

Получение адреса по координатам с помощью Python
Получение адреса по координатам, довольно полезная функция, которую можно использовать в различных целях. Например, вам скинули геолокацию. Можно сделать телеграм-бота, отправить ему полученные данные и в ответ получить адрес. Данный функционал можно реализовать на Python. Давайте посмотрим, как это можно сделать.
Для получения адреса по геолокации будем использовать библиотеку geopy. В ней реализованы классы для работы с сервисами геокодирования, такими как OpenStreetMap Nominatim, Google Geocoding API (V3) и многими другими. В нашем коде мы будем использовать OpenStreetMap, так как его использование бесплатно и не требует получения дополнительных ключей.
Установка библиотеки
Для установки библиотеки пишем в терминале команду:
pip install geopy
Импорт модулей в скрипт
После того, как библиотека будет установлена, необходимо импортировать модули для работы с ней в скрипт. Пишем следующий код:

Получаем адрес по координатам. Обратное геокодирование
Создадим функцию get_addr(location: list) -> str, которая на входе получаем широту и долготу в виде списка, а возвращает адрес в виде строки. В случае ошибки будет возвращен текст «Unknown».

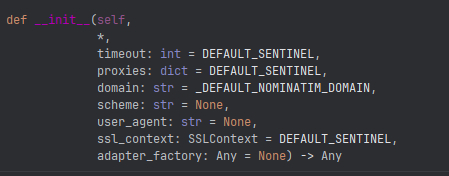
После этого инициализируем класс Nominatim и передаем в него user_agent. Здесь использование какого-то специализированного агента не принципиально и можно просто передать «GetLoc». Если мы заглянем в параметры данного класса, то увидим, что в него, кроме user_agent можно передать таймаут, прокси и еще множество других параметров, которые в данном случае не принципиальны.
Обратимся к инициализированному классу и его методу reverse, в который передадим координаты в виде списка с широтой и долготой. В ответ мы получим адрес, который и возвратим из функции, обратившись к методу address.
Запрос координат у пользователя. Вывод полученного адреса в терминал
Создадим функцию main(), в которой будем запрашивать широту и долготу у пользователя. После передадим их в функцию get_addr и выведем полученный результат в терминал. Здесь необходимо немного обработать полученные данные, так как они возвращаются в обратном порядке, начиная с номера дома и заканчивая страной. Поэтому, добавлена обратная сортировка, разбиение строки по запятой в список и обратное его объединение.
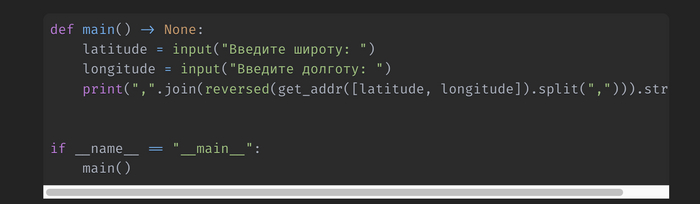
Тестирование функции
Протестируем написанный код. Возьмем произвольные координаты объекта с Яндекс.Карты и введем в запросе скрипта. В ответе мы видим полученный адрес, который совпадает с тем, что указан на Картах.

Итог:
Как видим, с помощью использования сторонней библиотеки получить адрес по координатам не такая уж сложная задача. К слову, возникновение исключений, когда адрес не был найден, происходит достаточно редко. В большинстве случаев все отрабатывает корректно.
Показать полностью
6

Что нужно для хорошей работы программиста:
Показать полностью
1

Этика в сфере ИИ или новые вызовы человечеству в XXI веке

Тема этики — одна из самых спорных тем в принципе.
Мы не стали акцентировать внимание на популярных проблемах, связанных с deepfake, безопасностью данных или использованием ИИ преступниками и хакерами. Вместо этого мы решили затронуть перспективы развития искусственного интеллекта.
Как научить морали сильный искусственный интеллект?
Как избежать использования человека как средства?
Как сделать ИИ безопасным (и использовать его в военных целях)?
Все эти вопросы так или иначе уже стоят или будут стоять перед разработчиками и государствами в течение следующих несколько лет. Мы специально не ориентировались на техническую часть вопроса, сколько максимально сущностную (фундаментальную) — ведь в ней и скрывается вектор решения.
Сильный искусственный интеллект и Super AI: новый человек или сверхмашина?
AGI или artificial general (общий) intellegence — интеллект, очень похожий на человека, владеющий всеми человеческими интеллектуальными навыками и обладающий соответственно автономией.
И это не говоря уже о Super AI, которое бы превосходило человеческие возможности (речь, например о «Демоне Лапласа», способного вычислить все положения частиц во вселенной и предсказать будущее утрированно). Такое ИИ способно гипотетически решать сложнейшие задачи в перспективе малого количества времени, в том числе и обхода собственного контроля.
Уже на протяжении 50-ти лет с появлением первых компьютеров на машинном коде, ученые/философы начали активное обсуждение вообще фундаментального устройства человеческого мозга и возможности его воссоздания на уровне машины.
В общем и целом, сегодня существуют три доминирующих мировоззрения в этом вопросе: материализм/физикализм (сознание = физ. процессы), функционализм (сознание как результат вычислительных процессов), эмерджентизм (сознание как побочное свойство действия нейронов).
И в самом деле, все сводится к: можно ли свести мозг к математическим абстракциям, логическим выражениям и вообще бинарным структурам, чтобы воспроизвести через нейронные сети?
Но в самом деле, для самой этики это не столь важно. Ведь если понимать AGI как сильный искусственный интеллект широкого назначения и автономии, то достаточно попросту наличия хоть какой-то автономии.
Существует такой популярный эксперимент «Китайская комната», который постулирует: любой алгоритм, обладая набором инструкций (те же распределенные веса связи слов в моделях LLM) может имитировать «понимание» вопросов.
В представленной ситуации воображаемой Китайской комнаты человек, не знающий китайского языка, находится внутри и обрабатывает входящие китайские символы согласно инструкциям, так же на китайском. Несмотря на способность обработки символов и генерации ответов, человек в комнате фактически не понимает языка, который он использует для взаимодействия с внешним миром.
И поэтому мы никогда не сможем по речевому поведению усмотреть ментальный, обязательный феномен человеческого сознания как «понимание» или «осмысление».
Самый пока что прямолинейный подход в воссоздании человеческого интеллекта наблюдается в методе «Emergence», на нем основан, кстати, проект OpenAI, показывающий впечатляющие результаты.
То же самое можно сказать о недавно запущенном суперкомпьютере, о котором мы писали в одном из постов. Впрочем, такой подход действительно показывает некоторые результаты: например, набор «нейронов» может генерировать подобие когнитивных карт ориентации в пространстве.
Но в самом деле такой подход вообще не контролируем, ведь он никак не регулируется и зависит, скорее, от скармливаемых данных. Хотя на это и делаются ставки. Вместо того чтобы архитектурно стремиться разработке AGI, создаются условия для его возникновения.
В контексте нейронных сетей, подход «emergent» означает, что сложные характеристики или поведенческие особенности модели возникают автоматически в процессе обучения, без явного задания конкретных правил или шаблонов. Это взаимодействие нейронов и слоев сети ведет к формированию эмерджентных свойств, которые могут быть неочевидными при анализе отдельных компонентов.

Множество объектов формирует некоторое “свойство” физического тела. Так, например, молекулы воды формируют волны. А с точки зрения некоторых ученых и философов, сетка нейронов мозга – сознание и когнитивные способности человека.
Вместо того чтобы программировать нейронные сети на выполнение конкретных задач, при использовании подхода «emergent» сеть обучается на данных и адаптируется к условиям задачи. Например, в обучении с подкреплением, где агент взаимодействует с окружающей средой, эмерджентные свойства могут включать в себя развитие стратегий, которые агент самостоятельно вырабатывает в процессе взаимодействия со средой, оптимизируя свою производительность.
Такой подход также может быть связан с использованием нейросетей с большим числом слоев и параметров, где обучение происходит на более высоких уровнях абстракции. Это позволяет модели выявлять сложные закономерности в данных и создавать эмерджентные структуры, которые позволяют эффективно решать поставленные задачи.
Именно поэтому Ник Бостром и Элиэзер Юдковски приводят доводы в пользу деревьев решений (таких, как ID3) против нейронных сетей и генетических алгоритмов, потому что деревья решений подчиняются современным социальным нормам прозрачности и предсказуемости.
Сегодня не существует понимания механизмов формирования абстрактных мировоззрений, убеждений, мотивов и морали в мозгу. А значит предсказаний момента их возникновения при симуляции нейронной сетей мозга быть не может.
Поэтому в точке перехода к AGI, когда возможно возникновение эмерденентных («случайно возникающих») феноменов по типу морали, мы никак не сможем контролировать их содержание.
И в этом и состоит ключевая проблема этики Сильного искусственного интеллекта — нет средств и инструментов, чтобы вшить инструкции, предписания или гуманные мотивации.
Но в самом деле, проблема здесь лежит еще глубже: нечего предписывать. Ибо любое этическое предписание уже предполагает выбора одних ценностей перед другими.
Допустим, практически любое общечеловеческое благо или благо отдельной группы людей зачастую противоречит благу частного лица. Поэтому принципиальный выбор между тем или иным = обязательный ущерб одному из субъектов будь то целый социальный класс или отдельный средний человек.
Нет абсолютно благих принципов этики, как и нет четкой и понятной этической системы, которая могла бы хоть как-то понизить шансы возникновения «неморального» сильного ИИ. И ни говорили некоторые, что отсутствие эмоций у искусственного интеллекта – определенный плюс. Возможно, эмпатичность и распознание человека как «своего» формирует почву для возникновения около-гуманных ценностей.

Хотя печальным примером проявления эмоций может послужить ИИ-ассистент из Космической Одиссеи Кубрика, саботирующий работу пилота корабля.
В этом смысле у GAI две проблемы: в силу популярности «emergence» подхода, направленного на непредсказуемый результат — сама непредсказуемость и невозможность на философском уровне выработки этических правил делает сильный ИИ опасным. С другой стороны, неморальный и гнусный GAI — это не проблема, ведь по своему функционалу он не должен превосходить человека.
Но что насчет Супер искусственного интеллекта, которого так боится Элиезер Юдковский? Проблема в том, что возникновение SAI вероятнее, нежели возникновение GAI, так как оно независимо от человеческих способностей и ориентировано концептуально больше на решение сложных задач (вычислительных).

Примером осмысления синтеза GAI и SAI становится Альт Каннигем, обладающая невероятными «интеллектуальными» способностями и странной антропоморфностью. Мистичность такого создания подчеркивается еще и тем, что сам конструкт обладает непонятной мотивацией.
И так как, опять концептуально, оно является производной Narrow AI (узкоспециализированного искусственного интеллекта), то предполагает предписанную задачу и цель. А возникновение предписанной цели предполагает выборку средств, причем с наличием автономии. И вот автономия может расположить искусственный интеллект, например, к использованию человека как «средства».
Естественно, такая проблема должна решаться моральными предписаниями и готовой «гуманной» мотивацией ИИ. Но здесь мы просим вас вернуться к нескольким абзацам выше.
Narrow AI: слабый искусственный интеллект в военных целях
Если какая-либо крупная военная сила продвигает разработку ИИ-оружия, практически неизбежна глобальная гонка вооружений, и в итоге автономное оружие станет автоматом Калашникова завтрашнего дня.
На самом деле, проблема ИИ в военном секторе не строится по принципу: а вдруг искусственный интеллект уничтожит союзника. Эта проблема решаема, ведь отвечает вполне понимаемым задачам холодного расчета.
Страны активно разрабатывают и внедряют военные технологии на базе искусственного интеллекта в попытке укрепить свое военное превосходство. Это создает геополитическую напряженность и может привести к гонке вооружений в сфере искусственного интеллекта, а значит и к увеличению смертоносности и беспрекословности оружия.

Гонка вооружений в области ИИ может привести к созданию высокоэффективных и автономных систем, что, в свою очередь, повышает риск ошибок, аварий и даже потенциальных кибератак.
К сожалению, практика ведения войн показывает, что международные конвенции нарушаются, а разработка ядерной бомбы, например, образовала новую эпоху в политической жизни всего мира.
С другой стороны, развитие ИИ в военной сфере может привести к невозможности любого вооруженного конфликта либо делегированию вооруженных столкновений беспилотникам. Как ядерная бомба запретила любые войны на уничтожение наций и государств, так и ИИ может запретить «войны», так как будет предполагать автоматическое поражение.
Но войны между равными странами, обладающими искусственным интеллектом в своем вооружении. А что насчет конфликтов между странами третьего мира и высокоразвитыми государствами? Главное отличие ядерного оружия — сдерживающий фактор в крупных войнах (т.к. атомная бомба обладает слепой разрушительной силой). Искусственный интеллект, способный распознавать цели и уничтожать их в частном порядке, дает значительное преимущество на поле боя и не создает эффекта разрушительности.
Подобная ситуация может стать опасной и привести к порабощению или явному политическому давлению со стороны высокоразвитых стран вплоть до экономического паразитизма. Впоследствии развития ИИ в военном секторе может привести к образованию новых военных союзов и коалиций.
Почему перед разработчиками стоят серьезные этические вызовы, которые нужно решать сегодня?
Этика в военных вопросах использования ИИ стоит уже не первый год. Так, например, беспилотники без проблем уничтожали террористические группировки, практически не давая никакого шанса на выживание. Тем более, ООН уже фиксировали уничтожение террористов без использования человека-оператора.
Если говорить об GAI и SAI — здесь вопросы упираются в разработку грамотного этического кодекса и способа контроля «emergent»-подхода, который может привести к необратимым последствиям вплоть до самораспространения нейросети или выбора человека как средства.
И это лишь малая часть этических проблем, которые стоят перед разработчиками ИИ. Не зря последнее время мы слышим много новостей, связанных с этой темой как со стороны крупных корпораций по типу Google и OpenAI, так и государств.
Но, а напоследок советуем посмотреть одно из видео Bostons Dynamics
Если вам было интересно прочитать эту статью (да и в целом интересна сфера айти и всё, что с ней связано), подписывайтесь на наш телеграм-канал. У нас только самые яркие новости из мира айти, куча полезной инфы (бесплатно и без регистрации :D), обзоры на ИИ-стартапы и мемы, конечно, куда ж без них :)
Показать полностью
4
Простой способ извлечения изображений из документов MS и Libre Office
Стандарт Open Document стал де-факто уже давно. И если раньше формат документов Microsoft Office был проприетарным, то теперь он представляет собой «.zip»-файл в котором храниться множество «.xml», а также изображения и прочие файлы. Конечно же, самым простым способом извлечь документы является изменение расширения документа на «.zip» и последующее извлечение файлов любым архиватором. Но, если вам нужно сделать это не с одним документом, это может быть достаточно продолжительно по времени. Поэтому, давайте рассмотрим несколько способов, с помощью которых можно извлечь изображения из файлов формата ".docx", ".xlsx", ".pptx", ".odp", ".ods", ".odt".
Способ №1: используем стандартные библиотеки python
Для данного способа не требуется установка сторонних библиотек. Достаточно тех, что поставляются в комплекте с самим интерпретатором.
Создадим файл extract.py.
Импортируем нужные нам в процессе работы библиотеки:

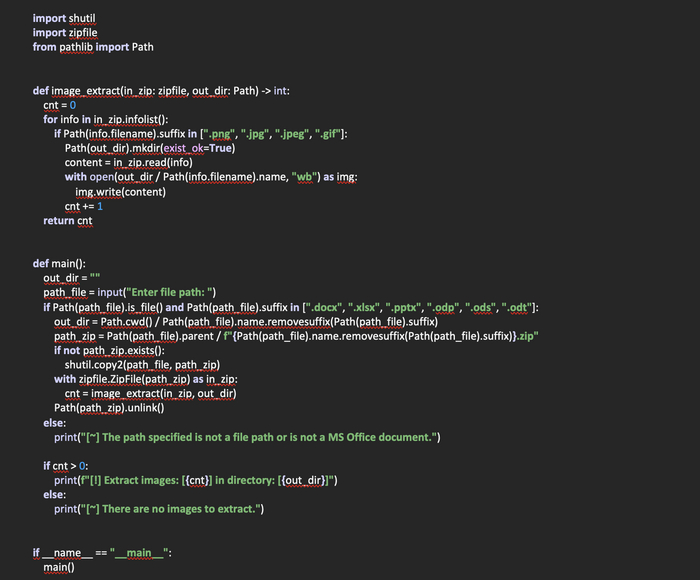
Создадим функцию image_extract(in_zip: zipfile, out_dir: Path), в которую будем передавать zip-файл, а также путь к директории в которую будут распакованы изображения. В данном случае путь у пользователя запрашиваться не будет.
Объявим переменную cnt, которая будет счетчиком распакованных изображений. Затем в цикле пробежимся по списку содержимого архива. Проверим расширения файлов в архиве. И если они совпадают с расширениями из списка, будем читать текущий файл с изображением и сохранять в байтовом режиме в директорию, которая передается в функцию. Также, данная директория создается автоматически и называется именем исходного документа. После того, как все изображения будут сохранены, возвращаем из функции наш счетчик.

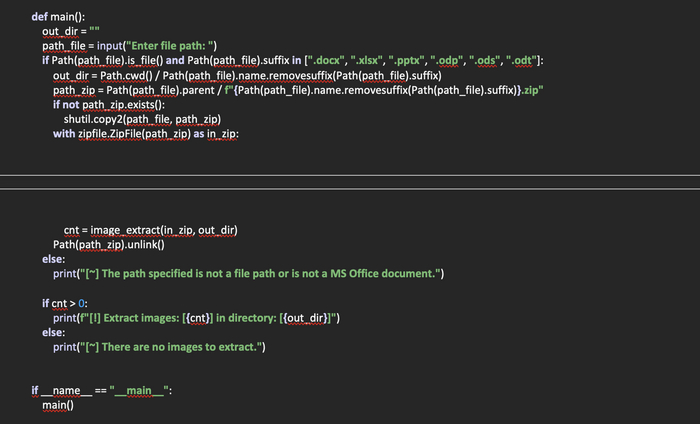
Осталось дело за малым, запросить у пользователя путь к файлу, проверить, является ли он файлом и имеет ли нужный формат. После чего скопировать файл с расширением «.zip», открыть с помощью zipfile и передать в функцию для поиска изображений и их распаковки. Ну и напоследок удалить скопированный zip-файл.
После окончания извлечения изображений вывести сообщение пользователю о том, сколько файлов было извлечено и в какую директорию.
Полный код скрипта:
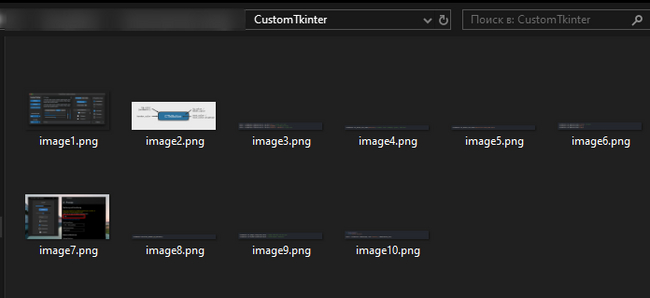
Протестируем созданный скрипт. У нас есть, для примера документ «CustomTkinter.docx». В нем содержаться несколько изображений. Вот их мы и попробуем извлечь.
Запускаем скрипт, указываем путь к документу и получаем папку с названием документа, в которой содержаться изображения.
Способ №2: используем библиотеку docx2txt
Создадим файл docx2im.py. В данном случае мы будем использовать стороннюю библиотеку docx2txt. Для ее установки пишем в терминале или командной строке:

Теперь импортируем нужные библиотеки в скрипт.

В данном случае нам не понадобиться создавать дополнительных функций. Сделаем все в одной. Хотя, в теории, можно было бы разделить извлечение изображений и текста. Да, дополнительным бонусом, при том, что извлекаются изображения только из документов «.docx», является извлечение текста.
Для начала запросим у пользователя путь к документу и путь к папке для извлечения изображений. Проверим, является ли переданный параметр путем к документу и является ли расширение данного документа «.docx». Затем проверим, существует ли директория для извлечения изображений. Если нет, создадим ее, так как docx2txt ее самостоятельно не создает.
Теперь передаем путь к документу и путь для извлечения изображений в функцию process данной библиотеки. Из нее будет возвращен текст документа. Проверим, содержится ли в переменной text что-нибудь. Для этого обрежем пробелы и знаки переноса каретки, так как, если в документе нет текста, но есть пустая строка, переменна text не будет пуста.
Затем открываем текстовый документ на запись и записываем в него полученный текст.

Этот способ достаточно простой, но, как вы уже поняли, извлекать изображения из других форматов документов он не умеет.
Думаю, что вышеприведенных скриптов будет достаточно. Можно использовать также библиотеку aspose-words, которая устанавливается с помощью команды:
pip install aspose-words
Однако, способ извлечения с ее помощью изображений не особо отличается от предыдущих. Создадим файл aspose_extract.py. Вот для примера код:
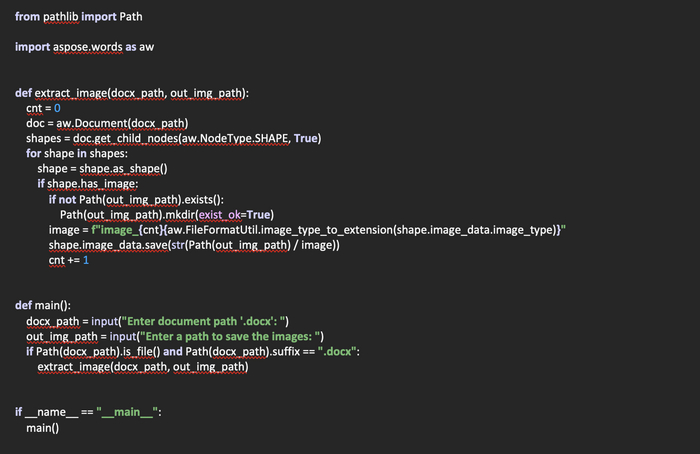
Выбирать, что использовать вам и в каком виде, конечно же, вам. Здесь описаны только несколько способов, с помощью которых можно проделать данную операцию. Скорее всего, если поискать более тщательно, найдется еще множество библиотек, с помощью которых можно извлечь изображения из документов.
А на этом все. Спасибо за внимание.
Надеюсь, данная информация будет вам полезна.
Показать полностью
9