

Вышла новая модель для оцифровки изображений DeepSeek-OCR
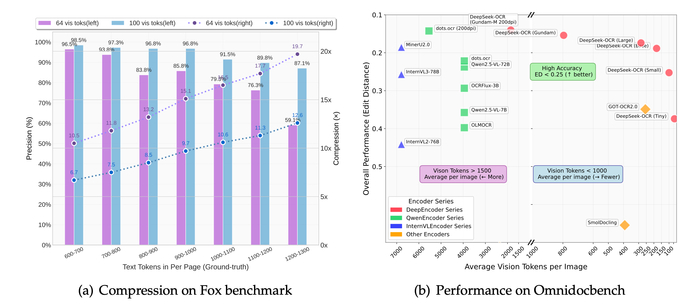
При создании модели DeepSeek-OCR (https://huggingface.co/deepseek-ai/DeepSeek-OCR) в DeepSeek исследовали сжатие длинных текстовых контекстов через их визуальное 2D-представление (оптическое сжатие).
В архитектуре использовали DeepEncoder, который сжимает высокоразрешающие изображения в малое количество визуальных токенов. А также Декодер (DeepSeek3B-MoE) для восстановления текста из сжатых визуальных токенов.
В результате при сжатии 10x точность распознавания (OCR) ~97%, а при сжатии 20x точность ~60%.
По тестам модель DeepSeek-OCR превышает производительность моделей GOT-OCR2.0 и MinerU2.0, используя в разы меньше визуальных токенов.
Может обрабатывать 200k+ страниц в день на одной A100-40G.
Показать полностью

















