



Пикабу на Android 2.3.3 - 2.3.7
Уважаемые пикабутяне!
Подскажите, пожалуйста, есть ли работающая полнофункциональная сборка Пикабу на Android 2.3.3 - 2.3.7?


Как узнать сколько трафика "жрёт" приложение на Android на примере Xiaomi (Redmi)

Картинка для привлечения внимания
Иногда случается так, что трафик на тарифе оператора заканчивается внезапно, хотя вы ничего крупного не загружали и фильмы не смотрели.
Причины могут быть разными: обновились приложения, появилась фоновая активность какой-то программы, которая обновляла данные всю ночь пока вы спали или что-то иное.
Без специального инструмента невозможно понять на телефоне, куда именно делся трафик и почему снова придётся за него платить.
Я покажу встроенный в Xiaomi (Redmi) инструмент, который следит за трафиком и покажет какое приложение, когда и сколько потратило лимиты, или слишком активно пользуется интернетом в фоновом режиме, когда вы этого не видите.
Как посмотреть траты трафика на Xiaomi (Redmi)
Оставлю текстовую версию инструкции:
Запустите системное приложение "Безопасность" на Xiaomi (Redmi).
Найдите иконку "Передача данных".
Выберите меню "Потребление трафика".
Вы видите таблицу, в которую внесены все приложения, включая системные, которые обращались в интернет за данными.
Выберите фильтр времени: Вчера, Сегодня, Прошлый месяц или последние 30 дней.
В верхнем правом углу выберите тип подключения: Сотовые сети или Wi-Fi.
Если выбрать приложение, вы увидите подробный график потребления трафика.
Снизу есть возможность принудительно ограничить доступ приложения в интернет в трёх вариантах: по сотовой сети, по Wi-Fi или в фоновом режиме.
Теперь вы сможете точно узнать какое приложение "Жрёт" больше всего трафика, и вычислить программы, которые в фоновом режиме любят постоянно обновлять данные без надобности, расходуя лимит Гигабайт из тарифа сотового оператора.
Если по необычайному стечению обстоятельств вам стало любопытно, есть ли ещё подобные лайфхаки для смартфонов Xiaomi - добро пожаловать на MetaMi.
Показать полностью
1


Да придёт спаситель!
Если вы это смотрите-вы и есть сопротивление!
Два уровня настройки экономии энергопотребления для любого приложения на Xiaomi (Redmi)

Картинка для привлечения внимания
Прогресс мчится вперёд, каждый полгода производители чипсетов для телефонов представляют новинки, которые: выше, быстрее, сильнее.
И каждый раз утверждается о возросшей энергоэффективности. И это правда, вот только субъективно это ощущается слабо.
Как жили смартфона одни сутки при обычном сценарии использования 10 лет назад, так живут и сегодня. Хотя ёмкость батарей заметно увеличилась. Почему - загадка.
В этом посте я покажу как добраться до настроек управления энергопотребления которые встроены в MIUI и HyperOS, но почему то скрыты от пользователя за семью уровнями меню.
Также покажу как добраться до настроек экономии энергии, которые встроены в Android.
Где скрыты настройки управления энергопотребления для приложений на Xiaomi (Redmi)
Для тех, кому не хочется смотреть видео, оставляю текстовую инструкцию:
Откройте общие настройки смартфона, перейдите в раздел "Батарея".
Вы увидите список приложений, которые были активны со времени последней зарядки батареи. Они выстроены по уменьшения потреблённой энергии. Сверху самые прожорливые, и чем ниже программа в списке, тем меньше она потратила энергии.
Нажмите на программу, которая вызывает у вас подозрение. Например, вы пользовались ею совсем немного, а она потратила непропорционально много энергии. Или вы вообще её не запускали, а она есть в топе списка.
Вас перенесёт в меню приложения, в нижней панели нажмите на кнопку "Сведения".
В следующем меню найдите строку "Контроль активности".
По умолчанию для каждой программы установлен контроль "Умный режим". Обычно он хорошо справляется с ограничением аппетита программы в фоновом режиме. Но если вам кажется, что она всё равно потребляет слишком много энергии, дайте ей режим "Мягкое ограничение".
После этого понаблюдайте за энергопотреблением в течении дня или двух, умерит ли приложение аппетит. Обычно этого достаточно. Но если программа продолжает наводить суету, установите для неё режим "Жёсткое ограничение".
Теперь расскажу о режиме экономии энергии, который встроен в Android. Для того, чтобы на смартфона Xiaomi (Redmi) до него добраться, необходимо установить приложение Hidden Settings MIUI, оно есть в магазине Google Play.
После установки запустите программу Hidden Settings MIUI.
Найдите меню "Оптимизация батареи".
Войдя в него обратите внимание на вкладку, она должна быть "Не экономят заряд".
В списке вы увидите только те приложения и сервисы, которые работают без режима экономии. Выберите ту программу, которая потребляет слишком много согласно отчёту в меню "Батарея" и переведите её в режим экономии.
Судя по справке Google этот режим работает только для тех программ, которые находятся в фоновом режиме. Он не влияет на энергопотребление приложения, если вы им активно пользуетесь.
Если по необычайному стечению обстоятельств вам стало любопытно, есть ли ещё подобные лайфхаки для смартфонов Xiaomi - добро пожаловать на MetaMi.
Показать полностью
1


Мое решение 3-х проблем MVx
Автор текста: Lynnfield
Итак, в прошлый раз я описал три проблемы, которыми, на мой взгляд, страдают все MVx и даже некоторые не MVx архитектуры. Если коротко, то это:
проблема остатка — при делении фичи на заявленные компоненты архитектуры остаётся либо «неделимая» часть фичи, либо лишние компоненты архитектуры;
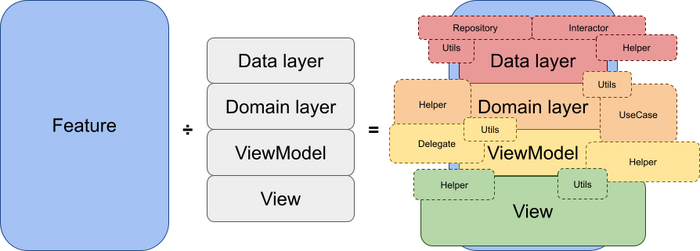
проблема масштабирования — при расширении фичи компоненты архитектуры начинают раздуваться, что усложняет дальнейшую поддержку;
и проблема разрывов логики, когда из-за взаимодействия с UI логика разрывается на части, что тоже не помогает нам делать систему более цельной, предсказуемой и тестируемой.

Описание проблем это, конечно, хорошо, но вопрос в том, как их решать? Об этом я бы и хотел поразмышлять в этом тексте. Спойлер: когда я нашел решение проблемы разрывов, я понял, что оно может решить и все остальные проблемы.
❯ Проблема остатка (Remainder issue)
Первый вопрос: что делать с остатком? Все просто — взять делитель поменьше, потому что чем меньше делитель, тем меньше остаток. Этому меня еще в школе научили. Но я столкнулся с тем, что это не работает с MVx архитектурами, потому что мой делитель, обычно, это набор определенных компонент, и введение новых — значит изменение архитектуры.
Возможно и вы с этим сталкивались, когда вводили всякие мапперы, делегаты, интеракторы (те, что репозитории репозиториев) и прочее. Помогли ли они мне? Нет. Лучшее решение, что я видел — это Flux- и ELM-like архитектуры, которые заявляют «чистую» функцию как единицу деления логики, но со всеми вытекающими отсюда удобствами и следующими за ними «эффектами».
Но решение проблемы остатка, даже если бы оно у меня было, не помогает мне решить проблему масштабирования.
❯ Проблема масштабирования (Scalability issue)
В прошлый раз я упоминал «интуитивный» подход к решению задачи масштабирования и рассказывал почему он не работает. По крайней мере не у меня.
А какой не интуитивный?
На мой взгляд это старая и уже не раз решенная задача. И примеры решения можно увидеть в том, как в теории вычислений доказывают некоторые теоремы через вкладывание одной машины Тьюринга в другую, или как элегантно эта проблема решается в процессорах, где более сложные компоненты — просто композиция более простых.
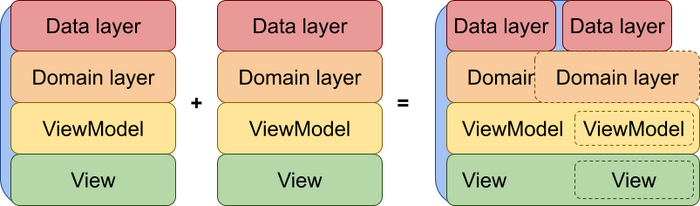
Так и в MVx архитектурах: можно было бы попробовать реализовывать доработки отдельно, а уже потом объединять их с существующей фичей, вместо того, чтобы вносить изменения в уже написанные компоненты. Что в прошлом не раз приводило меня к череде переписываний тестов, судорожному протыкиванию приложения на предмет того, что ничего не поменялось, и мольбам о том, чтобы очередной баг-репорт был не по моим изменениям.Но вот что я заметил, ведь именно такой подход, когда мы предпочитаем композицию изменениям, я и мои коллеги используем для Data-слоев. Например, новые источники данных оборачиваются в Репозитории, а потом комбинируются в Интеракторы. Но почему-то чем ближе мы подходим к UI-слою, тем больше начинаем изменять, а не комбинировать.
Чаще всего я вижу эту проблему как вечное переписывание тестов уже существующих компонент, или Presenter, ViewModel, Controller размером со вселенную, который даже трогать страшно, потому что что-то точно развалится.
Такой подход, где мы предпочитаем покомпонентную композицию фичи и доработок, вместо прямых изменений какого-нибудь компонента, действительно будет не интуитивным, потому что потребует реализовывать доработки как самостоятельную фичу. Я имею ввиду, что надо будет имплементировать доработки используя наш архитектурный подход, а потом написать еще одну пачку компонент, которая уже будет склеивать существующий функционал с новым. Но каким бы правильным мне это не казалось, я никак не могу отделаться от мысли, что такой подход приведет к написанию большого количества кода, который на первый взгляд будет казаться бесполезным.
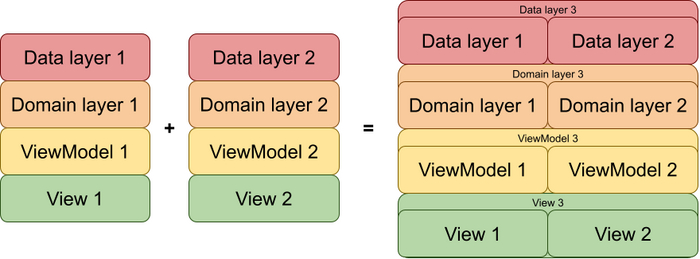
Еще мне показалось интересным, что тут нам может помешать проблема остатка, которая по идее должна привести к ситуации, когда такой подход не сработает, потому что надо будет внедрить доработки в “середину” компонента из уже существующей фичи, а значит придется делить существующие компоненты на новые, более мелкие. Чем крупнее делитель, тем крупнее остаток, да?
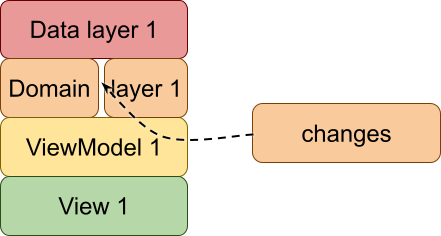
В итоге, даже использовав “неинтуитивный” подход к масштабированию, я все-равно не могу до конца понять как решить проблему масштабирования. А между прочим еще остается проблема разрывов.
❯ Проблема разрывов (Gaps issue)
И вот тут становится интересно. Все дело в Hello World. Мне все никак не дает покоя вопрос: какая у него архитектура?
Hello world
Я видел примеры Hello World в разных языках, фреймворках и архитектурах (кроме Open GL, конечно же), и у них не было проблем с его реализацией. Если не считать проблемой то, сколько усилий надо приложить, чтобы написать изначальный шаблон. Но, если результат одинаковый, не значит ли это, что разница только в том, сколько обвязок надо написать, чтобы Hello World работал? И нужны ли они? Тогда я стал думать: а что общего у всех этих реализаций Hello World в разных архитектурах? И как-то я пришел к мысли, что скорее всего правильный ответ — Алгоритм. И он до безобразия тривиален.

И что интересно, у самого алгоритма нигде не написана архитектура в которой он должен быть имплементирован. Но это Hello World. Как я и сказал: он чересчур прост.
Более интересные примеры
Давайте лучше взглянем на следующий пример, который используют в учебниках по программированию — Hello %username%. У него все та же проблема с архитектурами — его можно написать в любой из них, и общее между всеми реализациями в разных архитектурах — алгоритм.

А вот еще интересное наблюдение: если мы немного обобщим алгоритм Hello World, отделив show от Hello World, то увидим, что он дважды появляется в алгоритме этого примера.
Все еще слишком просто, правда? Следующий учебный пример — работа со структурами данных. И в самом простом виде — это CRUD плюс “показать все” с хранением в списке (он же List). Этот пример, не очень интересный с точки зрения реализации, интересен тем, что он добавляет в предыдущий алгоритм композицию.
По сути здесь мы первый раз сталкиваемся с тем, что нам надо создать пять независимых программ, а потом объединить их под управлением шестой. А еще эти шесть программ делят между собой один блок памяти — сам список структур. И мне кажется, что это уже напоминает решение одной из наших проблем, не так ли?
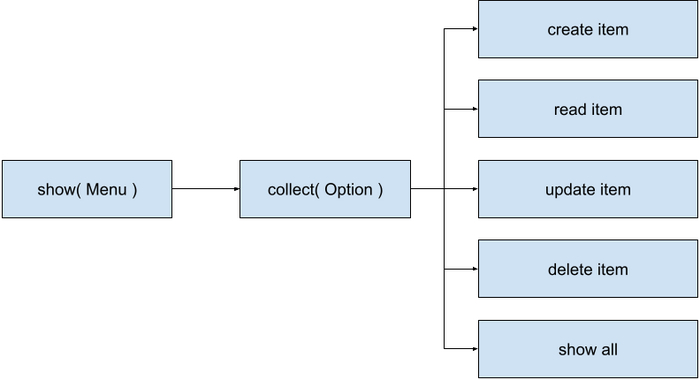
Появление Gaps issue
Но что происходит даже с этими простыми программами, когда мы пытаемся перенести их в UI-среду?
Легче всего Hello World, потому что он просто обрастает кучей компонент, которые помогают ему “жить” в новой среде. Даже не интересно.
А вот Hello %user name% приходится куда сложнее. Беднягу размазывает по компонентам системы или архитектуры: в одном месте мы слушаем ввод имени, в другом показываем приветствие, а в третьем прописываем реакцию на введенное имя.
Я даже боюсь говорить о том, что же происходит с CRUD-примером. В зависимости от того, какой макет нам нарисуют, мы будем писать совершенно разные приложения. Вот представьте, что вас попросили сделать такую программу как несколько разных экранов, а потом попросили переделать так, чтобы это был один экран. С часто используемым подходом к декомпозиции, когда один экран — один набор MVx-компонент, мы получим бессонную ночь переписывания кода, потому что части нашей логики разорваны и раскиданы по всей реализации.
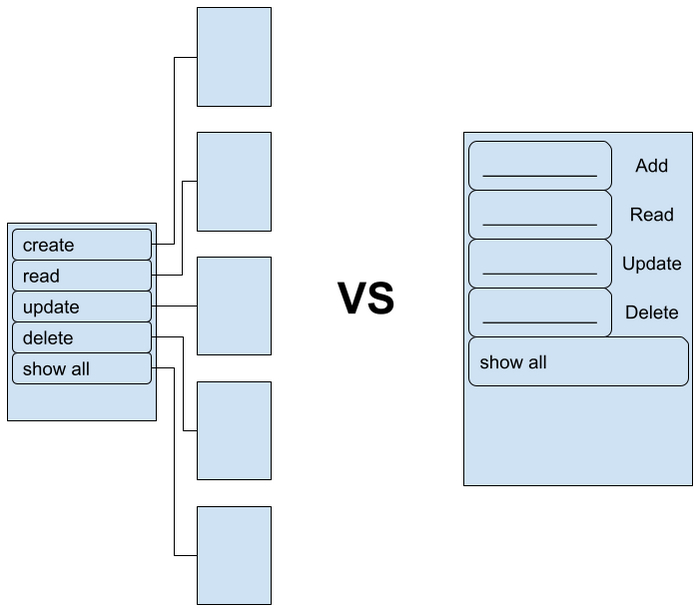
Но ведь изначально “не было ни единого разрыва”, а алгоритм остался тем же. Почему все стало так плохо?
Причина — асинхронность
На этот вопрос некоторые уже дали ответ в комментариях к предыдущим статье и видео, и я с ними полностью согласен. Причина — асинхронность. И я был искренне удивлен, когда пришел к этому выводу.
Многие, если не все GUI-системы построены вокруг event loop, потому что нам надо одновременно и экран рисовать, и ввод от пользователя слушать. А чтобы сюда добавить еще и наш алгоритм, его придется разделить так, чтобы он хорошо встраивался в этот event loop.
Я уже не говорю о том, что мы вообще-то еще должны взаимодействовать с другими асинхронными системами. Кстати, с ними то, обычно, проблем и не возникает. А почему?
Решение — закрытие разрыва
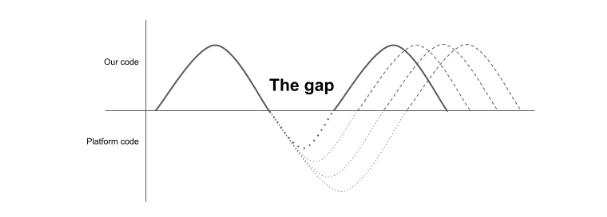
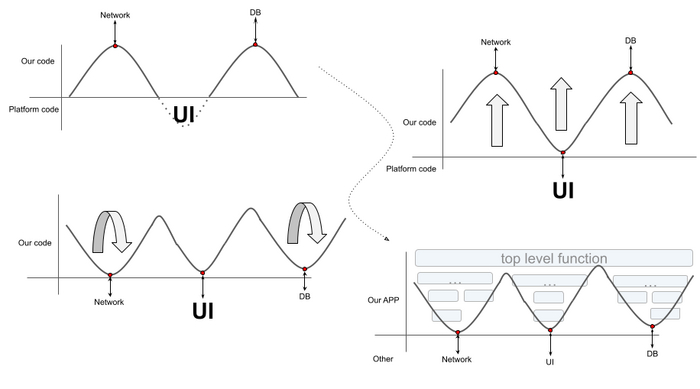
Обратим внимание на графикоподобную картинку, на которой я объяснял проблему разрывов в прошлый раз.
Напомню как всё было, и в этот раз уже не буду лукавить: путь нашей логики начинается в каком-то из callback’ов, а не в абстрактном “начале”. По мере выполнения мы продвигаемся все глубже по стеку вызовов, выполняем одну за другой функции, и в самой верхней точке нашего графика мы обращаемся к источнику данных: бэкенду, файлу, какой-то системе хранения. И что здесь обычно находится?

Обычно это вызов какой-то “асинхронной” функции: корутины, async- или suspend- функции, уж простите мой котлинский, или какой-то функции с callback’ом, или функции возвращающей какой-нибудь Future, Promise или Single.
И вот вопрос: вызывая эту функцию с callback’ом, как часто мы задумываемся, что эта операция может вообще никогда не вернуться в этот callback? Лично я до недавнего времени считал, что управление гарантированно будет передано в наш callback. Не считая случаев “отмены”, конечно же. Но откуда у нас такая гарантия? Возможно все дело в реализации системы? Давайте “заглянем под капот” и посмотрим что же там на самом деле происходит.
Наша функция формирует наш запрос к базе, запрос в сеть или еще что-то. В общем случае формирует какой-то контекст, с помощью которого надо выполнить запрос, и вместе с callback’ом, в который надо вернуть результат, отправляет его на другой поток, и там происходит все выполнение. После завершения выполнения, тот поток вызывает callback, передавая в него результат, что для нас, разработчиков, выглядит как своего рода возврат в точку вызова. Таким образом логика выглядит более цельной, и такого разрыва, как в случае с UI не происходит.
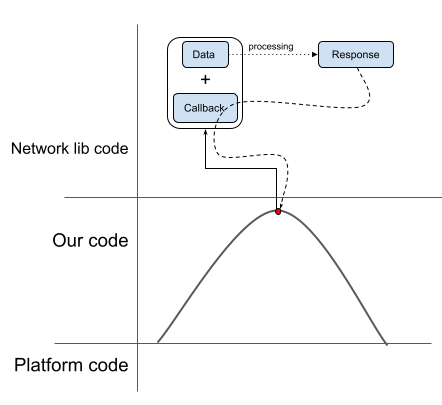
Так вот вопрос: а почему бы нам не повторить этот же трюк с UI?
На картинке это будет выглядеть как параллельный перенос: мы просто поднимем нашу линию, а вот тут, в нижней точке, вместо того чтобы разрывать логику и отдельно задавать на UI какое-то состояние и callback’и, сделаем функцию, которая отправляет запрос на UI и ждет от него ответа. Таким образом мы закрываем разрыв и теперь наша логика будет выглядеть как единое целое.

Ничего сложного, мы даже не изобретаем что-то новое, но такой подход поможет нам взаимодействовать с UI, как с любой другой внешней системой, а не как с чем-то особенным. И вот моё видение того, как это могло бы работать и решать проблемы, описанные выше.
❯ Proposal
Давайте писать функции…
Да, может звучать нелогично, тем более, что я уже говорил о том, что это не помогает Flux- и ELM-like архитектурам, но я объясню. Начнем с проблемы остатка.
Влияние на решение проблемы остатка
Добавлю небольшую аналогию с математикой. Как я и говорил «архитектура» — это делитель. А чтобы при делении не оставалось остатка — нам нужно найти наибольший общий делитель. Чем и является функция, на мой взгляд. Чем больше я смотрю на реализации всех наших «архитектур», тем больше я вижу, что все они, по сути, просто один из способов удобнее объединять и специализировать функции (и тут я подразумеваю, что метод класса — это функция, которая иногда неявно принимает дополнительный аргумент).
Дальше лучше — проблема масштабирования.
Решение проблемы масштабирования
Функции очень хорошо масштабируются, потому что, с точки зрения реализации, они могут вмещать в себя любой набор инструкций и в том числе вызовы других функций, а с точки зрения пользователя функции это всегда просто вызов функции: имя, параметры, результат, независимо от того как она реализована.
А что с разрывами?
Решение проблемы разрывов
До тех пор, пока мы будем поддерживаем нашу логику, как композицию функций, проблема разрывов будет естественным образом «выталкиваться наружу», за пределы нашей логики. А это в свою очередь будет гарантировать нам последовательность выполнения, тестируемость и как следствие — стабильность.
❯ Концепт
Так что же я предлагаю?
Во-первых, реализовывать логику, как функции и их композицию, а не как компоненты какой-нибудь архитектуры. Это позволит нам гарантировать и поддерживать последовательность выполнения, позитивно скажется на масштабируемости и тестируемости нашего кода, да и понимать такой код будет проще.
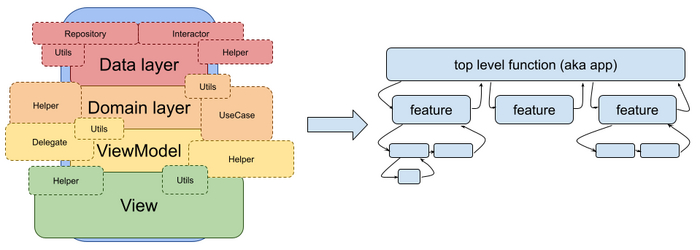
Во-вторых, у этой функции (композиции функций) должна быть возможность работать независимо от «сторонних» систем, поэтому я предлагаю вынести ее в свой поток, чтобы у нее была возможность спокойно выполняться, блокироваться при необходимости, параллелиться и тому подобное. Пусть будет “синхронной”. Обычно мне не надо, чтобы логика продолжала свое выполнение, когда она ждет какой-то ресурс. А если такое поведение нужно, то почему-бы его не описать его явно? И назвать бы этот поток Main, но имя уже “занято”. =)
В-третьих, хотя это и самый важный пункт, а у меня видимо есть тенденция оставлять все важное на потом, я предлагаю сосредоточиться на реализации логики приложений, а не экранов и виджетов. Как видите, с таким подходом нет разницы между слоем данных и пользователем. Есть только наша детерминированная логика и внешние системы, которые обмениваются данными через нее. Логика просто ходит между ними и предоставляет им некий контекст для принятия решения и набор возможных действий, а внешние системы в свою очередь “отвечают” нашей логике руководствуясь представленным контекстом. Это похоже на игру в шахматы, где внешние системы — игроки, а логика — доска с фигурами и правила игры.
Логика наших фич зачастую не зависит от представления, а как раз наоборот: представление является способом, который помогает логике взаимодействовать с пользователем в определенной среде, как какой-нибудь адаптер. Я думаю, что такой адаптер должен быть плагином к логике, а не фактором определяющим ее.
В конце концов, применив этот концепт, я хочу помочь всем нам проектировать и писать кроссплатформенные приложения в самом широком смысле этого слова: разрабатывая и реализуя end-to-end алгоритмы которые прозрачно перескакивают с бэкенда на фронт и обратно, которые не видят различия между разными видами фронтов, будь то Web, iOS или Android, или разными типами вроде UI, CLI, или TalkBack.
Но пока это только концепт и виденье. Пожалуй пора посмотреть на код, но он будет в следующий раз. А сейчас есть время порефлексировать на эту тему. Дайте этим идеям время перевариться. Прочитайте еще раз. Задайте вопросы. И может вы сможете написать код еще до того, как я опубликую продолжение. Хотите посоревноваться?
Увидимся.
Написано специально для Timeweb Cloud и читателей Пикабу. Больше интересных статей в нашем блоге на Хабре и телеграм-каналах (статьи и новости).
Облачные сервисы Timeweb Cloud — это реферальная ссылка, которая может помочь поддержать наши проекты.
Показать полностью
14
Включаем скрытые возможности по обработке видео и фото с помощью ИИ на Xiaomi (Redmi)

Картинка для привлечения внимания
Когда читаешь новости о выпуске очередного чипсета для мобильного телефона, обязательно видишь описание его возможности работы с нейросетевыми алгоритмами. В чипсетах создают специальные вычислительные блоки, которые эффективно способны работать именно с алгоритмами ИИ.
Но когда покупаешь телефон, в котором стоит чип, который умеет работать с алгоритмами ИИ, далеко не всегда видишь результат этой работы.
Зачастую в это вносят вклад маркетологи. Учитывая большое количество моделей, которое выпускает Xiaomi под своим брендом, а также под суббрендами Redmi и POCO не удивительно, что они искусственно отключают встроенные возможности, которые можно отнести к более дорогим моделям в более доступных.
Сегодня я покажу, как легко и непринуждённо вернуть 3 настройки обработки фото и видео на смартфонах Xiaomi, Redmi или POCO, которые работают на базе ИИ, но отключены во многих моделях.
Внимание: возможность включить алгоритмы ИИ определяется аппаратной возможностью чипсета вашего телефона. Если он не поддерживает эти функции, включить их не получится.
Как вернуть 3 настройки обработки фото и видео с помощью ИИ
Текстовая инструкция:
Установите приложение "Activity Launcher". Раньше оно было доступно в Google Play, сейчас его то ли удалили, то ли переименовали, не знаю. Я выложил его в ТГ - Activity Launcher в виде APK. Проверил, ни вирусов, ни другой ерунды в нём нет.
Запускаете приложение, в строке поиска вводите слово "Display".
Листаете поисковую выдачу вниз до раздела "Настройки".
Теперь ищите строки: "HDR-улучшение с ИИ", "MEMC" и "Улучшение изображений с ИИ". Если чипсет вашего смартфона поддерживает эти технологии, их возможно включить. Если этих настроек нет, значит ваш телефон эти технологии не поддерживает.
Надеюсь, использовать смартфон с дополнительными ИИ-алгоритмами стало приятнее.
Если по необычайному стечению обстоятельств вам стало любопытно, есть ли ещё подобные лайфхаки для смартфонов Xiaomi - добро пожаловать на MetaMi.
Показать полностью
1