Всем отличного начала нового года! Вчера утром в своём Телеграм-канале опубликовал интересную задачу по SQL с собеседования про IN и NOT IN.
С первого взгляда кажущееся правильным решение на самом деле ложно. Чтобы верно ответить в задаче, нужно знать как СУБД обрабатывает элементы множества, указанные для оператора IN / NOT IN в запросе.
Вначале вот текст самой задачи. Ниже я поясню правильное решение:
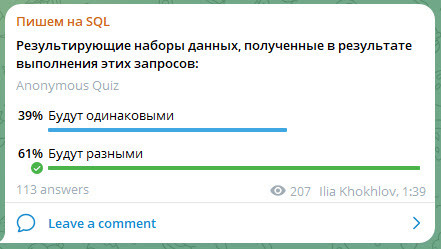
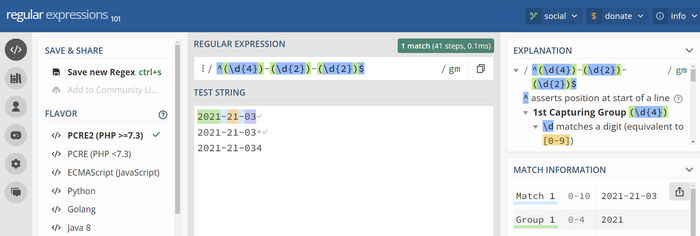
В таблице CLIENTS пять строк. В первых двух строках в поле CLIENT_TYPE значение 1, ещё в двух строках в CLIENT_TYPE значение 2 и в последней строке поле CLIENT_TYPE не заполнено, то есть в последней строке в поле CLIENT_TYPE значение NULL.
Есть два запроса: 1) SELECT * FROM CLIENTS WHERE CLIENT_TYPE IN (1) 2) SELECT * FROM CLIENTS WHERE CLIENT_TYPE NOT IN (2, NULL) Результирующие наборы данных, полученные в результате выполнения этих запросов, будут одинаковыми или разными?
Здесь поставь чтение на паузу и ответь на вопрос самостоятельно.
Первый запрос отбирает клиентов, у которых в столбце тип указано значение 1. В результате будут отобраны две строки. Здесь все понятно. Так как в таблице клиентов ещё остаются строки, не попавшие в выбор первого запроса, со значениями в столбце тип 2 и NULL, то видится, что второй запрос должен как раз вернуть такой же результирующий набор данных. Однако, тут дело в коварном NULL в значениях для оператора NOT IN. СУБД представляет оператор NOT IN:
SELECT * FROM CLIENTS WHERE CLIENT_TYPE NOT IN (2, NULL)
в результате должны быть отобраны клиенты, у которых значение в столбце тип не равно каждому из перечисленных во множестве значений:
SELECT * FROM CLIENTS WHERE ((CLIENT_TYPE <> 2) AND (CLIENT_TYPE <> NULL))
С NULL не допустимо использовать операторы сравнения. При сравнении с NULL (= NULL, <> NULL) результат будет всегда отрицательным.
В предыщущей статье мы ознакомились с базовыми элементами. в этой части мы рассмотрим более сложные примеры. И затем, применим эти знания для реальных задач.
Квантифаеры (Quantifier) + * ?
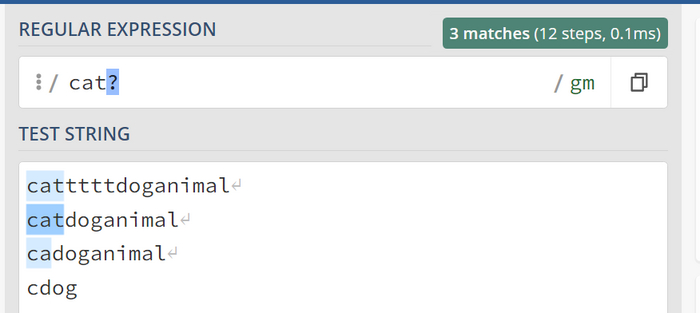
Предположим, в нашем выражении один из символов может быть опциональным или повторяться несколько раз. Например, мы ищем слово cat, которое может начинаться с "ca", но последующий символ "t" может быть опциональным или повторяющимся. Здесь у нас есть несколько вариантов в зависимости от наших требований:
Символ вопроса ? или {0,1}
Симол tможет отсутсвовать или присутствовать в рамках символа { } это { 0 , 1 }.
Как видно первые три варианта совпали но мы не задели больше одного символа t. Мы бы достигли такого же результата через cat{0,1}
DOS атаки вошли в чат. Catastrophic Backtracking (Катастрофический возврат)
Далее переходим к выражениям, неоптимальность которых может стать уязвимостью для атак типа DOS (Denial of Service - отказ в обслуживании) а точнее RegexDOS или ReDOS. Неоптимальные и сложные регулярные выражения могут потребовать экспоненциальной сложности для их обработки. Злоумышленник, зная об этом, может заспамить нас строками, которые быстро истощат наши процессорные ресурсы. Более подробную информацию по этой теме можно найти здесь. В качестве примера рассмотрим следующий запрос:
Regex101 достаточно умен чтобы даже не пытаться его запустить, он аналитически предотвратил запуска поиска.
Не стоит паниковать, так как регулярные выражения позволяют нам написать защищенные от атак типа DOS выражения.
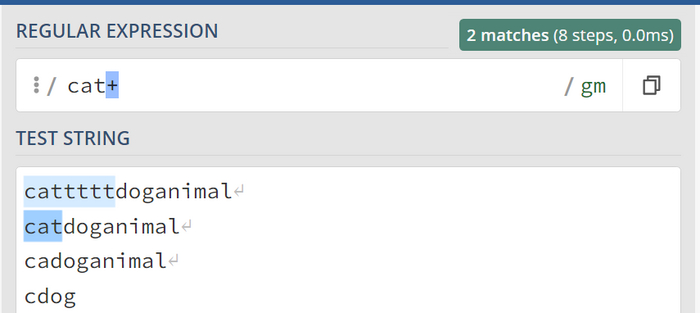
Символ плюса + или {1, } (от 1 до бесконечности)
Предположим, что символ "t"должен присутствовать, и при этом мы допускаем его повторение. Это эквивалентно записи {1,} (от 1 до бесконечности). Для этого используем символ "+":
t элемент должен обязательно присутствовать.
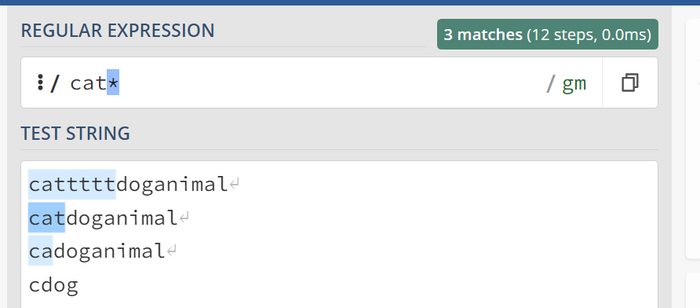
Символ звездочки * или {0, } (те от 0 до бесконечности)
В последнем варианте предположим, что символ "t" может быть не включен, и при этом может иметь бесконечное количество повторений. То есть это эквивалентно записи {0,} или от 0 до бесконечности:
Сравним каждый из квантифаеров
Пересмотрим еще раз каждый из них и эквивалентное к ним { }:
? эквивалентна { 0 , 1 }
* эквивалентна { 0, }
+ эквивалентна { 1, }
Cимволы \w \d \s и их отрицания \W \D \S
Некоторые из этих символов я уже упомянул в первой статье, но давайте повторим и добавим немного новых:
\w - любый алфавитный символ (a-z,A-Z) и цифры 0-9 и подчеркивание _
\d - цифры 0-9
\s - символ пробелов такие как - пробелы, табы, переносы строк итд
В regex есть удобная функциональность инверсии выражений. Например если вместо \d мы напишем \D то выражение будет искать все символы исключая цифры.
Также для инверсии любого общего выражения можно достичь символом ^ но указав его внутри скобок. Например любой символ кроме a-b: [^a-b]
Группировка.
Группировка - важная функциональность регулярных выражений, которая позволяет:
Составлять более сложные запросы.
Извлекать данные из выражений.
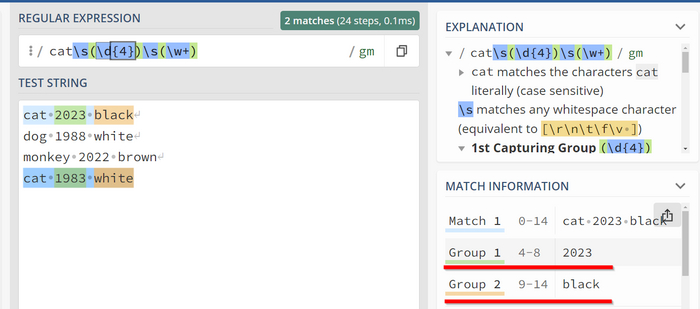
Чтобы выделить выражение в группу, нужно обернуть его в скобки ( ). Рассмотрим ситуацию, где у нас есть записи о животных в формате "название животного дата рождения цвет" (разделенных пробелом). Давайте напишем выражение для извлечения только кошек (любого года рождения и цвета), выделив цвет и год рождения в группу:
И так мы получили 2 результата и как вы можете видеть справа мы получили две группы Group 1 и Group 2.
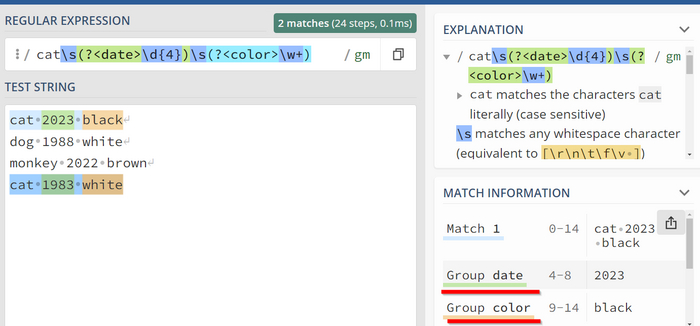
Group 1 и Group 2 совпадают с нашими ожиданиями, но могут быть неудобными для чтения. Давайте воспользуемся еще одной возможностью и дадим им ярлыки. Для этого, внутри круглых скобок, нужно в самом начале добавить "?<label>", где "label" - это название группы. Например:
Справа снизу видно что наши группы теперь имеют человеческий вид - date, color.
Применение регулярных выражений для промышленной задачи.
Итак, у нас перед нами задача: мы получили записи из ветклиники и хотим отфильтровать только валидные записи, а затем извлечь их для последующей аналитики.
Анализ входных данных
Теперь, когда у нас есть данные, нам нужно решить:
Какие данные считаются корректными?
Какие "отклонения" мы можем допустить?
Обычно ответы на эти вопросы предоставляются аналитиком, но в данном случае мы выполним все шаги самостоятельно. Итак, рассмотрим данные:
не стоит обращать внимание на хомяков весом почти в 1кг)
Из данных можно сделать вывод:
Первые цифры определяют год, просто 4 фиксированные цифры.
Данные разделены ";" (точкой с запятой) с потенциальными смежными пробелами.
Последняя колонка с весом - это число с плавающей точкой.
Напишем выражение для каждой из групп
дата (?<date>\d{4}) - ровно 4 цифры
имя (?<name>[a-zA-Z]+) слово длины от 1 до бесконечности состоящие из букв алфавита
животное (?<animal>(dog|cat|snake)) - лишь 3 вида допустимых животных собака, кошка, змея написанные строчными буквами
вес (?<weight>\d+\.\d+) - два числа длины минимум 1 и до бесконечности, разделенные точкой
между разделителями есть пробелы \s* (от нуля до бесконечности)
Итак, полученное выражение:
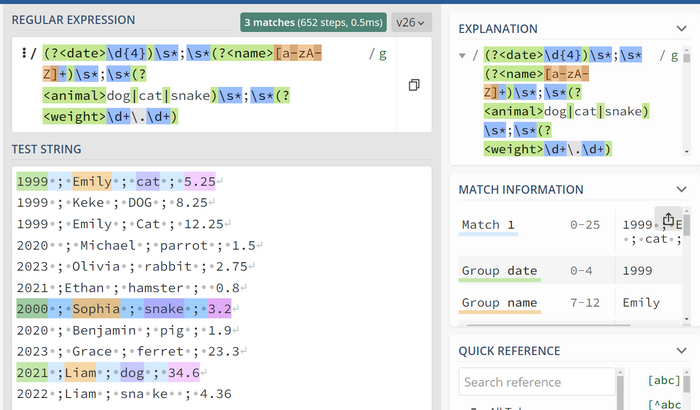
Предположим, что по требованиям нам нужно анализировать только собак, кошек и змей. Тогда наше конечное выражение будет выглядеть вот так:
Это регулярное выражение соответствует вашим требованиям для анализа записей о собаках, кошках и змеях. Оно разделяет данные на четыре группы: год, имя, вид животного и вес. Теперь проверим это выражение на наших данных:
можно заметить что группы совпадают с ожидаемыми значениями
Как мы могли бы улучшить запрос?
Наш первый вариант был слишком "жестким", и мы не предполагали, что животное может иметь заглавную букву. Давайте это поправим:
Добавить ?i что даст нам (?i:(?<animal>dog|cat|snake)) чтобы не учитывать регистр животного
Защита от DOS атак.
Чтобы предотвратить возможность перегрузки системы, уберем использование *, + и укажем максимальный допустимый размер, используя {}.
Новое выражение теперь учитывает и DOG и Cat благодаря ?i:. Все предыдущие записи были также включены, хотя все *, + были исключены из выражений.
Воспользуемые полученным выражением в Java.
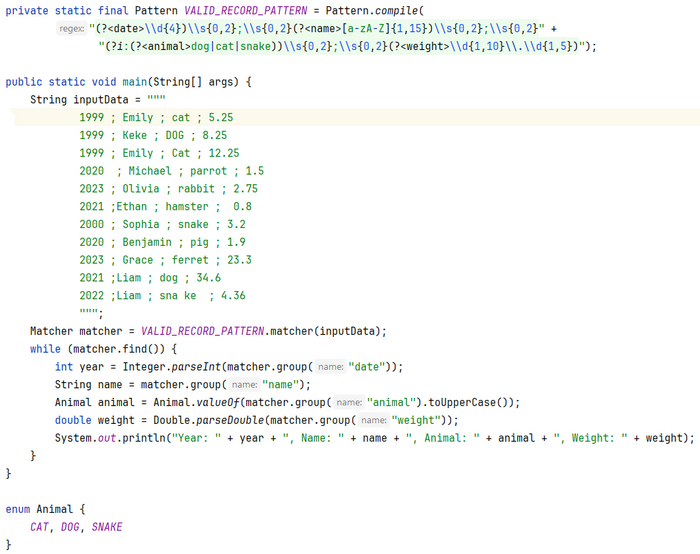
Цель - отфильтровать все валидные записи и привести к типам Javav. Я не планировал сильно погружаться в детали реализации Regex классов в Java, поэтому ниже просто покажу рабочее решение:
Код далек от идеала но достаточно прост для понимания.
Pattern, Matcher - классы для работы с Regex в Java.
В коде мы создаем объект класса Pattern и затем создаем Matcher на его основе. Класс Matcher позволяет обойти всe валидныe записи которые формирует наш Regex запрос используя метод matcher.find(). И затем вытаскиваем значения групп используя метод group("имя группы"). Результатом работы будет
И последнее. Полученные результаты совпадают с regex101.com, но нужно помнить, что у Java есть свои аспекты поддержки Regex, которые в редких случаях потребуют небольших изменений в регулярном выражении.
На этом рассказ про regex заканчивается, вот материалы. Материалы на которые стоит обратить внимание:
Птичка, цветочек, прямые линии. Почти неотличимо от обычного регекса)
Регулярные выражения, можно сказать, представляют собой своего рода язык запросов, благодаря которому можно выполнять следующие ключевые задачи:
Валидировать строки
Искать нужные подстроки в строках
Извлекать необходимые данные
Regex не ограничивается только языком Java.
Этот язык используется повсеместно в области информационных технологий. Зная его, вы можете применять свои навыки в множестве контекстов. Поддержка регулярных выражений присутствует в большинстве языков программирования, и множество программ полагаются на регулярные запросы. В какой-то мере regex является стандартом, который полезно знать каждому.
Regex часто кажется сложным для понимания, особенно новичкам.
К сожалению, регулярные выражения, особенно если они написаны неоптимально, могут требовать много усилий для разбора конкретного выражения.
Существует множество решений для упрощения написания и тестирования регулярных выражений.
К счастью, существуют готовые онлайн-решения, которые существенно облегчают процесс понимания. Например, regex101.com - сервис, который мы будем использовать далее. Вот пример того, как мы валидируем формат даты:
Можете пока не вдаваться в подробности. Ниже я объясню как им пользоваться.
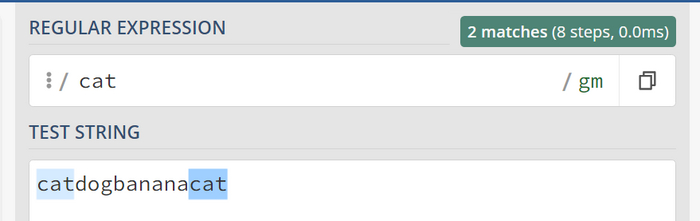
Самые основы. Ищем котов.
Давайте начнем с самых основ. Допустим, у нас есть задача: мы хотим найти все упоминания слова 'cat' в строке 'catdogbananacat'. Выражение для этой задачи будет очень простым: 'cat'. Именно так, просто слово.
Теперь давайте посмотрим, что мы найдем, используя утилиту regex101.com:
Мы нашли двух котов. (Заметьте первый кот подсвечен голубым, второй синим - тк найдено 2 упоминания или подстроки в строке).
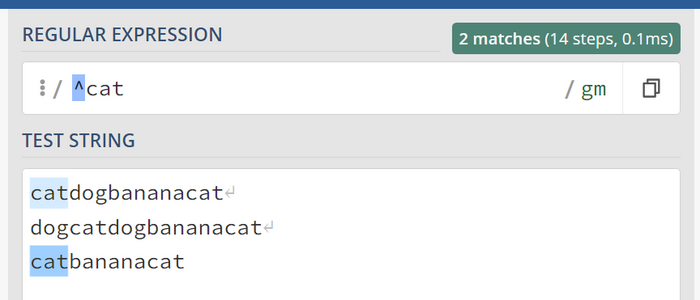
Символ начала строки ^
Теперь найдем только котов которые стоят в самом начале строки а не в середине или конце, для этого воспользуемся симоволом ^ (циркумфлекс символ или символ "домика" или "крышечки" или caret на английском).
Среди 3х вариантов было найдено два кота которые начинают строку.
И так среди вариантов мы нашли 2 котов которые начинают строку.
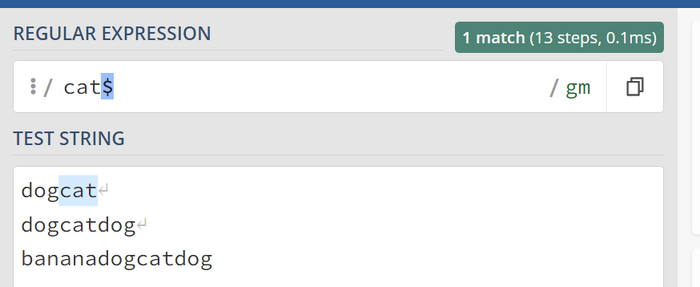
Символ конца строки $
Также, аналогично предыдущему, давайте найдем только те варианты, где 'cat' будет заканчивать строку. Для этого воспользуемся символом $. Итак, наше выражение будет cat$.
Найден лишь один который который заканчивает строку.
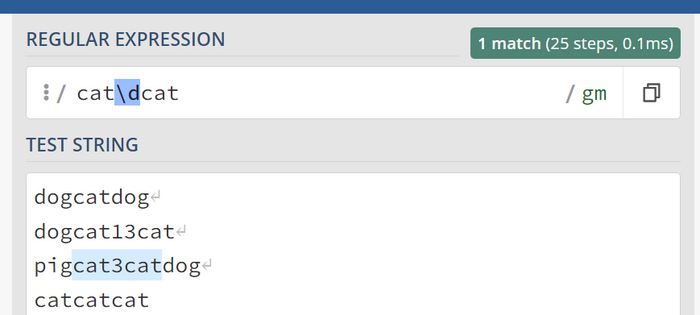
Усложняем задачу, находим двух котов между которыми есть цифра. Символ числа \d
Теперь усложним задачу и найдем двух котов, между которыми есть цифра. Для этого мы используем \d (от слова 'digit' - цифра). Итак, искомое выражение будет 'cat\dcat'.
Как мы видим лишь один случай найден. Именно один варинт ровно 1 числа между двумя котами.
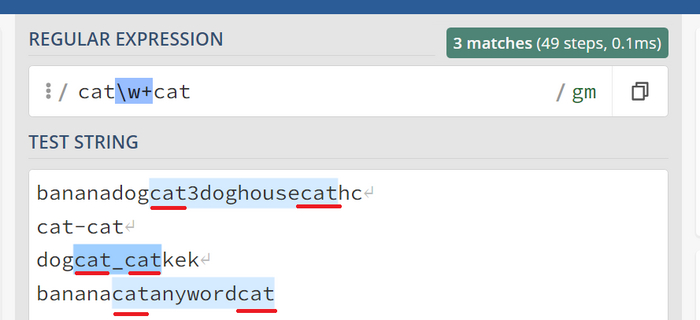
Знакомимся с \w и последовательностью +
Теперь предположим, что мы ищем двух котов, между которыми может быть несколько цифр, букв или подчеркиваний. Для этого воспользуемся \w, а затем добавим символ +, подсказыва регексу, что символов может быть больше одного. Конечное выражение: cat\w+cat
красным подчеркнуто, чтобы для удобства просмотра)
Перечисляем допустимые символы. Символ [ ]
Теперь сузим поиск и предположим, что мы ищем пару двух котов, между которыми есть лишь буквы a, b, c (либо их вариации). Для перечисления используем квадратные скобки: [abc], и добавим +, чтобы указать, что букв может быть несколько.
первые три вариана не подходя потому что: в первом есть цифра, во втором дефис, в третьем подчеркивание.
Указываем минимальную и максимальную длину. Символ { }
Теперь сузим поиск еще сильнее, предположим что в сумме букв a,b,c между котами может быть не менее 1 и не более 5 символов. Для этого воспользуемся фигурными скобками и получим выражение cat[abc]{1,5}cat
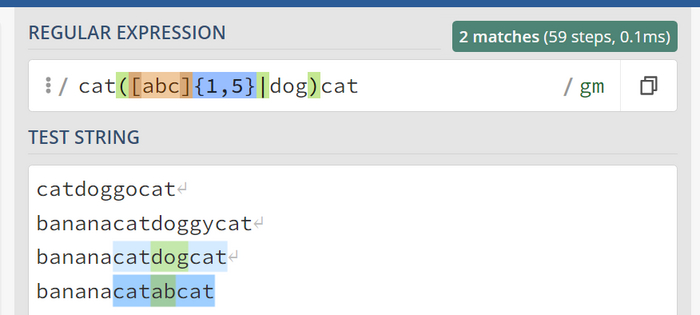
Добавляем вариации. Логическое ИЛИ. Символ |
Теперь допустим мы ищем всех котов между которыми может быть:
Уже знакомый вариант с a,b,c которых не более 5 и не менее 1
Либо слово dog
Для этого воспользуемся логическим выражением или используя | символ. Также чтобы указать что между двумя котами может быть лишь 1 вариант нам нужно использовать круглые скобки чтобы объединить их. Круглые скобки играют еще и другие роли (об этом будет позже). Итого наше выражение cat([abc]{1,5}|dog)cat
К старым результатам добавился catdogcat что и было ожидаемо.
Резюмируя первую часть статьи.
И так мы хорошо поработали, теперь мы научились работать с такими иероглифами как:
^ начало строки, $ конец строки
+ несколько последовательных символов (неограниченное количество)
\d любое число 0-9
\w любой алфавитный, цифровой символ и подчеркивание
[ ] - перечисление допустимх символов
{ } - указание минимальной, максимальной длины повторений
| - логическое ИЛИ которое для большинства случаев требует наличие скобок ( )
Что дальше?
Итак, мы познакомились с довольно простыми вещами, которые не слишком иллюстрируют всю мощь регулярных выражений. В следующих частях мы узнаем еще больше магических символов и применим их для первых промышленных задач.
Книга полна реальных прикладных примеров на популярных языках программирования (Python, jаvascript и Ruby), которые помогут освоить структуры данных и алгоритмы и начать применять их в повседневной работе.
2023 год был достаточно насыщенным, и наверно стоит немного оглянуться назад и подвести итоги: что удалось сделать, а над чем ещё нужно поработать. Ведь иначе может показаться, что за год ничего не было сделано.
❌ Конечно, планов было гораздо больше и не всё удалось сделать.
- Не успел подготовиться к собеседованию в Яндекс. Поэтому не пошёл на второе этап. - Не успел довести до ума утилиту для анализа Code Review - Не нашёл времени на английский - Осталось множество незаконченных проектов
Надеюсь следующий год будет по крайней мере не хуже.
Поздравляем с наступающим Новым годом! Желаем всем интересного контента, смешных жизненных мемов, счастья-любви-здоровья и, конечно же, любимых вкусняшек по акции в соседнем супермаркете!
Что готовит нам 2024? Как вы думаете? 👇 Пишите в комментариях свои прогнозы, ожидания, страхи и "раздувы" 😁
✅ Немного полезности в тему - как справляться с дедлайнами в срок, больше успевать и больше зарабатывать в IT, digital и других сферах. Мы собрали опытных специалистов из разных маркетинговых и околомаркетинговых направлений (SEO, SMM, performance, таргетинг, копирайтинг, контент, менеджмент) и выяснили: сколько, как и на чем они зарабатывают. С чего начинали, как прокачивались и к чему стремились на пике. Какие приемы, методы, инструменты и лайфхаки используют в своей работе, чтобы больше успевать и больше зарабатывать. Как справляются с многозадачностью, усталостью, выгоранием и многое-многое другое.
✅ А вот еще для тех, кто пропустил наш огненный материал, который попал в "горячее" на Пикабу - маркетинговый разбор самого хайпового явления и кино 2023 года. Вся правда о "Слове пацана" с комментариями сммщиков, медийщиков, бизнесменов, Михалкова, Месси и вердиктом профессионального психолога. Кто заплатил 1200 рублей Wink и кое-как вернул деньги? И при чем тут Гарри Поттер?
✅ + бонус - ТОП-10 захейченных реклам в рунете в 2023 году от Ozon’а до Тинькофф.Самые яркие промокампании и самая хайповая рекламная дичь - на что русскоязычные пользователи реагировали активнее всего. Что бесило, пугало, оскорбляло, обманывало, задевало чувства, борщило и это вот все.
Хотите в числе первых узнавать о новостях и трендах из мира digital-маркетинга? А также получать советы и лайфхаки от реальных профессионалов — маркетологов крупных компаний и практикующих топ-экспертов?
Подписывайтесь на наши каналы в VK (@marketing.education) и Telegram (@maed_online_marketeer) и получайте в свою ленту новостей самую актуальную, проверенную, интересную и полезную информацию о digital-продвижении. Наши инструкции, чек-листы, исследования, уроки, кейсы, подборки, инфографики, эксклюзивные материалы и конечно же МЕМЫ — помогут вам прокачаться, найти новые идеи, расширить профессиональный кругозор и быть в теме.