ПРЕДИСЛОВИЕ
Международная конференция по машинному обучению (International Conference on Machine Learning, или ICML) — одна из самых престижных научных конференций в области искусственного интеллекта (другая — Конференция по нейронным системам обработки информации, или NeurIPS). В 2020 году процент принятых в ICML статей составил 21,8% (22,6% в 2019 году) — в общей сложности было принято 1088 статей из 4990 представленных. Используя материалы конференции (ICML 2020), мы изучили каждую из принятых статей и составили список авторов и связанных с ними организаций, а затем рассчитали индекс публикаций для каждой из этих организаций (см. далее раздел “методология”). Самое интуитивное объяснение понятия “индекс публикаций” — с точки зрения эквивалентных полных статей: индекс публикаций Google, равный 92,2, можно интерпретировать так, как если бы Google опубликовал 92,2 полных статей на ICML 2020.
Мы начнем этот анализ с подробностей методологии, перейдем к рейтингам исследований искусственного интеллекта на ICML 2020, затем покажем интересную описательную статистику, обсудим изменения среди лидеров ICML 2019 и ICML 2020 и, наконец, поделимся ссылкой на наши файлы с данными.
МЕТОДОЛОГИЯ
Методология нашего индекса публикаций получила вдохновение от индекса журнала Nature (Nature Index):
Для определения вклада страны, региона или учреждения в статью и обеспечения того, чтобы они не учитывались более одного раза, индекс Nature использует дробный подсчет (ДП), который учитывает долю авторства по каждой статье. Общая сумма ДП, доступная для каждой статьи, равна 1, и она распределяется между всеми авторами при условии, что каждый из них внес свой вклад в равной степени. Например, статья с 10 авторами означает, что каждый автор получает оценку 0.1. Для авторов, связанных более чем с одним учреждением, авторский ДП затем делится поровну между каждым учреждением. Общая сумма ДП для учреждения рассчитывается путем суммирования ДП для отдельных аффилированных авторов. Этот процесс аналогичен для стран/регионов, хотя и осложняется тем фактом, что некоторые учреждения имеют зарубежные лаборатории, которые будут учитываться при подсчете итоговых данных по принимающей стране/региону.
Единственная разница заключается в том, что наш индекс публикаций учитывает зарубежные лаборатории по стране/региону штаб-квартиры (а не принимающей стране/региону). Это спорный момент, но мы считаем, что такой подход лучше отражает передачу интеллектуальной собственности и соответствующую выгоду, получаемую штаб-квартирой, а не местной лабораторией.
Вот пример расчета индекса публикации. Если у статьи пять авторов — три из Массачусетского технологического института (MIT), один из Оксфордского университета и один из Google, то каждый автор получит 1/5 от одного балла, или 0,2. В результате только из этой статьи MIT увеличит свой индекс публикаций на 3*0,2=0,6 пункта, Оксфордский университет увеличит свой индекс на 0,2, а Google добавит 0,2. Поскольку MIT базируется в Соединенных Штатах, MIT увеличит индекс публикаций США на 0,6. Аналогичным образом, поскольку Оксфордский университет базируется в Великобритании, категория “Европейская экономическая зона + Швейцария” увеличится на 0,2. Наконец, Google является многонациональной корпорацией со штаб-квартирой в Соединенных Штатах, поэтому Соединенные Штаты увеличат свой индекс публикаций еще на 0,2, а общее увеличение составит 0,8. Если у автора несколько аффилированных организаций, мы разделяем его долю на каждую из этих организаций. Например, в приведенном выше случае, если бы последний автор перечислил две аффилированных организации, Google и Стэнфордский университет (а не только Google), то и Google, и Стэнфордский университет получат дополнительные 0,2/2=0,1 балла.
РЕЙТИНГ МИРОВЫХ ЛИДЕРОВ В СФЕРЕ ИСКУССТВЕННОГО ИНТЕЛЛЕКТА НА ICML 2020
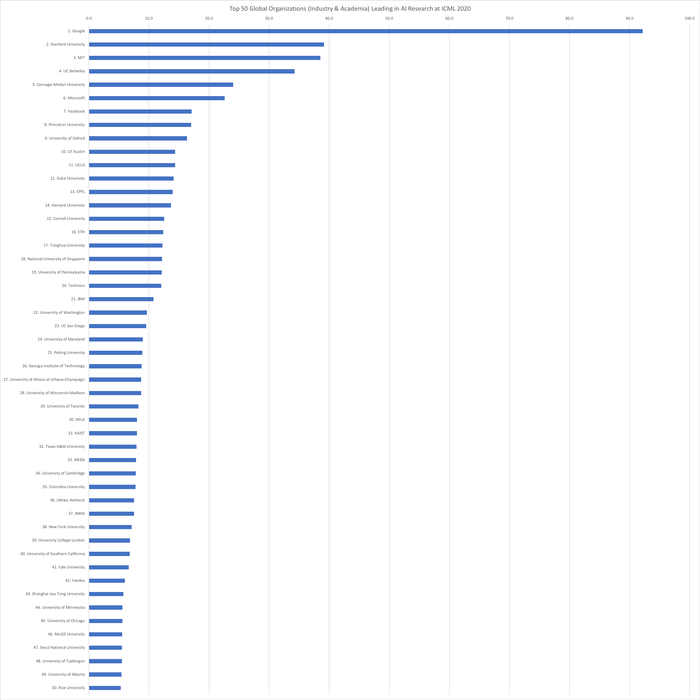
Топ-50 глобальных организаций (коммерческие и научные организации), лидирующих в исследованиях искусственного интеллекта на ICML 2020 (с индексами публикаций):
1. Google (США) — 92,2
2. Стэнфордский университет (США) — 39,2
3. Массачусетский технологический институт (США) — 38,5
4. Калифорнийский университет в Беркли (США) — 34,2
5. Университет Карнеги-Меллона (США) — 24,0
6. Microsoft (США) — 22,6
7. Facebook (США) — 17,1
8. Принстонский университет (США) — 17,0
9. Оксфордский университет (Великобритания) — 16,3
10. Техасский университет в Остине (США) — 14,3
11. Калифорнийский университет в Лос-Анджелесе (США) — 14,3
12. Университет Дьюка (США) — 14,1
13. Федеральная политехническая школа Лозанны (Швейцария) — 13,9
14. Гарвардский университет (США) — 13,7
15. Корнельский университет (США) — 12,6
16. Швейцарская высшая техническая школа Цюриха (Швейцария) — 12,4
17. Университет Цинхуа (Китай) — 12,3
18. Национальный университет Сингапура (Сингапур) — 12,2
19. Пенсильванский университет (США) — 12,1
20. Технион (Израиль) — 12,1
21. IBM (США) — 10,7
22. Вашингтонский университет (США) — 9,7
23. Калифорнийский университет в Сан-Диего (США) — 9,5
24. Мэрилендский университет (США) — 9,0
25. Пекинский университет (Китай) — 8,9
26. Технологический институт Джорджии (США) — 8,8
27. Иллинойский университет в Урбана-Шампейне (США) — 8,7
28. Висконсинский университет в Мадисоне (США) — 8,7
29. Университет Торонто (Канада) — 8,3
30. MILA — Институт обучающихся алгоритмов Монреаля (Канада) — 8,0
31. KAIST — Корейский институт передовых технологий (Южная Корея) — 8,0
32. Техасский университет A&M (США) — 7,9
33. RIKEN — Институт физико-химических исследований (Япония) — 7,8
34. Кембриджский университет (Великобритания) — 7,8
35. Колумбийский университет (США) — 7,8
36. Массачусетский университет в Амхерсте (США) — 7,5
37. INRIA — Государственный институт исследований в информатике и автоматике (Франция) — 7,5
38. Нью-Йоркский университет (США) — 7,1
39. Университетский колледж Лондона (Великобритания) — 6,8
40. Университет Южной Калифорнии (США) — 6,8
41. Йельский университет (США) — 6,6
42. Яндекс (Россия) — 6.0
43. Шанхайский Университет Цзяо Тун (Китай) — 5,7
44. Университет Миннесоты (США) — 5,6
45. Чикагский университет (США) — 5,6
46. Университет Макгилла (Канада) — 5,5
47. Сеульский национальный университет (Южная Корея) — 5,5
48. Тюбингенский университет (Германия) — 5,5
49. Университет Альберты (Канада) — 5,4
50. Университет Райса (США) — 5,3
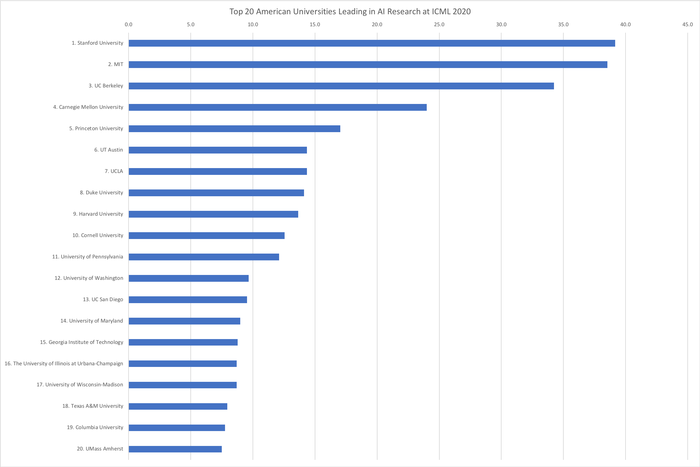
Топ-20 американских университетов, лидирующих в исследованиях искусственного интеллекта на ICML 2020 (с индексами публикаций):
1. Стэнфордский университет — 39,2
2. Массачусетский технологический институт — 38,5
3. Калифорнийский университет в Беркли — 34,2
4. Университет Карнеги-Меллона — 24,0
5. Принстонский университет — 17,0
6. Техасский университет в Остине — 14,3
7. Калифорнийский университет в Лос-Анджелесе — 14,3
8. Университет Дьюка — 14,1
9. Гарвардский университет — 13,7
10. Корнельский университет — 12,6
11. Пенсильванский университет — 12,1
12. Вашингтонский университет — 9,7
13. Калифорнийский университет в Сан-Диего— 9,5
14. Мэрилендский университет — 9,0
15. Технологический институт Джорджии — 8,8
16. Иллинойский университет в Урбана-Шампейне — 8,7
17. Висконсинский университет в Мадисоне — 8,7
18. Техасский университет A&M — 7,9
19. Колумбийский университет — 7,8
20. Массачусетский университет в Амхерсте — 7,5
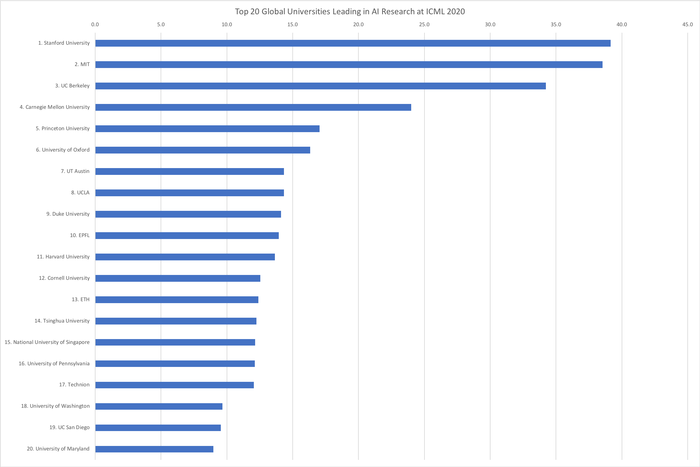
Топ-20 университетов мира, лидирующих в исследованиях искусственного интеллекта на ICML 2020 (с индексами публикаций):
1. Стэнфордский университет (США) — 39,2
2. Массачусетский технологический институт (США) — 38,5
3. Калифорнийский университет в Беркли (США) — 34,2
4. Университет Карнеги-Меллона (США) — 24,0
5. Принстонский университет (США) — 17,0
6. Оксфордский университет (Великобритания) — 16,3
7. Техасский университет в Остине (США) — 14,3
8. Калифорнийский университет в Лос-Анджелесе (США) — 14,3
9. Университет Дьюка (США) — 14,1
10. Федеральная политехническая школа Лозанны (Швейцария) — 13,9
11. Гарвардский университет (США) — 13,7
12. Корнельский университет (США) — 12,6
13. Швейцарская высшая техническая школа Цюриха (Швейцария) — 12,4
14. Университет Цинхуа (Китай) — 12,3
15. Национальный университет Сингапура (Сингапур) — 12,2
16. Пенсильванский университет (США) — 12,1
17. Технион (Израиль) — 12,1
18. Университет Вашингтона (США) — 9,7
19. Калифорнийский университет в Сан-Диего (США) — 9,5
20. Мэрилендский университет (США) — 9,0
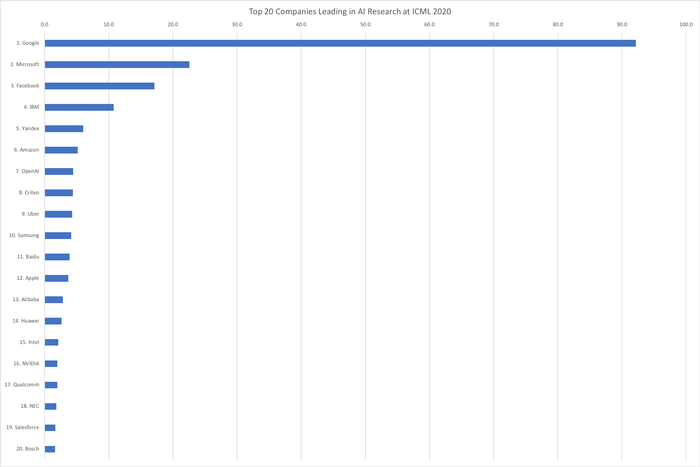
Топ-20 глобальных компаний, лидирующих в исследованиях искусственного интеллекта на ICML 2020 (с индексами публикаций):
1. Google (США) — 92,2
2. Microsoft (США) — 22,6
3. Facebook (США) — 17,1
4. IBM (США) — 10,7
5. Яндекс (Россия) — 6,0
6. Amazon (США) — 5,2
7. OpenAI (США) — 4.4
8. Criteo (Франция) — 4,4
9. Uber(США) — 4,3
10. Samsung (Южная Корея) — 4,2
11. Baidu (Китай) — 3,9
12. Apple (США) — 3,7
13. Alibaba (Китай) — 2,8
14. Huawei (Китай) — 2,6
15. Intel (США) — 2,1
16. NVIDIA (США) — 2,0
17. Qualcomm (США) — 2,0
18. NEC (Япония) — 1,8
19. Salesforce (США) — 1,7
20. Bosch (Германия) — 1,6
ДАЛЬНЕЙШИЙ АНАЛИЗ
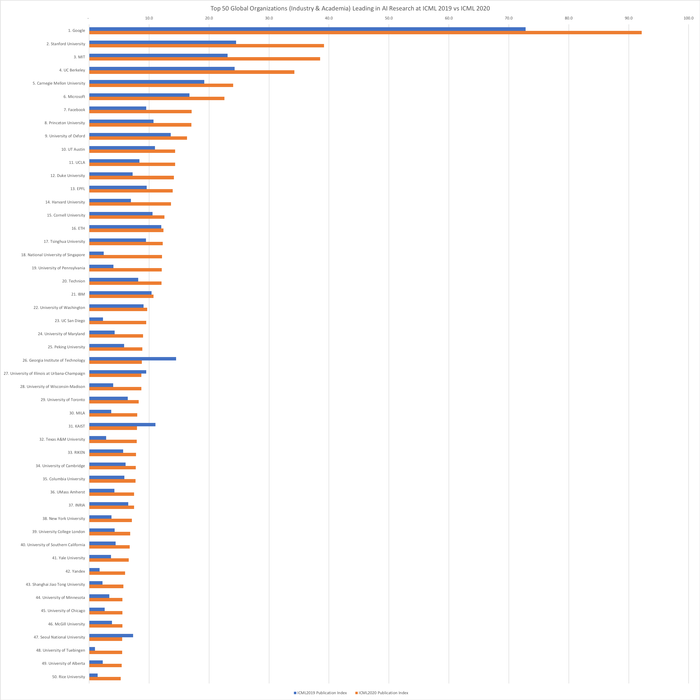
Top-50 глобальных организаций (коммерческие и научные организации) — сравнение количества статей на ICML 2019 и ICML 2020 (с индексами публикаций):
1. Google: +19,4
2. Стэнфордский университет: +14,7
3. Массачусетский технологический институт: +15,4
4. Калифорнийский университет в Беркли: +10,0
5. Университет Карнеги-Меллона: +4,8
6. Microsoft: +5,9
7. Facebook: +7.6
8. Принстонский университет: +6,3
9. Оксфордский университет: +2,7
10. Техасский университет в Остине: +3,4
11. Калифорнийский университет в Лос-Анджелесе: +5,9
12. Университет Дьюка: +6,9
13. Федеральная политехническая школа Лозанны: +4,3
14. Гарвардский университет: +6,7
15. Корнельский университет: +2,0
16. Швейцарская высшая техническая школа Цюриха: +0,3
17. Университет Цинхуа: +2,8
18. Национальный университет Сингапура: +9,7
19. Пенсильванский университет: +8,1
20. Технион: +3,9
21. IBM: +0.3
22. Вашингтонский университет: +0,6
23. Калифорнийский университет в Сан-Диего: +7.2
24. Мэрилендский университет: +4,7
25. Пекинский университет: +3,1
26. Технологический институт Джорджии: -5,7
27. Иллинойский университет в Урбана-Шампейне: -0,8
28. Висконсинский университет в Мадисоне: +4,7
29. Университет Торонто: +1,8
30. MILA — Институт обучающихся алгоритмов Монреаля: +4.3
31. KAIST — Корейский институт передовых технологий: -3.1
32. Техасский университет A&M: +5,1
33. RIKEN — Институт физико-химических исследований: +2.2
34. Кембриджский университет: +1,7
35. Колумбийский университет: +1,9
36. Массачусетский университет в Амхерсте: +3,3
37. INRIA — Государственный институт исследований в информатике и автоматике: +1,0
38. Нью-Йоркский университет: +3,4
39. Университетский колледж Лондона: +2,6
40. Университет Южной Калифорнии: +2,4
41. Йельский университет: +3,0
42. Яндекс: +4.3
43. Шанхайский Университет Цзяо Тун: +3,5
44. Университет Миннесоты: +2,2
45. Чикагский университет: +3,0
46. Университет Макгилла: +1,7
47. Сеульский национальный университет: -1,8
48. Тюбингенский университет: +4,5
49. Университет Альберты: +3,2
50. Университет Райса: +3,9
Облако слов названий статей на ICML 2020:
ОБСУЖДЕНИЕ
Давайте посмотрим, что изменилось в авторстве статей на ICML 2019 и ICML 2020 (данные за 2019 год см. в нашем рейтинге искусственного интеллекта на ведущих конференциях за 2019 год, где мы объединили статистику по NeurIPS 2019 и ICML 2019). Как видно в статистике, пятью ведущими мировыми организациями, лидирующими в исследованиях искусственного интеллекта, по-прежнему являются Google, Стэнфордский университет, Массачусетский технологический институт, Калифорнийский университет в Беркли и Университет Карнеги-Меллона. Каждый из них значительно увеличил свой индекс публикаций на ICML 2020 по сравнению с ICML 2019: Google опубликовал эквивалент дополнительных 19,4 статей на ICML 2020, Стэнфордский университет вырос на 14,7, Массачусетский технологический институт вырос на 15,4, Калифорнийский университет в Беркли вырос на 10,0, а Университет Карнеги-Меллона вырос на 4,8. Как и в гонке Красной Королевы Льюиса Кэрролла, ведущие исследователи каждый год вынуждены публиковать всё больше статей, чтобы сохранить своё лидерство.
«Нужно бежать со всех ног, чтобы только оставаться на месте, а чтобы куда-то попасть, надо бежать как минимум вдвое быстрее!». (Льюис Кэрролл)
ДАННЫЕ
Поскольку конференции не публикуют данные о статьях в стандартной форме, нам пришлось делать анализ вручную (анализ HTML, преобразования в Python, стандартизация названий организаций и исправление опечаток авторов, объединение в сводную таблицу). Если Вы обнаружите какие-либо ошибки, пожалуйста, напишите нам, и мы будем рады их исправить. Если Вы хотите скачать наш файл с данными, он размещен здесь. Желаем успехов!
О СЕБЕ
Меня зовут Глеб Чувпило, и я управляющий партнер венчурной компании Thundermark Capital, инвестирущей в стартапы в области искусственного интеллекта и робототехники. Я получил степень магистра в Лаборатории компьютерных наук и искусственного интеллекта Массачусетского технологического института и степень MBA в области финансов и стратегического менеджмента в Уортонской школе бизнеса Пенсильванского университета. Вы можете прочитать обо мне здесь. Пожалуйста, напишите мне по адресу gleb@thundermark.com если Вы хотите поговорить об искусственном интеллекте, робототехнике, инновациях вообще или о своей идее для стартапа в частности. 🤖