Всём доброго времени суток! Это мой первый пост ( о помощи) Работаю монтажником оконный конструкций. Зп хорошая, не жалуюсь. Но так сказать всё надоело, прикипели(работаю с 8 утра и примерно до 6 вечера, всегда по разному, ещё есть маленький и любимый сын)и понимаю, что всю жизнь не смогу так работать. Тянет меня в IT, начал многи посты читать, какие вообще направления есть. Понравился язык Golang (самообучаюсь), но не знаю правильно ли я что делаю и то ли направление выбрал и что я вообще хочу от изучения данного языка. Помощь прошу в том чтобы подсказать или посоветовать мб какие либо онлайн курсы или литературу дополнительно(читаю сейчас Донована) Извиняюсь за корявость поста Всем добра p.s. Вообще для меня сначала в идеале, это ТГ боты с AI. Но с тем временем, которое у меня есть для самообучения уйдёт лет 10, а то и больше
Привет, Пикабу! Меня зовут Александр Троицкий, я автор канала AI для чайников, и я запускаю серию коротких статей по метрикам качества моделей для машинного обучения!
Confusion Matrix - это основа основ результатов моделей ИИ, а Accuracy (или точность) - самая простая метрика. Сегодня разберемся что это такое и как они считаются.
Зачем вообще нужны метрики в моделях ИИ? Чаще всего их используют, чтобы сравнивать модели между собой, абстрагируясь от бизнес метрик. Если вы будете смотреть только на бизнес-метрики (например, NPS клиентов или выручка), то можете упустить из-за чего реально произошло снижение или повышение показателей вашего бизнеса. Например, вы сделали новую версию модели лучше предыдущей (метрики модели лучше), но в то же самое время пришёл экономический кризис и люди перестали покупать ваш продукт (упала выручка). Если бы в этой ситуации вы не замеряли показатели модели, то могли бы подумать, что из-за новой версии модели упала выручка, хотя упала она не из-за модели. Пример довольно простой, но хорошо описывает почему нужно разделять метрики модели и бизнеса.
Для начала надо сказать, что метрики моделей бывают двух типов в зависимости от решаемой задачи:
1. Классификации - это когда вы предсказываете к чему именно относится то или иное наблюдение. Например, перед вами картинка и вы должны понять, что на ней, а ответа может быть три: это либо собачка, либо кошечка, либо мышка.
К одному из под-методов классификации относится бинарная классификация: либо единичка, либо нолик. То есть мы предсказываем либо перед нами кошечка, либо это не кошечка.
2. Регрессии - это когда вы предсказываете какую-то величину на основании предыдущего опыта. Например, вчера цена биткоина была на уровне 32.000 долларов, а на завтра вы прогнозируете ее на уровне 34.533 доллара. То есть вы ищете какое-то число.
Соответственно метрики, на которые смотрят при работе с моделями тоже разные. В этом посте я расскажу именно про классификацию.
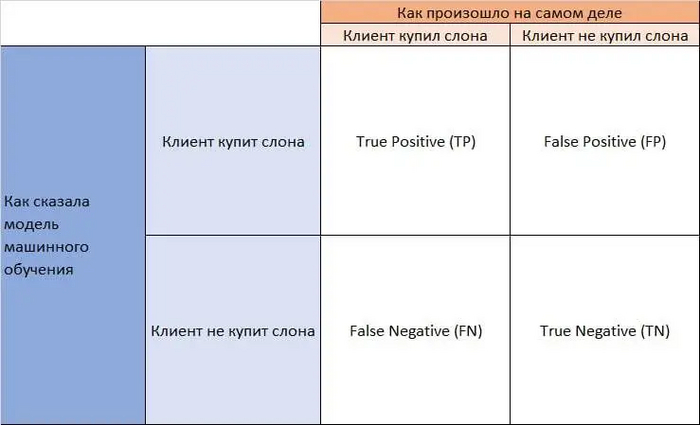
Confusion matrix
Для начала надо усвоить таблицу снизу. Она называется confusion matrix (матрица ошибок). Допустим, наша модель предсказывает купят ли некие люди слона. Потом мы пошли продавать им слона и оказалось, что часть людей слона купили, а часть - не купили.
Так вот результаты такого исследования можно разбить на четыре группы:
Модель сказала, что человек купит слона и он купил слона! -> True Positive (TP)
Модель сказала, что человек не купит слона, а он взял и купил слона! -> False Negative (FN)
Модель сказала, что человек купит слона, но он не купил его, когда ему предложили -> False Positive (FP)
Модель сказала, что человек не купит слона. И он действительно его не купил -> True Negative (TN)
Accuracy
Теперь давайте разберем самую простую и базовую метрику качества, про которую чаще всего говорят заказчики, не понимающие в ML. Называется она accuracy или точность. Смотрим выше на confusion matrix и запоминаем как считается точность модели:
Accuracy = (TP+TN)/(TP+TN+FP+FN)
Accuracy используют редко, потому что она дает плохое представление о качестве модели, если у нас не сбалансированны классы. Например, у нас есть 100 картинок котиков и 10 картинок собачек. Пускай для упрощения скажем, что котики - это 0, а собачки - это 1 (перейдем к бинарной классификации). В данном примере котики и собаки - это два класса. Собак меньше, чем котиков в 10 раз - значит выборка из картинок не сбалансирована.
Например, наша модель правильно определила 90 котиков из 100. Получается True Negative = 90, False Negative = 10.
Еще наша модель определила правильно 5 собачек из 10. Получается True Positive = 5, False Positive = 5.
Подставив данные в нашу формулу получим, что accuracy тут равен 86,4. Однако если бы мы просто сказали, что на всех картинках котики, то получили бы accuracy 90, хотя для этого и никакой модели и не нужно. И вот казалось бы, угадывая достаточно много картинок (аж 86%!) наша модель на самом деле плохая.
Заключение
В следующей статье я продолжу рассказывать про метрики ИИ, в том числе более ходовые Precision, Recall, F-score, ROC-AUC. А дальше коснусь метрик регрессии: MSE, RMSE, MAR, R-квадрат, MAPE, SMAPE.
Если вам интересно знать про ИИ и машинное обучение больше, чем рядовой человек, но меньше, чем data scientist, то подписывайтесь на мой канал в Телеграм. Я пишу редко, но по делу: AI для чайников. Подписывайтесь!
Привет, Пикабу! Меня зовут Александр Троицкий, я автор канала AI для чайников, и я продолжаю серию коротких статей по метрикам качества моделей для машинного обучения!
Что такое регрессия?
Задача регрессии в машинном обучении — это тип обучения в ИИ, когда модель обучается на данных с непрерывным значением, чтобы предсказывать его на основе одного или нескольких входных параметров. Отличие регрессии от задач классификации заключается в том, что регрессия предсказывает непрерывные значения (например, цену на дом, температуру, количество продаж), в то время как классификация предсказывает категориальные метки (например, да/нет, красный/синий/зеленый).
То есть задача регрессии предсказывает какую-то цифру, а задача классификации - это как выбор в тесте из нескольких вариантов ответа.
Пример
Давайте представим, что мы - доска объявлений типа Авито или Циана. Мы хотим подсказывать пользователю в интерфейсе по какой цене ему лучше разместить свою квартиру на основании множества факторов, например:
Местоположение квартиры
Площадь
Этаж
Ремонт
Год постройки здания
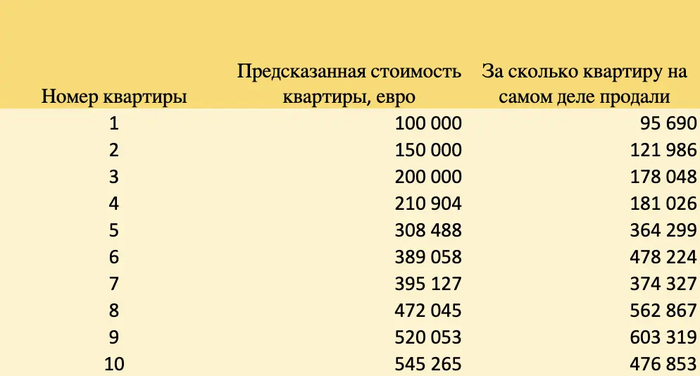
В итоге мы выводим пользователю рекомендуемую цифру в евро.Мы предсказали стоимость 10 квартир, а через месяц узнали за сколько их на самом деле продали.
Далее мы проведем с этими результатами нехитрые вычисления:
Вычтем из предсказанной цены реальную цену (первый столбик)
Возведем эту разницу в квадрат (второй столбик)
Возьмем корень из этого квадрата (третий столбик)
Получим следующие результаты на нашем примере:
P.S. да, можно просто взять разницу по модулю, но более умные математики говорят, что это все-таки не одно и то же - можете почитать об этом отдельно
MSE
Если мы возьмем второй столбик из зеленой таблицы выше, сложим все числа в нем, а потом поделим на количество этих чисел (возьмем среднюю), то получим MSE или среднюю квадратическую ошибку. В нашем случае:
MSE = 3353809295
Большое число! Из-за его величины оно сложно интерпретируется с точки зрения бизнеса. Чаще эту метрику используют при разработке моделей, когда важно наказывать большие ошибки сильнее, чем маленькие, так как ошибка возрастает квадратично. Это делает MSE чувствительной к выбросам. MSE используют, если большие ошибки недопустимы и должны сильно влиять на модель.
RMSE
RMSE или среднеквадратическая ошибка - это младший брат MSE. Чтобы ее посчитать нужно просто взять квадрат из MSE!
В нашем случае получится 57912.
RMSE также штрафует за большие ошибки, но в отличие от MSE, масштаб ошибки аналогичен исходным данным, что облегчает интерпретацию. Это делает RMSE хорошим выбором для многих практических задач, где важна интерпретируемость результата.
MAE
MAE или средняя абсолютная ошибка считается по третьем столбику из зеленой таблички выше. Нужно взять сумму корней из квадрата разницы между предсказанной ценой и реальной ценой и поделить ее на количество наблюдений. Проще говоря, берем среднее из третьего столбика.
В нашем примере MAE = 49243
MAE менее чувствительна к выбросам по сравнению с MSE и RMSE. Это делает её предпочтительным вариантом, когда выбросы присутствуют в данных, но не должны сильно влиять на общую производительность модели.
Немного усложним нашу зеленую табличку
Чтобы разобраться с тем как считается R-квадрат и MAPE нужно дополнить нашу зеленую табличку еще двумя стобиками:
Вычтем из предсказанной цены среднюю предсказанную цену и возведем это в квадрат (четвертый зеленый столбик 4). P.S. Не спрашивайте зачем это нужно и какой в этом практический смысл - просто сделайте :)
Поделим третий зеленый столбик на предсказанную цену квартиру из желтой таблички. То есть поделим разницу между предсказанной и реальной ценой квартиры по модулю на предсказанную стоимость квартиры. (пятый зеленый столбик)
Коэффициент детерминации (R квадрат)
Чтобы его получить надо из единицы вычесть разницу суммы второго и четвертого зеленых столбцов.
R-квадрат измеряет, какая доля вариативности зависимой переменной объясняется независимыми переменными в модели. Это хороший способ оценить адекватность модели: близость к 1 говорит о хорошем объяснении данных моделью. R-квадрат лучше всего подходит для сравнения моделей с одинаковыми данными.
MAPE
Средняя абсолютная процентная ошибка или MAPE - это среднее пятого зеленого столбца.
В нашем случае = 14,2%
MAPE измеряет отклонение прогнозов от фактических значений в процентах и является хорошим выбором, когда нужно легко интерпретируемое показание ошибки в процентном отношении. Однако MAPE может быть неэффективной, когда в данных присутствуют нулевые или очень маленькие значения.
Excel файл с примерами
Вы можете найти эксель файл с этими цифрами, бесплатно его скачать и собственноручно поиграться со значениями в нем вот в этом посте в моем телеграмм канале
Заключение
Поздравляю! Вы узнали про основные метрики в задачах регрессии!
Если вам интересно знать про ИИ и машинное обучение больше, чем рядовой человек, но меньше, чем data scientist, то подписывайтесь на мой канал в Телеграм. Я пишу редко, но по делу: AI для чайников. Подписывайтесь!
10 новых российских проектов для учета рабочего времени, контроля офисных помещений, удобного прослушивания аудио-книг, монетизации инструментальной музыки и многого другого. Битва за «Продукт недели» началась!
Product Radar — здесь каждую неделю публикуются лучшие онлайн-сервисы и железки от русскоязычных команд.
Это площадка, где энтузиасты из мира технологий делятся своими идеями, обсуждают и создают вместе новые продукты, чтобы делать жизнь людей лучше.
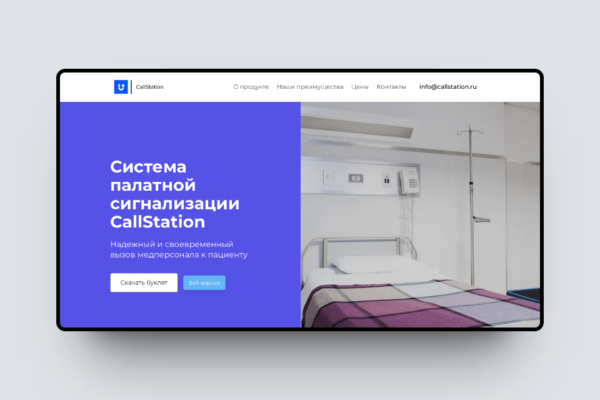
SaaS-платформа для полной автоматизации первой линии продаж
Участники 33-ого набора Product Radar
3 – 9 июня 2024 года
Читайте описания, кликайте на название проекта, голосуйте и комментируйте его на Радаре. Ваша поддержка очень важна основателям! 💙
Chrony
Ваш помощник для Google Календаря: создавайте и редактируйте события через текст, голос и фото.
Решаемая проблема: Люди тратят много времени на формирование расписания и забывают важные события. Google Календарь неудобен, поэтому многие предпочитают использовать заметки или избранное в Telegram.
Telegram Mini App для создания набросков, диаграмм и визуализаций.
Решаемая проблема: Телеграм-чаты часто используются для обсуждений, но ограничены в возможностях визуализации идей. Boardgram позволяет создавать наглядные схемы прямо в чате, облегчая понимание сложных концепций.
Облачная платформа с ИИ для контроля чистоты офисных помещений, мониторинга персонала и охраны.
Решаемая проблема: Отсутствие удобного и комплексного решения для управления коворкингами и гибкими офисами на базе ИИ технологий является барьером для эффективного функционирования современных рабочих пространств.
Сервис сверхбыстрой и точной транскрибации с помощью ИИ.
Решаемая проблема: Обработка аудио в текст для многих специалистов – трудоемкий и затратный процесс. Ручная транскрибация занимает много времени и денег, а использование нейросетей зачастую сложный процесс.
Превращает Google Таблицы в реляционную базу данных. Аналог Lookup из Airtable и JOIN из MySQL.
Решаемая проблема: Данные хранятся на разных страницах, отсутствуют нормальные связи и простая возможность отображать связанные данные в соседних страницах.
Решаемая проблема: Высокая стоимость и длительные сроки разработки веб-приложений с нуля, а также изобилие на рынке решений с некачественным кодом, уязвимостями безопасности и ограниченной функциональностью.
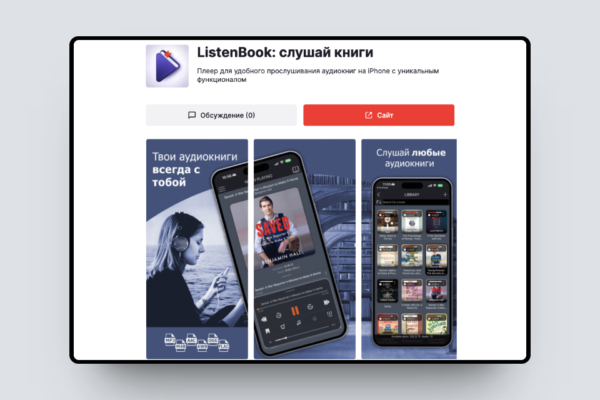
Плеер для удобного прослушивания аудиокниг на iPhone с уникальным функционалом.
Решаемая проблема: Прослушивание аудиокниг скачаных из различных источников в различных аудиоформатах. Простое добавление аудиокниг в приложение для прослушивания.
3 июня 2024 на сайте Product Radar были опубликованы свежие 10 проектов, которые поборются за ТОП-3 места по итогам недели. Победители получат значки «Продукт дня №1, 2, 3», а также отдельные посты в тг-канале Радара.
«Продукт недели № 1» получает грант от Yandex Cloud, а топ-3 продукта получают грант от Unisender в виде месячного тарифа и сопровождения по email-маркетингу.
Следующий «набор» появится на сайте через неделю, вы еще можете поучаствовать в нем или выбрать другую дату для размещения. Заполняйте заявку сейчас.
Поддержите проекты из подборки
Лайкните этот пост и поделитесь ссылкой на сайт Product Radar с друзьями и коллегами, чтобы как можно больше людей узнало о классных продуктах от русскоязычных команд!
Привет, Пикабу! Меня зовут Александр Троицкий, я автор канала AI для чайников, и сегодня я расскажу про самую популярную у дата саентистов модель машинного обучения - градиентный бустинг.
Что это за модель?
Если брать определение из словарика, то градиентный бустинг - модель машинного обучения, решающая задачи классификации и регрессии. Она состоит из ансамбля более слабых моделей (чаще всего дерево решений) и учится последовательно на ошибках предыдущей модели.
Но здесь я хочу упростить все сложные статьи с кучей математических терминов, коих в интернете немало, поэтому просто предлагаю разобрать это определение бустинга простыми словами:
"Решает задачи регрессии и классификации" - это значит, что модель может выбирать из нескольких заранее готовых ответов (котик на фото или пёсик - это классификация), так и угадывать какое-то число (сколько стоит квартира от млн рублей до млрд рублей - это регрессия).
"Состоит из ансамбля более слабых моделей" - это значит, что внутри нее сидит не одна модель, а множество. И вместе они каким-то образом принимают решение как ответить окончательно. В случае с бустингом модели принимают решения и исправляют ответы предыдущих последовательно. Что это за последовательность я подробно покажу на примере ниже.
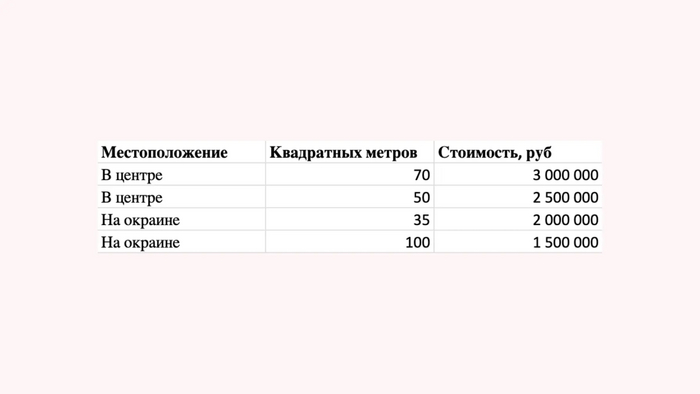
"Чаще всего состоит из деревьев решений". Дерево решений - это простой алгоритм машинного обучения. Для наглядности давайте представим, что у нас есть 4 квартиры, на основании которых мы хотим научиться оценивать стоимость квартиры. Само собой, в реальности мы бы делали модель на основании миллионов примеров стоимости квартир, но для упрощения мы возьмем 4 шутки:
Пример с квартирами
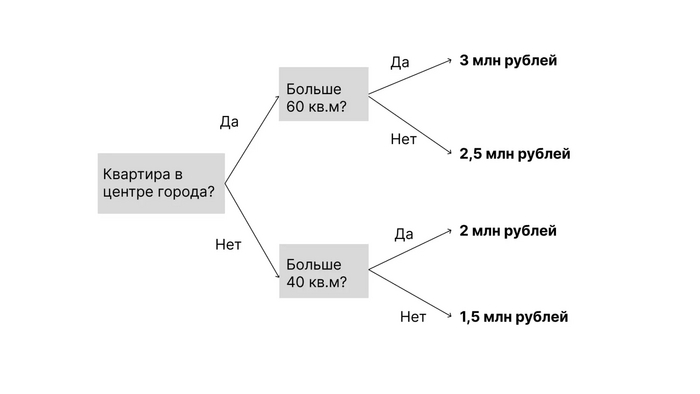
Вот какие выводы (примерно) сделал бы наш просто алгоритм дерева решений:
Результаты модели "дерево решений" на примере с квартирами
"Учится последовательно на ошибках предыдущей модели" - это значит, что мы сначала обучаем какую-то простую модель, потом смотрим, где мы ошиблись, и обучаем новую модель поверх первой, которая исправляет изначальные значения первой модели. Так повторяется какое-то количество раз, и в итоге мы складываем значения всех итераций (при регрессии). Давайте разберемся на примере с квартирами.
Как работает и обучается модель градиентного бустинга (XGBoosting) на примере?
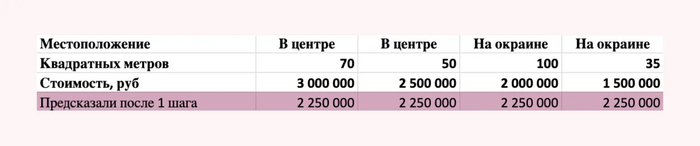
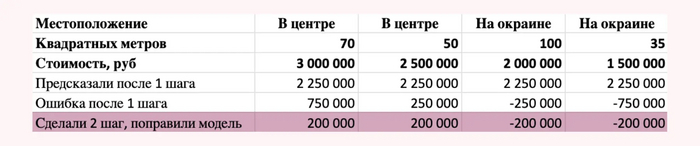
Для начала наша модель предсказала всем квартирам одинаковую стоимость (очень слабая модель).
Всем предсказали стоимость 2.250.000 рублей
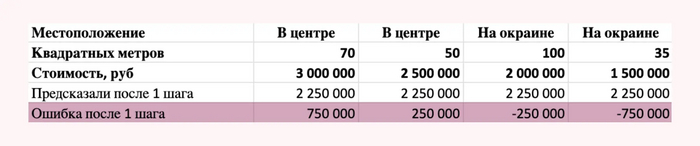
Таким образом, вычтя из реальной стоимости квартиры предсказанную нашей моделью величину, мы получаем ошибки нашей модели.
Ошибки после 1 шага, на них будем обучать 2 шаг
Именно на них будет обучаться следующая модель. Ее цель - уменьшить эти ошибки. При этом модель будет обучаться на тех же факторах, что и первая модель (местоположение и число квадратных метров). Во время следующей итерации наша модель решила добавить к изначально предсказанной стоимости 200.000 рублей квартирам в центре и вычесть 200.000 рублей квартирам на окраине.
Как изменили предсказания после 2 шага
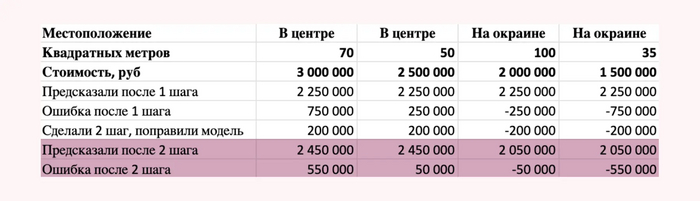
Таким образом, у нас получилась новая предсказанная стоимость квартир и новые ошибки.
Результаты после 2 шага и ошибки б
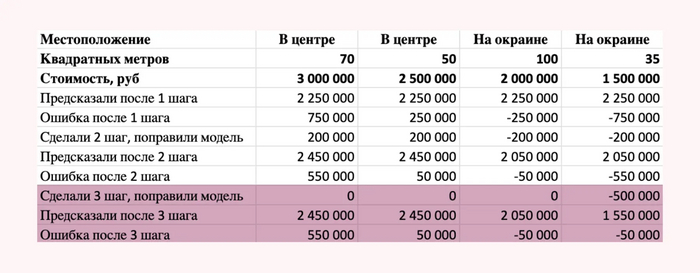
Дальше мы проводим еще один шаг обучения. На этот раз бустинг решил уменьшить предсказанную стоимость квартирам на окраине с площадью меньше 40 метров. Уменьшил он эту стоимость на 500.000 рублей.
Результаты после 3 шага обучения
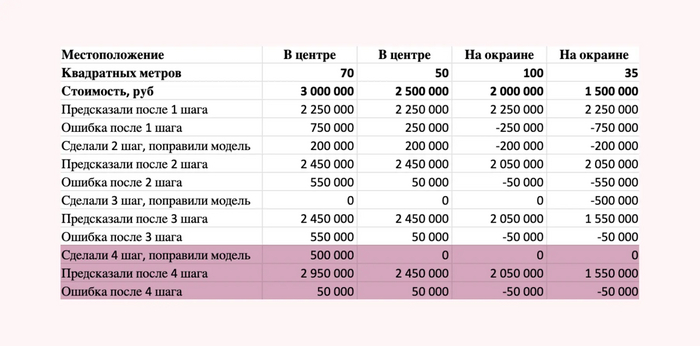
Ну и после 4 шага обучения алгоритм решил увеличить стоимость на 500.000 рублей квартирам площадью больше или равной 70 метрам в центре . Вот что получилось.
Результаты после 4 шага обучения
Итак, в итоге у нас получилась модель, которая обучилась на 4 шагах и в итоге предсказывает стоимость квартиры с погрешностью в 50.000 рублей.
Наш финальный алгоритм выглядит таким образом:
Базово оцени квартиру в 2.250.000 рублей
Если квартира в центре, добавь 200.000 рублей. Если она на окраине, вычти 200.000 рублей.
Если эта квартира на окраине и ее площадь меньше 40 метров, вычти еще 500.000 рублей.
Если квартира в центре и она больше или равна 70 метрам, добавь к стоимости 500.000 рублей.
Этот пример иллюстративный. Он описывает механику работы градиентного бустинга. В реальной жизни, конечно, этот пример бустинг решил бы с мЕньшей ошибкой за первое же обучение из-за маленького количества наблюдений.
Что еще стоит знать про модели бустинга?
У градиентного бустинга есть два основных гиперпараметра. Гиперпараметр - это то, что вы задаете модели как ограничение. С помощью них дата саентисты могут изменять модель, ничего не меняя в принципах ее работы. В основном тюнинг гиперпараметров используется, чтобы не дать модели переобучиться и показать хорошую предсказательную силу.
В нашем примере, переобучение модели - это когда модель хорошо предсказывает стоимость конкретно этих 4 квартир, но если ей дать другую квартиру, то она предскажет ее стоимость отвратительно.
Так вот у градиентного бустинга в качестве основных гиперпараметров есть learning rate и количество шагов обучения. Разберем каждый из них:
Количество шагов обучения - это сколько раз мы дообучаем модель на ошибках предыдущей. В нашем примере мы сделали 4 шага. Чем больше выборка, тем больше шагов обучения допустимо делать.
Learning rate - это то, на сколько мы можем исправлять предсказания предыдущего алгоритма. В нашем примере мы не ограничивали этот параметр, но часто рекомендуют ставить его меньше 0.2. Чем меньше этот параметр, тем больше возможностей вы оставляете для будущих шагов для улучшения качества модели.
Заключение
Поздравляю! Вы узнали про то как работает градиентный бустинг!
Своим опытом укрощения ИИ поделился Алексей Мартынов, программный директор Яндекс Практикума. Он рассказал, какие нейросети пригодятся разработчику и для чего. А еще на реальном кейсе показал, как их использовать, и дал советы новичкам.
Какие нейросети я рекомендую для работы программисту
Github Copilot
Для чего пригодится: ИИ-копилот позволяет быстро разрабатывать и находить проблемы в коде, повышая производительность опытных разработчиков в разы.
Вместе с редактором WebStorm выводит скорость написания кода на новый уровень. Но, конечно, при правильном применении. Новичкам в разработке, вероятно, будет мешать. Но если вы знаете, что вам нужно получить, подготовите контекст и запросите генерацию, то получите строго необходимый результат.
По сравнению с Amazon Whispers эта нейросеть работает несравнимо лучше. Сейчас JetBrains еще предлагает собственный AI-помощник в редакторе, но пока мало успел им попользоваться и не составил точного мнения. Хотя теоретически он должен работать лучше.
ChatGPT-4o
Для чего пригодится: GPT в новой версии отлично справляется с анализом графических изображений, неплохо переводит UML-диаграммы в код. Или, например, может выполнять несложную верстку по изображению.
Чат и до этого был неплохим помощником при проверке кода, генерации болванок и сниппетов. Но теперь, с расширенным контекстом и лучшим распознаванием изображений, обрел много новых вариантов применения.
Автоматизировать работу также поможет YandexGPT. Нейросеть ответит на вопросы по коду, объяснит работу алгоритмов и структуры данных.
Google TensorFlow
Для чего пригодится: это и все остальные решения требуют уже гораздо более глубокого погружения, но меняют сам подход к работе с кодом. Теперь программы — это набор действий, а их порядок может определяться моделями машинного обучения.
Google TensorFlow — это не только про анализ данных, но в том числе и отличное средство для формирования обучаемых программных систем на стыке обычного кода и машинного обучения. Очень производительное API, достаточно удобно встраиваемое в код.
Если вы только начинаете свой путь в разработке, но очень хотите попробовать нейросети в деле, перед этим пройдите наш бесплатный курс по основам программирования, чтобы лучше понимать код. А потом при желании можете освоить бесплатные курсы с базой по Python-разработке и Go.
Насколько нейросети экономят разработчику время
Работать в нейросети в виде чата — самый неудобный способ. Но если использовать API и предоставлять соответствующий контекст для заготовленных и отработанных запросов, то рабочую среду можно автоматизировать очень и очень сильно.
Мало того, в GPT, например, можно создавать агенты, которые могут даже исполнять произвольные действия. Аналогично используя API, можно реализовать и у себя на компьютере или сервере и использовать в повседневной работе. Такое применение устраняет большую часть рутины и может экономить до 60–70% времени, позволяя сконцентрироваться на важных задачах.
А теперь давайте разберем работу с ИИ на конкретном кейсе
Примеров применения нейросетей в программировании много, но мало какой кейс влезет в короткий текст, так как ежедневно используется в больших проектах. Из небольшого — это, например, быстрое прототипирование онлайн-сервиса для обрезки изображений в качестве учебного примера. Использовались Github Copilot и ChatGPT-4o.
```copilot
generate open api swagger defenition for photo crop service with following routes:
— post request for files upload return id for each file
— get request with id parameter for download image preview
— post request for croping array of prevoiously uploaded files by id and crop settings, return task id
— get request for downloading zip archive by task id
```
Генерация промежуточных типов, конфигов, описаний API и прочего значительно улучшает последующие результаты, но их нужно отсматривать и корректировать. После этого можно подготовить и настроить проектную директорию для бекэнда и сгенерировать сервер.
```
With open api defenition in api.yaml file generate routes realisation for express server using multer for file handling. Use unique identifiers for uploaded file names based on uuid package.
```
Причесываем код, устраняем ошибки. При генерации их всегда хватает, но можно скормить его GPT и попросить найти ошибки или предложить улучшения и т. д. Почему не в копилот? Чтобы не загрязнять его контекст, да и непосредственно с анализом и доработкой GPT справляется лучше, а у Copilot генерация первичная на лучшем уровне благодаря проектному контексту.
Подготавливаем заготовку фронта на реакт и генерируем основные компоненты.
Для загрузки:
```
Generate typescript react component for drag and drop uploading single file to the server using this api. Component should have a setFile(fileID) prop callback called when file uploaded and pass file id to them.
```
Для кроп зоны:
```
Generate typescript react component and corresponding styles for display and edit crop zone for uploaded image. Component should accept in props imageUrl, onChange and value for crop zone editing.
```
Вуаля, осталось собрать все это вместе, исправить ошибки и т. д.
Советы программистам, которые хотят освоить нейросети для работы
Не полагайтесь на код который выдает нейросеть, чтобы работать с ним вы должны знать его значительно лучше чем она и работать с ним очень внимательно. Запросы формируйте максимально конкретно: указывайте детали, дополнительный контекст, ограничения и пр.
Используйте нейросети для быстрого прототипирования какого-то решения, после чего его можно декомпозировать уже более детально и прописать требования и ограничения для каждой части. А уже с этими требованиями сгенерировать более годный код.
Не пускайте код от нейросети в прод: в нем изобилуют уязвимости, разного рода ошибки и не самые оптимальные решения. Но это хорошая болванка, чтобы не забивать кучу лишнего.
Не пытайтесь сгенерировать сразу все :) Чем меньшими шагами вы движетесь, тем лучше результат получаете.
Если вы начинающий разработчик, не генерируйте код. Лучше отправлять его части на проверку в нейросеть — вот это будет полезно.
Для тех, кто хочет войти в мир программирования, но пока сомневается, мы приготовили бесплатный тест на профориентацию. Его разработали методисты МГУ и Яндекс Практикума: он проанализирует ваши навыки, опыт и предложит подходящие специальности.
А наши бесплатные курсы помогут узнать о разных профессиях в IT, попробовать себя в них и определиться с направлением.
Такую задачу поставил Little.Bit пикабушникам. И на его призыв откликнулись PILOTMISHA, MorGott и Lei Radna. Поэтому теперь вы знаете, как сделать игру, скрафтить косплей, написать историю и посадить самолет. А если еще не знаете, то смотрите и учитесь.
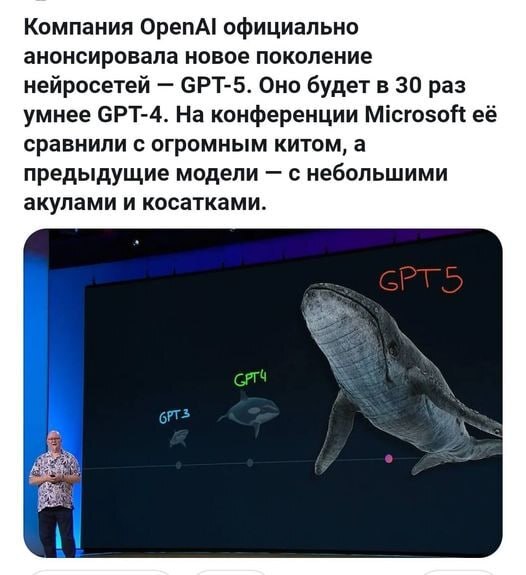
Куда умнее то :) см. картинку. Мы текущий потенциал еще не осознали. Пишут, что GPT-5 будет сильно лучше GPT4, которая уже крутая в типовых, жизненных задачах. Начинаю боятся :) будущего...