


Мое решение 3-х проблем MVx
Автор текста: Lynnfield
Итак, в прошлый раз я описал три проблемы, которыми, на мой взгляд, страдают все MVx и даже некоторые не MVx архитектуры. Если коротко, то это:
проблема остатка — при делении фичи на заявленные компоненты архитектуры остаётся либо «неделимая» часть фичи, либо лишние компоненты архитектуры;
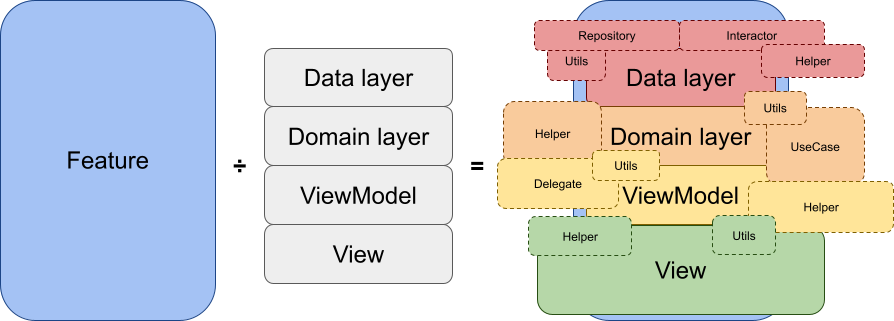
проблема масштабирования — при расширении фичи компоненты архитектуры начинают раздуваться, что усложняет дальнейшую поддержку;

и проблема разрывов логики, когда из-за взаимодействия с UI логика разрывается на части, что тоже не помогает нам делать систему более цельной, предсказуемой и тестируемой.

Описание проблем это, конечно, хорошо, но вопрос в том, как их решать? Об этом я бы и хотел поразмышлять в этом тексте. Спойлер: когда я нашел решение проблемы разрывов, я понял, что оно может решить и все остальные проблемы.
❯ Проблема остатка (Remainder issue)
Первый вопрос: что делать с остатком? Все просто — взять делитель поменьше, потому что чем меньше делитель, тем меньше остаток. Этому меня еще в школе научили. Но я столкнулся с тем, что это не работает с MVx архитектурами, потому что мой делитель, обычно, это набор определенных компонент, и введение новых — значит изменение архитектуры.
Возможно и вы с этим сталкивались, когда вводили всякие мапперы, делегаты, интеракторы (те, что репозитории репозиториев) и прочее. Помогли ли они мне? Нет. Лучшее решение, что я видел — это Flux- и ELM-like архитектуры, которые заявляют «чистую» функцию как единицу деления логики, но со всеми вытекающими отсюда удобствами и следующими за ними «эффектами».
Но решение проблемы остатка, даже если бы оно у меня было, не помогает мне решить проблему масштабирования.
❯ Проблема масштабирования (Scalability issue)
В прошлый раз я упоминал «интуитивный» подход к решению задачи масштабирования и рассказывал почему он не работает. По крайней мере не у меня.
А какой не интуитивный?
На мой взгляд это старая и уже не раз решенная задача. И примеры решения можно увидеть в том, как в теории вычислений доказывают некоторые теоремы через вкладывание одной машины Тьюринга в другую, или как элегантно эта проблема решается в процессорах, где более сложные компоненты — просто композиция более простых.
Так и в MVx архитектурах: можно было бы попробовать реализовывать доработки отдельно, а уже потом объединять их с существующей фичей, вместо того, чтобы вносить изменения в уже написанные компоненты. Что в прошлом не раз приводило меня к череде переписываний тестов, судорожному протыкиванию приложения на предмет того, что ничего не поменялось, и мольбам о том, чтобы очередной баг-репорт был не по моим изменениям.Но вот что я заметил, ведь именно такой подход, когда мы предпочитаем композицию изменениям, я и мои коллеги используем для Data-слоев. Например, новые источники данных оборачиваются в Репозитории, а потом комбинируются в Интеракторы. Но почему-то чем ближе мы подходим к UI-слою, тем больше начинаем изменять, а не комбинировать.
Чаще всего я вижу эту проблему как вечное переписывание тестов уже существующих компонент, или Presenter, ViewModel, Controller размером со вселенную, который даже трогать страшно, потому что что-то точно развалится.
Такой подход, где мы предпочитаем покомпонентную композицию фичи и доработок, вместо прямых изменений какого-нибудь компонента, действительно будет не интуитивным, потому что потребует реализовывать доработки как самостоятельную фичу. Я имею ввиду, что надо будет имплементировать доработки используя наш архитектурный подход, а потом написать еще одну пачку компонент, которая уже будет склеивать существующий функционал с новым. Но каким бы правильным мне это не казалось, я никак не могу отделаться от мысли, что такой подход приведет к написанию большого количества кода, который на первый взгляд будет казаться бесполезным.

Еще мне показалось интересным, что тут нам может помешать проблема остатка, которая по идее должна привести к ситуации, когда такой подход не сработает, потому что надо будет внедрить доработки в “середину” компонента из уже существующей фичи, а значит придется делить существующие компоненты на новые, более мелкие. Чем крупнее делитель, тем крупнее остаток, да?
В итоге, даже использовав “неинтуитивный” подход к масштабированию, я все-равно не могу до конца понять как решить проблему масштабирования. А между прочим еще остается проблема разрывов.
❯ Проблема разрывов (Gaps issue)
И вот тут становится интересно. Все дело в Hello World. Мне все никак не дает покоя вопрос: какая у него архитектура?
Hello world
Я видел примеры Hello World в разных языках, фреймворках и архитектурах (кроме Open GL, конечно же), и у них не было проблем с его реализацией. Если не считать проблемой то, сколько усилий надо приложить, чтобы написать изначальный шаблон. Но, если результат одинаковый, не значит ли это, что разница только в том, сколько обвязок надо написать, чтобы Hello World работал? И нужны ли они? Тогда я стал думать: а что общего у всех этих реализаций Hello World в разных архитектурах? И как-то я пришел к мысли, что скорее всего правильный ответ — Алгоритм. И он до безобразия тривиален.

И что интересно, у самого алгоритма нигде не написана архитектура в которой он должен быть имплементирован. Но это Hello World. Как я и сказал: он чересчур прост.
Более интересные примеры
Давайте лучше взглянем на следующий пример, который используют в учебниках по программированию — Hello %username%. У него все та же проблема с архитектурами — его можно написать в любой из них, и общее между всеми реализациями в разных архитектурах — алгоритм.

А вот еще интересное наблюдение: если мы немного обобщим алгоритм Hello World, отделив show от Hello World, то увидим, что он дважды появляется в алгоритме этого примера.
Все еще слишком просто, правда? Следующий учебный пример — работа со структурами данных. И в самом простом виде — это CRUD плюс “показать все” с хранением в списке (он же List). Этот пример, не очень интересный с точки зрения реализации, интересен тем, что он добавляет в предыдущий алгоритм композицию.
По сути здесь мы первый раз сталкиваемся с тем, что нам надо создать пять независимых программ, а потом объединить их под управлением шестой. А еще эти шесть программ делят между собой один блок памяти — сам список структур. И мне кажется, что это уже напоминает решение одной из наших проблем, не так ли?

Появление Gaps issue
Но что происходит даже с этими простыми программами, когда мы пытаемся перенести их в UI-среду?
Легче всего Hello World, потому что он просто обрастает кучей компонент, которые помогают ему “жить” в новой среде. Даже не интересно.
А вот Hello %user name% приходится куда сложнее. Беднягу размазывает по компонентам системы или архитектуры: в одном месте мы слушаем ввод имени, в другом показываем приветствие, а в третьем прописываем реакцию на введенное имя.
Я даже боюсь говорить о том, что же происходит с CRUD-примером. В зависимости от того, какой макет нам нарисуют, мы будем писать совершенно разные приложения. Вот представьте, что вас попросили сделать такую программу как несколько разных экранов, а потом попросили переделать так, чтобы это был один экран. С часто используемым подходом к декомпозиции, когда один экран — один набор MVx-компонент, мы получим бессонную ночь переписывания кода, потому что части нашей логики разорваны и раскиданы по всей реализации.

Но ведь изначально “не было ни единого разрыва”, а алгоритм остался тем же. Почему все стало так плохо?
Причина — асинхронность
На этот вопрос некоторые уже дали ответ в комментариях к предыдущим статье и видео, и я с ними полностью согласен. Причина — асинхронность. И я был искренне удивлен, когда пришел к этому выводу.
Многие, если не все GUI-системы построены вокруг event loop, потому что нам надо одновременно и экран рисовать, и ввод от пользователя слушать. А чтобы сюда добавить еще и наш алгоритм, его придется разделить так, чтобы он хорошо встраивался в этот event loop.
Я уже не говорю о том, что мы вообще-то еще должны взаимодействовать с другими асинхронными системами. Кстати, с ними то, обычно, проблем и не возникает. А почему?
Решение — закрытие разрыва
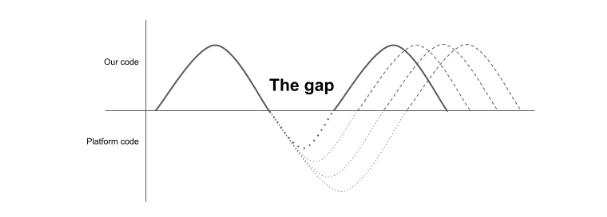
Обратим внимание на графикоподобную картинку, на которой я объяснял проблему разрывов в прошлый раз.
Напомню как всё было, и в этот раз уже не буду лукавить: путь нашей логики начинается в каком-то из callback’ов, а не в абстрактном “начале”. По мере выполнения мы продвигаемся все глубже по стеку вызовов, выполняем одну за другой функции, и в самой верхней точке нашего графика мы обращаемся к источнику данных: бэкенду, файлу, какой-то системе хранения. И что здесь обычно находится?

Обычно это вызов какой-то “асинхронной” функции: корутины, async- или suspend- функции, уж простите мой котлинский, или какой-то функции с callback’ом, или функции возвращающей какой-нибудь Future, Promise или Single.
И вот вопрос: вызывая эту функцию с callback’ом, как часто мы задумываемся, что эта операция может вообще никогда не вернуться в этот callback? Лично я до недавнего времени считал, что управление гарантированно будет передано в наш callback. Не считая случаев “отмены”, конечно же. Но откуда у нас такая гарантия? Возможно все дело в реализации системы? Давайте “заглянем под капот” и посмотрим что же там на самом деле происходит.
Наша функция формирует наш запрос к базе, запрос в сеть или еще что-то. В общем случае формирует какой-то контекст, с помощью которого надо выполнить запрос, и вместе с callback’ом, в который надо вернуть результат, отправляет его на другой поток, и там происходит все выполнение. После завершения выполнения, тот поток вызывает callback, передавая в него результат, что для нас, разработчиков, выглядит как своего рода возврат в точку вызова. Таким образом логика выглядит более цельной, и такого разрыва, как в случае с UI не происходит.
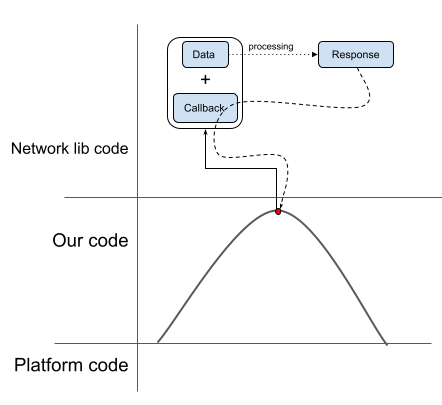
Так вот вопрос: а почему бы нам не повторить этот же трюк с UI?
На картинке это будет выглядеть как параллельный перенос: мы просто поднимем нашу линию, а вот тут, в нижней точке, вместо того чтобы разрывать логику и отдельно задавать на UI какое-то состояние и callback’и, сделаем функцию, которая отправляет запрос на UI и ждет от него ответа. Таким образом мы закрываем разрыв и теперь наша логика будет выглядеть как единое целое.

Ничего сложного, мы даже не изобретаем что-то новое, но такой подход поможет нам взаимодействовать с UI, как с любой другой внешней системой, а не как с чем-то особенным. И вот моё видение того, как это могло бы работать и решать проблемы, описанные выше.
❯ Proposal
Давайте писать функции…
Да, может звучать нелогично, тем более, что я уже говорил о том, что это не помогает Flux- и ELM-like архитектурам, но я объясню. Начнем с проблемы остатка.
Влияние на решение проблемы остатка
Добавлю небольшую аналогию с математикой. Как я и говорил «архитектура» — это делитель. А чтобы при делении не оставалось остатка — нам нужно найти наибольший общий делитель. Чем и является функция, на мой взгляд. Чем больше я смотрю на реализации всех наших «архитектур», тем больше я вижу, что все они, по сути, просто один из способов удобнее объединять и специализировать функции (и тут я подразумеваю, что метод класса — это функция, которая иногда неявно принимает дополнительный аргумент).
Дальше лучше — проблема масштабирования.
Решение проблемы масштабирования
Функции очень хорошо масштабируются, потому что, с точки зрения реализации, они могут вмещать в себя любой набор инструкций и в том числе вызовы других функций, а с точки зрения пользователя функции это всегда просто вызов функции: имя, параметры, результат, независимо от того как она реализована.
А что с разрывами?
Решение проблемы разрывов
До тех пор, пока мы будем поддерживаем нашу логику, как композицию функций, проблема разрывов будет естественным образом «выталкиваться наружу», за пределы нашей логики. А это в свою очередь будет гарантировать нам последовательность выполнения, тестируемость и как следствие — стабильность.
❯ Концепт
Так что же я предлагаю?
Во-первых, реализовывать логику, как функции и их композицию, а не как компоненты какой-нибудь архитектуры. Это позволит нам гарантировать и поддерживать последовательность выполнения, позитивно скажется на масштабируемости и тестируемости нашего кода, да и понимать такой код будет проще.

Во-вторых, у этой функции (композиции функций) должна быть возможность работать независимо от «сторонних» систем, поэтому я предлагаю вынести ее в свой поток, чтобы у нее была возможность спокойно выполняться, блокироваться при необходимости, параллелиться и тому подобное. Пусть будет “синхронной”. Обычно мне не надо, чтобы логика продолжала свое выполнение, когда она ждет какой-то ресурс. А если такое поведение нужно, то почему-бы его не описать его явно? И назвать бы этот поток Main, но имя уже “занято”. =)
В-третьих, хотя это и самый важный пункт, а у меня видимо есть тенденция оставлять все важное на потом, я предлагаю сосредоточиться на реализации логики приложений, а не экранов и виджетов. Как видите, с таким подходом нет разницы между слоем данных и пользователем. Есть только наша детерминированная логика и внешние системы, которые обмениваются данными через нее. Логика просто ходит между ними и предоставляет им некий контекст для принятия решения и набор возможных действий, а внешние системы в свою очередь “отвечают” нашей логике руководствуясь представленным контекстом. Это похоже на игру в шахматы, где внешние системы — игроки, а логика — доска с фигурами и правила игры.

Логика наших фич зачастую не зависит от представления, а как раз наоборот: представление является способом, который помогает логике взаимодействовать с пользователем в определенной среде, как какой-нибудь адаптер. Я думаю, что такой адаптер должен быть плагином к логике, а не фактором определяющим ее.
В конце концов, применив этот концепт, я хочу помочь всем нам проектировать и писать кроссплатформенные приложения в самом широком смысле этого слова: разрабатывая и реализуя end-to-end алгоритмы которые прозрачно перескакивают с бэкенда на фронт и обратно, которые не видят различия между разными видами фронтов, будь то Web, iOS или Android, или разными типами вроде UI, CLI, или TalkBack.
Но пока это только концепт и виденье. Пожалуй пора посмотреть на код, но он будет в следующий раз. А сейчас есть время порефлексировать на эту тему. Дайте этим идеям время перевариться. Прочитайте еще раз. Задайте вопросы. И может вы сможете написать код еще до того, как я опубликую продолжение. Хотите посоревноваться?
Увидимся.
Написано специально для Timeweb Cloud и читателей Пикабу. Больше интересных статей в нашем блоге на Хабре и телеграм-каналах (статьи и новости).
Облачные сервисы Timeweb Cloud — это реферальная ссылка, которая может помочь поддержать наши проекты.
Android Developers
90 постов2K подписчик
Правила сообщества
Друзья!
Давайте адекватно относиться к тематике сообщества. Посты, не удовлетворяющие требованиям канала, будут отклоняться. Разработка под Android - это не только описание того, что надо сделать
(освоить Java / покормить кота / установить студию), но и реальные примеры того, что Вы описываете.