Ответ на пост «Без рейтинга. Самообучение PHP или курсы»1
По PHP не подскажу. ЯП много и выбор в целом не однозначен. Но выбирать технологию следует с оглядкой на
1. популярность. Чем популярнее, тем больше мануалов, помощи везде и всё такое
2. сообщество. Мануалы нужны хорошего качества, иначе найденные решения будут учить плохому
3. применимость. У каждого инструмента своя область
по пункту 1 можно ориентироваться на рейтинги. Сами по себе рейтинги мало что говорят, но вот динамика подсказывает. Смотрим TIOBE. На скрине ниже выделены python, java и PHP.
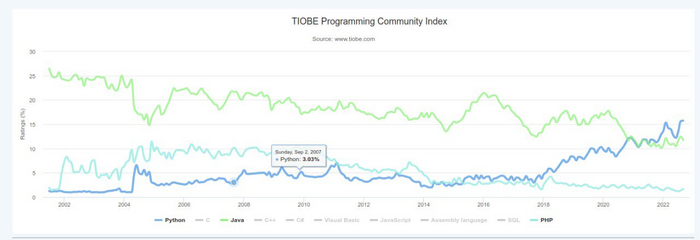
Нисходящий тренд PHP должен вызывать настороженность. Стоит ли выбирать инструмент, у которого было 10% рынка, а теперь 1.5?
более того, по пункту 2 - сообщество у PHP большие проблемы. В плане там слишком много legacy, очень много плохих подходов, переход на PHP7 вызвал большой раскол и вообще всё не очень хорошо. Имеет смысл идти в PHP, только если у вас есть хороший ментор. Перенять крутой опыт в любой технологии полезно.
Про курсы. Материала куча всякого разного. Рекомендую ориентироваться на крутые книги, добавлять статьи + видеоматериалы по теме. Можно посмотреть на бесплатные или недорогие платные курсы. Курсы типа за 120к в целом имеют мало смысла.
Наверное, 80% успеха в изучении - это самостоятельная работа. Ещё 20% заложено в обратную связь, когда вам покажут на ошибки. Прикол в том, что на больших образовательных площадках обратную связь дают далеко не профессиональные разработчики. Посмотрите вакансии тех, кто проверяет домашку, например, по запросу "<площадка> наставник", речь про зп в районе 30-55к в месяц.

Материалы в платных курсах могут быть далеко не выдающиеся по уровню. Можно наткнуться на плохой платный курс и на хороший бесплатный, и наоборот.
Небольшая подборка бесплатного материала по Python для старта:
1. Классическим хорошим курсом из бесплатных считаются Поколения Python на stepik для начинающих и для продвинутых.
2. На ютубе есть годные лекции Тимофей Хирьянова из МФТИ.
3. Python: основы и применение на stepik
4. Не питоном единым, поэтому надо ещё и немного в базы. Можно посмотреть на Интерактивный тренажер по SQL
5. Освоить git, достаточно 4 глав из книги Pro Git
Можно пойти на codewars и leetcode для закрепления умения программировать. Когда сложилось базовое понимание происходящего, рекомендую переключаться на книги типа Лутца (двухтомник, нужно свежее 5 издание 2019-2020 годов) и идти по ней. Книга большая и достаточно сложная, но покрывает много важных деталей. Можно читать не всю, а главами или разделами по непонятным темам.
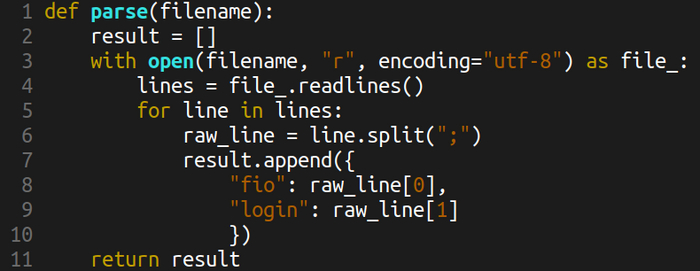
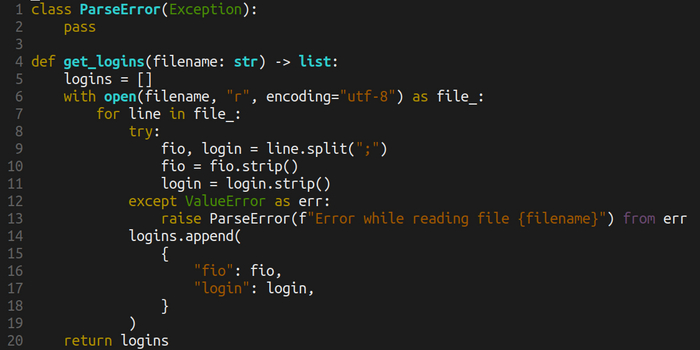
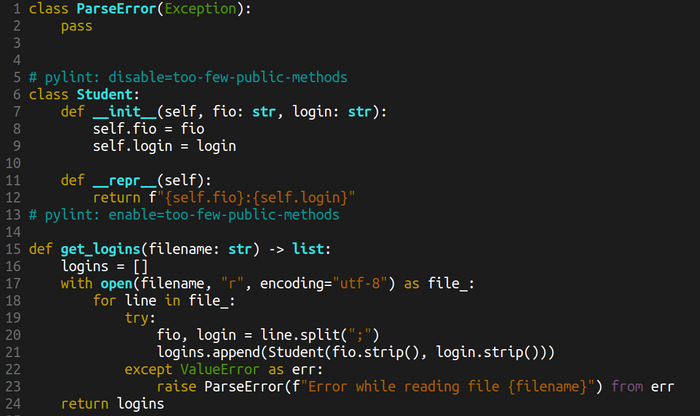
Когда появился некоторых опыт, можно выбирать подходящий курс или проект, на котором получать последующий опыт. Например, можно повторить мой часовой стрим по созданию небольшого проекта на python с нуля до небольшого логического завершения.
А дальше нужно писать как можно больше кода, периодически осматриваясь вокруг. Разработка - это не только язык, это ещё библиотеки, фреймворки, разные инструменты, тесты, проектирование архитектуры, командная разработка, получение задач через bug tracker, работа с ветками в git и вообще flow разработки, CI/CD и ещё много всякого разного.
Одним из источников кругозора может быть телеграмм-канал devfm, где разбираются разные нюансы из жизни разработчика на Python и не только — python, bash, linux, тесты, командная разработка.