
Это Искуственный Интеллект?

*(tierversuch с немец.=опыт над животными)
*(tierversuch с немец.=опыт над животными)
Разработчики многопользовательской VR-песочницы Modbox объединили платформу распознавания голоса Windows Speech Recognition, нейросеть от компании OpenAI - GPT-3 и систему синтеза естественной речи Replica. Всё ради уникального демо первых NPC с искусственным интеллектом.
Перемотайте на 4 минуты 25 секунд, чтобы посмотреть на общение между двумя NPC под управлением ИИ.
Корпорация Microsoft, которая инвестировала 1 миллиард долларов в OpenAI, обладает эксклюзивным правами на исходные коды и коммерческое применение модели GPT-3, потому вряд ли подобная технология будет реально применяться в самом Modbox. Но это видео-демо по прежнему отличный способ посмотреть на будущее NPC в играх. Языковые модели будущего могут изменить сам подход к геймдизайну и создать целые новые игровые жанры.
Эти неприятные паузы между вопросом и ответом NPC из-за того, что и модель GPT-3 и система синтеза голоса Replica - обе являются облачными технологиями. Будущие модели, запущенные на устройствах пользователей смогут преодолеть эту задержку. Google и Amazon уже включают специализированные чипы в некоторые устройства для умного дома, чтобы сократить задержку у цифровых ассистентов.
Как это возможно?
Книги, фильмы и телепрограммы все крутятся вокруг персонажей. Но в нынешних видеоиграх и VR-аттракционах вы не можете напрямую общаться с персонажами вовсе, или можете выбирать только из заранее прописанных ответов в диалоговом дереве.
Прямое общение с виртуальными персонажами и получение убедительных ответов, вне зависимости от вопроса, ещё совсем недавно было невозможно. Но недавний прорыв в технологиях машинного обучения делает эту идею наконец-то достижимой.
В 2017, подразделение по разработке ИИ Google представило новый подход к языковым моделям, под названием Транфсормеры. Новейшие модели машинного обучения на тот момент и так уже использовали концепцию внимания, чтобы получать лучшие результаты, но новый подход был полностью построен вокруг этой концепции.
В 2018 году, профинансированный Илоном Маском стартап OpenAI использовал подход Google при создании своей новой языковой модели общего назначения, названной Generative Pre-Training (GPT) и обнаружил, что GPT способна предсказывать следующее слово во множестве предложений, и может отвечать на некоторые вопросы со множеством вариантов ответа.
В 2019, OpenAI усложнил эту модель более чем в 10 раз в GPT-2. Они обнаружили, что это "усложнение" серьёзно улучшило возможности системы. Давай GPT-2 всего несколько предложений в качестве ввода, она теперь была способна писать целые эссе на почти любую тему, или даже производить грубый перевод. В некоторых случаях, вывод системы был неотличимым от человеческого. Из-за возможных последствий, OpenAI изначально решила не выкладывать модель в общий доступ, что привело к обсуждению в СМИ и спекуляциях о возможных социальных последствиях применения продвинутых языковых моделей.
У GPT-2 был 1.5 миллиард параметров, но в июне 2020 OpenAI опять усложнила модель, доведя количество параметров до 175 миллиардов в GPT-3 (использовавшейся в этом демо). Вывод GPT-3 почти всегда не отличим от человеческого.
Технически, у GPT-3 нет реального "понимания" (хотя, философские обоснования этого термина, все ещё обсуждаются). Порой GPT-3 может выдавать бессмысленные или предвзятые результаты. Исследователям все ещё предстоит найти механизмы решения подобных проблем, например "проверки на смысл", прежде чем подобные модели найдут применение в потребительских продуктах.
Оригинал статьи на английском

Сижу себе, перевожу всякий занятный (нет) контент о плазменной резке. В процессе подгугливаю и, дойдя до конца первой страницы, обращаю внимание на то, что предлагает позырить поисковик, в котором найдётся всё.

Наверное, ему показалось что англицкое слово torch завуалированно используется мной, чтобы найти чё.
Зачем тебе, Cingular, резаки эти? В*еби мефа лучше...

Друзья, недавно мы выкладывали подборку «Сегодня я узнал», где путём голосования был выбран пост для перевода про ИИ определяющий ориентацию людей по фото. Приятного чтения:
Искусственный интеллект может с высокой точностью определить ориентацию человека по фотографии лица. В новом исследовании говорится, что ИИ значительно лучше человека определяет ориентацию.

Иллюстрация технологии анализа лица, аналогичная использованной в эксперименте.
Исследование Стэнфордского университета показало, что компьютерный алгоритм может правильно различать геев и гетеросексуалов в 81% случаев для мужчин и 74% для женщин. Данное исследование подняло вопросы о биологическом происхождении сексуальной ориентации, этичности технологии распознавания лиц, а также вероятности того, что такое ПО может нарушить конфиденциальность или использоваться в целях борьбы с ЛГБТ.
В исследовании, которое появилось в Journal of Personality and Social Psychology и впервые упоминалось в Economist, использовалась выборка из более чем 35 000 изображений лиц, которые мужчины и женщины публично разместили на американском сайте знакомств. Исследователи, Михал Косински и Илун Ван, извлекли особые черты из изображений с помощью «глубоких нейронных сетей», то есть сложной математической системы, которая учится анализировать визуальные эффекты на основе больших данных.
Исследование показало, что мужчины и женщины нетрадиционной ориентации, как правило, имеют «гендерно-атипичные» черты лица, выражения и «стили ухода», что по сути означает, что геи выглядят более женственными, и наоборот. Данные также выявили определенные тенденции, в том числе то, что у геев более узкие челюсти, более длинные носы и более широкий лоб, чем у гетеросексуалов, а также - что у лесбиянок крупнее челюсти и меньше лоб по сравнению с гетеросексуальными женщинами.
Обычным людям определение ориентации давалось намного сложнее - только в 61% случаев для мужчин и 54% для женщин. Когда программа проанализировала по 5 фото каждого человека, процент успеха оказался еще выше - в 91% случаев с мужчинами и 83% с женщинами. В широком смысле это означает, что «в лицах содержится гораздо больше информации о сексуальной ориентации, чем может воспринимать и интерпретировать человеческий мозг», - пишут авторы.
В документе высказывается предположение, что полученные данные «убедительно подтверждают» теорию о том, что сексуальная ориентация связана с воздействием определенных гормонов еще до рождения, то есть, что люди рождаются с нетрадиционной ориентацией, а стать гомосексуалом невозможно. Более низкий показатель успешности ИИ для женщин также может подтвердить мнение о том, что женская сексуальная ориентация гораздо более изменчива.
Хотя результаты исследования несколько ограничены – в нем не рассматривались представители не-европеоидной расы, трансгендеры и бисексуалы – безбрежные последствия для ИИ настораживают. Авторы исследования считают, что с учетом миллиардов изображений лиц, хранящихся в социальных сетях и в государственных базах данных, эти данные могут использоваться для определения сексуальной ориентации людей без их согласия.
Легко представить, что супруги используют эту технологию для проверки своих партнеров, которых они подозревают, или что подростки используют алгоритм на себе или своих сверстниках. Пугает также то, что правительства, которые продолжают преследовать ЛГБТ в судебном порядке, гипотетически могут использовать эту технологию для выявления людей с нетрадиционной ориентацией в масштабе всей страны. Создание и публикация такого ПО вызывает споры. Также возникают опасения, что появятся и вредоносные приложения.
Но авторы утверждают, что технология уже существует, а ее возможности важно правильно раскрыть, чтобы правительства и компании могли проактивно учитывать риски конфиденциальности и оценивать необходимость мер безопасности и регулирования.
«Конечно, опасения не могут не возникать. Как и любой новый инструмент, если он попадет не в те руки, его можно использовать в преступных целях», - сказал Ник Рул, доцент кафедры психологии Университета Торонто, опубликовавший исследование по науке о гей-радаре. «Классификация людей по внешним признакам с последующей идентификацией и возможными негативными последствиями для этих людей- это преступление».
Рул утверждает, что разработка и тестирование этой технологии все еще стоят на первом месте: «Авторы исследования сделали очень смелое заявление о том, насколько значимой может стать эта технология. Теперь мы знаем, что нам нужна защита».
Косински не сразу прокомментировал исследование, но после публикации этой статьи в пятницу он рассказал Guardian об этических вопросах исследования и его последствиях для прав ЛГБТ. Профессор известен своей совместной работой с Кембриджским университетом по психометрическому профилированию, включая использование данных Facebook для того, чтобы сделать определенные умозаключения о личности. Кампания Дональда Трампа и сторонники Брексита использовали аналогичные инструменты для таргетирования избирателей, что вызвало обеспокоенность по поводу широкого использования личных данных на выборах.
В Стэнфордском исследовании авторы также отметили, что ИИ можно использовать для изучения связей между чертами лица и рядом других явлений, таких как политические взгляды, психологические состояния или личность.
Данный тип исследования также вызывает опасения в связи с возможными сценариями развития ситуации, которые напоминают научно-фантастический фильм «Особое мнение», в котором человека могут арестовать исключительно на основании предсказания того, что он совершит преступление.
«ИИ может рассказать вам всё, что угодно, о любом человеке, о котором достаточно данных», - сказал Брайан Бракен, генеральный директор Kairos, компании, занимающейся распознаванием лиц. «Вопрос заключается в том, хотим ли мы это знать?»
По словам Бракина, данные Стэнфордского университета о сексуальной ориентации «поразительно верны» и необходимо уделять больше внимания конфиденциальности и инструментам для предотвращения злоупотребления машинным обучением, поскольку оно становится все более распространенным и продвинутым.
Рул высказал предположение о том, что ИИ может использоваться для активной дискриминации людей на базе машинной интерпретации их лиц: «Мы должны быть коллективно обеспокоены».
***
Больше переводов в нашем telegram-канале «Офигенно News».
Перевод telegram - канал: https://t.me/ofigenno
Продолжение следует...
Для всех поклонников футбола Hisense подготовил крутой конкурс в соцсетях. Попытайте удачу, чтобы получить классный мерч и технику от глобального партнера чемпионата.
А если не любите полагаться на случай и сразу отправляетесь за техникой Hisense, не прячьте далеко чек. Загрузите на сайт и получите подписку на Wink на 3 месяца в подарок.

Реклама ООО «Горенье БТ», ИНН: 7704722037
В 2003 году Таня Бергер-Вольф, ученая из Университета Огайо, поехала в отпуск в заповедник в Кении. Там она встретила коллегу, который пытался идентифицировать зебру, сравнивая ее полосы с полосами сотен зебр на фотографиях, ранее сделанных в заповеднике.

Поиск занял примерно 20 минут, и Бергер-Вольф предположила, что должен существовать лучший способ идентификации диких животных. Вместе с коллегами они разработали Экологическую информационную систему на основе изображений (IBEIS), систему машинного обучения, способную сравнивать фотографии зебр и других видов животных.
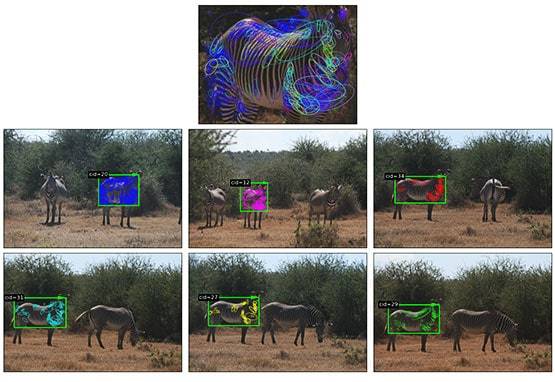
В процессе обучения IBEIS демонстрировали тысячи фотографий животных. Зебры идеально подходят для этой задачи, потому что, по сути, они являются ходячими штрих-кодами. Но будет ли IBEIS работать с другими животными, нуждающимися в защите? Профессор Бергер-Вольф объединила усилия с некоммерческой организацией Wild Me. Вместе они создали проект Wildbook, чтобы подсчитать китовых акул, находящихся под угрозой исчезновения, путем анализа фотографий исследователей, дайверов-любителей и обычных туристов на лодках.

У этих акул есть пятна на теле, уникальные для каждого животного. В рамках проекта было проанализировано около 75 000 фотографий и видеороликов, и выявлено около 8100 особей китовых акул. Проект был признан успешным, сейчас Wildbook продолжает работу с более чем 30 видами животных, включая белых медведей, жирафов и горбатых китов. Программное обеспечение просматривает публично размещенные изображения и клипы в социальных сетях в поисках подходящих животных.

В 2016 году Кения обратилась к Бергер-Вольф за помощью в подсчете зебр Греви. В 1970-х их было около 15000, но защитники природы считали, что их количество резко сократилось. Для этого ученые пригласили волонтеров, которые хотели помочь, и попросили их фотографировать животных в течение двух дней в местах их обитания. Сотни людей вызвались помочь, в общей сложности они сделали 40 000 изображений для обучения моделей машинного обучения.

Окончательный подсчет показал 2350 зебр, подтвердив опасения защитников природы. Но теперь, когда снижение численности было задокументировано, был предпринят ряд шагов. Новые переписи зебр, проведенные в 2018 и в начале 2020 года, показали увеличение поголовья до 3000 особей.











