
Записал мини краш курс по джанго
записал мини краш курс по джанго
я школьник так что не ругайте сильно
мой гитхаб -https://github.com/Nicheye
Показать полностью
записал мини краш курс по джанго
я школьник так что не ругайте сильно
мой гитхаб -https://github.com/Nicheye
Друзья, всем привет!
Помимо основной работы инженером данных, я поддерживаю небольшой сайт на Django (посвящен информационным материалам по преподаванию истории и обществознания).
Так как материалы на сайт добавляются довольно часто, а также регистрируются новые пользователи, конечно же возникла идея, как бы правильно организовать бэкап базы данных - чтобы я мог легко синхронизировать данные на сервере с данными, лежащими в базе на рабочем компьютере.
Сразу скажу, что такой подход подойдет для баз, размер которых не является астрономическим (сотни гигабайт), в моем случае база весит всего 50 Мб, статика около 400 - поэтому мне не составляло большого труда синхронизировать такие объемы. Думаю, небольшие и даже средние интернет магазины и блоги вряд ли хранят на порядки больше данных.
Для больших проектов, лучше бэкапы архивировать, шифровать и отправлять куда нибудь в s3 типа Minio.
Когда новая инфа на сайте появлялась довольно редко, я все делал руками, а именно:
заходил на удаленный сервер, где крутится сайт, по ssh
выполнял команду для создания полной копии БД
sudo -u postgres pg_dumpall -c -f {remote_db_copy_file_path
потом переключался в терминал ос рабочего ноута, создавал папку с названием, соответствующем дате бэкапа
с помощью утилиты scp, копировал с удаленной машины с сайтом бэкап, полученный в пункте 2 - т.е. типа такой команды
scp -r {remote_user}@{remote_host}:{remote_media_path} {local_media_full_path}
опять же с помощью scp копировал статику с файлами из папки
удалял файл бэкапа из папки на удаленном сервере
У такого подхода главный минус - это потраченное время, а также возможная путаница с названиями скопированных файлов и папок.
Поэтому настал час, когда я решил автоматизировать свою работу и написал скрипт на Python, автоматизирующий рутину по созданию бэкапа.
Сам скрипт лежит вот здесь, в моем GitHub, скачивайте и пользуйтесь.
Давайте более подробно рассмотрим, как он работает:
Делается подключение по ssh с помощью библиотеки paramiko, сделал с помощью файла rsa-key, который paramiko ищет автоматом, соответственно пароль указывать не надо
В скрипте за подключение отвечает функция _initialize_ssh_client
Получаем название файла с копией БД, которую необходимо будет создать, с помощью функции _get_db_copy_remote_filename. Принцип простой, берем текущее время и дату, и подставляем в название файлика, получается что то типа “01072023_155045.sql". К этому имени подставится путь, взятый из переменной окружения REMOTE_DBCOPY_FOLDER
Похожим образом задаются переменные, чтобы понимать, куда потом надо сложить на локальной машине копию базы, и как назвать папку для копии статических файлов. Т.е. это маленькие функции _get_db_copy_full_path и _create_local_media_folder, тоже работающие с переменными окружения
Функция make_db_backup собственно делает сам бэкап, через команду pg_dumpall, предварительно выдав права юзеру postgres на папку, куда положится бэкап
Бэкап грузится на локальную машину (upload_db_backup_to_local_machine)
Старые бэкапы удаляются с сервера (delete_old_copies_on_remote). Важно отметить, что срок актуальности бэкапа в днях можно задать в конфиге через переменную old-db-copies-exp-period. Потом данный период подставится в команду утилиты find.
Ну и в конце, функция copy_media_files_to_local перекачивает статику с сервера на локальную машину
С алгоритмом работы понятно, теперь давайте распишу, что вам надо сделать, чтобы у Вас тоже все запустилось и работало,
Иметь интерпретатор питона на локальной машине
Скачать репозиторий с моего гитхаба https://github.com/Riddik1993/DB-and-static-copy-from-remote
Настроить с Вашим удаленным сервером вход по ssh не по паролю, а по ключу из файла. Как это сделать - есть много туториалов в статьях и на ютубе, я сам научился по видео на канале Диджитализируй.
Также это стоит сделать и не только ради скрипта с копированием базы, но и просто из соображений безопасности - так как по паролю ваш сервер гораздо легче взломать чем через ключ rsa
Находясь в папке скаченного репозитория, вводим в терминале команду pip install requirements.txt и ставим нужные для скрипта зависимости. Если не хотите ставить их глобально, но создайте виртуальное окружение сначала и ставьте туда
Обращаем внимание на файл config.conf. Надо создать переменные окружения, которые указаны внутри фигурных скобок - это можно сделать, отредактировав файл ~/.bashsrc
Просто открываем этот файлик, добавляем строчки такого формата
export REMOTE_USER=”username”
Сохраняем, вводим команду
source ~/.bashsrc
Если совсем нет времени это делать, можно конечно и прямо в этот файл задать, паролей там никаких нет, но палить параметры напрямую в коде - это конечно плохо, все же через переменные безопасней.
Когда все сделано, в терминале в папке репозитория запускаем команду python3 make_db_media_copy.py
В выводе вы увидите логирование всех стадий работы скрипта.
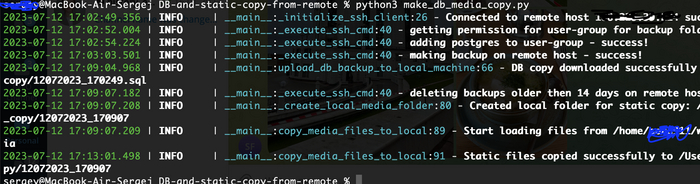
Файл с копией базы положился в папку, название которой хранится в переменной LOCAL_DBCOPY_PATH

Медиафайлы положились в папку, которую скрипт предварительно создал, в указанной нами директории LOCAL_MEDIA_PATH
Если что то упало - в принципе будет ясно почему (смотри скриншот с логами). Но если что. пишете в комментариях - всегда рад помочь)

Также пишите, как делаете логирование Вы)
Если понравилось, буду рад приветствовать вас в своем телеграм канале, куда публикую интересные обзоры питон-функций, разборы задачек с собеседований, ну и просто интересные мысли.
Добрый день, уважаемые форумчане.
Несколько дней назад, в поисках ответа на вопрос я попал на страницу с вопросом годичной давности одного пользователя, в которой он искал ментора, потому что сам не мог решить свой вопрос. В коментариях ему посоветовали выложить все задание здесь на pikabu. По причине отзывчивости и доброжелательного отношения пользователей я решил выложить свой вопрос, в надежде получить ответы.
Я рассылаю резюме на вакансию Python-разработчика, и получил тестовое задание. Хотя уже понимаю, что знаний моих не достаточно и нужно еще учиться и скорее всего в эту компанию меня не возьмут, но считаю обязаностью все тестовые задания решать . По причине самостоятельного обучения прошу строго не судить за вопросы, ответы на которые могут показаться очевидные.
И так задание:
Необходимо создать сервер авторизации и новостей с комментариями и лайками на Django с использованием RestFramework на python 3.
У каждого пользователя может быть две роли – пользователь и админ, админ может зайти в админ-панель, пользователь – нет. Как именно решить эту задачу не принципиально. Плюсом будет создание кастомного класса для авторизации наследуемого от BaseAuthentication - нам важно видеть как вы решите эту задачу.
Каждый пользователь может создать новость. Все пользователи могут получать списки всех новостей с пагинацией. Пользователи могут удалять и изменять свои новости. Админ может удалять и изменять любую новость.
Также нужно добавить механизм лайков и комментариев новостей – лайкать и комментировать может любой пользователь, автор может удалять комментарии к своим новостям, админ может удалять любые комментарии.
При получении списка новостей и одной конкретной новости нужно показать количество лайков и комментариев. Плюсом будет добавление списка последних 10 комментариев при получении списка новостей и одной новост.
Плюсом будет реализация механизма через микросервис.
Исходный код приложения необходимо выложить на GitLab или GitHub и запустить сервер. Сервер должен быть доступен для запросов из внешней сети, доступ к серверу (IP или доменное имя) а также роут для доступа к АПИ должны быть в README.md репозитория.
Краткий мануал по созданию виртуального сервера на базе яндекс.облака для новых пользователей даётся бесплатный период использования:
https://cloud.yandex.ru/docs/compute/quickstart/quick-create-linux
Также бесплатный сервер t2 micro можно поднять на Amazone:
https://us-east-2.console.aws.amazon.com/ec2/v2/home
Желательно:
контейнеризация в Docker
использование python venv
использование web сервера CherryPy, gunicorn и им подобных (какого-нибудь одного)
демонстрация понимание механизма миграций моделей (можно сделать несколько изменений в какой-либо модели и показать миграции)
использование .env файла для хранения информации о подключении к базе данных
файл README.md с описанием скриптов для разворачивания окружения и запуска сервера
Модели:
Users (имя пользователя, пароль в зашифрованном виде)
News (дата новости, заголовок новости, текст новости, автор)
Comments (Дата комментария, текст комментария, автор)
Опционально: Tokens (при авторизации можно создавать токены и хранить их в базе или использовать JWT токены)
Роуты
POST auth (передаем имя пользователя и пароль, получаем токен если пользователь с таким паролем есть и ошибку, если такого пользователя нет)
GET news (получаем список новостей с пагинацией)
POST news (создаем новость, проверка на авторизацию)
PUT news (обновляем новость, проерка на атворизацию, проверка на наличие прав)
DELETE news
GET comments (получение списка комментариев новости с пагинацией)
POST comments (создание нового комментария, проверка на авторизацию)
DELETE comments
Админка
Нужна стандартная админка Django (пользователи админки могут не пересекаться с пользователями в таблице Users)
Что мне непонятно:
1. Первое на чем я застрал это модель Users. Что мне нужно делать, использовать встроенную модель Django - User или создавать свою? Можно расширить джанговскую или создать прокси модель. Но я не понимаю, как хранить пароль, какой тип поля выбирать для этого? На даном этапе я создал модель News c полем ForeignKey(User).
2. Правильно ли я понял, что для выполнения задания создавать html-шаблон для отображения новостей не нужно? Хотя наверное это будет плюсом.
3. Для реализации механизмов коментариев и лайков в качестве микросервиса, нужно создать его как отдельное Django-приложение, а потом оформить как пакет и выкладывать на отдельном сервере?
4. В начале я пытался в качестве веб-сервера прикрутить CherryPY, но нашел только инструкции 10-летней давности. В итоге запускаю через Gunicorn, для него инструкция в документации Django. После запуска в админке Django, не отображалась статика, поэтому я установил Nginx. Это правильная последовательность действий или нужно было по другому делать?
5. Когда я сделаю проект, Nginx нужно устанавливать в Docker с остальными зависимостями? Создание докер-образа это одна задача, а разворачивание на сервере другая, или можно этот образ развернуть на сервере?
6. Еще читал, что плохая практика пихать в один образ Django-проект и БД, как лучше поступить в моем случае?
Заранее спасибо за ответы.
P.S. я откликался на вакансию Мидла, поэтому вариант задавать все эти вопросы рекрутеру с последующей переадресацией спецам я не рассматривал.
Возможно опенсорс на python/django 4.0 и фронт на обычном html/css ну и js наверно в ход пойдёт без библиотек и всего такого.Что можете предложить добавить в неё?Советы и предложения по разработке приветствуются.

Ребят, укажите правильный путь джедая !
Вот пишешь ты бота для телеги или проект на джанге. Учебное, не коммерческое! Но хочется чтобы все работало как у реальных людей. Куда это потом бесплатно сложить, чтобы бот 24/7 работал?
Что-то вообще потерялся. Если её трудно, подробно расскажите кто-то, пост для новичков сделайте плиз!
И с Джанго проектом такой же вопрос.
Спасибо








