Завершить серию постов тему собеседований хочется практической задачей. При поиске товаров на любой торговой площадке мы видим разухабистые возможности фильтрации товаров. Ваша задача — спроектировать функционал фильтрации результата поиска товаров.
Если вам на собеседовании поставили задачу в такой размытой формулировке, не пытайтесь сразу приступать к её решению. В первую очередь уточните требования и ограничения. Задумайтесь на минуту, какие вопросы следует задать.
После уточнения задачи получаем следующие вводные: — имеется клиент-серверное приложение интернет-магазина с возможностью поиска товаров;
— количество записей в результате поиска может доходить до 1кк;
— к полученным в результате поиска товарам можно применять множественные фильтры, у каждого фильтра есть набор значений;
— у разных категорий товаров разный набор фильтров;
— после применения конкретного фильтра появляется новая выборка и для нее также должны отображаться только актуальные фильтры. Рассмотрим на примере. Для телефонов должны быть фильтры "производитель" и "операционная система". После применения фильтра "производитель: Apple" в фильтрах ОС уже не может быть значения Android;
— для каждого значения фильтра необходимо отображать количество подходящих товаров. После выбора одного фильтра все счётчики должны пересчитываться. Было "производитель": "Apple: 10", "Xiaomi: 20", "Встроенная память": "128 Гб: 10", “256 Гб: 20". Выбрали "128 Гб", после применения станет, например, "производитель": "Apple: 7", "Xiaomi: 19". То есть 3 модели Apple и 1 модель Xiaomi не попали под выбранный фильтр.
— данные хранятся в PostgreSQL. Отдельно подумайте, как можно решить задачу, если у вас не стоит ограничение на базу данных
Как на настоящем собеседовании, уточняющие вопросы можно задать в комментариях. Наше решение задачи в 20:00 среды.
Продолжаем тему собеседований. Классический анекдот: Студент сдаёт экзамен по зоологии, а подготовился только к вопросу про блох. Тянет билет — там про собак. Начинает отвечать, что собака — млекопитающее, у неё есть голова, 4 лапы, хвост, всё это обильно покрыто шерстью, а в шерсти — блохи! И подробнейшим образом про блох. Преподаватель прерывает и просит рассказать про кошек. Студент снова: голова, усики, лапы, хвост и много шерсти, в которой — блохи, и опять про блох. Преподаватель снова прерывает и просит рассказать про рыб. Студент: тааак, рыбы., рыбы... плавают в воде, дышат жабрами, покрыты чешуёй. В чешуе блохи не водятся. Это спасает рыб от проблем с блохами. И снова про блох...
Рекомендуем версию этого анекдота с интересной историей из жизни про экзамен в РХТУ им. Менделеева. К чему это мы?
При ответе на собеседовании или на экзамене важно показать обширность и глубину ваших знаний. Выгодно максимально подробно отвечать, даже если ответ не совсем по теме. Забыли, что значит D в SOLID? Постарайтесь построить ответ так, чтобы максимально подробно рассказать про знакомые буквы. В процессе вспомнили другие темы, например, аббревиатуры, связанные с исходным вопросом? Пускайте в ход DRY, YAGNI, KISS, NIH-синдром, bus-factor и кучу другого материала, по возможности вплетая его в повествование. Высока вероятность, что собеседник забудет, что вы не до конца ответили на поставленный вопрос. Чем уместнее вы притянули смежные темы, тем менее заметна попытка скрыть незнание. Конечно, если тема совсем не к месту, то будет обратный эффект с обнаружением вашего незнания.
Кроме того, можете расставлять "ловушки". Намеренно допустите неточность в рассказе, на которую интервьюер среагирует наводящим вопросом, что ещё дальше отвлечёт его от исходного вопроса. Ляпните, что абстрактный класс и интерфейс — это одно и то же. На возмущённый уточняющий вопрос картинно задумайтесь, и дополните ответ, что не совсем одно и то же, и начните рассуждать о нюансах. Важно! Неточность можно допускать только там, где вы действительно хорошо ориентируетесь.
Но не злоупотребляйте таким приёмом. В работе важно уметь честно признать, что чего-то не знаешь. Нельзя знать всего, надо учиться у коллег, в том числе на правильном code review.
Если вы интервьюируете человека или принимаете экзамен, наоборот, добивайтесь конкретного ответа на поставленный вопрос.
Выстроенный code review позволяет: — найти баги и не пропустить их в прод. Конечно, в дополнение к статическому анализу с помощью настроенного pre-commit и тестам; — выявить проблемы в архитектуре; — сделать код единообразным. Спорный тезис, за единообразие должны отвечать линтеры и автоформатирование. Но code review помогает наладить те вещи, которые автоформатирование не тянут, например, именование переменных.
В долгосрочной перспективе постоянные code review: — налаживают обратную связь между участниками; — бустят уровень разработчиков, позволяя учиться на своих и чужих ошибках и давая обширную практику чтения чужого кода; — помогают делиться знаниями о технологиях, вариантах решения проблем, возможных проблемах и самом проекте в команде; — дают приток новых идей для улучшений в процессах, подходах и автоматизации; — увеличивают децентрализацию знаний и bus factor.
Бывает, смотришь на код и сразу видно, что код плохой. Признаков может быть множество: — разные куски кода по-разному отформатированы; — импорты в файлах никак не структурированы; — используются вперемешку синтаксис старых и новых версий питона; — где-то видны зачатки использования типов, но не везде; — где-то docstring есть, где-то нет; Всё это характеризуется так: нет единого стиля в написании кода. Проблема становится особенно актуальной, когда над проектом трудится несколько разработчиков.
Частично эту проблему решает встроенный в среду разработки анализатор кода или запускаемые вручную анализаторы кода. Но анализатор в среде разработки может быть настроен по-разному у разных членов команды. Если в проекте принято использовать несколько анализаторов одновременно, то разработчик может забыть прогнать код через все анализаторы до коммита.
Для решения всех обозначенных проблем есть замечательная утилита — pre-commit. Один раз в конфиге прописываете, какие анализаторы кода нужно запускать, и далее при любом коммите они будут запускаться автоматически. С этого момента код будет опрятным и шелковистым. Вы просто не сможете сделать коммит, если у анализатора есть вопросики к коду.
❌ Оказалось, что есть типовые вопросы, которые часто задают на собеседованиях, но к которым я специально не готовился. ООП, SOLID, микросервис vs монолит и подобное — без подготовки ответ выходит путанным. ✅ Подботал типовые вопросы.
❌ В какой-то момент я забывался, что нахожусь на интервью и общался с интервьюером, как с коллегой: рассказывал о каких-то негативных моментах в прошлых проектах, говорил от имени команды в контексте "Мы”. ✅ На интервью должна быть дружеская атмосфера, но не нужно забываться. Интервьюера нужно убедить, что я именно тот специалист, который им нужен. На работу устраиваюсь Я, значит в моих рассказах должно быть побольше Я и поменьше Мы. В эту же сторону, поменьше рассказывать о каких-то проблемных местах, побольше рассказывать о удачно решённых задачах.
❌ Во время рассказа "о себе" уходил в ненужные подробности, из-за чего рассказ получался водянистым и производил скорее негативное впечатление. ✅ Я полностью прописал рассказ "о себе", в несколько заходов вычитал и отрепетировал, чтобы в итоге было недолго и по делу.
❌ Когда интервьюер спрашивал "есть ли у меня вопросы по вакансии и компании", то возникала заминка. Я спрашивал не очень связно и не всё, что действительно хотел узнать о потенциальном работодателе. ✅ Для этого я также составил чеклист со списком интересующих меня вопросов.
Странное дело: Телеграм используют миллионы человек, а внятных гайдов по его удобному использованию я не встречал. Интернет полнится только всратыми лайфхаками вроде "10 полезных функций Телеграм" с набором фич разной степени полезности. Но ни у кого я не видел целостной картины, как ТГ превратить в удобный инструмент для решения задач. Усаживайтесь поудобнее, я вам всё покажу.
Это статья из моего цикла "Нетехнические инструменты разработчика", где я делюсь своим опытом: веду задачи в TickTick, трекаю рабочее время, преодолеваю откладывание дел с помощью декомпозиции задач.
Что разберём
как удобно работать с огромным количеством личных чатов с длительным сроком жизни
как удобно организовать чтение каналов, если их много
Как работать с огромным количеством чатов с длительным сроком жизни
Описанное подойдёт вам, если у вас много (десятки и сотни) постоянных чатов. Что значит "постоянных"? Я с одними и теми же людьми контактирую длительное время, месяцы и годы. То есть мой опыт не подойдёт, если вы условный менеджер по продажам с кучей ежедневных новых контактов, но весьма временных, то есть по которым дальнейшее общение не предполагается.
Мой метод пережил три больших этапа моей жизни:
преподавание, при котором в личном чатах десятки студентов, которые что-то хотят спросить или сдать;
разработка, при которой активно плодятся рабочие групповые чаты;
менеджерская позиция и люди в подчинении, когда групповых чатов становится ещё больше.
К последнему мой гайд относится в меньшей степени. Почему? Для позиции преподавателя и разработчика во главу угла я поставил минимизацию прерываний. Это значит, что для основной работы мне нужно обеспечить что-то вроде состояния потока (см. Как поймать «поток»), когда я вовлечён в рабочий процесс (будь то программирование, проверка задания или проектирование нового курса). Любой интеррапт, к которому относится и "прочитать сообщение в месенджере", прерывает поток, откатывает нужный настрой, ломает красивые абстракции в голове. Причём исследования (см. Никогда не отвлекай программиста) показывают, что любое прерывание по факту занимает больше 10 минут, чтобы вернуться к решению задачи. Вот такая вот плата за прерывание контекста у кожаного мешка.
Мой гайд по работе с рабочими чатами и группами чатов такой:
Создаём нужные папки. Думаю, всем пригодятся папки Р (рабочее) и dev (групповые чаты). Чтобы больше папок влезло без необходимости скроллить право, я пришёл к названию папок в 1-3 буквы. Не очень удобно по началу, но я быстро привык. Альтернативное решение – вместо букв использовать эмодзи, но я для этого староват, видимо. По неизвестной науке причине мне некомфортно с иконками в названиях чатов, слишком аляписто, что ли.
Добавляем в Р (рабочее) все рабочие контакты.
Добавляем в dev (групповые чаты) все групповые рабочие чаты.
Опциональный пункт. Для студентов я создал отдельную папку Ст (студенты). Но! Каждого студента при добавлении в контакты я ещё дополнительно помечаю номером его группы, чтобы упростить навигацию. У меня устоялась пометка в формате <год-поступления>-<номер-группы>-<первые-3-буквы-фамилии>, типа 2020-50-iva для Иванова из группы 50, поступившего в 2020 году. Такой формат обозначения вошёл у нас в практику регистрации на институтском гитлабе, поверх которого всякая автоматизация накручена.
Выключаю на всех групповых (кроме тех, где критически важно быстро реагировать) и студенческих чатах звук и все нотификации. У меня получилось, что контакты из Р довольно редко пишут по неважным и несрочным делам, поэтому звук я там оставил. Если бы там часто писали, я бы звук и там выключил. Или договорился общаться беззвучными сообщениями, это просто бомбическая фича в ТГ. Кто не знает – зажмите кнопку отправки сообщения (или правой кнопкой мыши на компе), и появится выбор – отправить сообщение без звука или отложенное сообщение. Отложенное сообщение тоже часто применяю, чтобы напомнить о каком-то деле, прислать мем не ночью и всякого такого.
Теперь у меня 3 папки с чатами (Р, dev, Ст), и вверху есть число непрочитанных чатов в этой папке.
Когда есть время, я смотрю чаты и отвечаю. Но теперь это асинхронное средство общения – уведомления меня не отвлекают от состояния потока. Как часто читать чаты? Я стараюсь ориентироваться на 1-3 часа для рабочих и групповых чатов (на мой взгляд, приемлемая скорость реагирования на не-срочные задачи), и 1-3 дня для студентов (в моём случае студентам мгновенная реакция не требуется).
Схему легко расширять, создавая ещё папки для отдельных групп чатов. В ТГ есть лимит по 100 чатов на папку. С помощью Premium его можно расширить до 200 чатов на папку.
Важные чаты можно закрепить, у каждой папки вроде можно закрепить до 5 чатов (и 10 с премиумом).
Конечно, ещё неплохо включить режим "не беспокоить" в нерабочее время. У меня это с 22:00 до 08:00 -_-
Как удобно читать много каналов
Во главе угла также минимизация прерываний. Поэтому вообще все каналы у меня без звука. Очень удобно по умолчанию сделать подписки беззвучными, для этого зайдите настройки – уведомления и звуки – выключить уведомления на каналах. После этого после подписки канал сразу будет без звука.
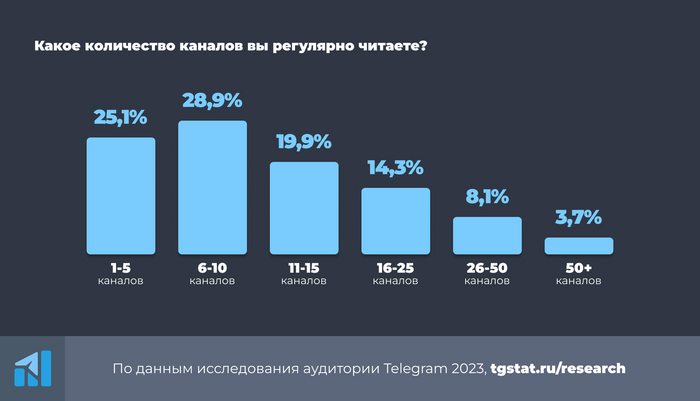
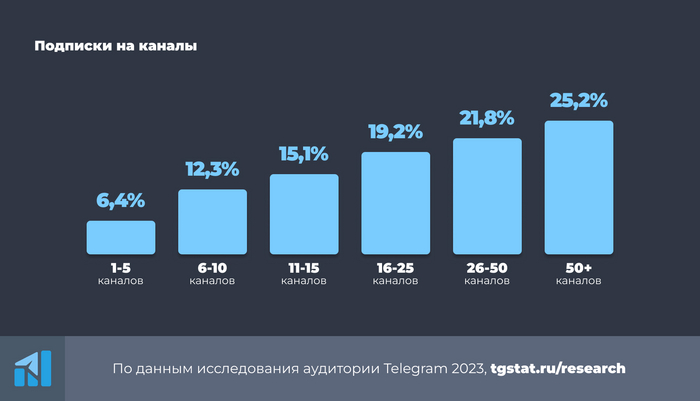
По данным mediascope, в конце 2023 года 84% пользователей читают каналы в ТГ. А у tgstat есть более детальный опрос про количество каналов.
Забавно при этом, что многие подписаны на какое-то адовое число каналов. Но не читают.
Я отношусь к той малой категории людей, которые читают 50+ каналов. Но мой способ чтения, в целом, будет полезен при любом количестве каналов, если вы периодически добавляете новые каналы и удаляетесь из более не актуальных.
Создаём две папки. Я назвал их К (контент) и S (хрен знает почему...).
В К (контент) добавляем самые важные для вас каналы, которые хочется читать всё время. Когда есть время для прокрастинации, читаем отсюда, пока все каналы не прочитаем.
В S добавляем новые, непроверенные каналы. Читаем, когда всё из К уже прочитано, и хочется чего-то ещё.
Если канал из К долго не читается, удаляем его совсем или переносим в S.
Если канал из S всё время хочется прочитать, переносим в К и читаем всё время :)
Для К я сверху закрепил несколько каналов, которые читаю в первую очередь.
Если постоянно остаются непрочитанные каналы, стоит задуматься и отписаться от не интересного вам.
Для удобства я ещё сделал папку Ch (chats), куда положил домовой чат (и закрепил), плюс все чаты каналов с отдельной подпиской. Но этой папкой я в итоге почти не пользуюсь, кроме время от времени заглядывания в домовой чат.
Такое деление на две группы каналов по приоритету позволяет подписываться на кучу временных каналов (типа, о, что-то прикольное), но при этом не терять основные каналы, которые хочется прочитывать всегда. И теперь вкладку "все чаты" можно игнорировать. Хотя я во "всех чатах" закрепил основные чаты (жена и пара друзей), с которыми я чаще всего веду переписку.
Ещё в какой-то момент Телеграм автоматически создал папки "личное" (куда попадают все личные чаты, то есть не каналы и не боты) и "боты" (где все боты и мини-аппы). Довольно удобно. Я сократил названия до Л (личное) и Б (боты). Личное удобно использовать, чтобы посмотреть последние чаты (из всех папок сразу).
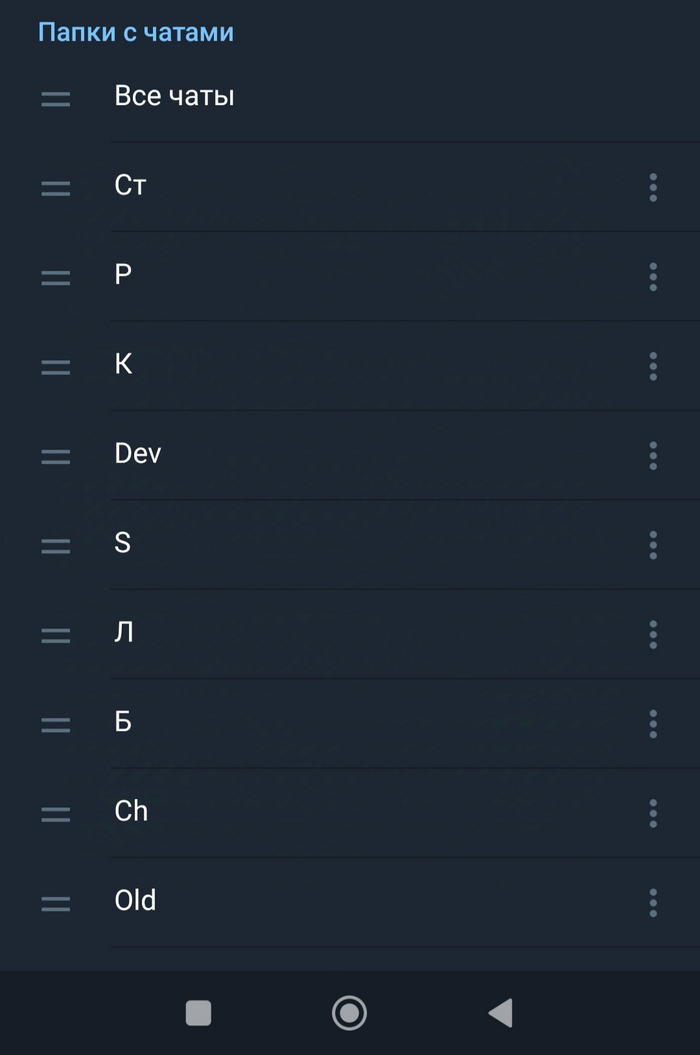
В итоге получаем такую картину папок
А в верхнем меню это выглядит так. Блоки S с неважными каналами и чаты Ch не влезают, нужно скроллить.
Сейчас болею и даже основые каналы нет сил читать, поэтому накопилось непрочитанных уведомлений в каналах.
Вот такой вышел гайд по применению ТГ для разработчика или тимлида. Или профессионального читателя каналов :)
Рекомендовал вам записать своё собеседование. Поскольку непроверенных советов я не даю, то совет я изначально обкатал на себе, то есть записал и проанализировал свои собеседования. Тезисно изложу свои ошибки, замеченные в результате просмотра собеседований и решения, к которым пришел.
❌ В самом начале собеседования возникала какая-то суета: включена ли камера и звук, открыто ли мое резюме, под рукой ли ручка с блокнотом. ✅ Составил небольшой чеклист, по которому пробегался за пару минут до начала собеседования.
❌ Камера смотрела не на меня, а в сторону, при этом я сам не смотрел в камеру, иногда я говорил не в микрофон и меня было плохо слышно. Да, это тоже очень важно. Собеседнику должно быть комфортно с вами общаться. ✅ Заранее настроил камеру, чтобы по умолчанию смотреть на собеседника, сделал в голове заметку говорить в микрофон.
❌ Я спешил ответить на вопрос интервьюера и начинал отвечать до завершения вопроса. Со стороны выглядело так, будто я просто перебиваю собеседника. Более того, иногда вопрос мог оказаться совсем не таким, как я думал. ✅ Пункт "дослушивать вопрос и не перебивать собеседника" отправился в копилку заметок.
❌ Порой меня спрашивали о технологиях, с которыми я не работал и про которые мало знал. В этот момент я терялся. ✅ При более предметном анализе оказалось, что на любую малознакомую технологию у меня в багаже есть аналогичная, решающая поставленную задачу. Я сделал для себя заметку: если не работал с технологией, не теряйся, подумай, как решить задачу знакомым способом. Более глобальная мысль: стараться минусы обращать в плюсы. И не забывать постоянно изучать разные технологии.
Современный специалист должен быть в курсе большого количества различных технологий и инструментов. Подобное знание не появляется из ниоткуда и не может быть освоено за выходные. Только процесс постоянного поиска информации и решения прикладных задач может приблизить к умению решать любую проблему за счёт представления места обитания потенциальных источников проблем.
Как организовать процесс постоянного поиска информации? Нужно на постоянной основе (в идеале ежедневно, нормально раз в несколько дней, приемлемо еженедельно) потреблять разнородную информацию как в своей профессиональной области, так и в различных соседних. Это существенно расширяет кругозор и повышает вероятность решения новой задачи впоследствии. Не стоит забывать и про не-технические скиллы, куда входят управление людьми, воспитание детей, истории из жизни — это позволит ориентироваться не только в технологиях, но и в жизни.
Неплохим источником информации для постоянного потребления могут быть проверенные книги, телеграм-каналы, подкасты, хабр, площадки вроде hackernews. Решать прикладные задачи самому тоже не следует забывать.
На хабре каждый день читай топ-3 статьи за сегодня, еженедельно читай лучшие 20 статей за неделю. При этом смотри не только саму статью. Часто более полезным является чтение комментариев, где сторонние люди любыми способами постараются доказать, что автор не прав. Чужие мнения могут развить твоё критическое мышление — умение видеть проблему в предлагаемом способе решения задачи.
В году чуть больше 50 недель. При еженедельном чтении десятка статей за год ты прочитаешь около 500 статей. Эти 500 статей и комментариев с обсуждением пополнят копилку решений и обсуждений. Ещё обсуждая с коллегами очередную задачу, можно приобрести опыт решения 500 других задач. И подойти к следующей задаче во всеоружии.
Помни: пока ты спишь, враг качается.
В телеграм-канале DevFM пишу о полезном для разработчика: инструментах, например, Raycast, или об архитектурных схемах, или записываю видео разного уровня, например, для начинающих по FastAPI + Docker. А ещё у нас есть бесплатный курс cli-for-dev по Linux на степике, немного подкастов и видео. Вливайся!