


Эксперимент над мифом: как коррелированные подзапросы обогнали JOIN по производительности
Взято с основного технического канала Postgres DBA (возможны правки в исходной статье).

Эксперимент над мифом: как коррелированные подзапросы обогнали JOIN по производительности.
Принято считать, что коррелированные подзапросы — это зло, ведущее к проблемам N+1, а JOIN — панацея для производительности. Статья описывает проверку догмы в ходе нагрузочного тестирования, будучи увереным в результатах еще до старта экспериментов.
Результат ошеломил: в некоторых сценариях коррелированный подзапрос показал кардинальное превышение производительности над классическим JOIN. Это наглядный пример того, как теоретическая стоимость запроса, которую мы видим в EXPLAIN, может быть совершенно не релевантна при оценке реальной производительности системы в целом.
Статья — это очередное напоминание всем разработчикам и DBA: в мире СУБД нет абсолютных истин, а любое, даже самое «логичное» правило, нужно проверять экспериментально.
ℹ️ Новый инструмент с открытым исходным кодом для статистического анализа, нагрузочного тестирования и построения отчетов доступен в репозитории GitFlic и GitHub
Задача
Провести экспериментальную проверку гипотезы о влиянии коррелированного запроса на производительность СУБД .
В этом тесте PostgreSQL 16 быстрее выполнил вариант с JOIN + GROUP BY: ~0.415 ms против ~0.803 ms для коррелированного подзапроса.
План JOIN: Hash Right Join + HashAggregate с одним проходом по таблицам — меньше итераций и накладных, чем у подзапроса.
План подзапроса: 25 запусков под-плана с Bitmap Scan по orders (классический N+1-эффект), поэтому медленнее.
Вывод: в PostgreSQL коррелированные подзапросы легко деградируют в N+1; предпочитайте set-based JOIN и проверяйте планы через EXPLAIN ANALYZE.
Источник:
Экспериментальная проверка гипотезы
Виртуальная машина
CPU = 8
RAM = 8GB
Postgres Pro (enterprise certified) 17.5.1 on x86_64-pc-linux-gnu, compiled by gcc (GCC) 11.4.1 20230605 (Red Soft 11.4.0-1), 64-bit
Результаты нагрузочного тестирования
Нагрузка на СУБД
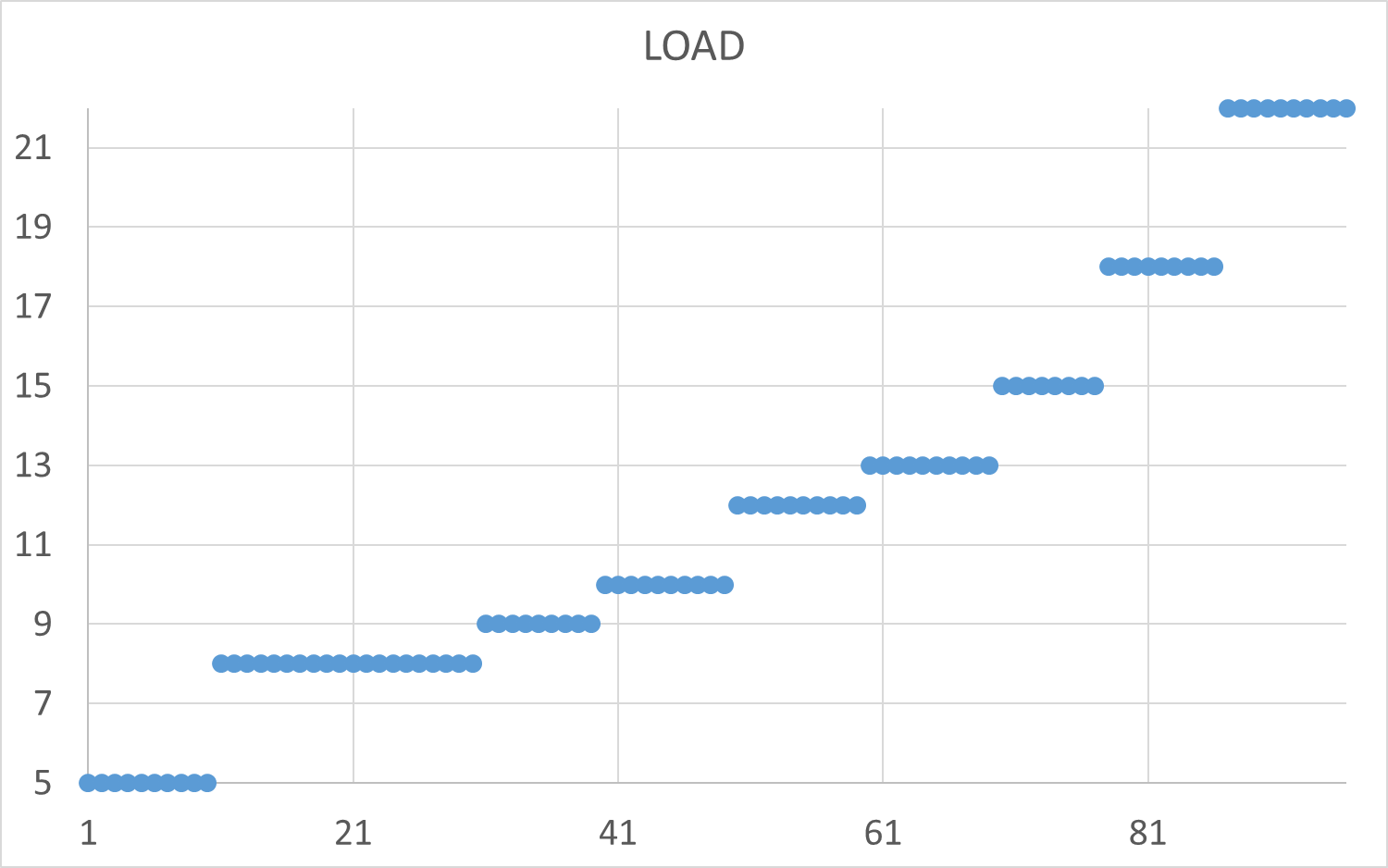
Нагрузка меняется от 5 до 22 одновременных соединений для тестового сценария
Операционная скорость
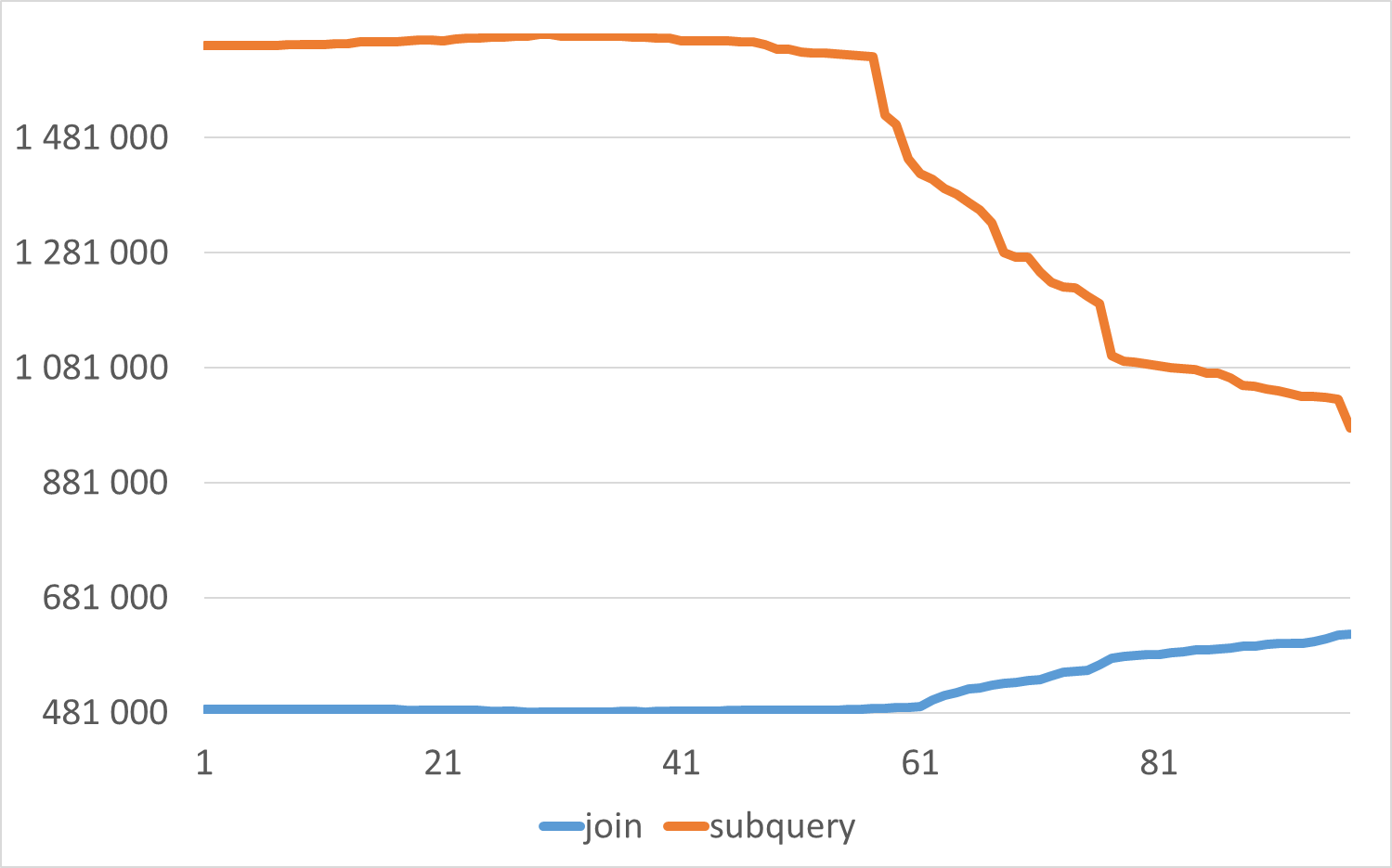
Операционная скорость в ходе нагрузочного тестирования для сценария-1(join) и сценария-2(subquery)
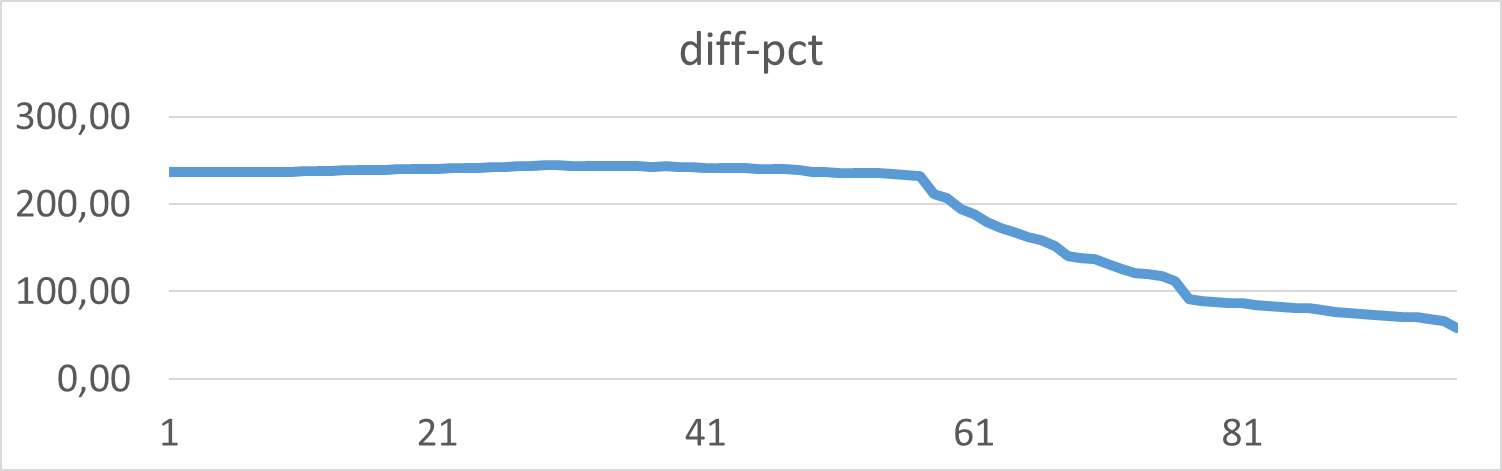
Относительная разницы операционной скорости в сценарии-2 по сравнению с сценарием-1
💣Результат нагрузочного тестирования
Для данной виртуальной машины , данной версии СУБД и данного характера нагрузки среднее снижение операционной скорости в ходе нагрузочного тестирования, для сценария использующего JOIN составило 188%.💥
Postgres DBA
150 постов27 подписчиков
Правила сообщества
Пока действуют стандартные правила Пикабу.