




Тишины абсолютной все равно в комнате достичь невозможно. А звуковику надо записать не тишину, а как раз фоновый шум!!! Тот самый который он потом исключит в программе обработки звука. Т.е. ему нужен слепок этого шума (Capture Noise Print) . И из всего репортажа он потом сможет удалить именно его и таким образом почистить (сделать шумоподавление Noise Reduction). Без оригинальной записи шума, его не исключить из всего репортажа. Это как собаке надо дать пример понюхать того, что искать.
раскрыть ветку (182)

раскрыть ветку (67)
Так именно Adobe и купил аудиоредактор CoolEdit с весьма толковым шумодавом. Оно теперь называется Adobe Audition.
раскрыть ветку (18)
Оффтоп шушуть. Познакомился с Adobe Audition ещё во времена версии 1.5, когда даже интерфейс ещё почти не поменяли. Потом у приятеля на компе увидел CoolEdit и подумал, вот же ж совести у людей нет, один в один у адоба софтину спиздили)

самый нормальный шумодав - использовать связку лимитера и компрессора. которую настраиваешь вручную перед записью, под окружение.
раскрыть ветку (16)
раскрыть ветку (15)
Не усилят, если отрезать фон лимитером. Я раньше тоже нойз редукшн использовал, но автоматика жрет помимо фона еще и нужные частоты иногда.
раскрыть ветку (14)
Лимитер - это компрессор, только очень быстрый и жёсткий. Он никак не может удалять фон.
Вы путаете лимитер с гейтом.
Вы путаете лимитер с гейтом.
раскрыть ветку (13)
Я ничего не путаю. Я работаю со звуком практически каждый день. С записью тем более. Из связки лимитер+компрессор я и настраиваю этот самый гейт. Раньше использовал iZotop Nektar 3 для этих целей (для лайв записи).
раскрыть ветку (12)
Вам правильно говорят) Компрессор и лимитер сужают динамический диапазон, и шум станет только громче. Возможно, вы действительно что то путаете. Для отрезания шума используют нойзгейты и экспандеры.
раскрыть ветку (11)
раскрыть ветку (10)
раскрыть ветку (8)

раскрыть ветку (5)
А в чем любовь к наушникам? Не наушники звучать должны, а микс. Наушники это только инструмент
раскрыть ветку (4)
Но согласитесь, что прекрасную музыку хочется слушать в прекрасно звучащих наушниках или с помощью отлично звучащих палочников :) А можно вас попросить порекомендовать отличные миксы? С удовольствием послушаю :)
раскрыть ветку (3)

Гейтом вы отрезаете шум исключительно в тишине, на голосе шум никуда не девается, а компрессор еще снижает с/ш. Ффт-шумодавы вычитают шум из всей дорожки одинаково, не смотря на то, "тишина" ли воспроизводится или речь. Гейт - это один инструмент, а шумодав - другой. И каждый применяется в своих ситуациях. Нельзя сказать, что перфоратор лучше шуруповерта.

раскрыть ветку (37)

Насчет запахов велись исследования. Одно из перспективных направлений — генерация запахов для 5-6D кинотеатров. Но тут вылезла засада. Сгенерировать запах — задача со звёздочкой, но решаема. А вот резко убрать запах — практически невозможно.
раскрыть ветку (28)

Ой, ну нашли проблему. Сделали бы "пустой" запах, да и все. И пускать его в зал, когда надо - чтоб работал, как освежитель воздуха, запах говна перебивая
раскрыть ветку (8)



раскрыть ветку (2)

Отличный план - загнать людей в закрытые комнаты и контрастно поочерёдно хуярить говном с хлоркой.
раскрыть ветку (1)
Продувать сжатым воздухом давлением 15 атмосфер (для верности) кинотеатр с посетителями каждый раз когда нужно убрать запах, делов то)
раскрыть ветку (3)


Если ароматизаторы сделать не на масло-жировой основе, а на спиртовой, то запахи будут быстро выветриваться. Как дым от вейпов. Только для основы нужен не пропиленгликоль, а именно спирт.
раскрыть ветку (12)
Представляю как по кинотеатру прокатывается спиртовая волна, а потом новая и новая и новая... Зрителям в фойе можно не попкорн а сразу закуску продавать. И непонятно что с детскими сеансами
раскрыть ветку (3)
спирт тут только как растворитель выступает. не все спирты воняют водкой. возмите любые духи - вытяжкик растворенные в спирту, с добавлением жировой или масляной основы.
Как дым от вейпов, лол.
Это говно для всех кроме курящего воняет ещё минут 30. А комната где часто курят вообще пропитывается запахом палёных ссаных тряпок навсегда
раскрыть ветку (7)


Это от айкоса, гло и плума. Это другие системы нагрева, табачные. Вейп это система нагрева жидкости с никотином, она и правда довольно легко уходит.
Блять, да не о вейпах речь идет же. Их я для примера привел. Вы вообще читали что я написал или просто увидели слово "вейп" и решили такие "ну вэйпы это вообще вонь, ссанина итд". Ссаниной и тряпками, кстати, не вейпы воняют а стики для СНТ.

Влепить бы тебе побольше минусов!!)) Учи матчасть, вейпы не воняют, а вкусно пахнут,при нужной дозировке вообще еле уловимый запах. Воняет айкос и гло и им подобные.
раскрыть ветку (2)
Ничего от айкоса не пропитывается, а уж от вейпа тем более, если конечно не парить такими облаками что аж глицерин оседает на всех поверхностях
ещё комментарии


раскрыть ветку (6)
раскрыть ветку (5)
Лига На**й убедительно просит не разглашать информацию о наших разработках до официального релиза
раскрыть ветку (3)


раскрыть ветку (1)
Не только ходим, но и отправляем, провожаем, организовываем экскурсии и туры выходного дня. Обращайтесь, будем рады помочь. Нахуй может пойти каждый!


Когда в Фотошопе появятся функции миджорни и т.д.? Что за средние века? Я хочу совмещать картинки и много ещё чего. А пока, что Фотошоп это деревянный дилдак. Который играет в руках профессионала, только.
раскрыть ветку (9)
Фотошоп играет только с очком своих разработчиков.
Эти уебаны даже нормально альфа-канал не могут обрабатывать у png. Элементарная задача - вырезать альфу в чб картинку из png - ощущается как выпадение прямой кишки.
Хотя это та вещь, которая должна одной ебучей кнопкой делаться.
1. в фотошопе давно есть ai
2. для чайников есть другие инструменты, а фотошоп оставьте профи
раскрыть ветку (6)
Нужна функция одно фото пластилиновый домик, второе фото обычный домик. Тыкаешь. Оп и второй домик из пластилина.
раскрыть ветку (4)


ещё комментарии
Ты описал приём для шумоподавления. А есть приём наоборот для добавления шума комнаты. Roomtone по-научному. Используется как раз для маскировки нежелательных артефактов. Грубо если объяснить, то - вытер ненужное из окружения и залил это всё румтоном. Получается естественная картина с, допустим, климатом офиса, но без ненужных деталей. Детали нужные тоже можно добавить.
раскрыть ветку (4)
Да, есть и такое. Но крайне редко, чтобы использовался реальный звук вокруг. Все это обычно берётся чищенное из банков, чтобы не дай бог вдруг случайно не вылез артефакт или вообще полный брак по звук, который все пропустили (типа скрипа какой-нибудь половицы или где-то далеко кто-то матернулся.) А то были прецеденты!!! Всем потом так прилетало.
раскрыть ветку (3)
Не, там идея другая. Нужен не звук всего всего вокруг, а именно монотонная пауза-румтон, равномерный шум тракта/окружения с той же ачх, что и у записанного голоса. Делается это для того, чтобы действительно сделать заплатки, потому что если вы не писались прям в заглушенной студии, где никакого румтона помещения и шума тракта человеческое ухо не услышит, то более выгодный вариант просто проложить паузы между репликами румтоном, чем оставлять дыры без звука вообще, потому что наш мозг так устроен, что мы очень быстро начинаем игнорировать монотонность, но резко на изменения, которыми и будут дыры между репликами - на реплике шум есть, а между - вдруг пропал и это гораздо сильнее будет привлекать внимание.
раскрыть ветку (1)


Самый залайканный коммент. Вот только к посту он не имеет отношения, так человек на скрине однозначно описывает не запись слепка для шумодава, а именно процесс записи чистого фона для подложек, или roomtone как здесь уже верно написали.
Никто в ноль фон комнаты не уводит, если только не нужна сухая запись голоса для последующей обработки при каком-нибудь дубляже или записи вокала. И слепок шума берут в первую очередь чтобы вычесть собственный шум микрофона с примесями из общей записи, но «румтон» по-прежнему необходим, чтобы заменять им посторонние ненужные звуки (звонки, щелчки и тп) на манер инструмента «заплатка» в фотошопе, о чем и рассказывается в самом посте. А вовсе не о шумодаве.
раскрыть ветку (2)
Как не крути, пост - говно. Скорее всего еще и переебаны все слова звуковика, чтобы выставить его дебилом.

Даёшь собаке понюхать то, что надо искать. А она всё-равно ест говно.
Вот такая вода на вкус!
Вот хоть кто правильно разбил все по полкам. В принципе так же и наушники с активным шумодавом работают. Берут за эталон слепок шума окружения и кидают его в противофазу к сигналу с устройства, грубо говоря
раскрыть ветку (41)

раскрыть ветку (36)

раскрыть ветку (35)

В шумодавах используется микрофон, который ловит шум и на лету добавляет к нему противофазу.
раскрыть ветку (27)
раскрыть ветку (22)

Нет. Разница в фоновом шуме. Если фон пропадает, слушатель это замечает. Но если с фоном ничего не происходит, он остаётся незаметным, как и должно быть. Это явление психоакустики, так наш мозг воспринимает информацию. Если человека поместить в абсолютно изолированную от шумов комнату, он достаточно быстро начнёт нервничать и почувствует себя плохо.
А шумоподавление в наушниках - обращённая фаза. Перевернутый в фазе сигнал сливается с исходным шумом и они взаимовычитаются.
А шумоподавление в наушниках - обращённая фаза. Перевернутый в фазе сигнал сливается с исходным шумом и они взаимовычитаются.
раскрыть ветку (8)

Круто, только к чему вся первая часть?
По факту, мы имеем два случая:
в первом наушники в реальном времени пишут "фон" и вычитают его противофазой, чтоб ты его не слышал.
Во втором звукооператор записывает фон заранее и потом точно также вырезает его из записи (вычитает), чтоб слушателю он не мешал.
Так в чём разница, кроме того, что одно налёту, а другое с записью делается?
По факту, мы имеем два случая:
в первом наушники в реальном времени пишут "фон" и вычитают его противофазой, чтоб ты его не слышал.
Во втором звукооператор записывает фон заранее и потом точно также вырезает его из записи (вычитает), чтоб слушателю он не мешал.
Так в чём разница, кроме того, что одно налёту, а другое с записью делается?
раскрыть ветку (3)
Да, если совсем втупую сравнивать, то действительно - разница только в том, что одно выполняется "на лету", а второе уже на постобработке. Но из-за изменения подхода, полностью меняется и сама схема работы:
В случае постобработки звука, выделяется некий кусочек фонового шума, который удаляется из оригинальной записи. Как пример - выделяется шум вентиляторов от ПК, и вырезается из звукозаписи. Однако, если в какой-то момент, на записи появится ещё и шум пылесоса - его нужно будет отдельно выделять и удалять. По сути - это ручная работа, в которой именно редактор определяет - что такое шум, а что - всё остальное.
В случае динамической обработки, у нас такого варианта нет вообще. Обычно, шумодавы в наушниках работают по следующему принципу: есть определённый диапазон частот, которые глушить не нужно - обычно это частоты голоса. И вот всё, что находится за их пределами считается шумом априори. Т.е. возвращаясь к случаю с шумом вентиляторов и пылесосом. И то и то будет автоматически распознано как шум, в следствие чего - заглушено автоматически и сразу. Но, проблема такого подхода в том, что зачастую так работает только в теории, а на практике, большинство этих шумов будет проходить тупо потому, что они недостаточно громкие, чтобы алгоритм их однозначно оценил как шум. Всё зависит от настроек выставленных производителем, который хоть и будет стараться сделать максимально универсальную вещь, но по итогу - это будет в любом случае работать хуже ручного удаления.
раскрыть ветку (2)
Да вроде точно та же схема, только в одном случае шум убирается руками и можно предусмотреть все нюансы, а в другом компьютером с общим алгоритмом.
раскрыть ветку (1)
Он прав, в случае активных наушников у вас вычитается когерентные сигналы, то есть точно такой же сигнал. А в случае постобработки, используется короткий кусочек фонового шума, т.е. его тональный окрас, это не одно и тоже. Простой вычет противофазой работает только тогда, когда сигналы одинаковые(когерентные). А на постпродакшене используется другой алгоритм очистки из файла фонового шума

А что значит взаимовычитаются? Как можно взаимовычесть звук? Звук не бывает же отрицательным.
раскрыть ветку (3)

Звук это цикличные уплотнения и разрежения среды (например воздуха). Если генерировать разрежение в моменты когда приходит уплотнение, и наоборот, то плотность среды практически не будет изменятся, т.е. звука в итоге не получится
раскрыть ветку (1)
Нет суть в "удаление" и "шумоподавление". Это несвязанные между собой термины. Удаление звука и так понятно как работает, однако можно это сделать только в постобработке записи звука, а с реальным звуком так не получится. А вот шумоподавление это реальный феномен в физике который использует свойства волн. Если условный "шум" толкает молекулу воздуха вправо, а наши наушники генерируют такую волну, которая толкает молекулу влево, то в итоге у нас молекула стоит на месте и волна гасится, а звук = волна и мы ничего не слышим. Если на пальцах, то примерно так.

раскрыть ветку (12)
Ну если математикой эти две волны сложить, то в чём будет отличие от удаления? Я так понимаю разница только в том на каком этапе мы удаляем, перед генерацией волны или за счёт генерации двух противофазных волн.
раскрыть ветку (1)
Если вы сидите в квартире и разговариваете с другом и у вас сверлит стену сосед, то в случае удаления звука и воспроизведения чистого диалога с колонок, вот вам это нихуя не поможет, а шумоподавляющие уши на вас позволят слышать даже тихий голос, чуете разницу?)
2 - 2 = 0 (вырезание шума)
2 + (-2) = 0 (наложение противофазы при шумоподавлении)
В чём вы тут разницу увидели?
2 + (-2) = 0 (наложение противофазы при шумоподавлении)
В чём вы тут разницу увидели?
раскрыть ветку (6)
Разница в том, что шумодав по паттерну это не 2 - 2, а 2 - «чё получилось» т.к. шум и звук меняются.
Поэтому его жирно смазывают гейтом и при изменении звука появляется… шум.
Например, при записи речи будет тишина, но слова будут с лёгким шумом на фоне.
А при динамическом паттерне - глушатся любые звуки. Т.е. 2 - 2.
Например, при записи речи будет также глушится речь.
Поэтому статика хорошо для звукозаписи, а динамика - на стройке.
раскрыть ветку (5)
раскрыть ветку (4)
Я говорю о том, что шумоподавление по паттерну оставляет грязь и немного портит оригинальный звук из-за несовпадения формы волны.
А шумоподавление противофазой (как в яблоидных наушниках) глушит вообще всё (в идеале - даёт полную тишину).
Теперь возьмём задачу - запись речи на стройке, где кроме речи появляется много лишних, нестабильных шумов (пневматическое оборудование, голоса рабочих, удары молотком).
Если давить такое профилем "шума тишины" - прочие звуки-стуки не будут удалены.
Если давить профилем случайного фрагмента той же записи - часть звуков останется.
Но можно сделать запись двумя микрофонами.
Первый у рта, а второй - в стороне.
Первый будет записывать голос + шум, а второй - только шум.
Тогда можно использовать запись со второго микрофона в противофазе (если подогнать амплитуду) чтобы сильно ослабить шумы на записи почти без повреждения записи голоса.
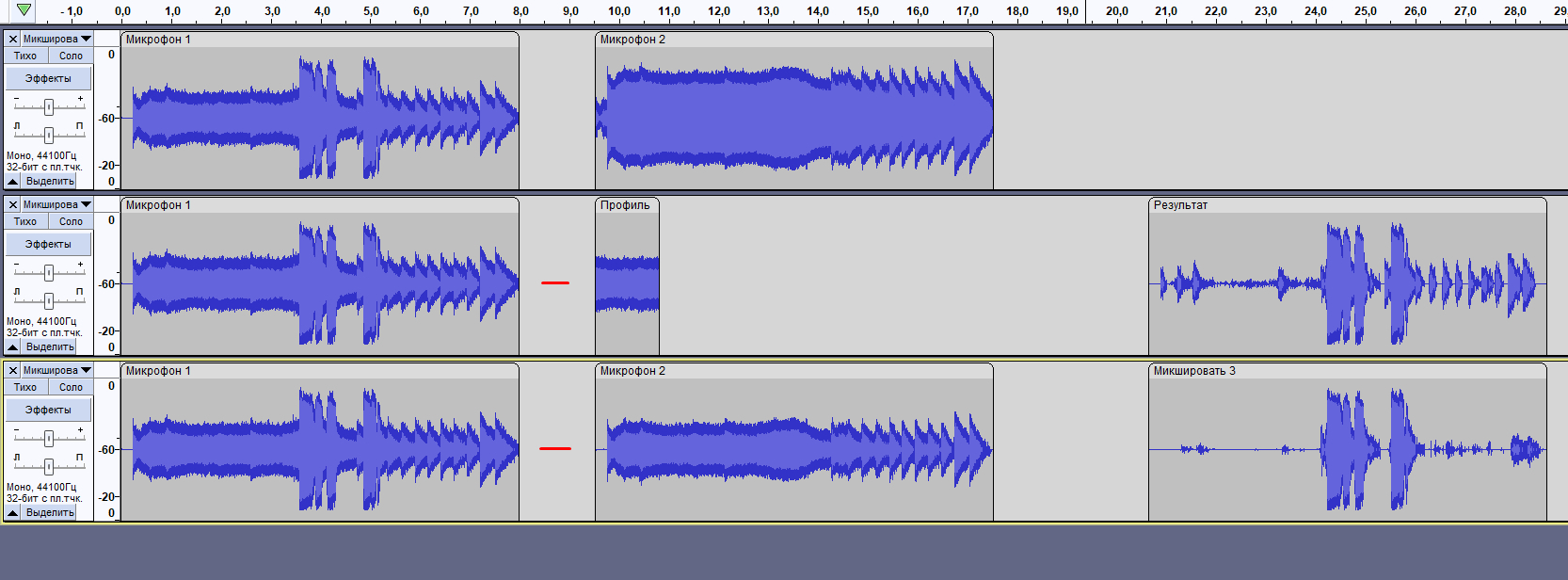
Вот для примера:
1 дорожка - оригинальные записи (слева - основной микрофон, справа - второй, для записи шумов).
2 дорожка - шумоподавление по профилю (взят фрагмент с работающей УШМ).
3 дорожка - шумоподавление противофазой второго микрофона.
4 пика в ~середине клипа - речь.
На 2 дорожке видно, что профиль шума хорошо справился с УШМ, но не удалил удары молотка (что логично).
На 3 дорожке - противофаза второго микрофона отлично справилась как с УШМ, так и с молотком.
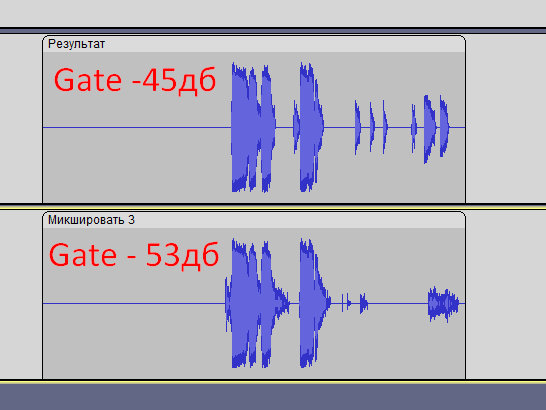
Если полирнуть оба результата гейтом - на второй дорожке потребуется порог больше -45дб, чтобы отрезать шумы.
На третьей дорожке - порог будет от -53дб и качество голоса почти не пострадает.
раскрыть ветку (3)
раскрыть ветку (2)
Худшее, что при такой записи может случиться - это разность реверберации в разных частях комнаты, которая даст сдвиг фаз и снизит эффективность глушения противофазой, убрав только часть частот. Так что такой способ по-определению требует программной обработки, чтобы подгонять сдвиг и амплитуду. А там вопрос фазировки решается одним кликом мышки.
раскрыть ветку (1)
Мужик, аналогии не твоё. Если спектр шума в диапазоне спектра голоса, ничего ты там не отфильтруешь и не удалишь... Железо не отличит единичную амплитуду шума от амплитуды голоса, ибо и то и то звук.
раскрыть ветку (2)
1) шумоподавление считывает весь шум снаружи наушников и насрать голос это или что-то еще.
2) Даже если не фильтруется голос это исключение, а принцип такой, как я описал, что и требовалось объяснить, так что пример норм. (у меня там вообще не было аналогий, лул)
Критика видимо не твое. Ну и на последок: не нравится, сделай лучше?
Существуют алгоритмы, которые способны отфильтровать шум, даже если он частотно совпадает с голосом. Если в одинаковой частоте у тебя и шум и полезный сигнал, они складываюсь, образуют суммарную амплитуду. И если будет достаточный сэмпл фонового постоянного шума, его будет возможно вычесть из суммарной амплитуды

Интересно, а если включить на внешнем устройстве ту же музыку, что и в наушниках, в тот же такт и подобрать громкость, то я получу почти тишину?)
раскрыть ветку (3)
раскрыть ветку (1)
Ну, так внешний в противофазе, наложенный на внутренний должен дать..не тишину, конечно, но сильное затухание. Почему нет?
раскрыть ветку (6)
Нет, из первого коммента не понятно, в чем принципиальные отличия от шумодава, можно предположить что они работают одинаково, что и сделал lzutoma. Мне тоже не очевидно в чем отличия.
upd: ниже объяснили #comment_267554073
ещё комментарии
раскрыть ветку (4)
раскрыть ветку (3)
Вы спросили в чем принцип работы удаления шума по сэмплу, а не почему шумодав наушников здесь непременим.
раскрыть ветку (2)
раскрыть ветку (1)
Ну вот жездесь совсем другой принцип
объясни тогда какой
Потом да, вы спросили про отличия.
ещё комментарии
ещё комментарии

Не, здесь просто вычисляется интегральный спектр шума и его флуктуации от помещения, микрофона, усилителей, в общем всего тракта. А потом его отнимают из общего спектра сигнала, но это делается динамически, т.е. если определенная спектральная полоса сигнала (например 1000 Гц +/- 10 Гц, зависит от разрешения FFT) в данный момент времени достаточно мощная, чтобы замаскировать шум, то в данной полосе его можно не отнимать. Т.е. получают в итоге "чистый" звук, на который уже впоследствии можно наложить что угодно. А в системах шумоподавления действительно используют фазовый метод подавая в противофазе внешний шум с микрофона (там не так однозначно, т.к. АЧХ и ФЧХ имеет не плоский график и фаза не всегда вращается на 180гр. на всех частотах), но от собственного шума системы это не избавляет.
раскрыть ветку (3)


Смотря какой сценарий. Если нужно вычистить шум, то 20 секунд - это прям эпично, обычно в материале достаточно пауз, чтобы их пролернить, буквально 1-2 секунды. А вот если это кино, например, то да, там скорее нужен румтон, который прокладывается между репликами, потому что наш мозг так странно устроен, что тихий равномерный шум он очень быстро перестанет слышать, а вот исчезновение этого шума, которое есть на реплике, но без румтона его не будет между репликами будет замечать гораздо отчётливее. Короче, монотонность меньше внимания привлекает, чем изменения
раскрыть ветку (4)
>>Короче, монотонность меньше внимания привлекает, чем изменения
Устал
@
Засыпаешь в шуме (тв, разговоры, машины за окном)
@
Крепеко спишь
@
Приходит добрая душа
@
Заботливо выключает тв/закрывает дверь/окно/выгоняет народ из комнаты
@
"не шумите пусть поспит"
@
Мозг фиксирует резкое изменение окружающей обстановки
@
ПАНИКА!!ПОДЪЕМ!! СРОЧНО!! АДРЕНАЛИН!!
@
Поспал, блять.. спасибо, нахуй.
раскрыть ветку (2)
Для такого в аудио существует такая штука как фейдаут, чтобы изменения были, но более плавные и тогда мозг на них не особо фокусируется. Идеальный вариант в вашем случае - сначала сделал телевизор потише, люди стали разговаривать менее громко, окно не закрыл, а подприкрыл, а потом уже все плавно стихает, окно закрывается, телевизор выключается окончательно и тишина, и вас не разбудили)
А вообще, кстати, в современных реалиях и с машинным обучением зачастую можно даже без профиля шума обойтись. Вон, в 7м уже кажется iZotope RX появился модуль dialogue isolate, который просто достаточно неплохо умеет отделять речь от всего остального, а в 9м RX ему алгоритм переписали, так что теперь он стал ещё круче, бывает даже шурши одежды с петличек неплохо убирает. Хотя прям совсем панацеи нет.
В анэхоической комнате (anechoic chamber, пардоньте мой французский) можно достичь абсолютной тишины. Под абсолютной я понимаю такой уровень шума, который ниже, чем чувствительность вашего микрофона. Но с ухом человека есть проблема - в тихой комнате, после адаптации, человек начинает слышать течении крови в ухе и свой пульс. От такого шума не избавиться.
раскрыть ветку (16)
Человеческое ухо может чувствовать давление 10¯5 степени Паскаля. Это почти тепловой шум молекул воздуха. Но мы начинаем слышать собственный организм, сердце и кишечник. ( Алдошина)
раскрыть ветку (4)

раскрыть ветку (2)


Алдошина Ирина Аркадьевна - профессор кафедры звукорежиссуры Санкт-Петербургского Гуманитарного университета профсоюзов, доктор технических наук.


От такого шума не избавиться.Почему, достаточно человеку остановить сердце и он больше не будет слышать течение крови в ухе и свой пульс
раскрыть ветку (2)



По незнанию думал, что подобное помещение называются "сурдо-камерой". Однажды довелось побывать в такой как на фото, только гораздо-гораздо меньшей по размеру. Пульс свой не слышал, но ощущения внутри были весьма странные: не хотелось там долго задерживаться.

раскрыть ветку (2)




На самом деле это не обязательно так. Интершум можно использовать и как написали вы, и как подложку для склеек по звуку ( скрыть их). Например плавно ввести закадровый голос, который записан в другом помещении, переписать вопрос журналиста который оговорился в процессе интервью (несколько слов запросто), создать атмосферу под несколькими перебивками с этого помещения без склеек по звуку и тому подобное. Очень полезная штука, не только в плане шумоподавления.

раскрыть ветку (22)

Нет. Не накладывается. Потому что природа волн в шуме такова, что нужно отделять определенное количество волн, которые соответствуют структуре шума по частотам и по энергии, которую они несут, а не по фазе. Нельзя просто взять слепок шума, инвертировать его и наложить на другую запись. Иначе в этом случае получится еще больше шума.
раскрыть ветку (21)
раскрыть ветку (20)
раскрыть ветку (19)
Неужели никогда не слышал про "белый шум" или "розовый шум"?
Цветом описывается равномерность спектра шума.
раскрыть ветку (9)

раскрыть ветку (7)

раскрыть ветку (6)
раскрыть ветку (5)
Именно. Свыше 50 процентов пациентов, способных прослушать 8 часов этой записи без перерыва, бегут на горшок. Остальных легко добить 12-часовой записью.
Главное, не включать голубой шум, а то мало ли.
раскрыть ветку (3)
Поговаривают, что если включить голубой шум, то мир становится розовым, т.к. коричневые нотки своё дело делают.
раскрыть ветку (2)
Нет, запаха нет. А цвета есть.
Одногруппник рассказывал, лет 15 назад. Накурили его в первый раз шишками через водник. Поехали они на 6ке по посёлку кататься. Пацанская тачка, булка из скотча и Дина из 90ка. Говорит накрыло так, что музыку смотрел.
раскрыть ветку (6)

раскрыть ветку (5)
раскрыть ветку (4)
раскрыть ветку (3)
Есть глюки, а есть непонимание какого юга происходит в первый раз. +течение мыслей меняется.
раскрыть ветку (2)
ещё комментарии

Всю жизнь занимаюсь съемками и монтажом новостных репортажей. Первый раз об этом слышу.
раскрыть ветку (1)

Потому что вы занимаетесь репортажкой и броадкастом где запись в студии или на хорошую технику, еслиб занимались подкастами/видео/рекламным продакшеном вам бы часто приходилось чистить начитку в случаях когда диктор записывался на у компа и от него слышен куллер или исходник записан на херовую технику.

Прикольно, мне кажется вы шарите, поэтому спрошу у вас, а такие штуки можно делать только в супер-пупер сложном софте или есть версия для любителей? =)
Нужен ли под это дорогущий микрофон или достаточно чтобы он был такой же, как на записи самого видеоролика (к примеру).
Это совсем не моё занятие, но я например однажды ради интереса научился в AAE фишке с MotionTrack, я это конечно же нигде не применяю, но мне понравилось изучать это =)
Так и тут захотелось попробовать такое сделать - просто ради сделать =)
Если такой софт +- понятный НЕзвуковикам есть, скажите название плиз, а найду сам уже.
раскрыть ветку (3)



Ну так с водой тоже самое! Абсолютно чистой воды не бывает. И вот эти добавки и дают ей вкус.
раскрыть ветку (1)
Абсолютно чистая вода бывает, она называется дистиллированная) А вообще, как человек учившийся на инженера по специальности водоснабжение и водоотведение, я вам скажу, что вода хорошего качества не должна иметь цвет, запах и вкус
справедливости ради, фоновый шум применяется и для описанного в посте. Если запись ведётся в хороших условиях и на хорошем (совсем не обязательно дорогом) оборудовании, то шумовычитание может и не требоваться.
Я примерно так же делал, когда старую звуковую дорожку крепил к аниме. Выбрал тихий участок на дорожке (секунд 5) и применил ко всей дорожке.

Какой бюджет вас замечательный (amazing) комментарий. Он содержит (contains) в себе полезную (useful) информацию (information).

Это интересно
891 пост1K подписчик