Прошло около 2-х месяцев с момента, как я опубликовал очередной курс по компьютерным сетям на stepik. За это время на курс записалось почти 1500 человек, а рейтинг держится 4.9. За что большое спасибо всем учащимся!
На курсе стараюсь активно взаимодействовать со всеми, кто пишет свои мысли, предложения и правки. И в процессе такого общения я решил, что хочу сделать еще одну вещь!
План поста:
что я сделал;
для чего;
причины.
Что я сделал
Сегодня я выложил все свои лекции по сетям в открытый доступ на GitHub (https://github.com/mimi-net/mimi-lectures) под лицензией BY-SA-4.0 (можно делать с ними почти все что хотите). Каждая лекция состоит из:
лекционный материал;
практические задания;
тестовые вопросы.
Помимо этого выложил в открытый доступ исходники всех своих графиков.
Для чего
Этот набор лекций можно использовать как базу для составления очередного курса по сетям. Не тратить время на написание лекций, рисования картинок, придумывания задач и тестовых вопросов.
Быть уверенным, что лекции годные.
Сразу видеть всех, кто вкладывался в написание материала.
Если вы разбираетесь в какой-то теме сетей, то можете написать 1-2 лекции или вообще, только дополнить существующую.
Причины
Когда я выложил свой курс "Основы компьютерных сетей" на Stepik, то мне напихали полную панамку очень много полезных комментариев и правок. Поэтому, говорить что я один автор курса уже как-то не очень правильно.
Даже при условии, что я очень люблю компьютерные сети и интересуюсь ими, я не могу быть экспертом во всех областях сети. В чем-то я отлично разбираюсь, в какой-то области я уже лет 10 ничего нового не смотрел, а что-то только по чужим лекциям и небольшой практике знаю. Я один, а знаний очень много!
Невозможно сделать один или несколько курсов по сетям на все случаи жизни. Разные условия и аудитория, разные цели.
Цель - свести роль преподавателя к составлению плана лекций по сетям и его исполнения. Убрать или максимально сократить часть про написание лекций, подготовке практических заданий и тестов.
Приглашаю всех к созданию публичной базы лекций по компьютерным сетям!
В этом посте поговорим про фрагментацию пакетов, разберемся как она работает и почему она не выгодна никому: ни хостам, ни маршрутизатором, сначала будет немного теории, а затем воспользуемся генератором пакетов и посмотрим дампы.
MTU параметр настраиваемый и не факт, что на всех линка будет настроен MTU, который будет пропускать пакеты, генерируемые отправителем.
Это некие вводные ограничения, которые нам дает Ethernet. IPv4 к этим ограничением добавляет то, что узел получатель должен гарантировать всем своим соседям, что он может принять IP-пакет размером 576 байт, а узел в IPv6 должен уметь обрабатывать пакеты размером 1280 байт.
С учетом вышеописанного легко можно представить две ситуации, в которых может начать работать фрагментация :
Хосты согласовали обмен пакетами 1500 байт (на самом деле они согласовали TCP или SCTP MSS), но на сети есть линк или линки, где MTU меньше 1500 байт.
Хосты генерируют пакеты размером более 1500 байт, а на транзитных узлах MTU равен 1500 байт.
Эти ситуации можно решить за счет хостов, им просто нужно генерировать такие пакеты, которые пролезут через любой линк на сети, проблема в том, что хосты не знают MTU на всей сети и обычно надеются, что MTU всей сети не меньше, чем MTU их интерфейсов, которые в эту сеть включены, но есть и другие варианты решения:
Транзитное устройство может уведомить отправителя о том, что тот генерирует слишком большие пакеты и, если отправителю не запрещено, то он может начать генерировать пакеты меньшего размера.
Транзитный узел может не уведомлять отправителя о том, что тот генерирует большие пакеты, а начать самостоятельно разбивать их на такие пакеты, которые гарантированно пройдут через линк. Это и есть фрагментация.
Слишком большие пакеты могут просто уничтожаться, но нам этот вариант не очень интересен.
Стоит понимать, что фрагментация пакетов явление вынужденное и не очень желательное, единственное достоинство фрагментации заключается в следующем: если приложения не заботятся о размерах передаваемых данных, то это делает IP, чтобы хоть каким-то образом, но связь между отправителем и получателем поддерживалась.
Минусов у фрагментации много, вот три основных на мой взгляд:
При потере одного из фрагментов можно считать, что теряется весь исходный пакет.
Фрагментация повышает нагрузку на устройства сети.
В некоторых случаях при сборке фрагментированного пакет может быть нарушена целостность передаваемых данных.
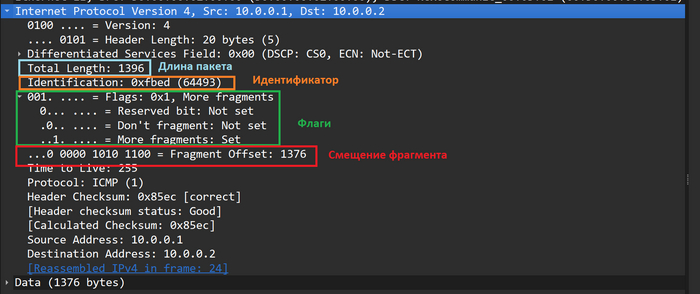
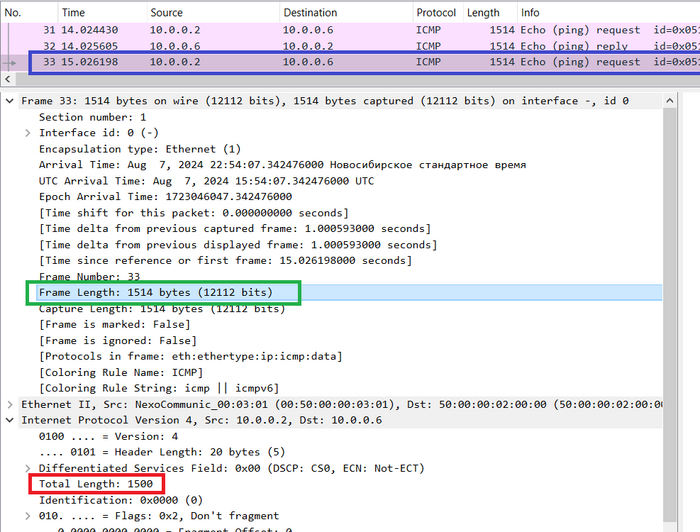
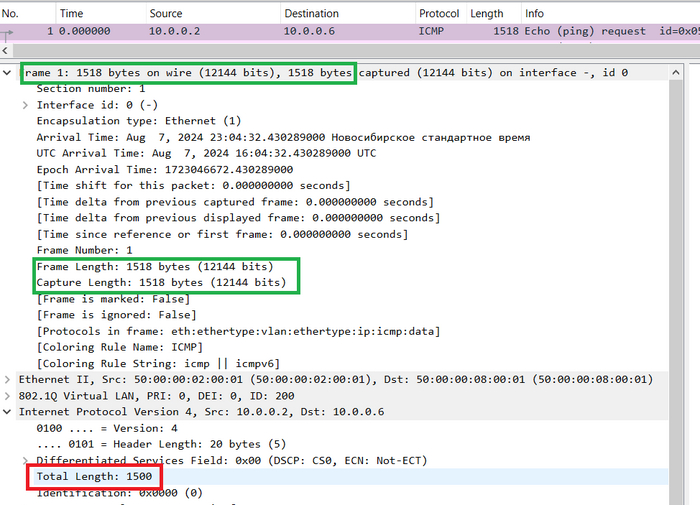
В IP заголовке имеется четыре поля, которые так или иначе используются при фрагментации.
Размер пакет (Total Lenght). В этом поле хранится полный размер пакета в байтах, т.е. заголовка плюс поля данных.
Идентификатор (Identification). Это поле помогает принимающей стороне собрать исходный пакет из полученных фрагментов, у фрагментов, которые являются частями одного исходного пакета, значение этого поля будет одинаковым.
Флаги (Flags). Под каждый флаг выделен один бит, нумерация начинается с нуля. Нулевой бит(нулевой флаг) нам не интересен, первый бит называется DF или do not fragment, если значение этого бита равно единицы, то пакет фрагментировать запрещено, если возникает ситуация когда у пакета DF = 1 и размер больше допустимого MTU, такой пакет уничтожается(некоторые устройства игнорируют бит DF и всё равно выполняют фрагментацию). Второй флаг называется MF или more fragments, он используется для того, чтобы обозначить конец последовательности фрагментированных пакетов, пока MF = 1 узел получатель будет ожидать новые фрагменты, как только придет пакет с MF = 0, получатель поймет, что последовательность фрагментированных пакетов закончилась.
Смещение фрагмента (Fragment Offset). IP не гарантирует того, что получатель будет получать пакеты в той же последовательности, в которой их генерировал отправитель. В случаях, когда фрагментации нет, проблема собрать всё в нужной последовательности это проблема вышестоящего процесса или протокола, но если получатель принял фрагментированную последовательность, задача собрать исходных пакет из фрагментов ложится на IP процесс, поле смещение помогает понять в какой последовательности надо собирать исходный пакет. Данное поле хранит численное значение, одна единица этого числа равна восьми байтам.
Вот так эти поля выглядят в дампе Wireshark.
Поля фрагментированного пакета:Total Length, Identification, Flags, Fragment Offset в дампе Wireshark
Структура IP-пакета
Цвета на двух картинках выше соответствуют.
Смещение фрагмента в IP
Стоит отдельно остановиться на поле Fragment Offset, его размер 13 бит, то есть максимальное значение этого поля 8191, но весь вопрос в том, какие единицы измерения используются для смещения фрагмента, если в этом поле стоит значение 1, то это означает, что сдвиг надо делать на 8 байт, то есть максимально возможное смещение 65528 байт.
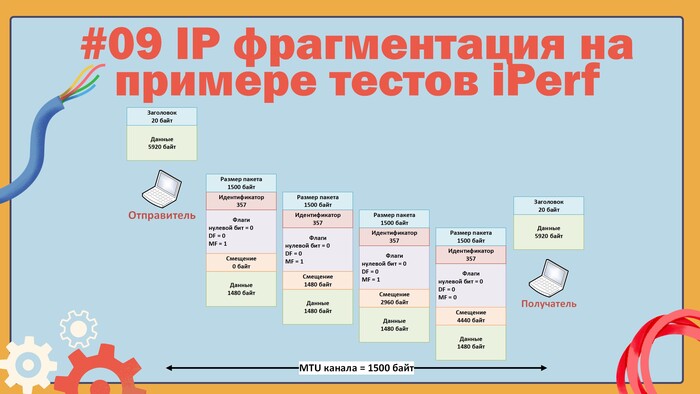
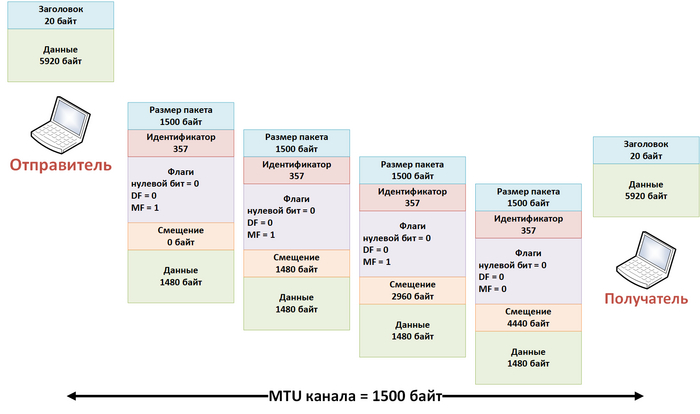
Проще всего разобраться с вопросом смещения можно будет на примере, допустим, у нас есть два хоста, соединенных каналом с MTU 1500 байт, но хосты хотят обмениваться пакетами размером 5940 байт, в этом случае будет включаться механизм фрагментации, и каждый исходный пакет будет разделен на четыре пакета по 1500 байт, чтобы они гарантированно прошли через канал, смещение первого фрагментированного пакета будет равно нулю, у второго пакета оно уже будет 1480 байт, третий пакет будет иметь смещение 2960 и последний пакет будет со смещением 4440 байт, все описанное выше представлено на рисунке.
Пример работы фрагментации IP пакетов
Для удобства я пересчитывал единицы измерения смещения в байты.
Из примера понятно, что фрагментация это лишняя работа не только для транзитных узлов, которые ее выполняют, но и для хостов. Также в примере виден смысл поля ID и флага MF, по ним получатель понимает, что это не конец фрагментированной последовательности, но получатель заранее не знает размер исходного пакета.
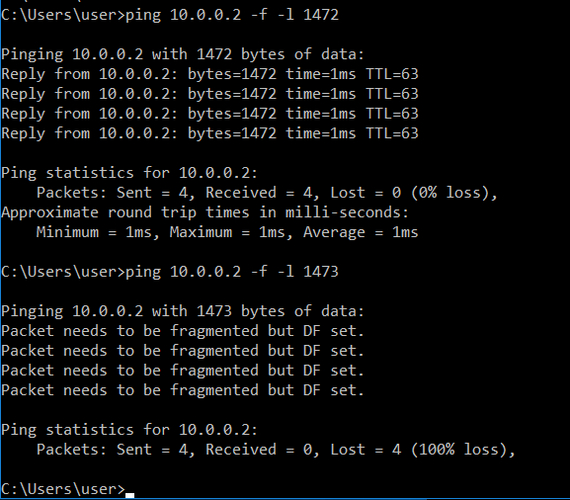
В качестве проверки и подтверждения сказанного ранее я сделал пинг пакетам с размером, как в примере выше, и снял дамп, важно, чтобы MTU линков был равен 1500 байт чтобы получилось как в примере.
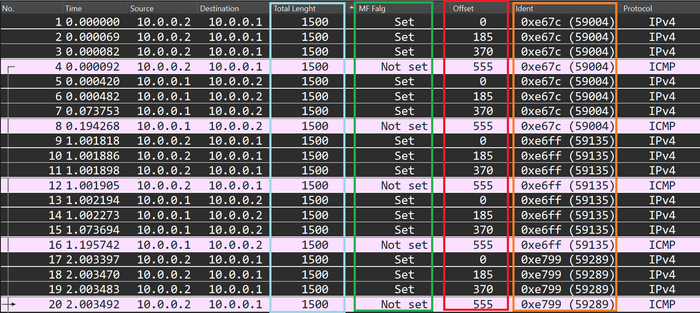
Пример фрагментированных пакетов в дампе Wireshark
Интересные столбцы выделены цветами:
голубой = размер пакета
зеленый = наличие флага MF
красный = смещение
оранжевый = идентификатор
Строки выделять не стал, поскольку розовая строка здесь означает конец фрагментированной последовательности. Плюс важно учитывать, что на этом скрине в столбце Offset значение смещения не в байтах.
Установка iPerf3 на Linux и в Windows
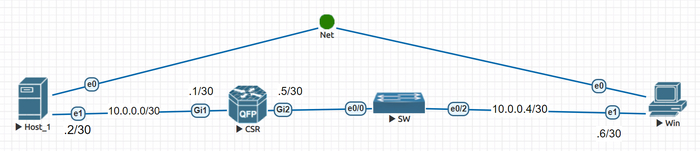
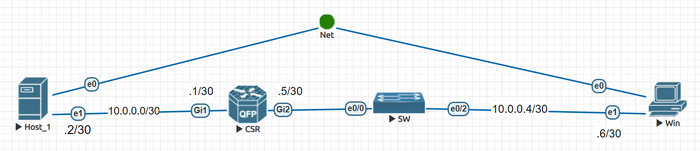
Перейдем к практике, тренироваться будем на той же лабе, которая использовалась в посте про MTU. Вот топология сети:
Топология сети лабы
Далее будет краткий гайд по установке и использованию iPerf в Linux и Windows, кому этот момент очевиден, можно смело пропускать.
Iperf представляет собой простой кросс-платформенный генератор трафика, у него есть две версии: вторая и третья, второй никогда не пользовался и чем она отличается от третьей не знаю. Iperf является клиент-серверным приложением.
Iperf это утилита командной строки в Windows, установка его здесь довольная простая, скачиваете архив по этой ссылке, выбирайте самую свежую версию, она внизу. Внутри полученного архива будет папка с именем iperf+номер_версии_разрядность_ОС:
Архив с iPerf3
Если хотите, можете скинуть эту папку в любое удобное вам место и на этом установка будет завершена. Я же создам в корне диска C папку с именем iperf3 и скопирую в него содержимое папки "iperf3.17_64.", так будет проще:
Установленный iPerf3
При желании можете добавить путь к файлу iperf3.exe в переменную PATH, тогда для запуска программы не придется каждый раз в командной строке переходить по пути C:\iperf3 чтобы запустить программу.
Установку в Linux буду показывать на примере Debian 10, пишем две команды:
sudo apt update&&upgrade -y
sudo apt install iperf3
В других дистрибутивах команды могут отличаться, в команде на установку iperf тройку после iperf пишем обязательно, иначе установится вторая версия.
Примечание
В репозитории дистрибутива, который вы используете, может находиться пакет не с самой последней версией iPerf, в моем случае вопрос версии не принципиален, нам просто надо посмотреть на работу фрагментации, но если вы планируете использовать его для тестов своих каналов, учитывайте два момента: тесты, выполненные на iperf разных версий, могут не показать реальной картины (обычно результаты хуже чем есть на самом деле), в разных версиях есть разные баги, влияющие на результаты тестирования. Microsoft же вообще не рекомендует использовать iPerf для тестов в Windows.
Как запустить тест скорости iPerf
Запустить тест скорости в iPerf дело не хитрое, начнем с сервера. Запуск сервера делается так:
iperf3 -s
Запущенный сервер iPerf в Linux
Сервер ожидает запросы от клиента на порт 5201 любого из транспортных протоколов: TCP, UDP, SCTP. Если у вас используется firewall, убедитесь что порт открыт.
Клиента iperf будем запускать в Windows, для этого нужно запустить командую строку желательно от имени администратора, перейти в папку, где лежит exe файл (переходить никуда не надо будет, если добавить путь к iperf3.exe в переменную PATH):
C:\Windows\system32>cd c:\iperf3
c:\iperf3>iperf3.exe -c 10.0.0.2 -f k -M 1300
Connecting to host 10.0.0.2, port 5201
[ 5] local 10.0.0.6 port 49786 connected to 10.0.0.2 port 5201
Опции для разных ОС одинаковые, пользователи Linux могут получить справку при помощи утилиты man, в Windows можно написать iperf3.exe -h, но лучше обратиться к документации. Опции iperf делятся на серверные, клиентские и универсальные.
Теперь по поводу команды в Windows: -c говорит о том, что iperf запускается в режиме клиента, при этом данной опции надо передать IP-адрес сервера. Опция -f k говорит iperf о том, что скорость должна быть отображена в kbps, а -M 1300 задает размер TCP MSS 1300 байт.
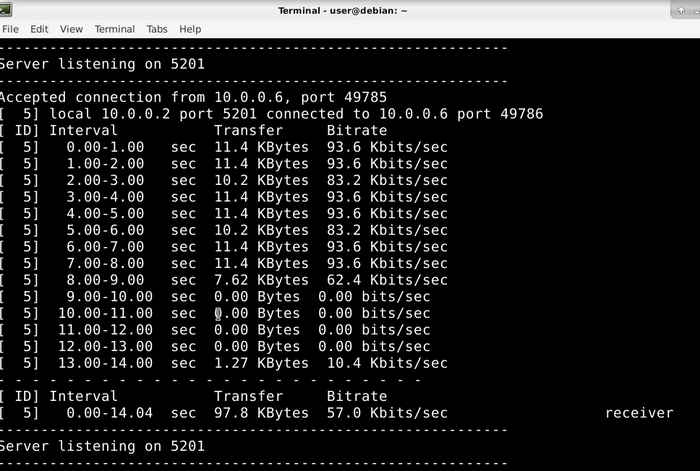
Учитывайте, что какой бы протокол вы не использовали, iperf выставить df-bit = 1 и это никак не изменить, насколько мне известно, и это нужно учитывать при дальнейших тестах, плюс по умолчанию iperf генерирует пакеты только в одну сторону: от клиента к серверу. На сервере статистика тоже отображается, вот статистика для соединения, которое мы инициировали командой, выполненной выше в Windows:
Статистика теста скорости iperf на Linux сервере
Более детальную информацию о тесте можно получать, если использовать опцию -V на клиенте и сервере.
Как убрать df-bit у транзитного IP-пакета на роутере Cisco
Пожалуй, самый плохой сценарий для маршрутизатора в вопросах фрагментации, это когда маршрутизатор выполняет эту самую фрагментацию. Выше я не случайно написал про df-bit, который iPerf всегда выставляет на генерируемые им пакеты. С выставленным df-bit мы фрагментацию никогда не увидим, значит, его надо обнулить, как это сделать средствами Windows я не знаю и тратить время на то, чтобы с этим разобраться я не захотел, а вот на роутерах Cisco можно написать route-map и навешать этот route-map на интерфейс, в который будут входить пакеты с установленным df-bit, который мы хотим обнулять.
Примечание
Для тех, кто читал пост про MTU. В той лабе на интерфейсе CSR в сторону коммутатора был создан саб-интерфейс Gi2.200, на нем и был настроен IP-адрес, сейчас же саб-интерфейс Gi2.200 удален, IP-адрес перенесен на Gi2, а на линке CSR/SW кадры ходят без вланов.
Создать route-map можно, например, такой:
CSR#conf t
CSR(config)#route-map RM_DEL-DF-BIT permit 10
CSR(config-route-map)#match ip address 101
CSR(config-route-map)#set ip df 0
CSR(config-route-map)#exit
CSR(config)#access-list 101 permit tcp 10.0.0.0 0.0.0.255 any
Строка set ip df 0 как раз и заставляет обнулять df-bit, а RM_DEL-DF-BIT это просто имя route-map, которое я ей придумал. Роут-мапу нам надо повешать на интерфейс Gi2, поскольку пакеты с df-bit, который мы хотим обнулять, будут входить именно в интерфейс (если бы остался саб-интерфейс Gi2.200, то тогда вешать надо было бы на него). Делается это так:
CSR#conf t
CSR(config)#int gi2
CSR(config-if)#ip policy route-map RM_DEL-DF-BIT
И давайте зададим IP MTU 1300 байт на интерфейс Gi1:
CSR#conf t
CSR(config)#int gi1
CSR(config-if)#ip mtu 1300
Всё, лабу подготовили.
Как работает фрагментация IP пакетов на роутере
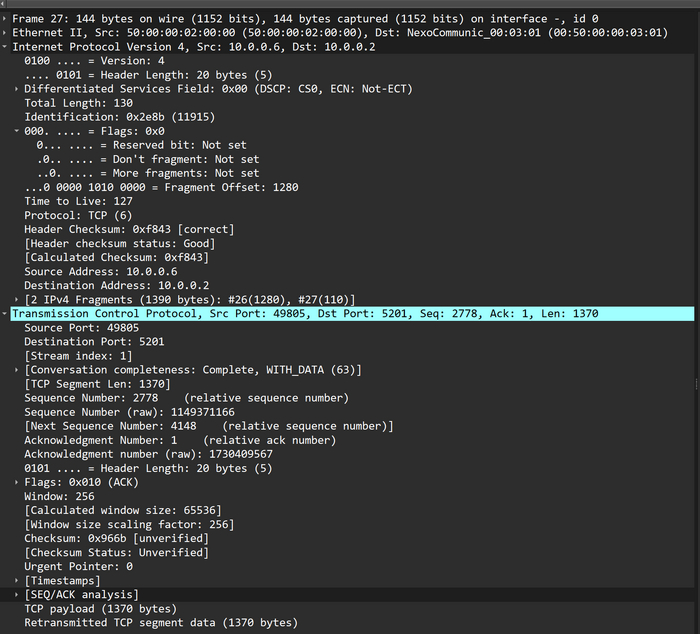
Наконец-то мы добрались до самой фрагментации. Запустим iperf на Винде(команда iperf3.exe -c 10.0.0.2 -f k -M 1370) и снимем дампы:
Первый с линка между SW/Win, здесь будут идти не фрагментированные пакеты с TCP MSS 1370 байт, это уже больше чем MTU интерфейса Gi1, но к значению MSS нужно будет добавить еще размеры заголовков TCP и IP.
Второй дамп будем делать с линка Host_1/CSR. Здесь мы сможем увидеть фрагментированные пакеты, видя два дампа, мы сможем сделать вывод о том, что фрагментацию выполняет именно роутер.
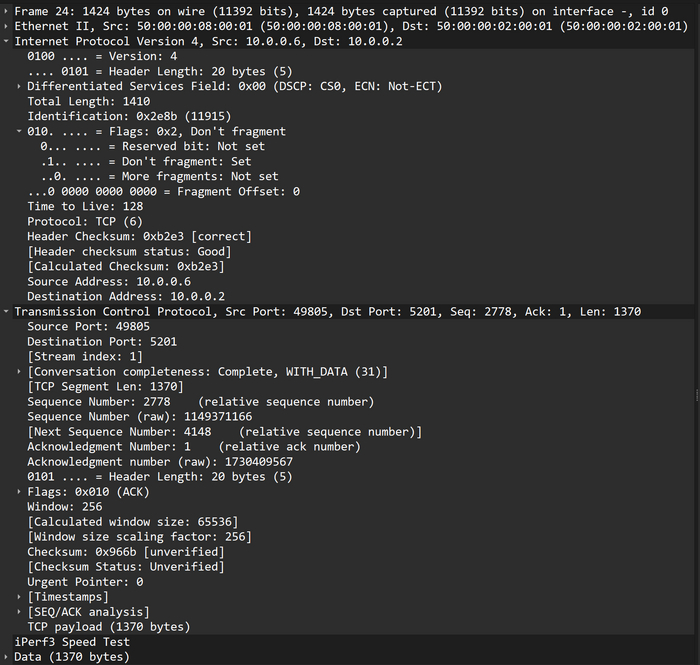
Важно найти один и тот же пакет как в первом, так и во втором дампе, проще всего это сделать по идентификатору пакета. Вот пакет с номером 2e8b на линке SW/Win:
Не фрагментированный пакет размером 1410 байт
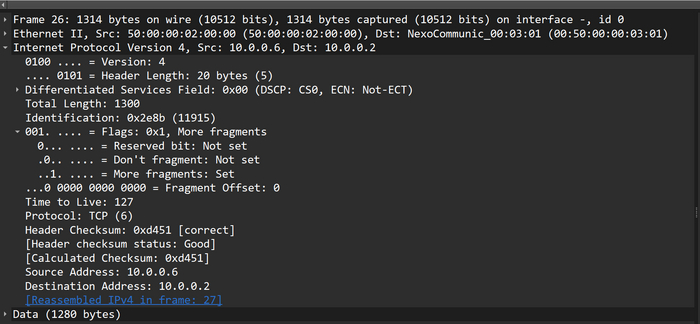
Размер пакета 1410 байт, df-bit = 1. А вот этот же пакет на линке Host_1/CSR:
Роутер разделил исходный пакет и теперь вместо одного пакета 1410 байт у нас два пакета размером 1430 байт
Во-первых, пакетов два: 1300 байт и 130 байт, а это больше изначальных 1410, уже неприятно, особенно, если счёт будем вести на миллионы. Во-вторых, видим, что пакеты, которые идут в сторону Debian, имеют df-bit = 0, из увиденного делаем выводы:
Route-map работает, CSR снимает df-bit и делает фрагментацию.
Фрагментацию выполняет роутер.
Не вижу сейчас особого смысла смотреть внутрь пакета, т.к. все интересующие нас поля я вывел в дамп, но если что, вот пакет, который генерировала Винда:
Исходный пакет размером 1410 байт
Вот первый фрагмент на выходе из CSR Gi1:
Первый фрагмент исходного пакета
А вот второй фрагмент:
Второй фрагмент исходного IP-пакета
Мы посмотрели пример фрагментации пакетов, понятно, что делать это на роутерах не очень правильно, но иногда приходится.
В следующий раз поговорим про Path MTU Discovery, для этого нужно отвязать route-map от интерфейса Gi2, чтобы роутер перестал обнулять df-bit:
CSR#conf t
CSR(config)#int gi2
CSR(config-if)#no ip policy route-map RM_DEL-DF-BIT
IP MTU 1300 байт на линке Gi1 оставляем.
Вопросы для ваших ответов
Может ли фрагментированный IP пакет быть меньше 68 байт и почему?
Напомню топологию
Топология сети лабы
Представим ситуации: на интерфейсе Gi2 роутера CSR настроен IP MTU 1400 байт, на всех остальных линках IP MTU 1500 байт, хост Windows генерирует в сторону Linux пакеты размером 1450 байт, что с этими пакетами будет?
Имеется линк с IP MTU 700 байт: на сколько фрагментов и какого разрмера будет разбит пакет1400 байт?
Имеется линк с IP MTU 725 байт: на сколько фрагментов и какого разрмера будет разбит пакет1430 байт?
Видео версия
Для тех, кому проще смотреть и слушать есть видео версия
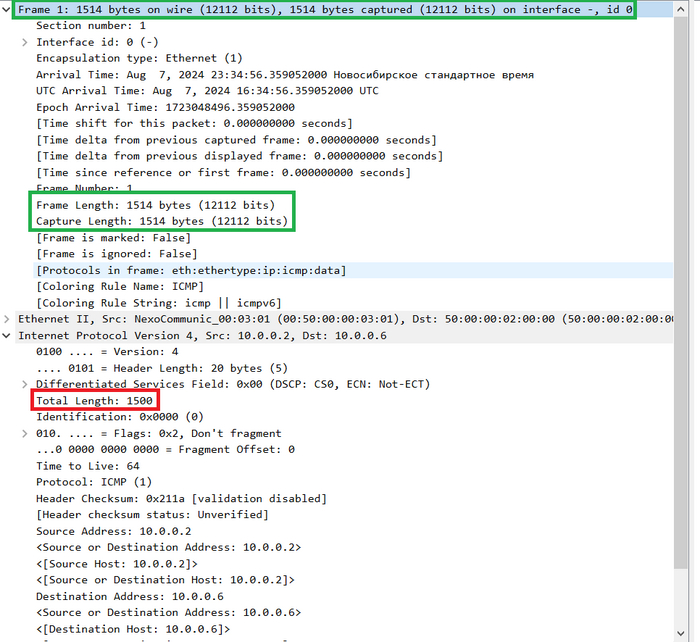
В прошлом посте обсудили MTU и некоторые важные особенности, связанные с размерами пакетов и кадров, в этом давайте посмотрим: как можно менять MTU на различном оборудование, для примера рассмотрим следующие устройства:
Компьютер под управлением Linux, для этого будет использоваться виртуальная машина с Debian 10 (на схеме это Host_1).
Компьютер под управлением Windows 10 (значок с подписью Win).
Роутер CSR1000v под управлением IOS XE.
Хотелось бы еще рассмотреть классические коммутаторы, но коммутаторы под управлением IOL в EVE-NG, как я понял, всё-таки являются multilayer свичами, а не классическими L2, плюс на IOL у меня не получилось изменить канальный MTU, но SW на схему добавлен и мы немного с ним поработаем.
Схема, на которой будем всё это тестировать:
Схема для тестов с MTU
Зеленый кружок это возможность для выхода устройств лабы в реальную сеть, IP-адреса подписаны на схеме, а на линке SW/CSR кадры ходят в 200 влане, в сторону Windows кадры отдаются без метки.
Как изменить MTU на коммутаторе Cisco
Перед изменением MTU разберемся как его смотреть, есть стандартное заблуждение, что на оборудование Cisco в конфигурации нельзя увидеть значения MTU, если оно равно значению MTU по умолчанию, и действительно, команда show run не дает никаких результатов:
SW#sh run | in mtu
SW#sh run | in MTU
SW#
Можно даже посмотреть конфигурацию одного из интерфейсов:
SW#sh run int e0/0
Building configuration...
Current configuration : 29 bytes
!
interface Ethernet0/0
end
SW#
Но почему-то многие забывают что есть show run all:
SW#sh run all | in mtu
crypto ikev2 fragmentation mtu 576
mtu 1500
mpls mtu 1500
mtu 1500
mpls mtu 1500
mtu 1500
mpls mtu 1500
mtu 1500
mpls mtu 1500
no ip tcp path-mtu-discovery
SW#
В лабе EVE-NG используется коммутатор IOL, MTU у них меняются на интерфейсах. Вот пример конфигурации интерфейса Ethernet0/0:
SW#show run all | s Ethernet0/0
buffers Ethernet0/0 permanent 96
buffers Ethernet0/0 max-free 96
buffers Ethernet0/0 min-free 0
buffers Ethernet0/0 initial 0
interface Ethernet0/0
switchport
switchport access vlan 1
no switchport nonegotiate
no switchport protected
no switchport port-security mac-address sticky
mtu 1500
no ip arp inspection trust
ip arp inspection limit rate 15 burst interval 1
ip arp inspection limit rate 15
load-interval 300
carrier-delay 2
no shutdown
tx-ring-limit 64
tx-queue-limit 64
no macsec replay-protection
no macsec
ipv6 mfib forwarding input
ipv6 mfib forwarding output
ipv6 mfib cef input
ipv6 mfib cef output
mpls mtu 1500
snmp trap link-status
no onep application openflow exclusive
cts role-based enforcement
no mka pre-shared-key
mka default-policy
cdp tlv location
cdp tlv server-location
cdp tlv app
arp arpa
arp timeout 14400
channel-group auto
spanning-tree port-priority 128
spanning-tree cost 0
hold-queue 2000 in
hold-queue 0 out
ip igmp snooping tcn flood
no bgp-policy accounting input
no bgp-policy accounting output
no bgp-policy accounting input source
no bgp-policy accounting output source
no bgp-policy source ip-prec-map
no bgp-policy source ip-qos-map
no bgp-policy destination ip-prec-map
no bgp-policy destination ip-qos-map
SW#
Если не увидели в выводе выше значение MTU, то вот строки: mtu 1500, mpls mtu 1500. Все интерфейсов на коммутаторе четыре:
SW#
SW#sh int des
Interface Status Protocol Description
Et0/0 up up
Et0/1 up up
Et0/2 up up
Et0/3 up up
SW#
Посмотреть MTU на интерфейсе можно еще и так:
SW#sh int e0/0 | in MTU
MTU 1500 bytes, BW 10000 Kbit/sec, DLY 1000 usec,
SW#
Это канальный MTU. В конфигурации каждого порта мы видим два MTU: Ethernet и MPLS, оба равны 1500 байт, но порт можно перевести в режим роутера, тогда у него появится еще и IP MTU. Переводим порт:
SW#conf t
SW(config)#int e0/1
SW(config-if)#no switchport
Посмотрим какие MTU есть на коммутаторе:
SW#sh run all | in mtu
crypto ikev2 fragmentation mtu 576
mtu 1500
mpls mtu 1500
mtu 1500
ip mtu 1500
mpls mtu 1500
mtu 1500
mpls mtu 1500
mtu 1500
mpls mtu 1500
no ip tcp path-mtu-discovery
SW
Появилась строка ip mtu 1500, она относится к порту Ethernet0/1. Чтобы посмотреть IP MTU можно воспользоваться вот такой командной:
SW#sh ip int e0/1
Ethernet0/1 is up, line protocol is up
Internet protocol processing disabled
SW#
Возникла ошибка, дело в том, что интерфейс e0/1 переведен в режим роутера, но на нем не работает IP процесс, чтобы он заработал, надо настроить IP-адрес:
SW#conf t
Enter configuration commands, one per line.
SW(config)#int e0/1
SW(config-if)#ip add
SW(config-if)#ip address 1.1.1.1 255.255.255.0
Теперь мы можем посмотреть IP MTU и другие параметры процесса IP:
SW#sh ip int e0/1
Ethernet0/1 is up, line protocol is up
Internet address is 1.1.1.1/24
Broadcast address is 255.255.255.255
Address determined by setup command
MTU is 1500 bytes
MPLS MTU посмотреть можно так (но MPLS должен быть включен на интерфейсе):
SW# sh mpls interfaces e0/1 detail
Interface Ethernet0/1:
Type Unknown
IP labeling not enabled
LSP Tunnel labeling not enabled
IP FRR labeling not enabled
BGP labeling not enabled
MPLS not operational
MTU = 1500
SW#
Изменить канальный MTU можно было бы вот такой командой:
SW#conf t
SW(config)#int e0/1
SW(config-if)#mtu 1600
% Interface Ethernet0/1 does not support user settable mtu.
SW(config-if)#
IP MTU на образах IOL меняется:
SW(config-if)#ip mtu 1000
MPLS MTU тоже можно поменять:
SW(config-if)#mpls mtu 1100
Итоговая конфигурация интерфейса теперь такая:
SW#sh run int e0/1
Building configuration...
Current configuration : 106 bytes
!
interface Ethernet0/1
no switchport
ip address 1.1.1.1 255.255.255.0
ip mtu 1000
mpls mtu 1100
end
SW#
Классические коммутаторы Cisco, как правило, не позволяют менять MTU отдельных интерфейсов и не имеют конфигураций MPLS MTU, у них есть так называемый system mtu, который позволяет задавать MTU всем интерфейсам сразу, показать не могу, поэтому отправлю к странице Configuration Guide для Catalyst 2960.
Команда Ping и размеры пакетов при пинге
Порт e0/1 на коммутаторе никак не влияет на передачу данных между хостами. MTU на всех линках, которые обеспечивают связность между ПК, сейчас стандартный и равен 1500 байт. Давайте в этом убедимся пингом с одного хоста на другой:
user@debian:~$ ping 10.0.0.6 -M do -s 1472 -c 4
PING 10.0.0.6 (10.0.0.6) 1472(1500) bytes of data.
1480 bytes from 10.0.0.6: icmp_seq=1 ttl=127 time=1.20 ms
1480 bytes from 10.0.0.6: icmp_seq=2 ttl=127 time=1.51 ms
1480 bytes from 10.0.0.6: icmp_seq=3 ttl=127 time=1.46 ms
1480 bytes from 10.0.0.6: icmp_seq=4 ttl=127 time=1.76 ms
Здесь стоит обратить внимание на то, что опция -s 1472 задает размер ICMP вложения без учета ICMP и IP заголовков, таким образом получается, что сформированный IP-пакет равен 1500 байт. В этом легко убедиться, если посмотреть на дамп Wireshark:
Размер пакета, который был сгенерирован при пинге с опцией -s 1472 в Linux
Если указать размер 1473 байта, то пинга не будет:
user@debian:~$ ping 10.0.0.6 -M do -s 1473 -c 3
PING 10.0.0.6 (10.0.0.6) 1473(1501) bytes of data.
На скрине зеленым выделен размер кадра, красным IP-пакета. А теперь сделаем пинг с роутера в сторону Debian:
CSR#ping 10.0.0.2 size 1500 df-bit
Type escape sequence to abort.
Sending 5, 1500-byte ICMP Echos to 10.0.0.2, timeout is 2 seconds:
Packet sent with the DF bit set
!!!!!
Success rate is 100 percent (5/5), round-trip min/avg/max = 1/63/121 ms
CSR#ping 10.0.0.2 size 1501 df-bit
Type escape sequence to abort.
Sending 5, 1501-byte ICMP Echos to 10.0.0.2, timeout is 2 seconds:
Packet sent with the DF bit set
.....
Success rate is 0 percent (0/5)
CSR#
По результату пингов можно сделать вывод, что в IOS XE задается размер IP пакета при выполнении пинга. В Windows при пинге задается размер ICMP вложения без учета заголовков IP и ICMP:
Пинг в Windows с указанием размера payload ICMP и запретом на фрагментацию
Вывод из этого всего простой. Когда вы задаете размеры чего-то при пинге, всегда узнавайте, чего именно размер вы задаете.
Как изменить MTU на роутере Cisco?
Фактически способы изменения различных MTU на роутере мы рассмотрели, когда говорили про коммутаторы, т.к. для примера использовался multilayer switch. Но давайте все-таки кое-что посмотрим.
Для начала обратим внимание что максимальный канальный MTU на интерфейсе роутера может быть 9216 байт:
CSR#configure terminal
Enter configuration commands, one per line. End with CNTL/Z.
CSR(config)#int gi1
CSR(config-if)#mtu ?
<1500-9216> MTU size in bytes
CSR(config-if)#mtu
При этом сейчас канальный MTU равен 1500 байт, давайте посмотрим на возможные значение IP и MPLS MTU:
CSR(config-if)#ip mtu ?
<68-1500> MTU (bytes)
CSR(config-if)#mpls mtu ?
<64-1500> MTU (bytes)
Изменим L2 MTU, зададим максимальное значение:
CSR(config-if)#mtu 9216
CSR(config-if)#do sh int gi1 | in MTU
MTU 9216 bytes, BW 1000000 Kbit/sec, DLY 10 usec,
Значение изменилось, а теперь давайте посмотрим на значения, которые можно задать IP и MPLS MTU:
CSR(config-if)#ip mtu ?
<68-9216> MTU (bytes)
CSR(config-if)#mpls mt
<64-9216> MTU (bytes)
Их верхняя граница отодвинулась на значение 9216 байт, при этом у IP минимальный MTU может быть равен 68 байт, а у Ethernet и MPLS 64. Давайте теперь посмотрим на линк в сторону коммутатора, в самом начале я упоминал, что на этом линке используется 200 влан, со стороны роутера настроен саб-интерфейс с номером 200, который инкапсулирует кадры в 200 влан, конфигурация выглядит так:
CSR# sh run int gi2
Building configuration...
Current configuration : 96 bytes
!
interface GigabitEthernet2
description toHost_2_via_SW
no ip address
negotiation auto
end
CSR# sh run int gi2.200
Building configuration...
Current configuration : 100 bytes
!
interface GigabitEthernet2.200
encapsulation dot1Q 200
ip address 10.0.0.5 255.255.255.252
end
CSR#
Поясню по поводу саб-интерфейса Gi2.200: о том, что на кадры нужно ставить метку с номером 200, говорит строка encapsulation dot1Q 200, цифра 200 после Gi2 это номер саб-интерфейса, эта цифра не обязана совпадать с номером влана, но для удобства их обычно делают одинаковыми.
Саб-интерфейс и влан в данном случае я городил, чтобы посмотреть на связь между MTU физического интерфейса и MTU саб-интерфейса.
Посмотрим какие MTU сейчас на Gi2 и Gi2.200:
CSR#sh int gi2 | in MTU
MTU 1500 bytes, BW 1000000 Kbit/sec, DLY 10 usec,
CSR#sh int gi2.200 | in MTU
MTU 1500 bytes, BW 1000000 Kbit/sec, DLY 10 usec,
CSR#sh ip int gi2.200 | in MTU
MTU is 1500 bytes
CSR#
Посмотрим какой MTU можно задать саб-интерфейсу:
CSR(config)#int gi2.200
CSR(config-subif)#mtu ?
<1500-9216> MTU size in bytes
Выставим саб-интерфейсу L2 и L3 MTU равными 1600 байт:
CSR(config)#int gi2.200
CSR(config-subif)#mtu 1600
CSR(config-subif)#ip mtu ?
<68-1500> MTU (bytes)
CSR(config-subif)#ip mtu
Роутер съел команду mtu 1600, но при этом задать ip mtu 1600 возможности нет. Давайте посмотрим применился ли L2 MTU 1600 для саб-интерфейса:
CSR#sh int gi2.200 | in MTU
MTU 1500 bytes, BW 1000000 Kbit/sec, DLY 10 usec,
CSR#
А вот и не изменился. Выставим L2 MTU 1600 байт для Gi2:
CSR(config)#int gi2
CSR(config-if)#mtu 1600
CSR(config-if)#do sh int gi2 | in MTU
MTU 1600 bytes, BW 1000000 Kbit/sec, DLY 10 usec,
CSR(config-if)#
Выставили, он применился. Посмотрим MTU Gi2.200:
CSR(config-if)#do sh int gi2.200 | in MTU
MTU 1600 bytes, BW 1000000 Kbit/sec, DLY 10 usec,
CSR(config-if)#
Увеличим MTU Gi2 до 1700 байт и посмотрим канальный MTU Gi2.200:
CSR(config)#int gi2
CSR(config-if)#mtu 1700
CSR(config-if)#do sh int gi2.200
GigabitEthernet2.200 is up, line protocol is up
Hardware is CSR vNIC, address is 5000.0002.0001 (bia 5000.0002.0001)
Internet address is 10.0.0.5/30
MTU 1700 bytes, BW 1000000 Kbit/sec, DLY 10 usec,
Канальный MTU саб-интерфейса увеличивается вместе с канальным MTU основного интерфейса. L3 MTU теперь тоже можно сделать 1700 байт, но мы сделаем 1600 байт:
CSR(config)#int gi2.200
CSR(config-subif)#ip mtu ?
<68-1700> MTU (bytes)
CSR(config-subif)#ip mtu 1600
CSR(config-subif)#do sh run int gi2.200
Building configuration...
Current configuration : 113 bytes
!
interface GigabitEthernet2.200
encapsulation dot1Q 200
ip address 10.0.0.5 255.255.255.252
ip mtu 1600
end
CSR(config-subif)#do sh ip int gi2.200 | in MTU
MTU is 1600 bytes
CSR(config-subif)#do sh int gi2.200 | in MTU
MTU 1700 bytes, BW 1000000 Kbit/sec, DLY 10 usec,
CSR(config-subif)#
Какие выводы мы можем сделать из увиденного?
В IOS XE значение Ethernet MTU саб-интерфейса наследуется от основного интерфейса.
Сетевым MTU саб-интерфейса можно управлять, но он не может быть больше канального.
Плюс нужно не забывать, что это пример конкретного оборудования с конкретной операционной системой, и на каком-то ином оборудование поведение может быть другим, поэтому либо читайте документацию, либо тестируйте, а лучше и то и другое.
По факту в IOS XE на саб-интерфейсе можно менять IP MTU и MPLS MTU, канальный MTU наследуется, это подтверждает вывод sh run all:
CSR#sh run all | b GigabitEthernet2.200
interface GigabitEthernet2.200
...
encapsulation dot1Q 200
ip address 10.0.0.5 255.255.255.252
....
ip mtu 1600
...
mpls mtu 1700
.....
!
По результатам sh run all видим, что нет даже возможности задать канальный mtu на саб-интерфейсе, а вот конфигурация основной интерфейс.
CSR#sh run all | b GigabitEthernet2
interface GigabitEthernet2
description toHost_2_via_SW
...
mtu 1700
...
ip mtu 1700
...
mpls mtu 1700
...
!
Для дальнейшего рассмотрения я вернул MTU всех интерфейсов на 1500 байт.
Размер Ethernet заголовка и настройки MTU
В прошлом посте про MTU я говорил, что есть некоторые стандарты, которые увеличивают размер заголовка, самый очевидный и часто используемый в компьютерных сетях стандарт это 802.1q или VLAN, он добавляет к полю заголовка 4 байта, то есть эта добавка никак не должна влиять на способность оборудования пропустить кадр с MTU 1500, если на интерфейсах этого оборудования настроено 1500 байт.
Убедимся в этом, запустим пинг из Linux в Windows IP-пакетами размером 1500 байт и снимем дамп с двух линков:
На линке Host_1/CSR. Здесь кадр идет без поля 802.1q.
На линке CSR/SW, здесь кадры идут с меткой 200.
На линке коммутатор/Windows дамп снимать смысла нет, потому что коммутатор убирает метку, когда отдает кадр в сторону ПК. Пинг:
user@debian:~$ ping 10.0.0.6 -M do -s 1472
PING 10.0.0.6 (10.0.0.6) 1472(1500) bytes of data.
1480 bytes from 10.0.0.6: icmp_seq=1 ttl=127 time=56.6 ms
1480 bytes from 10.0.0.6: icmp_seq=2 ttl=127 time=1.19 ms
1480 bytes from 10.0.0.6: icmp_seq=3 ttl=127 time=1.46 ms
1480 bytes from 10.0.0.6: icmp_seq=4 ttl=127 time=1.57 ms
1480 bytes from 10.0.0.6: icmp_seq=5 ttl=127 time=1.79 ms
1480 bytes from 10.0.0.6: icmp_seq=6 ttl=127 time=1.88 ms
Дамп с линка между Линуксом и роутером:
Ethernet кадр без метки размером 1514 байт с вложением 1500 байт
Зеленым выделен размер кадра (Dst MAC + Src MAC + Type + Payload). Красным выделен размер пакета 1500 байт. Теперь кадр на линке между роутером и коммутатором:
Ethernet кадр с меткой размером 1518 байт с вложением 1500 байт
Размер кадра увеличен до 1518 байт за счет того, что к заголовку добавились поля 802.1Q, но IP-пакет по-прежнему 1500 байт, данный кадр прошел через линк с MTU 1500 байт и это правильное поведение оборудование, но если вы работаете с каким-нибудь noname китайским тестируйте такие моменты.
Как изменить MTU интерфейса в Windows 10?
Сразу скажу, что я не самый быстрый стрелок на этом диком западе в части специфичных сетевых настроек на Винде, но как поменять MTU я знаю, для начала давайте посмотрим какие интерфейсы есть и какой MTU на них задан. Вот этой командной можно посмотреть канальные интерфейсы и их MTU в Windows:
C:\Windows\system32>netsh interface ipv4 show subinterfaces
В левом столбце значение L2 MTU, вывод я такой делаю, потому что можно посмотреть расширенные настройки интерфейсов:
C:\Windows\system32>netsh interface ipv4 show interfaces level=verbose
Interface Loopback Pseudo-Interface 1 Parameters
----------------------------------------------
IfLuid : loopback_0
IfIndex : 1
State : connected
Metric : 75
Link MTU : 4294967295 bytes
Reachable Time : 30500 ms
Base Reachable Time : 30000 ms
Retransmission Interval : 1000 ms
DAD Transmits : 0
Site Prefix Length : 64
Site Id : 1
Forwarding : disabled
Advertising : disabled
Neighbor Discovery : disabled
Neighbor Unreachability Detection : disabled
Router Discovery : dhcp
Managed Address Configuration : enabled
Other Stateful Configuration : enabled
Weak Host Sends : disabled
Weak Host Receives : disabled
Use Automatic Metric : enabled
Ignore Default Routes : disabled
Advertised Router Lifetime : 1800 seconds
Advertise Default Route : disabled
Current Hop Limit : 0
Force ARPND Wake up patterns : disabled
Directed MAC Wake up patterns : disabled
ECN capability : application
Interface Ethernet Parameters
----------------------------------------------
IfLuid : ethernet_32768
IfIndex : 8
State : connected
Metric : 25
Link MTU : 1500 bytes
Reachable Time : 20000 ms
Base Reachable Time : 30000 ms
Retransmission Interval : 1000 ms
DAD Transmits : 3
Site Prefix Length : 64
Site Id : 1
Forwarding : disabled
Advertising : disabled
Neighbor Discovery : enabled
Neighbor Unreachability Detection : enabled
Router Discovery : dhcp
Managed Address Configuration : enabled
Other Stateful Configuration : enabled
Weak Host Sends : disabled
Weak Host Receives : disabled
Use Automatic Metric : enabled
Ignore Default Routes : disabled
Advertised Router Lifetime : 1800 seconds
Advertise Default Route : disabled
Current Hop Limit : 0
Force ARPND Wake up patterns : disabled
Directed MAC Wake up patterns : disabled
ECN capability : application
И тут написано Link MTU. Поменяем значение MTU интерфейсу со значением Ethernet на 1600 байт через командую строку. Изменения рекомендую вносить через командую строку, запущенную от имени администратора:
C:\Windows\system32>netsh interface ipv4 set subinterface "Ethernet" mtu=1600 store=persistent
Ok.
C:\Windows\system32>netsh interface ipv4 show subinterfaces
Слово "Ethernet" в команде для смены MTU это имя интерфейса, имена интерфейсов можно посмотреть командой ipconfig. В графическом интерфейсе можно изменить размер кадров, который должен уметь обрабатывать интерфейс, заходим в меню "Настройки параметров адаптера" и здесь жмем ПКМ на нужный интерфейс:
Перечень адаптеров в Windows 10
Выбираем пункт "Свойства"/"Properties".
Меню просмотра и настроек свойств выбранного интерфейса
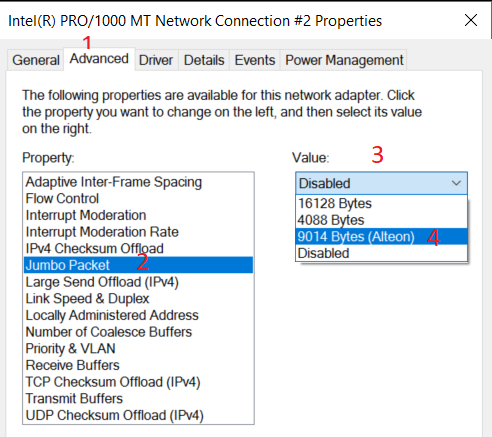
Жмем на кнопку "Configure..."/"Настроить...". А далее идем по цифрам:
Меню включения Jumbo Frame на сетевых интерфейсах в Windows 10
В русской версии Windows меню "Jumbo Packet" перевели как "Большой кадр". Значение 9014 байт это именно что размер кадра, потому что после того как будет выбрано 9014 байт, MTU интерфейса станет 9000 байт:
C:\Windows\system32>netsh interface ipv4 show subinterfaces
Когда вы включаете Jumbo кадры, интерфейс перезагружается.
Как изменить MTU в Linux?
Перейдем к Linux. Разберемся как проверять MTU на интерфейсах.
Прежде чем продолжить сделаю одно примечания. В посте о настройке лабы TTL я довольно подробно описал базовые сетевые настройки для Debian 10, плюс там же дал некоторые полезные ссыли, поэтому сейчас на этом вопросе подробно не останавливаюсь.
На конкретном интерфейсе MTU смотрим так:
user@debian:~$ ip link show dev ens3
2: ens3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP mode DEFAULT group default qlen 1000
Разберемся с тем, как сделать временные изменения MTU на интерфейсе, изменять будем на ens3, этот интерфейс включен в мою домашнюю сеть, а через нее в интернет, для проверки попинуем Гугл:
У интерфейса ens3 MTU будет 1400 байт до перезагрузки машины, после ребута он вновь станет 1500 байт. Разберемся как изменить MTU на постоянной основе, как и большая часть других настроек Linux, постоянные изменения применяются через изменение конфигурационных файлов. Открываем файл с сетевыми настройками любым удобным редактором:
sudo nano /etc/network/interfaces
Находим конфигурацию нужного нам интерфейса и добавляем в нее значение MTU нужного нам размера, в моем случае 1400 байт:
#to_CSR
allow-hotplug ens4
iface ens4 inet static
address 10.0.0.2/30
up ip route add 10.0.0.4/30 via 10.0.0.1
mtu 1400
Стоит учитывать что название и расположение файла с сетевыми настройками зависит от дистрибутива, с которым вы работаете. Давайте проверим изменился ли MTU:
user@debian:~$ ip link show dev ens4
3: ens4: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP mode DEFAULT group default qlen 1000
PING 10.0.0.1 (10.0.0.1) 1372(1400) bytes of data.
1380 bytes from 10.0.0.1: icmp_seq=1 ttl=255 time=60.9 ms
1380 bytes from 10.0.0.1: icmp_seq=2 ttl=255 time=0.641 ms
1380 bytes from 10.0.0.1: icmp_seq=3 ttl=255 time=0.591 ms
1380 bytes from 10.0.0.1: icmp_seq=4 ttl=255 time=0.595 ms
^C
--- 10.0.0.1 ping statistics ---
4 packets transmitted, 4 received, 0% packet loss, time 61ms
rtt min/avg/max/mdev = 0.591/15.670/60.856/26.088 ms
user@debian:~$
И не забывайте, что в Linux есть замечательная утилита grep, которая позволяет избежать просмотра портянок различного рода конфигураций и диагностических выводов:
user@debian:~$ ip a | grep mtu
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
2: ens3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1400 qdisc pfifo_fast state UP group default qlen 1000
3: ens4: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1400 qdisc pfifo_fast state UP group default qlen 1000
user@debian:~$
Ну и всё, спасибо, что дочитали!
Вопрос для вашего ответа
Почему роутер дает возможность установить минимальный MTU для IP 68 байт, а для MPLS и Ethernet 64 байта? В чем логика, если IP это вложение в Ethernet и тот же IP может быть закрыт MPLS заголовком?
Видео версия
Видео версия для тех, кому проще посмотреть и послушать, чем почитать.
Ниже поговорим о допустимых размерах Ethernet кадров и IP-пакетов, этот пост по факту небольшое отступление от протокола IP, поскольку речь будет в основном про Ethernet, но это отступление, на мой взгляд, необходимо в связи с тем, что далее запланирован пост про фрагментацию пакетов в IP, а там бы не хотелось отвлекаться на размеры пакетов и ограничения с этим связанные.
Что такое MTU и PDU?
Читая или смотря что-то о компьютерных сетях, вы часто можете встретить две аббревиатуры: PDU и MTU. Первая расшифровывается как Protocol Data Unit, проще говоря PDU это обобщенное название фрагмента данных, которым обмениваются устройства по тому или иному протоколу. Например, IP устройства обмениваются пакетами, значит PDU в IP это пакет, у Ethernet это будет кадр или фрейм, а PDU в UDP это дейтаграмма.
MTU расшифровывается как Maximum Transmission Unit или максимальная единица передачи, проще говоря, это максимальный размер пользовательских(полезных) данных, которые можно передать внутри одного PDU тем или иным протоколом без фрагментации. Стоит пояснить, что понимается под полезными данными. Для Ethernet полезными данными может выступать IP-пакет, для IP-пакета полезными данными может быть ICMP сообщение, TCP сегмент или UDP дейтаграмма.
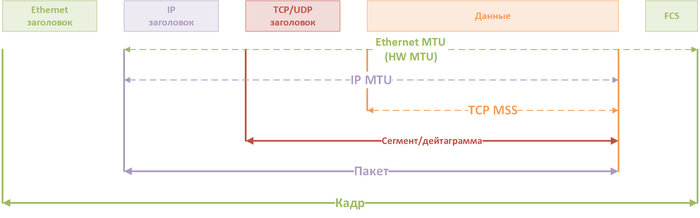
Обычно, когда говорят об MTU, имеют ввиду MTU канального уровня, его еще называют Hardware MTU, но про MTU можно говорить в принципе на любом уровня, начиная с транспортного и ниже. Вот так будет выглядеть MTU протоколов разных уровней, если мы исходим из определения, что MTU это полезные данные, переносимые внутри PDU:
Примеры PDU и MTU(MTU IP-пакет на рисунке показан неверно, ниже пояснение)
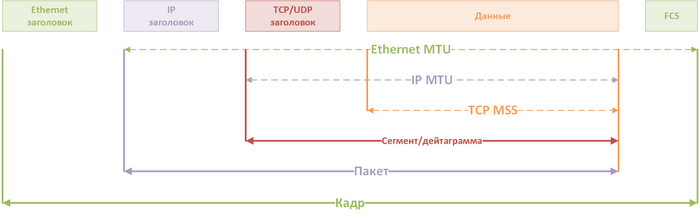
Но на самом деле в IP определение MTU отличается от Ethernet или TCP. Для IP MTU это пользовательские данные плюс заголовок пакета, поэтому картинка должна быть такой:
Верный пример PDU и MTU
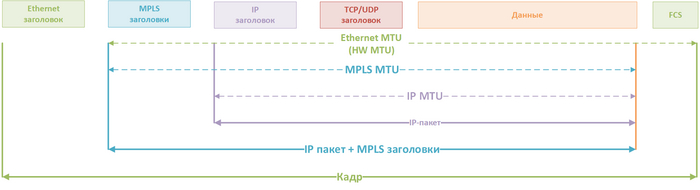
Но тогда непонятно: в чем разница между канальным и сетевым MTU? Разница будет видна при различного рода туннелях, мне ближе всего MPLS, поэтому вот пример MTU с MPLS:
Пример PDU/MTU с MPLS заголовками
Здесь мы видим, что MPLS заголовки включаются в MTU кадра, но не являются MTU пакета, для MPLS на оборудование можно задавать свой собственный MTU, но это отдельная история. Понятно, что чем больше в PDU выделено места для пользовательских данных по сравнению со служебными, тем для получателя услуги скорость будет выше. Вот здесь есть краткий обзор того, как различные размеры кадров и их MTU влияют на скорость для конечных хостов (правда не на нашем языке).
Примечание
Из выше описанного понятно, что MTU на канальном уровне не включает в себя байты, выделенные под Ethernet заголовок, но есть исключения. Например, оборудование Cisco под управлением ОС IOS XR считает канальный MTU не как размер полезной нагрузки в Ethernet кадре, а как размер полезной нагрузки + Ethernet заголовок. С этим нужно быть внимательным, особенно когда настраиваются протоколы, для которых MTU имеет значение, например, OSPF.
Максимальный размер MTU
Вопрос не такой однозначный и простой. Будем исходить из того, что MTU не может быть бесконечным, на это есть много причин, вот некоторые из них:
Некоторые алгоритмы, которые используются для расчета контрольных сумм, при больших размерах пакетов могут давать сбой.
Когда-то раньше, когда в Ethernet сетях были топологии с общей шиной, а сети строились на хабах и повторителях, большие кадры и пакеты были невыгодны, поскольку в таких сетях пока один из участников канальной среды вел передачу, все остальные его слушали и молчали.
Размер буфера портов у транзитных узлов не бесконечен, чем больше пакет, тем больше места он будет занимать в буфере, а слишком большие буферы делать нерационально, поскольку долго хранящийся в буфере пакет может стать не актуальным для получателя.
Потеря маленького пакета не так критична, как большого, вероятность получить искажение большого пакета выше, чем маленького.
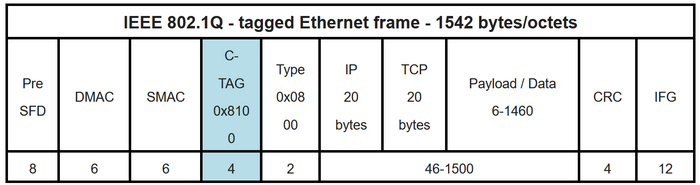
Семейство Ethernet, а также фичи и костыли, которые к Ethernet приделываются, как правило, описываются стандартами IEEE. Самый базовый стандарт Ethernet это IEEE 802.3, он дает следующие верхнее ограничение на размер Ethernet кадра в целом и его MTU в частности:
Размер кадра не должен превышать 1518 байт.
MTU кадра должен быть 1500 байт.
В большинстве случаев можно быть уверенным в том, что кадры с полезной нагрузкой в 1500 байт пролезут через любую сеть.
Примечание
Большинство документов, описывающих IP это RFC (request for comment), изначально идея RFC была в том, что кто-то придумал какую-то фичу или метод, описал как ее реализовать и этот кто-то направляет своим коллегам запрос на комментарии к тому, что он придумал. Сейчас RFC можно считать рекомендациями к реализации той или иной фичи. Ethernet же описывается стандартами, полагаю, разница между словом рекомендация и стандарт особых пояснений не требует.
Минимальный размер MTU
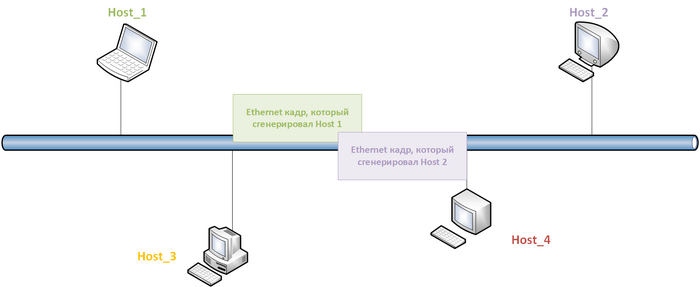
Теперь поговорим о нижем ограничение для MTU. Если коротко, то оно есть и, как правило, это ограничение описывается стандартом протокола. Связаны такие ограничения с физикой нашего мира: дело в том, что сетевые устройства обмениваются физическими сигналами, которые генерируются и распространяются по среде передачи данных не мгновенно(хоть и на скоростях близких к скорости света в вакууме), если говорить про Ethernet, то здесь минимальный размер кадра связан с доменом коллизий (участком сети, где два кадра могут столкнуться друг с другом). Дело в том, что размер кадра должен быть настолько большим, чтобы отправителю кадра в случае возникновения коллизии хватило времени на детектирования коллизии.
Пример коллизий в сетях с Ethernet с общей шиной
Если хотите деталей, то поищите информацию про CSMA/CD. На современном оборудование метод CSMA/CD реализован, но зачастую не используется, в виду того, что домен коллизий ограничен линком между двумя конкретными устройствами, а на линке, как правило, работает full duplex (если вы переводите линк в half, то вопрос обнаружения коллизий на этом линке снова становится актуальным), т.е. для приема своя физика, а для передачи своя, что исключает возможности появления коллизий.
Для Ethernet есть множество стандартов, которые описывают различные физические реализации этого самого Ethernet, у разных стандартов может быть свой минимальный размер кадра, а может быть и так, что стандарты разные, но размер кадра одинаковый.
Для стандартов Ethernet со скоростями 10Mbps и 100Mbps минимальный размер кадра равен 64 байта, для стандартов Ethernet со скоростью 1000Mbps по меди(1000BASE-T) минимальный размер кадра увеличен до 512 байт, а если не ошибаюсь, то для стандарта 1000BASE-X(оптика) минимальный размер кадра 416 байт.
Насколько мне известно, стандарты, описывающие реализацию Ethernet на скоростях 2.5Gbps и выше, не предусматривают возможность работы в режиме half duplex, а это означает, что ограничений, которые накладывал CSMA/CD на размер кадра в этих стандартах нет. Сам не тестировал, но встречал упоминания о том, что для Ethernet кадров из стандартов для скоростей выше 1Gbps наследуется минимальный размер кадра в 512 байт.
Если говорить про связку IP+Ethernet, то здесь минимальные MTU для IP такие:
Для IPv4 минимальный MTU не может быть меньше 68 байт. Иногда можно найти информацию о том, что для IPv4 минимальный MTU равен 576 байт, но это не так, на самом деле 576 байт это гарантированный размер IP-пакета, который должен смочь обработать получатель, то есть хост в IP должен уметь обрабатывать пакеты размером 576 байт, а вот пакеты больших размеров он уже не должен уметь обрабатывать.
Для IPv6 минимальный MTU не может быть меньше 1280 байт.
Почему я не писал явные размеры минимальных MTU станет понятно ниже, когда речь пойдет про размеры Ethernet заголовка.
Размер Ethernet заголовка
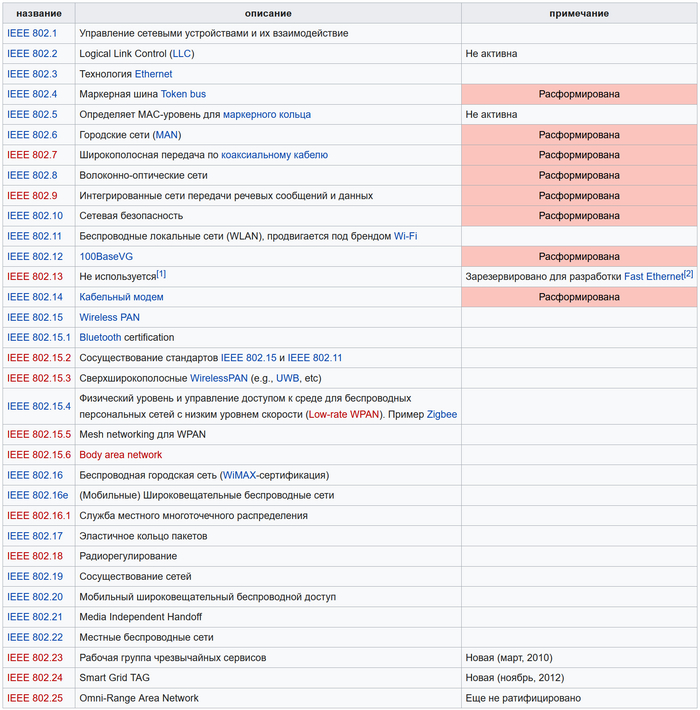
Есть группа стандартов под номером IEEE 802, эта группа описывает сети LAN(local area network) и MAN(metropolitan area network). В этой группе есть подгруппа 802.3, в которой собрано всякое разное про Ethernet, плюс есть подгруппа 802.1, которая тоже будет нам интересна в контексте обсуждения Ethernet заголовка.
Группа стандартов IEEE 802
Таблица выше была взята с википедии. Группы 802.3 и 802.1 включают в себя некоторые стандарты, которые увеличивают размер Ethernet кадра за счет добавления или расширения служебных полей, это означает, что зачастую для того, чтобы пропускать такие кадры, оборудование должно поддерживать этот стандарт, эти стандарты как правило не требуют увеличения MTU на линках, но лучше заглянуть в документацию оборудования. Вот примеры таких стандартов.
IEEE 802.1q, 802.1p, 802.3ac
Первым делом стоит сказать про 802.1q, он описывает технологию VLAN, которая реализуется за счет добавления нового поля в заголовок кадра, и есть 802.1p, который описывает методы приоретизации трафика. Стандарт 802.3ac предписывает увеличение Ethernet-кадра на 4 байта, в этих четырех байтах как раз и содержится информация о влане и важности кадра.
Структура Ethernet кадра IEEE 802.1Q
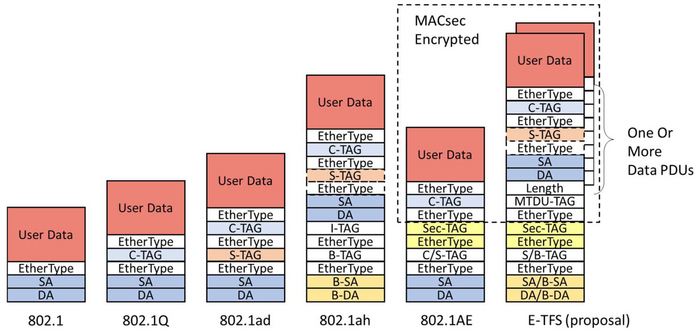
IEEE 802.1ad
Стандарт 802.1ad известен больше как QinQ, он расширяет размер кадра как минимум до 1526 байт, этот стандарт позволяет добавлять в кадр две или более метки VLAN, при этом у каждой может быть свой приоритет. Метки и приоритеты как раз описаны в 802.1q и 802.1p. Как правило используют два влана, хотя, наверное, вы можете встретить сценарии с тремя и более тегами.
Структура Ethernet кадра IEEE 802.1AD
IEEE 802.1ah
Стандарт 802.1ah более известный как PBB или MACinMAC.
Структура Ethernet кадра IEEE 802.1AH
IEEE 802.1ae
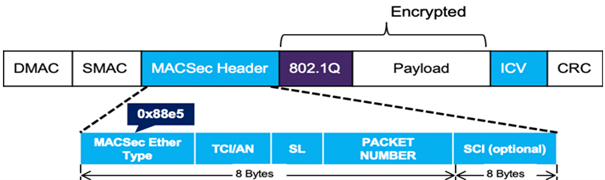
Стандарт 802.1ae (технология MAC Security) позволяет генерировать кадры размером 1550 байт, 16 байт выделяется под заголовок MAC Security и 16 байт под поле ICV(контрольная сумма).
Структура Ethernet кадра IEEE 802.1AE
Хороший обзор Ethernet кадров различных стандартов и с различными доп. полями можно почитать здесь. Картинки выше взяты оттуда. А вот сравнение размеров различных Ethernet заголовков:
Сравнение размеров Ethernet кадров различных стандартов
Изображение было взято отсюда. На самом деле размер кадра может больше, чем я описывал ранее. Кадры больше стандартных имеют даже свои названия, например, Baby Giant или Jumbo Frame, названия не официальные.
Baby Giant обычно называются кадры размером от 1519 до 1600 байт. Джамба фреймами обычно называются кадры больше 1518 байт. Не всё оборудование умеет работать с jumbo кадрами, как правило их поддержку нужно включить. Стандартов по обработке jumbo фреймов никаких нет, всё на совести вендора.
Теоретический максимально возможный размер Jumbo Frame ограничивает поле FCS и алгоритм CRC32(Cyclic Redundancy Check), который используется для проверки целостности данных в Ethernet, из-за этих ограничений размер не может превышать11455 байт. Если говорить о реальных реализациях, то современные роутеры позволяют задать канальный MTU немногим более 9000 байт.
И в завершении стоит сказать про стандарт 802.3as. Проблема Ethernet в том, что на ранних стадиях он развивался реактивно: возникала потребность в какой-то фичи, и под эту потребность придумывался новый заголовок, в котором вводились новые поля и этот новый заголовок был больше исходного. В итоге такое развитие привело к созданию стандарта 802.3as, он увеличивает размер кадра до 2000 байт, грубо говоря и не вдаваясь в детали, этот стандарт говорит о том, что кадр размером 2000 байт и MTU не более 1500 байт должен быть обработан любым Ethernet интерфейсом.
Вопросов к данному посту нет, поскольку информация здесь больше справочная, чем на понимание логики работы.
Ниже поговорим о контрольной сумме в IP и посмотрим на то, как узлы вычисляют ее. Напомню, что IP не контролирует целостность пользовательских данных, контрольная сумма считается только для заголовка. Поскольку на каждом транзитном узле заголовок пакета изменяется, каждый узел пересчитывает контрольную сумму с учетом внесенных изменений при отправке пакета дальше.
Плюс нужно не забывать: контрольная сумма является одним из полей заголовка, но для расчета контрольной суммы узел обнуляет значение этого поля.
Алгоритм расчета контрольной суммы в IP-заголовке
Сразу хочу обратить внимание, что ниже упрощенная интерпретация алгоритма по расчету контрольной суммы, если вам нужны строгие определения или же примеры реализации на различных языках программирования, вам нужно почитать RFC 1071.
Заголовок разбивается на слова по 16 бит слева направо.
Поле контрольной суммы само равно 16 бит, узел, получивший пакет, для расчета контрольной суммы не должен учитывать значение поля контрольная сумма.
Таким образом если у заголовка нет опций, а само поле контрольной суммы мы отбрасываем, то получается 9 слов по шестнадцать бит, в общем виде одно слово будем обзывать буквой W, таким образом у нас есть слова от W0 до W8.
Чтобы узнать контрольную сумму мы должны сперва сложить все слова: Wsum = W0+W1+W2+W3+W4+W5+W6+W7+W8. Правило о том, что от перестановки мест слагаемых сумма не меняется здесь тоже работает.
Если Wsum получилась размером больше, чем 16 бит, получившееся число разбивается на два слова по 16 бит, которые затем складываются между собой(и так нужно будет повторять до тех пор, пока не получим число 16 бит).
И наконец нужно выполнить операцию "исключающего ИЛИ" между шестнадцатеричным числом FFFF и получившимся Wsum. Это и будет контрольная сумма.
Если честно мне никогда не был понятен алгоритм, описанный словами. Поэтому ниже пример.
Рассчитываем контрольную сумму на калькуляторе
Чтобы проверить свои расчет, проще всего сделать дамп пакета, в котором контрольная сумма уже посчитана.
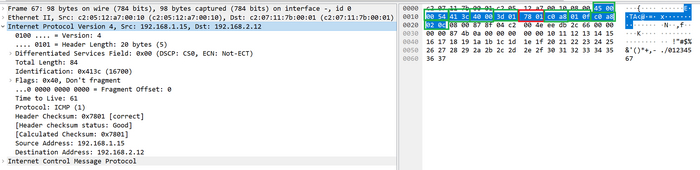
Дамп IP-пакета для расчета контрольной суммы
Слева в Wireshark мы видим представление пакетов удобное нам, человекам, а справа мы видим байтовой представление пакетов, где каждый байт представлен числом в шестнадцатеричной системе счисления, минимальное значение одного байта 00(ноль в десятичной), максимальное его значение FF(255 в десятичной), но для расчета нас интересуют слова по два байта.
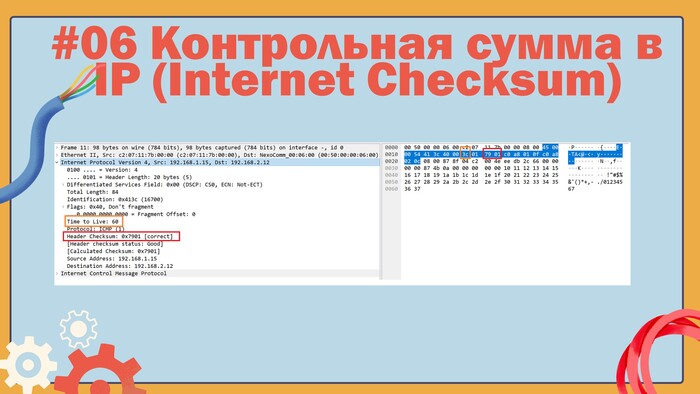
Если слева нажать на строку Internet Protocol Version 4..., то справа нам подсветятся байты, соответствующие IP-заголовку. Байты я разбил на слова зелеными рамками, красная рамка это поле контрольная сумма и его мы отбросим.
Не забудьте переключить калькулятор в режим HEX, чтобы выполнять вычисления в шестнадцатеричном формате:
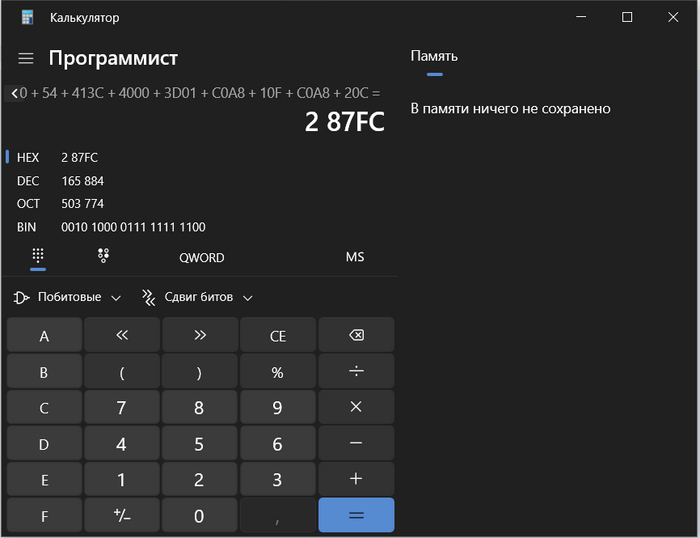
Складываем слова IP-заголовка
Число 287FC в шестнадцатеричной системе счисления занимает места больше, чем 16 бит, а значит надо разбить его на два числа по 16 бит и сложить их, делается это так:
Wsum = 0002 + 87FC = 87FE
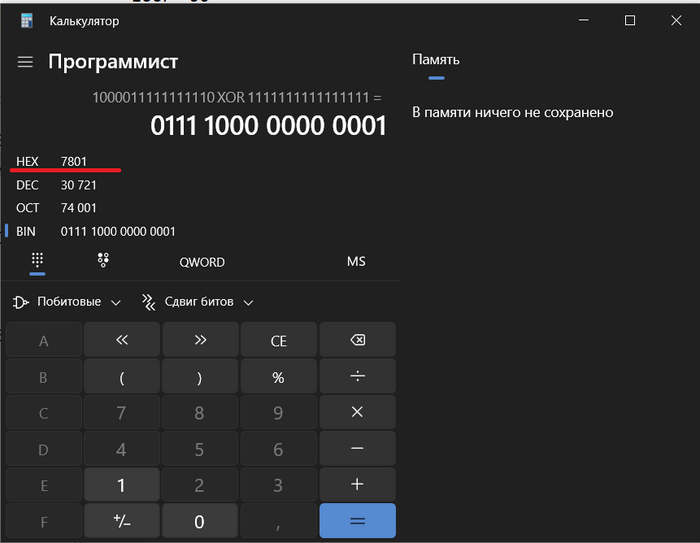
Чтобы записать шестнадцатеричное число 87FE в двоичном виде шестнадцати бит хватит, а значит нам надо сделать FFFF XOR 87FE, здесь XOR это ИСКЛЮЧАЮЩЕЕ ИЛИ, подробнее про операцию можете почитать на вики, мы же сейчас возьмем калькулятор, переведем своё число в двоичный вид и сделаем XOR с двоичным числом 1111111111111111 (в HEX на калькуляторе можно сделать то же самое).
Выполняем операцию исключающее ИЛИ
В результате получилась та же контрольная сумма, что и насчитал роутер (7801 в шестнадцатеричном виде):
Контрольная сумма IP-заголовка посчитана
В общем, ничего сложного нет.
Для самостоятельного расчета
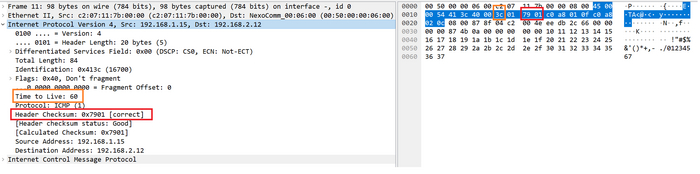
Теперь посмотрим на этот же пакет в дампе, который был сделан на следующем узле по пути его следования, это означает, что у него должен уменьшился TTL на 1 и должна пересчитаться контрольная сумма.
Дамп пакета на следующем узле
Оранжевым выделено поле TTL, его значение изменилось(3c в шестнадцатеричной это 60 в десятичной), красным выделена контрольная сумма, у нее изменился первый байт, все остальные байты заголовка без изменений. Для закрепления алгоритма попробуйте самостоятельно рассчитать контрольную сумму этого заголовка.
C мая 24 года на роутер стал выдаваться "серый" IP адрес из диапазона 100.64.0.0/8
Техподдержка отговаривается и разбирается в проблеме. Заявляли что дело в роутере(который не мтс). В последний раз заявили что без услуги "статический адрес" "белый" IP вообще не положен, хотя на сайте черным по белому написано: "При подключении выдается внешний динамический IP-адрес, который Вам выделит наш сервер при подключении."
Кто-нибудь сталкивался с подобной проблемой на проводном интернете от МТС? Какие IP выдаются у вас без подключения спец. услуги?
Сижу на Йопте вынужденно уже несколько лет, и если честно подзадолбало качество соединения. Доказать не могу, но нутром чую, что есть некоторый процент соединений, которые оператор тупо сбрасывает. То есть скорость обещанная вроде держится, а вот СТАБИЛЬНОСТИ нет. Сайт то грузится за пару секунд, то долго и тщетно пытается прогрузить свои части. То же самое с играми. Сыну критически необходим Роблокс, а связь в игре редко держится более нескольких минут.
То же самое с софтом облачным. Простейшее сохранение файла может пройти как за секунду, так и занять вечность и повиснуть (ну тут конечно частично вопрос и к производителям такого софта). Загрузка файлов и даже торренты работают весьма неплохо.
Что посоветуете для диагностики сети? Чтобы потом было хоть какое то основание начать беседу с провайдером?
Предыдущая публикация была о TTL и в ней для демонстрации работы я использовал небольшую лабу, собранную в EVE-NG, этот пост для тех, кто хочет самостоятельно собрать такую же лабу и немного поэксперементировать. Ниже мы разберемся с некоторыми особенностями настроек роутеров и хостов лабы TTL.
Чего не будет в посте
Здесь не будет гайда о том, как установить виртуалку и поднять на ней EVE-NG, т.к. таких гайдов много, плюс есть официальная документация.
Вот на этом ютуб канале есть много гайдов на русском языке по EVE.
Вот раздел документации на официальном сайте. Если вы планируете использовать версию EVE-NG для бедных, то рекомендую начать с раздела Community Cookbook, в интернете есть где-то даже машинный перевод этой документации.
В лабе используются хосты, поднятые на образах Debian 10, но гайдов по работе с Linux здесь тоже не будет, я лишь опишу действия, которые делал, чтобы поднять лабу. Если хотите разобраться со всеми этими линуксами, то рекомендую посты пользователя @doatta. Есть еще два хороших канала на Ютубе: Кирилла Семаева и UNИX, у второго есть еще свой сайт.
В лабе протоколом маршрутизации выбран OSPF, сейчас я лишь покажу как его настроить, чтобы заработало, но детальных пояснений не будет, возможно, когда-нибудь я доберусь до OSPF.
Настройка роутеров
В целом, в настройках роутеров ничего сложно нет, вот основные моменты:
Каждому роутеру был задан Loopback адрес с маской /32, каждый октет адреса равен номеру роутера, сделано это было просто для удобства, например, для R3 это 3.3.3.3/32.
На интерфейсах роутеров были назначены р2р сети, принцип назначения объяснялся в посте про TTL.
Маршрутизация использовалась динамическая, протокол OSPF.
Петля делалась за счет статического маршрута на R4.
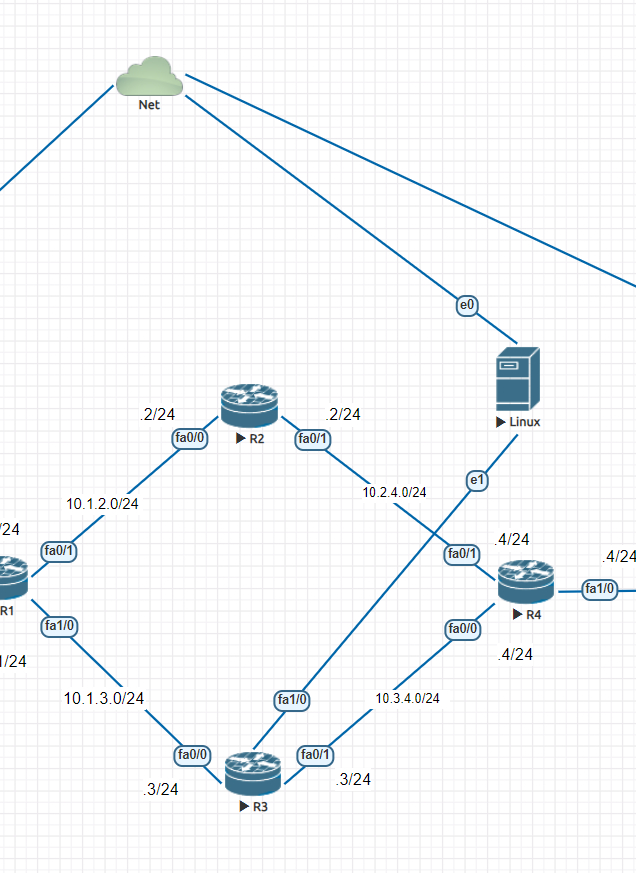
Но, наверное, мне нужно было бы начать с напоминания топологии:
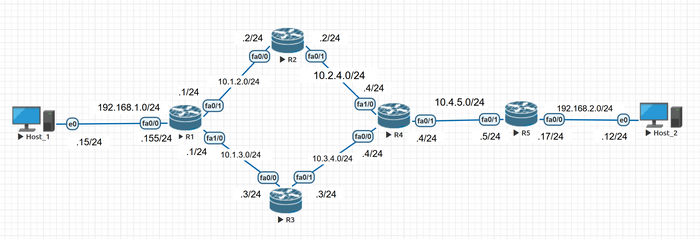
Топология сети, которую будем настраивать
IP настройки на интерфейсах
Вот так настраиваются Loopback интерфейсы на роутерах (на примере R5, фактически для этой лабы Lo адреса и не нужны):
R5#conf t
R5(config)#interface lo0
R5(config-if)#description system
R5(config-if)#ip address 5.5.5.5 255.255.255.255
На других роутерах меняется только IP-адрес. IP настройки на интерфейсах роутеров Cisco подробно рассматривались здесь. Но, если что, вот пример настроек на физических интерфейсах R5:
interface FastEthernet0/0
description to_Host_2
ip address 192.168.2.17 255.255.255.0
speed auto
full-duplex
interface FastEthernet0/1
description to_R4
ip address 10.4.5.5 255.255.255.0
speed auto
full-duplex
Настройки OSPF
Детально про настройку OSPF говорить не буду. Но его конфиг я покажу, вот так он выглядит на R5:
R5#conf t
R5(config)#router ospf 100
R5(config-router)#network 5.5.5.5 0.0.0.0 area 0
R5(config-router)#network 10.0.0.0 0.255.255.255 area 0
R5(config-router)#network 192.168.2.0 0.0.0.255 area 0
На R1 строку network 192.168.2.0 0.0.0.255 area 0 нужно будет заменить на network 192.168.1.0 0.0.0.255 area 0. На других роутерах третья команда network не нужна.
Краткое пояснение по командам OSPF
Командной router ospf 100 мы запускаем процесс OSPF на роутере и даем ему номер 100, как понимаете, на роутере может работать несколько разных процессов OSPF, при этом на двух соседних роутерах номера их OSPF процессов могут не совпадать, но обычно их делают одинаковыми для удобства.
Команда network довольно интересная, первое число, похожее на IP-адрес, это номер сети, второе число, похожее на маску сети, на самом деле wildcard mask, на русский язык ее переводят как обратная маска или инверсная маска, но сути ее работы это название не отражает. Когда-нибудь я про не напишу, сейчас отправлю в Яндекс или Гугл.
Можно сказать, что команда network это правило для маршрутизатора, роутер перебирает свои IP-интерфейсы и проверяет: попадают ли они под правило, заданные командой network или нет. Если интерфейс попадает под правило, то на нем включается OSPF процесс, интерфейс включается в регион, который указан после ключевого слова area, а информация о сети, которая настроена на этом интерфейсе, будет рассказана другим маршрутизаторам, с которыми установлено OSPF соседство.
Примечание:
Такая конфигурация OSPF подходит для лабы, но не подходит для реальных сетей. Как минимум, потому, что считается небезопасной, дело в том, что командой network 192.168.2.0 0.0.0.255 area 0 мы включаем OSPF на интерфейсе fa0/0, и роутер будет пытаться найти OSPF соседей за портом fa0/0. Fa0/0 это порт в сторону клиента, за которым на самом деле может оказаться злоумышленник.
Выход из такой ситуации у Cisco называется passive-interface, у Huawei такая же фича называется silent-interface. Вообще, хорошим тоном с точки зрения безопасности сети, является включение OSPF руками на тех сетевых линках, где он вам действительно нужен, а сети с клиентских интерфейсов, если это действительно требуется, вкидывать процессу OSPF через механизм редистрибьюции маршрутов.
Под правило network 5.5.5.5 0.0.0.0 area 0 попадает интерфейс Lo0, на нем включается OSPF процесс, сам интерфейс включается в нулевой регион, его адрес относится к сети 5.5.5.5/32, R5 начинает рассказывать всем своим OSPF соседям о том, что у него есть такая сеть.
Посмотреть OSPF интерфейсы на роутере можно так:
R5#show ip ospf int br
Interface PID Area IP Address/Mask Cost State Nbrs F/C
Fa0/0 100 0 192.168.2.17/24 10 DR 0/0
Fa0/1 100 0 10.4.5.5/24 10 DR 1/1
Lo0 100 0 5.5.5.5/32 1 LOOP 0/0
Если нужна какая-то более детальная информация по интерфейсу:
R5#show ip ospf int fa0/1
FastEthernet0/1 is up, line protocol is up
Internet Address 10.4.5.5/24, Area 0
Process ID 100, Router ID 5.5.5.5, Network Type BROADCAST, Cost: 10
Adjacent with neighbor 4.4.4.4 (Backup Designated Router)
Suppress hello for 0 neighbor(s)
Для создания петли маршрутизации на роутере R4 прописывался вот такой статический маршрут:
R4#sh run | in ip ro
ip route 192.168.2.12 255.255.255.255 10.3.4.3
R4#
На статиках сейчас останавливаться не буду, скоро будет отдельный пост.
Настройка и подготовка хостов
Теперь о подготовке и настройке хостов. Я не сисадмин Linux, поэтому, возможно, действия, описанные ниже, можно сделать более оптимально и просто, но тут уж как смог.
Для начала разберемся, где взять образы дистрибутивов Linux для EVE-NG, во-первых, на официальном сайте, там же есть гайд: текст + видео. На Ютуб канале, который был обозначен в начале поста есть видео о том, как подготовить свой дистрибутив для эмуляции в EVE-NG.
Настройки EVE-NG для хостов
Теперь о некоторых настройках в EVE-NG, которые я использовал для хостов. При первом запуске образа Linux в EVE-NG для подключения к хосту придется использовать VNC. Мне через VNC с отдельными окнами для каждого хоста работать было неудобно, поэтому я решил проблему так: на эмулируемом образе создал два порта, один из которых был подключен в лабу, второй был подключен в мою домашнюю сеть. На порт, который смотрит в домашнюю сеть, IP-адрес прилетает по DHCP от домашнего роутера, по этому адресу я и подключался к машине в дальнейшем.
Вот первичные настройки виртуальной машины в EVE:
Первичные настройки в EVE-NG для хостов
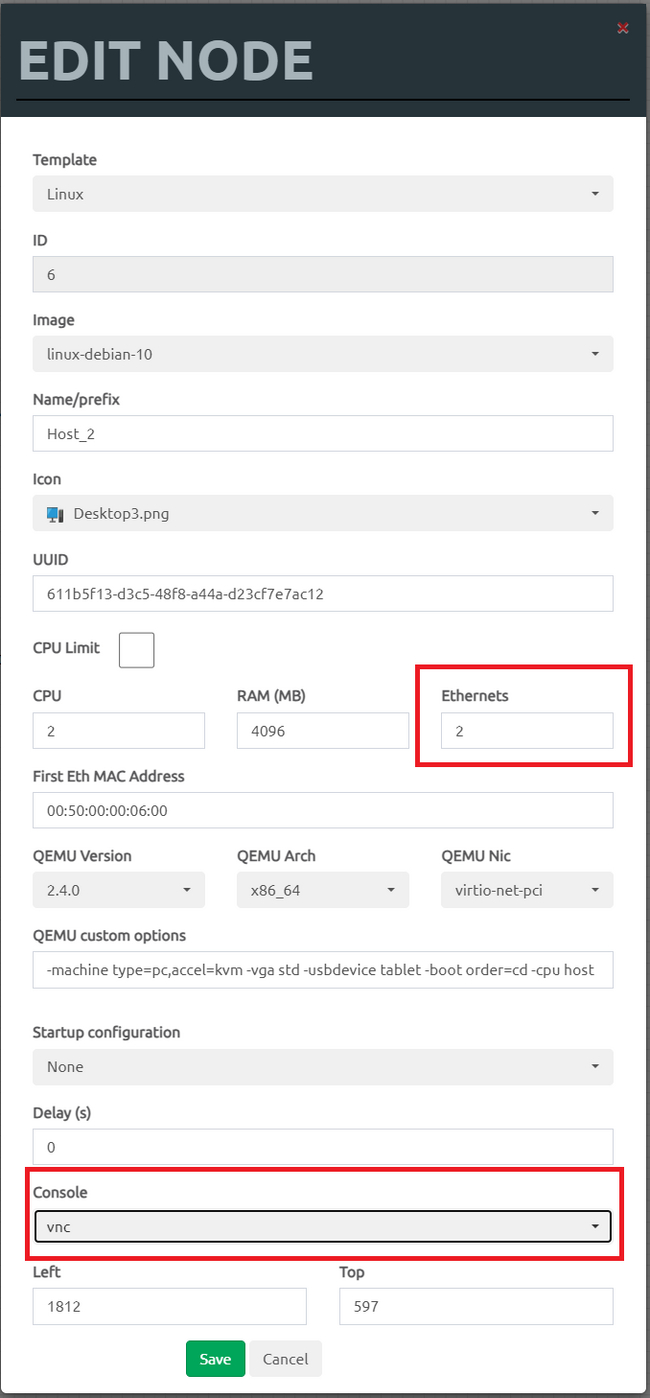
Чтобы эмулируемые в лабе устройства могли получать адреса от физического роутера, в сетевых настройках VMWare для виртуалки EVE-NG должен быть включен bridge. Настройка производится вот здесь, вот так:
Нужно поставить чекрыжик на Bridged... и галку на Replicate physical...
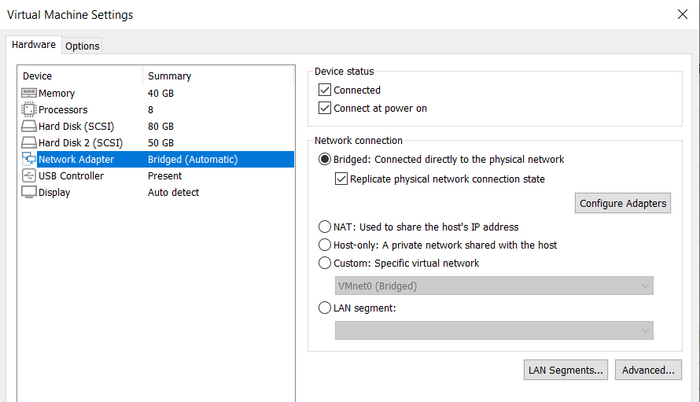
На топологию лабы нужно добавить интерфейс/устройство, через которое виртуальные хосты, могли бы подключаться к реальной физической сети, надо сделать так: по рабочей области жмем ПКМ, в меню выбираем Network, в появившемся окне в списке Type выбираем как на скрине ниже.
Добавляем устройство для организации связности между виртуальной сетью и физической
Образ Linux одним линком нужно будет подключить к появившемуся облаку, это облако свяжет его с физической сетью.
На официальном сайте EVE образ Debian идут с графическим интерфейсом, но все примеры настроек сделаны в эмуляторе терминала, во-первых, это быстрее, во-вторых, я не знаю как делать сетевые настройки в Linux через графику.
Если вы скачали образ Debian с официального сайта EVE (а я так и сделал), то там уже будет создан пользователь с логином user и паролем Test123.
Настройка sudo на хостах
Мне удобнее работать через sudo, в Debian sudo нужно включить, вот перечень команд для этого:
su
#ввести пароль Test123
apt install sudo
exit
Установка sudo в Debian 10
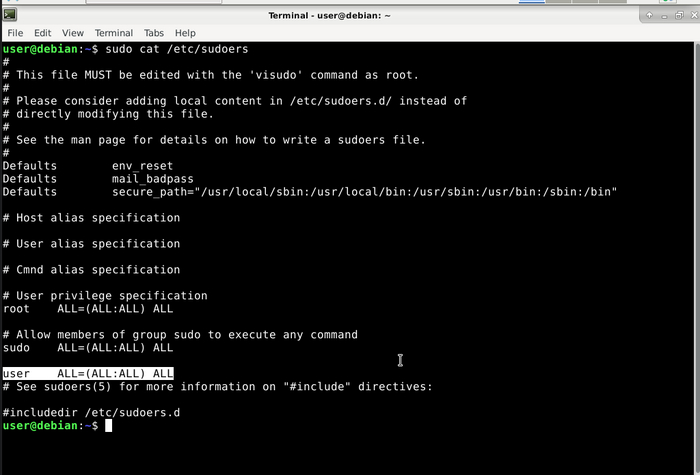
Для пользователя с логином user правка файла /etc/sudoers не требуется, но если хотите создать нового пользователя и работать из-под него, то не забудьте отредактировать файл sudoers, добавив запись аналогичную той, что сделана для user.
Содержимое файла sudoers
Сетевые настройки хостов
Теперь к сетевым настройкам на хостах. Командой ip a смотрим сетевые интерфейсы, которые сейчас есть.
Список IP-интерфейсов
Интерфейс ens3 соответствует интерфейсу e0 на топологии EVE-NG, интерфейс ens4 это e1, этот мануал я пишу уже после того, как собрал изначальную схему и записал видео, т.е. ниже буду рассказать как добавить третий образ на схему (для исходных двух хостов отличаться будут только настраиваемые IP-адреса и прописываемые статики), физически я его подключил так:
Настраиваем узел с именем Linux
Перед тем как продолжать докладываю, этих ваших команд в Linux вагон и маленькая тележка, список команд можно увеличивать за счет установки новых программ и утилит, но базовые команды по работе с сетью и интерфейсами можно найти в этой шпаргалке на сайте Red Hat.
Я хочу чтобы на ens3 мне приходили настройки из моей реальной сети по DHCP, давайте это организуем, пишем команду:
sudo nano /etc/network/interfaces
В данном файле можно делать различные сетевые настройки, VIM не использую, потому что не хочу писать гайд о том, как из него выйти. В этом файле пишем настройки для интерфейса ens3, пишем их так:
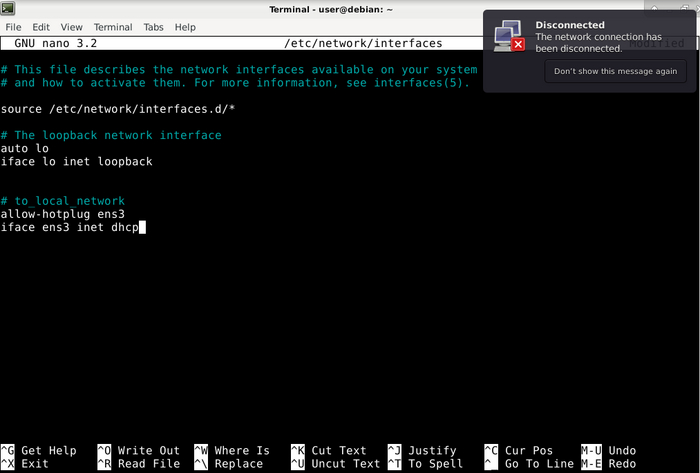
# to_local_network
allow-hotplug ens3
iface ens3 inet dhcp
Строка с решеткой это просто комментарий, вторая строка говорит том, что ens3 надо включать сразу как включится образ, третья строка заставляет машину начинать слать DHCP запросы через ens3, чтобы получить свои сетевые настройки. В файле это выглядит так:
Настройка получения IP-адресов по DHCP в Debian 10
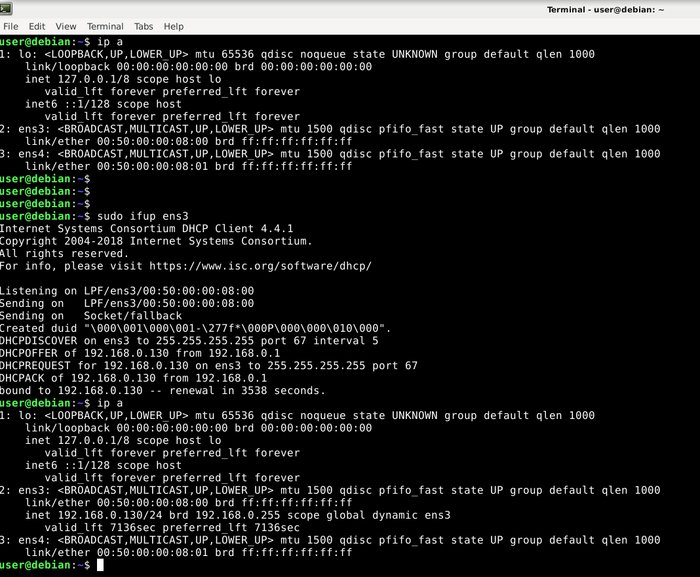
Далее нажимаем Ctrl+O чтобы сохранить, Ctrl+X закрыть файл. Если вы после редактирования напишите ip a, то увидите, что сетевые настройки на ens3 по DHCP не прилетают, на самом деле они и не запрашиваются, значит нужно передернуть, передергивать интерфейс будем такой командой:
sudo ifup ens3
Смотрим настройки сетевых интерфейсов после передергивания
После этого мы видим, что адрес был выдан и это 192.168.0.130. Всё, по этому адресу мы можем подключаться при помощи SSH клиента, который установлен на основной операционной системе, плюс образ Linux теперь имеет доступ к интернету.
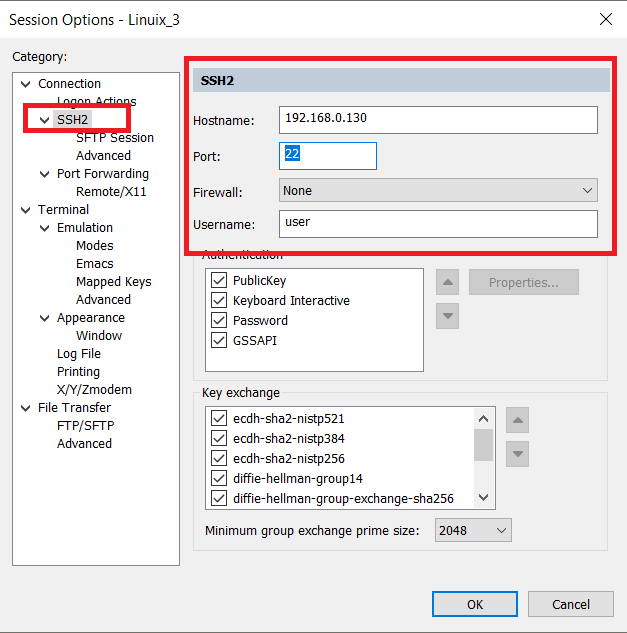
Настройки SSH на клиенте, через который мы будем подключаться к Debian, стандартные, в SecureCRT они находятся здесь:
Настройки SSH на клиенте
Для того чтобы была возможность подключаться по SSH на виртуальной машине должен быть запущен SSH сервер, который должен слушать 22 порт на предмет входящих подключений, сам порт должен быть открыть, включен ли сервер и какой порт он слушает можно проверить так:
debian sshd[491]: Server listening on 0.0.0.0 port 22.
debian sshd[491]: Server listening on :: port 22.
Строка Active: active (running) означаете, что сервер включен, по портам, полагаю, не нужно пояснять. Посмотреть открытые tcp/udp порты можно еще и так:
ss -lnput #UDP+TCP
ss -lu #только UDP
ss -tl #только TCP
Если не установлен ssh сервер его надо установить, в Debian и ему подобных дистрибутивах это делается так:
sudo apt update
sudo apt install openssh-server
Если 22 порт закрыт, его надо открыть, вариантов почему порт закрыт, может быть много, например, у вас установлен фаервол ufw и он не разрешает подключение к 22 порту, открыть порт можно будет так:
sudo ufw allow ssh
С вопросом подключения по SSH мы разобрались, нам надо теперь разобраться с интеграцией образа Linux в лабу, для этого на ens4 нужно назначить IP-адрес:
sudo nano /etc/network/interfaces
# to_lan_network
allow-hotplug ens4
iface ens4 inet static
address 192.168.3.25/24
# gateway 192.168.3.1
up ip route add 192.168.1.0/24 via 192.168.3.1 #первый статик
up ip route add 192.168.2.0/24 via 192.168.3.1 #второй статик
up ip route add 10.0.0.0/8 via 192.168.3.1 #третий статик
Строка iface ens3 inet static говорит о том, что адрес на интерфейс надо назначить руками, строка address 192.168.3.25/24 сообщает операционной системе какой IP-адрес и маску мы хотим использовать на этом интерфейсе. Строка # gateway 192.168.3.1 закомментирована, если убрать решетку, то машина будет считать, что за портом ens4 находится шлюз по умолчанию. Эту строку я закомментировал, потому что мой домашний роутер по DHCP сообщил, что именно он является шлюзом по умолчанию для данного хоста(а через домашний роутер осуществляется выход в интернет, а обычным домашним компьютерам и роутерам живется проще, когда они дорогу в интрнет знают не как full view, а как маршрут по умолчанию).
В связи с тем, что домашний роутер является шлюзом по умолчанию, но третий хост все-таки должен знать как добраться до других устройств лабы, пришлось писать и три статических маршрута: первый нужен чтобы был доступен узел Host_1, второй нужен чтобы был доступен Host_2, третий нужен чтобы были доступны p2p сети, настроенные между роутерами между роутерами. Если нужно чтобы были доступны Loopback интерфейсы роутеров, статики до них нужно тоже прописать.
Посмотрим применились ли настройки на ens4:
user@debian:~$ ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
inet 192.168.3.25/24 brd 192.168.3.255 scope global ens4
valid_lft forever preferred_lft forever
user@debian:~$
И будете правы, получилось! Сразу после этого в таблице маршрутизации должны будут появиться маршруты, которые мы задавали статикой:
user@debian:~$ ip route show
default via 192.168.0.1 dev ens3
10.0.0.0/8 via 192.168.3.1 dev ens4
192.168.0.0/24 dev ens3 proto kernel scope link src 192.168.0.130
192.168.1.0/24 via 192.168.3.1 dev ens4
192.168.2.0/24 via 192.168.3.1 dev ens4
192.168.3.0/24 dev ens4 proto kernel scope link src 192.168.3.25
user@debian:~$
Если не появились, надо будет напечатать в эмуляторе терминала три команды из файла interfaces, но уже без ключевого слова up, вот так:
ip route add 192.168.1.0/24 via 192.168.3.1
ip route add 192.168.2.0/24 via 192.168.3.1
ip route add 10.0.0.0/8 via 192.168.3.1
Чтобы новый хост получил связность с другими узлами сети, нужно не забыть выполнить настройки на R3(донастроить OSPF + настроить интерфейс в сторону хоста), показывать я это уже не буду.
Для просмотра базовой информации о сетевых и канальных параметрах есть четыре команды:
ПОСМОТРЕТЬ СЕТЕВЫЕ НАСТРОЙКИ:
user@debian:~$ ip addr show
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
192.168.0.101 dev ens3 lladdr 8c:55:4a:a9:b9:dd REACHABLE
192.168.0.1 dev ens3 lladdr b#:#0:24:#0:#f:#0 STALE
ТАБЛИЦА МАРШРУТИЗАЦИИ:
user@debian:~$ ip route show
default via 192.168.0.1 dev ens3
10.0.0.0/8 via 192.168.3.1 dev ens4
192.168.0.0/24 dev ens3 proto kernel scope link src 192.168.0.130
192.168.1.0/24 via 192.168.3.1 dev ens4
192.168.2.0/24 via 192.168.3.1 dev ens4
192.168.3.0/24 dev ens4 proto kernel scope link src 192.168.3.25
user@debian:~$
Давайте проверим доступность R3:
user@debian:~$ ping 192.168.3.1
PING 192.168.3.1 (192.168.3.1) 56(84) bytes of data.
64 bytes from 192.168.3.1: icmp_seq=1 ttl=255 time=9.88 ms
64 bytes from 192.168.3.1: icmp_seq=2 ttl=255 time=11.1 ms
64 bytes from 192.168.3.1: icmp_seq=3 ttl=255 time=2.07 ms
^C
--- 192.168.3.1 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 5ms
rtt min/avg/max/mdev = 2.074/7.673/11.067/3.988 ms
user@debian:~$
Успех, а теперь попингуем Host_1 и Host_2:
PING 192.168.1.15 (192.168.1.15) 56(84) bytes of data.
^C
--- 192.168.1.15 ping statistics ---
4 packets transmitted, 0 received, 100% packet loss, time 75ms
user@debian:~$
user@debian:~$ ping 192.168.2.12
PING 192.168.2.12 (192.168.2.12) 56(84) bytes of data.
^C
--- 192.168.2.12 ping statistics ---
4 packets transmitted, 0 received, 100% packet loss, time 68ms
user@debian:~$
А вот хосты не доступны. Вопрос: почему? На роутерах настройки корректные. Что надо сделать, чтобы эти узлы стали доступны?
Напоследок дам еще некотрые пояснения. Сетевые настройки мы выполняли в файле /etc/network/interfaces для того, чтобы после перезагрузки виртуальной машины они сохранились. Но адреса можно настраивать временно без сохранения в настроек в файл.
В примере ниже адрес 192.168.3.44/24 добавляется на интерфейс ens4 как secondary, поскольку основной адрес у нас уже задан, а add означает добавить. Вторичный адрес будет активен до перезагрузки.
user@debian:~$ sudo ip address add 192.168.3.44/24 dev ens4
user@debian:~$ ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000