

DBA. Какие технические навыки развивать?
Ребят, по-любому же есть на Пикабу админы БД.
После sql куда лучше направить усилия? В линукс? Баш? Питон? Чего в первую очередь учить?
Буду благодарен адекватным советам)
Ребят, по-любому же есть на Пикабу админы БД.
После sql куда лучше направить усилия? В линукс? Баш? Питон? Чего в первую очередь учить?
Буду благодарен адекватным советам)

Аудиоверсия в Телеграме, 8 минут
Arm вышла на биржу Nasdaq: торгуются 95,5 млн акций или 9,4% по 63,6 $ за штуку. Капитализация 67,9 млрд $. SoftBank, который владеет компанией, заработал 4,9 млрд $.
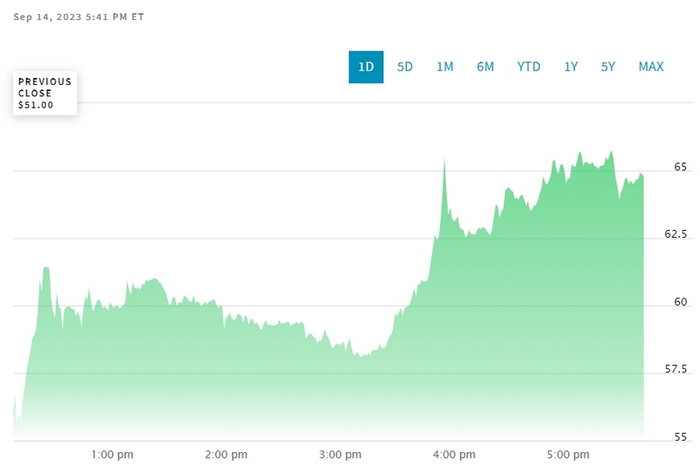
Релиз PostgreSQL 16: добавили синхронизацию между серверами и балансир нагрузки, проверку типа и создание JSON, новые метрики, улучшили скорость, местами до +300%, и многое другое. Версия поддерживается до 2028.
Забастовка 150 000 работников автозаводов Ford, General Motors и Stellantis в США. Требуют прибавку к ЗП. Ford предложил +20%, но этого оказалось мало.
Oracle договорилась с Microsoft о переносе части своих мощностей в Azure.
# Software
▸[4] Яндекс Пэй заработал с картами сторонних банков. Кешбэк 1% баллами Плюс.
▸[5] Бета-версия Фотографий в Windows 11 научилась размывать фон, копировать текст и автоматически скрывать адреса e-mail и номера телефонов на фото.
▸[6] Релиз плагина WordPress ActivityPub: дублирует посты в Mastodon и другие децентрализованные соцсети.
▸[7] Бета-версия Chrome 118 научилась работать с iCloud Keychain под Маком. Релиз в следующем месяце.
▸[8] Яндекс Браузер теперь умеет добавлять русские субтитры к любым видео. Доступен для Windows и Linux, а под мак в конце месяца.
▸[9] Консорциум Unicode одобрил 22 новых эмодзи.
# Hardpron
▸[10] Кружка Ember Tumbler: поддерживает температуру от 50 до 62 ˚C, управляется со смартфона, батарейка на 3 часа, объём 450 мл. Цена 200 $.

▸[11] Апдейт линейки беспроводных наушников Bose QuietComfort: обновили шумодав и железо, добавили Snapdragon Sound для Android. Затычки на 6 часов за 300 $ + 50 $ за кейс с беспроводной зарядкой. Полноразмерные на 24 часа за 350 и 430 $.

▸[12] Планшет Huawei MatePad: матовый дисплей 11,5" IPS @ 120 Гц, Snapdragon 7 Gen 1. ОЗУ 8 Гб, ПЗУ 256 Гб, HarmonyOS 3.1. В продаже со вторника за 500 €.

▸[13] Наушники Huawei FreeBuds Pro 3: беспроводные затычки, два излучателя, шумодав, батарейка с учётом кейса на 31 час, сколько в самих наушниках не уточняется. Цена 200 €.

▸[14] Часы Huawei Watch GT 4: 46 и 41 мм, новые датчики здоровья и графический интерфейс. Батарейка на две недели. Цена 250 €. Версия в золотом корпусе за 3000 €.

▸[15] Внешние накопители WD SanDisk G-Drive Project и G-Raid Mirror: HDD от 6 до 44 Тб, проприетарный слот SSD, Thunderbolt 3. Цены от 370 до 1500 $.


▸[16] Мышь Razer Viper V3 HyperSpeed: 30 000 DPI, 6 кнопок, память для профилей, вес 82 г, батарейка на 280 часов при опросе 1000 Гц и на 75 при 4000 Гц. Цена 70 $ + 50 $ за приёмник на 4000 Гц.

▸[17] Геймпады PlayStation 5 DualSense и сменные панели консолей: красного, синего и серебряного цвета. В продаже с ноября за 75 и 60 $.


# Business
▸[18] США ввели санкции против нашего завода компьютеров Kraftway, поставщика серверного железа 3Logic Group и других связанных с айти компаний.
▸[19] Google продлил поддержку Chromebook с 8 до 10 лет, но только для выпущенных после 2019.
▸[20] ЕС оштрафовал TikTok на 345 млн € за нарушение правил обработки данных детей. Их профили и видео были по умолчанию доступны для поиска.
▸[21] Соцсеть X согласилась на переговоры с двумя тысячами сотрудниками Twitter, которые обвиняют её в невыплате выходных пособий при увольнении. Встреча пройдёт 1 декабря.
▸[22] TikTok вместе с журналом Billboard запустили рейтинг топ 50 песен в соцсети.
▸[23] Unity временно закрыла два офиса в США из-за угроз расправы.
▸[24] Apple обещает обновить прошивку iPhone 12, чтобы Франция сняла запрет на их продажу.
▸[25] Infosys, вторая по величине айти-компания Индии, подписала 15-летний контракт на внедрение и поддержку нейросетей за 1,5 млрд $. Кому поможет их внедрять не говорит, но это «крупная корпорация».
▸[26] Биток 26 559 $, +1,3% за день.
▸[27] Некоторые тарифы МТС подорожали на +59 ₽. Федеральная антимонопольная служба проверяет законность повышения стоимости.
▸[28] Совет директоров Logitech переизбрал председателя Венди Беккер на новый срок. 96% голосов «за». Сооснователь компании, Даниел Борел, призывает переголосовать и выбрать того, кто будет лучше сокращать расходы и реагировать на изменения рынка.
▸[29] Google согласился выплатить штраф 155 млн $ по иску жителей штата Калифорния, которые обвиняют компанию в отслеживании местоположения даже после отключения этой функции.
# Alt stream
redirect(ntab.telegram);
# Увидимся в понедельник
Товарищи, прошу не уничтожать сильно за описанные вопросы. Я просто учусь. Искренне надеюсь на помощь сообщества и некоторое наставничество.
По результатам данного вопроса и предложенным вами материалам к прочтению, обязуюсь разобраться основательно и выпустить по этому поводу пост для тех, кто задумается о том же.
Возможно, ответы на ои вопросы есть в документации или являются базовыми, однако, я не нашёл ответов или плохо искал.
Речь пойдёт про работу с базой данных PostgreSQL в приложении на Python.
Итак. Из базовых описаний процесса работы мы знаем, что при работе с БД требуется провести простой объём операций, в частности:
# Создать объект "соединение"
conn = psycopg2.connect(паратметры)
# Получить курсор по этому соединению
cursor = conn.cursor()
# Формируем какой-то запрос
cursor .execute("Запрос на вставку данных в базу")
# Отправляем данные в базу
conn .commit()
# Закрываем соединение
conn .close()
Кажется всё просто. Но есть ряд вопросов.
А что, собственно, собой представляет объект conn? Имеется ввиду, что происходит на стороне базы, когда запрашивается соединение? Производится какая-то запись куда-то? Как это выглядит?
Почему объект conn нельзя десериализовать, чтобы передавать его между процессами в мультипроцессинге?
А что если твоё приложение и функция, которая открыла соединение упала, не закрыв соединение, что происходит с соединением на стороне базы?
А если твой код выглядит примерно так (ниже). Т.е. в бесконечном цикле в отдельном процессе выполняется функция, тогда как закрывать соединение? Когда? А что будет, если программа вылетит?
def функция(параметры):
conn = psycopg2.connect(паратметры)
cursor = conn.cursor()
while True:
cursor .execute(запрос)
conn.commit()
time.sleep(2)
if __name__ == "__main__":
mp_take_proxy_us_proxy_org = mp.Process(target=Фнукция, kwargs={параметры}, )
Вот пока вроде и весь пул вопросов. Подскажите, пожалуйста.
Аллоха! Прошу помочь чайнику)
Ситуация: К стационарному компу подключил съемный HDD, на него поставил postgresql. Теперь съемный HDD подключил к ноутбуку, чтобы через dbeaver поработать с БД. Но прикол в том, что сервер не запущен.
Вопрос: как запустить теперь сервер на ноутбуке?
Сразу спасибо за помощь, если она будет)
Люди, человеки, мастера Postgres, очень нужна помощь (возмездная! ) в решении пары задачек по основам Postgres. Работодатель уж послал, так послал меня повышать квалификацию, но ребята на курсах решили отбить всё уплоченные бабки и упихали в курс невпихуемое, включая базы данных, с которыми работа у меня планируется примерно никогда (штоп я сдохла). Тренировочная база bookings, многим известная, мать её в коробушку, и несколько задачек, подвластных человеческому уму, но не моим двум извилинам. Выручайте, а то хочется точить слезу каждый раз в три ночи, когда я после работы решаю эту дрянь собачью. Торжественно клянусь не идти работать никуда, где нужен постгрес впоследствии и не похерить тем самым отечественную экономику)
В прошлом посте обмолвился, что собираюсь в своей базе данных завести каждому пользователю по табличке. Ну потому что у меня запросы всегда только для одного пользователя, а значит можно сэкономить ресурсы сервера на индексации, так я думал. Мне накидали полную панамку что так делать нельзя, но почему – никто особо не объяснил. И я решил бахнуть небольшой тест на нескольких БД – проверить что там будет на самом деле.
Для ЛЛ: В большинстве случаев выдавать каждому пользователю по таблице действительно нет смысла. Но для SQLite запросы обрабатываются ощутимо быстрее, если у каждого пользователя своя табличка.
Итак, тестовая задача, более- менее приближенная к моему сценарию:
периодически пользователи закидываеют в БД записи в которой есть ID пользоватея, время записи, текстовая метка (комментарий) и какой-то параметр (число)
INSERT INTO mega_table (id, dt, txt, dat_stat) VALUES ( %s, %s, %s, %s )
после наполнения базы пользователями иногда запрашивается статистика по тому самому числовому параметру за какой-то период времени и с определенным комментарием
SELECT SUM( dat_stat ) FROM mega_table WHERE id=%s AND dt < %s AND dt > %s AND txt = %s
Проверял 3 БД: MySQL сдвижками InnoDB и MyISAM, SQLite и Postgres. Написал скрипт, который эмулирует заполнение БД и запросы к ней, и измеряет сколько времени занимает добавление записи и выполнение запроса. Скачать скриптец можно тут (он сугубо тестовый, т.е. стрёмный и без никакой обработки ошибок, уж сорян). Менял количество пользователей и количество записей у каждого пользователя и смотрел что будет если всё писать в одну таблицу, либо каждому пользователю создавать отдельную. Заодно после выполнения скрипта посмотрел сколько полученные базы данных занимают места на диске.
И вот получились такие таблички.
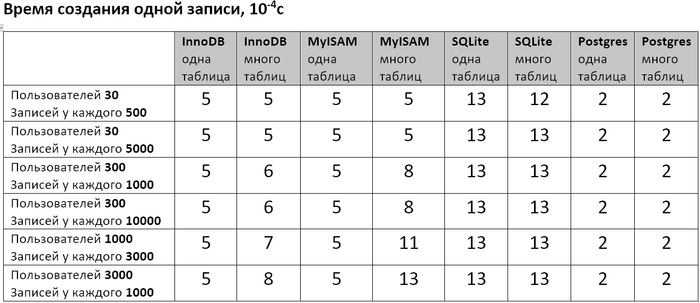
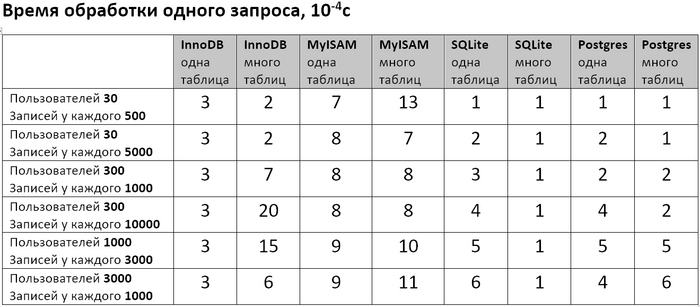
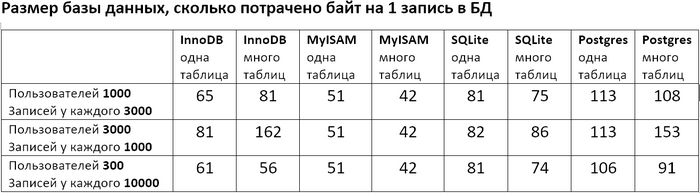
Какие выводы я для себя сделал.
Во первых видно, что если делать по таблице для каждого пользователя, то и добавление записи, и обработка запроса и размер БД получаются вобщем не лучше, чем если завести одну таблицу на всех. Единственное исключение – выполнение запросов в SQLite (и в некоторых случаях для Postgre) может быть в разы быстрее на многих таблицах, чем на одной. Почему так получается? Думаю потому что БД люто заоптимизированы очень крутыми чуваками под определенные сценарии использования. И если ты не столь-же крут (я лично нет), то нужно выбрать наиболее подходящую БД и подгонять свою задачу под типичные сценарии использования этой БД.
Во вторых если мне важнее скорость добавления/чтения (т.е. экономить вычислительные ресурсы) то из протестированных лучше пользовать Postgres, если важнее экономить место на диске – то MySQL с движком MyISAM. MySQL с движком InnoDB где-то посередине.
В третьих SQLite неожиданно всех обошел в скорости выполнения запросов (для моего случая по крайней мере). Прикольно.
Ну и в четвертых, питоновская обёртка для SQL-запросов про которую я писал в прошлом посте таки упростила бы мне написание тестового скрипта, но для чистоты эксперимента пришлось её отложить в сторону.
В любом случае это было интересно сделать, надеюсь кому-то было интересно и почитать.
Вот опять, очередной «Российский аналог ...». Как и соцсеть ВКонтакте, которая сделана братьями Дуровыми изначально российским аналогом Facebook* (*владелец бренда Meta — запрещённая в России организация). Что мы значимого сделали в ИТ не как аналог чего-то успешного?
Почему так происходит уже 20 лет? Почему наши "предприниматели" хотят быстрых денег здесь и сейчас? Хотя наших разработчиков с удовольствием используют западные бизнесмены — значит, потенциал же есть. И не только в космической отрасли, которая его подрастеряла после 80-х. Не только в ВПК, который производит оборонных ракет ПВО столько же, сколько весь остальной мир ( https://tass.ru/armiya-i-opk/16829181/ ).
И снова вроде крутой продукт, востребованный. Но почему цены такие конские, сравнимые с лицензией оригинала? Почему попробовать бесплатно можно только оставив контакты?
Из российских продуктов только СУБД Postgres хоть как-то адекватно подходит под мои претензии. И то это изначально opensource проект американского ученого Майкла Стоунбрейкера, профессора Калифорнийского университета. Наши дельцы подсуетились, даже получили лицензию ФСБ для её внедрения госорганами и организациями — и вот она, российская СУБД. Но хотя бы дают бесплатную версию as is, без гарантий. И лицензии с разовым платежом для тех, кто не хочет платить бесконечно за подписку, тем более за каждого пользователя/подключение.
Вспоминаю прекрасный пример Microsoft, подсадившей весь мир на Windows. Кажется, даже Билл Гейтс в одном из интервью проговорился, мол, пусть домашние юзеры и малый бизнес пиратят и обучаются работе в нашей ОС, а мы потом заработаем на крупном бизнесе, когда они в него превратятся или придут туда работать. Это я называю стратегическим мышлением. Если бы не было пиратства — сколько Майкрософту пришлось бы потратить на рекламу, на которую сейчас не тратится практически ничего?
В 2002 году компания объявила временный мораторий на борьбу с интернет-кафе и компьютерными клубами России и стран СНГ, использующими нелицензионное (ворованное) программное обеспечение Microsoft. Не удивлюсь, если сами же его и раздавали на торрентах. "Мы не будем обращаться в правоохранительные органы с просьбой о проведении проверок, а также не намерены выступать с заявлением о возбуждении уголовных дел, даже если правоохранительные органы в ходе проверок в любом из интернет-кафе выявят нарушения авторских прав корпорации". ( https://www.kommersant.ru/doc/318389 )
И волна антипиратских дел по Винде и Офису в конце нулевых - начале 2010-х не по их инициативе по России прокатилась. Управление К просто "рубило палки".
Дофига написал, резюмирую. С таким подходом EvaProject навсегда останется локальным российским продуктом, выживающим только благодаря "импортозамещению". Да и в России доля рынка будет сравнима с "российскими операционными системами" (даже в т.ч. без кавычек ОС РОСА ХРОМ для процессоров Байкал, потому что купить его и попробовать её уж слишком дорого для домашних юзеров). Просто потому что есть Jira, а это очередной "российский аналог".
- Дать ее бесплатно, чтобы через 10 лет на нее подсела вся Россия и страны БРИКС? ❌
- Напишем «российский аналог» и сразу поставим цены оригинала! ✅
Не стесняюсь называть себя патриотом, выбираю продукты российского производства. Но почему патриотами бывают только потребители? У бизнеса другая родина — та, которая печатает зелёные бумажки?

B-дерево - это алгоритм индексирования, который используется в PostgreSQL. Он основан на идее разделения данных на несколько секций, которые называются узлами дерева. Каждый узел содержит набор ключей и ссылок на дочерние узлы. Поиск значения в B-дереве осуществляется путем последовательного перехода по узлам дерева, начиная с корневого узла, и сравнения искомого ключа с ключами в текущем узле. Этот алгоритм обеспечивает быстрое поиск, вставку и удаление данных, особенно в случае большого объема данных.
Узел дерева - это элемент структуры данных, который содержит информацию и ссылки на другие узлы. В B-дереве, каждый узел содержит набор ключей и ссылок на дочерние узлы. Корневой узел дерева является вершиной, откуда начинается обход дерева. Узлы ниже корня называются потомками. Каждый узел может иметь одного или несколько дочерних узлов, которые соответственно называются листьями дерева. Листья являются конечными узлами дерева и не содержат дочерних узлов.
B-дерево является структурой данных, которая может быть реализована в различных языках программирования, включая PHP. Чтобы реализовать B-дерево в PHP, вы можете создать класс, который описывает узел дерева и содержит методы для добавления, удаления и поиска элементов в дереве.
Некоторые из основных методов, которые вы можете реализовать в классе B-дерева в PHP, могут включать:
insert($value) - добавляет новое значение в дерево
delete($value) - удаляет значение из дерева
search($value) - ищет значение в дереве и возвращает true, если найдено, и false в противном случае
getMinimum() - возвращает минимальное значение в дереве
getMaximum() - возвращает максимальное значение в дереве
Важно отметить, что реализация B-дерева может быть сложной и требует некоторой предварительной
подготовки и знания алгоритмов и структур данных. Вам также может потребоваться протестировать и отладить ваш код для обеспечения корректной работы.
В PHP так же можно использовать сторонние библиотеки для реализации B-дерева, к примеру, "btree" или "B-tree" или "php-btree". Использование сторонних библиотек может значительно упростить процесс реализации B-дерева в вашем PHP-коде и обеспечить более надежную и оптимизированную реализацию.
Так же стоит отметить time complexity и space-complexity
Time complexity B-дерева обычно определяется как O(log n), где n - это количество элементов в дереве. Это достигается за счет того, что каждый узел дерева содержит не более t-1 ключей и t дочерних узлов, таким образом максимальная глубина дерева ограничена log(n/t).
Space complexity определяется как O(n), где n - это количество элементов в дереве. Это означает, что память, необходимая для хранения дерева, зависит от количества элементов в дереве. Каждый узел дерева содержит не более t-1 ключей и t дочерних узлов, поэтому количество узлов в дереве будет ограничено n/t.
Однако, необходимо учитывать, что в B-дереве также может быть использован дополнительный объем памяти для хранения информации о дочерних узлах и других метаданных.
"Introduction to Algorithms" авторы: Thomas H. Cormen, Charles E. Leiserson, Ronald L. Rivest and Clifford Stein. Эта книга считается одним из лучших учебников по алгоритмам и структурам данных и включает подробное описание B-дерева и других структур данных.
"Database Systems: The Complete Book" автор: Hector Garcia-Molina, Jeff Ullman, and Jennifer Widom. Эта книга посвящена базам данных и включает подробное описание B-дерева и других индексных структур, используемых в базах данных.
"Algorithms in C++" автор: Robert Sedgewick. Эта книга предоставляет практическое руководство по алгоритмам и структурам данных на языке С++ и включает код для реализации B-дерева.
Спасибо за дополнения и замечания https://t.me/gasoid
Ещё больше полезной информации тут https://vk.com/work2oq






