


Синьоры на C++ И C# они такие, еще частично и к жаbникам относится

да-да мемы родом из 2005ого, когда и были популярны и круты С++ ники.
Показать полностью
1
да-да мемы родом из 2005ого, когда и были популярны и круты С++ ники.
Вспомнил игру, которая могла вызвать психические расстройства, Flappy Bird. Решил с помощью нейросети попробовать сделать аналог этой игры, но с небольшой доработкой, в виде встречного движения. Можно теперь позалипать и побеситься в два раза больше.

Знаете, у нас, русских, есть такая суперсила - лень. Иногда она нас подводит, как тот диван, который не даёт встать по утрам, но порой спасает от лишних мук. Взять меня: я всегда откладываю голосовые сообщения от друзей или коллег "на потом". И это "потом" так и не приходит, потому что... ну, лень же! А кто я такой, чтобы спорить с национальным достоянием?
Классика: пара знакомых и даже шеф обожают слать пятиминутные аудио. Слушать их - сплошная пытка, хуже, чем пытаться собрать мебель без инструкции. В голове барьер: то отвлечешься на кота, то перемотаешь назад, то на третьей минуте потеряешь суть из-за этих вечных "эээ", "мэээ" и "ну короче". В итоге переслушиваешь заново, и так по кругу... Как будто жизнь — это подкаст с Лебедевым.
В какой-то момент моя лень взбунтовалась: "Хватит мучиться, давай придумаем, как обойтись без прослушки, иначе я уйду в забастовку!". Я сел и на Python слепил простенький инструмент: кидаю голосовое - и на выходе короткая суть плюс список задач, без всяких слов-паразитов. Всё гениально просто: за секунды понимаешь, что от тебя нужно, и не тратишь пять минут на поиски "а там на второй минуте было важное, кажется". Лень - 1, голосовые - 0.
Недавно опробовал на встрече: в Телеге включил запись, после скинул боту. Он выдал готовый протокол - ключевые тезисы, задачи, кто за что отвечает, всё по пунктам разложено. Удобно до чёртиков: не надо мучиться с "а что там Петя в начале говорил? Или это был эхо от моего собственного зевка?". Вы даже представить не можете как я облегчил себе жизнь, сейчас даже начал просить чтобы все в голосовом отправили.
Как это всё родилось? Сначала научил систему распознавать речь из аудио - типа, "эй, железяка, переведи этот бормот в текст". Потом добавил "очистку" - вырезает "эээ", "ммм" и повторы, как редактор в газете вычёркивает лишние запятые. Далее - выжимка сути и задач в списке. Прикрутил напоминания в пару кликов, чтоб не забыть "завтра утром" - иначе лень напомнит сама, но уже с опозданием. По ходу дела разобрался с форматами, тихими записями и длинными файлами - да, было непросто, как пытаться уговорить лень встать с дивана, но оно того стоило.
Я это для себя сделал, потому что сказать людям "мне лень слушать ваши голосовые" - как-то неловко, а терпеть эти аудио-романы - словно аудиокнигу Войну и мир от энтузиаста с заиканием. Хотелось остаться в комфорте, никого не обидев, и не тонуть в потоке. Похоже, вышло на ура — лень гордится мной.
p.s накидайте идей что еще можно добавить, а то мне лень.

визуал ответа
Напомню - я сам не программист. Делаю онлайн школу программирования с помощью нейросетей.
Уроки проверяются живыми программистами :)
Кстати даю доступ бесплатно, если у вас в Pikabu больше 1000 подписчиков. Пишите в Telegram @mezhirnov
Планирую сделать мобильное приложение с помощью нейросетей.
Уроки уже готовы. Делаю визуальный редактор чтобы можно было учиться не устанавливая ничего на компьютер.
Но пока я решил сделать визуальный редактор, в котором можно писать код. :

Как технически решаю проблемы напишу в следующей статье - потестите пожалуйста и напишите интересны технические статьи или нет?

В новостях всё чаще говорят об «ИИ‑диктофонах» — гаджетах, которые записывают каждый ваш разговор в течение дня, отправляют аудио в облако, превращают его в текст и даже готовят краткую сводку по итогам. Звучит футуристично, но такие решения стоят дорого, требуют постоянной подписки и вызывают вопросы о приватности.
Лично мне идея тотальной записи кажется избыточной. Зато куда практичнее другая задача: получить точную текстовую расшифровку лекции, доклада или публичного выступления. Чтобы потом не переслушивать часы аудио, а быстро найти нужную цитату или мысль простым поиском по тексту.

Мой купленный за 2 т.р. диктофон с возможностью подключения внешнего микрофона на фоне коробки с ESP32
В этой статье я покажу, как построить такую систему без платных подписок и полностью под вашим контролем. Всё, что нужно — обычный диктофон за 1–3 тыс. рублей или даже просто приложение на телефоне — тогда затраты вообще равны нулю, и набор бесплатных, открытых программ, которые работают на вашем компьютере. Я купил диктофон для теста и поделюсь результатами.
Сердцем решения станет OpenAI Whisper — мощная технология распознавания речи от создателей ChatGPT. Главное её преимущество — она может работать полностью автономно на вашем ПК, не отправляя никуда ваши данные. К тому же Whisper распространяется как open‑source: исходный код и модели доступны бесплатно — вы можете скачать, использовать и при необходимости даже модифицировать.
Мои скрипты выложены на GitHub.
За последние пару лет появилось немало open‑source решений для распознавания речи, но именно Whisper стал фактическим стандартом. Его модели обучены на колоссальном массиве данных, что обеспечивает высокую точность распознавания. По сравнению с другими бесплатными движками, Whisper даёт результат ближе всего к коммерческим сервисам вроде Google Speech‑to‑Text и при этом работает автономно. Важный плюс — мультиязычность. Русский язык поддерживается «из коробки».
Модели Whisper бывают разных размеров: от tiny до large. На данный момент наиболее актуальной и точной является large-v3. Главный принцип здесь — компромисс между скоростью, точностью и требуемыми ресурсами (в первую очередь, видеопамятью). У меня видеокарта NVIDIA GeForce RTX 5060 Ti 16 ГБ, поэтому на тестах использую large модель, она требует ~10 ГБ VRAM, но можно начать и со small модели — для неё достаточно ~2 ГБ VRAM.
Не стоит забывать и о приватности: все данные остаются у вас на компьютере. Никаких облачных серверов, никаких подписок. Что понадобится для запуска?
Железо: компьютер с Linux (я использую Ubuntu, но у меня стоит двойная загрузка Windows & Linux через rEFInd Boot Manager). Рекомендуется видеокарта NVIDIA — GPU многократно ускоряет работу, хотя на CPU тоже всё запустится, только медленнее. В качестве источника звука я тестировал обычный диктофон за пару тысяч рублей.
Диктофон за 1–3 тыс. рублей. Много их
Софт:
Python — язык, на котором работает весь стек.
FFmpeg — универсальный конвертер аудио/видео.
PyTorch — фреймворк, на котором обучены модели.
NVIDIA Drivers и CUDA — для связи с видеокартой.
Теперь перейдём от теории к практике и соберём рабочую систему распознавания. Я разбил процесс на несколько шагов — так будет проще повторить.
Шаг 1. Подготовка окружения
Когда‑то я собирал dlib с поддержкой CUDA для для того чтобы распознать лица всех соседей с камеры в подъезде. Тогда я прошёл через несовместимости, конфликты версий и ручную сборку библиотек. Поэтому к установке Whisper я уже был подготовлен.
Чтобы избавить вас от всего этого «удовольствия», я написал универсальный bash‑скрипт setup_whisper.sh. Он берёт на себя всю грязную работу по настройке окружения на Ubuntu 24:
обновляет систему и ставит базовые пакеты, включая Python и FFmpeg;
проверяет драйверы NVIDIA и при необходимости устанавливает их;
подтягивает CUDA Toolkit;
создаёт виртуальное окружение Python и внутри него ставит PyTorch (учитывая модель видеокарты);
загружает сам Whisper и полезные библиотеки;
запускает тест, проверяющий, что GPU действительно работает.
Запуск прост:
chmod +x setup_whisper.sh
./setup_whisper.sh
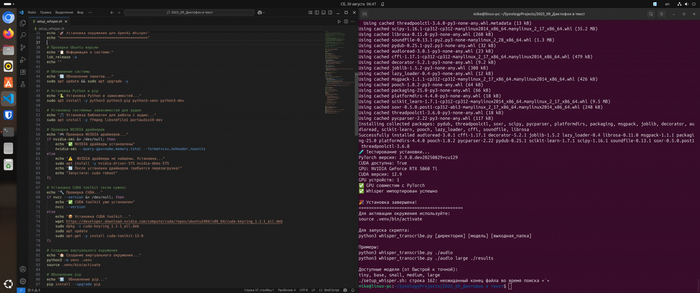
Запуск ./setup_whisper.sh
Полный код setup_whisper.sh на Гитхабе.
Шаг 2. Запись и подготовка аудио
Чем лучше исходная запись, тем меньше ошибок. Записывайте ближе к источнику звука, избегайте шумных помещений и треска. Whisper работает с самыми популярными форматами: mp3, wav, m4a, так что конвертировать вручную не придётся.
Шаг 3. Массовая расшифровка всех подряд записей
Здесь в игру вступает мой второй скрипт — whisper_transcribe.py. Он:
автоматически находит все аудиофайлы в папке;
использует GPU (если доступен), ускоряя работу в десятки раз;
сохраняет результат в нескольких форматах:
.txt для текста,
.srt с таймкодами (можно открыть как субтитры),
all_transcripts.txt — общий файл со всеми расшифровками.
Пример использования:
# Активируем окружение
source .venv/bin/activate
# Запуск по умолчанию (ищет аудио в текущей папке)
python3 whisper_transcribe.py
# Указываем папку с файлами, модель и папку для результатов
python3 whisper_transcribe.py ./audio large ./results
Полный код whisper_transcribe.py на Гитхабе.
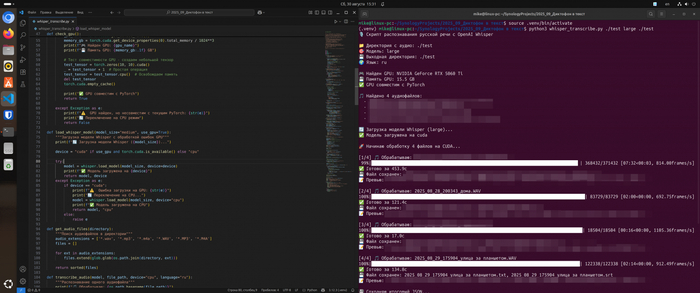
python3 whisper_transcribe.py ./audio large ./results
Шаг 4. Анализ результатов
После обработки вы получите полный набор файлов. Например:
some_lecture.txt — текст лекции;
some_lecture.srt — субтитры вида:
12 00:04:22,500 --> 00:04:26,200 Здесь спикер рассказывает о ключевой идее...
all_transcripts.txt — всё сразу в одном документе.
Я проверил систему на часовом файле. Модель large на моей RTX 5060 Ti справилась за ~8 минут.
А если записывать не лекцию, а совещание? На записи говорят пять человек, и вам нужно понять, кто именно что сказал. Обычный Whisper выдаёт сплошной текст без указания человека. Здесь на помощь приходит диаризация — технология, которая анализирует голосовые характеристики и помечает фрагменты как «Спикер 1», «Спикер 2» и так далее.
Для этого существует WhisperX — расширенная версия Whisper с поддержкой диаризации. Однако при попытке установки я опять столкнулся с классической проблемой ML‑экосистемы: конфликтом зависимостей. WhisperX требует определённые версии torchaudio, которые несовместимы с новыми драйверами NVIDIA для RTX 5060 Ti.
Решение мне подсказали: Docker‑контейнеры NVIDIA. По сути, это готовые «коробки» с предустановленным софтом для машинного обучения — разработчики уже решили все проблемы совместимости за вас. NVIDIA поддерживает целую экосистему таких контейнеров через NGC (NVIDIA GPU Cloud), а сообщество создает специализированные образы под конкретные задачи. Вместо многочасовой борьбы с зависимостями достаточно одной команды docker pull, и вы получаете полностью рабочую среду с предустановленным WhisperX, настроенным PyTorch и всеми библиотеками. В данном случае контейнер ghcr.io/jim60105/whisperx включает диаризацию из коробки и отлично работает с современными GPU.
Диаризация откроет новые возможности: автоматическую генерацию протоколов встреч с указанием авторства реплик, анализ активности участников дискуссий, создание интерактивных расшифровок с навигацией по спикерам.
Это тема для отдельной статьи, которую планирую выпустить после тестирования Docker‑решения на реальных многоголосых записях.
Мы собрали систему, которая позволяет бесплатно и полностью автономно расшифровывать лекции, выступления, а в перспективе и совещания. В основе — OpenAI Whisper, а все настройки и запуск упрощают мои open source скрипты. Достаточно один раз подготовить окружение — и дальше вы сможете регулярно получать точные транскрипты без подписок и риска приватности.
Следующий шаг — диаризация. Это позволит автоматически разделять текст по спикерам и превращать расшифровку совещания в полноценный протокол с указанием авторства.
Автор: Михаил Шардин
🔗 Моя онлайн‑визитка
📢 Telegram «Умный Дом Инвестора»
2 сентября 2025




