




Грокаем алгоритмы. Иллюстрированное пособиедля программистов и любопытствующих

"Грокаем алгоритмы" - иллюстрированное пособие, написанное Бхаргава А., предназначено для программистов и всех, кто интересуется алгоритмами. Книга предлагает читателю познакомиться с различными алгоритмическими концепциями и методами, используемыми в программировании.
Автор представляет сложные материалы в простой и доступной форме, используя иллюстрации, наглядные примеры и практические задания. Книга охватывает широкий спектр алгоритмов, начиная с основных структур данных и поиска, и заканчивая более сложными алгоритмами сортировки, графами и динамическим программированием.
Особенностью книги является ее практическая направленность. После изучения каждого алгоритма читатель имеет возможность применить полученные знания на практике, решая задачи с использованием соответствующих алгоритмов. Книга также содержит советы по оптимизации алгоритмов и обсуждение их эффективности.
"Грокаем алгоритмы" является полезным ресурсом для программистов всех уровней - от начинающих до опытных разработчиков. Она поможет читателям освоить фундаментальные принципы алгоритмического мышления и расширить свои навыки программирования.
p.s.книгу вы можете легко скачать по ссылке https://t.me/bitebusters/174
Показать полностью
1


Бинарная куча и приоритетная очередь
Последние пару месяцев я решил попрактиковаться в решении задач на алгоритмы и структуры данных и вспомнить всё, что мы проходили в универе. Там, кстати, ни слова не было не только о сложностях алгоритмов, но и о Приоритетных очередях.
❓ Что это такое “Приоритетная очередь”
Приоритетная очередь — это коллекция, в которой, в отличии от обычной очереди, элементы упорядочиваются не на основе того, когда был добавлен элемент, а на основе приоритета, который этот элемент имеет. То есть, первым всегда будет извлекаться элемент с максимальным приоритетом. Также можно настроить очередь, чтобы она работала с наименьшими приоритетами.
Приоритетная очередь поддерживает те же операции, что и обычная очередь.
❓ Что это такое “Бинарная (двоичная) куча”
Бинарная куча – структура данных, позволяющая быстро (за логарифмическое время) добавлять элементы и извлекать элемент с максимальным приоритетом.
Куча представляет собой полное бинарное дерево, в котором каждый элемент не меньше своих потомков. Таким образом, максимальный элемент всегда находится в корне, поэтому доступ к нему происходит за O(1).
Можно сказать, что приоритетная очередь — это интерфейс, а бинарная куча — одна из возможных реализаций интерфейса “приоритетной очереди”.
💡 О том, как происходит добавление и удаление элементов из бинарной кучи описано в статье на хабре Структуры данных: двоичная куча (binary heap)
🧑💻 Собеседования
Интересный факт, что при прохождении собеседования на вашем языке программирования такая структура данных может отсутствовать.
Например:
- В .NET 6 появилась встроенная реализация приоритетной очереди, она так и называется PriorityQueue
- А вот в JavaScript из коробки в нет подобной реализации
В таком случае можно быстро реализовать приоритетную очередь с помощью динамического массива:
- Описать класс PriorityQueue, у которого под капотом используется динамический массив
- Метод Enqueue — добавляет элемент в конец динамического массива
- Метод Dequeue — извлекает элемент с наименьшим приоритетом
Эта реализация, будет работать очень медленно, но нам нужна лишь эмитация приоритетной очереди, ведь нам главное решить задачу и показать, что мы понимаем принцип работы этой структуры данных. Но прежде чем, писать даже такую быструю реализацию, лучше согласовать свои действия с интервьюером.
⌨️ Пример задачи с Leetcode
Чтобы понять как и зачем использовать приоритетную очередь можно порешать следующие задачи на Leetcode
1. Top K Frequent Words
2. Top K Frequent Elements
Еще по теме:
- .NET 6: PriorityQueue
- Top K Frequent Words - Priority Queue Approach (LeetCode)
#algorithms #interview
Показать полностью

Алгоритмы поиска в гошечке (golang)
Привет, чувачёчки.
В этом посте я хочу поделиться с вами кодом на Go для некоторых популярных алгоритмов поиска.
Наслаждайтесь.
Линейный поиск
Линейный поиск (Linear Search) - это простой алгоритм поиска элемента в списке, массиве или коллекции. Он работает путем последовательного перебора всех элементов до тех пор, пока не будет найден искомый элемент или не будут проверены все элементы.
Описание алгоритма:
1. Начните с первого элемента списка.
2. Сравните его с искомым элементом.
3. Если элемент совпадает с искомым, верните его индекс (или значение, в зависимости от реализации).
4. Если элемент не совпадает с искомым, перейдите к следующему элементу в списке.
5. Повторяйте шаги 2-4 до тех пор, пока не найдете искомый элемент или не пройдете весь список.
Линейный поиск имеет временную сложность O(n), где "n" - это количество элементов в списке. В худшем случае алгоритм может проверить все элементы, поэтому его производительность ухудшается с ростом размера списка.
Помимо своей простоты, линейный поиск также может применяться в неотсортированных списках или там, где нет возможности использовать более сложные алгоритмы поиска, такие как двоичный поиск. Однако для больших объемов данных и поиска в отсортированных структурах обычно рекомендуется использовать более эффективные алгоритмы.
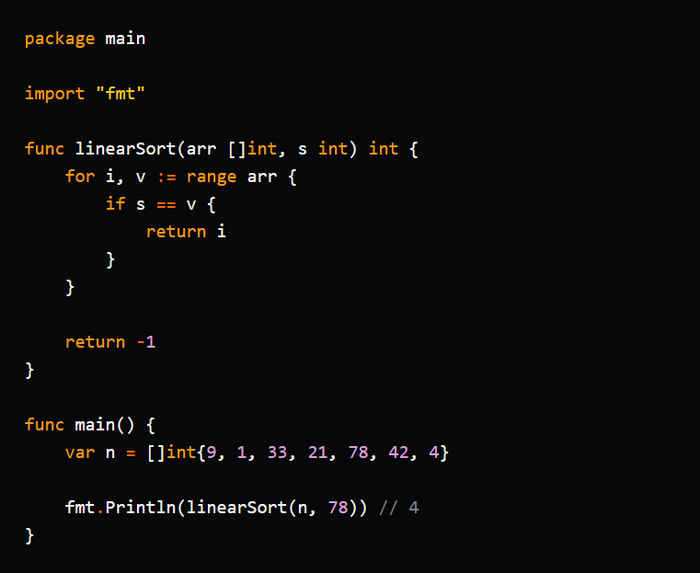
Бинарный поиск
Бинарный поиск (Binary Search) - это эффективный алгоритм поиска элемента в отсортированном списке, массиве или коллекции. Он использует стратегию "разделяй и властвуй", что позволяет быстро находить искомый элемент.
Описание алгоритма:
1. Начните с определения границ поиска. Установите начальную границу (left) в начало списка и конечную границу (right) в его конец.
2. Найдите средний элемент между начальной и конечной границей.
3. Сравните средний элемент с искомым значением.
4. Если средний элемент совпадает с искомым значением, возвращаем его индекс (или значение, в зависимости от реализации).
5. Если средний элемент больше искомого значения, обновите конечную границу (right) на позицию перед средним элементом и перейдите к шагу 2.
6. Если средний элемент меньше искомого значения, обновите начальную границу (left) на позицию после среднего элемента и перейдите к шагу 2.
7. Повторяйте шаги 2-6 до тех пор, пока не будет найден искомый элемент или пока начальная граница (left) не станет больше конечной границы (right).
Бинарный поиск имеет временную сложность O(log n), где "n" - это количество элементов в списке. Это означает, что в худшем случае алгоритм будет выполняться за логарифмическое время, что является значительно более эффективным, чем линейный поиск.
Однако для применения бинарного поиска список должен быть отсортирован по возрастанию или убыванию. В противном случае результаты будут непредсказуемыми. Бинарный поиск особенно полезен, когда требуется повторно выполнять поиск в отсортированных структурах данных, таких как массивы или списки, с минимальными затратами на время выполнения.
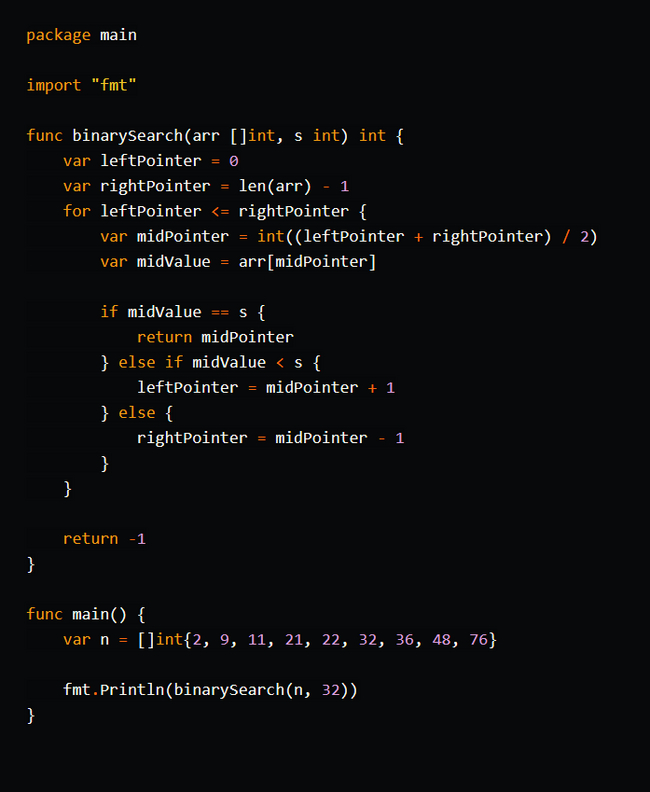
Прыжковый поиск
Прыжковый поиск (Jump Search) - это алгоритм поиска элемента в отсортированном списке, массиве или коллекции. Он использует идею деления интервала на блоки и прыжки через эти блоки для быстрого приближения к искомому элементу.
Описание алгоритма:
1. Задайте размер прыжка (jump size). Обычно он выбирается как квадратный корень из общего количества элементов в списке.
2. Начните с первого элемента списка.
3. Сравните текущий элемент с искомым значением.
4. Если текущий элемент равен искомому значению, верните его индекс (или значение, в зависимости от реализации).
5. Если текущий элемент больше искомого значения или достигнут конец списка, перейдите к следующему шагу.
6. Сделайте прыжок через блоки, перемещаясь вперед на размер прыжка.
7. Повторяйте шаги 3-6 до тех пор, пока текущий элемент не станет больше искомого значения или вы превысите границы списка.
8. Если текущий элемент больше искомого значения, выполните линейный поиск в предыдущем блоке с момента последнего прыжка.
9. Если элемент найден, верните его индекс (или значение, в зависимости от реализации).
10. Если элемент не найден, верните -1 (или другое значение, указывающее отсутствие элемента).
Прыжковый поиск имеет временную сложность O(√n), где "n" - количество элементов в списке. Он более эффективен, чем линейный поиск, но менее эффективен, чем бинарный поиск. Однако прыжковый поиск особенно полезен, когда список имеет равномерное распределение данных и доступ к элементам осуществляется за постоянное время.
Важно отметить, что прыжковый поиск также требует отсортированного списка для правильного функционирования.
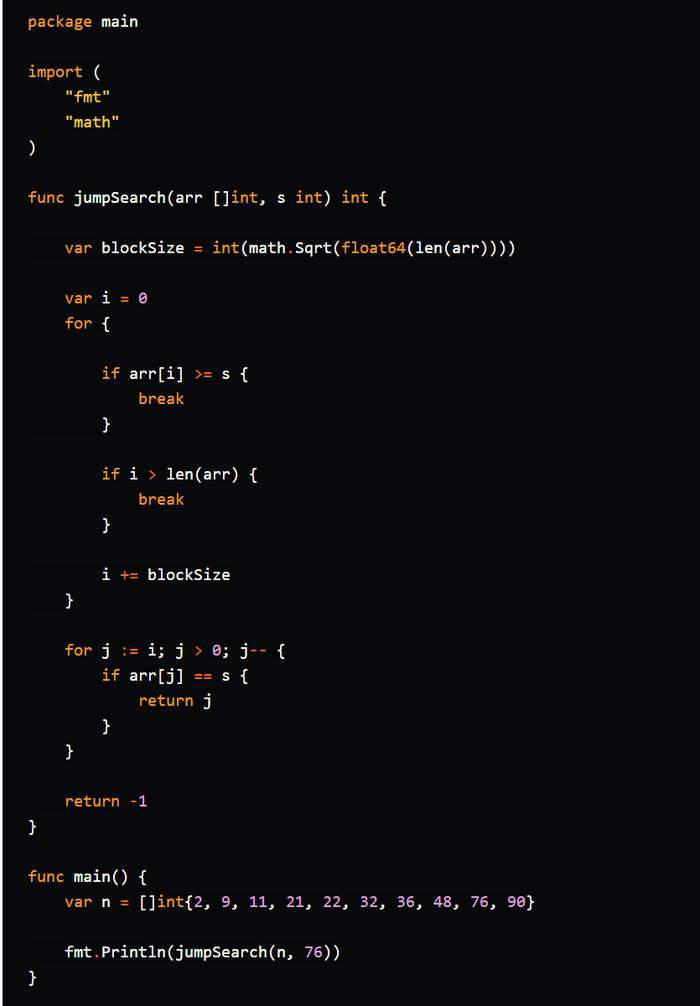
В общем: да прибудет с вами сила.
Постепенно цикл буду дополнять.
Показать полностью
3


LeetCode День 2 Longest Substring Without Repeating Characters [Medium]
Несмотря на знатное облажание в прошлый раз, я решил продолжить ̶л̶а̶ж̶а̶т̶ь̶ ̶п̶у̶б̶л̶и̶ч̶н̶о̶ решать задачи и выкладывать свои соображения тут.
Задача опять помечена, как среднего уровня, поэтому приступим: на первый взгляд все казалось достаточно просто, нужно всего лишь определить внутри строки самую длинную последовательность не повторяющихся символов.
![LeetCode День 2 Longest Substring Without Repeating Characters [Medium] Программирование, Python, Обучение, ChatGPT, Программист, IT, Алгоритм, Длиннопост](https://cs14.pikabu.ru/post_img/2023/05/22/5/1684741894185619503.jpg)
Очевидное решение в лоб - это перебрать все возможные подстроки внутри данной строки и оценить эти подстроки на уникальность символов. Значит нам нужна функция для определения строки из уникальных символов и какой-то цикл обхода.
![LeetCode День 2 Longest Substring Without Repeating Characters [Medium] Программирование, Python, Обучение, ChatGPT, Программист, IT, Алгоритм, Длиннопост](https://cs14.pikabu.ru/post_img/2023/05/22/6/1684743585139887812.jpg)
Сначала определим словарь, куда будем складывать длинны строк и значения этих самых строк. Для определения уникальности символов в строке просто считаем количество вхождений для каждого символа в отдельной функции. Ну а в цикле будем пробегать по всем подстрокам этой строки. Получилось практически с первого раза и я уже решил, что задаче надо сменить уровень на easy:
![LeetCode День 2 Longest Substring Without Repeating Characters [Medium] Программирование, Python, Обучение, ChatGPT, Программист, IT, Алгоритм, Длиннопост](https://cs13.pikabu.ru/post_img/2023/05/22/6/1684742530177211327.jpg)
Действительно это будет работать для относительно коротких строк, но я не обратил внимание на мелкий шрифт в конце:
![LeetCode День 2 Longest Substring Without Repeating Characters [Medium] Программирование, Python, Обучение, ChatGPT, Программист, IT, Алгоритм, Длиннопост](https://cs14.pikabu.ru/post_img/2023/05/22/6/1684742607168173730.jpg)
Т.е. на вход может подаваться текст на 50000 знаков. На одном из кейсов я закономерно получил ошибку, и даже перенеся на локальную машину подсчёты затянулись на 10+ минут, дальше я просто прервал исполнение.
![LeetCode День 2 Longest Substring Without Repeating Characters [Medium] Программирование, Python, Обучение, ChatGPT, Программист, IT, Алгоритм, Длиннопост](https://cs14.pikabu.ru/post_img/2023/05/22/6/168474400419570905.jpg)
Съев яблочко, мне пришла в голову мысль. А что если зайти с другой стороны. Т.е. предположить, что все символы в строке уникальные. Т.е. нам нужно взять строку целиком, потом и проверить на уникальность символов, потом взять все подстроки входящие в эту строку длинной на один символ меньше и проверить на уникальность символов. Потом взять все строки длиной на два символа меньше и зациклить.
Получилось тоже несложно, тесты на коротких строках прошли без проблем, но тест длинной строки опять провалился.
![LeetCode День 2 Longest Substring Without Repeating Characters [Medium] Программирование, Python, Обучение, ChatGPT, Программист, IT, Алгоритм, Длиннопост](https://cs13.pikabu.ru/post_img/2023/05/22/6/1684742733163574255.jpg)
Стало очевидно, что надо как то уменьшить количество пустых итераций, ну не может же быть, что очень длинный текст набран только уникальными символами. Ну и логично, что размер искомой подстроки не может быть больше количества уникальных символов в этой строке. Значит сначала надо подсчитать количество уникальных символов в строке и этим числом ограничить начальный размер искомой подстроки, а не полной длиной строки.
Ну и таки да, сначала подсчитали максимально возможный размер подстроки в отдельной функции и все тесты прошли успешно.
![LeetCode День 2 Longest Substring Without Repeating Characters [Medium] Программирование, Python, Обучение, ChatGPT, Программист, IT, Алгоритм, Длиннопост](https://cs13.pikabu.ru/post_img/2023/05/22/6/16847444741884240.jpg)
Ну и бонусом решение от chatGpt, которое оказалось намного лучше моего:
![LeetCode День 2 Longest Substring Without Repeating Characters [Medium] Программирование, Python, Обучение, ChatGPT, Программист, IT, Алгоритм, Длиннопост](https://cs14.pikabu.ru/post_img/2023/05/22/6/1684746469142986768.jpg)
![LeetCode День 2 Longest Substring Without Repeating Characters [Medium] Программирование, Python, Обучение, ChatGPT, Программист, IT, Алгоритм, Длиннопост](https://cs14.pikabu.ru/post_img/2023/05/22/6/168474647713418707.jpg)
В целом собой доволен, но решение от chatGpt опять вгоняет меня в уныние. Мало того, что бот сделал быстрее чем я, он сделал сильно лучше, чем я.
Показать полностью
9
LeetCode на пикабу
Привет товарищи, усиленно учусь программированию. В какой-то момент осознал, что мне сильно не хватает подготовки по алгоритмическим задачам. Хочу запустить серию постов в формате: берём задачку на LeetCode, разбираем что к чему, пишем решение на Python, публикуем на пикабу. Накидайте плюсцов, если не есть желание на это посмотреть.

Решил за 1 час

Показать полностью
1

Поиграем в бизнесменов?
Одна вакансия, два кандидата. Сможете выбрать лучшего? И так пять раз.
Какие игдексы существуют в PostgreSQL

B-дерево - это алгоритм индексирования, который используется в PostgreSQL. Он основан на идее разделения данных на несколько секций, которые называются узлами дерева. Каждый узел содержит набор ключей и ссылок на дочерние узлы. Поиск значения в B-дереве осуществляется путем последовательного перехода по узлам дерева, начиная с корневого узла, и сравнения искомого ключа с ключами в текущем узле. Этот алгоритм обеспечивает быстрое поиск, вставку и удаление данных, особенно в случае большого объема данных.
Узел дерева - это элемент структуры данных, который содержит информацию и ссылки на другие узлы. В B-дереве, каждый узел содержит набор ключей и ссылок на дочерние узлы. Корневой узел дерева является вершиной, откуда начинается обход дерева. Узлы ниже корня называются потомками. Каждый узел может иметь одного или несколько дочерних узлов, которые соответственно называются листьями дерева. Листья являются конечными узлами дерева и не содержат дочерних узлов.
B-дерево является структурой данных, которая может быть реализована в различных языках программирования, включая PHP. Чтобы реализовать B-дерево в PHP, вы можете создать класс, который описывает узел дерева и содержит методы для добавления, удаления и поиска элементов в дереве.
Некоторые из основных методов, которые вы можете реализовать в классе B-дерева в PHP, могут включать:
insert($value) - добавляет новое значение в дерево
delete($value) - удаляет значение из дерева
search($value) - ищет значение в дереве и возвращает true, если найдено, и false в противном случае
getMinimum() - возвращает минимальное значение в дереве
getMaximum() - возвращает максимальное значение в дереве
Важно отметить, что реализация B-дерева может быть сложной и требует некоторой предварительной
подготовки и знания алгоритмов и структур данных. Вам также может потребоваться протестировать и отладить ваш код для обеспечения корректной работы.
В PHP так же можно использовать сторонние библиотеки для реализации B-дерева, к примеру, "btree" или "B-tree" или "php-btree". Использование сторонних библиотек может значительно упростить процесс реализации B-дерева в вашем PHP-коде и обеспечить более надежную и оптимизированную реализацию.
Так же стоит отметить time complexity и space-complexity
Time complexity B-дерева обычно определяется как O(log n), где n - это количество элементов в дереве. Это достигается за счет того, что каждый узел дерева содержит не более t-1 ключей и t дочерних узлов, таким образом максимальная глубина дерева ограничена log(n/t).
Space complexity определяется как O(n), где n - это количество элементов в дереве. Это означает, что память, необходимая для хранения дерева, зависит от количества элементов в дереве. Каждый узел дерева содержит не более t-1 ключей и t дочерних узлов, поэтому количество узлов в дереве будет ограничено n/t.
Однако, необходимо учитывать, что в B-дереве также может быть использован дополнительный объем памяти для хранения информации о дочерних узлах и других метаданных.
"Introduction to Algorithms" авторы: Thomas H. Cormen, Charles E. Leiserson, Ronald L. Rivest and Clifford Stein. Эта книга считается одним из лучших учебников по алгоритмам и структурам данных и включает подробное описание B-дерева и других структур данных.
"Database Systems: The Complete Book" автор: Hector Garcia-Molina, Jeff Ullman, and Jennifer Widom. Эта книга посвящена базам данных и включает подробное описание B-дерева и других индексных структур, используемых в базах данных.
"Algorithms in C++" автор: Robert Sedgewick. Эта книга предоставляет практическое руководство по алгоритмам и структурам данных на языке С++ и включает код для реализации B-дерева.
Спасибо за дополнения и замечания https://t.me/gasoid
Ещё больше полезной информации тут https://vk.com/work2oq
Показать полностью
1