


Установка программы2

Показать полностью
1

Наступает осень, а с ней и очередной учебный сезон. Но книги, конспекты и тетради — не единственное «оружие» современных школьников и студентов. В 21 веке трудно представить учебу без помощи персонального компьютера. Какие ПК и ноутбуки будут оптимальными покупками для учебы в 2025 году.
На днях, зайдя в «ДНС», я стал случайным свидетелем разговора, который заставил меня задуматься. Консультант уверенно объяснял пожилой паре, собравшейся сделать внуку подарок к 1 сентября, что компьютер «для учёбы, но без игр» будет стоить не меньше 100 тысяч рублей. Пока я не вмешался, продавец продолжал настойчиво предлагать дорогие модели с ненужными для школьных задач характеристиками.
К сожалению, такая ситуация — не редкость. Многие родители и родственники переплачивают за мощь, которая никогда не будет использована, или вовсе отказываются от покупки, считая её неподъёмной. Но правда в том, что хороший компьютер для учёбы можно собрать или выбрать вдвое дешевле — важно лишь понимать, какие критерии действительно важны.
В данной статье мы будем рассматривать компьютеры, которые подойдут для общих задач большинству учеников средних школ и высших учебных заведений. Для студентов, специальность которых плотно связана с графикой или архитектурой, а также специалистов рассмотрим в другой раз.
Главные задачи, которые должен уметь выполнять компьютер для учебы — легкий веб-серфинг, работа с документами, а также программами для видеозвонков и конференций. Сегодня с этим справляются практически все современные ПК. Поэтому в даже в случае ограниченного бюджета остается возможность приобрести устройство базового уровня, которое поможет ученику.
DEXP Aquilon O320
Среди домашних ПК один из таких вариантов — DEXP Aquilon O320. Это недорогой системный блок, оснащенный двухъядерным четырехпоточным процессором AMD Athlon 300GE, 8 ГБ оперативной памяти и SSD-накопителем на 256 ГБ. В комплект к устройству неплохо подойдет IPS-монитор DF24N1S от одноименной фирмы, который обладает разрешением Full HD и диагональю 23,8 дюйма. Этот набор, дополненный клавиатурой и мышью, обойдется пользователю в 22 000 рублей.
Альтернативным решением может стать «брат-близнец» DEXP Aquilon O331. Он имеет схожие основные параметры, но обладает чуть более быстрым процессором Pentium Gold G6405. Стоит такая модель немного дороже.
DEXP Atlas M14-I3W303
Если нужен бюджетный портативный компьютер, стоит обратить внимание на DEXP Atlas M14-I3W303. В отличие от многих конкурентов с ЦП из серии Intel Celeron, эта модель построена на гораздо более шустром Core i3-1215U. В оснащение ноутбука входит целых 16 ГБ оперативной памяти, 14-дюймовый IPS-экран с разрешением 1920х1200, а также SSD-накопитель на 256 ГБ. Несмотря на современную начинку, наш герой имеет довольно скромную цену 23 000 рублей.
OSiO FocusLine F160i-001
Для тех, кому экран с диагональю 14 дюймов покажется маленьким, альтернативой может стать OSiO FocusLine F160i-001. При сравнимой стоимости, этот ноутбук имеет немного более медленный процессор Core i3-1115G4 и аналогичный объем ОЗУ, зато оснащен крупным 16,1-дюймовым экраном с разрешением Full HD и SSD-накопителем на 512 ГБ.

Помимо базовых задач, при активной работе над сочинениями и рефератами ученикам может понадобиться работа со множеством вкладок в браузерах, а иногда и редактирование изображений. Для подобных целей лучше подходят компьютеры с более высоким быстродействием. Чаще всего именно такие ПК являются наиболее оптимальным выбором. Стоят они не сильно дороже базовых устройств, но взамен предлагают заметно большую производительность, которой хватит на много лет вперед.
DEXP Aquilon O337/0338
Одним из таких системных блоков является DEXP Aquilon O337/0338. Он оснащен быстрым шестиядерным процессором Core i5-12400, который способен одновременно обрабатывать 12 потоков вычислений. Устройство выпускается в двух версиях: с 8 и 256 ГБ памяти (ОЗУ/ПЗУ), а также с 16 и 512 ГБ. Вместе с монитором, клавиатурой и мышью из комплекта базовой сборки, его младшая версия обойдется пользователю в 36 000 рублей, а старшая лишь на 2 000 дороже.
DEXP Atlas H544
Если вы относитесь к любителям хранить на ПК множество данных, обратите внимание на похожий системный блок DEXP Atlas H544. За дополнительную тысячу рублей он готов предложить к вышеописанным параметрам SSD с объемом в целый терабайт.

DEXP AIO-MC B065
Любителям моноблоков наверняка понравится DEXP AIO-MC B065. Здесь тоже производительный Core i5-12400, 8 ГБ ОЗУ и 23.8-дюймовый IPS-экран. Внутри устройства установлен SSD объемом 512 ГБ, а для дополнительного накопителя формата 2,5 дюйма имеется еще один свободный слот. Приятный бонус — беспроводная клавиатура и мышь уже входят в комплект. Стоимость такого компактного и стильного устройства составляет 42500 рублей.
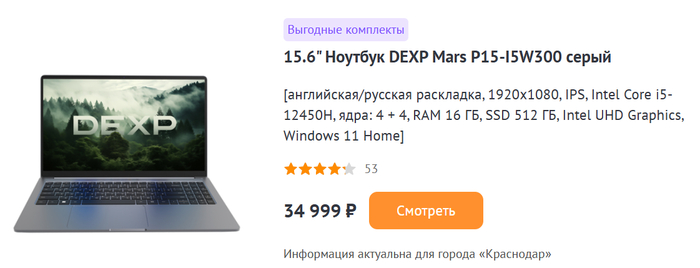
DEXP Mars P15-I5W300
Среди ноутбуков стоит присмотреться к DEXP Mars P15-I5W300 за 35 000 рублей. Эта модель основана на быстром процессоре Core i5-12450H, у которого четыре производительных и четыре энергоэффективных ядра. Дополняет картину 15,6-дюймовый IPS-экран с разрешением Full HD, SSD-накопитель на 512 ГБ и 16 ГБ ОЗУ: с такими параметрами апгрейд понадобится нескоро.
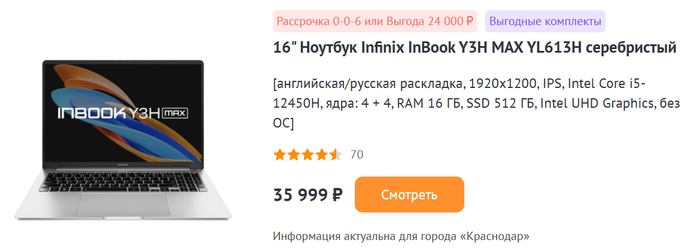
Infinix InBook Y3H MAX
В качестве альтернативы может выступить Infinix InBook Y3H MAX. У него схожие параметры, но другой экран. Здесь установлена более крупная 16-дюймовая IPS-матрица с разрешением 1920х1200 точек и соотношением сторон 16:10, что является наиболее удобной комбинацией характеристик для работы с документами.
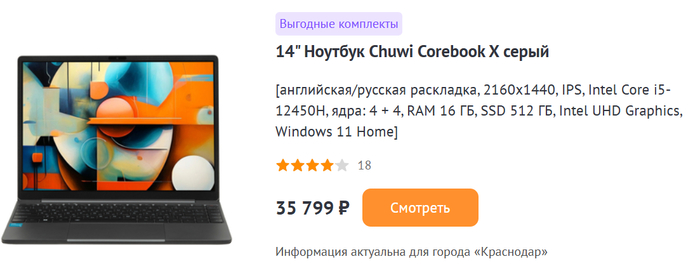
Chuwi Corebook X
Вопреки распространенному мнению, найти ноутбук с производительным процессором можно и среди компактных моделей. Одной из них является Chuwi Corebook X. За сравнимую цену устройство предлагает все возможности своих более крупных собратьев. А его изюминкой является 14-дюймовый IPS-экран — несмотря на малую диагональ, он обеспечивает гладкую картинку с высокой плотностью пикселей. Это достигается за счет повышенного разрешения в 2160x1440 точек.
Как видим, сегодня компьютер или ноутбук учебы стоит не так уж дорого. Базовые варианты можно приобрести за 20–25 000 рублей. Они порадуют умеренным быстродействием, и их возможностей хватит для решения основной массы учебных задач в ближайшее время.
Но куда более выгодной покупкой являются ПК с продвинутой конфигурацией. За счет высокой производительности они могут обеспечить молниеносную работу даже при множестве запущенных программ. А ее запас позволит не беспокоиться о необходимости апгрейда или замены устройства в течение нескольких лет как минимум. При этом обойдутся такие модели не сильно дороже: в большинстве случаев достойный вариант производительного компьютера, моноблока или ноутбука можно подобрать в диапазоне от 35 до 40 000 рублей.
Все указанные модели приведены как пример. Поэтому при выборе всегда можете ориентироваться на схожие по характеристикам компьютеры, моноблоки или ноутбуки. При ограниченном бюджете обратите внимание, чтобы выбранный ПК был оснащен как минимум процессором Intel Pentium Gold или AMD Athlon (на базе Zen), 8 ГБ оперативной памяти и SSD объемом не менее 240 ГБ. Максимум, который может понадобится для стандартных учебных задач – это компьютер на базе процессоров Core i5/ Ultra 5/Ryzen 5, 16 ГБ ОЗУ и SSD накопитель от 480 ГБ. Видеокарта в данном случае не играет роли: будет вполне достаточно и встроенной в процессор графики.
Ну а приобретать устройства с более высокими техническими характеристиками для учебы обычно не имеет смысла. Разницу в использовании (даже интенсивном) вы вряд ли почувствуете, а устареют они в будущем практически одновременно с описанными выше максимальными конфигурациями ПК.
P/S
Данная статья не несет в себе никакой рекламной нагрузи и предназначена для ознакомления с линейкой ПК и ноутбуков которые подойдут для выполнения стандартных задач необходимых в учебном процессе.
Если вы собираетесь сделать сюрприз своим близким, лучше обращайтесь к знакомым, которые хоть немного разбираются в технологиях, чтобы подобные "МЭээнеджеры" не могли ввести вас в заблуждение и подарок был действительно стоящим.
Если коснуться почему DEXP? Сам приобретал в свое время железку которая в режиме 24/7/365 отработала до 2023 года и умерла только из скачка напряжения который сначала убил ИБП а следом и все что стояло за ним.
Для лиги лени: ничего нового, проходите мимо
Часть 1. Общая
Часть 2. Gitlab и Nexus
Часть 3. Ansible и Ansible AWS
Часть 4. Наконец переходим к Proxmox
Часть 5, не запланированная. Обновляем Proxmox с 8.4 до 9.0. Неудачно.
Часть 6. Возвращаемся к запуску Ansible
Часть 7. Разница концепций
Разница концепций. Часть 7.1 Обновления компонентов и система информирования.
Разница концепций. Часть 7.2 Сети
Разница концепций. Часть 7.3 предисловие к теме «Дисковое пространство».
Разница концепций. Часть 7.4 «Локальное дисковое пространство».
Часть 8. Разница концепций
Разница концепций. Часть 8.1 Расположение дисков VM
Разница концепций. Часть 8.2 Добавление дисков к хосту
Разница концепций. Часть 8.3 Настройка нескольких дисков
Разница концепций. Часть 8.4 Управление диском виртуальной машины.
Часть 9. Скорости дисков
Часть 10. Внешние СХД, iSCSI
Часть 11. Система прав
Сначала еще раз немного теории.
Про разницу аутентификации (ты чьих будешь, чей холоп ?) и авторизации (у вас есть право) много раз написано. Кроме них есть и единый источник истины (Single Source of Truth, SSOT). Истины для системы управления жизненным циклом пользователеля, User lifecycle management (ULM), то есть для плановых замен паролей и сертификатов, проверка того, что учетная запись еще включена и имеет те же самые права, что и ранее, и прочее.
Есть два подхода – локальное хранение учетных записей, и удаленное хранение учетных записей.
С локальным хранением все понятно, с удаленным хранением тоже - Identity and access management (IAM or IdAM) or Identity management (IdM), ISO/IEC 24760-1 a framework for identity management, и прочие слова.
Вокруг этого начинаются протоколы, фреймворки, методологии, ISO\ГОСТ, и конечные реализации, в том числе реализации системы прав через ролевую модель, RBAC \ ABAC \ PBAC, вот это все.
Отдельно существуют системы хранения секретов – покойный RatticDB, модные современные HashiCorp Vault, Bitwarden Vault, их клоны и так далее.
В чем проблема? Для малой организации на 2 сервера и 20 сотрудников никакой проблемы с раздачей прав нет. Альтернативно одаренные администраторы сразу дают всем права «на все», хотя бывает и хуже. Как вам, например, заведение на Linux серверах учетных записей root1, root2, root3 и передача паролей от них? Потому что менять руками сложно, а ssh \ bash \ Ansible слова слишком страшные.
Реализаций центральной служб каталогов несколько, многие (как Novell Netware Directory Services (NDS) \ NetIQ eDirectory) уже ушли в небытие. Замена AD на SAMBA не является предметом данной статьи.
Предметом специальных BDSM практик является использование Realmd\ SSSD, или такое отвратительное явление, как хранение сертификатов в домене. Оба извращения не являются предметом данной статьи.
Что есть в Proxmox .
Конечно, в Proxmox есть встроенная авторизация, в web и SSH, и возможность использовать внешние сервисы.
По умолчанию в Proxmox (из коробки) включены:
Linux PAM standard authentication
Proxmox VE authentication server
Можно добавить Microsoft Active Directory (AD), LDAP и OpenID. Можно добавить 2FA.
В чем разница Linux PAM standard authentication и Proxmox VE authentication server?
Отвечает reddit:
long story short: PAM users are normal gnu/linux user, as in username/password that you can use to log in via ssh.
PVEAS otoh are Proxmox users, they cannot be used to log in via ssh, they are stored in the clustered/distributed storage along with proxmox configuration and they are the same on all the nodes of a proxmox clusters
Как это работает в GUI на уровне DC
Завожу пользователя user_pam как Linux PAM на уровне DC, но в поле заведения пользователя нет пароля.
Есть выбор группы, но нет предопределенных групп.
При попытке смены пароля для пользователя user_pam получаю ошибку:
change password failed: user 'user_pam' does not exist (500)
В /etc/passwd – нет такого юзера.
В /etc/pve/user.cfg есть оба созданных
По команде «pveum user list» выводится таблица того, что насоздавал. В том числе user_pam@pam.
По команде pveum passwd user_pve@pve можно сменить пароль для юзера в PVE
По команде pveum passwd user_pam@pam сменить пароль тоже нельзя – получаю ошибку
change password failed: user 'user_pam' does not exist
Но в таблице (pveum user list) он есть.

Когда я заводил юзера user_pve в realm Proxmox VE, система сразу предложила не только создать юзера, но и назначить ему права из заранее созданных наборов ролей – от Administrator до No access.
Но это окно почему-то возникает только один раз, и это магия.
В остальных случаях оказывается, что интерфейс писали люди со своими представлениями, и права выставляются на вкладке Permission, это не только именование раздела.
И изнутри свойств объекта user эти права можно только посмотреть. Как и из Permission, или add, или remove
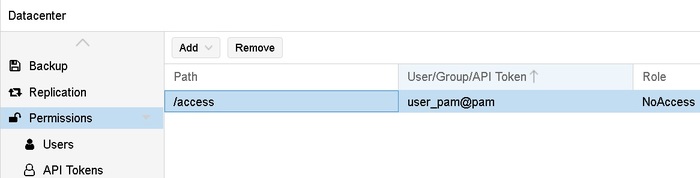
Остальные права выставляются как права на объект в дереве обьектов
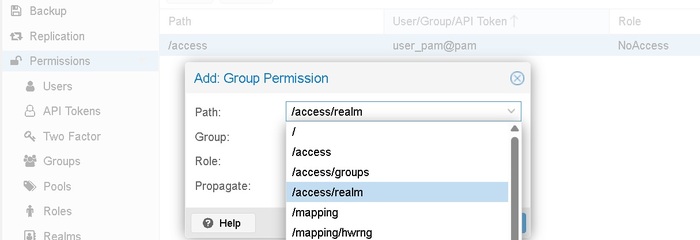
В сочетании с ролями «что с ними делать». Наличие двух ролей Administrator и PVEAdmin только делает жизнь веселее
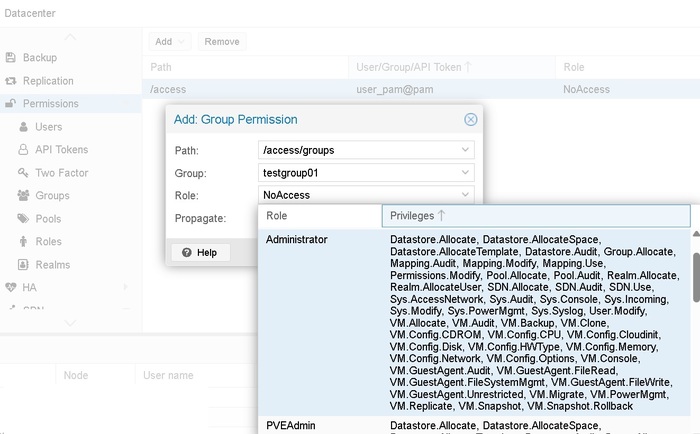
Управление входом в GUI отличается тем же своеобразием.
В CLI я вижу пользователя как root@pam
Но войти в GUI, как root@pam я не могу, вне зависимости от выбора realm.
То есть, система не может сама опознать, что я ввел @realm, и realm надо выбирать вручную в GUI, и входить без указания @realm.
Управление ролями в GUI тоже отличается неожиданным подходом. К роли можно выбрать привилегии, но в выпадающем списке нет чекбоксов, но работает OnClick и OnClickAgain , то есть выбор по клику. Это было очень неожиданно.
Чуть странная, с первого взгляда, но понятная ролевая модель. То что у Microsoft называется AGDLP, тут соответственно это User <> Group <> Role <> Permissions
Отредактировать права из GUI нельзя, можно только удалить и создать. УДОБНО!
Права на «просто логин» можно дать через роль No Access, ок, понятно.
Права на консоль можно дать через привилегию Sys.Console, только она не работает «из коробки». Привилегию я выдал, причем на /», причем наследование тоже какое-то не очевидное. Но это привилегия не на запуск консоли, а на право на запуск консоли, и консоль снова запрашивает логин-пароль, но user_pve прав на вход в консоль не имеет. Решение «делать через sudoerr» описано, но проблеме со всей системой прав уже семь лет.
Наблюдается расхождение. Пользователь может быть заведен в Linux, и иметь права на SSH, и на su, но не иметь прав на pveum.
Очень, очень странно.
Примечание. В Hyper-V , несмотря на развесистую систему прав, нет делегирования права на только Hyper-V или отдельную оснастку. Можно знатно поиграть в PowerShell Web Access (PSWA), PswaAuthorizationRule и security descriptor definition language (SDDL), но это надо знать, во что играть.
Заключение.
Система понятна, много описано, много описано на практических примерах и форуме. Жить можно, но root отключить нельзя.
По многим причинам, в том числе я еще не описывал все приключения с кластеризацией.
Литература
Difference between RBAC vs. ABAC vs. ACL vs. PBAC vs. DAC
Red Hat Chapter 2. Using Active Directory as an Identity Provider for SSSD
Red Hat Chapter 3. Using realmd to Connect to an Active Directory Domain
Realmd and SSSD Active Directory Authentication
Proxmox User Management
Proxmox Proxmox VE Administration Guide - 14. User Management
Proxmox forum group permissions
Proxmox forum "change password failed: user 'johnsmith' does not exist (500)"
Proxmox forum Add user/group account with ssh access and root privileges
Proxmox forum SSH Login with VE Authentication Server
Proxmox Bugzilla Bug 1856 - System Updates with non-root User using Web-GUI
Proxmox CLI pveum(1)
Reddit ELI5: PAM vs PVE Authentication Server
Microsoft PowerShell Web Access in action
Для лиги лени: ничего нового, проходите мимо.
Часть 1. Общая
Часть 2. Gitlab и Nexus
Часть 3. Ansible и Ansible AWS
Часть 4. Наконец переходим к Proxmox
Часть 5, не запланированная. Обновляем Proxmox с 8.4 до 9.0. Неудачно.
Часть 6. Возвращаемся к запуску Ansible
Часть 7. Разница концепций
Разница концепций. Часть 7.1 Обновления компонентов и система информирования.
Разница концепций. Часть 7.2 Сети
Разница концепций. Часть 7.3 предисловие к теме «Дисковое пространство».
Разница концепций. Часть 7.4 «Локальное дисковое пространство».
Часть 8. Разница концепций
Разница концепций. Часть 8.1 Расположение дисков VM
Разница концепций. Часть 8.2 Добавление дисков к хосту
Разница концепций. Часть 8.3 Настройка нескольких дисков
Разница концепций. Часть 8.4 Управление диском виртуальной машины.
Часть 9. Скорости дисков
Часть 10. Внешние системы хранения данных
Что есть в 2025 году из протоколов подключения систем хранения?
FCP, Fibre Channel Protocol. Старый, постепенно отмирающий, но менять надежность и привычность FCP на DCB сложно. Не столько сложно технически, сколько организационно. Для внедрения нужно будет бить сетевиков палкой, чтобы не пытались рассказывать про LAG вне контекста Mellanox 6 (или 8, не помню).
iSCSI \ iSCSI Extensions for RDMA (iSER). C iSCSI работает вообще все, вопрос с какой скоростью и с какими настройками. iSER при этом под вопросом самого своего существования.
SMB Multichannel. Живее всех живых.
NVMe over Fabrics в ее вариантах – over FC, over Ethernet, over IB.
Поскольку речь про Proxmox, то SMB Multichannel, крайне удобная и рабочая конструкция для S2D, Storage Spaces Direct, тут рассматриваться не будет.
Подключение по FC сейчас, ввиду политики Broadcom, вещь неоднозначная.
Остается iSCSI.
Открываем OceanStor Dorado and OceanStor 6.x and V700R001 Host Connectivity Guide for Red Hat и читаем до просветления главу Establishing iSCSI Connections и Recommended Configurations for 6.x and V700R001 Series Storage Systems for Taking Over Data from Other Huawei Storage Systems When the Host Uses the OS Native Multipathing Software.
Или, если у вас другой вендор системы хранения, читаем его документацию. Вообще, конечно, очень странно устроен Linux в части device-mapper-multipath. Точнее, у Hyawei пишется, что настройки нужно делать в alua, и не содержит указаний на настройки rr_min_io, хотя path_selector и выставлен в "round-robin 0". В главе про ESXi для AFA (all flash array) указано про rr=1, а тут нет. Но это настройки больше про скорость, а так и 1000 IOPS сойдет (но может быть не так просто).
Теперь к практике. Сделаю iSCSI target на Windows server, эта функция там из коробки лет 20, и добавлю к Proxmox.
Сначала спланирую сеть, как обычно – с извращениями.
Vlan 11, Windows server 172.16.211.151/24; Proxmox 172.16.211.162/24
Vlan 12, Windows server 10.0.12.151/24; Proxmox 10.0.12.162/24
LACP для iSCSI не рекомендован много кем, в том числе из-за сложностей с Multiple Connections per Session.
Добавляю новый свитч:
New-VMSwitch -Name Privet01 -SwitchType Private
Добавляю по 2 сетевые в обе VM -
Add-VMNetworkAdapter -VMName Proxmox -SwitchName Privet01 -Name V11
Add-VMNetworkAdapter -VMName Proxmox -SwitchName Privet01 -Name V12
Set-VMNetworkAdapterVlan -VMName Proxmox -Access -VlanId 11 -VMNetworkAdapterName V11
Set-VMNetworkAdapterVlan -VMName Proxmox -Access -VlanId 12 -VMNetworkAdapterName V12
и аналогично для второй VM
В этой конфигурации есть проблема. По умолчанию для VMNetworkAdapter включен VMQ. В некоторых сценариях и с некоторыми сетевыми картами эта функция работает очень плохо, вызывая какие-то разрывы, там, где не было ни единого разрыва, причем влияя на весь сетевой стек.
Я бы рекомендовал всем, кто использует Hyper-V и VMQ, проводить тестирование работы до запуска в продуктив.
В этой конфигурации есть еще одна проблема. После создания нового виртуального коммутатора и добавления двух сетевых карт в VM Windows server, первая сетевая карта в VM перестала получать адрес по DHCP, и основной адаптер стал (может, и был, я не проверил)
Microsoft Hyper-V Network Adapter #2
Первый раз такое вижу. Ситуация усугубляется тем, что старый интерфейс управления сетями в Windows server 2025 спрятали, а новый убогий.
Удалил вновь созданный виртуальный коммутатор, хотя он был SwitchType Private, все пересоздал, перезагрузил, сделал статичный IP внутри VM – вроде, работает.
Вопрос «что это было» не раскрыт.
Настройка VM Windows Server
Самое неудобное – это найти по MAC адресу, какая сетевая карта куда включилась.
Get-NetAdapter
вы думали
Set-NetIPAddress -InterfaceIndex 10 -IPAddress 172.16.211.151 -PrefixLength 24 ?
Ничего подобного.
New-NetIPAddress -InterfaceIndex 10 -IPAddress 172.16.211.151 -PrefixLength 24
New-NetIPAddress -InterfaceIndex 12 -IPAddress 10.0.12.151 -PrefixLength 24
И, конечно,
Install-WindowsFeature -Name FS-iSCSITarget-Server –IncludeManagementTools
Настройка Proxmox
ip a, только для того чтобы увидеть MAC адреса интерфейсов
nano /etc/network/interfaces
auto vmbr1.11
iface vmbr1.11 inet static
address 172.16.211.162/24auto vmbr1
iface vmbr1 inet manual
bridge-ports eth2
bridge-stp off
bridge-fd 0
bridge-vlan-aware yes
bridge-vids 11
не забываем про ifreload -a
И даже пинг не работает на таком свиче. Что-то прописать забыл. Очень неудобная история с системой интерфейсов в Proxmox. С одной стороны со схемой тут я переусложнил, с другой – в целом система настройки Linux bridge – vlan interface не самая удобная. Слишком много сущностей приходится прописывать.
Примечание. Не забыл. Прописал лишний раз – у меня же отдельный интерфейс отдан в VM, ему не надо настраивать vlan, как будто он в транк включен. Поэтому все проще, не забыть разрешить any any в windows firewall (в рабочих сетях так делать, конечно, не надо), и :
iface eth2 inet manual
auto vmbr2iface vmbr2 inet manual
address 172.16.211.162/24
bridge-ports eth2
bridge-stp off
bridge-fd 0
аналогично настроить iface eth3, и заработало .
желательно сразу посмотреть ID инициатора -
cat /etc/iscsi/initiatorname.iscsi | grep InitiatorName=
Отдаем iSCSI target с Windows server
Тут ничего нового уже много лет. Server manager – files services – iSCSI – далее- далее – прописать (для стенда сойдет) IP адреса и готово. Конечно, с CHAP. Получаем iSCSI target с Windows server
Два НО.
Первое НО. Нужно заранее прочитать про Set-IscsiTargetServerSetting и сделать
Set-IscsiTargetServerSetting -IP 192.168 (что там у меня) -Enable $False
и проверить
netstat -an | findstr "3260"
Менять ли приоритеты для IPv6 или их отключать – ваше личное дело. Напоминаю, что чекбокс «отключить ipv6» не работает уже лет 10. Нужно делать как написано в Guidance for configuring IPv6 in Windows for advanced users
или сделать
Get-NetIPAddress | Select IPAddress
Set-IscsiTargetServerSetting для ipv6
и перепроверить по старой школе
netstat -an | findstr "3260"
Или по новой школе
Get-NetTCPConnection | where {$_.LocalPort -eq 3260}
Второе НО.
Для тестов не забыть сделать:
New-NetFirewallRule -DisplayName "001 permit any 172.16.211.162" -Direction Inbound -Action Allow -RemoteAddress 172.16.211.162
New-NetFirewallRule -DisplayName "001 permit any 10.0.12.162" -Direction Inbound -Action Allow -RemoteAddress 10.0.12.162
С IPv6 поступать опционально, внимательно прочитав Guidance for configuring IPv6 in Windows for advanced users
Подключаем iSCSI target с Windows server на Proxmox (Initiator) - отладка
В GUI подключение iSCSI находится в datacenter-storage, а не в управлении хостом.
Редактируем /etc/iscsi/iscsid.conf согласно статье Proxmox Multipath и рекомендациям вендора СХД. Или не редактируем!
открываем GUI и .. и видим фигу, потому что полей для авторизации \ CHAP нет, а без них никакого target.
Отключаю CHAP, и все равно ничего не видно. Как обычно, в GUI никаких деталей нет, поэтому проверять придется руками.
Начнем по встроенной инструкции по кнопке HELP в GUI -
pvesm status
pvesm scan iscsi 172.16.211.151:3260:3260
и получу iscsiadm: No portals found
Пойду почитаю Подключение iSCSI диска в Proxmox,
iscsiadm --mode discovery --type sendtargets --portal 172.16.211.151
и получу тот же - iscsiadm: No portals found
nc -z 172.16.211.151 3260
выдает ничего. Пинг есть.
Поиграем в отладку!
nc -v 172.16.211.151 3260 со стороны инициатора (proxmox) работает с выводом результата
[172.16.211.151] 3260 (iscsi-target) open
netstat -an | findstr "211" со стороны target (Windows) работает с выводом результата
TCP 172.16.211.151:3260 172.16.211.162:37638 ESTABLISHED

Осталось протереть глаза, и оказалось, что я, вводя разрешенные IP в target, ввел не 172.16.211.162, а 172.16.11.162
ввел нужные данные, и
pvesm scan iscsi 172.16.211.151:3260
выдал все что надо.
Иначе бы пришлось лезть в tcpdump с обеих сторон. Для Windows, после ухода на пенсию (deprecated) Microsoft Network Monitor и Microsoft Message Analyzer, пока что есть wireshark.
Верну обратно chap, user = user, password = password1234, добавлю через GUI, посмотрю что вышло в
/etc/pve/storage.cfg
Вышло как по руководству,
iscsi: mynas
portal 10.10.10.1
target iqn.2006-01.openfiler.com:tsn.dcb5aaaddd
content none
И затем в GUI делаем Datacenter – Storage – add – LVM –
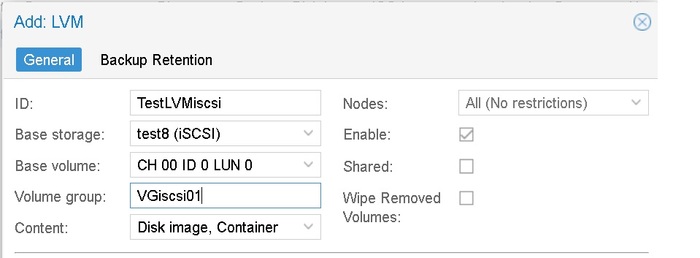
То, что это делается на уровне DC, а не на уровне хоста, раздражает конечно. Как и vmotion диска на уровне VM – hardware.
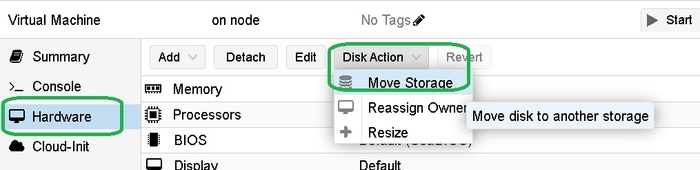
При этом, даже когда я включил CHAP, но или ранее был сделан логин, или еще по каким-то причинам сессия не переподключилась, то можно сделать LVM том , но при попытке перенести на него тестовую VM – получить:
iscsiadm: initiator reported error (8 - connection timed out)
iscsiadm: Could not login to [iface: default, target: iqn.1991-05.com.microsoft:win25-target01-target, portal: 192.168.2.150,3260].
iscsiadm: initiator reported error (19 - encountered non-retryable iSCSI login failure)
iscsiadm: Could not log into all portals
После таких включений на стендах всегда надо перегружать initiator, да и target не повредит.
Подключаем iSCSI target с Windows server на Proxmox (Initiator) с CHAP
Для начала удалю все, что сделал до этого – пустой LVM и подключение iSCSI. Тоже неудобно, конечно – есть у тебя том, зачем на нем еще сущности типа LVM применять.
Удалить iSCSI подключение из управления DC нельзя, будет ошибка
delete storage failed: can't remove storage - storage is used as base of another storage (500)
При этом все сущности хранения лежат в одной куче – и iSCSI, и LVM, и все на уровне DC, а не ноды. Поэтому тут тоже надо сразу делать соглашение по именованию.
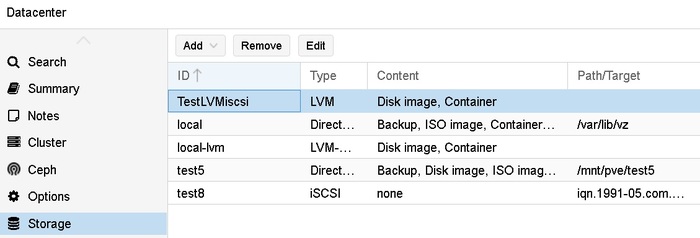
Удалю сначала LVM, тогда дает удалить и iSCSI.
Без ввода CHAP в GUI (его там нет) подключение к порталу проходит . Но при попытке создать LVM не возникает список томов для создания LVM.
Придется на ручном приводе (в норме, конечно, через Ansible)
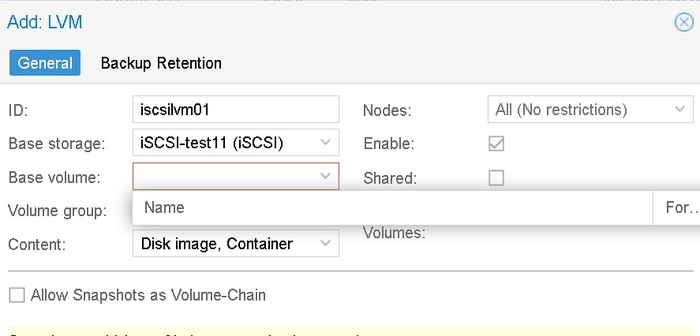
nano (или vi) /etc/iscsi/iscsid.conf
Конфигурация содержит блоки:
1 # To enable CHAP authentication set node.session.auth.authmethod
2 # To set a CHAP username and password for initiator
3 # To set a CHAP username and password for target(s)
4 # To enable CHAP authentication for a discovery session to the target, set discovery.sendtargets.auth.authmethod to CHAP. The default is None.
5 # To set a discovery session CHAP username and password for the initiator
6 # To set a discovery session CHAP username and password for target(s)
Мне нужны
node.session.auth.authmethod = CHAP
node.session.auth.username = user
node.session.auth.password = password1234
и потом по вкусу
systemctl restart iscsid
iscsiadm -m node --portal "172.16.211.151" --login
после чего должны получить:
iscsiadm: default: 1 session requested, but 1 already present.
iscsiadm: Could not log into all portals
посмотрим, что там:
iscsiadm -m discovery -p 172.16.211.151 -t st
о, все работает, нужные порталы есть, не нужных порталов нет!
Если вы все сделали правильно, то в GUI появится возможность выбора base volume
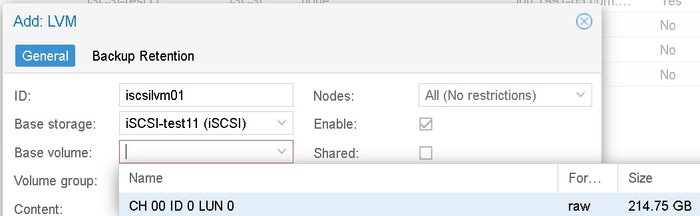
И при попытке создать LVM вы получите ошибку –
create storage failed: command '/sbin/pvs --separator : --noheadings --units k --unbuffered --nosuffix --options pv_name,pv_size,vg_name,pv_uuid /dev/disk/by-id/scsi-360003ff44dc75adcbb96b955813029da' failed: exit code 5 (500)
Хотя должна была быть другая ошибка -
create storage failed: vgcreate vg01 /dev/disk/by-id/scsi-360003ff44dc75adc839073953a451b73 error: Cannot use device /dev/sdc with duplicates. (500)
Отключу один IP на windows target и проверю:
iscsiadm -m session
service open-iscsi status
systemctl restart iscsid.service
systemctl restart open-iscsi.service
/etc/init.d/open-iscsi restart
Ничего не помогает, сессия со стороны Linux до 10.0.12.151, была и осталась. Со стороны Windows target TCP сессий при этом нет.
И так ничего не получается.
И ладно, да и пошло все, семь бед – один reboot.
после ребута все хорошо, один путь, но при создании группы получаю ошибку, что группа уже создана!
create storage failed: device '/dev/disk/by-id/scsi-360003ff44dc75adcbb96b955813029da' is already used by volume group 'VGiscsi01' (500)
Удалю ее (на уровне хоста в disks – LVM) и пересоздам.
ВЖУХ И ВСЕ СОЗДАЛОСЬ.
Снова удалю, верну обратно два пути на target, перезагружу proxmox (видимо, самый надежный метод),
посмотрим, что там:
iscsiadm -m discovery -p 172.16.211.151 -t st , отлично, два портала на месте.
Создам еще раз LVM через GUI, и отлично, ошибка создания воспроизвелась,
create storage failed: command '/sbin/pvs --separator : --noheadings --units k --unbuffered --nosuffix --options pv_name,pv_size,vg_name,pv_uuid /dev/disk/by-id/scsi-360003ff44dc75adcbb96b955813029da' failed: exit code 5 (500)
И группа iscsiVG02 создалась! Хотя и не должна была!
Надо будет воспроизвести и баг репорт написать.
Подключаем iSCSI target с Windows server на Proxmox (Initiator) с CHAP и Multipath
Читаем ISCSI Multipath, видим что текст устарел, идем на Multipath. В втором окне не забываем открыть Подключение iSCSI диска в Proxmox – там как раз про multipath есть параграф.
В старом тексте есть абзац
# apt-get install multipath-tools
В новом тексте
apt install multipath-tools
Но почему-то в середине текста.
Окей, multipath-tools поставил,
nano /etc/iscsi/iscsid.conf поправил, lsblk посмотрел, wwid сравнил
/lib/udev/scsi_id -g -u -d /dev/sdc
/lib/udev/scsi_id -g -u -d /dev/sdd
остальные настройки прописал, только для 7.3-6. сервис был
systemctl restart multipath-tools.service
а в 9 стал
systemctl restart multipathd.service
или я опять что-то путаю.
Доделаю. multipath -r; multipath –ll; multipath -v3
Следующий раздел меня, конечно, удручает:
Multipath setup in a Proxmox VE cluster If you have a Proxmox VE cluster, you have to perform the setup steps above on each cluster node. Any changes to the multipath configuration must be performed on each cluster node. Multipath configuration is not replicated between cluster nodes.
Впрочем, на ESXi с прописыванием esxcli storage nmp satp list и esxcli storage nmp satp rule, на каждом хосте, все то же самое.
Далее далее, новая VG создалась. ВЖУХ и трансфер прошел.
На физическом сервере можно было померять скорость доступа и нагрузку на интерфейсы, но в nested среде особого смысла в этом нет.
Может быть, потом.
Литература
Microsoft Set-IscsiTargetServerSetting
Microsoft Simplified SMB Multichannel and Multi-NIC Cluster Networks
Microsoft Guidance for configuring IPv6 in Windows for advanced users
Microsoft New-NetFirewallRule
Huawei OceanStor Dorado and OceanStor 6.x and V700R001 Host Connectivity Guide for Windows
Huawei OceanStor Dorado and OceanStor 6.x and V700R001 Host Connectivity Guide for Red Hat
Huawei Recommended Configurations for 6.x and V700R001 Series Storage Systems for Taking Over Data from Other Huawei Storage Systems When the Host Huawei Uses the OS Native Multipathing Software.
NVMe over Fabrics: Fibre Channel vs. RDMA
Synology What is SMB3 Multichannel and how is it different from Link Aggregation?
Обзор NVMe over Fabric, NVMe-oF
Configuring Highly Available NVMe-oF Attached Storage in Proxmox VE
High Performance Shared Storage for Proxmox VE
RH 4.4. Multipaths Device Configuration Attributes
RH Chapter 5. Modifying the DM Multipath configuration file
ISCSI: LACP vs. MPIO
802.3ad LACP for ISCSI
Proxmox Network Configuration
Proxmox Storage: iSCSI
Proxmox Multipath
Proxmox forum iSCSI Huawei Oceanstore Dorado 3000 LVM and Multipath
Proxmox forum How to Configure and Manage iSCSI Storage in Proxmox for Your Virtual Machines?
Proxmox forum How to setup multipathing on Proxmox VE?
Proxmox forum iSCSI with CHAP
Proxmox forum Proxmox, iSCSI and CHAP
Proxmox forum Proxmox 7.1, iSCSI, chap, HPE MSA and problems
Proxmox forum How to move VM to another storage
Подключение iSCSI диска в Proxmox
Для лиги лени: неудачная часть. Пусть все видят, как я ничего не умею.
Часть 1. Общая
Часть 2. Gitlab и Nexus
Часть 3. Ansible и Ansible AWS
Часть 4. Наконец переходим к Proxmox
Часть 5, не запланированная. Обновляем Proxmox с 8.4 до 9.0. Неудачно.
Часть 6. Возвращаемся к запуску Ansible
Часть 7. Разница концепций
Разница концепций. Часть 7.1 Обновления компонентов и система информирования.
Разница концепций. Часть 7.2 Сети
Разница концепций. Часть 7.3 предисловие к теме «Дисковое пространство».
Разница концепций. Часть 7.4 «Локальное дисковое пространство».
Часть 8. Разница концепций
Разница концепций. Часть 8.1 Расположение дисков VM
Разница концепций. Часть 8.2 Добавление дисков к хосту
Разница концепций. Часть 8.3 Настройка нескольких дисков
Разница концепций. Часть 8.4 Управление диском виртуальной машины.
Часть 9. Скорости дисков
Отказ от ответственности. Эта часть тестов предназначена для описания общей идеологии тестирования. Результаты и методология могут быть неправильными и показывать некорректный, или неприменимый в вашем случае, результат.
Базовые скорости, от которых я буду отталкиваться, сформированы как результат не очень показательных тестов из статей:
Тестирование локальных дисков и систем хранения данных: подводные камни. Часть 1 - общая
Тестирование локальных дисков и систем хранения данных: подводные камни. Часть 2 - виртуализация
Тестирование локальных дисков и систем хранения данных: подводные камни. Часть 3 – цифры и предварительные итоги
Тестирование локальных дисков и систем хранения данных: подводные камни. Часть 4 – что там изнутри виртуализации
Новый ноутбук: скорость, плюсы-минусы, DiskSPD, Hyper-V и продолжение про методику тестирование скорости
Новый ноутбук 2: скорость, плюсы-минусы, DiskSPD, Hyper-V и далее
Итак, тесты.
Тест скорости локальных дисков сформирован исходя из того, что у меня на ноутбуке 64 Гб памяти, 6 ядер и 12 потоков. И это AMD, который показывает на AMD варианте HT хороший прирост скорости вплоть до использования всех 12 потоков при дисковых операциях.
Поэтому тесты планировались следующие: (потом все поменялось)
Для Windows:
diskSPD для 8 и 12 потоков на одном 150 Гб файле, с файловой системой NTFS, размер кластера 4к.
diskSPD для 8 и 12 потоков на одном 150 Гб файле, с файловой системой NTFS, размер кластера 8к.
Тесты на 5 минут: тест 1 - 100% чтение, тест 2 - 100% записи. IO блок 4k
Итого 8 тестов.
Для Windows server внутри Hyper-V:
Виртуальной машине будет выделено 8 ядер и 24 Гб памяти. Очередь 16.
diskSPD для 8 потоков на одном 150 Гб файле, с файловой системой NTFS, размер кластера внутри VM 4к, параметры vhdx диска LogicalSectorSize 4KB PhysicalSectorSizeByte 4K
diskSPD для 8 потоков на одном 200 Гб файле, с файловой системой NTFS, размер кластера 4к внутри VM, параметры vhdx диска LogicalSectorSize 4KB PhysicalSectorSizeByte 4K, NTFS диска с файлом VM с размером кластера 8k.
Полученные данные надо было бы сводить в таблицу, но тогда будет картинка, а это неудобно, поэтому:
тестовый прогон, когда я ошибся с параметром очереди:
В IOPS per thread указан разброс, с округлением вниз, до целых тысяч.
Короткие тесты хоста (d10 = 10 секунд на тест), в данном случае моего ноутбука.
Новый стенд я так и не собрал, а на основных тестовых стендах крутятся совсем другие задачи.
Расшифровка параметров: diskspd Command line and parameters
-t8 -w0 -b4k -W10 -o2 -d10 -Suw -D –L
-t8 -t<count> Number of threads per target.
-w0 -w<percentage> Percentage of write requests to issue (default = 0, 100% read).
-b4k -b Block size in bytes or KiB, MiB, or GiB (default = 64K).
-W<seconds> Warmup time – duration of the test before measurements start
-o2 -o<count> Number of outstanding I/O requests per-target per-thread.
-d10 -d<seconds> Duration of measurement period in seconds, not including cool-down or warm-up time (default = 10 seconds).
-Suw -S[bhmruw] This flag modifies the caching and write-through modes for the test target.
-Su Disable software caching, for unbuffered I/O.
-Sw Enable write-through I/O. This opens the target with the FILE_FLAG_WRITE_THROUGH flag. This can be combined with either buffered (-Sw or -Sbw) or unbuffered I/O (-Suw).
-D<milliseconds> Capture IOPs higher-order statistics in intervals of <milliseconds>
-L Measure latency statistics.
-c<size> В пример не попало.
Короткие тесты хоста NTFS 4k
-t8 -w0 -b4k -W10 -o2 -d10 -Suw -D -L = 42-44 k IOPS per thread = 347 k IOPS total
-t12 -w0 -b4k -W10 -o2 -d10 -Suw -D -L = 36-36 k IOPS per thread = 453 k IOPS total
-t8 -w100 -b4k -W10 -o2 -d10 -Suw -D -L = 33-34 k IOPS per thread = 272 k IOPS total
-t12 -w100 -b4k -W10 -o2 -d10 -Suw -D -L = 27-28 = 340 k IOPS total
Короткие тесты хоста NTFS 8k
Очень странный результат, я ожидал, что будет падение в разы.
По моему, я померял скорость кеша NVME .
-t8 -w0 -b4k -W10 -o2 -d10 -Suw -D -L = 44-44k 44 k IOPS per thread = 356k IOPS total
-t12 -w0 -b4k -W10 -o2 -d10 -Suw -D –L = 36-38 k IOPS per thread = 459 k IOPS total
-t8 -w100 -b4k -W10 -o2 -d10 -Suw -D –L = 39-39 k IOPS per thread = 315 k IOPS total
-t12 -w100 -b4k -W10 -o2 -d10 -Suw -D –L = 31-33 = 397 k IOPS total
В последнем тесте записано 16.275.570.688 байт = почти 16 Гб, столько оперативной памяти вроде там быть не должно.
Результаты рабочего теста хоста. 5 минут на тест (как оказалось, мало). NTFS 4k
-t8 -w0 -b4k -W10 -o16 -d300 -Suw -D -L = 29-30 = 239
-t12 -w0 -b4k -W10 -o16 -d300 -Suw -D –L = 25-28 = 325
-t8 -w100 -b4k -W10 -o16 -d300 -Suw -D –L = 14-15 = 120 . Вот и падение на запись появилось, куда ниже данных короткого теста.
-t12 -w100 -b4k -W10 -o16 -d300 -Suw -D -L = 9-10 = 119
Результаты рабочего теста хоста. 5 минут на тест (как оказалось, мало). NTFS 8k
-t8 -w0 -b4k -W10 -o16 -d300 -Suw -D –L = 38-39 = 313
-t12 -w0 -b4k -W10 -o16 -d300 -Suw -D –L = 29-32 = 371
-t8 -w100 -b4k -W10 -o16 -d300 -Suw -D –L = 12-12 = 102. Вот и падение на записи блоком 4к на диск с разметкой 8к. Было 120, стало 102. Точнее, было 15 на тред, стало 12 на тред. И это с включенным кешем на запись на уровне диска, который не понятно, учитывается при ключе -Suw или нет. И когда этот чекбокс применяется, до перезагрузки или после
-t12 -w100 -b4k -W10 -o16 -d300 -Suw -D -L – 7-7 = 94
окей, базовые цифры понятны.
Теперь то же самое, но с отключенным буфером записи на уровне дисков.
-t8 -w100 -b4k -W10 -o16 -d300 -Suw -D -L
NTFS4k = 14..14 = 117
NTFS8k = 12..12 = 100
окей, падение есть, но все же меньше 20%. По моему, я все равно буфер меряю.
Результаты теста VM Windows Server 2025 Evaluation с 8 ядрами и 24 Гб памяти
настройки VHDX: LogicalSectorSize : 4096 ; PhysicalSectorSize : 4096
NTFS 4k host, NTFS 4k внутри vhdx
-t6 -w0 -b4k -W10 -o16 -d300 -Suw -D -L = 4-93 = 390
-t8 -w0 -b4k -W10 -o16 -d300 -Suw -D -L = 9-75 = 475
-t6 -w100 -b4k -W10 -o16 -d300 -Suw -D -L = 9-10 = 61
-t8 -w100 -b4k -W10 -o16 -d10 -Suw -D –L = 10-14 = 90
Просадка идет по 2 потокам из 8, так что 6 физических ядер справляются полностью, но вот Hyper-V транслирует задачи на логические потоки AMD, видимо «так себе». Так что надо будет смотреть внимательнее, но у меня ни одного сервера на AMD нет. И в дальнейшем надо ограничивать виртуальные машины по числу физических ядер на виртуалку, если нужен максимум без просадок.
-t8 -w100 -b4k -W10 -o16 -d300 -Suw -D -L = 2.4 – 2.6 = 20
-t12 -w0 -b4k -W10 -o16 -d300 -Suw -D –L = 4-76 = 491
тесты на 12к тоже прошли, но они показывают только продолжение деления потоков.
NTFS 8k host, NTFS 4k внутри vhdx
-t6 -w0 -b4k -W10 -o16 -d300 -Suw -D -L = 4-94 = 404. При том, что три потока по 74.
-t8 -w0 -b4k -W10 -o16 -d10 -Suw -D –L = 9-63 = 416
-t8 -w100 -b4k -W10 -o16 -d10 -Suw -D -L = 1.8 = 14. Вот это падение. Причем тест длиной в 10 секунд.
-t8 -w0 -b4k -W10 -o16 -d300 -Suw -D –L= 9-78 = 482
-t8 -w100 -b4k -W10 -o16 -d300 -Suw -D –L = 2.5 = 20 . Падение .. какое-то.
Что из этого можно понять? Ничего, кроме того, что с тестами что-то не так.
Физика -t8 -w0 = 29-30 = 239
VM -t8 -w0 = 9-75 = 475.
Так быть не должно. И, очень может быть, что источник проблемы – кеширование дисков VM средствами ОС. Есть у Windows такая нехорошая привычка, втихаря кешировать файлы данных, пока оперативной памяти хоста хватает, и еще немного после. Видно это явление через Rammap, но отслеживать мне это явление крайне , крайне лень.
Обойдусь указанием на тот факт, что за 5 минут тестов «на запись» - динамические диски VM выросли всего до 13 Гб и 12 Гб. Значит, нужен тест не на 5 минут внутри VM, а часа на два. И на чтение такой же, чтобы система точно не успела откешировать.
Что ж. Поставлю тесты по 7200 секунд и пусть считает хоть всю ночь.
Все равно надо подобрать параметры, потому что на 8 виртуальных ядрах даже на 4 потоках получается какой-то ужасный разброс, типа 3 потока по 80 тысяч на чтение, и один поток на 7 (семь) тысяч на чтение, падение в 10 раз. Это не disk write caching, а или
[HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\DynCache\Parameters]
или что-то отсюда же.
Начинаем тестирование по новой!
Итак, 6 vCPU Hyper-V в случае AMD, очень похоже что для Windows означают 6 потоков. Первые три потока распределяются на три физических ядра, следующие потоки начинают отправляться на исполнение на HT поток, но. Но если для физического хоста дисковые операции в diskspd идут почти без просадки, то для такого же diskspd изнутри VM это уже не так. Как итог, VM под Windows с 6 vCPU при трех дисковых потоках выполняет три потока без рассинхронизации, 4 потока идут уже с значительной просадкой одного потока, 5 и 6 потоков идут с просадкой в 10 (десять) раз.
таким образом, для VM на 10 vCPU должны исполняться до 5 потоков без существенной рассинхронизации.
Проверка.
-t2 -w0 = 161;165 = 327
-t3 -w0 = 76;75;76 = 227
-t4 -w0 = 26;26;26;26 = 107
-t5 -w0 = 32;32;32;32;1.2 = 131
При 5 потоках начался рассинхрон, причем разница не в 10, а в 30 раз, когда потоки получаются по 30 тысяч, и по 1.2 тысячи.
Значит, для 10 vCPU , максимальный имеющий смысл длительный тест – 4 потока, и 5 потоков подойдет для «мне только посмотреть».
При этом, практика на Intel серверах показывает, что для ряда задач ситуация совершенно другая.
Проводите измерения, пожалуйста, самостоятельно.
Внимание, все дальнейшие тесты выполнены с ВЫКЛЮЧЕННЫМ кешем на запись в свойствах диска хоста.
В гостевой системе Win server 2025 кеш диска на запись штатно не отключаем.
VM = 10 vCPU
Общие параметры теста -t2 -w0 -b4k -W10 -o16 -d5400 -Suw -D –L
-t2 -w0 NTFS4k = 190; 186 = 376
-t2 -w0 NTFS8k = 193;190 = 384
-t3 -w0 NTFS4k = 82;81;81 = 245
-t3 -w0 NTFS8k = 79;78;78 = 237
-t4 -w0 NTFS4k = 27;27;27;27 = 111
-t4 -w0 NTFS8k = 27;27;27;27 = 111
-t5 -w0 NTFS4k = 31;31;31;31,1 = 128
-t5 -w0 NTFS8k = 24;24;24;24,0.8 = 99
-t5 -w100 NTFS4k = 11,11,11,11,11 = 56
-t5 -w100 NTFS8k = 9,9,9,9,9 = 48
Итого, для 10 vCPU –
Для 4 потоков на чтение еще соблюдается баланс между потоками. На 5 потоках уже нет баланса на чтение.
Для 5 потоков на запись – какой-то баланс еще есть.
Побочное открытие. Поскольку файл с данными для diskspd лежит на тонком томе, и не вырос, то получается, что случайное чтение идет не с реальных данных какого-то паттерна, а с не записанных данных. То есть вопрос, а что система читает, ответ драйвера «0» в большей части случаев, поскольку фактический размер тестовых файлов 10-12 гб?
Прочие инструменты тестирования
Кроме ранее упомянутых тестов SQLsim и HammerDB
Есть статья (перевод: Рекомендации по тестам производительности для Azure NetApp Files) с рекомендованными инструментами:
Sql Storage Benchmark (SSB) и FIO.
Для FIO сделаны рекомендации
fio --name=8krandomreads --rw=randread --direct=1 --ioengine=libaio --bs=8k --numjobs=4 --iodepth=128 --size=4G --runtime=600 --group_reporting
с комментарием, цитата:
Эти сценарии охватывают как кэширование, так и обход кэширования для случайных рабочих нагрузок ввода-вывода с помощью параметров FIO (в частности, randrepeat=0 для предотвращения кэширования в хранилище и directio, чтобы предотвратить кэширование на клиенте).
При этом, что не менее интересно, изнутри VM с Windiws – diskSPD видит систему как:
cpu count: 10
core count: 5
Как при этом работает CPU scheduler в ОС гипервизора и ОС гостевой системы – я не понимаю. Возможно, надо делать 6 ядер для гостевой ОС, и в Hyper-V указывать threads per core =1 , а не оставлять по умолчанию.
Какие можно сделать промежуточные выводы?
30 секундные, 1-5 минутные тесты показывают кеширование. Реальная производительность после 1-2 часов тестирования будет отличаться. И это я еще не рассматриваю проблему домашних SSD дисков с работой в «пустом» режиме, с 50% заполнением и с 75% заполнением, вот там могут начинаться совсем другие истории по скорости работы.
Для точки отсчета можно принять следующие данные:
Для 4 потоков чтения с хоста можно иметь стабильные 50 тысяч IOPS на чтение на поток, всего 200 тысяч. /
Все данные ниже, относительно IOPS, указаны в тысячах IOPS.
Host = -t3 -w0 = 52, 52, 82, = 186
Host = -t3 -w100 = 28,28,44 = 100 (NTFS 4k)
Host = -t3 -w100 = 22,22,34 = 78 (NTFS 8k)
VM = -t3 -w0 = 76;75;76 = 227 (все цифры в тысячах IOPS).
Балансировщик IO \ CPU в Windows 11 для NVME работает не очень предсказуемо, но достаточно балансируемо. Можно покрутить minroot, но это избыточно для данного текста.
diskspd дает повторяемые результаты, что уже и неплохо.
Linux VM , 10 vCPU, 24 Gb RAM
ОС (заодно и обновил) - Debian12
Было: 6.1.0-37-amd64 #1 SMP PREEMPT_DYNAMIC Debian 6.1.140-1 (2025-05-22)
Стало: 6.1.0-38-amd64 #1 SMP PREEMPT_DYNAMIC Debian 6.1.147-1 (2025-08-02)
Разомнемся:
fio --randrepeat=1 --ioengine=libaio --direct=1 --gtod_reduce=1 --name=fiotest --filename=testfio --bs=4k --iodepth=64 --size=8G --readwrite=randrw --rwmixread=75
read: IOPS=95.3k, BW=372MiB/s (390MB/s)(6141MiB/16494msec)
Сделаю файл настроек, чтобы было чуть нагляднее.
nano fiotest_001.test с содержанием, цитата:
[global]
name=fiotest123
ioengine=libaio
direct=1
iodepth=16
bs=4k
group_reporting
runtime=300
startdelay=10
rw=randread
size=32Gb
numjobs=3
filename=delme_after.test
[test1234]
Как оказалось, group_reporting работает крайне, крайне странно.
Ещё спроси а где тут вожжи, ещё поехали скажи
echo '11=====' ; date ; echo '22====='; fio fiotest_001.test ; echo '33==========='
Пометки? Или параметр group_reporting вовсе не лишний ?? Потому что английским по белому сказано, цитата:
After the test is completed (or cancelled with Ctrl+C), the Fio will generate a detailed report showing more details. If --group_reporting attribute was used, it will show the summary for all the threads together, but if it wasn't used, the details will be shown for each thread separately and it may be confusing.
Что мешало сделать авторам вывод [total] без использования [group_reporting], не понятно. Переписывать тест я, конечно, не буду.
Но, к цифрам:
read: IOPS=126k, что меньше, чем с хоста, но больше, чем с непонятно как отработавшего теста внутри VM Windows server 2025.
Детальнее:
iops : min=26524, max=68224, avg=43534.54, stdev=8559
iops : min=22610, max=68030, avg=43995.81, stdev=8268
iops : min=26540, max=63692, avg=44087.64, stdev=7910
Данные куда понятнее, чем diskspd, видно и среднее, и максимум, и разброс. Хороший такой разброс, надо сказать.
Поправлю файл конфига, допишу:
[test1234]
numjobs=5
И получу
iops : min=18646, max=78609, avg=33717.05, stdev=6821
iops : min=13126, max=58088, avg=34077.43, stdev=6590
iops : min=14158, max=54144, avg=34087.76, stdev=6473
iops : min=15500, max=56756, avg=33983.17, stdev=6233
iops : min=14676, max=52144, avg=34009.63, stdev=6541
Допишу
[test1234]
numjobs=5
group_reporting
(Минута нытья) как же все непривычно в выводе, детализация богатая, но не читаемая. Зато время до конца теста показывается. И сумма IOPS не совпадает и никак не бьется с настройкой group_reporting и без нее.
с ней
read: IOPS=124k, BW=483MiB/s (507MB/s)(142GiB/300002msec)
iops : min=59479, max=242247, avg=123919.97, stdev=5378
Но 5 потоков по 30-35 в сумме дают 170 k IOPS, а не 124. Такое впечатление, что настройка
[global]
numjobs=3
[test1234]
numjobs=5
Проводит пять тестов (в отчете - Starting 5 processes), но считает статистику за три первых потока (Jobs: 3 (f=3) )
Не тесты, а какая-то неведомая лажа.
Я буду жаловаться в спортлото!
Для Proxmox 9 (Debian 13) внутри Hyper-V, CPU nested.
Настройки те же, 10vCPU \ 24 RAM
numjobs=3
iops : min=26250, max=86042, avg=44499.43, stdev=18314
iops : min=34930, max=62044, avg=54114.53, stdev=7103
iops : min=28046, max=71702, avg=50969.20, stdev=11388
numjobs=5
iops : min=11804, max=33632, avg=28052.91, stdev=3660
iops : min=11694, max=33590, avg=27945.52, stdev=3794
iops : min=17816, max=43656, avg=27950.35, stdev=3753
iops : min=10628, max=43976, avg=27898.52, stdev=3993
iops : min=16428, max=34810, avg=27951.97, stdev=3732
numjobs=5 плюс group_reporting
read: IOPS=81.9k, BW=320MiB/s (при конфликте [global] и [test1234])
read: IOPS=98.7k, BW=386MiB/s (при одинаковой настройке [global] и [test1234])
Один и тот же тест.
Расчет group_reporting для двух потоков
group_reporting считает что-то свое, в зависимости от настроек numjobs в [global] – 2/1 или 2/2, и того где указан group_reporting – в [global] или в [test]
iops : min= 5434, max=41258, avg=30155.54, stdev=6075
iops : min= 5442, max=40952, avg=30271.04, stdev=6121
iops : min=90444, max=184954, avg=131080.09, stdev=10288 (group_reporting )
iops : min= 8630, max=85296, avg=59160.71, stdev=7513 (group_reporting - global)
или
iops : min=24398, max=44548, avg=33152.11, stdev=3566
iops : min=25010, max=43772, avg=33056.37, stdev=3417
iops : min=49320, max=163531, avg=78313.81, stdev=11188 (group_reporting )
Заключение
Надо везде мерять fio, если будет сравнение Windows \Linux , и сразу готовить какой-то авто парсер результатов.
Тестирование короче хотя бы 15-30 минут на тест , и с размерами тестового файла меньше оперативной памяти позволяет только проверить работу скрипта. Может, покажет какие-то цифры скорости работы кеширования.
Параметр group_reporting для fio рассчитывается как-то странно.
Планировщик задач в Windows server, Debian 12 и Debian 13 работает по разному.
Debian 12 VM и Debian 13 (proxmox) CPU nested дают разброс вида
Deb12 iops : min=26524, max=68224, avg=43534.54, stdev=8559
Deb13 iops : min=26250, max=86042, avg=44499.43, stdev=18314
Даже средние показатели могут сильно расходиться.
Один плюс – сами тесты делались в основном ночью, потратил только час на сведение всего этого в одну большую, не читаемую, кучу.
Литература
Ru Рекомендации по тестам производительности для Azure NetApp Files
Ru Общие сведения о методологии тестирования производительности в Azure NetApp Files
Performance benchmarking with Fio on Nutanix
fio - Flexible I/O tester rev. 3.38
ZFS: fio random read performance not scaling with iodepth
Тестирование производительности дисков с помощью fio
Hyper-V storage: Caching layers and implications for data consistency
diskspd Command line and parameters
Работаю в IT. Сфера инфобезопасности.
Поднял сервер с зигби, все это крутится на малинке и выводит на телик всю инфу по кнопке. Голосовые команды работают. Датчики температуры, воды, протечки, входа и выхода, электронный замок, колонки и умные розетки тоже есть от Алисы. Все в одной экосистеме. Камера на входную дверь, и камера на домофон. Я всегда знаю что у меня происходит дома. Без инета это все работает так же локально, и тоже голосом. Плюс NAS сервер, и мультимедиа, с выбором скачанного на NAS. Мне фактически даже кинопоиск не нужен и другие сервисы, просто скачал фильм или сериал и сразу на телике включил. Ну и хуавеевская эко система(2 планшета, часы, наушники, 2 ноута. Короче дом умнее меня. Я пользуюсь всеми благами цивилизации, от ИИ до блин кондиционера по температуре в квартире.
Так что ТС в посте, это не айтишник, а эникейщик, который живет в другой реальности и тупо боится чихнуть на камеру. Ты может еще и вебку заклеиваешь?
Для лиги лени: общеизвестное и душное.
Часть 1. Общая
Часть 2. Gitlab и Nexus
Часть 3. Ansible и Ansible AWS
Часть 4. Наконец переходим к Proxmox
Часть 5, не запланированная. Обновляем Proxmox с 8.4 до 9.0. Неудачно.
Часть 6. Возвращаемся к запуску Ansible
Разница концепций. Часть 7.1 Обновления компонентов и система информирования.
13 августа 2025 года вышло обновление Proxmox до 9.0.5
было pve-manager/9.0.3/025864202ebb6109 (running kernel: 6.14.8-2-pve)
стало pve-manager/9.0.5/9c5600b249dbfd2f (running kernel: 6.14.8-2-pve)
Но искать «что там было обновлено», это тот еще процесс.
То есть:
Вот большая статья: вышла версия 9, Proxmox Virtual Environment 9.0 with Debian 13 released
Вот Git с фиксами.
После обновления до 9.0.5, внезапно появился
/etc/apt/sources.list.d/pve-enterprise.sources
да и ладно
У Broadcom VMware все проще – вот патч (сейчас официально только по подписке), вот компоненты в нем.
У Microsoft все еще проще – вот MicrosoftUpdate Catalog. Если выходят бесплатные обновления (для 2012 и 2012R2 – только платные, нужна подписка Extended Security Updates (ESU) for Windows Server, для 2008 нужна подписка premium assurance. Но обновления выходят, например:
2025-08 Security Monthly Quality Rollup for Windows Server 2008 R2 for x64-based Systems (KB5063947)
Поэтому можно сходить на
http://download.proxmox.com/debian/pve/dists/bookworm/pve-no...
http://download.proxmox.com/debian/pve/dists/trixie/
Скачать там файл
http://download.proxmox.com/debian/pve/dists/trixie/pve-no-s...
И увидеть, цитата
Package: pve-manager
Maintainer: Proxmox Support Team support@proxmox.com
Installed-Size: 3573
Provides: vlan, vzdump
Depends: apt (>= 1.5~), ..
Recommends: proxmox-firewall, proxmox-offline-mirror-helper, pve-nvidia-vgpu-helper
Conflicts: vlan, vzdump
Breaks: libpve-network-perl (<< 0.5-1)
Replaces: vlan, vzdump
Filename: dists/trixie/pve-no-subscription/binary-amd64/pve-manager_9.0.5_all.deb
Size: 580388
Окей, а как-то поудобнее можно?
Конечно после обновления можно увидеть:
cat /var/log/apt/history.log
Но это после обновления.
Очень, очень не хватает решения типа Windows Server Update Services (WSUS), но для Linux и Proxmox. Foreman+Katello говорят «ок». RedHat Satellite ? SpaceWalk:Satellite ?
Разница концепций. Часть 7.2 Сети
В ESXi «из коробки» все просто. Есть стандартный свитч, vSphere Standard Switch, vSS. Он мало чего умеет «из коробки», но самое главное, что вы можете завести несколько коммутаторов, и распределять физические порты сетевых карт, и порты виртуальных сервисов – самого менеджмента, сервисов, итд, как вам нравится.
Вместе с некоторыми (их опять поменяли) лицензиями вы получали vSphere Distributed Switch (VDS), с дополнительными функциями.
Если хотите добавить в жизнь интима - Single Root I/O virtualization (SR-IOV).
Хотите чего-то большего – покупайте VMware NSX.
У Microsoft в чем-то схожий подход. Есть Hyper-V switch с массой настроек исключительно из powershell.
Хотите большего – добро пожаловать в увлекательный мир Network Controller Server Role.
Хотите того же самого, но иначе – вот вам Set up networking for Hyper-V hosts and clusters in the VMM fabric, вот вам Set up logical networks in the VMM fabric, и вперед.
У Proxmox все немного не так. То есть, так то так, архитектура та же, x86, но.
За уровень «стандартного коммутатора» отвечает стандартный функционал Linux. Проблема в том, что он (как, впрочем, и в Broadcom, и в Microsoft) читаемо и полноценно настраивается только из командной строки. Режима Switch Embedded Teaming (SET) в нем нет, есть active-active bond, но.
Red Hat пыталась сделать что-то такое же, и даже статья есть - 8.3. Comparison of Network Teaming to Bonding, но это Red Hat.
Чтобы в этом разбираться, все равно необходим базовый уровень знания сети, в масштабе CCNA: Switching, Routing, and Wireless Essentials, он же CCNA Routing & Switching ICND1 100-105 Course. Иначе вопросов будет больше, чем ответов. У Broadcom есть best practice – собирайте actve-active, LACP не нужен. Если вы упрт нркмн, то вот вам beacon probe и shotgun mode, можете упртс. Если хотите совсем упртс, то вот вам air-gap storage fabric, только лучше бы вы так не делали.
У Microsoft есть best practice – просто ставьте SET, он сам разберется.
У proxmox, их-за наличия Bridge, который по сути L2 switch, и iptables, появляется L3 конфигурация с NAT, но планирование сети заставляет каждый раз думать «как лучше-то».
Кроме того, в конфигурации сети отдельно английским по белому написано:
For the cluster network (Corosync) we recommend configuring it with multiple networks. Corosync does not need a bond for network redundancy as it can switch between networks by itself, if one becomes unusable. Some bond modes are known to be problematic for Corosync, see Corosync over Bonds.
Особенно мне понравилась строчка:
We recommend at least one dedicated physical NIC for the primary Corosync link
То есть, поскольку сетевые карты нынче идут, чаще всего, с двумя портами, то надо брать 2 карты по 2 порта, всего 4 порта, и один порт выделять под Corosync. Но если у меня конфигурация нормального человека, 2 порта по 25, это мне что, под кластер надо выделять целых 25G? А не жирновато?
При этом сценарии отказа описаны понятно и обоснованно, но как-то заставляют задуматься. Это же придется ставить на мониторинг не только состояние порта on\off\ CRC, но и, для оптики, уровень сигнала по SFP модулям с обеих сторон, RX power \ TX power.
Середины (типа vSphere Distributed Switch (VDS)) нет.
Зато есть SDN
От теории к практике.
Поскольку для этой серии статей у меня Proxmox развернут как вложенная (nested) виртуализация, то мне придется или переделать всю сеть, или пересобирать рабочие стенды, или ограничиться двумя виртуальными сетевыми картами.
К моему величайшему отвращению, Hyper-V Windows 11 'Default Switch' зачем-то снабжен никак нормально не настраиваемым DHCP сервером. В Server 2012\2016\2019\2022\2025 такого нет, если нет DHCP в сети, значит нет сети.
Конфигурация хоста Hyper-V:
Get-VMSwitch 'Default Switch' | fl – от этого виртуального свича все отключено.
Вот он мне и вредил, поскольку в нем и NAT и DHCP , и ничего в нем не настраивается, согласно Change Hyper-V (Default Switch) IP address range.
The Hyper-V Default Switch will randomly use one these IP address ranges based on the host system IP address:
Start IP: 192.168.0.0 – End IP: 192.168.255.255
Start IP: 172.17.0.0 – End IP: 172.31.255.255
Поэтому я новый виртуальный свитч и сделал, режим external. И все у него хорошо.
Конфигурация proxmox по умолчанию
auto lo
iface lo inet loopback
iface eth0 inet manual
auto vmbr0
iface vmbr0 inet static
address 192.168.10.202/24
gateway 192.168.10.1
bridge-ports eth0
bridge-stp off
bridge-fd 0
Конфигурация с двумя виртуальными сетевыми картами у меня будет выглядеть так:
auto lo
iface lo inet loopback
iface eno1 inet manual
iface eno2 inet manualauto bond0
iface bond0 inet manual
bond-slaves eno1 eno2
bond-miimon 100
bond-mode active-backup
bond-xmit-hash-policy layer2+3
auto vmbr0iface vmbr0 inet static
address 192.168.10.202/24
gateway 192.168.10.1
bridge-ports bond0
bridge-stp off
bridge-fd 0
Конфигурация с VLAN для рабочих сред описана в разделе Example: Use VLAN 5 for the Proxmox VE management IP with VLAN aware Linux bridge, конфигурация The next example is the same setup but a bond is used to make this network fail-safe.
Разница концепций. Часть 7.3 предисловие к теме «Дисковое пространство».
Чтобы понимать незначительные сложности, нужно немного отойти назад, в состояние «дисковых пространств» 15-20 лет назад, и огромный скачок для всего человечества за последние пять лет.
15 назад, в 2010 году, концепция дисковых пространств была достаточно проста.
Есть одиночные локальные диски, которые могут быть включены по IDE (уже крайне редко на тот момент), SATA, SCSI и SAS. Но интерфейс особого значения не имеет (то есть, еще как имеет, но это другая история), потому что глобально выбора конфигурации особо и нет.
Для домашней и офисной техники: 1 диск, без всяких массивов.
Для дисков с операционной системой: аппаратный RAID 1 (зеркало) из 2 дисков. Не надо забывать, что диски тогда были маленькими, как 72GB 2.5-inc SFF 3G Single Port SAS 10K, 146GB SCSI U320 или 146GB hot-plug Serial Attached SCSI (SAS).
Для дисков с данными для «быстрого» доступа: аппаратный RAID 10.
Для дисков с данными для «медленного» доступа: аппаратный RAID 5, если у вас диски меньше 1 терабайта, аппаратный RAID 6, если у вас диски больше 1 терабайта.
Потому что, запишите это уже большими буквами: RAID 5 на дисках бытового и начально-корпоративного сегмента, при размере одиночного диска больше 1 Тб, достаточно часто умирает при стандартном ребилде. Вероятности считайте сами.
Плюс локально включенные коробки с дисками.
И, для дисковых массивов, у вас есть FC 4g (c 2004), FC 8g (с 2008), и с 2007 года есть 10G Ethernet для iSCSI. 25G Ethernet появится только в 2018 году.
NFS поверх 1\10G, конечно, тоже уже есть. Apple File Service (AFS) еще не умер.
Современные технологии быстрого перестроения массивов уже почти есть в HPE Eva.
Еще есть InfiniBand, но дорого.
Основная проблема – ребилд. Это долго, это дорого с точки зрения потери производительности, но это зачастую проще, чем переставлять ОС или поднимать данные из архивов. Поэтому везде RAID 1\10 и еще раз RAID. Альтернативы были, но все равно, RAID это было просто, понятно, наглядно, и не требует вмешательства администратора, особенно если есть запасной диск.
Сейчас все поменялось.
Окончательно ушли в историю диски на 15.000 и 10.000 оборотов, и та же судьба уже видна для дисков 7200 для массивов, и для дисков 5400 для ноутбуков. SSD с двумя оставшимися вариантами подключения, SAS и NVME, побеждают почти везде.
Появились технологии для гиперскейлеров, и не только – S2D, vSAN (StarWind дано был). И то, и другое, уже не redundant array of inexpensive disks, а Redundant Array of Independent Nodes (RAIN) .
Сети стали быстрее, диски быстрее, объемнее, и возникает другой вопрос – старые RAID контроллеры перестали справляться с производительностью новых дисков. Новые RAID контроллеры тоже не блещут при работе с NVME, но это уже другая история:
NVME Raid – We Need To Go Deeper, или что там на глубине. GPU over NVME, с водяным охлаждением
Проблема даже не в этом, а в том, что нет смысла держать разные диски на передней панели «под ОС и «под данные», с точки зрения работы, закупок, и в целом. Удобнее использовать один тип дисков, и никто не перепутает. В таком случае проще поставить или PCIe карту на 2 m.2 планки, или взять internal M.2 boot module или что-то типа Dell BOSS, собрать недоаппаратный или программный рейд на такой карте, и отдать остальные одинаковые диски, установленные в передние слоты, под данные, собрав тот или иной вид программного рейда.
НО.
Дальше начинаются «проблемы legacy 2.0».
В корпоративном варианте заказчику, за очень дорого, продадут и S2D и vSAN, со всеми их свистелками, типа быстрого перестроения при сбое, RAID 5+6, поддержке RDMA. Продадут со свичами Arista или Mellanox с их скоростями и cut-through (вместо Store-and-Forward), и lossless Ethernet, и так далее. Это все есть, это все работает, как и последние навороты в MPIO для IP в NVIDIA ConnectX-8 .
Это все есть, но это: 1) дорого 2) требует настройки 3)требует переписать драйвера 4)требует настроить сеть и следить за ней.
В то же время, существуют, как продукты, Ceph и drbd, то есть Linstor. И не только.
Они работают, но. Но настройка, скорость работы (задержки, и как следствие IOPS), проблемы связности, проблемы на ребилде, пожирание памяти как не в себя, и так далее.
В домашней лаборатории, где все работает, а отказ или split brain или остановка сервисов не важны – CEPH работает.
В масштабах VK – тоже работает, вопрос какой ценой.
Ceph вырос как проект 2007 года, времен медленных дисков небольшого объема, отсутствия на рынке «дешевого» варианта собрать хранилище на петабайт и больше, и даже работал, но в 2020 - 2021 году начал уходить с рынка. SUSE отказалась от развития, еще кто-то отказывался. FUJITSU Storage ETERNUS CD10000 S2 - The sale of this product was terminated in December 2019.
Причины понятны, сейчас петабайт хранения требует не двух стоек, а двух юнитов в одной стойке, а рынок опять меняется.
Поэтому Ceph для дома – пожалуйста, Ceph для VK облака или каких-то еще облаков – сколько угодно. Ceph для SMB или чуть выше – не знаю, зачем настолько жертвовать производительностью и иметь бонусом головную боль при обновлениях. И еще один не очевидный многим нюанс ниже.
Но люди верят, что он работает (это почти правда, если не рассматривать ребилд), быстрый (нет), надежный (очень не всегда). Вопрос цены. Люди верят, что можно обмануть систему, взять бесплатное решение, дешевых людей, дешевое железо и получить производительность и надежность «как в облаке, но дешевле».
Кроме того, есть вопросы и к бекапу, и к восстановлению, и много к чему еще.
Но люди верят. Мерять производительность не хотят, тесты ребилда под нагрузкой делать не хотят, некоторые и бекапы не делают.
Сложность и нюансы в понимании (и отсутствии понимания) «зачем все это».
Для одного сервера все равно нужен какой-то RAID, в современных условиях, для одного сервера, с таким бизнесом, которому достаточно одного сервера, может быть аппаратный контроллер и будет неплохим решением. Для двух серверов уже может быть проще собрать отказоустойчивый кластер не на уровне железа и репликации средствами ОС, а через репликацию сервиса. Базы данных это умеют, для репликации файловых кластеров с низкой нагрузкой подойдет что угодно, остальные сервисы типа etcd тоже реплицируются без кластерной файловой системы.
Разница концепций. Часть 7.4 «Локальное дисковое пространство».
Для Hyper-V все проще некуда. Собрал диски – хочешь в soft raid, хочешь в storage space (не путать с S2D), хочешь на аппаратном рейде. Отформатировал, создал тонкие или толстые виртуальные тома ОС, создал на них тонкие (динамические) или толстые файлы (vhdx), отдал файлы виртуальным машинам, и все.
Есть проблемы с производительностью storage space в parity, если вдруг не читали вот это.
Новый ноутбук: скорость, плюсы-минусы, DiskSPD, Hyper-V и продолжение про методику тестирование скорости
Устроено все проще некуда, диск виртуальной машины == файл с заголовком.
Для Broadcom ESXi все еще проще. Создал «на чем есть» storage, создал виртуальные машины с нужными дисками.
Устроено все проще некуда, диск виртуальной машины == 2 файла. Файл с текстовым описанием, и файл с RAW данными.
Для Proxmox начинается проблема выбора: что взять. Есть Ext4, есть ZFS, есть BTRFS. Есть XFS.
Был GlusterFS, но он все, цитата
As GlusterFS is no longer maintained upstream, Proxmox VE 9 drops support for GlusterFS storages. Setups using GlusterFS storage either need to move all GlusterFS to a different storage, or manually mount the GlusterFS instance and use it as a Directory storage. Roadmap
ПОМЕР.
Development has effectively ended. For years Red Hat drove development for its RHGS product, but with the EOL of RHGS at the end of 2024. Date: 2024-06-25
Само разбиение дисков сделано странно.
ISO images в GUI это /var/lib/vz/template/iso
CT templates в GUI это /var/lib/vz/template/cache
Конфигурация контейнеров /etc/pve/lxc
Конфигурация виртуальных машин /etc/pve/qemu-server
Диски виртуальных машин – о, тут все странно. В конфиге диск прописан как
scsi0: local-lvm:vm-100-disk-0,iothread=1,size=5G
но это блочный lvs том, который виден по команде lvs , или
find /dev | grep vm
И получаем /dev/pve/vm-100-disk-0
или команда
lvdisplay
покажет что где и как.
Неприятно с точки зрения операций с локальными томами. С ZFS та же история.
Разница концепций. Часть 7.5 «Локальное дисковое пространство - добавление».
Окей, создам отдельный том
New-VHD -Path C:\test\Proxmox\ data.vhdx -LogicalSectorSize 4KB -PhysicalSectorSizeByte 4KB -SizeBytes 105GB -Dynamic
добавлю его через GUI к Proxmox, но это уже будет другая история
Литература
Single Root I/O virtualization (SR-IOV)
Set up networking for Hyper-V hosts and clusters in the VMM fabric
Set up logical networks in the VMM fabric
How to configure System Center VMM Part 1 – Basic Design
8.3. Comparison of Network Teaming to Bonding
3.18. Bridge and Bond Configuration
Proxmox Network Configuration
How to enable DHCP on Hyper-V switch
Hyper-V - Default Switch & DHCP Server
Configuring VM Networking on a Hyper-V NAT Switch
A Practical Guide to Hyper-V Virtual Switch Configuration
Change Hyper-V (Default Switch) IP address range
Proxmox Ebook Free Download for Home Labs – тут почему-то удалили pdf, но он есть тут, хотя он и для 7.1
Proxmox for Everyone: Your Complete Guide to Virtualization, Kubernetes, and Homelab Automation (Next-Gen Infrastructure Strategies Book 2) Kindle Edition by da li (Author), PlanB Mr (Author)
Искал срочную замену Цапу и открыл Jami , вкрадце это децентрализованный мессенджер с поддержкой аудио и видеозвонков, чатов и обмена файлами.Основная фишка — P2P-соединение: сообщения и звонки идут напрямую между устройствами, без центрального сервера.Используется сквозное шифрование (E2EE), так что прослушать или прочитать ваши данные без ключей нельзя, есть версии для Windows, macOS, Linux, Android iOS. Исходный код открыт, разработка идет уже много лет и активно поддерживается сообществом. Протестировано в групповом звонке с устройствами андроид , айфон и винде и оно работает!!!


