Вышла новая модель LongCat-2.0
Выложена новая MoE-модель LongCat-2.0 (https://huggingface.co/meituan-longcat/LongCat-2.0) с 1.6T общих и примерно 48B активных параметров на токен, полностью обученная на AI ASIC-суперкластерах без откатов и потерь.
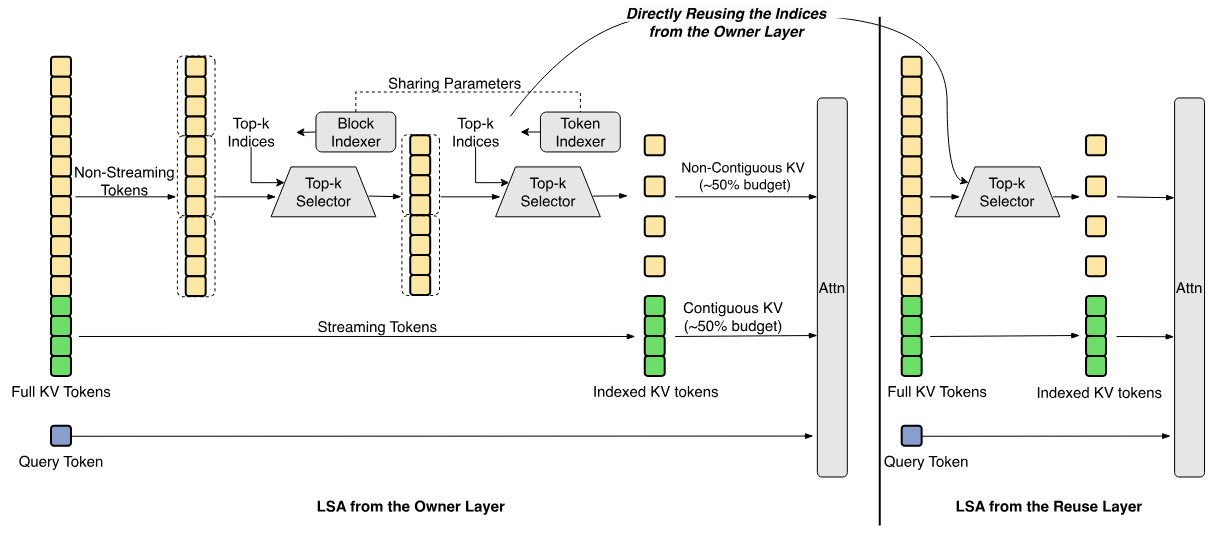
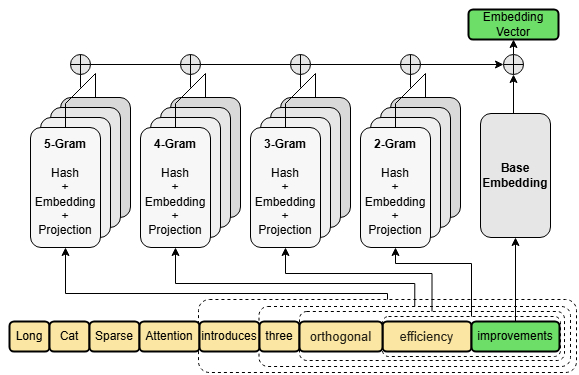
Улучшенная архитектура имеет LongCat Sparse Attention (LSA) из трёх ортогональных оптимизаций индексатора, среди которых Streaming-aware Indexing, Cross-Layer Indexing и Hierarchical Indexing, ускоряющие обработку сверхдлинных контекстов. За расширение пространства эмбеддингов примерно в 100 раз, повышая эффективность использования параметров при выводе, отвечает N-gram Embedding (5-граммы, 135B параметров).
Основными частями инфраструктуры стали обучение на более 50K ускорителях (6D-параллелизм, ZeRO-1, оптимизатор Muon, детерминизм и контроль точности) и вывод через PD-разделение, KV-cache параллелизм, перекрытие вычислений и коммуникаций, супер-ядра, предвыборка весов.
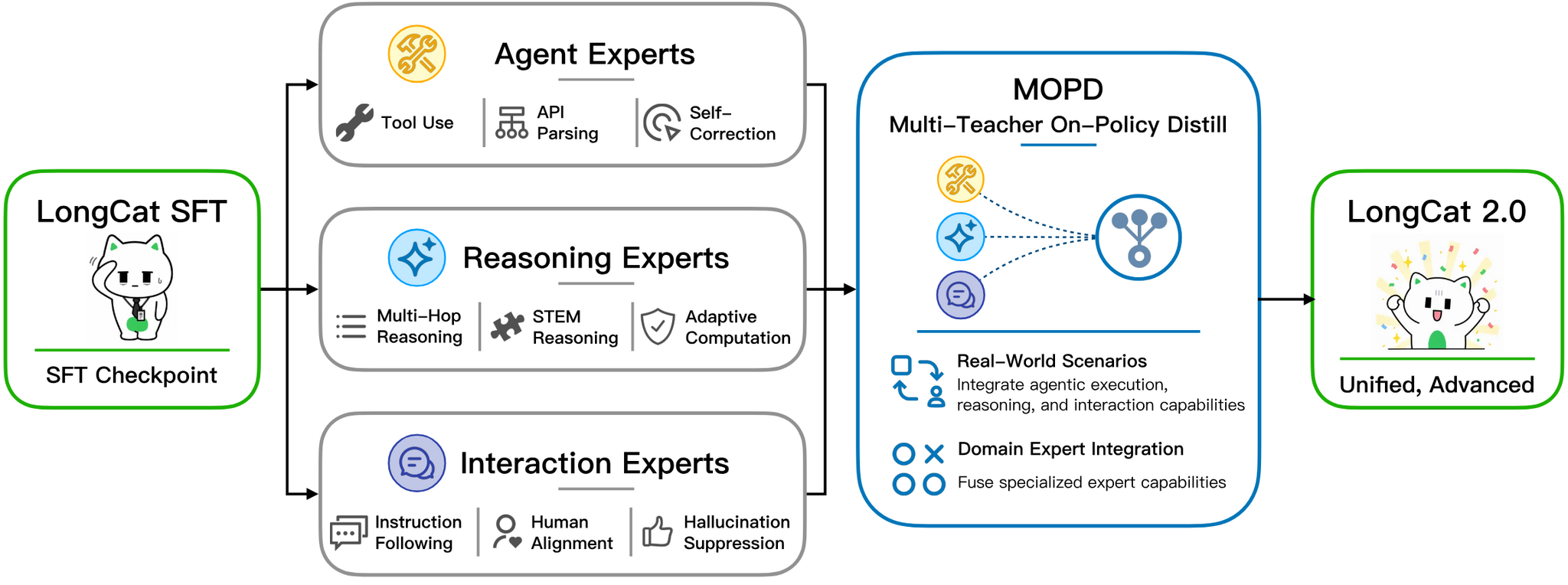
Посттренировка Multi-Teacher On-Policy Distill (MOPD) использовала три группы экспертов, включая Agent (инструменты, самокоррекция), Reasoning (глубокая логика) и Interaction (инструкции, выравнивание).
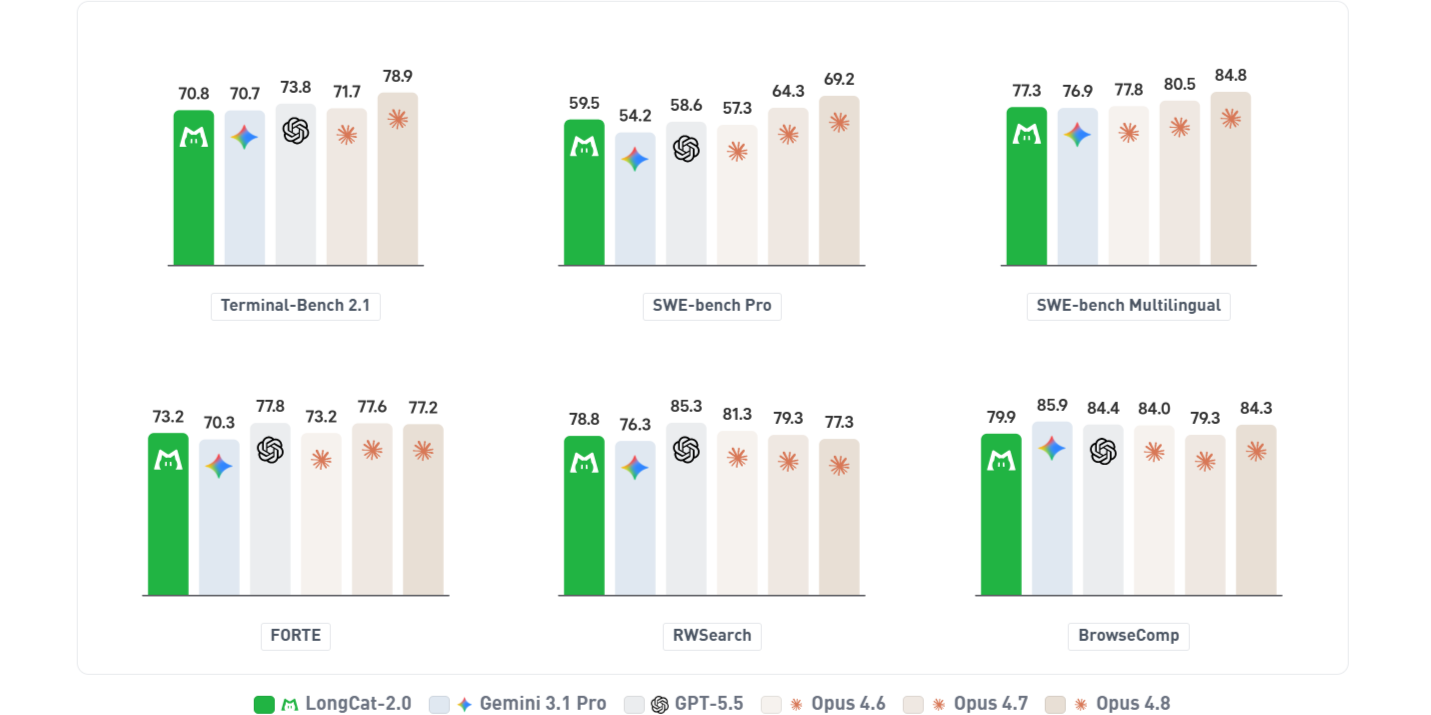
В результате обретён уровень лучших проприетарных моделей, а конкретно 70.8 на Terminal-Bench 2.1, 59.5 на SWE-bench Pro, 77.3 на SWE-bench Multilingual, 73.2 на FORTE, 79.9 на BrowseComp, 81.8 на IMO-AnswerBench и других.