Привет! Эта серия посвящена процессу разработки моего бота для распознавания и модификации голосовых сообщений в Telegram. Статья, является продолжением предыдущего поста из этой серии: Ответ на пост «Я сделал приложение для разумных трат»
Время чтения ~ 7 минут.
Приятно и одновременно удивительно, что предыдущий пост вышел в горячее. Отдельно греют душу черт знает откуда появившиеся звездочки на GitHub, видимо кого-то это действительно заинтересовало. Спасибо вам, ребята =)
В комментариях к предыдущему посту было предложено немало интересных идей по улучшению функционала бота. Основные предложения касались языковой поддержки уже имеющихся функций - распознавания и синтеза речи. Почитав комментарии и ознакомившись с аналогичными разработками, я вооружился верной кружкой-жабушкой я принялся за работу...
Вкратце для ЛЛ, список изменений выглядит следующим образом:
В принципе, дальше вы можете не читать, а перейти в бота и потестить самостоятельно: https://t.me/Soulcatcher_voice_changer_bot а я пока расскажу о каждом изменении и связанными с ними сложностями (мы же любим сложности?) по отдельности.
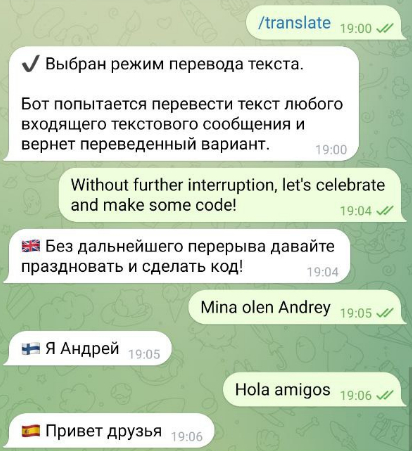
Начнем с минорной функции перевода текста. Она не является киллер фичей бота и в данной версии добавлена скорее как фундамент для будущей функции "распознавание + перевод", к которой мы вернемся чуть позже. Сама функция вызывается одной командой из главного меню и не имеет никаких дополнительных настроек. Выглядит это вот так:
Перевод происходит с любого из 180 поддерживаемых языков (которые я, естественно не тестировал) на язык пользователя. Пользовательский язык достается из метаданных сообщения. Несомненно, перевод, обладает некоторой степенью всратости, но мы к этому еще вернемся. Сейчас важно лишь то, что в качестве языкового движка использован Google Translate API. Для безлимитного (относительно) доступа к этой библиотеки, используется библиотека Translators, авторы которой, любезно предоставили свой приватный ключ. Как вы уже заметили, вместе с результатом перевода возвращается и флаг страны, язык которой был определен переводчиком - удобно. Для достижения этого результата я модифицировал библиотеку Translators, заставив ее возвращать не только перевод текста, но и код языка, для которого произведен перевод. По какой то причине, "из коробки", этого функционала небыло.
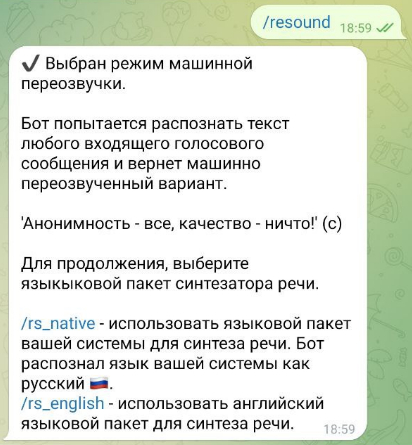
Машинная переозвучка тоже получила языковую поддержку. Выглядит это так:
Озвучка доступна на ~25 языках, нативный язык озвучки, так-же, как в переводчике, автоматически выбирается исходя из локали, установленной на устройстве пользователя. Помимо этого, вне зависимости от системного языка, всегда доступна озвучка на английском. В случае, если вы носитель одного из этих выдуманных языков с закорючками из самого низа языковых настроек телефона (иными словами, ваш язык не поддерживается ботом), для переозвучки будет предложен только английский =)
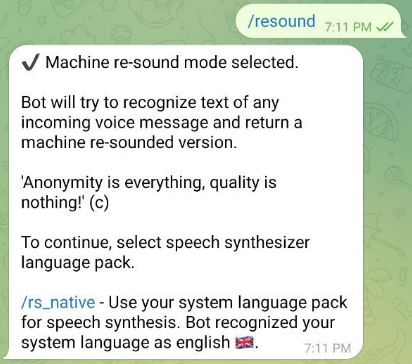
Подводя статью к самой интересной части - проблеме распознавания иностранной речи, не могу не отметить еще одно минорное изменение - перевод интерфейса бота на английский язык. Вот как выглядит ресаунд для англоговорящих пользователей (Обратите внимание, на список предложенных языков):
Абсолютно весь интерфейс бота переведен на английский язык. Интерфейс на английском автоматически выводится для всех пользователей, с локалью, отличной от русской. Перевод машинный, частично отредактированный вручную, так что указания на ошибки и опечатки приветствуются!
Итак, мы подошли к самому важному и неоднозначному нововведению в этой версии - мультиязычному распознаванию речи. Не смотря на то, что используемая технология позволяет распознавать речь с огромного количества языков, в предыдущей версии Soulcatcher, распознавание было возможным лишь с русского. Связано это с одной фундаментальной проблемой текущих решений в сфере распознавания речи: Я провел опредеенное время в изысканиях, после чего пришел к выводу, что на данный момент, не существует сервисов или отдельных технических решений, способных достаточно эффективно распознавать речь с заранее неизвестного языка. Даже такие гиганты как Google, не предоставляют своим клиентам (речь идет о коммерческих решениях) подобный функционал, что говорить о бесплатных сервисах? Обратите внимание на нижнюю часть скриншота:
Все дело в том, что современное распознавание речи производится при помощи языковых моделей, что само по себе, достаточно дорогой (в контексте аппаратных возможностей) процесс. Для того, чтобы понять почему это сложнее, чем анаогичное автораспознавание языка в тексте, нужно понять, как это распознавание устроено. Хорошее объяснение одного из популярных подходов представлено на этой странице: https://translatedlabs.com/определение-языка (Не реклама, мне до работы в таких компаниях еще далеко)
Простыми словами, происходит сравнение переводимого текста с заранее загруженными образцами. В чем же проблема сравнить переводимый голос, с заранее записанными файлами? Дьявол кроется в деталях. Текст по своей сути так-сказать "стабилен", вне зависимости от автора, стиля и назначения текстовой информации, одни и те же слова, дадут предсказуемый, одинаковый результат при любом форматировании. Голос же, имеет такие неочевидные для компьютера свойства как тональность, интонация, акцент. Именно для этого существуют голосовые модели, уникальные для каждого языка и предназначенные для обработки этих, свойственных только человеческому голосу данных. Если еще проще, то при попытке сравнения одного и того же текста, продиктованного разными людьми с некими контрольными показателями, мы всегда будем получать разные результаты. Поэтому голос предварительно необходимо привести в "стабильный" вид при помощи голосовой модели. Для точного распознавания, необходимо применить к записи голоса все доступные языковые модели и только после этого, производить сравнение. Как было отмечено выше, для массового применения, это слишком дорогая (долгая) операция. По этой причине, я пошел по проторенной дорожке и ввел необходимость явно указывать язык распознавания:
Языки были выбраны по принципу "топ семь смешных лягушек 9 самых популярных языков мира" =)
В целом, распознавание речи работает достаточно сносно, по крайней мере на английском и русском языках. Если в комментариях присутствуют носители индонезийского или, внезапно хинди, было бы здорово услышать ваше мнение.
Следующая версия будет сосредоточена на функционале для бесед, ибо текущая реализация со стейтами, хранимыми в оперативной памяти не только не устраивает меня с точки зрения производительности, но так-же не позволяет ввести функционал администрирования бота админами каналов. Кое-какие идеи, на этот счет уже есть. Еще раз хочу обратить внимание, на то, что без вашего внимания к посту и справедливым замечаниям под ним, это обновление никогда бы не вышло. А на этом у меня все, еще раз спасибо =)
P.S. Возвращаясь к проблеме выбора API Google Translate в качестве штатного переводчика. Один находчивый человек в комментариях, посоветовал использовать DeepL для этих целей, в целом, я присоединяюсь к его мнению, DeepL реально превосходит все остальные решения на две головы за исключением одного но: Он не доступен в России. Клянусь, я пытался подделать эстонскую кредитку, чтобы зарегистрироваться на их ресурсе, но все тщетно. Если у кого то есть идеи, как это обойти не тратя кучу денег - буду рад их услышать.
-----
По ссылке ниже, вы попадете в репозиторий бота на моем Github, где сможете подробнее ознакомиться с функционалом, стеком использованных технологий, а так же узнать тайну отсылки в его названии. Мой телеграм для связи можно найти как в самом боте, так и на Github.
https://github.com/Raiksler/Soulcatcher-voice-changer