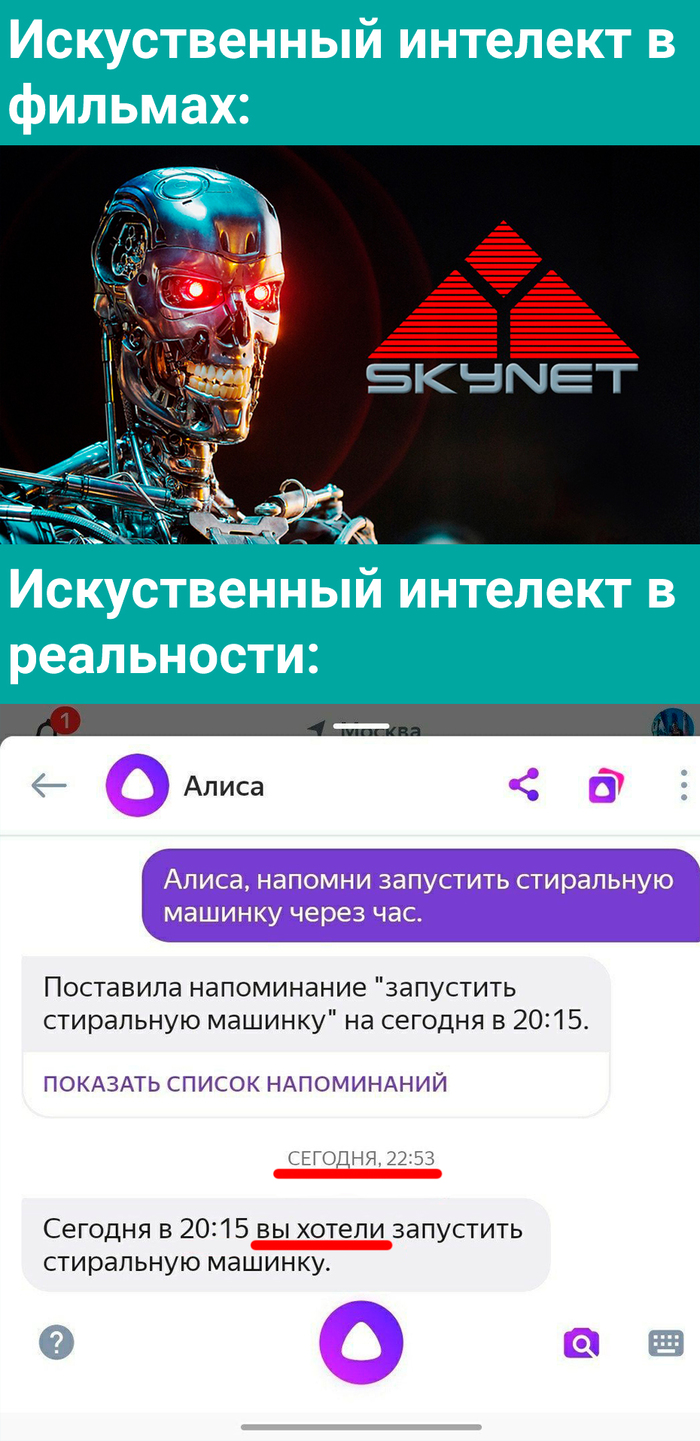
Идея отказаться от использования Яндекс Алисы в системе умного дома возникла у меня после новости о принятии Госдумой законопроекта, касающегося штрафов за поиск и доступ к экстремистским материалам в интернете. Казалось бы, при чём тут голосовой помощник? Однако Яндекс входит в реестр организаторов распространения информации, что означает определённые юридические и технические обязательства по хранению и передаче данных.
Хотя я не ищу ничего, выходящего за рамки интересов приколов на Пикабу, желание иметь полностью автономный, локально работающий умный дом - без зависимости от интернета и облачных сервисов - стало для меня ещё актуальнее.
Тем более что сейчас единственным слабым звеном в моём умном доме остается Яндекс Алиса - которая требует постоянного интернет-соединения даже для выполнения простейших команд управления локальными устройствами.
В этой статье я расскажу, как и на что планирую заменить Алису, чтобы сохранить привычный голосовой контроль, но без сторонних подключений и рисков для приватности.
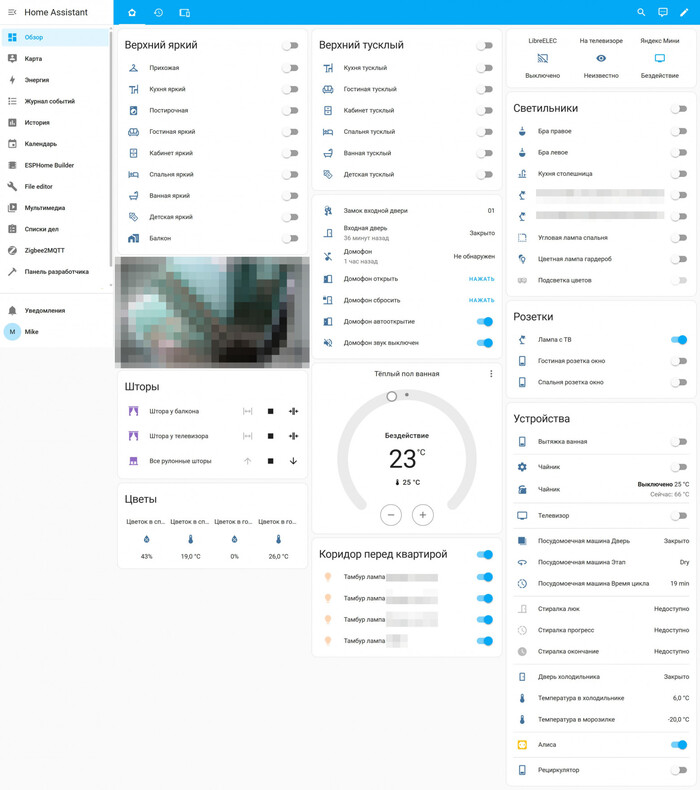
Мой Home Assistant в "человеко читаемом" виде
Мой умный дом строился с прицелом на автономность, надежность и открытые стандарты - так, чтобы управление работало даже при полном отсутствии интернета. На данный момент архитектура системы выглядит следующим образом.
Мозг системы: центральный контроллер - это Raspberry Pi 4 Model B с 2 ГБ оперативной памяти, установлен в 2022 году. На него установлена Home Assistant OS - полноценная операционная система, заточенная под локальное управление умным домом - подробнее описывал в другой статье. Вся логика автоматизаций, интерфейс управления и интеграции работают исключительно локально, без необходимости в сторонних облаках.
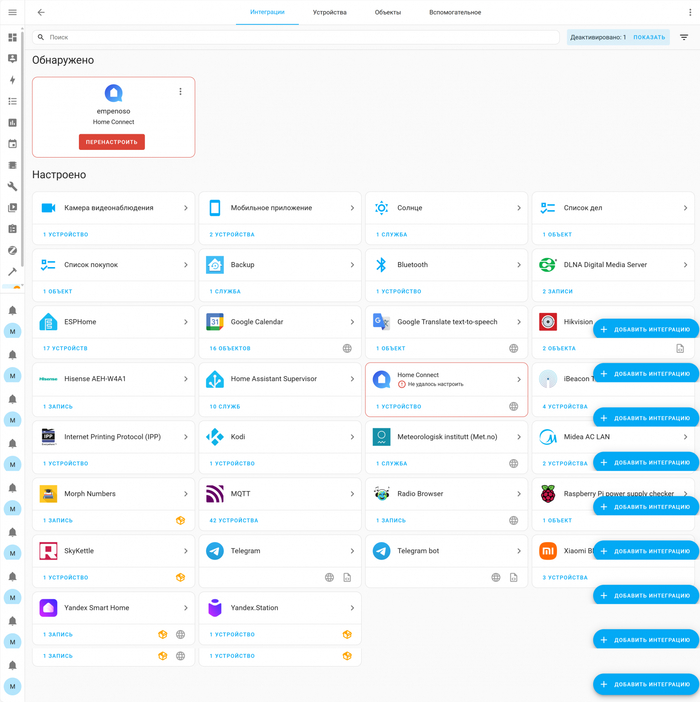
Извиняюсь за скриншот, но с прокруткой только PicPick под Windows умеет делать - и вот результат :(
Протоколы связи: большая часть устройств использует Wi-Fi через прошивку ESPHome - это 17 модулей: от простых температурных датчиков до управляющих реле в светильниках.
Ключевую нагрузку по управлению берет на себя Zigbee-сеть: 42 устройства, объединённые с помощью USB-донгла Sonoff Zigbee 3.0 Plus и интеграции Zigbee2MQTT. Это датчики, реле освещения и другие элементы.
Что управляется:
Освещение: в каждой комнате - два контура: тусклый (вечерний) и яркий, плюс светодиодная лента в спальне, освещение общего коридора с двумя режимами.
Климат: кондиционеры, обогрев ванной комнаты через реле теплого пола.
Электропитание и бытовая техника: управляемая розетка для ТВ, стиралка, холодильник, посудомойка, чайник.
Датчики: движения, открытия, температуры и влажности.
Шторы: моторизованные рулонные и классические.
Мультимедиа: управление Kodi на медиаплеере и доступ к медиатеке NAS Synology, панель управления умным домом.
Безопасность: камера видеонаблюдения из подъездного домофона, IP-камера у лифтов, управление домофоном в многоквартирном доме - автовахтер по моим правилам.
Все эти устройства уже управляются локально, без облачных зависимостей - кроме стиралки Bosch, купленной ещё в 2022 году.
Однако чтобы убрать колонку Яндекса и заменить Алису на полностью автономного голосового помощника, нужно понять, из каких компонентов он состоит. Это не “одна программа”, а целая цепочка взаимодействующих модулей, каждый из которых выполняет свою задачу:

ESP32-S3-BOX-3. Фото из интернета
Микрофон и динамик («Уши и рот» системы) - это устройства, которые слышат пользователя. Не должно быть колхоза из датчиков. Устройство должно выглядеть современно и не портить интерьер.
В моем случае я присматриваюсь к двум: компактный M5Stack ATOM Echo для комнат и более продвинутый ESP32-S3-BOX для гостиной.

Официальный комплект для разработки умных динамиков ATOM Echo M5Stack
Они захватывают звук и отправляют его на сервер для дальнейшей обработки.
100% новый ESP32-S3-BOX-3 ESP32-S3-BOX-3B модуль комплекта разработки приложений AIOT 2,4 ГГц Wi-Fi + Bluetooth 5
Wake Word движок: нужен, чтобы система слушала нас постоянно, но реагировала только по ключевой фразе (например, «Привет, пирожок!»). Используем OpenWakeWord - полностью локальный и настраиваемый.
Speech-to-Text (STT): этот модуль превращает речь в текст. Здесь смотрю на Whisper от OpenAI - пишут что это один из самых точных и устойчивых к шуму движков, работающий прямо на локальном сервере. Про его выбор чуть ниже.
Распознавание намерений (Intent Recognition): после получения текста нужно понять смысл команды. Эта задача ложится на встроенный в Home Assistant механизм Assist, который сопоставляет текст с действиями и сущностями в системе.
Text-to-Speech (TTS): чтобы система могла отвечать голосом, нужен синтез речи. Я планирую использовать Piper - современный, быстрый, качественный, легко интегрируется как Add-on в HA. Как вариант RHVoice - тоже отличный вариант, но Piper сейчас является де-факто стандартом в сообществе HA за простоту и качество.
Wyoming Protocol: связующее звено. Простой, но мощный протокол, через который все эти модули общаются между собой и с Home Assistant.
Давайте будем честны: моя Raspberry Pi 4 с 2 ГБ памяти - отличный мозг для автоматизации, но для тяжелых вычислений, таких как распознавание речи в реальном времени, её мощности не хватит.
Поэтому, помимо «ушей» в виде ESP32-S3-BOX и M5Stack ATOM Echo, в систему придется докупить отдельный мини-ПК. Это может быть недорогой китайский NUC-подобный компьютер, который возьмет на себя самую ресурсоемкую задачу - преобразование речи в текст (Speech-to-Text (STT)).

Или может быть Raspberry Pi 5 c 16 ГБ оперативной памяти - цены сопоставимы.
Самый главный вопрос - что на нем будет крутиться? Выбор STT-движка определяет, насколько умным и гибким будет наш ассистент.
Speech-to-Phrase (от Open Home Foundation): это самый легковесный вариант. Он не распознает речь, а просто ищет точное совпадение с заранее заданными фразами.
К тому же это не конкретный движок, а концепция pipeline в HA. По умолчанию он использует тот же Whisper, но его самую легкую модель, чтобы хоть как-то работать на слабых устройствах вроде RPi. Плюс: минимальные требования к железу. Минус: абсолютная негибкость. Система поймет «включи свет на кухне», но проигнорирует «сделай на кухне посветлее». Это не интеллект, а поиск по словарю.
Rhasspy: ветеран мира локальных ассистентов. Мощный, но сложный в настройке комбайн. Главный аргумент против него сегодня: проект развивается медленнее, чем экосистема Home Assistant. Пока Rhasspy остается монолитной системой, связка Assist + Wyoming-протокол ушла далеко вперед в плане гибкости и интеграции.
Whisper от OpenAI - современный стандарт транскрипции. Понимает естественную речь в свободной форме, работает с русским языком. Различные модели (tiny, base, small, medium) позволяют балансировать между скоростью и качеством. Активно развивается, поддерживается сообществом HA, появляются оптимизированные версии вроде distil-whisper. Это выбор на перспективу.
Поскольку я нахожусь в активном поиске оптимального решения и уже закупаюсь компонентами, то буду признателен за ваши комментарии, критику и предложения.
Лично для себя я не рассматриваю этот вариант, однако этот путь подойдёт тем, кто хочет попробовать локальное голосовое управление с минимальными затратами времени и денег. Как раз, чтобы "пощупать" концепцию и понять, насколько она жизнеспособна.

M5Stack ATOM Echo. Микроразмер. Фото из интернета
Или если вы только планируете сделать умный дом - можно изначально заложить более мощное железо - чтобы всё было на одном севере.
Все компоненты - Home Assistant, распознавание речи (STT) и синтез голоса (TTS) - работают прямо на Raspberry Pi. Один микрофон, одна точка входа, минимум зависимости.
То есть:
[M5Stack ATOM Echo] ← Wi-Fi → [Raspberry Pi 4 (HA + STT + TTS)]
Если брать мой случай:
Уже есть: Raspberry Pi 4 (2 ГБ) с установленной Home Assistant OS.
Нужно купить: M5Stack ATOM Echo (примерно 1 400 рублей). Это крошечное устройство с микрофоном, динамиком и Wi-Fi - почти готовый китайский мини-клон Алисы.
Настройка:
Прошивка ATOM Echo: через ESPHome. Готовый YAML-конфиг для голосового ассистента легко найти в официальных примерах.
Pipeline в HA:
STT: Используем Assist pipeline от Open Home Foundation с движком faster-whisper и моделью tiny. Запустится скорее всего даже на Pi 4.
TTS: Устанавливаем Add-on Piper - быстрый и качественный синтезатор, особенно с голосами на русском.
Плюсы этого решения:
Минимальные вложения - только 1 400 рублей и немного времени.
Простота - всё работает на одном устройстве.
Быстрый старт - можно реализовать за один вечер.
Минусы:
Скорее всего заметная задержка из-за слабого железа.
Нагрузка на Home Assistant - может тормозить работу системы во время STT.
Плохо масштабируется: один микрофон - ещё приёмлимо, но два и больше будут проблемой.
Это мой приоритетный путь - вынести ресурсоёмкие задачи обработки речи на отдельный сервер, а Raspberry Pi остаётся заниматься только управлением умным домом. Подход масштабируемый, стабильный и в моём случае надеюсь что будет в разы быстрее.

ESP32-S3-BOX. Фото из интернета
Схема сложнее:
[Пользователь]
↓ говорит
[ESP32-S3-BOX / M5Stack ATOM Echo] ← микрофон + wake word ("Привет, пирожок!")
↓ захватывает аудио
(по Wi-Fi)
↓
[Мини-ПК: Whisper STT-сервер]
↓ распознаёт речь в текст (Whisper STT)
↓
[Home Assistant на Raspberry Pi 4]
↓ определяет намерение (Assist)
↓ выполняет команду
↓ (опционально)
[Мини-ПК: Piper TTS]
↓ синтезирует голосовой ответ
(по Wi-Fi)
↓
[ESP32-S3-BOX / M5Stack ATOM Echo] ← динамик
↓ озвучивает ответ
[Пользователь]
Железо:
Уже есть Raspberry Pi 4 (2 ГБ) - Home Assistant, Zigbee, автоматизации.
Примерно 14 т.р.: Mini PC (Intel N100 или N95) - сервер обработки голоса.
Примерно 6 т.р. ESP32-S3-BOX - «умный» ассистент для гостиной.
Примерно 1,4 т.р. M5Stack ATOM Echo - недорогие ассистенты для других комнат.
Сервер обработки голоса (Mini PC):
Устанавливаем легкий Linux (Debian/Ubuntu Server), затем - Docker и Docker Compose. В docker-compose.yml разворачиваем сразу три контейнера:
Whisper - для распознавания речи (STT).
Piper - синтез речи (TTS).
OpenWakeWord - «ключевая фраза» для активации.
С мощностями N100 можно использовать модель Whisper уровня small или даже medium, получая более точное и быстрое распознавание речи, чем на Pi.
Настройка Home Assistant: на Raspberry Pi в этом случае не используется голосовых add-on'ов - только интеграция через Wyoming:
Заходим в Настройки → Устройства и службы → Добавить интеграцию.
Добавляем Wyoming Protocol трижды — для каждого из сервисов (Whisper, Piper, WakeWord), указав IP и порты Mini PC.
Создаём Voice Pipeline, выбираем нужные сервисы из выпадающих списков.
Спутники (ESP32-S3-BOX и ATOM Echo): прошиваются через ESPHome. У ESP32-S3-BOX можно задействовать экран: отображать статус («Слушаю», «Думаю», «Выполняю»), добавляя интерактивности.
Плюсы:
Ожидаемая быстрая реакция.
Ожидание распознавания сложных фраз.
Не грузит Home Assistant.
Масштабируемость: добавляем спутники - и всё.
Минусы:
Дороже (нужен Mini PC).
Потребуются базовые навыки Linux и Docker.
Можно полностью избавиться от Raspberry Pi 4 с 2 ГБ памяти и абсолютно всё перевести на новый мощный сервер. RAM видимо выбрать 16-32 ГБ чтобы с запасом на все. Может быть даже купить NVIDIA VRAM 6 ГБ, но это тогда сильно увеличит стоимость и можно будет забыть о безвентиляторности.

Сборка в mini-ITX. Фото из интернета
Можно тоже будет использовать Home Assistant OS или Linux (Ubuntu/Debian) + Docker.
Правда это большая работа - много устройств. Пока склоняюсь к второму варианту.
Переход на локального голосового ассистента - это не просто технический эксперимент, а осознанный шаг к созданию по-настоящему приватного и независимого умного дома.
Первый вариант - это отличная, почти бесплатная возможность «пощупать» технологию и понять ее ограничения. Второй - полноценное решение, которое по скорости и качеству скорее всего не уступит Алисе, при этом полностью оставаясь под контролем. Третий вариант - если есть бюджет.
Все пути ведут к одной цели - избавлению от «облачного рабства». До сентября ещё есть время. А расставание с Алисой может быть не только экологичным, но и очень увлекательным!
А каким голосовым помощником пользуетесь вы?
Автор: Михаил Шардин
🔗 Моя онлайн-визитка
📢 Telegram «Умный Дом Инвестора»
29 июля 2025 года
Всем привет! Возвращаюсь с новым постом о реальном проекте.
В феврале этого года нам поступила заявка на автоматизацию кинотеатра в частном доме, проект еще в реализации, но хочу поделиться промежуточными результатами :)
Любое обращение начинается с изучения дизайн-проекта (если он есть), этот случай не исключение.
Получив документацию от наших партнеров, дизайн-студии dekaart, мы видим красивые картиночки визуализации:

Зона бара и кальяна

Зона кинотеатра
А так же схему осветительных приборов, электрики
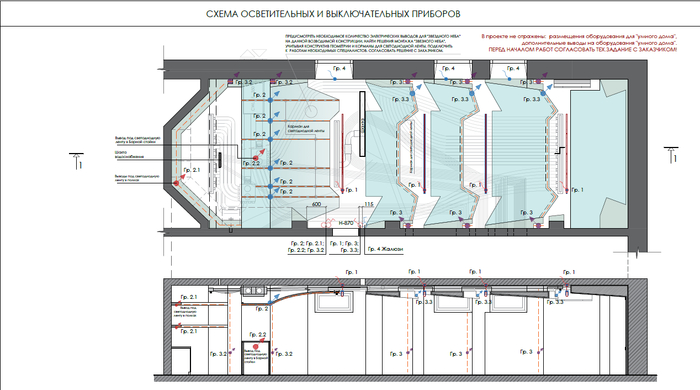
Схема осветительных приборов и их привязки к выключателям
Так же был получен перечень оборудования для автоматизации, а именно:
1) Проектор JVC NZ30BG
2) Ресивер Denon AVR-X2800H
3) Приточно-вытяжная вентиляция VHR BlackVent 500
4) Кондиционер Royal Clima RCI-RSN75HN
5) DMX приборы для режима "Дискотека"
6) Трековые системы Arlight
7) Ооочень много одноцветной светодиодной ленты (65 метров)
8) RGB светодиодная лента для полок в барной зоне
9) Роллеты на окна с приводами
10) Android TV Homatics Box R 4K Plus (Был предложен заказчику нами)
Из требований заказчика:
1) Управление всем освещением, как со смартфона, так и с выключателей
2) Аналогичное управление с планшета
3) Несколько сценариев поведения, таких как "Кино", "Дискотека", "Кальян" и тд
4) Автоматическое управление вент-установкой
5) Автоматическое управление кондиционером
6) Управление всем мультимедиа оборудованием
7) Голосовое управление с "Алисы"
8) Управление в одном треке разными источниками освещения
Прежде чем приступать к проектированию, провели аудит уже закупленного заказчиком оборудования. Нашли несоответсвие ТЗ (конкретно пункт 8) и купленной системы освещения.
У заказчика в шинопроводе размещаются два источника освещения, такие как:

Так называемые SPOT

И встраиваемые "заподлицо" в шинопровод линейные светильники
Управление ими раздельно не было предусмотрено, так как были закуплены модели, не поддерживающие протокол DALI (Если кратко, то это когда у светильников есть свой адрес и они могут управляться по отдельности). О чем было сообщено заказчику и оборудование было заменено.
Далее мы приступили к проектированию кабельного журнала и размещению на схеме точек, куда должны прийти кабели.
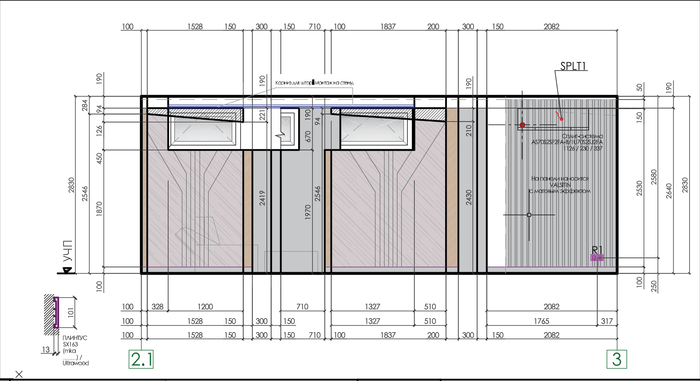
Одна из разверток, с указанием точки под сплитсистему и одну из розеток
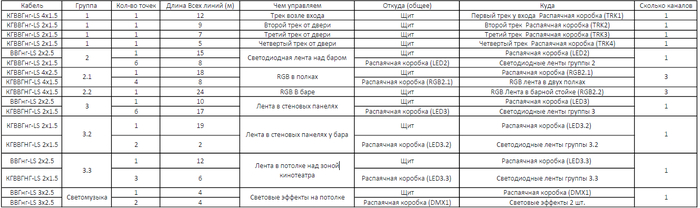
Часть кабельного журнала
Параллельно с монтажом электрики мы работали над схемой коммутации щита с автоматикой, для управления всем оборудованием.
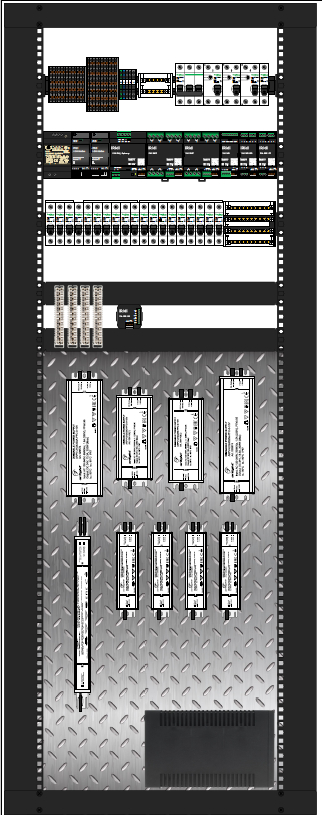
Визуализация наполнения щита
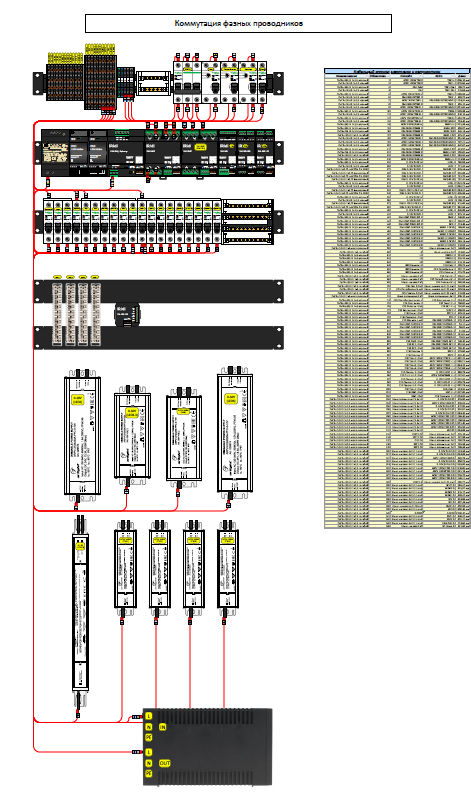
Один из листов с коммутацией
Блоки питания так же были приобретены заказчиком заранее, за счет чего, пришлось увеличить щит практически в 2 раза, чтобы их нормально разместить. Обычно мы используем DIN реечные БП за счет чего существенно выгрываем в габаритах.
Жду шутки про щит для однушки :)
Такое большое количество автоматов обусловлено удобством использования и небольшой разницы в цене. Если из строя выйдет один из блоков питания, его можно будет временно отключить, не лишаясь остального освещения.

Одна из фотографий в процессе электромонтажа

Скоммутированный щит, вид спереди

Скоммутированный щит, вид сзади
Паралельно со сборкой щита, разрабатывался дизайн приложения, как для смартфона, так и для планшета.
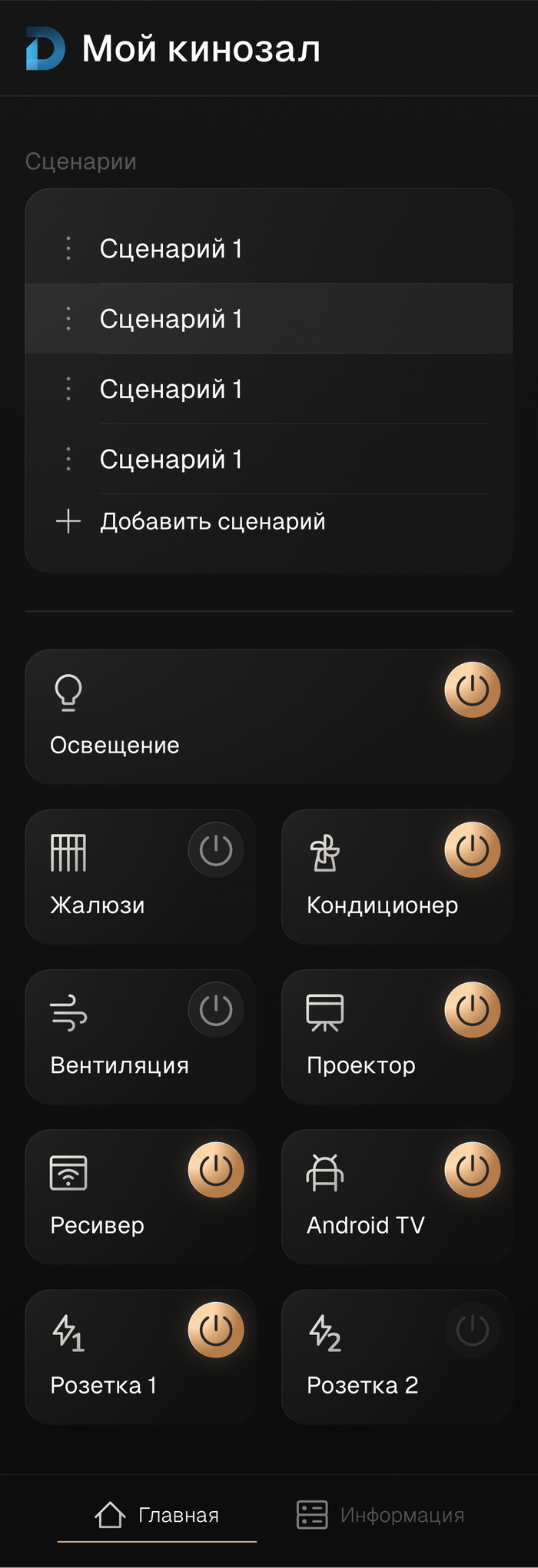
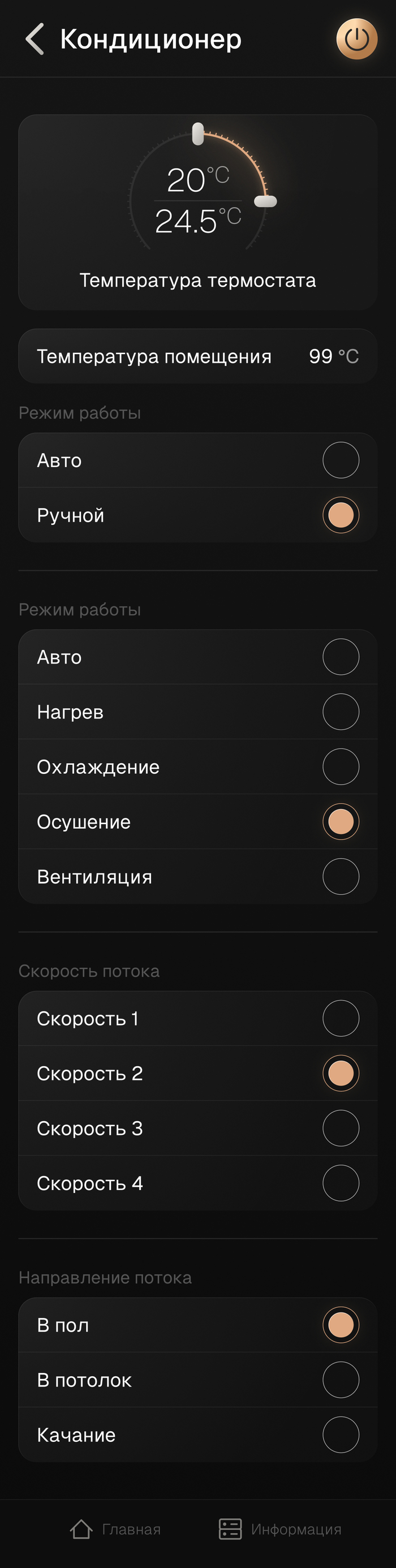
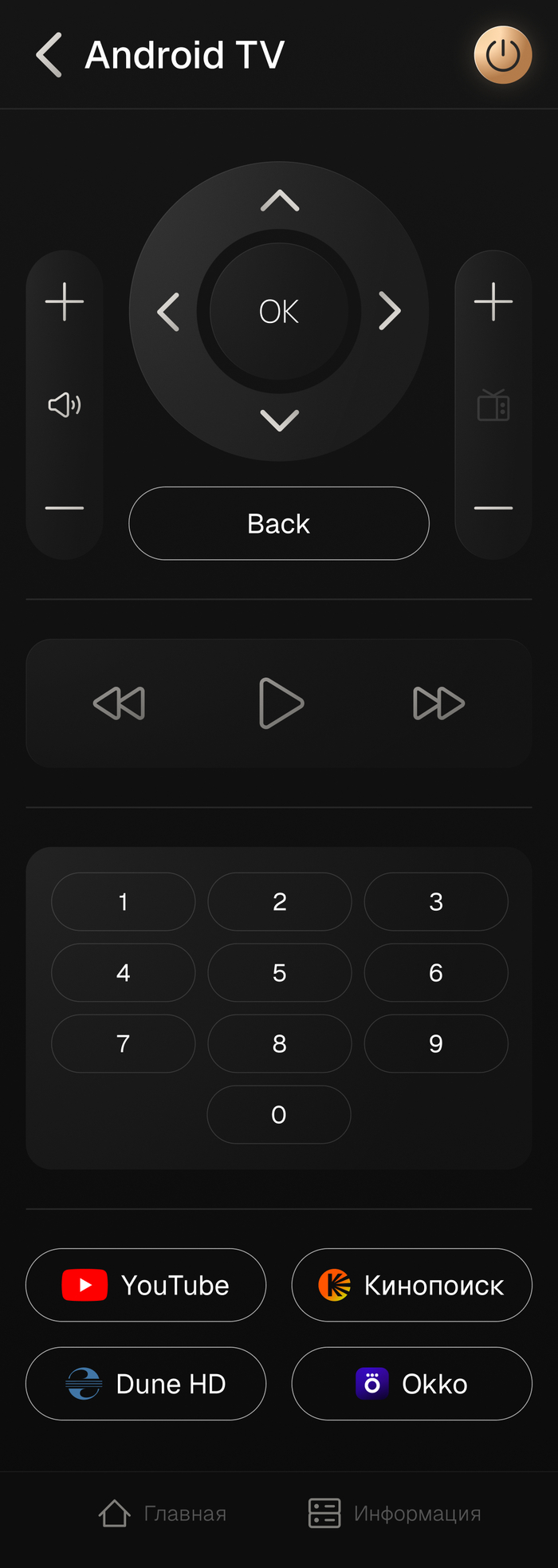
Несколько страниц приложения на смартфон
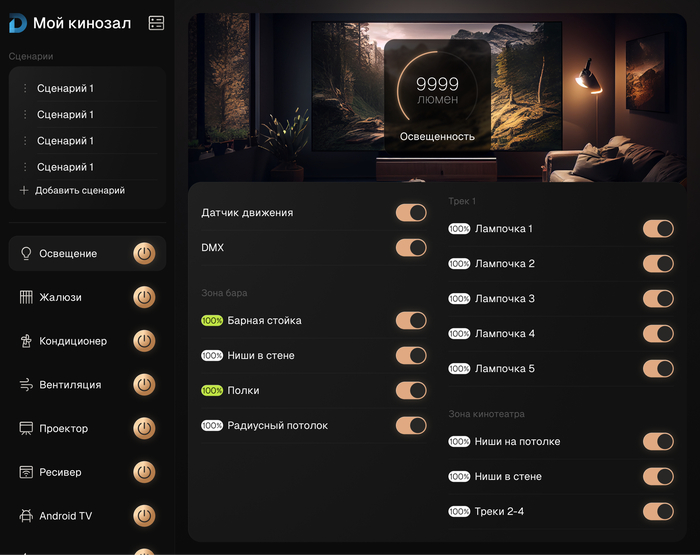
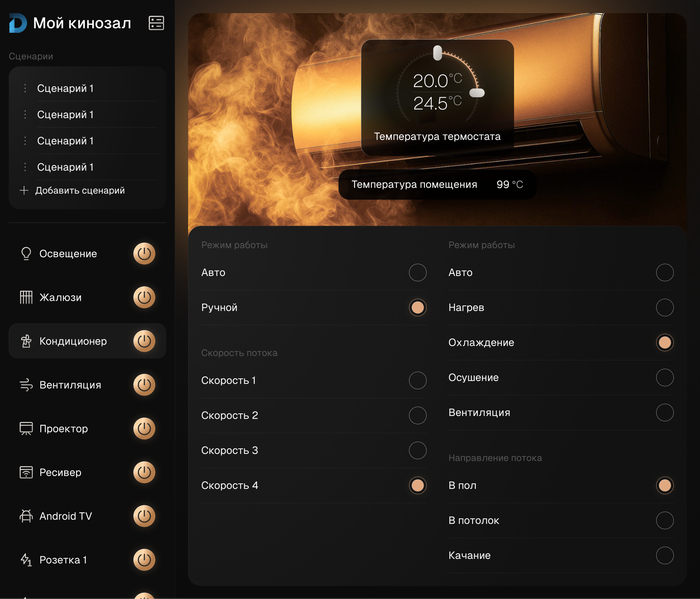
Пара страниц интерфейса планшета
Частично сверстанный интерфейс на смартфоне, еще без логики и подключения оборудования.

Промежуточный этап отделки
По итогу, что получит заказчик?
- Полный контроль над системой
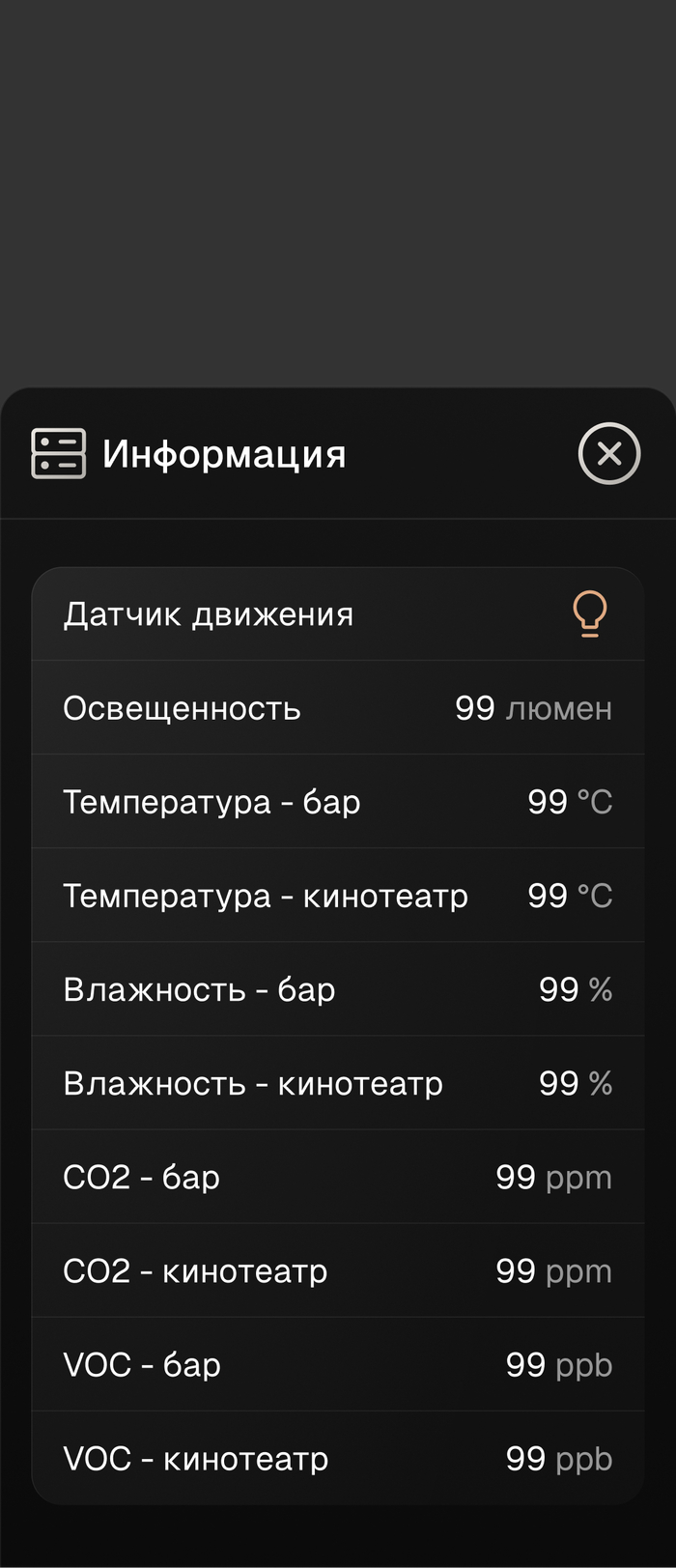
- Климат контроль, на основании сплит-системы и группы датчиков температуры
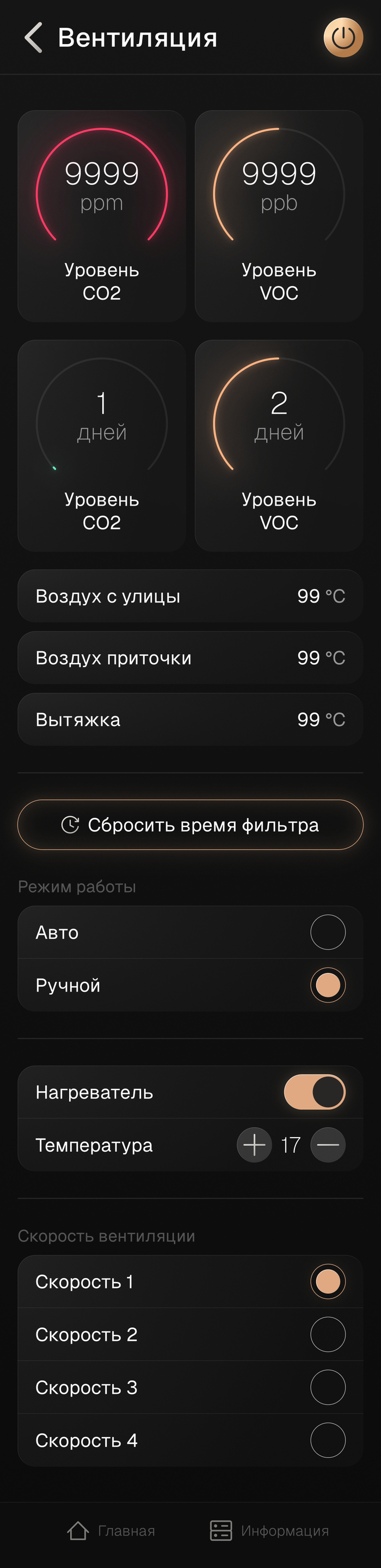
- Автоматическое управление вентиляцией при помощи датчиков кислорода и VOC (например при курении кальяна, либо при определенной концентрации CO2)
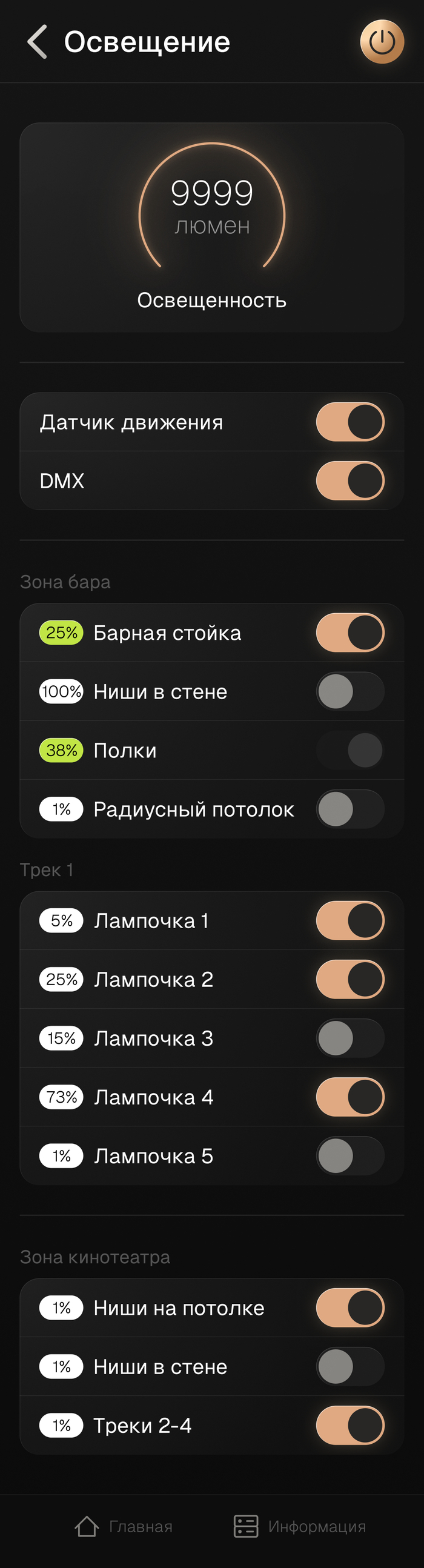
- Приветственное включение света при входе в помещение, яркость зависит от времени суток
- Управление всей системой при помощи заранее прописанных и редактируемых сценариев,в том числе и управление контентом
- Управление всеми устройствами с помощью голосового помощника "Алиса"
- Управление всеми источниками освещения, в том числе и автоматизированное, благодаря датчику движения и сценариям
- Управление роллетами с приводами
- Все источники освещения являются диммируемыми
- Абсолютно автономная система, работающая без доступа к интернету (за исключением Алисы)
Наша система строится на полностью проводном решении от компании IRIDI, в т.ч и управление всей мультимедиа, климатом, вентиляцией, что почти полностью исключает сбои в работе.
На данном этапе еще не окончена отделка помещения, в скором времени будет смонтирован щит автоматики, а так же программируется логика работы внутри приложения.
Если вам было интересно, подписывайтесь, в дальнейшем выложу окончательный результат по проекту, с демонстрацией всех функций.
Супер подробно не стал описывать все этапы, функции, так как в таком случае и 5 постов не хватит :)
Работаем в г.Ростов-на-дону и в области
Если у вас есть запрос на подобную систему, либо полную автоматизацию своего жилья, пишите в ТГ - @Ranger236, обсудим
Так же задавайте вопросы в комментариях, делитесь мнением о проекте, буду рад ответить.
P.S Да, такая система стоит денег. Да, можно сделать на HomeAssistant. Но заказчику нужно готовое решение под ключ, с дальнейшей поддержкой, в виде добавления например караоке, расширения системы на планирующийся рядом дом. А так же независимость от обновлений, модулей, которые могут перестать выпускать, глушилок которые работают у нас в городе на 150%.
Привет, Пикабу!
Я тут в свободное время пилю пет-проект — Telegram-бота VoiceNote AI. Идея простая, но, как мне кажется, полезная. Часто на ходу приходит какая-то мысль, которую надо срочно записать. Доставать телефон, открывать заметки, печатать — долго и неудобно. Гораздо проще надиктовать.
Вот так и родился мой бот. Его основная фича — он превращает голосовые сообщения в умные заметки.
Что умеет бот?
Распознает речь: Кидаешь ему голосовое, он с помощью Yandex SpeechKit превращает его в текст.
Понимает смысл: Дальше в дело вступает нейросеть (DeepSeek), которая из этого текста вытаскивает суть: задачи, даты, время, места и даже имена.
Создает напоминания: Если в сообщении было "Напомни завтра в семь вечера позвонить маме", бот не просто запишет текст, а создаст полноценное напоминание и пришлёт его в нужное время.
Работает с текстом: То же самое можно делать, просто пересылая ему текстовые сообщения.
Ведёт архив и статистику: Все заметки можно посмотреть, отредактировать, выполнить (тогда они уйдут в архив).
Помнит о днях рождения: Есть отдельный раздел, чтобы не забыть поздравить близких.
В общем, получился такой карманный секретарь, который помогает разгрузить голову. Проект я пилю для себя и для людей, поэтому основной функционал бесплатный.

И тут меня осенило: а что, если заметки можно будет создавать, вообще не прикасаясь к телефону? Просто сказать: "Алиса, попроси VoiceNote напомнить мне купить хлеб". Идеально же! Сидишь в машине, готовишь ужин, руки заняты — а мысль улетела в Telegram и превратилась в напоминание.
Сказано — сделано. Я поднял на сервере веб-сервер на FastAPI, который работает параллельно с ботом на aiogram. Написал логику для привязки Telegram-аккаунта к аккаунту Яндекса через одноразовый код. Всё по уму: пользователь в боте получает код, говорит его Алисе, и аккаунты связываются.
В теории всё должно работать как часы.
И вот тут начинается самое интересное. Я дошёл до настройки навыка в консоли Яндекс.Диалогов, и... всё. Я в тупике.
Проблема: при тестировании навыка в консоли диалога - все работает хорошо
Это тесты в приватном режиме бота с Алисой
Но вот стоит мне отправить на публикацию в открытый доступ - начинается дикая вакханалия
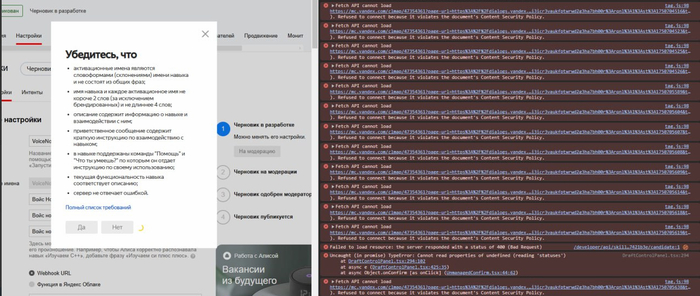
Я перерыл всё. Пробовал разные браузеры, чистил кэш, писал в поддержку (пока молчат). Ни кнопки, ни других способов отправки на модерацию.
Получается функционал я пообещал людям а фактически сижу и ничего не могу сделать
Собственно, обращаюсь к коллективному разуму. Может, кто-то из вас недавно делал навыки для Алисы и сталкивался с таким?
Может, я что-то упускаю и есть определенные условия перед отправкой?
Или я просто слепой и не вижу очевидного? :)
Буду благодарен за любой совет, идею или просто моральную поддержку. Очень уж хочется довести идею до ума и дать людям удобный инструмент.
Ну и, конечно, если вам интересен сам бот — заходите, пробуйте. Он живёт тут: VoiceNote AI. Буду рад любому фидбэку!
Спасибо, что дочитали. Всем добра и работающих API
Всем привет. Вопрос к прогерам и разработчикам. Есть такая умная штука, Алиса. Сценарии мне много упрощают жизнь, хоть и не полноценный умный дом, пока, по потихоньку докупаю устройства и датчики. Хотелось бы узнать, существуют ли прошивки на Алису, с открытым кодом, чтобы на голосовые команды, могла выполнять прописанные скрипты, например тот же wake on LAN для компьютера, или перезагрузка роутера, ну или еще что то простецкое. Грубо говоря голосовой запрос, а в результате какая нибудь CMD строка (через клиент) или запуск батника. Домовенка пока у меня нет, и не смотрел, хотя вроде как он должен уметь такое, но может кто Алиску прошивал?
только что миниАлиса (ребёнкина) наконец-то воспроизвела Депешей, и, увы, инстасамку, и сообщила следующее:
а вы знали, что раньше люди думали глазами, потому что у них не было ушей?
и потом ещё раз повторила, но на другой вопрос.
чо?
Яндекс планирует создать аналог ChatGPT, который встроит в собственные сервисы. Например, «Алису» это сделает «умнее», а поиск сможет сам генерировать ответы на запросы, говорят в компании.
Нейросеть получит название YaLM 2.0, а первые интеграции с сервисами запустят до конца 2023 года.