


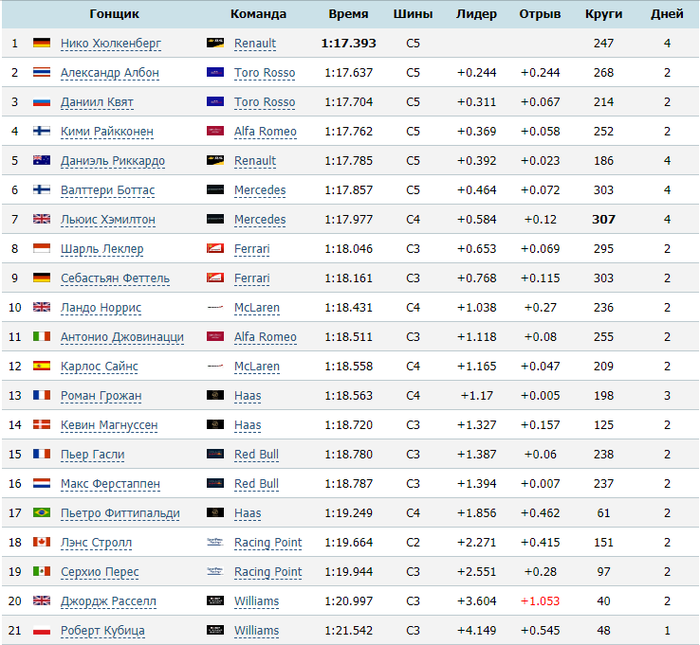
Тесты в Барселоне: лучшие результаты за 4 дня.
Блин, прям не могу, как меня прёт с успеха Торо-Хонды! Понятное дело, что соперники, скорее всего, загасят их уже на следующих тестах, но это прикол из приколов - Албон и Квят в топе!


Пульс "Лучшего", статистика и статистические заблуждения. Часть 3.
(В предыдущих сериях я описал способ скачивания данных о постах с Пикабу, показал графики зависимости количества постов от их рейтингом и график количества постов с определёнными тегами в зависимости от времени, а также обещал рассказать про распространённое статистическое заблуждение, связанное с интерпретацией таких графиков)
Но для начала ещё парочка графиков: зависимость рейтинга поста от времени его публикации. График зависимости рейтинга от дня недели:
Мобильная версия с читаемым шрифтом

Полная версия с мелкими деталями (откройте в отдельном окне на компьютере):

Графики количества постов и среднего рейтинга поста в лучшем на будних днях:


В целом результаты моего исследования снова сходятся с результатами исследования ponyuh и графиками webkitten:
1) Наблюдается чистенькая циклическая зависимость количества постов от времени. Посты, созданные между 13 и 15 часами чаще всего достигают лучшего, и, вероятно, их просто больше, плюс постов стабильно много с 15 до 19. Оно и логично, в 4 утра мало желающих что-нибудь запостить. Расхождение с красивой синусоидой между 16и 20 часами наблюдается по всей видимости из-за распределения читателей Пикабу по России: когда большинство из Москвы и Питера уже отстрелялось, пикабушники из Владивостока только расчехляют длиннопосты.
2) В субботу и воскресенье наблюдаются два пика - утром и вечером. Видимо, первый пик - это посты которые пилили в день до этого до 3 ночи, и которые решили оставить на следующий день, а второй - посты, которые пилили днём в выходной день. В целом же лучшего достигают лишь чуть меньше постов, чем на буднях.
3) На удивление, наибольший рейтинг имеют посты созданные на буднях в 7 утра. Второй наилучший период, чтобы пост поднялся наверх - с 9 до 11 часов. Третий - с 13 до 15. Эти пики очень подозрительно совпадают со временем, когда большинство людей в московском часовом поясе соответственно, встают, приезжают на работу и обедают. Можно даже интерпретировать время с 18 до 20, как время, когда большинство людей возвращаются с работы, но этот пик уже намного слабее.
4) Щедрее всего люди раздают плюсы в среду и четверг утром. Чуть хуже - в понедельник утром. На выходных лучше не поститься! Средний рейтинг заметно меньше. Хоть свободного времени для написания поста больше всего на выходных, уже готовый пост лучше оставить до будней. Как видно из графиков, пикабушникам есть чем заняться, кроме как читать ваши творения.
Чисто ради интереса посмотрим на график рейтинга в зависимости от дня месяца, когда создан пост, и убедимся, что в среднем, раз выходные и праздники накладываются друг на друга, график держится примерно на одном уровне:

Однако бдительные читатели заметят, что мои графики всё же отличаются от графиков ponyuh. Скажем, на его графиках по субботам постов немного больше среднего, а у меня немного меньше. Плюс, на моём графике присутствует подозрительный пик рейтинга в 7 утра. Тут и настало время рассказать, где я вас немного обманул.

Дело в способе создания выборки данных (как вы скорее всего не помните, я скачивал 15 страниц лучшего), а имя этому способу статистической манипуляции - ошибка отбора (selection bias). Ошибка (или намеренное искажение) заключается в том, что фильтрация данных перед использованием очень часто влияет на её статистические показатели.
Примеры:
1) Самый простой пример происходит из известного анекдота: "Интернет-опрос показал, что 1000 из 1000 российских семей пользуются интернетом". Это предложение и кажется нам смешным, потому что даже незнакомому со статистикой человеку очевидно, что сам способ создания опроса (размещение в интернете) предрешил его исход. Но систематическая ошибка отбора далеко не всегда так заметна.
2) Школа А расположена в центре города, в престижном районе, а школа Б - в обычном спальном районе. После проведения ЕГЭ оказалось, что учащиеся школы А написали экзамен в среднем на 10 баллов лучше учащихся школы Б. Означает ли это, что в А лучше учителя? Стоит ли только ради образования своего ребёнка переезжать в центр? Может быть, но всё далеко не так однозначно. Дело в том, что само их географическое положение предрешает, что в школу А будут ходить дети родителей, которые в среднем чаще имеют высшее образование и лучше следят за питанием и развитием своих отпрысков. Чтобы отследить именно положительный эффект школы, следует провести два теста, до и после, а лучше несколько, в ходе обучения.
3) Один из примеров искусственного создания ошибки отбора: если из школы А в предыдущем примере будут дополнительно "убеждать" переводиться детей, про которых ясно, что ЕГЭ они хорошо не напишут.
4) Также такое возможно при проведении недобросовестных научных экспериментов. Например, если создатель лекарств для снижения веса хочет "доказать" эффективность своего препарата, он может набирать контрольную группу на улице, а тестовую - в спортзале. Тем самым он заранее обеспечивает желание тестовой группы сбрасывать вес.
В моём же случае "средний рейтинг больше всего у постов, которые созданы около 7 утра" не равно "средний рейтинг постов, достигших "Лучшего", больше всего у постов, которые созданы около 7 утра". "Средний рейтинг больше всего у "Лиги синего бобра"" не равно "средний рейтинг постов, достигших "Лучшего", больше всего у "Лиги синего бобра"". Допустим, на Пикабу есть 1000 постов с тегом А и 1000 постов с тегом Б. 500 постов А имеют рейтинг 100 каждый (не в Лучшем) и 500 - рейтинг 300 (в Лучшем). 950 постов Б имеют рейтинг 0 (не в Лучшем), 50 - рейтинг 1000 (в Лучшем). Наивный анализ Лучшего показал бы, что Б постят в 10 раз чаще, и рейтинг у таких постов в 3 раза выше, тогда как в реальности происходило бы обратное. Ещё раз, постоянная бдительность!
Значит ли это, что мой анализ постов ничего не стоит? Ну... вряд ли. Как я уже упоминал, результаты большей частью совпадают с результатами ponyuh. Да и в существовании тегов, которые стабильно либо летят на дно, либо поднимаются в самый топ, я слабо верю. Так что просто, если читаете пост на Пикабу, статью в газете или исследование в интернете старайтесь отследить, откуда берутся данные.
Бонусные картинки для тех, кто не поленился дочитать простыню про статистическое искажение: как размещение наилучших постов по определённым тегам зависит от волн хайпа на этот тег. Оказывается, что часто самые крутые посты по тегу создаются не на волне популряности, а следом за нею. Так что если популярность тега прошла, но вы вспомнили классную историю, постите её, не стесняйтесь. Мне интересно, какая здесь причинно-следственная связь? Аудитория лучше воспринимает посты, если они уже когда-то были популярны, или пикабушникам нужно время, чтобы вспомнить/придумать самые интересные истории?




Ну вот пока что и всё. Задавайте вопросы в комментариях. Ссылка на программу и архив с дополнительными картинками была в предыдущем посте. Следующий пост скорее всего будет посвящён аналитике комментариев. Баянометр говорит, что мой пост похож на рисунки анимешных девочек =/
Показать полностью
10

Поиграем в бизнесменов?
Одна вакансия, два кандидата. Сможете выбрать лучшего? И так пять раз.
Пульс "Лучшего", статистика и статистические заблуждения. Часть 2.
Первая часть здесь.
В комментариях к предыдущей части мне советовали вывести распределение количества постов по рейтингу в логарифмическом масштабе. Собственно, вот, обратите внимание на ось Y:
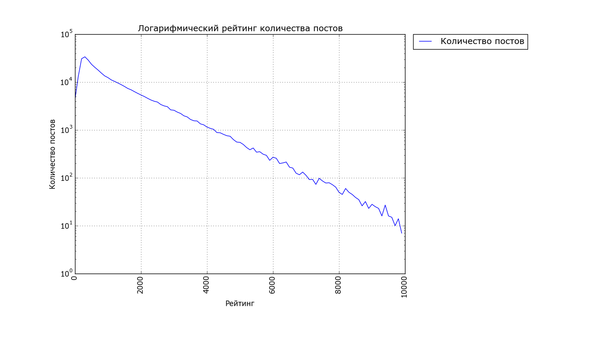
График хорошо согласуется с предложенной моделью, и с графиком в исследовании @ponyuh. Мы видим, что количество постов с заданным рейтингом не просто убывает с увеличением этого рейтинга, а убывает экспоненциально.
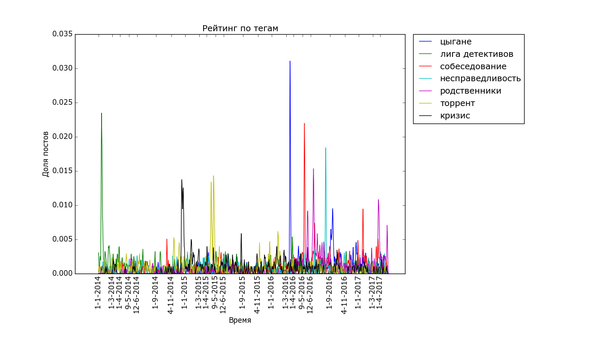
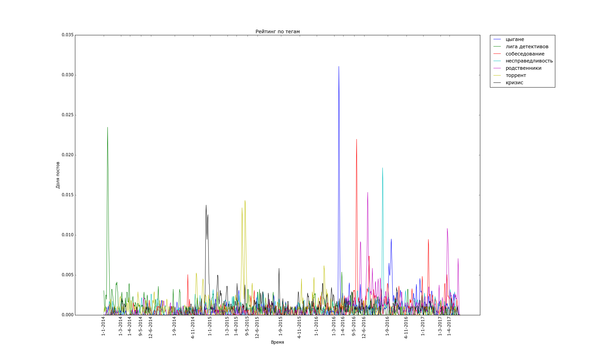
Теперь, посмотрим на временной анализ количества постов с определёнными тегами на Пикабу. Для этого я снова выделил теги, которые встречаются хотя бы 200 раз и подсчитал, сколько постов с этими тегами было в каждый день. Для удобства вывода и сравнения полученные значения были отнормированы: массивы значений для каждого тега были поделены на сумму значений по массиву. Таким образом, график для тега тем выше, чем более неоднородно распределение постов с данным тегом (и не зависит от количества постов с ним). Графики дополнительно немного сглажены для лучшей читабельности узких пиков, и чтобы низкоуровневый шум не портил низ изображения.
Для начала проверка здравого смысла: теги, связанные с праздниками и временами года:
Мобильная версия (большой текст):
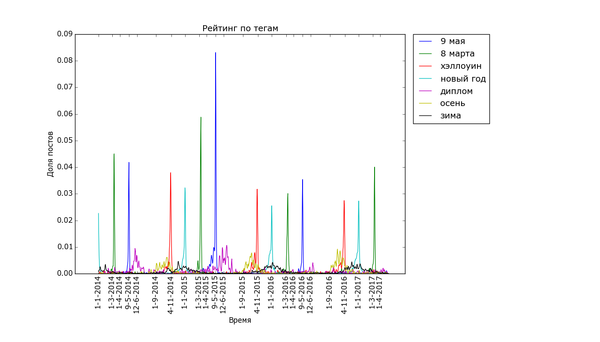
Широкоформатная версия (мелкие детали, откройте в полном окне):
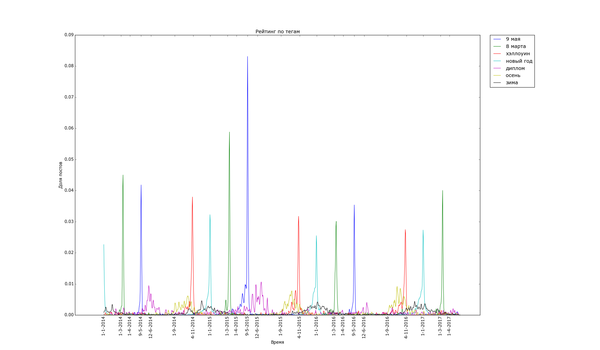
Внизу стабильно плещутся волнами "осень", "зима" и "диплом", распределение постов с ними размазано по соответствующим месяцам. Зато явно видно как примерно за месяц начинают набирать обороты, а затем резко взмывают вверх перед определёнными датами "праздничные" теги. Больше всего выделяется "9 мая" - это график с самым большим перепадом из всех, видимо, сказалось, что в 2015 году было 70 лет победы в Великой Отечественной. Но вообще, хоть постов про девятое мая больше всего, хм, около девятого мая, не сказать, что Пикабу помнит про ветеранов только весной. Графики уверяют, что посты про ветеранов и Великую Отечественную войну иногда достигают "Лучшего" в течение всего года.
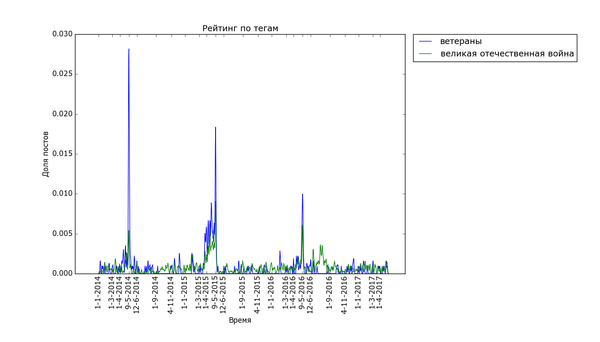
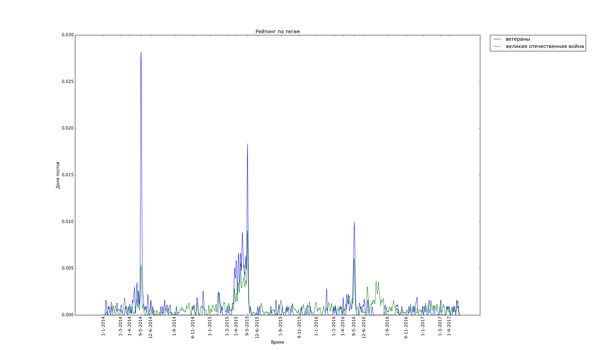
Примерно так же выглядят графики для тегов "Леонардо ди Каприо" и "Оскар":
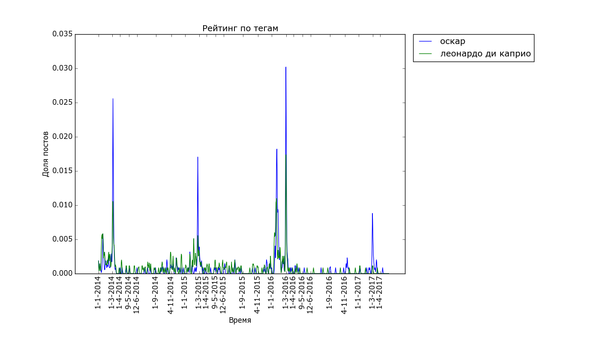
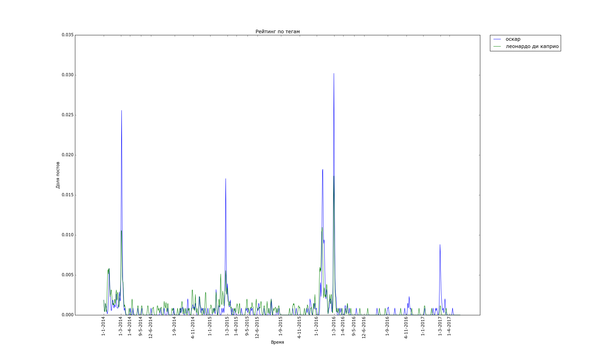
Бедный ди Каприо, после того как ему таки дали злосчастный Оскар, про него совсем перестали вспоминать =(
Пикабу очень не против поделиться своим мнением о политике:
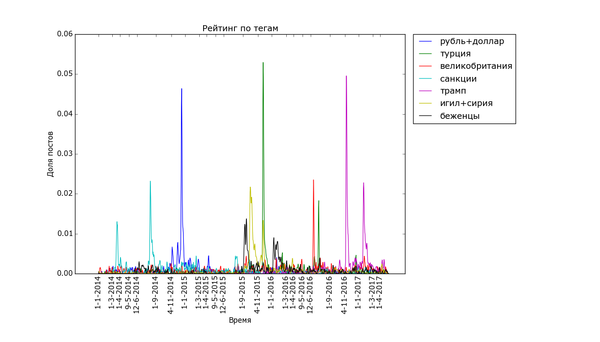
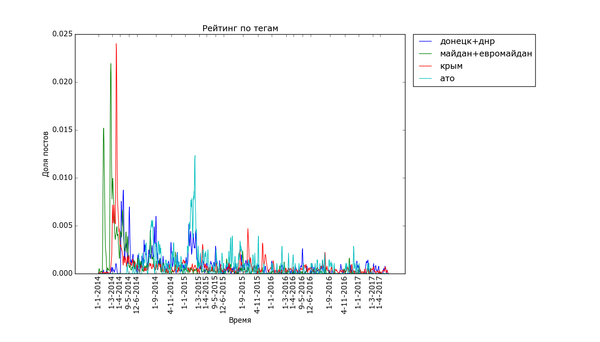
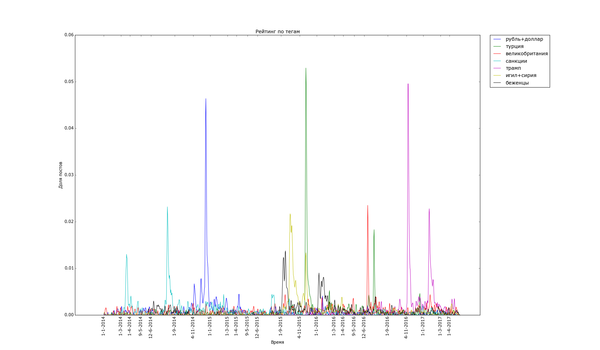
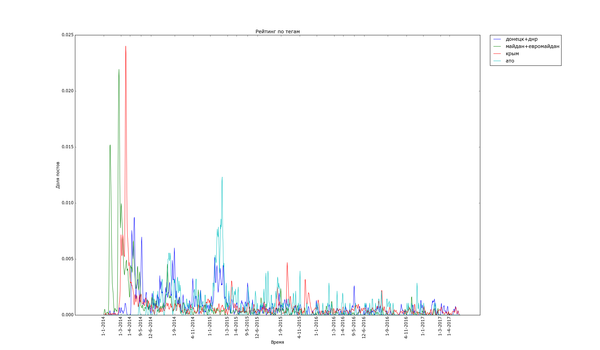
Часто шумиха стихает в течение месяца ("Трамп", "Турция", "Великобритания" (в контексте Brexit), "санкции"), иногда двух ("беженцы", "Сирия"). Украинские теги держатся дольше, но меняют акцент со временем. Впрочем, и они потихоньку сходят на нет.
Графики соответствующие волнам историй на определённую тематику ещё уже. К тому же не все из них так явно выражены. Волна тега "трамвай" всего в пять раз выше уровня шума (частоты появления постов с тегом "трамвай" в остальное время):

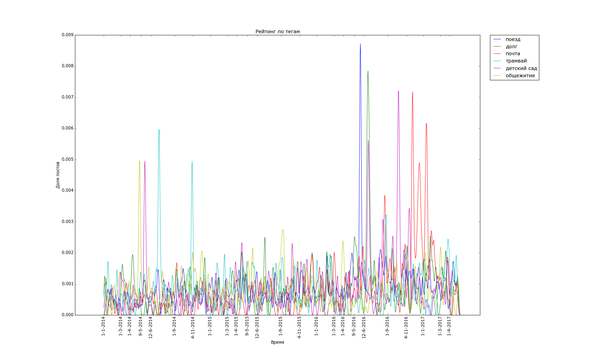
Накладывание графиков друг на друга позволяет сказать, что волны историй не соседствуют друг с другом. Единственное исключение - теги "долг" и "детский сад", возникшие из шума одновременно летом 2016. (Возможно, есть какие-то малые волны, которые соседствуют с большими, но не попали на график).
Графики, соответствующие событиям в гик-культуре, бывают как острыми, так и размазанными по времени:
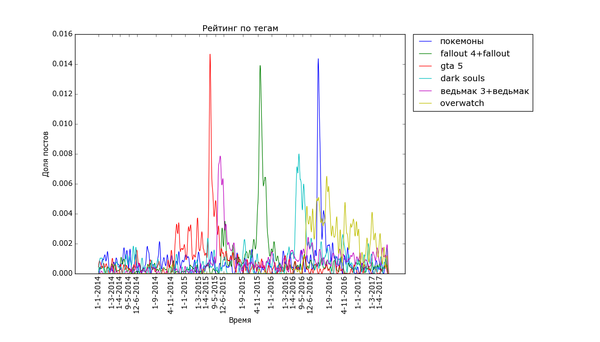
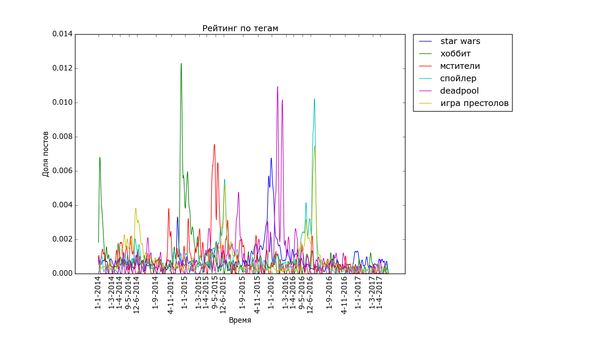
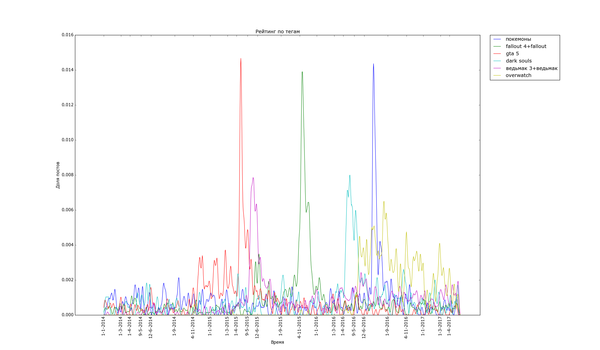
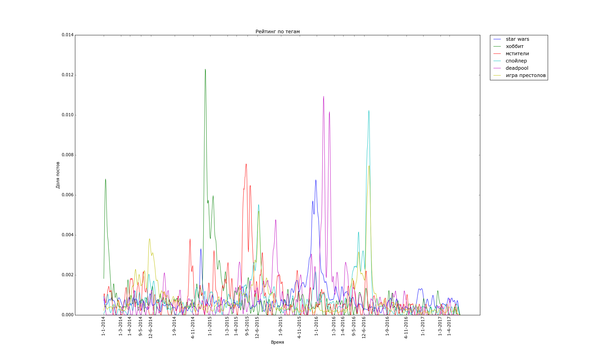
Особенно поразителен узкий вжух "покемонов". Помните, такая игра была, а? За рубежом её так долго ждали... "Overwatch", напротив, демонстрирует поразительную стабильность. "Star Wars" и "Мстители" демонстрируют как сравнительно медленный подъём, так и затухание. Также обратите внимание на интересную форму - двойной пик - некоторых графиков. Особенно сильно это заметно с "Дэдпулом" и "Хоббитом". По всей видимости, это соответствует двум датам выхода фильмов - в России и за рубежом. Также это может быть связано с тем, что первая волна зрителей/игроков своими положительными отзывами создаёт вторую волну.
Подытожу:
3) Если вы почему либо хотите "попасть в волну", то следует правильно рассчитывать "мощность" горячего тега.
Волны кулстори на определённую тематику на Пикабу имеют наименьших срок жизни (порядка 15 дней). Сиюминутные политические и общественные события немногим лучше (около месяца). Более продолжительные события или новые однопользовательские игры (не мобильные с дополненной реальностью) могут протянуть несколько месяцев. Больше всего живут раскрученные франшизы и мультиплеерные игры.
4) Не стоит форсить свою линейку историй, если Пикабу уже увлечён чем-то другим. Лучше подождать недолго, пока шумиха утихнет.
5) Иногда получение Оскара может повредить вашей популярности.
Извини, Пикабу. Что-то я не рассчитал длину поста и своё время. Пост с общим временным анализом по дням недели и рассказом про некорректное использование статистики будет завтра или чуть позже. Но если вдруг кому интересно, выложу ссылку на программу и данные сегодня, как и обещал.
Исходный код. Для работы нужен Python 3.4 с установленными numpy и matplotlib; для работы обходчика веб-страниц нужен ещё и scrapy. Чтобы скачать сырые данные, настройте и запустите scraper.py (лучше на ночь). После этого в корне проекта появится data.pkl. Для анализа и вывода данных - main.py.
Чтобы не скачивать все данные с Пикабу и не вычислять всё с нуля, скачайте кэш-файлы и разархивируйте их рядом с main.py. Осторожно, в функциях проекта используется очень наивная реализация кэша. Если бы будете запускать функции с соответствующей аннотацией, не забудьте вручную удалить соответствующий файл кэша.
Архив со всеми графиками, в том числе и теми, что будут в следующем посту.
Если у вас есть предложения, график или статистику чего вы бы хотели увидеть, пишите в комментариях.
Показать полностью
19
Пульс "Лучшего", статистика и статистические заблуждения. Часть 1.
Привет, Пикабу!
Я программист, и моё хобби - статистика, анализ данных и машинное обучение. Чтобы отвлечься от пережёвывания однообразных банковских и социальных данных, пару недель назад я расковырял данные Пикабу о лучших постах. Я хотел бы поделиться с вами результатами этого небольшого исследования и разобрать на его примере один типичный случай неправильного применения статистики. Попробуйте обнаружить её в ходе повествования.
Сначала немного о способе получения информации. К сожалению, доступ к полной статистике посещения, кликов и размещения постов имеет разве что админ, и вряд ли со мной поделится. Поэтому пришлось довольствоваться тем, что есть, а именно кодом страниц Пикабу. Его можно увидеть в браузере, нажав правой кнопкой мыши на страницу и выбрав "Просмотреть код" или посмотрев, что приходит в ответ на запрос страницы (F12 в Chrome). Эту длинную HTML-простыню несложно распилить на сегменты, отвечающие за каждый пост, а из них, в свою очередь, наковырять чего-нибудь интересного. Разумеется, сохранять все данные вручную, было бы невероятной тратой сил, поэтому я написал бота, обходящего "Лучшее". К счастью, адрес страниц Пикабу имеет простой формат "http://pikabu.ru/best/XX-XX-XXXX?page=YY".

Выкачивать всю информацию, включающую в себя многомегабайтные картинки, было бы грустно для свободного места на моём компьютере, поэтому пока что я остановился только на базовых данных: названии поста, тегах, рейтинге, количестве комментариев и дате отправки. Также я решил, что абсолютно все посты меня не интересуют, поэтому ограничился лишь 15 страницами "Лучшего" каждого дня начиная с 1 января 2014 года по 1 апреля 2017. Вышло 361604 записи.
Даже из этих простеньких данных можно состряпать что-нибудь интересное. Для начала давайте просто посмотрим на количество постов с различным рейтингом. По вертикали отложен рейтинг, толщина жёлтой области по горизонтали - количество постов с данным рейтингом, жирные красные точки - единичные посты с высоким рейтингом.
Мобильная версия с читабельным текстом:
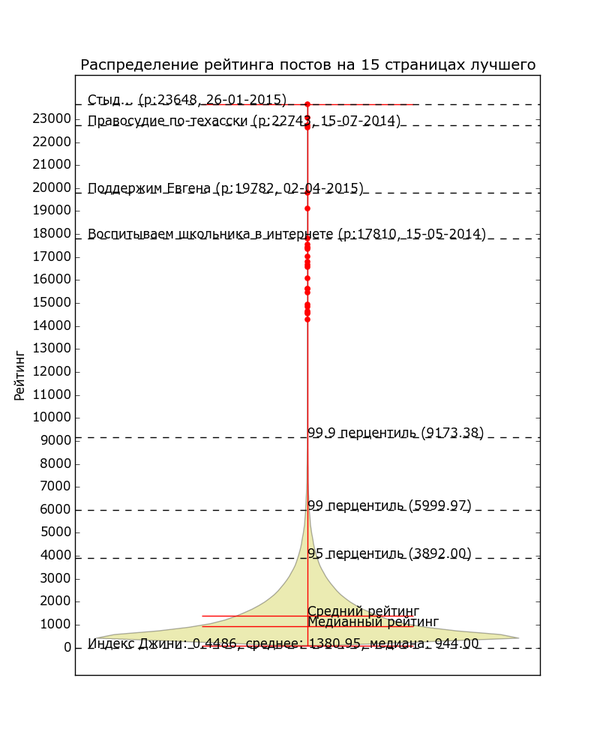
Версия с высоким разрешением и большим количеством информации (откройте в полное окно во избежание шакалов):
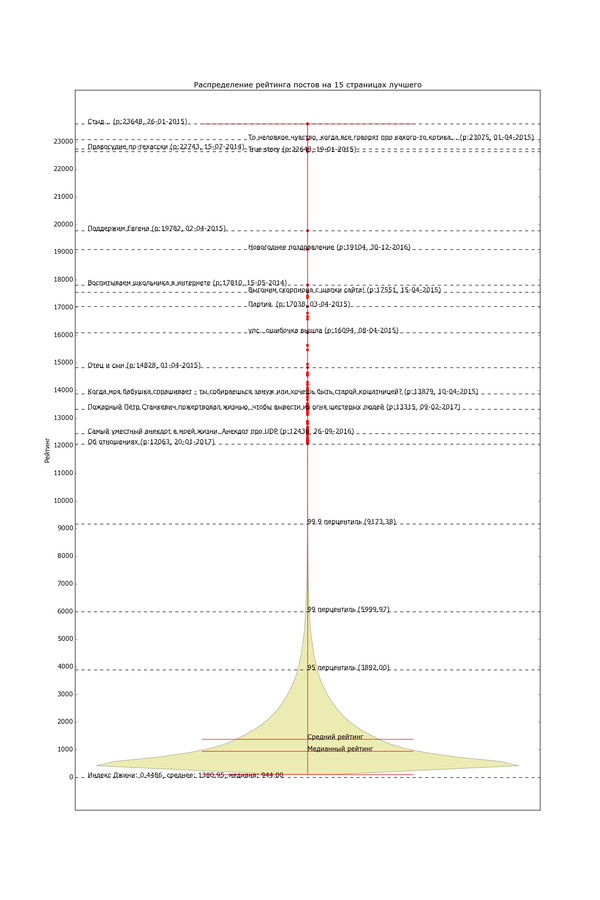
Невооружённым глазом видно, как график очень быстро сужается. Распределение рейтинга по постам довольно неравномерно. Половина постов в "Лучшем" имеет рейтинг в диапазоне от 0 до 944 (жирный кусок "юлы"). Если сложить весь рейтинг и поделить поровну, получится 1380 рейтинга на пост. Только 5% постов в лучшем имеют рейтинг выше 3892 (95 перцентиль) и лишь 1% - выше 6000. Хоть график тянется довольно высоко, его высокие уровни почти не населены. В верхней половине графика находятся 80 постов "элиты" с рейтингом выше 12 тысяч (красные точки); остальная 361 тысяча - в нижней половине. Вот такое вот неравенство.
Проанализировав данные при помощи стандартной метрики неравенства, индекса Джини, я получил значение в ~0.45. 0 означало бы абсолютно одинаковое распределение рейтинга, 1 - абсолютное неравенство. Для сравнения стоит заметить, что неравенство распределения доходов россиян по индексу Джини оценивается в ~0.41, американцев в ~0.43, французов в ~0.31, а чилийцев - в ~0.55.
Вообще такой график соответствует часто встречающемуся в различных системах закону "богатые становятся богаче". На Пикабу такое поведение связано с тем, что разные читатели просматривают разное количество страниц. Лишь небольшая их доля отлавливает посты в свежем. Только если посту повезло, и рыцари свежего одарили его плюсам, он "получает доступ" к более широкой аудитории людей, пролистывающих "Горячее" до конца. Если и там он поднялся, то свою порцию плюсов накидывают обитатели первых страниц "Лучшего" и "Горячего", а затем и просто люди заходящие только на первую страницу "Лучшего". Разумеется публика не столь стратифицирована, кто-то, кто обычно сидит в свежем, может сегодня только посмотреть пару страниц "Горячего", а кто-то, сидящий в "Горячем", может вовсе не зайти на Пикабу. Тем не менее, "подъём" поста - многоступенчатый и самоподдерживающийся процесс с положительной обратной связью (чем популярнее пост, тем он станет ещё популярнее в будущем). Качество контента играет роль, но если на каком-то этапе из-за случайных флуктуаций иссякает "топливо", то увы. Хотя вообще и пост может оказаться неоч для "Лучшего", это да.
Что самое интересное, "топ топа" не особо отличается от случайных постов в лучшем. То есть, они довольно хорошие, без треша, но за исключением нескольких постов от 0x00, вряд ли бы я бы опознал их на общем фоне:
То неловкое чувство, когда все говорят про какого-то котика...
Воспитываем школьника в интернете
Выгоним Скорпиона с шапки сайта
Наверное, это можно интерпретировать так: шанс попасть на самый верх есть у каждого, но его можно здорово повысить умением создавать длинные гифки-мультики.
Теперь посмотрим на распределение рейтинга по тегам. Для полученных данных я подсчитал, сколько раз используется каждый тег. Для тегов, встречающихся более чем в 200 постах, вычислил средний рейтинг постов с этим тегом. В итоге:
Мобильная версия:
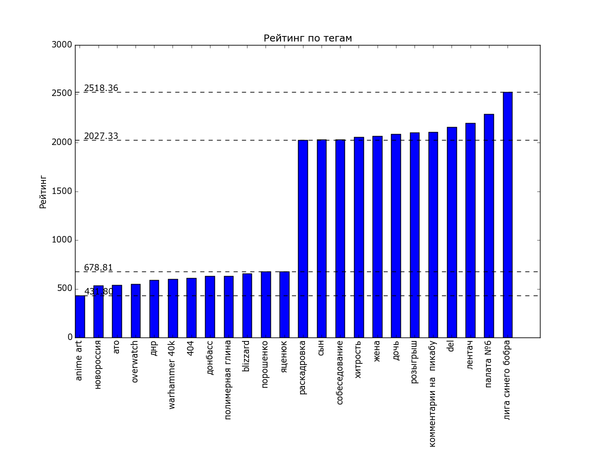
Полная версия:
Ииии в самом топе по рейтингу... с уверенным отрывом... "лига синего бобра". Хах. Кто бы мог подумать. Я один не замечал этот тег раньше? Второе и третье место занимают "палата №6" и "лентач". Вообще состав тегов правой половины графика намекает на то, что на Пикабу ценятся кулстори из личной жизни ("сын", "отец", "дочь", "жена"), с работы ("клиенты", "собеседование", "начальник") и из понятной всем повседневной жизни ("почта России", "очередь", "яжмать", "азиаты" (?)). Не стесняется Пикабу таскать контент с bash im и заниматься самолюбованием ("комментарии на Пикабу").
На донышке находится политота - туда ей и дорога! - аниме, некоторые игры и хобби. Рискну предположить, что политика просто всех так достала, что большинство её уже просто пролистывает или помещает тег в игнор. Остальное - просто слишком специализированное, так что если и выходит в "Лучшее", то далеко не уходит просто за счёт того, что на Пикабу слишком мало людей, которым был бы интересен, скажем, рисунок карандашом.
Прошлый анализ никак не учитывал, что пост может быть одновременно отмечен несколькими тегами, входящими в перечень (скажем, и "blizzard", и "собеседование"). Скажем, если аудитория не любит "тег 1" и любит "тег 2", при этом "тег 2" почти всегда встречается с "тегом 1" и постов с "тегом 1" гораздо больше, то это может привести к "занижению ценности" "тега 2". Чтобы оценить степень проблемы, посмотрим на матрицу корреляции самых популярных тегов:
Мобильная версия:
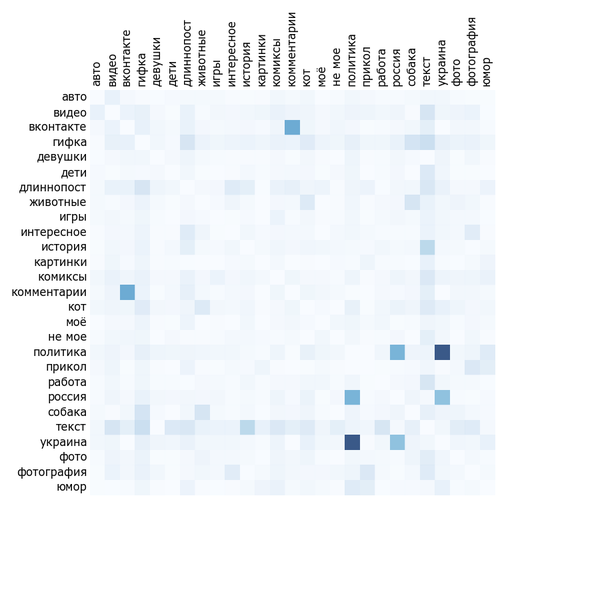
Полная версия:
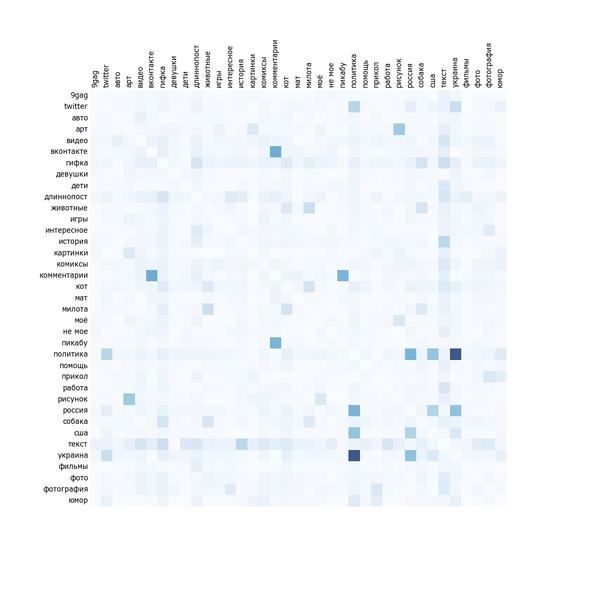
Чем синее квадрат на пересечении, тем чаще эти два тега встречаются вместе. Очевидно, что рисунок симметричен. Хоть тег сам с собой встречается постоянно, диагональ специально сделана белой для читабельности.
В общем-то анализ не слишком показателен. Тегов всего 37 на большой картинке. Невооружённым глазом видна плеяда "политика", "Украина", "США", "Россия", "twitter". "Милота", "собаки", "коты" и "животные" часто встречаются вместе. Также можно увидеть, что "моё", "рисунок" и "арт" часто встречаются вместе. Комментарии чаще всего с Пикабу или ВКонтакте. Текст коррелирует вообще со всем, причём "не моего" текста на Пикабу больше, чем "моего". Будем надеяться, что влияние статистических артефактов окажется малым.
Кто-то может сказать, что вышеперечисленные умозаключения довольно капитанские. Я же отвечу, что приятно, когда формальный анализ сходится с интуитивными предположениями.
Итак, промежуточные выводы:
1) Постов с рейтингом выше шести тысяч исключительно мало.
1.5) Тем не менее, повезти может каждому, было бы начальное внимание к посту (от 100 плюсов).
1.75) Коэффициент везения зависит от качества контента и от количество "0" в нике.
2) Для более высокого рейтинга постов лучше постить что-то, что понятно каждому.
2.5) Но не политику. Кармалюбствовать на политике не выгодно.
В следующих частях: временной анализ (общий и по тегами), рассказ про статистическое искажение, ссылка на исходный код.
Показать полностью
7

Статистика рулит!
Мы в составе 159 лучших!!!
http://total-rating.ru/1902-rost-promyshlennogo-proizvodstva...

Чартовое
В этом посте я сделал списки лучших авторов в различных номинациях. Использовались все посты с тегом "cynicmansion". Всего таковых 809. Авторов 308.
Лучший пост:
឴ ឴ ឴ ឴ ឴ ឴ ឴Автор ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴Рейтинг ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴Пост1) MathGeek ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴14 040 ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴Правильные два косаря.
2) w1LdF1re ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴7 124 ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴Пранк
3) cynicmansion ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴6 874 ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴Призывательское
4) Cosmocrator ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴6 871 ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴Желанное
5) SolderingTool ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴6 553 ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴Геймерское
Сумма рейтингов постов:
឴ ឴ ឴ ឴ ឴ ឴ ឴Автор ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴Рейтинг ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴Количество
1) cynicmansion ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴288 523 ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴136
2) w1LdF1re ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴66 704 ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴119
3) Cosmocrator ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴32 897 ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ 18
4) Loma ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴14 999 ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴26
5) MathGeek ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴14 040 ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴1
Количество постов:
឴ ឴ ឴ ឴ ឴ ឴Автор ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴Количество ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴Средний рейтинг
1) cynicmansion ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴136 ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴2 121
2) w1LdF1re ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴119 ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴561
3) notos007 ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴32 ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴124
4) Loma ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴26 ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴577
5) SoeThizng ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴18 ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴203
6) Cosmocrator ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴18 ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴ ឴1 828
И бонус в комментариях, поклонники
Показать полностью
Сможете найти на картинке цифру среди букв?
Справились? Тогда попробуйте пройти нашу новую игру на внимательность. Приз — награда в профиль на Пикабу: https://pikabu.ru/link/-oD8sjtmAi


Пикабу. Чем дышит Лучшее (Часть 5, последняя - Авторы и чтиво)
Продолжим препарировать Лучшее. Ранее были посты:
Часть1: http://pikabu.ru/story/pikabu_chem_dyishit_luchshee_chast_1_...
Часть2: http://pikabu.ru/story/pikabu_chem_dyishit_luchshee_chast_2_...
Часть3: http://pikabu.ru/story/pikabu_chem_dyishit_luchshee_chast_3_...
Часть4: http://pikabu.ru/story/pikabu_chem_dyishit_luchshee_chast_4_...
1. TOP-20 оригинальных авторов текстов, имеющих более 10 авторских постов (условие выборки: теги "моё" и "текст")
1.1 Сортировка по среднему рейтингу поста

Автор с наибольшим средним рейтингом поста, естественно - Админ, ибо слово админово весомо, убедительно, логично и лучше его прочитать. :-)
Если вы ищете интересного, оригинального чтива, то на этих авторов можно подписываться не задумываясь - качество написанного люто зашкаливает.
1.2 Сортировка по суммарному рейтингу постов

Вот так выглядит список лучших текстовых авторов по абсолютному значению рейтинга, написанных ими постов. Никаких тебе миллионов рейтинга - лишь легкие килотонны. :-)
И для ознакомления с полным (а не только текстовым) рейтингом оригинальных авторов:
2. TOP-20 оригинальных авторов по суммарному рейтингу постов, имеющим более 10 авторских постов (условие выборки: тег "моё")

Тут все узнаваемые лица, для тех кто хорошо знает Лучшее. :-)
Все. Проект закончен.
Показать полностью
3