

ГЫЧА
1 пост
1 пост
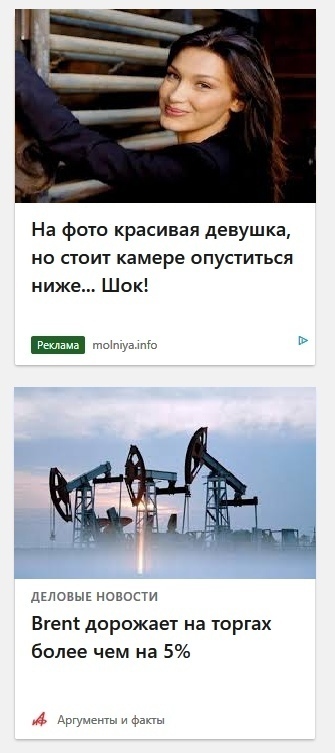

Исследователи из UC Berkeley обучили робота имитировать поведение собаки с помощью обучения с подкреплением. Предложенный фреймворк масштабируется на другие виды животных. Модель получает на вход видеоролик с записью движения животного. На основе входного ролика RL-агент выучивает политику контроля движений, которая позволяет ему имитировать движение. Поддержка других видов движения добавляется аналогично. Исследователи обучили RL-агента выполнять такие действия, как поворот, быстрая ходьба и прыжок. Политики агент выучивает в симуляции. Затем модель переносится в реальный мир с помощью метода адаптации скрытого пространства, который позволяет адаптировать политику к реальной среде на основе коротки видеозаписей реального робота.
Ниже - описание самой научной работы в формате видео
Архитектура фреймворка
Предложенный фреймворк состоит из трех этапа:
1. Переоценка движения, во время которой движения животного на входной видеозаписи соотносятся с движениями робота;
2. Имитация движения, когда выход из первого этапа используется для обучения политики имитации движения агента;
3. Адаптация к реальной среде, когда обученная модель из симуляции переносится на реальную среду
В качестве робота использовали модель четвероногого робота от Laikago.
Проверка работы алгоритма
RL-агент способен выучивать различные типы движений собаки. Среди типов движений — разные виды ходьбы, включая бег рысью или неспешный шаг, и быстрые повороты. Если обучать агента на видеозаписях с ходьбой, отмотанных в обратную сторону, то робот научается ходить назад.


Сравнение поведения до и после обучения робота: до адаптации робот склонен к падению в ходе выполнения задачи; после же тот готов последовательно исполнять предлагаемые команды.

Исследователи опубликовали датасет с неструктурированными изображениями культурных объектов. Он включает в себя 25 тысяч изображений, каждое из которых содержит информацию о местоположении и наклоне. Данные собирали из открытых источников в интернете. Датасет создавали в сотрудничестве с UVIC, CTU и EPFL.
Восстановление 3D структуры зданий
Реконструкция 3D объектов и зданий из последовательности изображений (Structure-from-Motion) — это одна из открытых проблем компьютерного зрения. Одним из применений таких моделей является возможность изучения культурных объектов в браузере.
Google Maps уже использует изображения пользователей для обновления списка популярных мест или рабочих часов места. Однако использование такого типа данных для построения 3D моделей является более сложной задачей. Это связано с тем, что поступающие изображения имеют большую вариативность в том, с какой позиции снимали кадр, перекрывали ли люди объект на кадре и какие были погодные условия и освещение.
Что внутри датасета
Опубликованный датасет включает в себя 25 тысяч изображений из датасета YFCC100m. Каждое изображение имеет данные о позе (локация и направление). Исследовали сгенерировали тестовые 3D модели с помощью крупномасштабной SfM модели, которая использовала от сотен до тысяч фотографий здания для восстановления формы объекта. Такой подход не потребовал использования сенсоров или человеческой разметки для сбора данных.

3D форма объекта (Фонтан Треви), которую восстановили из 3 тысяч фотографий
Всем добрый вечер!
Объявляется сбор тегов, пострадавших от нехватки символов. То есть, название какой-либо сущности оказалось обрезанным вследствие тегового ограничения в 30 символов.
За помощь @editors в этом нелегком деле полагается наш личный респект. И, к сожалению, ничего боле.
Сделаем навигацию по Пикабу красивенькой и удобненькой :з
Нерелевантные комментарии = флуд.
Пример:
Иван Васильевич меняет професс
Гарри Поттер и философский кам
Гарри Поттер и Принц-полукровк

StyleGAN2: улучшенная нейросеть для генерации лиц людей
Встречаем StyleGAN2 — вторую версию нейронной сети, которая создает реалистичные изображения людей и предметов. Пока мы стебались над тем, кто она не умеет воспроизводить человеческие уши и волосы, нейросеть качалась.
После просмотра результатов обучения как-то уже несмешно.
Протестировать работу нейронной сети - thispersondoesnotexist.com

В StyleGAN2 обновили архитектуру модели и методы обучения, чтобы минимизировать количество артефактов на генерируемых изображениях. Артефакты — это части изображения, которые снижают его реалистичность. Примером артефакта является размытость части изображения.
В частности, исследователи добавили измененные нормализацию генератора, регуляризацию генератора и прогрессивное повышение (progressive growing). Добавление регуляризатора в генератор решает проблему качества изображений и позволяет распознать изображения, которые были сгенерированы определенной нейросетью.
StyleGAN
Предыдущей state-of-the-art архитектурой для генерации изображений являлась StyleGAN модель. Отличительной чертой модели является архитектура генератора. Генератор принимает на вход промежуточное представление входного объекта. Слои генератора проходят через адаптивную instance нормализацию (AdaIN). Несмотря на высокие результаты по сравнению с конкурирующими подходами, оригинальная StyleGAN генерирует изображения с заметными артефактами.
StyleGAN2
В генераторе StyleGAN2 были убраны излишние операции в начале, вынесли суммирование bias термов за пределы блока стиля. Обновленная архитектура позволяет заменить instance нормализацию (AdaIN) на “демодуляцию”. Операция демодуляции применяется к весам каждого сверточного слоя.
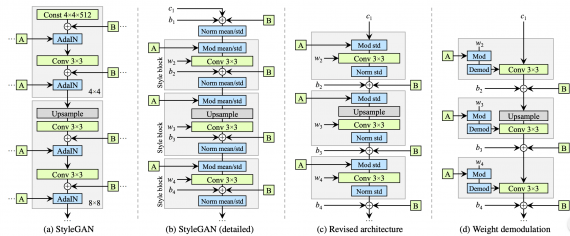
Сравнение составных частей StyleGAN (a-b) и StyleGAN2 (c-d)
Оценка работы модели
Для сравнения качества сгенерированных изображений исследователи использовали стандартные метрики: Frechet inception distance (FID) и Precision and Recall (P&R). Ниже видно, что внесенные в архитектуру StyleGAN изменения (B-F) улучшают качество изображений.

Сравнение результатов базовой StyleGAN и ее модификаций на датасетах FFHQ и LSUN Car
В браузере Google Chrome есть игра с динозавриком. Когда нет интернета, браузер показывает такое:

Если нажать на пробел, то динозаврик оживёт, и ваша задача — управлять им с помощью пробела (прыжок) и стрелочки вниз (присесть), чтобы не сталкиваться с препятствиями.
Недавно в Chrome добавили возможность поиграть в эту игру даже с интернетом: вбейте в адрес chrome://dino
Программист из Австралии по имени Эван (на Ютубе — CodeBullet) написал нейросеть, которая сама играет в эту игру, и выложил об этом видео:
Спойлер: в конце ИИ просто рвёт игру на части.
Давайте по шагам разберём, что он сделал и что у него получилось в итоге. Сам ролик на английском, поэтому, если вы не знаете английского, считайте эту статью смысловым переводом происходящего.
Создание игры
Можно научить ИИ играть в игру, просто глядя на экран и анализируя всё, что там происходит. Но тогда быстродействие ИИ будет ограничено скоростью работы экрана, то есть на каких-то сверхскоростях ИИ играть уже не сможет. А мы хотим играть на сверхскоростях, поэтому эффективнее будет встроить ИИ прямо в игру.
Пол и прыгучий персонаж. Чтобы попробовать первую версию игры как можно быстрее, Эван не рисует динозавра, а делает вместо него прыгающий прямоугольник. С поверхностью то же самое: простая линия вместо дороги с перспективой и песком в случайных местах. Единственное, что пока можно в игре — прыгать прямоугольником на месте:
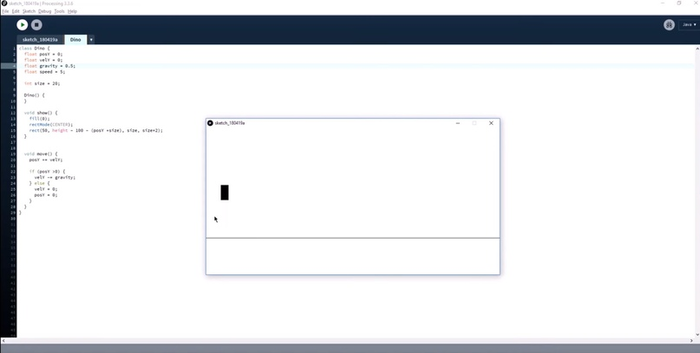
Кстати, если вы обратите внимание на игру в Chrome, то заметите, что хотя динозаврик (по ощущениям) бежит по земле, на самом деле его координата X на экране не меняется. Можно представить, что это не динозаврик бежит, а кактусы летят на него со всё более высокой скоростью. Иллюзия!
Движение и препятствия. На следующем шаге Эван делает так, чтобы на динозаврика двигались кактусы. Но кактусы тоже рисовать долго, поэтому снова берём прямоугольники. Сначала делаем их маленькими и смотрим, что происходит:
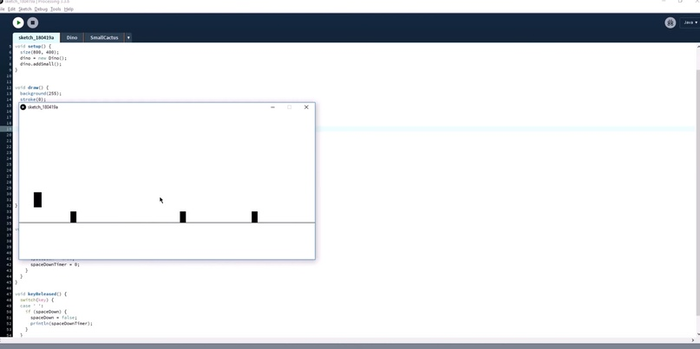
Пока всё хорошо: персонаж прыгает, прямоугольники двигаются. Можно сделать следующий шаг — добавить кактусы разной высоты и ширины, как в оригинальной игре. И снова это всё ещё прямоугольники:
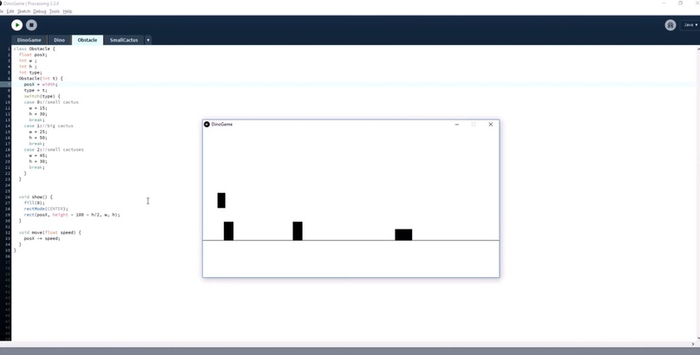
Смерть от кактусов. Последнее, что делает Эван — добавляет в игру условие, что как только персонаж коснулся кактуса, то умирает. Это делается просто проверкой пересечения границ одного и второго объекта. Коснулся кактуса — всё исчезло:
Теперь всё готово для первой версии, можно поиграть и проверить, всё ли там происходит как надо.
Эван не начал программировать сразу всю игру с динозаврами, графикой и красивыми кактусами. Вместо этого он сделал макет игры и физику; потом убедился, что всё работает; и только после этого заменил прямоугольники на динозавра и кактусы, а линию на полу — на дорогу с песком. Всё это он просто вырезал из игры и вставил в свой проект:
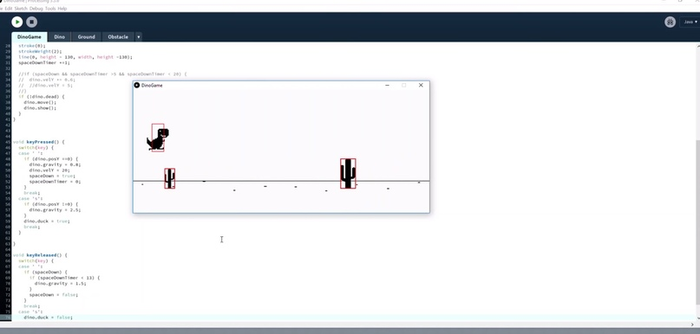
За кадром осталось то, как Эван делал птиц: они могут летать низко, повыше или совсем высоко. Но мы уже понимаем, что сначала это был прямоугольник выше линии, а потом его заменили на картинку с птицей.
Динозаврику тоже пришлось научиться пригибаться — прямоугольник, который уменьшал свою высоту, превратился в пригибающегося динозаврика:
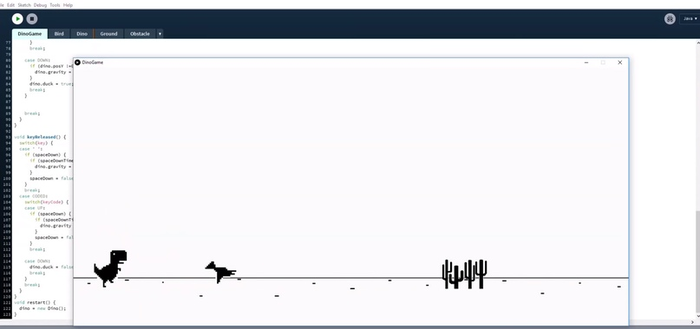
Нейросеть
Когда игра готова, можно к ней прикручивать искусственный интеллект. Для этого Эван пишет простую самообучающуюся нейросеть, которая работает по принципу обучения с подкреплением. Это значит, что ИИ сначала ничего не знает о мире, в который его поместили, и его задача — определить для себя правила, которые помогут играть в игру как можно дольше.
Если очень коротко, то это работает так:
- делают первое поколение сети;
- запускают её в игру и смотрят результат;
- те версии первого поколения, которые показали наилучшие результаты или дольше всех играли, остаются, а остальные убираются;
- эти удачные версии снова запускают в игру и тоже смотрят, какие из них покажут наилучший результат;
- новых везунчиков оставляют, остальных убирают, и всё повторяется до тех пор, пока ИИ не научится полностью проходить игру.
Первая версия ИИ, которую сделал Эван, просто прыгала случайным образом, и, если повезёт, то перепрыгивала кактусы:
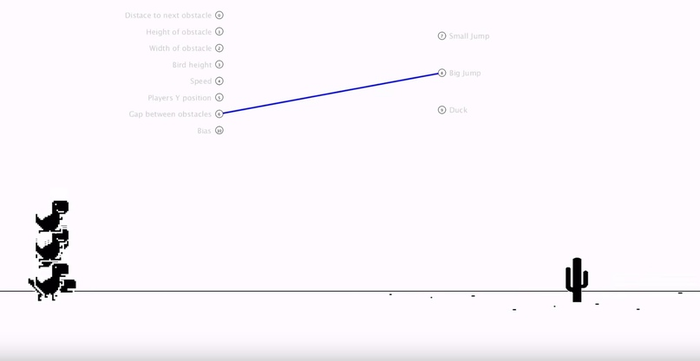
Синяя линия — связь между параметрами игры и действием динозаврика. Пока всё примитивно.
У первых нескольких поколений ИИ была примитивная тактика: просто прыгаешь и надеешься, что интервал прыжков совпадёт с расстояниями между кактусами. Это не сработало, поэтому к седьмому поколению нейросеть нашла взаимосвязь между расстоянием до препятствия, расстоянием между препятствием и моментом, когда надо подпрыгивать:
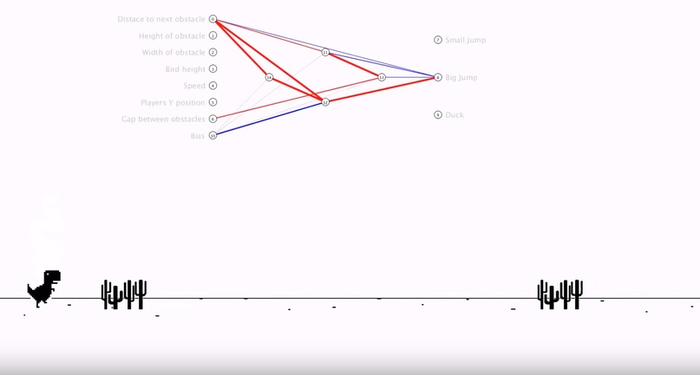
Цветные линии вверху — это связи внутри нейросети в упрощённом виде. Видно, как одни параметры начинают влиять на другие.
Теперь ИИ умеет дожидаться, пока кактусы не окажутся достаточно близко для прыжка, вместо того чтобы перепрыгивать их случайным образом.
Интересный момент: так как Эван использует самообучающуюся нейросеть, то мы можем заметить, как в некоторых моментах динозаврик раздваивается или распадается на множество частей.

Это связано с тем, что ИИ постоянно проверяет, что лучше: прыгнуть чуть раньше или чуть позже. И если какая-то стратегия даёт результат лучше, чем у остальных вариантов — ИИ делает эту стратегию базовой и в следующем поколении опирается уже на неё.
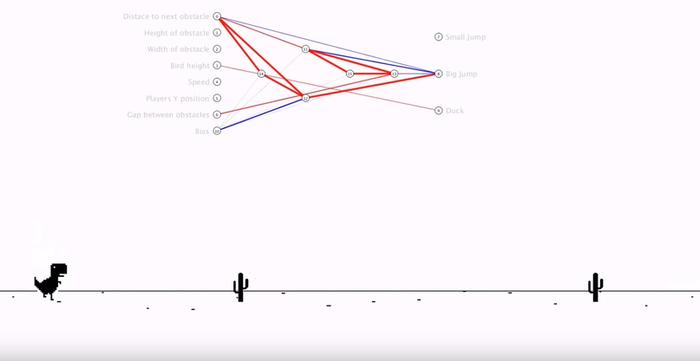
25-е поколение — здесь появилась реакция на низко летящего птеродактиля (в авторском тексте значится утка): нужно пригнуться.

40-е поколение — связи поменялись, чтобы приспособиться к высокой скорости игры, когда кактусы за секунду пролетают от одного края до другого.

43-е поколение — визуально отличие не сильно заметно, но некоторые линии в связях стали толще. Это значит, что одни коэффициенты и параметры стали сильнее влиять на другие.
Финал
К сорок третьему поколению нейросеть Эвана научилась играть в динозаврика с такой скоростью, которая выходит за пределы человеческих возможностей. Именно для этого и используют ИИ — чтобы помочь человеку справляться с задачами ещё лучше, чем он это делает сейчас.
Есть и другие
На Ютубе много примеров, как нейросети учатся играть в эту игру. Подходы существуют разные, но чаще всего вы увидите какие-то эволюционные или генетические алгоритмы, смысл которых в одном: случайным образом мутируешь много исходных персонажей, проверяешь их, отбираешь лучшего, потом делаешь ему копии и случайным образом мутируешь их. И так шаг за шагом, поколение за поколением удачные мутации укрепляются, а ненужные пропадают.
Так как машины могут прогонять поколения очень быстро, буквально за секунды, за несколько часов можно обучить нейронку какой-нибудь несложной игре, даже если она не знает её правил. А за дни, недели и месяцы можно обучить и более сложным играм.




