

Ответственно подошли к списку..

Показать полностью
1
Классификатор средств массовой информации. В него вошли 100 изданий — это самые читаемые ресурсы с федеральным охватом, разделенные на несколько категорий.


Если узнали себя можете не признаваться. ))

1) Очень боится вампиров поэтому ест чеснок килограммами, желательно с луком и бобовыми.
2) Боится смыть с себя священные воды где крестился, поэтому не моется.
3) Не знаком с благом цивилизации, поэтому орёт в трубку телефона, а не пишет смс или пользуется гарнитурой.
Особо отбитые включают на телефоне динамик.
4) Свистит, пердит, рыгает, шмыгает, кряхтит, цокает, сопит, рычит и издаёт серию не поддающихся описанию звуков.
5) Залезает в центр маршрутки, избивая всех и вся. На следующей остановке выходит.
6) Запихивает деньги в самый дальний карман своих необъятных одеяний. Всю поездку раскидывает в радиусе 3х метров все живое пока пытается достать деньги.
7) Часто встречается мобильная пивнушка и не понятно где пива больше, снаружи или уже внутри.
8) В час пик ехать на рынок? Он откроется только через 1.5 часа? Я вас умоляю!
9) Смотреть смишнявые ролики на полную громкость? Спасибо тебе за тонну бородатых шуток про жопу.
10) Тормознутый тормоз, вставший у выхода, косплеящий Гендальфа.

Дверь в кабинет начальника.
Одна вакансия, два кандидата. Сможете выбрать лучшего? И так пять раз.
Некоторые пользователи не особо жалуют использование макросов в Excel, поэтому предлагаю рассмотреть сравнение двух списков с помощью условного форматирования и формул.
Допустим, что у нас имеется два списка с повторяющимися словами:
Самый быстрый и лёгкий способ найти отличия в двух таблицах – это применить условное форматирование. Итак, выделяем оба диапазона удерживая клавишу «Ctrl» и на вкладке Главная – Условное форматирование – Правила выделения ячеек – Повторяющиеся значения выбираем опцию "Уникальные", в результате Excel подсветит все ячейки, где нет повторов. Выбрав вариант "Повторяющиеся", будут выделены совпадения:

Таким способом можно применить оба правила одновременно.
Положительное свойство заключается в простоте и наглядности. Отрицательным – совпадения/отличия просто подсвечиваются и всё, поэтому для полного эффекта сравнения необходимо использовать формулы. Рассмотрим следующие примеры.
Чтобы получить отличия отдельным списком я пошагово покажу процесс создания такого списка. Для этого вводим в соседней ячейке D2 формулу =ЕСЛИ(СЧЁТЕСЛИ($A$2:$A$9;C2)=0;СТРОКА(C2)) которая будет проверять количество вхождений с помощью функции СЧЁТЕСЛИ и если оно равно 0, то выводить номер строки для текущего элемента функцией СТРОКА.
Для того, чтобы номер ячейки стал абсолютным, т.е. со знаком $, нужно в строке формулы навести курсор на номер и нажать F4.

Дальше в ячейке F2 используем формулу СТРОКА(F1)
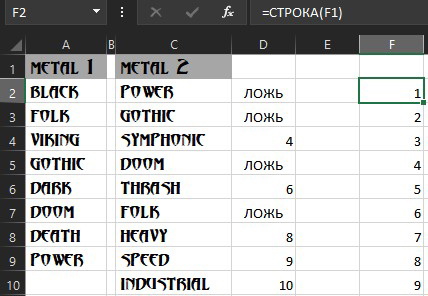
Затем в ячейку G2 вводим формулу =НАИМЕНЬШИЙ($D$2:$D$10;F2) которая выведет последовательно номера строк от меньшего к большему:
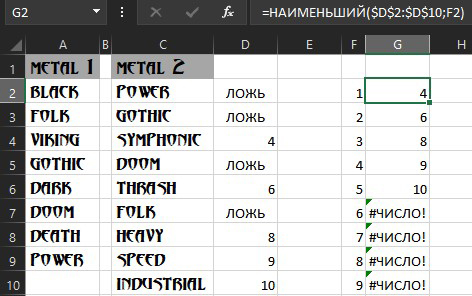
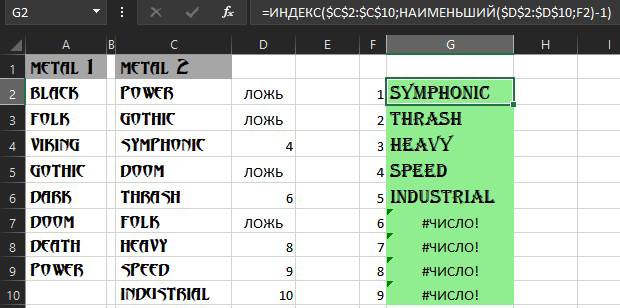
Так мы получили номера строк отличающихся элементов второго списка от первого. Чтобы извлечь их самих, используем формулу
=ИНДЕКС($C$2:$C$10;НАИМЕНЬШИЙ($D$2:$D$10;F2)-1)
которая показывает значение из массива-столбца по порядковому номеру:
Теперь, чтобы избавиться от вспомогательного столбца, вместо диапазона D2:D10 вставим в нашу формулу логическую проверку количества вхождений с помощью функций ЕСЛИ и СЧЁТЕСЛИ, которую мы применили в самом начале:
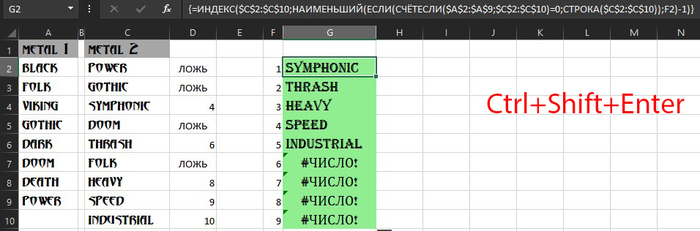
Вводим формулу =ИНДЕКС($C$2:$C$10;НАИМЕНЬШИЙ(ЕСЛИ(СЧЁТЕСЛИ($A$2:$A$9;$C$2:$C$10)=0;СТРОКА($C$2:$C$10));F2)-1) Чтобы формула массива заработала нажимаем сочетания клавиш Ctrl+Shift+Enter и протягиваем формулу вниз. После этого столбец D можно удалить.
Добавим красоты спрятав ошибку #ЧИСЛО!, возникающие в избыточных ячейках. Добавляем к формуле функцию =ЕСЛИОШИБКА, получается:
=ЕСЛИОШИБКА(ИНДЕКС($C$2:$C$10;НАИМЕНЬШИЙ(ЕСЛИ(СЧЁТЕСЛИ($A$2:$A$9;$C$2:$C$10)=0;СТРОКА($C$2:$C$10));F10)-1);)
Убираем нули в Файл – Параметры – Дополнительно – Показывать нули… и получаем результат
Заменив цифру 0 на 1, мы получим общие значения в списках
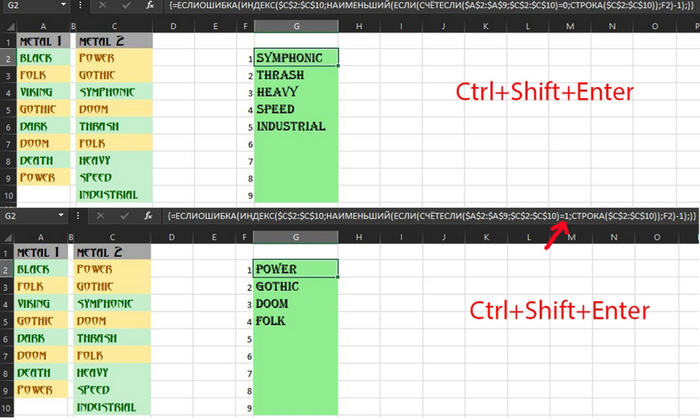
Для поиска совпадений в трёх и более списках проделаем следующее.
Сначала озаглавим наши списки, чтобы использовать их в формулах. Для этого выделим оба диапазона вместе с названиями, удерживая клавишу «Ctrl» и на вкладке Формулы – Создать из выделенного в открывшемся окне включим галочку «в строке выше» и жмём ОК:
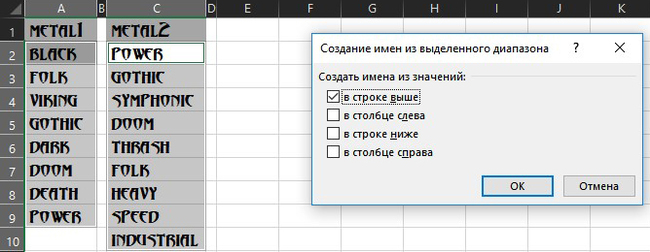
Excel даст нашим спискам имена, взяв их из первых строк выделенных диапазонов, т.е. Metal1 и Metal2. Проверить именованные диапазоны можно на вкладке Формулы - Диспетчер имён:
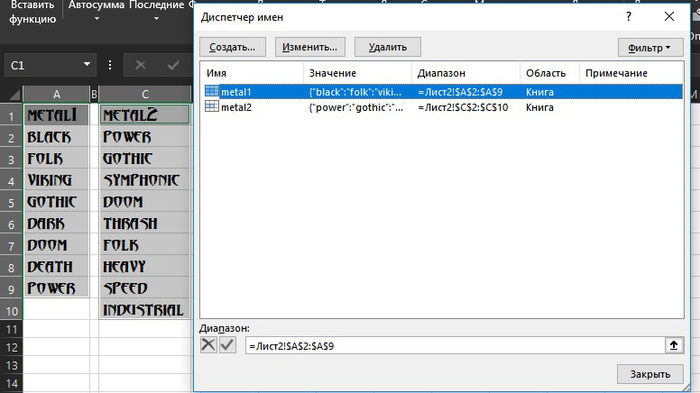
Здесь же можно впоследствии подкорректировать и размеры диапазонов, если количество элементов в списках будет меняться.
Нужная нам формула для поиска и вывода общих элементов в этих двух списках будет выглядеть следующим образом:
=ИНДЕКС(metal1;ПОИСКПОЗ(1;СЧЁТЕСЛИ(metal2;metal1)*НЕ(СЧЁТЕСЛИ($H$1:H1;metal1));0))
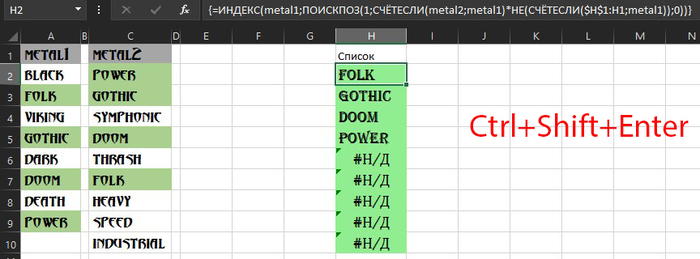
Плюсом является то, что при увеличении количества списков достаточно будет добавить ещё один именованный диапазон (Metal3) и множитель в нашу формулу-массив проверки совпадений с помощью ещё одной функции СЧЁТЕСЛИ:
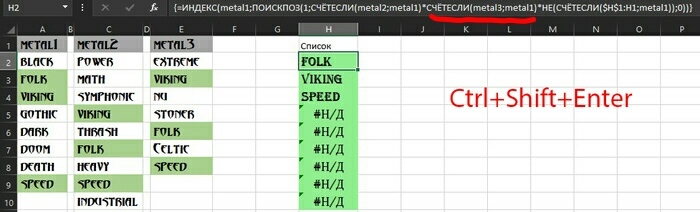
В общем списке будут указаны только те значения, которые являются общими во всех трёх списках, при удалении одного элемента из списка, в общем списке он также исчезнет.
Данные примеры не конфликтуют с пустыми ячейками. Формулы на вид кажутся сложными, но всё выполнимо. Можно создать один шаблон с большим диапазоном ячеек и в последующем вставлять в него необходимые списки для проверки.









