
0 просмотренных постов скрыто



Пояснительная бригада: что-то пошло не по плану

Поясняет редакция «Кода»:
На картинке — вымышленная ситуация, которая произошла у молодой пары (если что, даже в этой вымышленной ситуации всё по взаимному согласию и без домашнего насилия, это мы осуждаем).
Девушка предлагает парню её связать и делать всё, что он хочет, очевидно намекая на более интимное продолжение вечера. Но мы сразу понимаем, что парень — настоящий программист: ему сказали, что можно связать и делать то, что он хочет, значит, можно действительно всё.
Дальше мы видим связанную девушку, огорчённо лежащую на кровати, а парня — увлечённо сидящего за компьютером с лого дистрибутива Arch Linux. Судя по всему, парню нужна настоящая жесть и хардкор, поэтому он решил поставить дистрибутив, в котором:
Всё нужно делать самому (иногда даже писать свои драйверы).
То, что не получается сделать самому, нужно выяснять на форумах, пробовать, делать, сносить систему, ставить снова, пробовать,
вырезано цензуройи так по кругу.Следить за всеми зависимостями, ставить несколько разных версий одной и той же библиотеки, чтобы разный нужный софт хоть как-то запустился. И это только в первый день…
И это лучше делать через командную строку (что парень и делает).
Но при этом Arch прекрасен, потому что это действительно один из самых независимых и гибких дистрибутивов.
Главное, не говорить ему про Gentoo. После этого вязать придётся уже самого парня.
Показать полностью
1


Делаю игру на Unity3d. Эпизод 7: Дерево поведения
Здравствуйте, дорогие Пикабушники и Пикабушницы!
Сегодня мы посмотрим, как выглядит дерево поведения!

Ведь посмотрим, да?
Использование дерева поведения требует прикрепления к игровому объекту специального компонента - BehaviourTreeComponent.
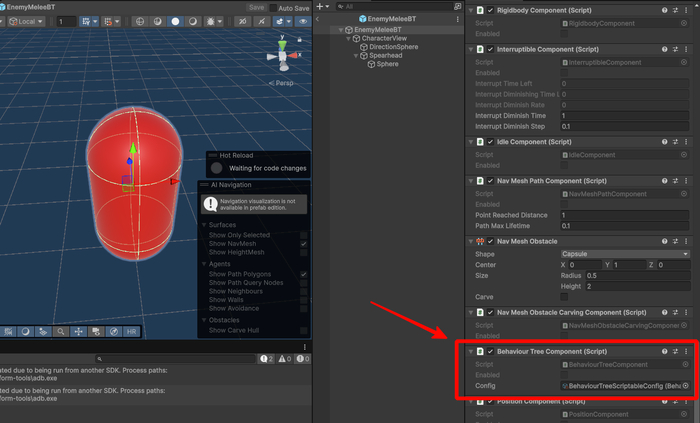
Ничего лишнего
В компоненте указывается только конфиг с настройками дерева. Конфиг у нас в виде ScriptableObject и настройки всех нод дерева тоже выполнены в виде ScriptableObject, но уже вложенных.
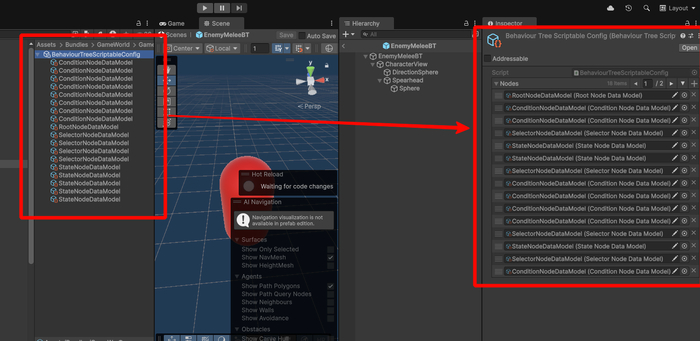
Двойным кликом по конфигу открываем его редактор. В левой части располагается инспектор, в котором будут отображаться параметры узлов. А в правой части поле для визуального редактирования дерева через graph api.
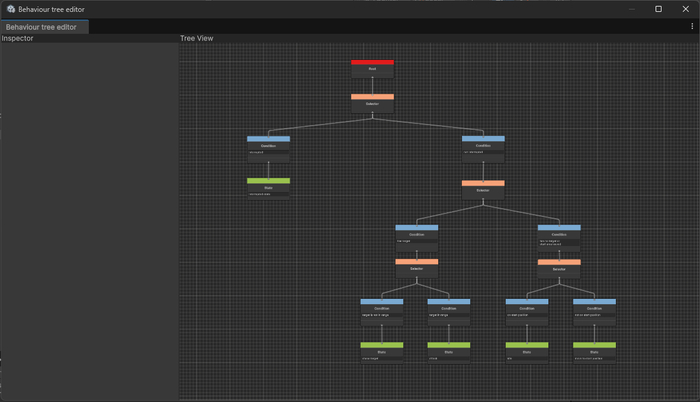
Есть несколько типов нод - корневая, составная (параллельная, выборочная, последовательная), условная и действие (состояние). Все выделено особым цветом для удобства. При клике на ноду видим ее параметры.
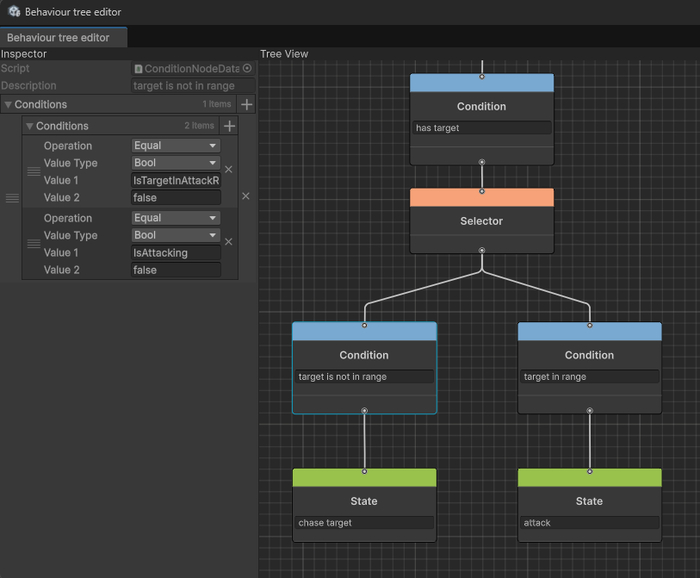
Красота!
Присутствует режим отладки, когда в рантайме дерево подсвечивает активные узлы для конкретного объекта.
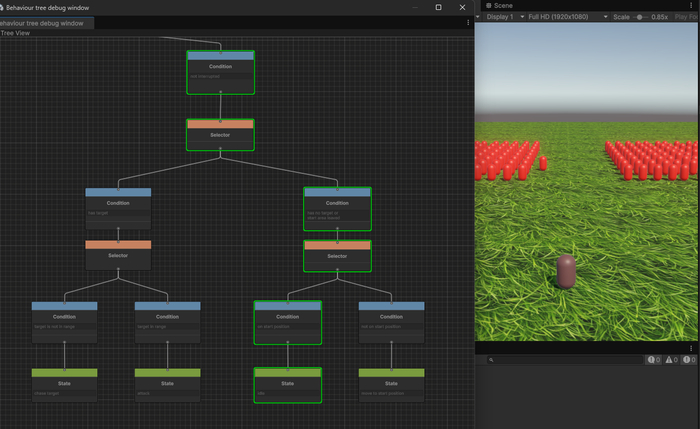
Зеленым выделены активные узлы
Система получилось достаточно гибкая и легкая. 500 юнитов с деревьями поведения кушают 2-3 мс процессорного времени. У меня в игре не будет замесов между армиями, состоящими из сотен юнитов, плюс будут дальнейшие оптимизации при масштабировании, так что определенный запас производительности я себе обеспечил.
Подробности, как всегда, в полном видео на моем канале
А потом приглашаю в комментарии - задавайте вопросы по видео и просто по юнити!
Приятного просмотра!
Показать полностью
6
1
Пояснительная бригада: микросервисы

«Теперь при помощи контейнеров можно решить проблемы, которых не было до появления контейнеров»
В Великобритании по историческим причинам очень много где используются не смесители, а два отдельных крана. Весь остальной мир гадает, как же они в итоге пользуются этими кранами. Самый рабочий вариант для нас, кто привык к смесителям, — быстро-быстро подставляют руки под одну и под другую струю.
Так вот, микросервисы — это такие отдельные сервисы в общем приложении. Но встаёт вопрос: а как их объединить? Примерно как в британской ванной: давайте быстро-быстро опрашивать то один, то другой сервис.
— Паша Вавилин, наставник на курсе по Python
Показать полностью
1
Пояснительная бригада: стоимость обращения
Поясняет Паша Вавилин, наставник на курсе по Python:
Есть такое понятие — время ответа (или «стоимость обращения»). Оно означает, сколько времени нужно системе, чтобы выдать ответ на запрос. Это время может значительно различаться.
Например, получить данные по сети или прочитать с диска будет гораздо дольше, чем если эти данные уже лежат в оперативной памяти компьютера. Но по меркам процессора поиск по индексу в оперативной памяти и чтение из оперативной памяти — это тоже довольно долго.
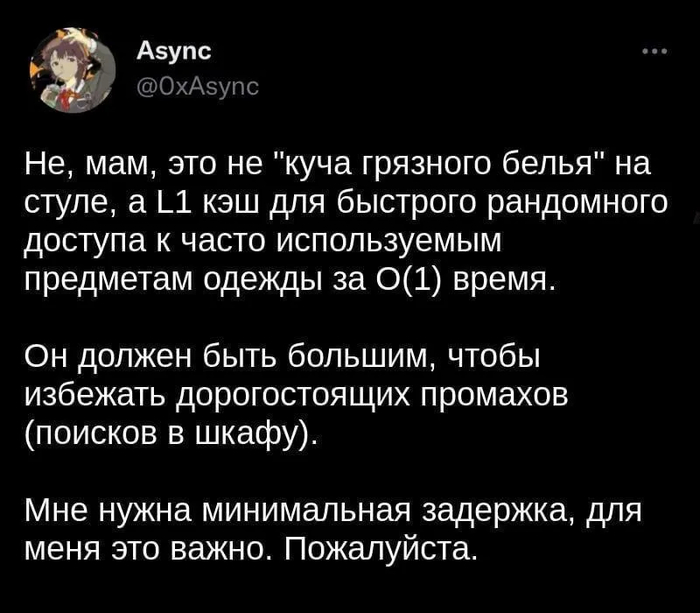
Поэтому придумали несколько кешей в самом процессоре: это такие небольшие участки памяти для максимально быстрого доступа к данным. В эти кеши попадают не всякие данные, а только те, которые наиболее часто используются. Расчёт на то, что если мы уже раз 10 запросили какие-то данные, то, наверное, эти данные мы запросим и далее несколько раз. А ещё можно указывать компилятору, что эти такие-то данные лучше положить в кеш, но компилятор не обязан это делать, а только примет к сведению.
А вот обычные человеки не такие продуманные, как инженеры процессоров. Особенно мамы! Зачем-то они заставляют всё раскладывать по ящикам и шкафам, в итоге тратится уйма времени на доступ к ним. Например, на поиск футболки уйдёт 15 секунд, ещё 15 — штаны, ещё 15 — носки, ещё 15 — трусы (порядок может быть иным). В итоге минута ушла только на поиск и «загрузку» одежды. А это ещё надо будет уложить обратно. То есть в день 2 минуты уходит на загрузку-выгрузку. В неделю 14–15 минут. В месяц целый час!!!
Показать полностью
1
Пояснительная бригада: мем про данные

Комментирует Лёша Эльнатанов, наставник на курсе по Python:
«Утечка данных обычно происходит неожиданно для разработчиков, в результате чего данные становятся доступны снаружи, разлетаясь по сети.
При децентрализованном бэкапе данные тоже дублируются в нескольких разных узлах, но это происходит в пределах сети организации и под защитой системы контроля доступа».
Ну, а юмор сами разгадайте :-)
Показать полностью
1
Пояснительная бригада: мем про скорость кода на C

Поясняет Паша Вавилин, наставник на курсе Python:
«Как я понимаю, юмор в том, что плохо написанный код на C будет не быстрее, чем код на Python. В последнем кадре первый персонаж понимает, что его код, получается, плохой»
И добавляет редакция «Кода»:
Это правда, что один и тот же набор команд на C исполнится быстрее, чем на Python, — хотя бы потому, что код на C компилируется под процессор, а на Python проходит дополнительный слой интерпретации и преобразований. Но это касается сравнения одинаковых операций в двух языках.
Само приложение на C и Python можно написать как угодно. Можно использовать неоптимальные алгоритмы, брутфорсить решение тупым перебором, заставлять компьютер вхолостую считать всякую ненужную ерунду. А, например, все эти задачи внутри Python уже решены готовыми библиотеками, где умные люди уже всё оптимизировали.
И в итоге да, код на C исполняется быстрее. Но самого кода может быть настолько больше и он может быть настолько более сложным, что в итоге приложение на Python работает лучше.
Показать полностью
1