






“Надежность” (Reliability) и “Доступность” (Availability) — в чём разница?

Photo by Jeremy Thomas on Unsplash
Надежность и доступность имеют разные значения, когда речь идет о программном обеспечении. В чем разница между ними и что они значат по отдельности?
В чём разница между надежностью и доступностью?
Доступность — это процент времени, в течение которого система доступна пользователям. Надежность — это вероятность того, что система будет соответствовать определенному уровню производительности, основанному на потребностях пользователя, в течение определенного периода времени.
Хотя надежность звучит очень похоже на доступность, при более внимательном рассмотрении обнаруживаются определенные различия. Например, если два сервиса имеют следующие значения доступности, какой из них будет считаться более надежным?
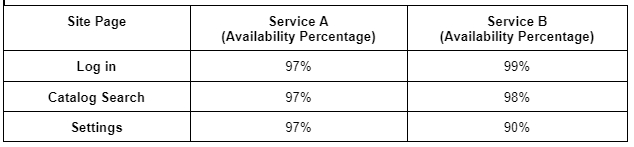
График, показывающий процент доступности двух сервисов
На первый взгляд кажется, что сервис А более надежен, но при более внимательном рассмотрении оказывается, что это не так. Пользователи не обращаются к каждой странице сайта равномерно. Каждый пользователь обязательно заходит на страницу входа в систему, около 90% из них посещают каталог, а страницу с настройками посещает только 30% пользователей. Учитывая это, сервис B будет восприниматься как более надежный, потому что надежность определяется на основе пользовательского опыта.
Что такое “доступность”?
Доступность, также известная как время безотказной работы, описывает процент времени, в течение которого сервис функционирует. Это самый простой и основной элемент надежности, и его часто путают с надежностью. Доступность — это широкий термин, и разные организации могут определять его по-разному. Например, одна организация может считать событие сбоем, когда оно затрагивает определенный процент пользователей, в то же время другая организация может это же событие считать сбоем независимо от количества затронутых пользователей.
Кроме того, вы не должны просто стремиться быть “доступными”. Сервис должен быть способен выполнять свои запланированные операции даже при изменяющихся условиях. В распределенных системах вы можете использовать chaos engineering для экспериментов с отказоустойчивостью вашего сервиса.
Как измерить доступность?
Вот как вы можете рассчитать процент доступности вашего сервиса:
Определите общее время работы
Вычтите время, в течение которого сервис был недоступен
Разделите получившееся время на общее время
Процент доступности = (Общее время — Сумма простоев)/Общее время
“Девятки” доступности
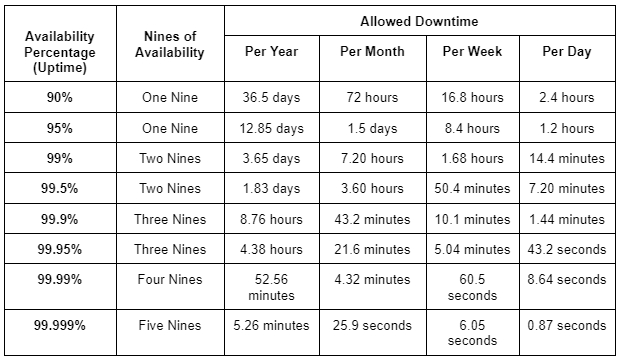
Допустимое время простоя для различных “девяток” доступности
Как улучшить доступность услуги?
Развертывайте свой сервис в различных географических точках по всему миру, сокращая количество единичных точек отказа.
Используйте chaos engineering для экспериментов и поиска уязвимостей системы.
Эффективно используйте балансировщики нагрузки для перенаправления запросов.
Улучшите процесс управления инцидентами, чтобы сократить время простоя, вызванное инцидентами.
Что такое надежность?
Надежность системы — это вероятность того, что она будет соответствовать определенным стандартам производительности и выдавать правильный результат в течение определенного времени. Она используется, чтобы понять, насколько хорошо сервис будет работать в реальных условиях.
Как измерить надежность?
Поскольку надежность — это продолжительность безотказной работы системы, мы можем измерить ее, используя метрику “Среднее время наработки на отказ” (MTBF).
Посчитайте количество отказов
Найдите общее время работы
Разделите общее время на количество сбоев
Среднее время наработки на отказ (MTBF) = Общее время работы (в часах)/Количество отказов
Надежность также может быть измерена с помощью частоты отказов сервиса:
Посчитайте количество отказов
Найдите общее время работы
Разделите количество отказов на общее время работы
Частота отказов = Количество отказов/Общее время работы
Имейте в виду, что, хотя эти формулы и выглядят простыми, самое сложное — определить, что же такое “сбой” для вашей системы. Поскольку надежность основана на пользовательском опыте, вам необходимо использовать такие процессы, как SLI, чтобы понять, каков приемлемый уровень обслуживания.
Как повысить надежность сервиса?
Тестируйте систему и разверните runbook automation.
Тщательно тестируйте новые функции перед деплоем.
Внедрите надлежащий процесс управления инцидентами.
Взаимосвязь между надежностью и доступностью
Надежность системы зависит от того, будет ли она выдавать правильный результат, когда это нужно. Это не то же самое, что доступность, которая означает доступность в любое время. Тем не менее, доступность и надежность взаимосвязаны. Можно сказать, что доступность — это самый простой и основной элемент надежности. Надежность и доступность идут рука об руку, поскольку одно невозможно без другого. Только если что-то доступно, мы можем определить, насколько оно надежно. Таким образом, высокий уровень надежности приводит к высокому уровню доступности.
Что такое ремонтопригодность и как она связана с доступностью и надежностью?
Ремонтопригодность — это способность сервиса сохраняться или восстанавливаться до прежнего состояния после проведения технического обслуживания. Она влияет на доступность, определяя, насколько эффективно устраняются простои. В случае инцидента обслуживаемые сервисы могут быть легко восстановлены или быстро сохранены. Ремонтопригодность может быть как проактивной, так и реактивной.
Проактивная ремонтопригодность предполагает создание сервиса с понятным и легко изменяемым кодом. Проактивное техническое обслуживание также включает практики, такие как тестирование и контроль качества (QA).
Реактивная ремонтопригодность относится к способности системы восстанавливаться после инцидента. Поскольку инциденты неизбежны, лучше всего внедрить надежный процесс реагирования на инциденты.
Надежность против инноваций
Независимо от того, предлагаете ли вы продукт или услугу, надежность очень важна, но так же важны и инновации. Вы не сможете оставаться конкурентоспособными без постоянных улучшений своего продукта, а инновации означают изменения, которые могут привести к нестабильности. Жизненно важно найти и соблюдать баланс между надежностью и инновациями. С другой стороны, предложение лучших функций на рынке может оказаться напрасным, если ваш потребитель не сможет получить к ним доступ. Сохранение хорошего баланса надежности и скорости развития является трудной задачей, но в конечном итоге хорошая надежность повысит скорость развития благодаря таким практиками, как, например, бюджетирование ошибок.
Всегда будут изменения, нестабильность и неопределенность, и именно поэтому бессмысленно стремиться к совершенству. Вы всегда должны стремиться к реалистичному и практичному времени безотказной работы (которое никогда не будет 100%). После определенного момента улучшение надежности или доступности станет незаметным для пользователей. Усилия, которые вы тратите на повышение надежности после этого момента, лучше было бы направить в другое место. Лучшие в своем классе корпоративные организации часто обеспечивают доступность на уровне 99,999%, также известную как доступность “пять девяток”, с годовым временем простоя всего 5,256 минут.
Процент доступности системы, гарантированный пользователям, обычно указывается в соглашении об уровне обслуживания (SLA). Лучший способ справиться с простоями — это быть готовым к любому инциденту. Наличие надежного процесса управления инцидентами и соответствующего бюджета на ошибки (допустимая ненадежность) жизненно важно для каждой организации.
Показать полностью
2
Как находить и исправлять ошибки
Оригинал: How to debug by Phil Booth
Как инженеры, мы проводим много времени за отладкой проблем, однако этому редко учат, как самостоятельному навыку. Некоторые ошибки настолько сложны, что их решение может показаться практически невозможным, особенно для разработчиков без опыта. Нет худшего чувства, чем застрять на сложной проблеме, не зная, как действовать дальше. Конечно, самое правильное, что нужно сделать, если вы застряли — это попросить помощи: у своей команды, у других инженеров в вашей организации или в вашем кругу общения, у случайных незнакомцев в интернете. Как случайный незнакомец в интернете, этот пост — моя попытка помочь вам выбраться из тупика, если вы оказались в подобной ситуации.
На самом деле это началось с моей попытки написать пост типа “чему я научился за 25 лет работы инженером”, как некоторые другие, которые я видел в последнее время. Но оказалось, что я больше склоняюсь к конкретным, практическим советам, чем к глубокой, философской мудрости. 🤷
Пост написан в виде упорядоченного списка, но не каждая проблема требует выполнения всех шагов. Иногда правильное решение приходит в голову само собой на шаге 1 или, что еще лучше, на шаге 0! В других случаях вы можете пропустить несколько шагов или выполнить их в другом порядке. Но в целом, порядок, приведенный здесь, это основа, на которую я постепенно перешел со времени моей первой работы над модулем обработки ресурсов для контроллера базовой станции GSM в компании Lucent Technologies в 1997 году. За прошедшие годы я работал во многих различных средах: системное программирование, базы данных, настольные приложения, веб-приложения, backend и frontend. Эти шаги обобщены и применимы ко всем этим средам, они не являются специфическими для какого-то конкретного языка или парадигмы.
0. Ваше психическое состояние
Самые сложные проблемы часто возникают в моменты наибольшего напряжения. Что-то сломалось на продакшене и платящие клиенты жалуются на это. Возможно, они требуют возврата денег. Ваш начальник хочет знать, когда вы это пофиксите, а вы еще даже не знаете, в чем дело.
Если все это происходит, вы, вероятно, находитесь в состоянии стресса, а стресс заставит вас решать проблему медленнее, а не быстрее. Поэтому, прежде чем перейти к очевидному шагу 1, нам нужно сначала позаботиться о шаге 0. Убедитесь, что вы находитесь в хорошем расположении духа. Постарайтесь расслабиться, будьте спокойны. Ваш продакшен может не работать в течение часа, но это лучше, чем если бы он простоял много часов из-за того, что вы поспешно предприняли неправильные действия.
Не менее важно быть уверенным и оптимистичным в своих взглядах. Программирование — это не волшебство, системы следуют правилам, даже если эти правила загадочны и неизвестны нам. У каждой проблемы есть рациональная причина и решение, которые вы найдете со временем. Поэтому будьте настойчивы, не сдавайтесь.
Наконец, будьте честны с собой в отношении проблемы. Не обманывайте себя в том, что вы знаете, что что-то является правдой, если это всего лишь предположение. Проверяйте эти предположения, потому что они часто удивляют вас. Это нормально, что вы не всегда понимаете все части проблемы, если только вы признаете те части, которые вам пока непонятны. Держите их в уме, но отделяйте и возвращайтесь к ним позже. Разделяй и властвуй.
1. Воспроизведите проблему
Воспроизведение проблемы кажется настолько очевидным первым шагом, что почти не заслуживает упоминания. Это должен быть первый шаг каждого, но я часто удивлялся в разговоре с инженерами, когда спрашивал, воспроизвели ли они проблему самостоятельно.
Недостаточно работать на основе чужого описания ошибки или того, что вы думаете о проблеме. Помните, что вам нужно проверять свои предположения, и нет более важного предположения, чем то, существует ли проблема в том виде, в котором она описана, или какие шаги нужно предпринять, чтобы ее решить. Сначала докажите, что вы правильно их понимаете.
На моей второй работе в компании Transoft я работал над текстовым редактором и получил отчет об ошибке от команды контроля качества о “бесконечном цикле” при нажатии правой кнопки мыши для вызова контекстного меню. Я не мог воспроизвести это, поэтому попросил их показать мне. Оказалось, что “бесконечный цикл” возникал, когда они щелкали правой кнопкой мыши в другой области экрана и ожидали, что это приведет к закрытию меню. Но программа работала как положено, закрывая первоначальное меню и открывая новое в новом месте щелчка. Таким образом, “ошибка” на самом деле была просто ошибкой в ожиданиях.
2. Воспроизведите ее снова
Отлично, вы воспроизвели проблему. Но действительно ли это так или это было просто совпадение? Ошибки иногда могут быть продуктом многих взаимосвязанных факторов, и если у вас есть только одна точка отсчета, вы не можете быть уверены, что понимаете основную причину (причины).
Повторное воспроизведение может исключить возможность того, что в первый раз вы допустили глупые ошибки, и повысить уверенность в том, что вы на правильном пути. Уверенность, если она подкреплена честностью, — ваш лучший друг в этом процессе. Но уверенность — это нежный цветок, и вы должны защищать его любой ценой. Не позволяйте ничему растоптать вашу уверенность.
3. Не воспроизводите ее
Если вы знаете, как воспроизвести проблему, знаете ли вы также, как ее не воспроизводить? Иными словами, знаете ли вы, какие переменные играют важную роль в определении возникновения проблемы?
Экспериментируйте с этими переменными, изменяйте их и доказывайте их значимость. Это может привести к сокращению шагов по воспроизведению, что абсолютно необходимо сделать на данном этапе. Недостаточно того, что вы можете надежно воспроизвести проблему, вы хотите изолировать ее до наименьшего количества шагов или наименьшего количества данных.
4. Поймите код
Теперь вы находитесь на том этапе, когда можно посмотреть на код и попытаться понять, что не так, потому что теперь вы действительно понимаете суть проблемы.
Примените свои знания о действующих переменных к системе, которая находится перед вами. Какой код управляет этими переменными? Как они взаимодействуют? Если есть код, который вы не понимаете, попробуйте найти человека или команду, которые над ним работали. Они смогут сократить ваш путь к просветлению и, возможно, даже уже сталкивались с проблемами, подобными вашей.
Иногда код поступает из непрозрачных сторонних источников. Если у вас нет доступа к этим источникам, у вас все равно есть пути для расследования. Прочитайте справку по API или другую документацию, поищите в базе данных ошибок, если таковая имеется. Есть ли соответствующие вопросы на Stackoverflow или в других местах?
В начале 2000-х годов я работал над прикладным фреймворком, который был бинарником для Internet Explorer 6. Это означало использование ряда API IE и Windows, которые имели скудную документацию. Всякий раз, когда реальность не совпадала с нашими ожиданиям от этих API, мы прибегали к поиску ответа в Usenet или на других онлайн-форумах. Чаще всего, когда мы в конце концов находили правильный ответ, его размещал таинственный гений с именем “Игорь Тандетник”. Прошло немного времени, прежде чем мы начали по умолчанию добавлять ко всем нашим поисковым запросам “Игорь Тандетник”. В качестве ускорителя отладки это полностью оправдало себя.
5. Наблюдайте за состоянием
После рассуждений о коде в его статической форме, посмотрите на динамическое состояние памяти в момент возникновения проблемы (до, во время и после).
Как вы это сделаете, зависит от вас. В начале своей карьеры я предпочитал использовать отладчик, но в наши дни я чаще всего просто вывожу значения на консоль. Отладчик — это здорово, но для определенных классов проблем (например, параллелизм, события пользовательского интерфейса) они представляют собой наблюдение как взаимодействие; попадание в точку останова может само по себе изменить условия кода, который вы пытаетесь отладить. Ведение журнала может быть более надежным отладчиком в таких условиях. И наоборот, чтение логов быстро надоедает, если ваш проект медленно компилируется. Выбирайте то, что лучше всего подходит для конкретных условий.
Логи также помогут вам на этом этапе, не забывайте обращаться к ним. В идеале ваши логи структурированы и доступны для поиска, поэтому вы можете легко устранить шум, используя соответствующие условия запроса. Если вы не знакомы с инфраструктурой ведения производственных журналов, найдите кого-нибудь, кто знаком с ней, и попросите их ввести вас в курс дела.
Какой бы метод вы ни использовали, есть два типа состояний, которые вас интересуют: пути, по которым следует код, и сохраненные значения. Обязательно посмотрите и то, и другое.
6. Запишите то, что вы (как вам кажется) знаете
Записывание информации на бумаге или в электронном виде может быть удивительно эффективным методом анализа. Он работает на два фронта: заставляет вас активно обдумывать то, о чем вы пишете, а затем служит в качестве памятки при просмотре информации в ваших заметках.
Постарайтесь не поддаваться искушению преждевременно найти решение в этих заметках. Если преждевременная оптимизация — корень всех зол (или, по крайней мере, большинства из них), то преждевременная разработка решений — корень всех неправильно диагностированных ошибок (или, по крайней мере, большинства из них). Сосредоточение внимания только на тех вещах, которые, по вашим наблюдениям, являются безусловно верными, поможет держать под контролем ваши предположения и предубеждения.
Заставляйте себя делать записи, как только вы начинаете исследовать проблему, даже если кажется, что она может быть тривиальной. В худшем случае вы сможете выбросить их, если они не пригодятся. Также может быть полезно записывать их в публичном месте, чтобы другие люди могли воспользоваться тем, что вы узнали, и, возможно, внести свои предложения по проблеме, над которой вы работаете. Прозрачность — это суперсила.
Всякий раз, когда я отлаживаю продакшн-инциденты или просто выполняю рутинное обслуживание прод-инфраструктуры, я начинаю новую тему в Slack в нашем канале #devops и веду там оперативные записи. По крайней мере, эти темы служат публичной записью всего, что я делал или наблюдал, с привязкой к временной метке. В дальнейшем, инженеры могут найти их с помощью поиска и вернуться к ним, если подобные сценарии возникнут снова. Но не раз они также служили толчком для полезного обсуждения того, над чем я работаю. Благодаря этим тредам мы быстрее устраняли проблемы.
7. Исключите некоторые вещи
Иногда полезно удалить куски кода, чтобы доказать, что они не связаны (или нет). Это можно сделать по двум направлениям: по времени и по функциям.
Временной подход означает использование контроля исходного кода для постепенного определения набора изменений, в который была внесена ошибка. Если вы используете git, то git bisect существует именно для этой цели. Это отличное оружие в вашем арсенале, и вам следует ознакомиться с ним, если вы еще не знакомы с ним.
Feature-based означает посмотреть на код и физически удалить его части самостоятельно. Удалите его, закомментируйте, используйте условную компиляцию, что угодно. Это проверка ваших предположений. Убедитесь, что вы делаете маленькие шаги, следуя этому подходу. Слишком легко изменить множество вещей одним махом и потом не знать, какая из них отвечает за наблюдаемые эффекты.
8. Погуляйте с собакой
Если вы слишком долго концентрируетесь на одной и той же проблеме, ваш мозг “затуманивается”, и вы становитесь менее эффективным. В этот момент лучше всего пойти погулять, но часто бывает трудно понять, когда для этого настало время. Старайтесь сознательно анализировать свою работу всякий раз, когда вы отходите от рабочего места. Будьте честны в своей оценке.
Мне повезло, что у меня есть собака Майло, которая заставляет меня прекращать работу через регулярные промежутки времени, чтобы мы могли поиграть или погулять. Эти прогулки иногда являются самой продуктивной частью моего дня, количество случаев, когда во время прогулки приходит свежая идея, просто поразительно. (Самое главное, чтобы вам никто не мешал думать, когда вы гуляете :)) Если это не полное решение, то это может быть какая-то его часть или теория, которая продвигает меня на шаг ближе.
Дело в том, что ваш мозг не перестает работать над проблемой только потому, что вы перестали активно думать о ней. Он все еще там, работает в фоновом режиме. Дайте ему немного передышки, чтобы сделать свое дело.
9. Перепишите компонент
Хотя переписывание целых систем редко бывает хорошей идеей, переписывание небольших фрагментов функциональности может быть эффективным способом выявить факторы, которые часто могут быть скрыты от глаз. Иногда вы можете смотреть на код целую вечность, и он выглядит прекрасно, но как только вы попытаетесь переделать его на свой лад, вы столкнетесь с костылями, на которые пришлось пойти автору. Эти костыли — отличный источник моментов “ага!” для отладки.
Важно отметить, что вы не стремитесь заменить код, который вы переписываете. План состоит в том, чтобы отбросить ваш код после того, как он выполнит свою работу, которая заключается исключительно в том, чтобы помочь вам понять. Иногда вам может повезти, и вы обнаружите, что исправление вашей ошибки скрывается в коде “замены”, но лучше не ставить перед собой такую цель, так как это может отвлечь вас от реальной задачи.
10. Напишите неудачный тест
Если и есть одно замечание, которое бросают мне чаще других, как в качестве комплимента, так и в качестве критики, так это то, что я пишу много тестов (для некоторых людей слишком много). Но есть один вид тестов, в котором я абсолютно не иду на компромисс, и это регрессионные тесты. Они подобны технологическому антидолгу, сложным процентам, которые выплачивают все большие суммы по мере накопления их в вашем проекте.
Каждый раз, когда вы исправляете баг, вы должны добавлять как минимум один новый тест в ваш набор регрессионных тестов. То, что в программных проектах идет не так один раз, часто идет не так и во второй раз. Молния бьет дважды. Самый простой способ справиться с этим — писать регрессионные тесты по ходу работы. А самый простой способ убедиться в том, что ваши регрессионные тесты действительно работают, — это написать сначала неудачный тестовый пример, прежде чем приступить к его исправлению.
Написание подобных тестов также является хорошим способом убедить любых специалистов, не склонных к тестированию, внести свой вклад в тестируемый код. Им будет гораздо труднее отказаться по причине нехватки времени или усилий, если вы попросите всего один тест в их PR. Дюйм за дюймом вы сможете подтолкнуть их в направлении лучших привычек.
11. Исправь это
В конце концов, вы поймете проблему настолько хорошо, что один или несколько способов ее решения откроются вам. Если вы в глубине души знаете, в чем заключается единственное верное решение, то можете смело использовать его, и никаких проблем. Но в других случаях дальнейший путь будет менее ясен, и в таких случаях вам следует проявлять инициативу, собирая больше мнений. Не думайте о неуверенности как о признаке слабости; напротив, ваша готовность обсуждать ее — признак силы. И все эти обсуждения будут направлены на устранение будущих ошибок, делая вас более сильными для решения проблем, которые ждут вас впереди.
Показать полностью


Складной и горный?
Товарищи! Прошу помощи!
Увидел сочетание горного и складного велосипедов, как на фото ниже. Рама 19 либо 18, колёса 27,5, алюминиевый сплав (так написано). Три варианта:
- Forward
- Lorak
- Третий (забыл название, но он чуть дороже предыдущих)
Теперь вопросы знатокам, кто уже брал себе такие "раскривушки":
1. Если я люблю кататься по пердям с кочками и преодолевать всякое — выдержит такое педальный конь? И как долго он сможет это терпеть?
2. Краем уха видел слово "люфт" в отношении небольших складных велосипедов. На крупных это страшно? Консультант сказал, что могут быть проблемы с петлями. Когда ждать по прогнозам этих болячек?
3. Меня также тревожит сам замок — в какое спортлото бежать, если с его осью что-то произойдёт? Материал её не указан, да и формы они, конечно, разной бывают.
В общем, насколько надёжна конструкция? Точнее — место, которое складывается. И как долго катаетесь?
Если вам есть чем поделиться из своего опыта — подскажите, пожалуйста.
На вопрос, почему хочу купить именно такой, отвечаю — места дома для обычного особо нет. Предыдущий (пока не спёрли) оставлял в подъезде, либо дома его нужно ставить у шкафа, который нужно каждый день открывать. Сложна.
А для складного есть НИША.
Ах, да! На велосипеде собирается кататься кОбан в 95 кг (с учётом одежды/рюкзака).
Заранее благодарен.


Фото — для понимания того, о чём я написал, если кто не видел.
П.с: на фотках нет "Форварда" — он был слишком красив и от изумления я забыл его запечатлеть.
П.п.с: если хотите написать о том, что нужен вел за 300 тыр — пишите. Но это не про меня. Если хотите написать о том, что конструкция — говно, то прошу вас размазать подробнее.
Показать полностью
2


Продолжение поста «Юмани»
всё друзья я сделал киви спасибо большое LindaRaschke
я вообще не знал что можно было переделать свой никнейм в ссылку
LindaRaschke спасибо большое за помощь
Юмани
друзья подскажите пожалуйста, сайт Юмани вообще надёжный ?
просто, я ищу более удобный, способ для вас, отправки подарков в виде Донатов
просто многие пишут что ссылка не видна так же как и кнопка Поддержки


Корабль, который не брали ядерные взрывы
С 6 февраля по 11 мая 1946 года, 180 американских специалистов ВМФ готовили линкор «Нагато» к последнему походу к атоллу Бикини, где легендарный флагман адмирала Ямомто, должен был стать одной из целей ядерных испытаний. Именно с этого корабля был отдан приказ «Тора Тора Тора» - когда стало ясно, что атака на Перл-Харбор оказалось полной неожиданностью в соответствии с планом. Хотя «Нагато» был одним из самых старых военных кораблей Императорского флота, он принимал участие в боях и был серьезно поврежден в сражениях за Филлиппины.

После 3-х дневных испытаний в Токийском заливе, в течение первых двух недель марта, а так же переговоров с некоторыми японскими специалистами, знавшими «Нагато», линкор вышел из Токио в Эниветок. В пути, старый линкор сопровождал один из крейсеров поздней постройки – «Сакава» (1944г.). С двумя работающими из четырех огромных винтов, исполин мог развить скорость только в 10 узлов. Два других винта просто вращались под напором воды. Линкор водоизмещением 35 тысяч тонн идущий с такой небольшой скоростью требовал повышенного внимания к управлению, т.к. совсем легко уходил с курса и порой, непослушный корабль выписывал зигзаги. Первая часть пути прошла бес приключений, но затем стало очевидно, что «Сакава» и «Нагато» набирают воду, а насосы не справляются с холодным душем, сквозящим через боевые раны обоих кораблей.
О качестве в спешке выполненных японцами ремонтных работ, можно было судить хотя бы по тому, что на 8-й день плавания, корабль принял 150 тонн воды в носовые отсеки и чтобы выровнять линкор, пришлось дополнительно затопить отсеки на корме. На 10-й день, «Сакава» окончательно отстал, при попытке взять его на буксир на линкоре взорвался один из котлов и оба корабля встали. Несколько дней, пока не подошли буксиры, остатки некогда величественного флота дрейфовали. С черепашьей скоростью в 1 узел, буксир тащил тушу «Нагато» в Эниветок, несомненно, если бы не помощь еще одного более крупного буксира, линкор рисковал попасть в шторм и затонуть, в следствие неработающих насосов – на борту не было электричества - крен достиг 7 градусов. На подступах к Эниветоку, «Нагато» все же попал в волну тайфуна, но остался невредимым и 4 апреля бросил якорь, на 18-й день перехода.
После 3-х недельного ремонта, «Нагато» предпринял последний в своей жизни 200-мильный поход к месту своей последней стоянки – атоллу Бикини. Казалось, огромных корабль в последний раз хотел показать на что способен, хоть уже с нефункционирующим вооружением, на скорости 13 узлов, без посторонней помощи достиг своей цели.
Главной мишенью испытаний был американский линкор-ветеран «Невада», выкрашенный в яркий красно-оранжевый цвет, он должен был стать эпицентром взрыва. По правому борту от «Невады» суждено было стоять «Нагато». Бывшие противники собирались встретить мощнейший взрыв плечом к плечу. 21 килотонная бомба «Гильда» была взорвана 1 июля 1946 года на высоте примерно 150 метров над уровнем океана, взрывная волна распространялась от эпицентра со скоростью 3 мили в секунду! Но вся эта совершенная мощь, последнее слово в науке и технике оказались бессильны перед «человеческим» фактором. «Невада» и «Нагато» должны были принять всю мощь взрыва на себя, но… взрыв произошел не там где намечалось. Не над ветераном Перл-Харбора, а над легким авианосцем «Индепенденс», чья полетная палуба была уничтожена, корпус смят, а надстройка сметена как чудовищным молотом! Спустя шесть часов авианосец еще горел, как его собрат по несчастью «Принстон» в заливе Лейте 2 года назад.
А что «Нагато»? Бомба разорвалась примерно в 1.5 километрах от линкора, и, можно сказать, не сильно повредила его «пагоды» и орудийные башни, главный дальномер да некоторые коммуникации – вот и все, что было выведено из строя. Силовая установка и прочие жизненно важные механизмы не пострадали. Сосед – «Невада» получил повреждения надстройки, да труба обрушилась – и только! Линкоры выстояли. (Американцы, исследуя «Нагато» после взрыва были удивлены, что 4 из действующих котлов остались нетронутыми, в то время как на американских кораблях на той же дистанции от взрыва, эти механизмы были разрушены либо отказали. Комиссия ВМФ приняла решение тщательно изучить силовую установку японского корабля и внедрить некоторые особенности конструкции в американские послевоенные суда.)

25 июля 1946 года, вторая бомба – «Бэйкер» была взорвана с целью обрушить на корабли ударную волну из массы воды, американский авианосец «Саратога» с одной стороны и «Нагато» с другой должны были встретить взрыв на расстоянии 870 м. от эпицентра, и находились ближе всех к нему. Если не принимать во внимание линкор «Арканзас» в почти 400 метрах. Огромная лавина воды высотой 91.5 метра, массой несколько миллионов тонн со скоростью 50 миль в час обрушилась на «флот Бикини». На сей раз «Нагато» принял удар так, как было рассчитано и мелкими повреждениями уже невозможно было отделаться. Несчастный «Арканзас» взрывом был вдавлен в воду и затонул за 60 секунд. Огромный «Саратога» получил удар такой силы, что ее корпус был смят как картонный, а полетная палуба продольно была испещрена огромными трещинами.
Но когда туман из брызг и дым рассеялись, «Нагато» как ни в чем ни бывало оставался на плаву, он опять оказался сильнее атомного взрыва! Как несокрушимая гора, линкор возвышался над поверхностью воды, его огромная «пагода»-надстройка и орудийные башни, казалось не понесли никакого значимого ущерба от ярости «Бейкера». Лишь крен в 2 градуса на правый борт выдавал тот факт, что корабль только что перенес самый страшный взрыв и подводную ударную волну. За кормой японца, американский линкор «Невада» так же пережил сокрушающий удар, но его мачты и надстройки были разрушены. Таким образом, казалось, массивные корабли оказались абсолютно невосприимчивы к силе атома, однако, все еще на плаву, они таили в себе иную опасность – радиационную.Выброшенные на палубы массы загрязненной воды сделали невозможным приближение к кораблям ближе чем на 1000 метров, после визуального осмотра, был отмечен крен в 5 градусов, но казалось «Нагато» вовсе не собирался тонуть! Американцы попытались смыть радиацию с испытуемых кораблей с помощью брандспойтов, но это не принесло успеха. Уровень радиации был настолько высоким, что счетчики Гейгера истерично щелкали рядом с кораблями. Американцы были удивлены, что подводный взрыв оказался очень «грязным» по сравнению с первым, они не учли огромное количество загрязненной воды, прокатившейся по палубам.
Надежды спасти корабли были тщетны, команды не могли взойти на борт для того чтобы исследовать повреждения и предотвратить затопление внутренних отсеков. Не имея возможности как-то побороться за живучесть «Саратоги», американцы бессильно наблюдали, как медленно авианосец соскользнул на дно, встав на ровный киль. «Нагато» тоже, молчаливо взирал, как носовая часть «Саратоги» с номером «3» последний раз мелькнула над водой.
После того, как невозможность дальнейшего изучения «Нагато» ввиду радиации стала очевидной, американцы быстро потеряли к нему интерес. Хотя были высказаны предложения отбуксировать линкор на глубину и затопить, загрязненность делала такие попытки весьма небезопасными. Тем более, что крен на правый борт постепенно очень медленно увеличивался, спустя три дня он составлял 8 градусов. Это было настолько необычно, что многие наблюдатели стали подозревать, что «Нагато» удасться выжить и тем более беспокоило американцев, теперь им нужно было как-то избавляться от «радиактивного линкора»!
Но утром 29 июля, ситуация кардинально изменилась. «Нагато» еще был на плаву, но уже очень сильно осел, так что воды атолла Бикини могли спокойно переливаться на палубу со стороны правого борта и затоплять отсеки под главной надстройкой. Крен достиг 10 градусов, но со стороны казалось, что в таком состоянии корабль может пробыть довольно длительное время – очевидно, затопление постепенно выровняло «Нагато», который продолжал возвышаться над волнами рядом с «Невадой»…
Медленно на атолл опустилась ночь, озаряя поврежденный флот лунным светом. Именно под покровом темноты, «Нагато» ушел на дно, как будто не пристало гордости японского флота тонуть под взорами любопытных американцев, он выбрал свое время. Ранним утром 30 июля, крен неожиданно увеличился, нос корабля задрался, линкор опрокинулся, оседая на морское дно. Никто не знает точного времени, никто не был очевидцем - такой должна быть смерть переполненного достоинством истинного самурая.
Недоумевающих американцев на заре встретило ровная океанская гладь на том месте, где стоял «Нагато» - после 4 дней наблюдений, уже сомневавшихся насчет того затонет ли линкор или нет, но его гибель заметно упрощало положение дел. Позднее, подводные исследования выявили, что «Нагато» лежит на морском дне на правом борту под углом 120 градусов вверх дном, корма разбита, т.к. опустилась на дно первой, но, что любопытно, «мостик Ямомото» оказался неповрежденным – надстройка оторвалась и одной стороной зарылась в ил.
С тех пор, «Нагато», как и многие остальные жертвы испытаний покоятся на морском дне, являясь лакомым кусочком для исследователей затонувших судов, кои посещают Бикини с завидным рвением и регулярностью.
Показать полностью
2