Запускаем DeepSeek локально и сраниваем модели
Вижу явный перебор с хайпом по теме дикпика дипсика. С одной стороны модель, которая работает на сайте явно имеет много преимуществ. Но вот то, что ее можно установить на свой компьютер и будет работать гораздо лучше любых других моделей это явное преувеличение. К такому выводу я пришел когда решил проверить всё сам.
Проверить можете и вы. Привожу простой рецепт для Linux, потому что понятия не имею как запустить на винде.
Для запуска использовал вот этот репозиторий:
https://github.com/ntimo/ollama-webui
На Linux чтобы запустить DeepSeek локально
Клонируем репу, предварительно установив git:
git clone https://github.com/ntimo/ollama-webui
2. В скачаной директории исправляем docker-compose.yml, раскоментировав раздел 'ollama' для поддержки Nvidia GPU (удалить #). Если запускать на CPU, то этот пункт пропускаем.
Тут может быть проблема в том, что yaml формат очень строг к отступам. Редакторы могут заменять пробелы и табуляции, а потом при запуске будет выдавать неясные ошибки.
# Uncomment below for GPU support
# deploy:
# resources:
# reservations:
# devices:
# - driver: nvidia
# count: 1
# capabilities:
# - gpu
3. Устанавливаем docker и docker-compose
для вашего дистрибутива загуглите, но скорее всего это что-то вроде
sudo apt install docker docker-compose-plugin
4. Запускаем:
docker-compose up
5. Profit!
Найти веб-морду можно на http://localhost:3000/
Дальше в вебморде нужно нажать создание нового чата и установить модель, выбрав ее название вот тут: https://ollama.com/library

Размеры моделей deepseek-r1
Итак, тестирую.
В качестве промпта использую "Расскажи на русском что ты знаешь про Пикабу и про минусы". Запускаю на видеокарте Nvidia RTX4070 Ti Super 16Gb. Но модели меньше 32b хоть медленно, но работают даже на видеокартах 8-10Gb. Как я понял, размер видеопамяти примерно должен соответствовать размеру модели иначе очень проседает скорость генерации ответа. К примеру, на GPU 16Gb модель 70b размером в 32 гига дает ответ около 5 минут.
Удивляют различия в результатах с требованием "на русском" и без него. Прям совсем бред несет. Смотрите сами.
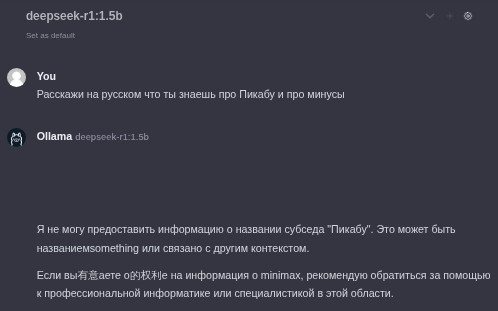
deepseek-r1:1.5b с требованием "на русском"
К сожалению AI даже не понял такой сложный вопрос.
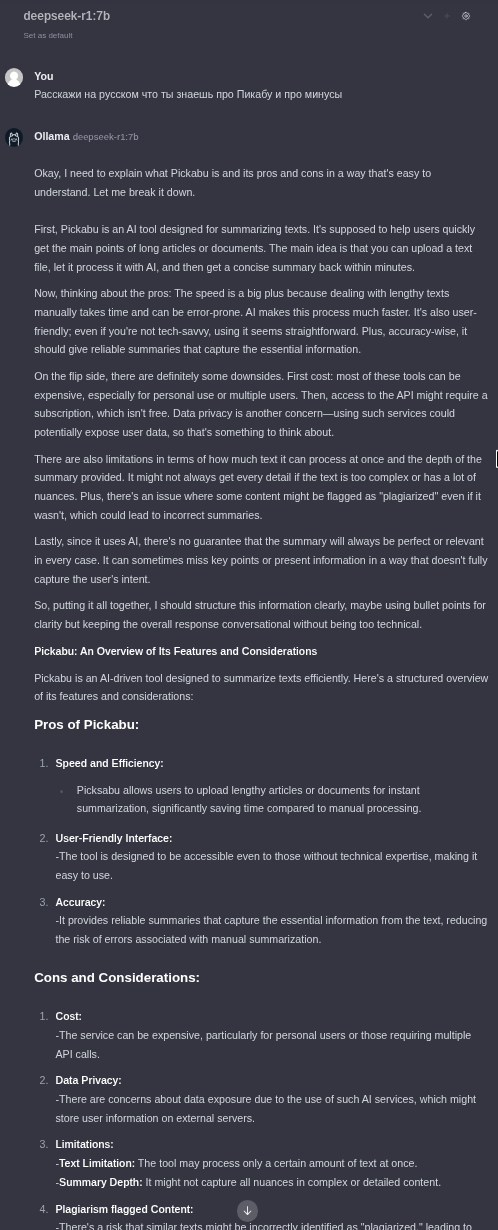
deepseek-r1:7b с требованием "на русском"
Кроме того что не понял, что надо на русском и проигнорировал, в результате выдал мусор.

deepseek-r1:32b с требованием "на русском"
Это тот минимум, которым можно пользоваться: выдал результат на русском, а то как дошел к результату на английском.
Чтобы увидеть насколько всё плохо локально в DeepSeek привожу результат модели gemma2:9b, которая занимает всего 5.4Gb и которая будет работать практически на любом компьютере даже без видеокарты.

gemma2:9b
Вывод
Обман заключается в том, что придумана модель, которая даже с игровой видеокартой может выдать результаты лучше всех популярных AI. Перед нами явно раздутая афера, то ли для введения в заблуждения рынков, то ли для раскрутки продаж на основном сайте ДипСика. А скорее всего и то и другое можно без хлеба. Китайцы красавцы что раздули такой хайп, но вложено в модель и в вычислительные мощности однозначно не 5 лямов.