

Учёные и журналисты




Когда сложно получить факты, важно хотя бы изучать взгляды разных сторон. В отсутствие конкурирующих мнений, можно искажать детали до любой степени
Моя группа ВК и телеграм-канал
Показать полностью
4
Когда сложно получить факты, важно хотя бы изучать взгляды разных сторон. В отсутствие конкурирующих мнений, можно искажать детали до любой степени
Моя группа ВК и телеграм-канал
В 2015 году учёные исследовали образцы геномов из гидротермальных источников между Норвегией и Гренландией. Поле с этими источниками ранее было поэтично названо замком Локи

Замок Локи
Учёные нашли в образцах геномы архей и назвали этот тип живых существ Локиархеоты (Lokiarchaeota) в честь места находки и скандинавского бога хитрости. В дальнейшем были обнаружены новые типы архей. Другие группы учёных решили поддержать традицию именования и дали им имена в честь иных персонажей германо-скандинавской мифологии. Так в биологии появились Торархеоты, Одинархеоты и Хеймдалльархеоты (Thorarchaeota, Odinarcheota и Heimdalarchaeota) в честь бога грома, верховного бога и стража богов соответственно

Надтип, объединяющий эти типы, назвали попросту Асгардом. Интересно, что эукариоты – ядерные организмы, к которым относится и человек, могли произойти из этого надтипа. Как пишет Википедия: "Похоже, что эукариоты впервые возникли в Асгарде”
Моя группа ВК и телеграм-канал
Продолжаем анализировать русский язык при помощи математики! Предыдущие посты:
1. Частота букв в русском языке
2. Лев Толстой против Пикабу — статистика русского языка
В комментариях под прошлым постом предложили сравнить очень интересный материал — магистерскую и докторскую диссертации, написанные на одной кафедре. Этим мы сегодня и займёмся! А чтобы читать пост было интересно всем, сравним их с первой и последней книгами из серии о Гарри Поттере
Волшебник из книг Джоан Роулинг рос вместе с нами. Первая книга «Гарри Поттер и философский камень» написана простым языком, понятным и детям. В последней книге серии — «Гарри Поттер и дары смерти» герои взрослее, а проблемы серьёзнее

В науке исследования, как правило, ведутся в узком направлении. Но каждая работа должна быть уникальной, а магистерская и докторская диссертации отличаются по сложности. Итак, что по вашему мнению будет больше похоже: первая и последняя книги о Гарри Поттере или магистерская и докторская диссертации, написанные на одной кафедре? Ставки приняты, начнём анализ!
Тексты о волшебстве
Начнём с анализа книг о Гарри Поттере. Сперва, по традиции, посмотрим на топ 15 самых частых слов в книгах:
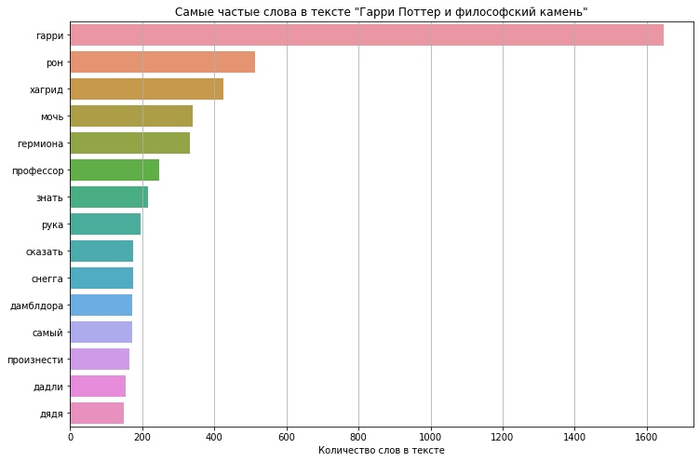
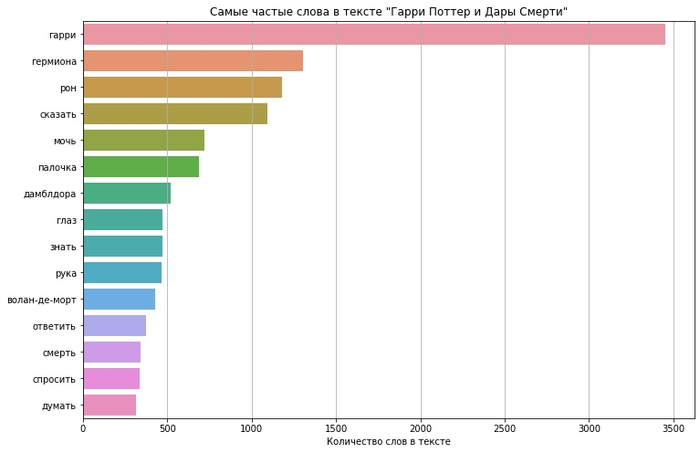
Да уж, нет никаких сомнений в том, кто главный герой серии. Забавно, что Гермиона обогнала Рона по частоте упоминаний в последней книге, хотя в первой уступала даже Хагриду. А ещё в серии неожиданно часто встречаются руки
Кстати, в этот раз я улучшил предобработку: теперь стоп-слова, наподобие частиц и предлогов, выбрасываются из текста, а остальные слова приводятся к одинаковой форме. Например, и «ответил», и «ответила» превращаются в «ответить», а «Рона», «Рону» и «Рон» считаются как одно слово. Это называется лемматизацией
Это делается автоматически и иногда приводит к казусам. Например «Малфой» превратился в слово «Малфа», а «Снегг» в «Снегга». Любители фанфиков, наверняка, останутся довольны
Вот визуализация топ 150 слов в текстах. Чем больше слово, тем чаще оно упоминается в книге:


В первой книге очень много имён, ведь она знакомит нас с новым миром. В последней речь больше идёт о главных героях и их действиях
Тексты о науке
Для анализа использовались две работы с кафедры электротехнологий, электрооборудования и автоматизированных производств Чувашского Государственного Университета. Большое спасибо за этот материал Фёдору Иванову (@fedor0804)
1. Магистерская диссертация «Индукционная установка для сквозного нагрева заготовок» Фёдора Иванова
2. Докторская диссертация «Исследование особенностей характеристик электротехнологических дуг в дуговых печах» Дениса Михадарова
Топ слов, конечно, совсем не похож на книги о Гарри Поттере. Главные герои здесь индуктор и дуга, а в тексте часто встречаются числа и специальные символы. Их, к сожалению, не удалось правильно обработать и на графиках они выглядят как прямоугольники. Скорее всего, это греческие буквы, например, β


Сравнение магии и науки
Итак, у нас есть 4 огромных текста. Как понять, насколько они похожи друг на друга? Для этого можно посчитать косинус угла между текстами или даже сам угол. Давайте разберёмся, как это работает
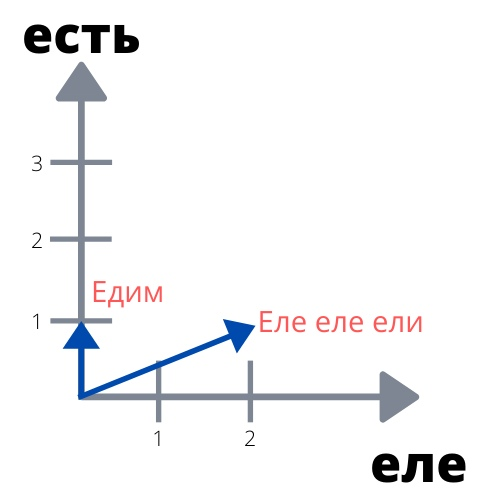
Представим два текста поменьше: по одному предложению в каждом. Первый текст — «Еле-еле ели». Второй текст совсем лаконичный — из одного слова «Едим». После лемматизации у нас будут уже такие тексты:
1. еле еле есть
2. есть
Теперь подсчитаем количество слов в них:
1. «еле»: 2, «есть»: 1
2. «еле»: 0, «есть»: 1
Мы можем нарисовать простой график, где по одной оси будет отложено количество слова «еле» в тексте, а по другой — количество слова «есть». Изобразим наши предложения на этом графике
Теперь не проблема посчитать угол между текстами! Можно, конечно, взять транспортир. Но для того, чтобы решить эту задачу для текстов с тысячами слов, это не поможет. Если конечно, вы не живёте в тысячемерном мире и у вас полно тысячемерных транспортиров
Мы представили тексты в виде векторов. В школе вы считали скалярное произведение между векторами и находили через него угол. Здесь можно сделать то же самое — и неважно, сколько всего уникальных слов в текстах – два или тысячи. Для текстов из примера — косинус будет равен примерно 0.44, а угол — 63 градуса
Чем меньше угол между текстами, тем больше они похожи. Если же угол равен 90 градусам, то тексты перпендикулярны — совсем разные. Например, такой угол был бы между текстами на русском и китайском языках — у них нет общих слов. Надеюсь, вы только что стали немного умнее :)

Вернёмся к нашим текстам. Больше всего оказались похожи книги о Гарри Поттере. Угол между ними — всего 26 градусов
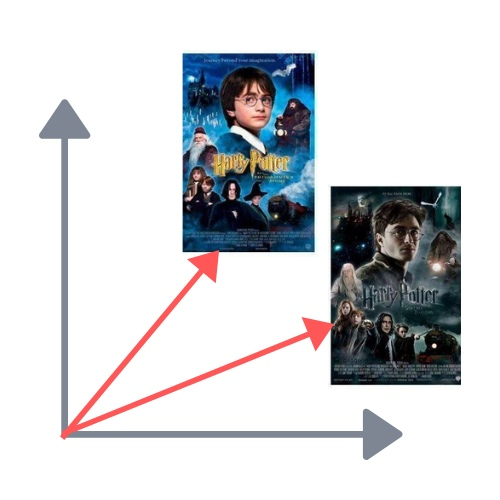
Между магистерской диссертацией и книгами о Гарри Поттере оба угла составили 87 градусов. Эти тексты очень разные. Ещё менее похожими на книги Джоан Роулинг оказалась докторская диссертация — у неё получился угол 88 градусов с первой книгой и 89 градусов с седьмой
Что забавно, научные работы тоже оказались довольно разными. Угол между диссертациями — целый 71 градус
Так что, последняя книга о Мальчике, который выжил — почти то же самое, что и первая, но немного под другим углом. А читая научные работы, даже с одной кафедры, вы каждый раз изучаете новый труд

Заглядывайте в комментарии – там есть небольшой бонус. Пишите, анализ, каких текстов вам ещё бы хотелось увидеть
Моя группа ВК и телеграм-канал
Недавно я делал пост о частоте букв в русском языке. Из него вы узнали, что «О» встречается чаще, чем 14 самых редких букв вместе взятые, 50% языка написана всего 7 буквами, а «Ё» пора переносить из букваря в Красную книгу
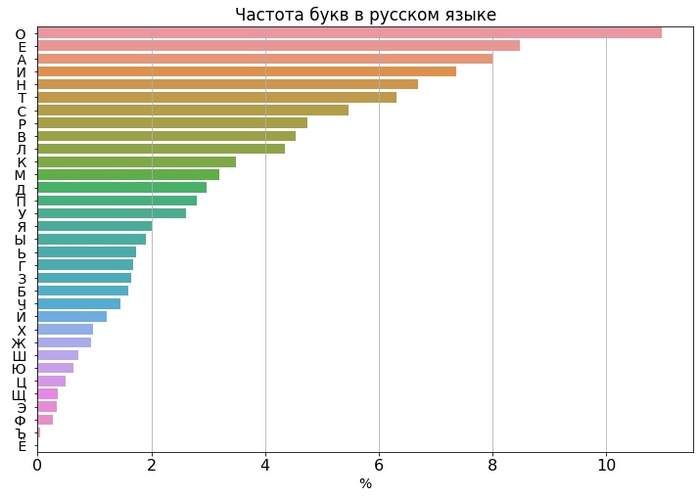
Сегодня мы пойдём ещё дальше! Проанализируем не только буквы, но также их сочетания и целые слова. Для анализа возьмём 4 тома произведения «Война и мир» одного небезызвестного Льва. А для того, чтобы понять, насколько достояние культуры похоже на современный русский язык, сравним его с одним из самых популярных постов на Пикабу 2020 года. У него достаточно много комментариев, в которых люди говорят на разнообразные темы. Это отлично подходит для анализа языка. Вот содержание поста:
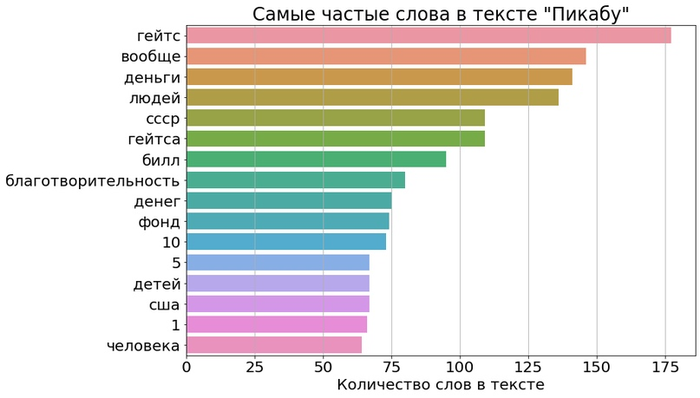
Кажется, что язык в комментариях под такой картинкой будет совсем не таким, как в художественном произведении 19 века. Но достаточно длинные тексты становятся похожими друг на друга и подчиняются общим закономерностям. Например, сравним частоты букв:
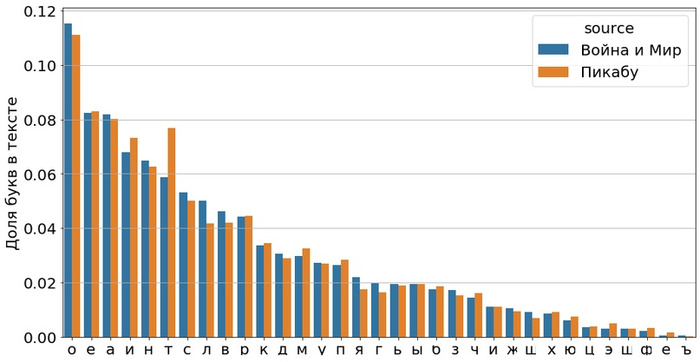
Они почти идентичны! Единственное, что явно выделяется — частота буквы «Т» в комментариях Пикабу. Предположу, что это связано с тем, что в посте обсуждают Билла Гейтса
Кстати, в комментариях получилось 83 тысячи слов, а в книге — 465 тысяч
Теперь посмотрим на статистику поинтереснее! И самое популярное слово… «И». «И» — самое популярное слово. В обоих текстах
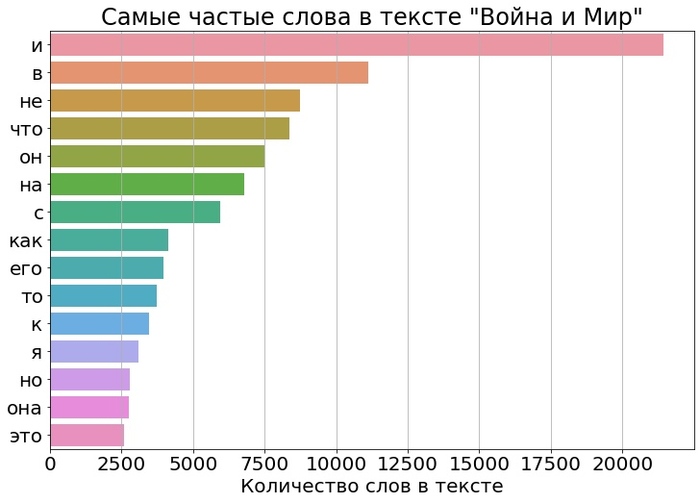
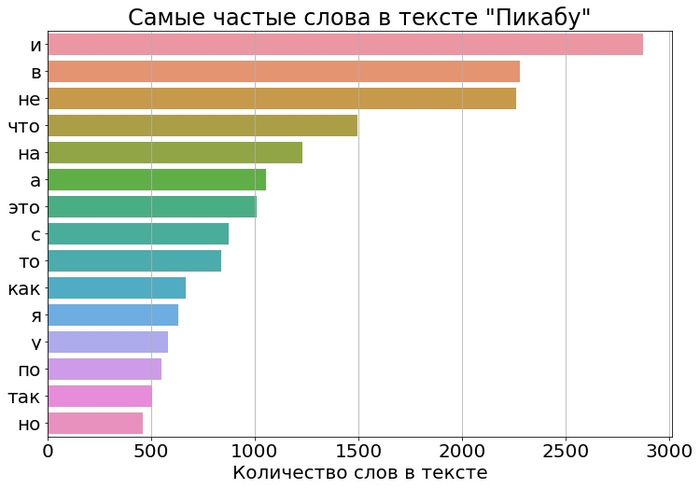
«Топ 15» слов удивительно похожи! Настолько, что первые 4 слова полностью совпадают. Забавляют и суммарные количества слов. Читая «Войну и Мир», вам придётся больше 20 тысяч раз встретить слово «И». Предположим, что на его прочтение уходит одна десятая секунды. Тогда после завершения всех четырёх томов, вы суммарно потратите пол часа только на чтение слова «И»
Вы можете возразить, что эти слова необходимы для связывания текста, поэтому неудивительно, что они так часто встречаются. Можно удалить все предлоги, союзы, частицы и прочие «стоп-слова». Тогда тексты снова приобретают свою индивидуальность. По графику можно сказать, о чём в них шла речь и кто именно главный герой:
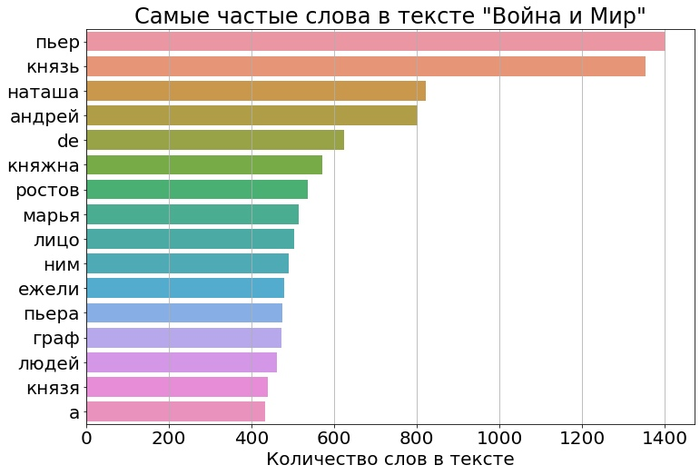
Тогда в топ «Войны и мир» попадает 2 французских «стоп-слова» — «de» и «a», что тоже забавно. А у Пьера Безухова и князя Болконского идёт нешуточная борьба за первое место
Ещё правильнее было бы привести слова к одинаковой форме (например, считать «Пьера» и «Пьер» или «Деньги» и «Денег» как одно и то же слово). Могу сделать это в следующих постах :) Пишите, анализ каких текстов вам ещё хотелось бы увидеть или если у вас есть идеи для более интересного анализа
Моя группа ВК и телеграм-канал
Работа учёного — производить знание, которого в мире раньше не было. Это знание упаковывают в удобную и компактную форму — научную статью. Другие учёные затем могут сослаться на неё в своих работах — это называется цитированием. Количество цитирований показывает, скольким людям пригодилось добытое вами знание. Это одна из основных метрик полезности научной статьи

Гора только из титульных листов всех научных статей была бы выше Килиманджаро
Конечно, количество цитирований не определяет качество работы. Она может быть сделана по очень узкой теме, которую сложно использовать большому количеству учёных. Среднее количество цитирований отличается и по научным областям — в медицине оно больше, а в математике — меньше. А есть и вообще откровенное читерство — изобрести метод, который позволит другим людям делать новые открытия. Такие статьи гарантированно будут хорошо цитироваться. Идеальный рецепт! Дело за малым — изобрести революционный метод…
Вот график топ-100 статей по цитируемости. Высота столбиков обозначает количество цитат, а цвет – научную область
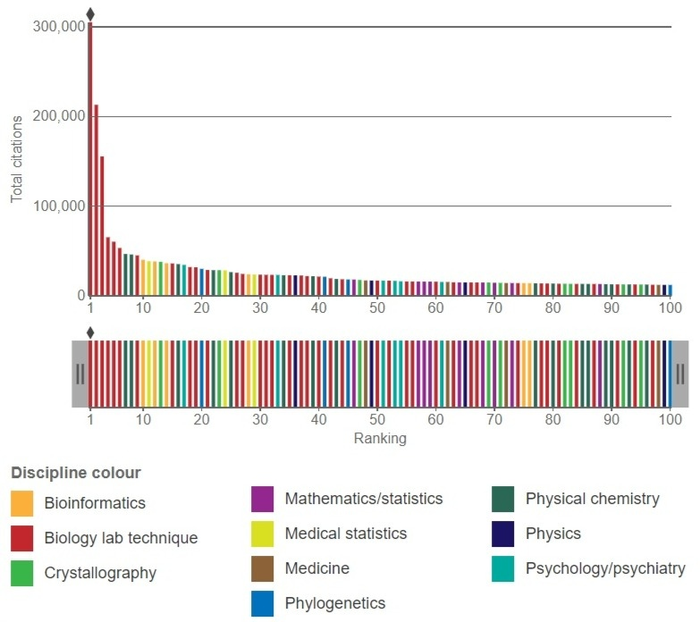
Разберём рекордсменов — самые цитируемые статьи за всю историю. Как вы могли догадаться, они все связаны с биологией. И во всех изобретается новый метод
1. Измерение количества белка
У этой статьи с лаконичным названием «Protein measurement with the Folin phenol reagent» больше 300 тысяч цитирований! Её первый автор — американский биохимик Оливер Лоури. Статья была принята к публикации в 1951 году и с тех пор стала настоящим блокбастером. Метод, изложенный в ней известен каждому биохимику на планете
А ещё, в ней очаровательные иллюстрации, сделанные от руки. Вот так выглядели графики, когда не существовало даже экселя:

В чём открытие?
Лоури разработал метод для определения количества белка в растворе. Вкратце это выглядит так — вы добавляете к раствору некоторое химическое вещество и он меняет цвет. Чем больше в исследуемой жидкости белка, тем насыщеннее будет цвет раствора

Измерив насыщенность цвета с помощью специального прибора, вы сможете найти точку на графике, которая покажет, сколько белка было в растворе
Почему это важно?
Белки — это основа известной нам жизни. И людям очень интересно измерять, сколько их в разных жидкостях! На этом основаны медицинские тесты и множество других научных работ
2. Разделение белков по массе
Статья с чуть более громоздким названием «Cleavage of Structural Proteins during the Assembly of the Head of Bacteriophage T4» на момент написания этого поста процитирована 268668 раз! С момента выхода в печать в 1970 году это в среднем по 14 цитирований в день. Согласитесь, было бы приятно, если бы десяток человек каждый день вспоминал о вашей работе?
В чём открытие?
Швейцарский учёный Леммли усовершенствовал метод для разделения белков по заряду и молекулярной массе. Это позволило другим учёным отделять разные белковые молекулы друг от друга. Выглядит это примерно так. В отдельных тёмных полосках — разные молекулы

Почему это важно?
Как вы уже поняли, белки очень важны для биологии и медицины, и потому интересны учёным. Но белков очень много. Например, у человека их почти 30 тысяч. Даже у такого маленького организма, как фаг (вирус) кишечной палочки их 160. Исследовать сразу все почти невозможно. Было бы гораздо удобнее отделить белки друг от друга и изучать по отдельности. Это и позволяет сделать метод Леммли
3. Измерение количества… белка?
Почётная бронза пока что принадлежит работе с уж совсем длинным названием «A rapid and sensitive method for the quantitation of microgram quantities of protein utilizing the principle of protein-dye binding». В 2020 году у неё было 221523 цитирования. Забавно, но её тема точно такая же, как у золотого рекордсмена

В чём открытие?
Метод Лоури, как и все первопроходцы, имел свои недостатки и был слегка капризен к условиям. Американский учёный Брэдфорд разработал ещё более простой и быстрый метод для измерения количества белка, за что и получил заслуженное признание
Почему это важно?
Это вы уже и сами знаете ;)
4. Чтение ДНК
Чтобы не оставлять впечатление, как будто учёные занимаются только белками, добавим ещё одну статью. У неё чуть более скромное количество цитирований — «всего» 75 тысяч. Зато эта работа была отмечена Нобелевской премией по химии

Фредерик Сэнгер, автор работы
В чём открытие
ДНК — это инструкция по сборке живых организмов, которая записана в каждой живой клетке. Английский биохимик Фредерик Сэнгер разработал метод, который позволяет её читать
Почему это важно
ДНК хранит в себе невероятно много информации о каждом организме. История жизни на планете, механизм заболеваний, ключ к появлению новых лекарств — всё это можно найти в ДНК. Сэнгер открыл настоящую сокровищницу для учёных со всего мира! С тех пор появились и другие методы, решающие ту же задачу, но именно метод Сэнгера остаётся самым точным. Впервые геном человека был прочитан во многом благодаря ему

Наверняка вы слышали про Нобелевскую премию. Но не удивлюсь, если вы никогда не смотрели церемонию награждения — она довольно скучная. Может быть даже скучнее, чем бубнеж одного конкретного лектора по физиологии на втором курсе
Наверное, так и подумал Юрий Мильнер, основатель Mail.ru Group и владелец инвестиционной компании DST Global. В прошлом — физик-теоретик МГУ
Вместе с женой Юлией в 2012 году они учредили приз за прорывные достижения в области фундаментальной физики и выплатили девяти учёным награду в 3 000 000$ каждому
В 2013 Миллеры позвали своих друзей – Марка Цукерберга и Присциллу Чан, Сергея Брина и Энн Воджицки, Джека Ма и Пони Ма. И как забабахали призовой фонд в 33 миллиона долларов (совершенно обычная история, мы с друзьями так каждую субботу развлекаемся)
Так родился Breakthrough Prize, и вот почему это круче чем Нобелевка:
• Он присуждается за значительные достижения в области фундаментальной физики, медицины и биологии, а также математики.
• Непосредственно каждый победитель получает 3 000 000$, а те, кто был номинирован и попал в шорт-лист получают премию Новые Горизонты в <вставить область науки> размером в 100 000$. Кстати, основной приз в 2 раза больше размера Нобелевской премии, но кто считает…
• Победителей награждают серебристым трофеем в форме тороида, выполненным дизайнером Олафуром Элиассоном. Кому-то он напоминает чёрную дыру, галактику или ДНК

• Наряду с самим Breakthrough Prize, с 2015 года призом Breakthrough Junior Challenge награждаются школьники от 13 до 18 лет. 50 000$ учителю, 100 000$ школе на покупку научной лаборатории, и стипендия в 250 000$ школьнику на высшее образование за трехминутный ролик на YouTube с объяснением научной концепции
• Фонд также финансирует два научных благотворительных проекта Breakthrough Initiatives. К созданию инициативы приложили руку не только технические гиганты, но и такие популяризаторы науки как Стивен Хокинг и последователи Карла Сагана. Breakthrough Listen - программа по поиску внеземной разумной жизни во Вселенной которую курировал Хокинг, а Breakthrough Starshot занимается разработкой концепции межзвездного флота, способного совершить путешествие к Альфа Центавре за 20 земных лет
На церемонию 2020 вы уже опоздали - она проводилась 3 ноября 2019 года. Этот приз — он про будущее ;)
Церемония награждения Breakthrough Prize проводится в Первом Ангаре НАСА, в Маунтин-Вью в Калифорнии и больше напоминает церемонию Оскар (эти два события продюсирует один и тот же человек)
Её посещают не серьёзные дяденьки в строгих костюмах - такого там вообще нет! Туда идут по зову сердца. Знаменитости не получают за это гонорар, музыканты выступают на церемонии чтобы поздравить ученых, а приз вручают известные актеры, модели и CEO крупнейших технических компаний
В 2020 шоу вёл Джеймс Корден, и даже спел смешную песенку про “науку, достойную трёх миллионов”
Так и проходит это торжество: на сцене слышны всевозможные акценты - от русского до испанского, ведущие обязательно скажут несколько шуток об образе „типичного ученого“, и наука здесь поставлена во главу всего
Так что если хотите, чтобы когда-нибудь симпатичный блестящий тороид вам вручила Адриана Лима, а руку пожал Марк Цукерберг и Бенедикт Когтевран, придётся учить математику, постигать науку и открывать человечеству новые горизонты. По-другому никак

Данные окружают нас повсюду. Цены на доллар и бензин, количество новорождённых в стране, температура на улице. Цифры сыпятся со всех сторон! Но гораздо приятнее смотреть на красивые картинки, чем на таблицы с числами. Как же красиво отобразить эти данные?

Гистограмма
Представьте, что у вас есть данные по зарплатам всех людей в стране. Это может быть таблица Excel с единственным столбиком. Смотреть на миллионы чисел вам уж точно не хочется! Но интересно разбить людей на категории по зарплате. Берём одну «корзину» и складываем туда все строки таблицы, в которых записано меньше 15,4 тысяч рублей. Во вторую — людей с зарплатой от 15,4 до 21,8 тысяч и так далее. Получим такую картину:
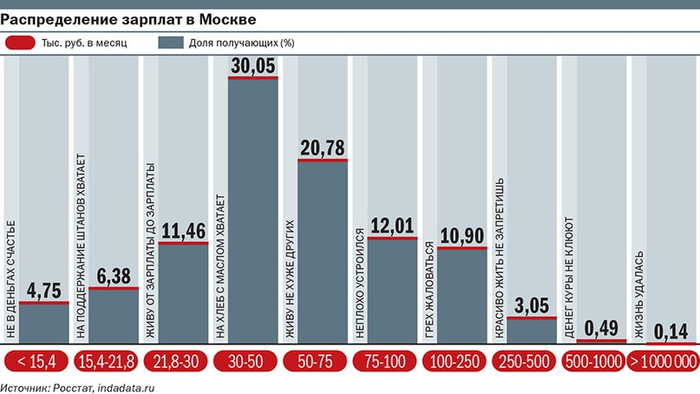
Визуализация от Коммерсантъ, 2017 год. Современные данные можно найти на сайте росстата
Хотелось бы увидеть нормальное распределение — большую часть людей в центре, немного бедных людей (вряд ли можно полностью избавиться от бедности) и богачей по краям:
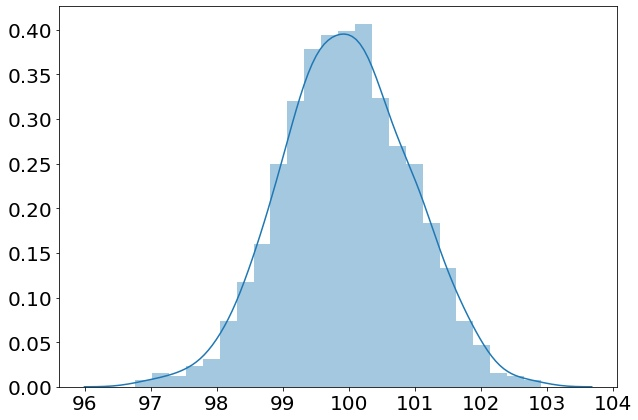
К сожалению, это не так: левый «хвост» реального распределения тяжеловат. Благодаря гистограмме мы это увидели, дальше осталось лишь думать и делать выводы
Если данных совсем много, можно не визуализировать отдельные «корзины» в гистограмме, а смотреть только на сглаженную кривую (как на иллюстрации выше). Например, можно посмотреть на то, как изменялся доход на душу населения во времени:
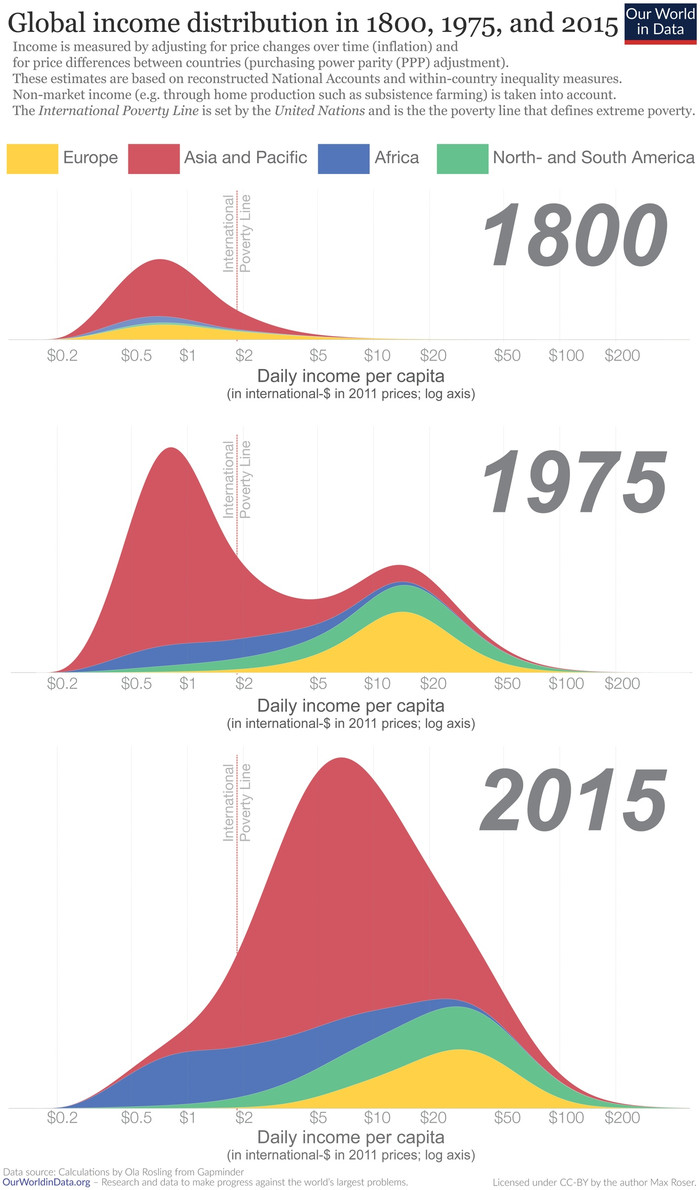
Источник – очень интересное исследование
Стоблчатая диаграмма (bar plot)
В прошлом примере у нас было много чисел в одном столбце таблицы. Это было одно большое распределение, которое мы для удобства разбили на «корзины». Но иногда такие корзины есть в самих данных. Например, если бы у нас были данные о количестве людей, работающих в разных отраслях. Тогда мы бы смогли для каждой отрасли высотой столбца изобразить, как много человек в ней трудоустроены. Это и называется столбчатая диаграмма! Как пример – процент использования разных социальных сетей в мире в 2010-2019 годах:
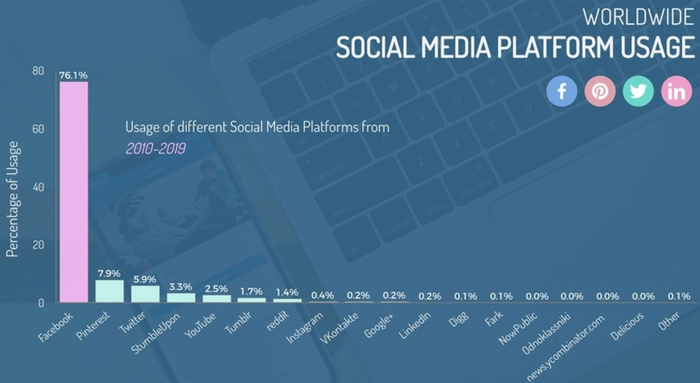
Круговая диаграмма (pie chart)
Иногда данные составляют доли от чего-то целого. В примере выше, все люди, работающие в разных отраслях, в сумме составляют всё работающее население страны. Есть соблазн изобразить такие данные в виде круга и раскрасить секторы в разные цвета. Площадь сектора будет изображать количество людей, работающих в отрасли. Это называется «круговая», а на английском «пироговая» диаграмма. Например, рекомендованная диета:
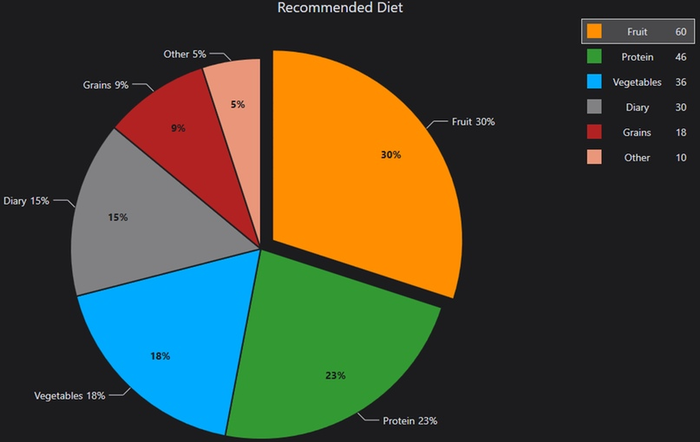
Но такому соблазну лучше не поддаваться! Круговые диаграммы ужасны. Они красивы, но, как оказывается, наш мозг довольно плохо на вид оценивает площадь. Особенно если для секторов выбраны контрастные цвета или график сделан трёхмерным и под наклоном. Вот отличная иллюстрация того, как непросто оценивать круговые диаграммы:
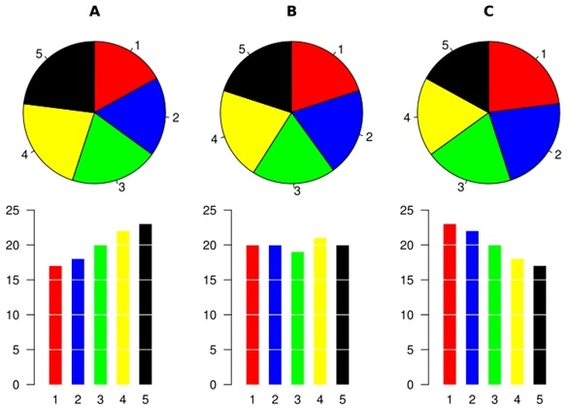
На первом графике сектора возрастают по площади от красного к чёрному. На втором они почти одинакового размера. А на третьем — наоборот, убывают. Но на первый взгляд диаграммы кажутся почти одинаковыми! Чтобы увидеть различия приходится внимательно в них вглядываться. А мы как раз хотим упростить понимание данных. Сравните с нижней частью рисунка чтобы понять, как просто ту же информацию извлечь из стобликов
Гифка о том, как сделать круговую диаграмму лучше:

Коротко — лучше не использовать круговые диаграммы вообще, если только вы не хотите намеренно запутать людей. Но иногда их использование уместно. Например, мне кажется удобной визуализация места на диске в Ubuntu. Это не совсем классический pie chart, но суть похожа. Можно рассмотреть сколько места занимает каждая папка, а затем её подпапки:

Иногда круговые диаграммы используют с настоящими пирогами, обыгрывая английское название:

Линейный график
Отлично подходит, когда между точками на графике есть какая-то связь. Например, временная. Когда вы можете сказать, что в разных точках что-то растёт или падает, по отношению к предыдущим, это именно тот случай, когда нужно использовать линейный график! Вот, например, график количества смертей от лесных пожаров по годам:
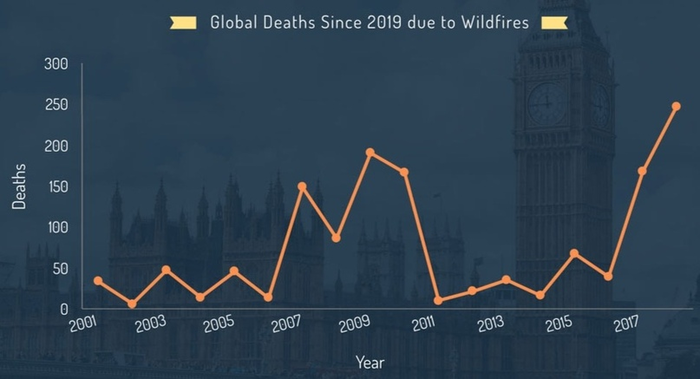
Цены акций, количество денег у вас на счету, количество заболевших какой-нибудь болезнью — всё это можно визуализировать именно так. Иногда для тех же данных используются и другие методы. Например, уже знакомая нам столбчатая диаграмма, где все столбики помещены друг на друга:
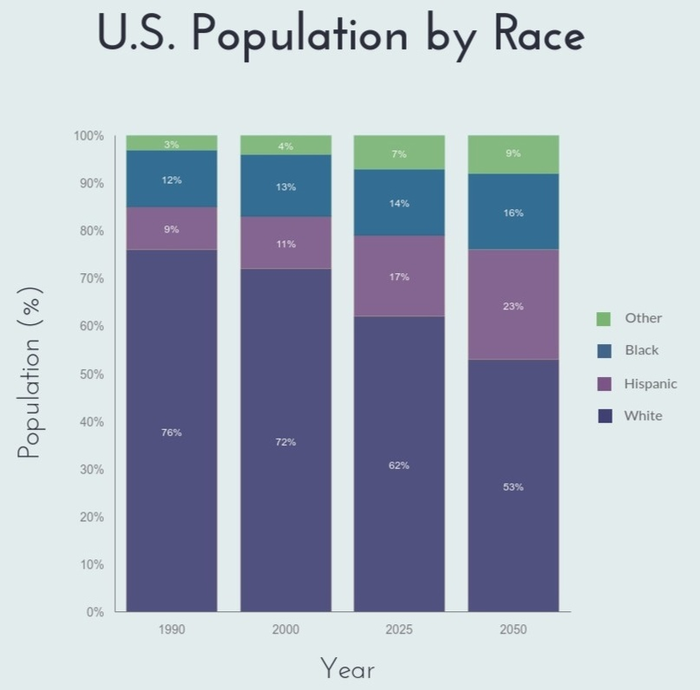
Или можно изображать визуализировать данные как площади, помещая их друг на друга:
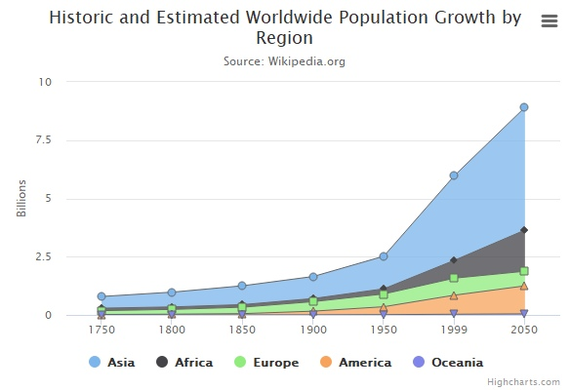
У этих видов графиков есть свои плюсы и минусы, но не будем останавливаться на них в этой статье. Можете предположить в комментариях, когда такая визуализация будет хорошей, а когда непонятной или некрасивой!
Точечный график (scatter plot)
На русском также называется «диаграмма рассеяния». Этот график помогает понять зависимость одной переменной от другой. Например, по одной оси откладывается площадь дома, а по второй его цена:
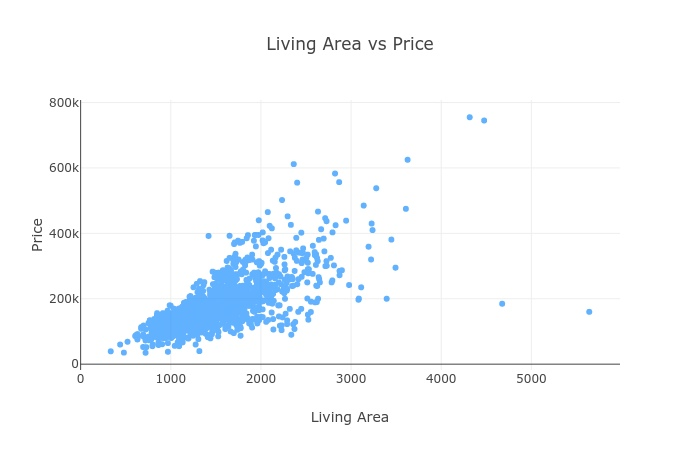
Видно, что в целом, чем больше площадь дома, тем дороже он стоит (переменные коррелируют). Визуально видно и исключения: по цене ниже 200 тысяч есть дома с очень большой площадью
Такой вид графика хорош ещё и тем, что он показывает сырые данные, как они есть. Иногда графики отображают только средние значения или разброс точек вокруг средних. На диаграмме рассеяния же мы видим каждый дом в виде точки!
Иллюстрация ниже показывает, почему это может быть важно. У всех графиков на ней одинаковые средние по обеим осям. Более того, на всех графиках одинаковая дисперсия и корреляция между переменными. Не пугайтесь, если не знаете термины, они просто означают разброс данных и связь между переменными

Все эти данные «одинаковые», если смотреть на средние, дисперсию или корреляцию, но благодаря простому графику очевидно, насколько они разные!
Недостаток такой визуализации в том, что она позволяет изобразить только две переменные. Если их в ваших данных три, то можно попробовать построить трёхмерный график. А если четыре? Такое изображение поймут только существа из фильмов Кристофера Нолана. А если переменных десять, то даже они не справятся
Хотя, используя разные цвета и формы точек, всё же можно изобразить на одном рисунке много переменных. На графике ниже изображены данные по возрасту актёров и актрис в фильмах. Каждая точка обозначает возраст главного актёра (по горизонтальной оси) и возраст главной актрисы (по вертикальной). Размер круга обозначает бюджет фильма, а цвета — конкретных актёров
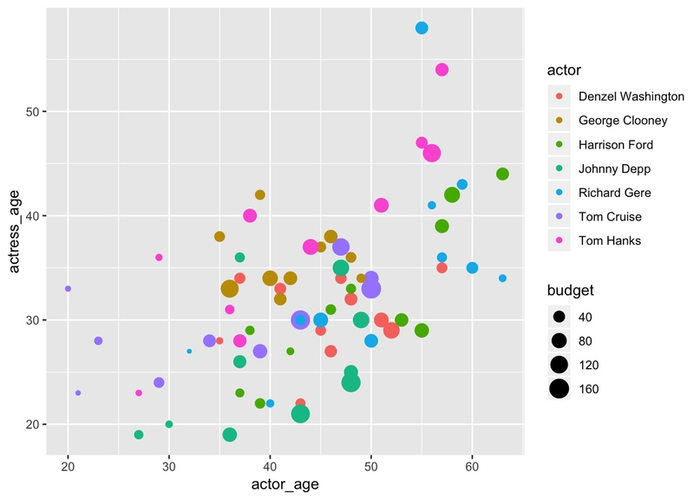
Видно, что в актёры обычно старше актрис. Кажется, что это различие ещё больше выражено в высокобюджетных фильмах. А цвета позволяют проследить карьеру каждого актёра. Целые четыре переменные мы уместили на плоскости! И смогли увидеть в данных много интересного
На этом сегодняшняя подборка завершается. Это были только самые базовые виды графиков. В арсенале аналитика есть также скрипичные графики, «ящики с усами» и многое другое! Если вам понравится пост, то сделаю продолжение :)
Моя группа ВК и телеграм-канал
Невозможно быть учёным только в рабочие часы. Научный склад ума накладывает отпечаток на все сферы жизни. Даже на чаепитие. Как следует заваривать чай, чтобы получить наибольшее удовольствие? Это маленький вопрос для науки, но очень важный для конкретного учёного!

Сперва нужно выделить факторы, которые могут повлиять на удовольствие от чаепития. Я пока что решил не пытаться выявить идеальное время заварки или количество кипятка. Также я ограничусь одним видом чёрного чая в пакетиках, который я привык пить с молоком. Другие сорта чая и переменные можно исследовать в будущем. А пока проверим три простые гипотезы:
1. Важно заливать чай молоком не сразу, а сперва дать ему завариться. Я обычно делал не так, но если ожидание поможет улучшить вкус чая, то это следует проверить!
2. Важно заливать чай кипятком. Если чайник закипел какое-то время назад и «бурление» уже прошло, то лучше поставить его кипятиться снова. Так всегда делала моя мама, и я с детства привык поступать также. Может быть, это не влияет на вкус и я зря каждый раз спешу залить чай кипятком
3. Влияние шоколада. Я очень люблю чай, как напиток, сам по себе. Помогает ли сладкое усиливать от него удовольствие или наоборот отвлекает от вкуса?

Своё удовольствие от чая я буду измерять в 10-бальной шкале. Но как в итоге понять, что повлияло на оценку больше всего? В этом нам поможет полный факторный эксперимент
Иногда нужно выяснить, как какая-то величина зависит от других параметров. Например, вы хотите понять, какие вещества нужно добавлять в сталь, чтобы она была как можно прочнее. Или какими лекарствами нужно лечить пациента, чтобы он поскорее выздоровел
Конечно, хочется попробовать все возможные сочетания всех возможных веществ. Но на это у сталелитейного завода не хватит денег, а у больницы – пациентов. Лучше исследовать действие всего нескольких факторов, воздействие которых, как вам кажется, может повлиять на результат. Испытаний также хочется провести как можно меньше
К счастью, существует теория планирования эксперимента, которая даёт вам готовую инструкцию. Если у вас есть N факторов, каждый из которых может находиться на 2 уровнях, то понадобится 2 в степени N испытаний. Например, для 3 факторов придётся поставить 8 разных опытов
Эксперимент следует проводить по такой схеме, как на рисунке внизу. Каждая строчка таблицы обозначает один опыт, а в столбцах – уровни фактора. В этой таблице «+» означает наличие фактора, а «–» его отсутствие. На примере эксперимента с чаем: плюс в колонке с чайником значит, что в этом опыте я заливаю заварку кипятком, а минус – жду какое-то время

Проведя все опыты, мы поймём как действует каждый фактор на интересующую нас величину. И даже больше: мы поймём, как на неё влияет взаимодействие факторов! Например, шоколад сам по себе может не увеличивать удовольствие от чаепития, но доставлять его в сочетании с добавленным сразу молоком. А какие-то два компонента в составе стального сплава могут увеличивать его прочность только вместе, но не по отдельности
Осталось самое приятное – провести эксперимент. Каждый день после обеда я пил по чашке чая, случайно выбирая строку из таблицы и выписывал своё удовольствие в баллах. У меня получился такой результат:

После того, как все строки заполнены нужно сделать несколько действий и получить долгожданное уравнение идеального чая!
1. Сложить все баллы удовольствия и поделить на количество экспериментов (посчитать среднее арифметическое). В уравнении это будет моё базовый уровень удовольствия от чая
2. Добавить столбцы для взаимодействий факторов. Например, в столбце «Взаимодействие молока и шоколада» будут плюсы только если знаки в столбцах «Молоко сразу» и «Шоколад» одинаковы. Кроме этого взаимодействия нужно добавить ещё 3 столбца (в том числе, тот, в котором будут все 3 фактора)

3. Посчитать коэффициенты уравнения! Для каждого из столбцов нужно сложить баллы удовольствия в тех строках, где в столбце стоят плюсы и вычесть баллы удовольствия в строках с минусами
4. Выбросить незначимые коэффициенты. Для этого нужно совсем немного применения статистики. Но чтобы не пугать читателей формулами, скажем просто, что слишком маленькие коэффициенты выбрасываются
Вот и всё, уравнение получено! У меня оно вышло таким:

В этом уравнении вместо молока нужно поставить единицу, если мы льём его в чай сразу после кипятка и минус единицу, если льём спустя минуту. Точно также для остальных факторов. Там где их несколько, знаки от отдельных факторов нужно перемножить
Какие можно сделать выводы? Мой базовый уровень удовольствия от чая – 65 баллов. Если лить молоко сразу после кипятка, то оно сразу же понижается на 5 баллов (а если подождать – повышается на 5). Шоколад также мешает наслаждаться любимым напитком и снижает удовольствие на 3 балла (а вместе с молоком – ещё на 3). Если же сразу добавить молоко, есть шоколад и залить заварку кипятком, то можно вернуть себе 3 балла удовольствия. Чтобы вернуться к десятибальной шкале нужно поделить всё на 8
Забавно, что коэффициент при «кипятке» оказался слишком маленьким – статистически незначимым. Значит, для меня нет разницы заливать чай кипящей водой или подождать, пока она немного остынет в чайнике. Это сделало мою жизнь немного спокойнее

Эксперимент, конечно, можно улучшить. Например, я всегда знал, какой набор факторов заварен в моей чашке. Мои предположения о результатах эксперимента могли повлиять на его результат. Если бы чай заваривал кто-то другой, а я не знал, залит ли он кипятком сразу, результат был бы объективнее. Это называется «ослепление» и применяется в исследованиях эффективности лекарств
Также был проведён всего один опыт для каждого набора переменных. Это помогло получить результат всего за 8 дней, но могло исказить результаты. Например, если в какой-то день у меня было хуже настроение, чем в другие и чай казался невкусным (или наоборот — значительно его поднимал)

Сможете ли вы найти комбинацию факторов, которые сделают удовольствие от чая в моём уравнении максимальным? А как бы выглядел ваш идеальный чай?
