PG_EXPECTO : Тюнинг параметров ОС для оптимизации IO
Взято с основного технического канала Postgres DBA (возможны правки в исходной статье).

PG_EXPECTO: Когда каждый параметр на счету. Тонкая настройка IO — максимальная производительность.
От диагностики к действию
Высокая нагрузка на дисковую подсистему — частое «бутылочное горло», способный затормозить работу даже самого мощного сервера. Когда мониторинг показывает 100% утилизацию диска, растущие задержки и очередь из процессов, ожидающих IO, стандартных настроек ОС уже недостаточно.
Эта статья — не теория, а готовый план как по конкретным симптомам (OLAP-нагрузка, неэффективный кэш, блокировки) выявить корень проблемы и применить целенаправленные правки: от выбора IO-планировщика и настройки виртуальной памяти до оптимизации файловой системы. Каждое изменение объяснено, обосновано и снабжено конкретной командой. Следуя этому руководству, вы системно оптимизируете производительность IO, переводя подсистему из состояния «выживания» в режим эффективной работы.
Начало: Получение данных о производительности IO
Задача
Сформировать список изменений параметров ОС для оптимизации производительности IO.
Промпт
Используя данные о результатах производительности системы IO,
необходимо подготовить список изменений параметров операционной системы для оптимизации производительности подсистемы IO:
**Общее описание оптимизируемых параметров и ожидаемый эффект**
**Оптимизация параметров IO**
- Получение текущего значения параметра
- Изменение значения параметра
- Основание для изменения
- Ожидаемый эффект от изменения
**Итог**
Тюнинг параметров ОС
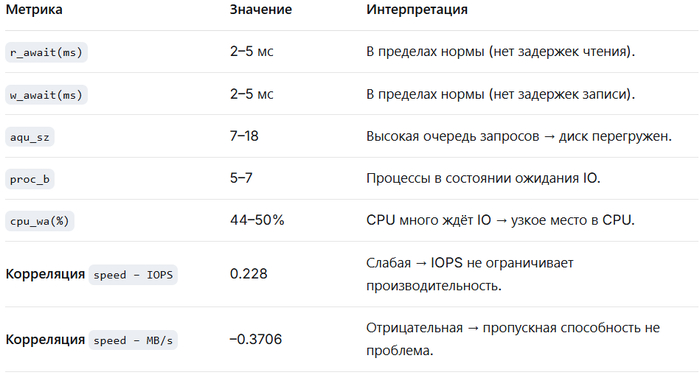
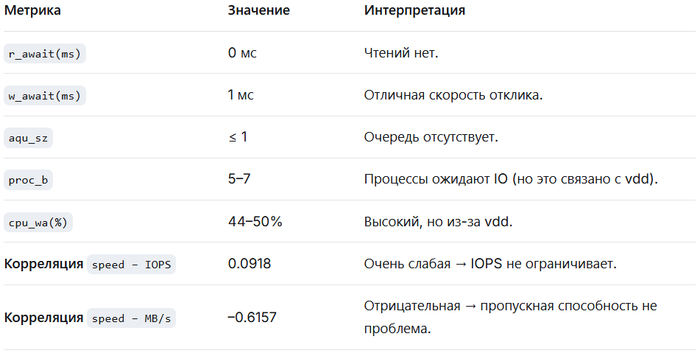
На основе анализа предоставленных данных о производительности IO-подсистемы выявлены следующие проблемы:
Высокая загрузка диска vdd (100% utilization).
Высокая корреляция между использованием кэша памяти и операциями чтения/записи, что указывает на недостаточную эффективность кэширования.
Большое количество процессов в состоянии ожидания IO (uninterruptible sleep), превышающее количество ядер CPU.
Высокое отношение операций чтения к записи (OLAP-сценарий).
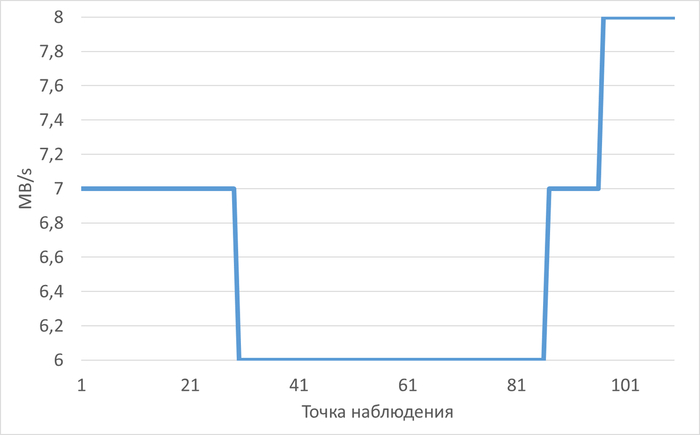
Низкая корреляция между операционной скоростью и IOPS/MB/s, что говорит о том, что узкое место — не в дисках, а в других подсистемах (CPU, блокировки, параметры СУБД).
📋 Список изменений параметров ОС для оптимизации IO
1. Общие параметры производительности
Параметр: vm.dirty_ratio, vm.dirty_background_ratio
Текущее значение:
sysctl vm.dirty_ratio
sysctl vm.dirty_background_ratio
Изменение:
sysctl -w vm.dirty_ratio=10
sysctl -w vm.dirty_background_ratio=5
Основание: Снижает объем «грязных» страниц в памяти перед записью на диск, уменьшая пиковую нагрузку на IO.
Ожидаемый эффект: Более равномерная запись, снижение пикового времени ожидания записи.
2. Параметры IO-планировщика
Параметр: Выбор планировщика для дисков vdd и vdc
Текущее значение:
cat /sys/block/vdd/queue/scheduler
cat /sys/block/vdc/queue/scheduler
Изменение:
echo deadline > /sys/block/vdd/queue/scheduler
echo deadline > /sys/block/vdc/queue/scheduler
Основание: deadline уменьшает задержки для операций чтения, что критично при OLAP-нагрузке.
Ожидаемый эффект: Улучшение времени отклика на чтение, снижение r_await.
3. Увеличение размера очереди запросов
Параметр: nr_requests
Текущее значение:
cat /sys/block/vdd/queue/nr_requests
Изменение:
echo 256 > /sys/block/vdd/queue/nr_requests
Основание: Увеличивает глубину очереди запросов, позволяя диску эффективнее планировать операции.
Ожидаемый эффект: Снижение aqu_sz (средней длины очереди), улучшение утилизации диска.
4. Настройки кэширования и буферизации
Параметр: vm.vfs_cache_pressure
Текущее значение:
sysctl vm.vfs_cache_pressure
Изменение:
sysctl -w vm.vfs_cache_pressure=50
Основание: Уменьшает давление на кэш dentry и inode, что может улучшить кэширование файловых операций.
Ожидаемый эффект: Улучшение эффективности кэша, снижение нагрузки на дисковые операции чтения.
5. Увеличение лимитов на количество открытых файлов
Параметр: fs.file-max, ulimit -n
Текущее значение:
sysctl fs.file-max
ulimit -n
Изменение:
sysctl -w fs.file-max=655356
echo "* soft nofile 65535" >> /etc/security/limits.conf
echo "* hard nofile 65535" >> /etc/security/limits.conf
Основание: При большом количестве операций чтения/записи может требоваться больше открытых файлов.
Ожидаемый эффект: Избежание ошибок “too many open files”, стабильность работы.
6. Настройка параметров виртуальной памяти
Параметр: vm.swappiness
Текущее значение:
sysctl vm.swappiness
Изменение:
sysctl -w vm.swappiness=10
Основание: Уменьшает склонность системы к свопингу, что важно при высокой нагрузке на IO.
Ожидаемый эффект: Больше оперативной памяти доступно для кэширования, меньше свопинга.
7. Настройка параметров сетевой подсистемы (если есть сетевые FS) - опционально
Параметр: net.core.rmem_max, net.core.wmem_max
Текущее значение:
sysctl net.core.rmem_max
sysctl net.core.wmem_max
Изменение:
sysctl -w net.core.rmem_max=16777216
sysctl -w net.core.wmem_max=16777216
Основание: Увеличивает буферы сетевой подсистемы, если используется NFS или другие сетевые хранилища.
Ожидаемый эффект: Улучшение пропускной способности сетевого IO.
8. Оптимизация параметров файловой системы
Параметр: Монтирование с опциями noatime,nodiratime
Текущее значение:
mount | grep /data
Изменение:
В /etc/fstab добавить для разделов /data, /log, /wal:textnoatime,nodiratimeОснование: Уменьшает количество операций записи метаданных времени доступа.
Ожидаемый эффект: Снижение нагрузки на запись.
9. Увеличение размера буферов для операций с блочными устройствами
Параметр: /sys/block/vdd/queue/read_ahead_kb
Текущее значение:
cat /sys/block/vdd/queue/read_ahead_kb
Изменение:
echo 4096 > /sys/block/vdd/queue/read_ahead_kb
Основание: Увеличение предварительного чтения может улучшить производительность последовательных операций чтения.
Ожидаемый эффект: Улучшение rMB/s для последовательных рабочих нагрузок.
10. Настройка параметров энергосбережения для дисков - опционально
Параметр: Управление APM (Advanced Power Management)
Текущее значение:
hdparm -B /dev/vdd
Изменение:
hdparm -B 255 /dev/vdd
Основание: Отключает энергосберегающие режимы, которые могут увеличивать задержки.
Ожидаемый эффект: Снижение r_await и w_await.
Итог
Предложенные изменения направлены на:
Снижение нагрузки на диски за счёт оптимизации кэширования и буферизации.
Улучшение отклика подсистемы IO через настройку планировщика и очередей.
Увеличение эффективности использования оперативной памяти для снижения количества операций чтения/записи.
Оптимизацию работы файловых систем и сетевых подсистем.
Рекомендация:
Вносить изменения постепенно, тестируя каждый параметр под нагрузкой.
Для постоянного применения добавлять настройки в /etc/sysctl.conf, /etc/security/limits.conf и /etc/fstab.