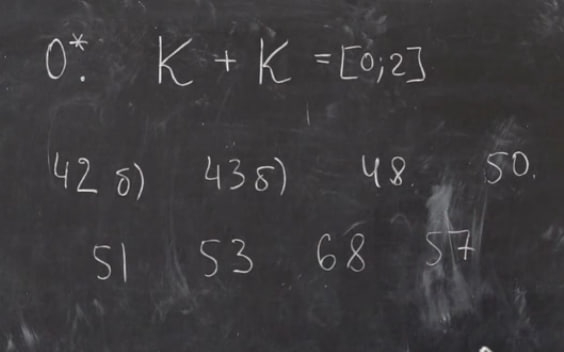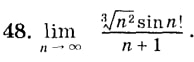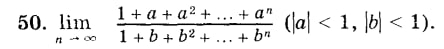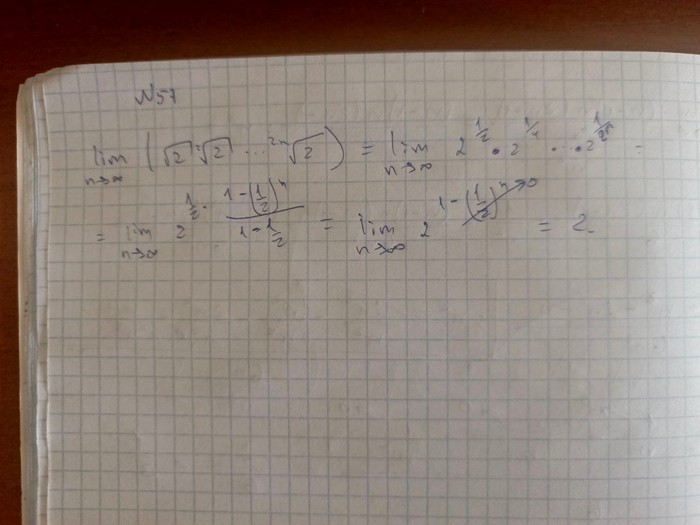Извините что грязно оформил. Потом научусь красиво делать посты))
0* я не стал решать))
Забыл, что препод по семинарам просил 42 б просто предложить выражение, а не решать уравнение, я заколебался с этим выражением
Я думал оно решается очень сложно, но по факту, если разделить на два множителя: 1) кубический корень из n^2 деленную на n+1
2) sin(n!)
Тогда мы сможем легко определить что первая часть стремится к 0, а вторая часть ограничена от -1 до 1. И у нас получается 0 * sin(n!), И ответ 0
Тоже просто решается оказывается. Надо всего лишь записать в виде суммы геом прогрессии, потом уже видно, что b^(n+1) и a^(n+1) стремятся к нулю и у нас полностью иcчезает n.
Номер 53 практически сам решил. По кайфу. Лишь вспомнил о том, чему равна кубическая сумма. Но думаю чем больше я узнаю, тем меньше я буду заглядывать в подсказки.
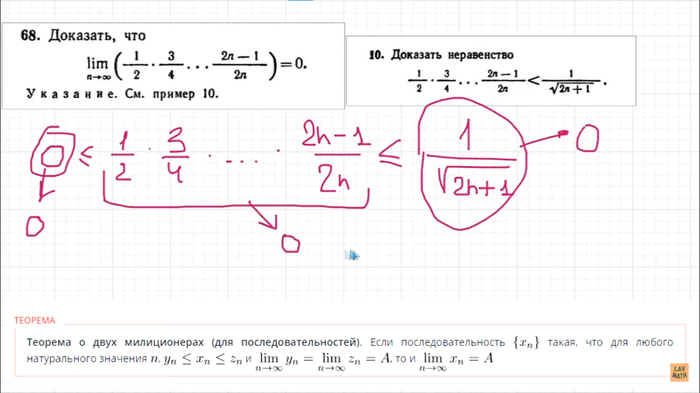
Я конечно понимаю, что в пределе самый крайний член будет равен нулю и тогда все выражение будет равно нулю, так как каждый раз мы берем все меньшую часть единицы, но доказать это прям грамотно не смогу)
Можно конечно попытаться записать в виде 2n/2n - 1/2n но что нам это даст?
КАПЕЕЕЕЕЦ, чтАААААА
как так?
Короче вот так вот, живите теперь с этим. Так просто оказывается, он тупо взял его и между двумя нулями засунул и получил 0. Жесть
Дело в том, что мы ранее доказывали, что по индукции все это равно правой 1/корень(2n+1), а оно по своей сути стремится к 0. А наше выражение с огромным количеством множителей больше 0, поэтому мы все это выражение засунули между ними, и по теореме двух милиционеров получили что и он равен 0
Прикол в том что лекции и семинары связаны. То есть учишь не просто теорию, но еще и разбираешься на реальных задачах на семинарах и выполняешь домашку, которую там задали. Плюс еще и с помощью третьего источника можно проверить свои знания после месяца учебы, то есть сделать срез знания. Там есть тесты
Честно говоря, я давно пишу код, но в основном — для автоматизации и решения личных задач. Иногда выкладываю результаты на GitHub или делюсь опытом в статьях. Работу в IT целенаправленно не искал, поэтому это было скорее хобби.
Сейчас я заканчиваю магистратуру, и в ближайший год для меня важны две цели:
написать диплом,
устроиться разработчиком в аккредитованную компанию.
Чтобы поддерживать мотивацию, я решил вести «публичный дневник» на Хабре и выкладывать прогресс каждые 1–2 дня. Начну с курса «ИИ старт» от Deep Learning School МФТИ (Stepik).
Немного о мотивации
С детства меня привлекала математика: она позволяет описывать практически всё — от физических процессов до человеческого поведения. В этом есть что-то завораживающее: строгий язык, через который можно понять устройство мира.
К этому добавляется интерес к современным технологиям и понимание того, куда они могут привести нас в будущем. Поэтому для меня машинное обучение — это не просто модное направление, а возможность объединить математику, анализ и программирование. Хочется внести свой вклад и заниматься любимым делом.
Что будет в серии статей
В публикациях я планирую делиться:
опытом прохождения курсов (их плюсы и минусы),
кусочками кода из проектов,
своими ошибками и тем, чему научился в процессе.
Это первый пост — пока без глубоких разборов. Главная задача сейчас — понять, куда двигаться и как выстроить обучение.
Нефтяные пласты содержат множество мелких пустот и полостей, которые заполнены не только углеводородами, но и водой. Она может занимать до 70% их объема. Для точного расчета запасов нефти и планирования эффективной добычи важно заранее определять количество воды в породе. Традиционно это рассчитывается с помощью трудоемких и дорогостоящих испытаний образцов породы в лабораториях. Однако при работе со сложными неоднородными пластами они не всегда дают точные результаты. Ученые Пермского Политеха и Иранского Университета Персидского залива разработали инновационный метод качественной оценки водонасыщенности нефтяных коллекторов с использованием машинного обучения. Комплексное исследование позволило выявить наиболее оптимальный алгоритм, который превосходит традиционные подходы, обеспечивая точность прогноза до 99,5%.
Статья опубликована в журнале «Scientific Reports», 2025.
В нефтяной отрасли ключевой задачей является определение физических параметров горных пород – пористости, проницаемости, насыщенности, плотности и многих других. От них зависит, как и какими методами будут добывать нефть на том или ином месторождении. Обычно их определяют путем отбора керна (образца породы) и его изучения в лабораторных условиях. Однако это дорогостоящий процесс, занимающий много времени.
Сегодня на смену традиционным методам приходит машинное обучение. Это подраздел искусственного интеллекта, работающий на математических алгоритмах. На основе больших массивов информации он способен уловить сложные связи между свойствами пласта и сделать точный прогноз. Выдавая быстрые результаты при меньших затратах.
– Такой подход уже успешно применяют для прогнозирования пористости, проницаемости горных пород и интерпретации данных, получаемых с лабораторных и скважинных испытаний. Однако значительно меньше внимания уделяется оценке водонасыщенности – одного из ключевых параметров в вопросе эффективной нефтедобычи, – объясняетДмитрий Мартюшев, профессор кафедры «Нефтегазовые технологии» ПНИПУ, доктор технических наук.
Ученые Пермского Политеха и Университета Персидского залива с помощью комплексного инновационного подхода определили наилучший метод машинного обучения, который на основе известных скважинных параметров наиболее точно предсказывает значения водонасыщенности коллекторов.
Существуют десятки разных математических алгоритмов, подходящих под эту задачу. Но для того, чтобы они смогли самостоятельно рассчитать нужные показатели, требуется большая обучающая база данных.
Для этого эксперты собрали обширную информацию с нефтяных месторождений, расположенных в юго-западном регионе Ирана. Она включает в себя более 30 000 замеров с реальных скважин по 9 параметрам: глубина, пористость, сопротивление горной породы, расчетное и спектральное гамма-излучение, диаметр скважины, время прохождения продольных волн, объемная плотность и температура.
Для выбора наиболее подходящего метода машинного обучения отобрали пять разных алгоритмов, которые хорошо справляются с прогнозами свойств пород. По собранной базе данных их обучали, тестировали и сравнивали друг с другом, проверяя способность предсказывать содержание воды в нефтяных пластах. Каждый алгоритм запускали в работу по десять раз. Это позволило убедиться в достоверности и надежности результатов.
– Из всех наилучший результат показал метод опорных векторов. Коэффициент, который показывает, насколько хорошо алгоритм предсказывает водонасыщенность, составил целых 0,995 из 1, что почти идеально, а погрешность – 0,002. Это означает, что он предсказывает содержание воды в пласте с точностью до 99,5%, и полученные данные отличаются от реальных лишь на 0,2%, – поделился Дмитрий Мартюшев.
Таким образом, на основе девяти ключевых параметров, которые регулярно контролируются геологами, обученный алгоритм сможет непрерывно выдавать показатели насыщения скважины водой. Внедрение такой технологии может кардинально изменить процесс управления нефтяными месторождениями, особенно в условиях сложных и неоднородных коллекторов: повысить точность подсчета запасов углеводородов, оптимизировать добычу, снизить зависимость от дорогостоящих и не всегда продуктивных исследований керна.
Эксперты отмечают, что алгоритм обучен на данных, относящихся к песчаным породам. Для его применимости к другим типам, например, карбонатам или трещиноватым системам, может понадобиться переобучение или дополнительная адаптация из-за различий в свойствах и характеристиках данных.
Исследование ученых ПНИПУ и Ирана доказало потенциал методов машинного обучения. Они не только значительно превосходят традиционные подходы, но и обходят другие алгоритмы, делая метод опорных векторов самым надежным и стабильным инструментом для оценки водонасыщенности пластов.
Некоторые «мыслящие» модели ИИ, которые генерируют длинные пошаговые рассуждения перед ответом, могут выделять до 50 раз больше CO₂, чем модели, дающие короткие прямые ответы.
Каждый раз, когда мы задаем вопрос ИИ, он не просто возвращает ответ — он также сжигает энергию и выделяет углекислый газ.
Немецкие исследователи выяснили, что некоторые «мыслящие» модели ИИ, которые генерируют длинные, пошаговые рассуждения перед ответом, могут выделять в 50 раз больше CO₂, чем модели, дающие короткие, прямые ответы. При этом такие выбросы не всегда приводят к лучшим ответам.
Ответы ИИ имеют скрытую экологическую цену
Независимо от того, что вы спросите у ИИ, он всегда сгенерирует ответ. Для этого, независимо от точности ответа, система полагается на токены. Эти токены состоят из слов или фрагментов слов, которые преобразуются в числовые данные, чтобы модель ИИ могла их обработать.
Этот процесс, наряду с более широкими вычислительными операциями, приводит к выбросам углекислого газа (CO₂). Тем не менее, большинство людей не знают, что использование инструментов ИИ сопряжено со значительным углеродным следом. Чтобы лучше понять это влияние, исследователи из Германии проанализировали и сравнили выбросы нескольких предварительно обученных больших языковых моделей (LLM) с использованием согласованного набора вопросов.
«Воздействие на окружающую среду при обращении к обученным LLM в значительной степени определяется их подходом к рассуждениям, при этом процессы явного рассуждения значительно увеличивают потребление энергии и выбросы углерода», — сказал первый автор Максимилиан Даунер, исследователь из Мюнхенского университета прикладных наук и первый автор исследования Frontiers in Communication. «Мы обнаружили, что модели с поддержкой рассуждений производят до 50 раз больше выбросов CO₂, чем модели с краткими ответами».
Модели с рассуждениями сжигают больше углерода, но не всегда дают лучшие ответы
Команда протестировала 14 различных LLM, каждая из которых имела от семи до 72 миллиардов параметров, используя 1000 стандартизированных вопросов по различным предметам. Параметры определяют, как модель обучается и принимает решения.
В среднем модели, созданные для рассуждений, производили 543,5 дополнительных «мыслительных» токенов на вопрос, по сравнению с всего 37,7 токенами у моделей, дающих краткие ответы. Эти мыслительные токены — это дополнительный внутренний контент, генерируемый моделью, прежде чем она остановится на окончательном ответе. Больше токенов всегда означает более высокие выбросы CO₂, но это не всегда приводит к лучшим результатам. Дополнительные детали могут не улучшить точность ответа, даже если это увеличивает экологические издержки.
Точность против устойчивости: новый компромисс в ИИ
Самой точной моделью оказалась модель Cogito с поддержкой рассуждений и 70 миллиардами параметров, достигшая точности 84,9%. Эта модель произвела в три раза больше выбросов CO₂, чем модели аналогичного размера, которые генерировали краткие ответы. «В настоящее время мы видим явный компромисс между точностью и устойчивостью, присущий технологиям LLM», — сказал Даунер. «Ни одна из моделей, у которых выбросы не превышали 500 граммов эквивалента CO₂, не достигла точности выше 80% при правильном ответе на 1000 вопросов». Эквивалент CO₂ — это единица, используемая для измерения воздействия различных парниковых газов на климат.
Тематика также приводила к значительному различию в уровнях выбросов CO₂. Вопросы, требующие длительных процессов рассуждения, например, по абстрактной алгебре или философии, приводили к выбросам в шесть раз выше, чем по более простым предметам, таким как история средней школы.
Как делать запросы умнее (и экологичнее)
Исследователи заявили, что надеются, что их работа заставит людей принимать более обоснованные решения об использовании ИИ. «Пользователи могут значительно сократить выбросы, давая ИИ указания генерировать краткие ответы или ограничивая использование высокопроизводительных моделей для задач, которые действительно требуют такой мощности», — отметил Даунер.
Например, выбор модели может иметь существенное значение для выбросов CO₂. Например, если DeepSeek R1 (70 миллиардов параметров) ответит на 600 000 вопросов, это создаст выбросы CO₂, равные перелету туда и обратно из Лондона в Нью-Йорк. Между тем, Qwen 2.5 (72 миллиарда параметров) может ответить более чем в три раза больше вопросов (около 1,9 миллиона) с аналогичными показателями точности, генерируя те же выбросы.
Исследователи заявили, что на их результаты может повлиять выбор оборудования, используемого в исследовании, фактор выбросов, который может варьироваться в зависимости от региональных энергетических сетей, и исследуемые модели. Эти факторы могут ограничивать обобщаемость результатов.
«Если бы пользователи знали точную „цену“ в CO₂ каждого сгенерированного ИИ результата — например, когда они ради развлечения создают собственное изображение в виде экшен-фигурки — они, возможно, были бы более разборчивы и вдумчивы в том, когда и как использовать эти технологии», — заключил Даунер.
Привет пикабушники! Сегодня мы создадим и обучим модель инверсионной диффузии для генерации изображений.
Требования - python, conda/rocm, pytoch, torchvision matplotlib(для визуализации)
1 Скачайте и установите python, на GNU/Linux установите uv , а затем uv python install python3.12
2 Создайте и активируйте виртуальное окружение. Что такое виртуальное окружение(venv)? venv это изолированная среда python для установки зависимостей
1 Вариант (для uv, очень простой) uv venv .venv --python python3.12, выполните команду, которую выдаст uv, установка зависимостей в окружении uv pip install datasets torch torchvision matplotlib (для cpu, для gpu ниже). Внимание!! Вам нужна особая команда для установки torch с поддержкой gpu. Полный список здесь - uv pip install torch torchvision --index-url https://download.pytorch.org/whl/cu128, это для nvidia uv pip install torch torchvision --index-url https://download.pytorch.org/whl/rocm6.4 amd rocm(только на GNU/Linux). 2 Вариант для python venv.
На винде - py -3.12 -m venv .venv, дальнейшие этапы аналогичные, только команды для установки зависимостей без uv, просто pip. 3 Этап создайте файл, назовите его как хотите, но с расширением py , например model.py. Скопируйте туда данный код, запустите через python вашфайл.py и начнется скачивание mnist датасет с рукописными цифрами и затем обучение в 20 эпох.
Если у вас слабый gpu или его нет, то, к сожалению, ждать нужно будет очень долго. С gpu +- час - 2 часа. В результате у вас отобразится результат генерации, а также поле для ввода цифры, чтобы сгенерировать. Чем больше эпох при обучении, тем лучше результат. Но не стоит ставить огромные значения, модель может переобучиться.
Для тех у кого нет gpu можете загрузить пред обученную модель с моего гитхаба.
Как это работает и что это такое
Это условная диффузионная модель (Conditional Diffusion Model), которая генерирует изображения цифр MNIST (0–9) с контролем над классом (например, можно запросить генерацию именно цифры "5"). Модель сочетает:
Диффузионный процесс — постепенное добавление/удаление шума.
Условную генерацию — зависимость от целевого класса (цифры).
Архитектуру U-Net — для обработки изображений на разных уровнях детализации.
Как это работает?
1. Прямой диффузионный процесс (заражение шумом)
Цель: Постепенно превратить изображение в случайный шум за T=1000 шагов.
Математика:
xt=αˉt
⋅x0+1−αˉt
⋅ϵ
где:
x0 — исходное изображение,
ϵ — случайный шум (Gaussian noise),
αˉt=∏s=1t(1−βs) — кумулятивное произведение коэффициентов "чистоты" сигнала.
2 Создайте и активируйте виртуальное окружение. Что такое виртуальное окружение(venv)? venv это изолированная среда python для установки зависимостей
1 Вариант (для uv, очень простой) uv venv .venv --python python3.12, выполните команду которую выдаст uv, установка зависимостей в окружении uv pip install datasets torch(для cpu, для gpu ниже). Внимание!! Вам нужна особая команда для установки torch с поддержкой gpu. Полный список здесь - uv pip install torch torchvision --index-url https://download.pytorch.org/whl/cu128, это для nvidia uv pip install torch torchvision --index-url https://download.pytorch.org/whl/rocm6.4 amd rocm(только на GNU/Linux). 2 Вариант для python venv.
На винде - py -3.12 -m venv .venv, дальнейшие этапы аналогичные, только команды для установки зависимостей без uv ,просто pip. 3 Этап создайте файл, назовите его как хотите, но с расширением py , например nlp.py. Скопируйте туда данный код, замените в нём отзывы на свои. Модель простая и понимает только англ язык. При первом запуске скачается датасет и начнётся обучение в 5 эпох, с gpu будет раз в 10 быстрее, запуск через python вашфайл.py, это нужно делать в окружении.
Как это работает?
Этот код реализует бинарную классификацию отзывов из датасета IMDB (положительный/отрицательный) с использованием упрощенной архитектуры трансформера. Вот ключевые аспекты работы модели:
1. Подготовка данных (пред обработка)
Датасет: Используется IMDB (50k отзывов, разделенных на 25k обучающих и 25k тестовых примеров).
Словарь:
Строится на основе 10,000 самых частых слов из обучающих данных.
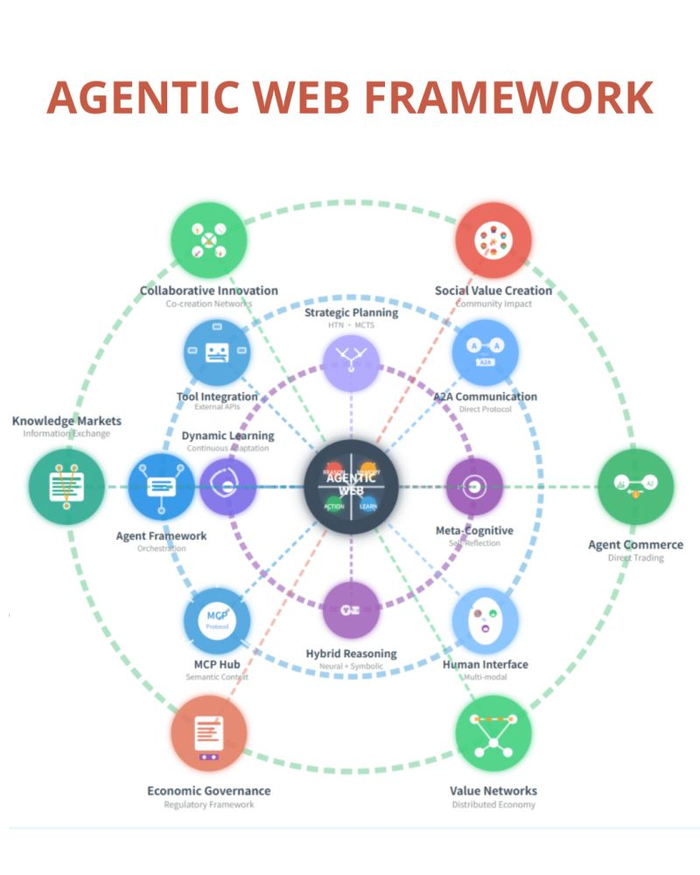
Эта тенденция получила название «Агентная паутина» (Agentic Web) и она полностью меняет правила игры. Суть в том, что пользователи будут взаимодействовать не напрямую с сайтами и приложениями, а с умными агентами, которые выступают в роли автономных посредников.
Работает это следующим образом: вы просто ставите цель агенту ИИ, например, просите его спланировать рабочую поездку в Токио. Получив задачу, он самостоятельно разрабатывает план, привлекает других специализированных агентов для поиска авиабилетов, бронирования отеля или анализа погоды и действует автономно. В процессе эти агенты взаимодействуют, адаптируются под изменяющиеся условия и в итоге выдают вам готовый результат.
И все это без лишних вкладок, утомительного поиска и какого-либо стресса для вас.
Агенты больше не просто ищут информацию. Они анализируют, договариваются и действуют, используя различные сервисы, API и других агентов. Это не та сеть, которой пользуетесь вы. Это сеть, которой пользуется ваш ИИ от вашего имени. В основе этой концепции лежит так называемая «сеть действий» — полноценная экосистема агентов, которые общаются друг с другом, оптимизируют рабочие процессы и выполняют планы без контроля со стороны человека. Происходит переход от простого поиска к организации процессов и от кликов к достижению конкретных результатов. Что нас ждет? Вашим следующим «приложением» может стать агент, а ваш следующий «рабочий процесс» может проходить вообще без вашего участия. Это ставит новые вопросы для дизайна продуктов, владения данными и будущего работы.
Придется выбирать: создавать продукты для пользователей или для агентов, которые им служат.
Технологии вроде Model Context Protocol (MCP) уже закладывают фундамент для этого будущего, стандартизируя взаимодействие между ИИ-моделями и различными инструментами, такими как базы данных или API. Это позволяет создавать более мощные и гибкие приложения, где агенты могут беспрепятственно обмениваться информацией и координировать свои действия.