


Православный json rpc
Знаете почему JSON RPC православен? Потому что он требует соблюдать POST
(Стянуто с рабочего чата)
Знаете почему JSON RPC православен? Потому что он требует соблюдать POST
(Стянуто с рабочего чата)
В рамках создания комплекса экзокисти под управлением нейрокомпьютерного интерфейса написал прошивку для Arduino Mega, которая через CAN-контроллер управляет серводвигателем RMD-X8 Pro, приводящим в движение механизм экзокисти. Модель экзокисти создавали наши студенты, прошивка представляла собой скетч, вырезанный из другого проекта, двигатель мог управляться только с помощью джойстика. Причем джойстик при движении вперед раскручивал двигатель вперед, а при отклонении джойстика в обратную сторону постепенно останавливал его и начинал неконтролируемые движение в обратном направлении. При остановке джойстика движение также не прекращалось. Контроля углов вращения не было.

Особенность этого двигателя в том, что при вращении вала двигателя на 360 градусов редуктор примерно в четыре раза уменьшает угол поворота, а энкодер двигателя контролирует вращение только на 360 градусов по валу двигателя, что фактически является только четвертью полного оборота. При прохождении отметки в 360 градусов энкодер сбрасывался в ноль и считал данные заново.
Для двигателя есть настроечная программа, которая работает по протоколу serial-232, имеются варианты интерфейса двигателей с RS485 у которого больше возможностей, чем у CAN, который через один датафрейм может передать максимум 8 байт. В тестовой вкладке программы настройки примеры интерфейса управлением двигателя работают не так, как хотелось бы, но зато оказалось, что там есть команды, не описанные в документации. При использовании тестовых режимов программа указывает, какие данные она пересылает в датафрейме, и стало видно, что кроме команд позиционирования А1-А6 также используются команды А7 и А8, и последняя команда как раз подошла для нашей задачи.
Сейчас прошивка реализована следующим образом: от джойстика или от внешней управляющей программы (в итоге это будет нейрокомпьютерный интерфейс) приходит команда, что нужно выставить угол экзокисти в заданное значение. Прошивка определяет текущее положение двигателя, если угол больше, то подается команда на движение в обратную сторону, положение кисти постоянно контролируется.
Энкодер двигателя очень чувствительный – он позволяет позиционировать двигатель с точностью до сотых долей градуса. При команде на остановку двигатель по инерции проходит еще несколько сотых градуса, и без усреднения данных положения энкодер постоянно пытался бы вернуть двигатель точно в заданное положение, опять бы проскакивал его по инерции и т.д., что вызывало бы постоянное дерганье. Усреднил показания позиции, разделил их на 100 и отбросил дробную часть, чтобы сравнивались только целые градусы углов, поскольку точность в 1 градус вполне достаточна, а лишних дерганий удается избежать.
Добавил в прошивку подстраховку, что в случае неисполнения двигателем команды на остановку она будет посылаться снова и снова, пока двигатель не остановится. Кроме того, есть команда на аварийное отключение двигателя, если что-то идет не так.
Также добавил в прошивку работу с внешними интерфейсами через последовательный порт в формате JSON, через которые прошивка будет получать команды от внешней управляющей программы. На Java написана ретранслирующая программа, которая принимает пакеты по протоколу UDP, пересылает их в Ардуино по serial, с последовательного же порта получает ответ от платы и пересылает его обратно в управляющую программу высокого уровня по UDP. Это необходимо для обратной совместимости со сторонним программным обеспечением.
Формат файла Adobe XD представляет из себя архив, который содержит описание структуры макеты в виде JSON структуры, графических растровых и векторных файлов использованных при создании макета.
Стандартный метод — открыть в программе Adobe XD — нужна программа купленная за деньги (подписка).
Использовать сервис-конвертор XD2SKETCH.COM — за деньги (подписка или платное разовое использование).
Программу-сервис Avocode — за деньги.
Кроме того, некоторые программы работают только в среде Mac OS (Sketch - только MAC OS или веб-приложение)
И тому подобное.
Чтобы открыть макет Adobe XD бесплатно, можно воспользоваться бесплатной программой-сервисом Photopea — в этом случае видны все параметры объектов макета и даже доступ к CSS значениям реализован удобнее чем в Photoshop. А вот реализация извлечения растровых объектов из макета, для внедрения в вёрстку, немного подкачала, на мой вкус.
Чтобы получить объекты из файла Adobe XD, достаточно открыть его как Zip-архив, например с помощью архиватора 7-Zip. В результате получим несколько папок с ресурсами JSON, XML, и папкой с растровыми объектами: «resources».
Содержащиеся там файлы будут без расширений, но это решается просто переименованием, с добавлением соответствующего расширения. Если есть сомнения в том, какое расширение необходимо, достаточно открыть файл в программе Notepad++ или в другом тактовом редакторе. У файлов формата PNG в первой же строчке будет «‰PNG». У SVG-файлов будет так же видна вся XML структура присущая SVG-файлам.
Итого, файл макета открыт в Photopea — данные CSS доступны для переноса. Папочка с графикой для вставки в вёрстку — готова.
Кроме того, из Photopea можно сохранить в PSD, который открывается некоторыми бесплатными просмотровщиками и редакторами.
Возможно, подход не оригинальный. Но уж чем богаты.
Вероятно есть и более простые методы.

Стянуто с телеги.
Первая часть: Сказ о том, как Рыцарь свежего смог достучаться до самого сердечка ИЛИ ищем API Пикабу
Предыдущая часть: Ищем API Пикабу. Часть 1.5. Интермедия

Жил-был маленький Программист, который смог. И вот однажды в глубине интернета он переходил на вражеские сайты — клик-клик-клик-клик, клик-клик-клик-клик, бляяять-бляяять! Программисту был дан приказ найти инструменты для распаковки APK и скачать их на компьютер, который оборонял Windows Defender. Надо ли говорить, что вирусов кругом была тьма тьмущая. Думаешь, это остановило Программиста, который Смог? Да черта с два! Он гуглил себе и гуглил — клик-клик-клик-клик, клик-клик-клик-клик, бляяять-бляяять! Даже когда он скидывал скриншоты местного GUI на Java знакомым Qt-девелоперам и они задыхались от увиденного. У тех из глаз кровища течет вперемешку с соплями. Но, думаешь, это остановило Программиста? Правильно! Он так и гуглил дальше — клик-клик-клик-клик, клик-клик-клик-клик, бляяять-бляяять!
И всё бы ничего… Да гуки выложили на сайте два плагина для IDE. И как раз когда Программист установил его и начал исследовать код — БААМ!!! Не декомпилировалось! Кругом программное месиво, ассемблерный листинг повсюду разбросан, и тут откуда-то выползает мой друг-фронтэндщик Буба в Slack. Ему больно! Но он пишет мне:
— tmax! Я UI/UX не чувствую…
А я ему:
— Буба, у них его нет!
Гляжу, а культи у него дергаются быстро-быстро, вот так! Я говорю:
— Буба! До ближайшего code review 30 недель. Если не можешь позвонить и наорать на них матом, значит нам пизда!
И тут вдруг отовсюду ответные задачи как повыскакивают, а у меня из IDE один блокнот. Но делать то нечего… Надо прорываться! Ааааааааааааааааааааааааааааааааааааааааааааааааааааа!!!!!!!!!
Pull, падла, pull! Мидл tmax живым не сдается! Commit, это тебе за моего друга! Commit! Commit!

Предыдущая мажорная часть закончилась на том, что были перехвачены пакеты между приложением Пикабу на Android и серверами Пикабу. В минорной версии я рассмотрел плюсы и минусы разных способов распарсить содержимое страниц, и остановился на приватном API приложения Пикабу.
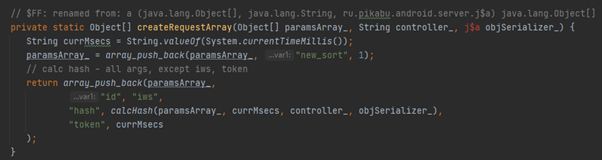
В каждом JSON запросе (по крайней мере в тех, которыми грузятся посты) всегда используется четыре ключа - id, hash, token, и new_sort. id всегда равен "iws". Существует несколько аббревиатур, не знаю, что именно означает эта, но сейчас это и не важно. Главное, что она не меняется и она едина для всех запросов. token - это время формирования запроса в миллисекундах, записанное в строку. new_sort всегда равен 1, это похоже на баг, пока я не вижу смысла включать этот ключ в каждый формируемый запрос, но он есть и придётся с этим смириться. Остается только hash, значение которого является закодированным base64 MD5 хешем, например "NWQ2MDRjYmMxY2FhZjNlYmE0MmU4NjA1ZTgzM2Q1NDM=". Да, это спойлер, доказательства будут приведены в конце статьи.
Дальше надо определить, как формируются входные данные для вычисления хеша. Простые комбинации имеющихся в запросе данных к результату не привели, придется реверсить приложение и искать алгоритм формирования исходных данных. Если что, то я вообще не умею в Android, но имею небольшой опыт обратной разработки и анализа приложений, собранных с помощью C/С++ с использованием IDA Pro. Так как IDA является именно интерактивным дизассемблером (Interactive Disassember), то я бы хотел получить исходники в любом виде, при условии, что у меня будет возможность переименовывать функции, переменные, параметры функций, конструкторы, классы и оставлять комментарии. Ну, собственно, не очень много требований, правда?
Хуй там плавал. Спойлер - я не нашел ни одной полноценной утилиты, которая покрыла бы все мои потребности на 100%. Но пиздеть - не мешки ворочать, поехали разбираться. Что делает программист, когда ныряет в свежее неизвестную область? Правильно, идет яростно гуглить, гуглить вдвойне - за ноябрь и за декабрь.

(С учетом вышеприведенной ссылки, данный мем выглядит чуть-чуть по-другому. Одобрям-с)
Немного расскажу про APKTool, которым я перепаковывал APK. Да, эта маленькая утилитка полностью декомпилировала APK и позволила собрать его назад. Однако, весь код приложения, который хранится в .dex файлах в виде инструкций для виртуальной машины Dalvik, она преобразовала в формат smali – это те же самые инструкции, только в текстовом виде ибо smali – местный ассемблер. Ассемблерный листинг - это пиздец, товарищи. Нет, он, разумеется, ощутимо проще ассемблера x86/x86_64, но использовать его для какого-либо продвинутого анализа могут только отцы. У меня на это нет ни времени, ни желания, хотя в конце первой статьи я написал, что надо в нем разобраться. Оказалось, что один из способов пропатчить код приложения - это ручками писать на smali, а затем результат упаковывать назад. Лучше, чем байткод напрямую править (а байткод - это единственный способ патчить native приложения/библиотеки). Пока разбирался, то нагуглил Java Decompiler и понеслась душа в рай. Вместо этой статьи должен был выйти туториал по анализу на основе smali, но ну его на хер, есть же гораздо более читаемый Java :> Правда, анализ пока немного не согласован с начальством, да и вообще, сабж вызвал горение жопы, так что я обязан вам все рассказать. Что вы там кричите с галёрки? Есть еще способы? Frida? Meh, оставьте себе эту хипстерскую дрянь перспективную штучку (я нашёл её много позже и не пробовал).
Вот в этом месте раньше начинался подробный разбор всех утилит, что я перекачал/пересобрал/перепробовал. Я рассмотрел примерно 2/3 заготовленных программ и за каким-то хуем решил прогуглить, вдруг, на Пикабу уже был подобный разбор приложений. И знаете, что? Правильно, я наткнулся на статью на Дзене и вбил в гугл одно рандомное предложение из той статьи.
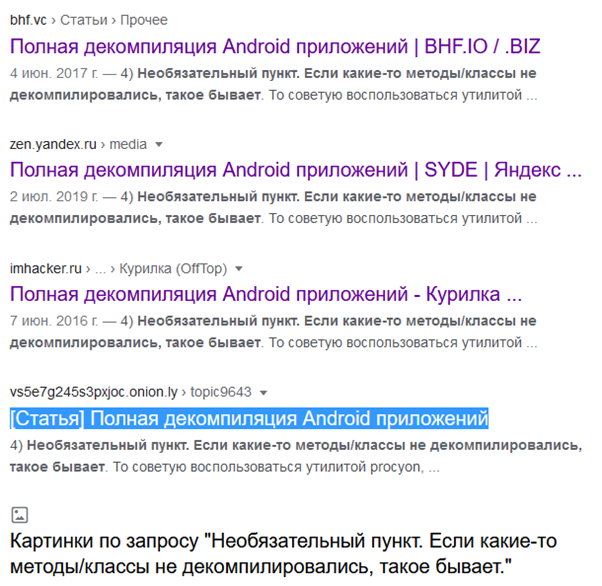
А я-то такой, весь из себя в Дольче и Габбане, ковырял англоязычные статьи, думал «какой же я сейчас охуенный контент подвезу, почти подробный разбор найденного мной ПО для декомпиляции на русском». Пиздец (лиса продолжает игнорировать слово "пиздец" и предлагает заменить его на "эпизодец". В этом что-то есть...). Выделенная статья на скриншоте является исходником и доступна в вебархиве. Она датируется 05.2016, потом её спиздили на imhacker, потом на bhf и только потом этот дремучий баян-бабаян три года спустя оказался на Дзене. С минимальными изменениями и ссылками на файлы в сети TOR, где она и родилась, лол. И что теперь, предлагаете моё изложение написать сюда? Чем этот пост лучше? Ничем, увы. Всё ПО, что я попробовал, так или иначе встречается там. Более того, в статье упоминается другой декомпилятор dex, enjarify. Я с ним не сталкивался, но проверю его за кадром. Если он окажется лучше, заберу себе вместо dex2jar. Фана ради стоит заметить, что последние правки dex2jar свежее, чем у enjarify, хотя в той статье ситуация как раз наоборот, надо протестировать. Вот так я словил дизмораль и к хуям снёс всё, что касалось разбора приложений.
_____________________________
Что дальше? Я нашел две рабочие конфигурации. Первая:
- консольная jadx, которая сразу выплёвывает .java, но делает это не на все 100%;
- Eclipse. Нахуй-нахуй-нахуй, тьфу блять. Хватит ебать труп, оставьте его! Бох накажэт, накааажэт!
- IntelliJ IDEA. IDE богов с нормально работающим рефакторингом с возможностью вести разработку Android приложений.
Вторая конфигурация:
- 7-zip, чтобы вытащить .dex файлы;
- dex2jar, чтобы из .dex файлов получить .jar-архивы с .сlass;
- Опять 7-zip, чтобы объединить полученные .jar-архивы в один, ибо декомпилятор должен работать сразу со всеми .class файлами, чтобы не возникало проблем с вызовом отсутствующих функций вследствие независимой обработки одного .jar за раз (я на эту проблему не наткнулся, так как сразу начал упаковывать в один файл по этой надуманной причине);
- fernflower, декомпилятор, поддерживаемый Jet Brains и встроенный в IntelliJ IDEA, но который можно скачать и собрать отдельно, чтобы была возможность запускать на пачке файлов (IDE позволяет работать только с одним файлом за раз в режиме read-only). Преобразует .jar с .class-ами на борту в .jar с .java;
- IntelliJ IDEA.
Первая конфигурация лайтовая, но jadx умеет читать метаданные Kotlin (кот с лампой, гы), что в случае нашего приложения дает такой нехуёвый результат в виде большого числа декодированных имен классов. Вторая же конфигурация длиннее, сложнее и требует сборки fernflower вручную (которая без костылей не обошлась, блять), но дает более качественный код, декомпилируя те методы, которые не взял jadx.
Ну и, собственно, пара скриншотов, чтобы вы не думали, что я пиздобол. Вытащенные из .apk .dex-файлы + полученные из них .jar-архивы. combined.jar содержит в себе все содержимое из прочих .jar-архивов.
Параметры для запуска fernflower, которые я использовал на combined.jar (да, компилятор зависал на каких-то функциях, я ему урезал время обработки до 30 секунд):
java -jar fernflower.jar -dgs=1 -mpm=30 -ren=1 combined.jar fernflower_out
Ну и скриншот функции, в которой собирается запрос (уже отрефакторенный):
А еще я оказался прав. Хеш считается как MD5 + base64:
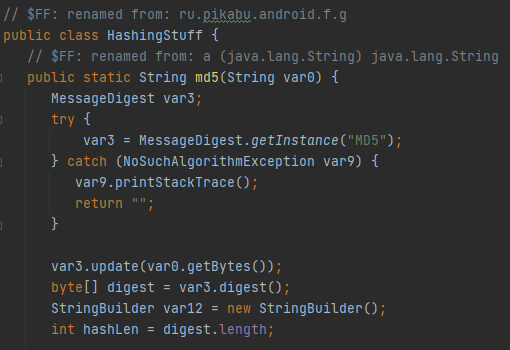
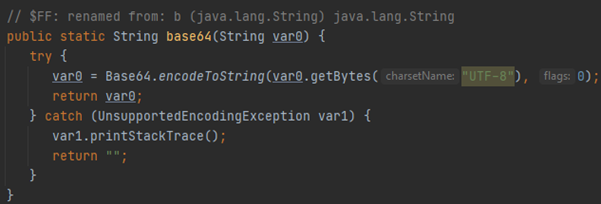
На момент написания вот ЭТОГО слова я полностью знаю, как формировать структуру данных для алгоритма хеширования. Только что я удалил ту часть статьи, о которой упоминал выше, время было потрачено впустую на никому не нужный анализ ПО, горящая жопа была потушена дизморалью (рекомендую), настроение ниже плинтуса.
Благодарю за внимание, знаю, что читать длиннопосты сложно. Я стараюсь сжимать инфу. Чуточку доброты не помешает никому.
Предыдущая часть: Сказ о том, как Рыцарь свежего смог достучаться до самого сердечка ИЛИ ищем API Пикабу
Сразу хочу поблагодарить комментаторов в предыдущем посте за проявленный к теме интерес, за вопросы и за предложения. Ознакомившись с комментариями (целых 14 штук, чуть не надорвался!), я решил написать этот промежуточный пост и разобрать альтернативные пути дальнейших действий.
Итак, прошлый пост закончился на том, что я успешно перехватил трафик с приложения Пикабу для Android, увидел волшебную ссылку https://api.pikabu.ru/v1 и определил, что обмен данными производится по JSON (логично). Но пикабушники не были бы пикабушниками, если бы обошлись без подколов в комментах. Люблю вас, честно.
Проблема в том, что в обнаруженном API мог оказаться вообще любой формат - JSON, XML, YAML или, прости хоспаде, голый HTML. И я покажу HTML внутри ответа от сервера в формате JSON чуть далее. Морально я был готов увидеть в протоколе вообще всё, что угодно, но это оказался JSON, чему я был несказанно рад, так как лично мне с ним работать много проще, чем с тем же XML, да и читать его в сыром виде приятнее, чего греха таить. В качестве особого извращения, можно возвращать результат в виде base64(zlib(protobuf())). Упаковка и распаковка ляжет целиком на плечи серверов и клиентов, зато, с высокой долей вероятности, будут пересылаться меньшие пакеты данных, что актуально для спутникового интернета где-нибудь у черта на куличиках.
Ладно, не буду превращать пост в ответы на комментарии, я только один раз, всего лишь на пол шишечки <3
В комментариях пользователи также предложили еще два способа получить данные с сайта для последующей обработки. Рассмотрю их в порядке возрастания интереса лично для меня.
На данный момент, самый горячий пост - Оскорбил. Его и буду препарировать. Погнали.
Справедливое замечание. Но мне это даже в голову не пришло. Наверняка, это была заводская блокировка, чтобы я не заморачивался всякими анализами HTML. У меня Firefox, поэтому выполню аналогичные действия. Тут это называется "Адаптивный дизайн".
Вероятно, так выглядит Пикабу на iPhone X/XS. Не знаю, не хочу проверять в живую. Открываю devtools (они же инструменты разработчка на F12) и первое, что я вижу - разметка страницы. Допустим. Ищу текст статьи, вот он:
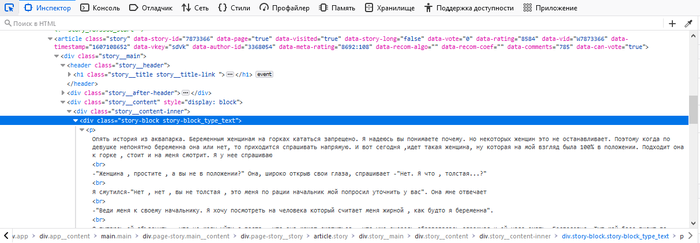
Чтобы до него добраться надо, как я понимаю, найти блок div с классом(-ами?) "story-block story-block_type_text". Но не пинайте строго, я в вебе не особо разбираюсь и сайты ранее не парсил, умею только читать (глазами и головой) разные штуки и анализировать прочитанное. Как по мне, такое название класса не выглядит чем-то фундаментально неизменяемым, но кто его знает, на самом деле. Могу ошибаться, но это, вроде, ссылка на таблицу стилей. Получается, если стилисты поменяют название класса, то парсер посыпется. Неприятно. Однако, хочу заметить, что посыпется любая программа, заточенная под специфическую строку, даже в случае JSON.
Итог - требуется парсер HTML. Конкретно эта страничка весит ~404 кб (для проверки размера я сохранил .html файл на диск и посмотрел его размер). Пока не знаю, много это или мало, разберемся чуть позже.
Та-а-ак, а это уже интересно. Давай попробуем: Оскорбил
{"result":false,"message":"Krasavchik"}
Спасибо, товарищ программист бэкэнда, стараемся! Жаль, что не удалось договориться :) Ответ пришел, тем временем, в JSON. С конкретным постом не прокатило, надо попробовать в общей ленте: https://pikabu.ru/?twitmode=1&of=v2
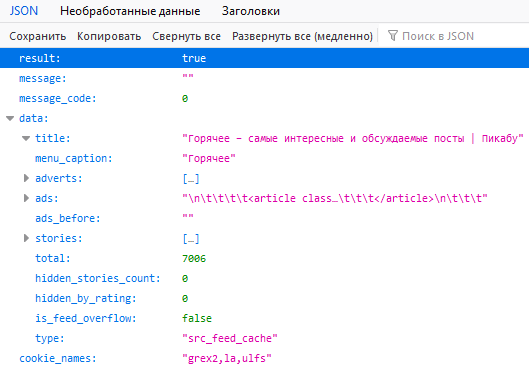

Есть ответ! В JSON! Похоже, загрузилась какая-то часть из 7006 постов в горячем. Есть какая-то реклама (ключ ads), есть какие-то stories (aka посты), поглядим...


Спасибо, Киану. Ты очень точно передал моё выражение лица. Продолжим... Ключ "html", да и содержимое со всякими там div-ами. Да, похоже на правду. Вот только множество переносов строк (\n) и табуляций (\t) напрягает. Ладно, надо найти какой-нибудь html beautifier, чтобы посмотреть на это дело в нормальном виде.
Как обычно, искать лень, а на первом попавшемся сайте по выравниванию HTML эскейп-символы не убираются. Но я же программист C++, я знаю аж 2 способа, как от них избавиться. Их можно заменить в каком-нибудь Notepad++ на пустой символ или просто напечатать все содержимое в программе С++. Программисты С++ не всегда ищут простые пути. Зачастую, лучший путь тот, что занимает меньше кликов :)
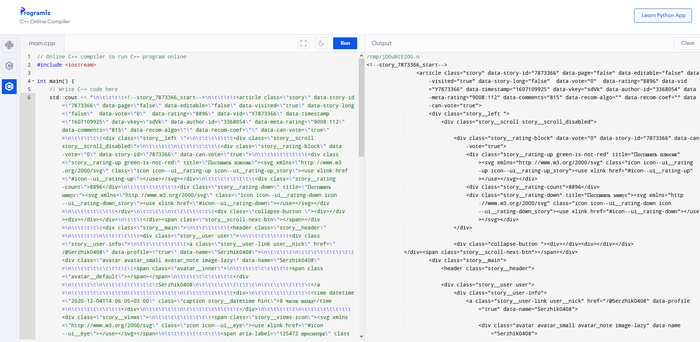
Хорошо, но можно сделать еще лучше.
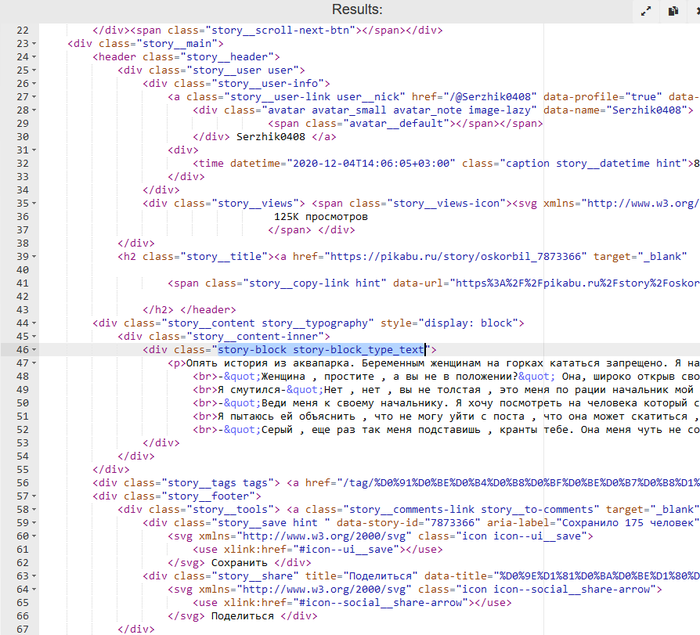
Во, в самый раз. И что же я теперь вижу? То же название класса в теге div, то же содержимое. Дальше углубляться не вижу смысла.
Сразу виден минус этого подхода - предоставленные мне ключи запроса не подошли для получения данных конкретного поста, а было бы хорошо грузить только конкретные посты, а не всю пачку целиком. И еще возникает вопрос о способе получения "среза" постов за определенный период. Думаю, способа запросить у сервера список допустимых ключей для запроса нет, ну да ладно. Требуется два инструмента - парсер для JSON и парсер HTML. Размер - ~156 кб, но это не один пост, а целая пачка с главной страницы. Требование двух инструментов не является таким критичным, как невозможность использовать этот способ при загрузке конкретно одного поста.
Итого, если очень хочется парсить HTML, то первый способ с готовой страницей все-таки более гибкий, чем этот, но там наверняка всплывут какие-нибудь проблемы с определением номера поста из пачки загруженных. Сомневаюсь. Короче, хочу перейти к разбору третьего способа, уже и колется, и чешется узнать, какие там получатся результаты.
Третий способ - воспользоваться API мобильного приложения. Поехали.
Я буду пользоваться всё тем же mitmproxy и эмулятором с установленным пропатченным приложением Пикабу, хотя и ознакомлюсь с питоновскими библиотеками, предложенными в комментариях, чуть позже. Открываю через приложение страничку горячего. Запрос:
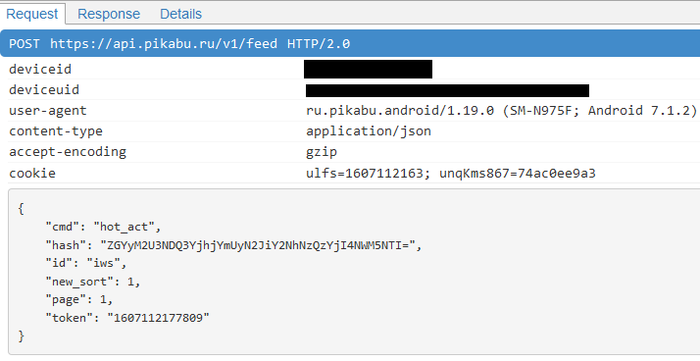
Щьёрт побьери! Пока писал пост, горячее обновилось и сравнить размеры не получится. Вижу номер запроса страницы. Хорошо. Ответ:

Содержимое ответа скрыто, поэтому предлагаю поверить мне на слово, что там JSON :) Никакой пользы этот скриншот, кроме размера в 241.9 кб в рамках текущего разбора не несет, но почему бы и нет? Интернет не казенный, так что расчехляйте свои байты, гулять так гулять! А, вы уже?...
Но теперь-то появилась возможность проверить страничку тестового поста! Ищу пост по имени пользователя за последние сутки, нахожу и открываю его. Приложение генерирует следующий запрос:

Вах, целочисленный story_id, по которому можно просто в цикле грузить посты с Пикабу. Супер. Страница номер 1? Комментарии? В ответе пришла вся информация по посту, включая какой-то список комментариев, возможно полный. Приведу наиболее интересную часть ответа:

story_data - список блоков поста, в нашем случае, один блок типа "t" (text), но который содержит какие-то теги HTML. Вполне возможно, тут же будет присутствовать и форматирование, и ссылки, но с этим буду разбираться потом. Также, тут присутствует полный URL на пост. Я не знаю, возможно ли осуществлять переход по конкретным постам в десктопной/мобильной версии, имея на руках только номер поста, но тут есть полная ссылка, что, определенно, плюс. Хотя я бы возвращал только относительный путь к посту, независимо от домена, а сам домен настраивал в момент первого включения приложения или периодически возвращал бы его в процессе обновления ленты. Короче, я бы не стал отправлять его постоянно, только время от времени. Мало ли... Есть также информация о пользователе - его идентификатор в БД, ник и ссылка на профиль. Ну и был обнаружен интересный ключ sber_donation_url, но тут и так всё понятно :)
К этому моменту каждый уже мог сделать для себя выводы о плюсах и минусах, но для адептов ЛЛ я их все-таки сформулирую, я про вас помню, ребятки.
Плюсы - можно грузить что угодно, в каком угодно порядке и в любое время. Все эксперименты проводились на приложении без аккаунта :) Нужен один инструмент для работы с JSON. Данные приходят в подготовленном для обработки виде, удобнее не придумаешь. Размеры пакетов.... Ну хз, где-то может быть больше, где-то меньше. В готовой странице можно оставлять только необходимые для работы данные/ссылки, тут же прилетает куча дополнительной информации (количество плюсов и минусов для самостоятельного подсчета соотношения, например), многое дублируется. Я бы добавил в запрос еще ключ типа verbose, и если false - то присылать только то, что необходимо для отображения по минимуму, без комментариев. Короче, тут есть простор для воображения.
Минус я вижу только один - нужно исследовать алгоритм авторизации приложения и расколоть формат запросов (есть там один противный hash, пока не ясно, от чего он считается). К каждому запросу (кроме двух первых) прикрепляется два каких-то неопознанных идентификатора. Один из них - deviceuid, и вполне может оказаться, что он не просто сгенерирован на устройстве один раз. Есть подозрение, что придется изрядно помучаться, прежде чем получится эмулировать процесс получения данных по этому способу.
Для себя я сделал выбор - буду продолжать намеченный курс и исследовать приватный API приложения Пикабу. Мне он кажется наиболее гибким и наиболее простым в починке, в случае, если что-то поломается.
Это должен был быть маленький оффтоп-пост, я не хотел, честно! Благодарю за внимание, мне приятно, что вы проявляете интерес к моему творчеству. Будьте чуточку добрее, мы тоже люди.


Около 3 месяцев назад я уже писал статью про это приложение, тогда это были еще первые наброски без четкой структуры и с крайне ограниченным функционалом. У приложения было всего 7 методов. Что ж в сегодняшнем релизе их уже 28.
С тех пор функционал сильно расширился, теперь в приложении есть методы для работы с файлами и папками, что собственно говоря было и тогда, но появилась возможность использования его как полноценной базы данных, создание коллекций и реализации CRUD. А также были добавлены методы для хранение файлов без обработки, что то вроде storage.
Сразу оговорюсь, что данная статья является лишь обзором, но не как не документацией. Так если надумаете попробовать приложение вам все же придется ее почитать.
Теперь более детально.
За основу приложения был взят npm модуль fs. Так что если приложение вернуло вам ошибку, то то что было в блоке error нужно гуглить в контексте модуля fs, а не Gh-database или ghc-db.
Приложение написано на nodejs, то бишь это обычный сервер к которому можно обращаться посредством POST запросов. Подробнее о них можно почитать в документации: https://github.com/GreenHouseControllers/GH-database
Для удобной работой с приложением был написан npm модуль - ghc-db. Думаю не стоит останавливаться на том что такое npm модули, как их устанавливать и так далие.
Прежде чем работать с приложением нужно сделать коннект с ним. Для этого есть метод connect, в него вы должны передать токен. Токен вы задаете в файле config в файлах Gh-database. Подробнее об этом читайте в документации.
Для работы с файлами есть:
createDir/removeDir - для создания/удаления папок и createFile/removeFile - соответственно для файлов.
readFile/writeFile - для чтения/записи файлов.
rename - для переименования файлов и папок.
Для работы с файлами имеющими расширение .json, есть отдельный набор методов
readJson/writeJson - для чтения записи файлов.
getElement - возвращает ответ по ключу.
pushElement/deleteElement - для добавления и удаления элемента в массиве.
Немного о функционале базы данных
Для создание и удаления коллекций используются методы createCollection и removeCollection соответственно.
Имеются методы для CRUD, по аналогии с MongoDB, но метод read возвращает всю коллекцию. Для получения одного объекта по параметрам есть метод get.
Так же вы можете переименовывать коллекцию с помощью метода renameCollection
Функционал файлового хранилища реализован в трех методах:
upload - для загрузки файлов
remove - для удаления файлов
download - для скачивания файлов
Обращение к файлам происходит по тому имени с которым он был загружен.
Для того чтобы получить токен, можно воспользоваться методом login. Но чтобы создать пользователя нужно использовать метод register, для которого уже нужен токен.
Также среди методов админа есть метод getErrorLog, который возвращает полный массив объектов с ошибками в формате json.
Данная версия еще все же сырая. Но я рад буду если вы заинтересуетесь данным приложением. Жду конструктивной критики, предложений, переделок, багов.
Будем рады если вы напишите простые примеры с использованием приложения и модуля ghc-db. Присылайте их в комментариях к статье и в телеграм, Вы можете перейти в группу в телеграмме где можете высказать свое мнение, предложить собственные идеи, поделится чем то новым. Сообщения касательно Gh-database присылайте с #ghDb в начале сообщения.
Ссылка на группу: https://t.me/joinchat/LvAn_FR2r9crJGKqP_aYYA
Справились? Тогда попробуйте пройти нашу новую игру на внимательность. Приз — награда в профиль на Пикабу: https://pikabu.ru/link/-oD8sjtmAi







